Walmart 会在一天内多次调整部分商品的价格。,你一定懂那种痛苦:脚本刚开始还能正常跑 20 分钟,接着就悄悄开始返回伪装成正常 200 OK 响应的 CAPTCHA 页面。
在 Thunderbit 的数据提取工作中,我花了大量时间研究 Walmart 的反爬防线,也想把我学到的一切分享给你——哪些方法在 2025 年真正有效、哪些“静默失败”会污染你的数据,以及在自建爬虫、付费抓取 API、和直接用无代码工具之间该如何做出诚实的取舍。这篇指南会涵盖三种提取方法(HTML 解析、__NEXT_DATA__ JSON 和内部 API 拦截)、生产环境级别的错误处理(大多数教程都会直接跳过),以及帮你选择合适方案的决策框架。无论你是在写 Python,还是只想在午饭前拿到一整份价格表,这里都有你需要的内容。
为什么要用 Python 抓取 Walmart?
Walmart 是全球按营收计算最大的零售商——,并且。这个网站大约有,Walmart 的 CFO 还提到其平台上有。其中大约,这意味着商品目录非常不稳定——卖家不断更替,变体随时变化,库存也天天翻转。
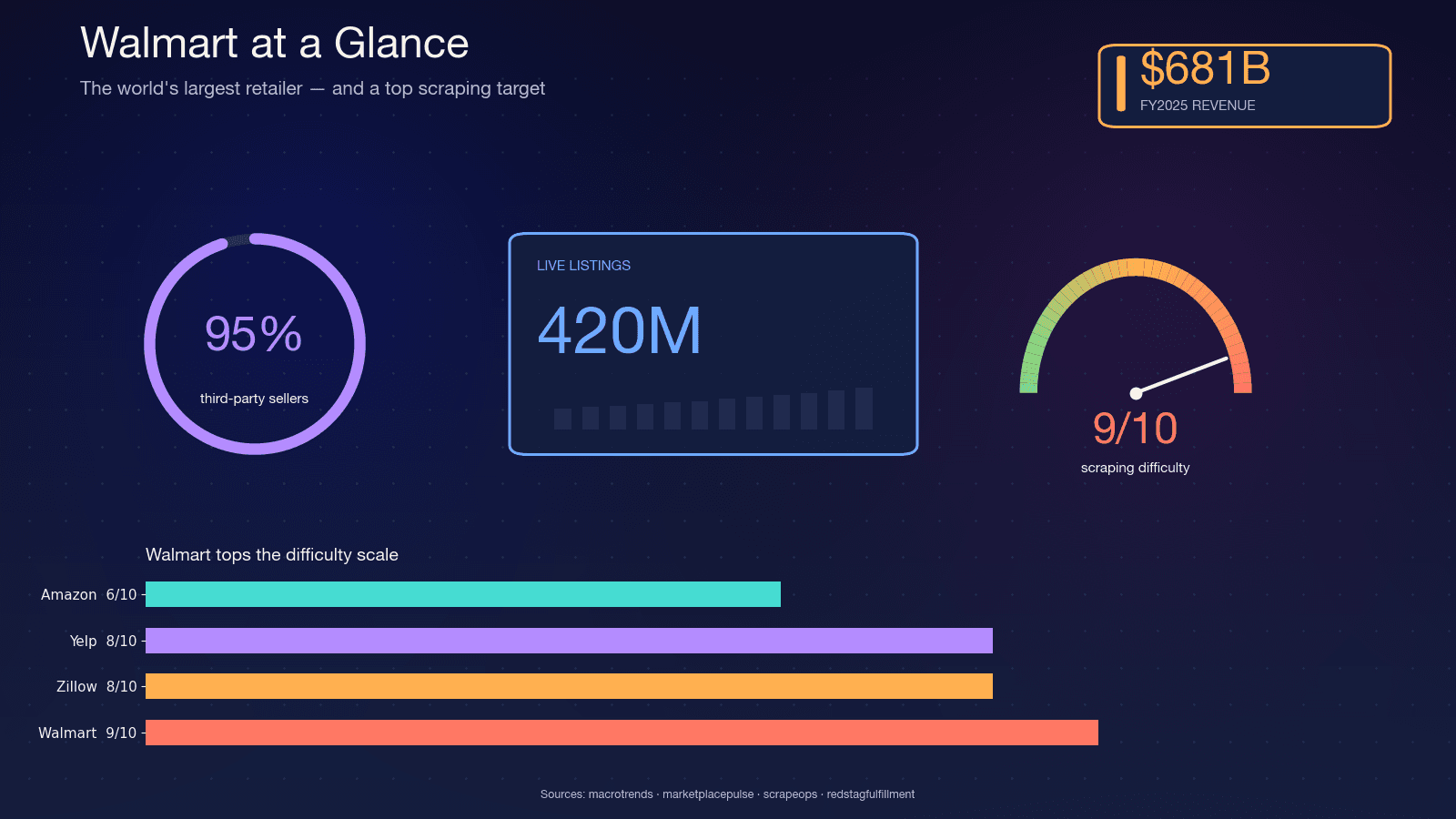
正因为这种波动性,抓取才有价值。季度报告捕捉不到夜间抓取能看到的变化。下面是我最常见的几个用例:
| 用例 | 需要它的人 | 提取什么 |
|---|---|---|
| 竞品价格监控 | 电商运营、调价工具 | 价格、促销、MAP 合规性 |
| 商品目录丰富化 | 销售与商品团队 | 描述、图片、规格、变体 |
| 库存可用性追踪 | 供应链、代发货商 | 库存状态、卖家信息 |
| 市场研究与趋势分析 | 市场营销、产品经理 | 评分、评论、类目结构 |
| 线索生成 | 销售团队 | 卖家名称、商品数量、类目 |
单是,并预计到 2033 年将增长到 50.9 亿美元。消费者行为推动了这部分支出:,而且 83% 的人会跨多个网站比价。
Python 是这类工作的默认语言。Apify 的 2026 基础设施报告显示,,而核心库 requests 每周下载量约。如果你要做任何规模的抓取,几乎肯定会用 Python。
为什么 Walmart 是最难抓的网站之一
Walmart 之所以特别难抓,是因为它串联了 两层商业级反爬产品: 作为边缘 WAF 和 TLS 指纹识别层,以及作为行为型 JavaScript 挑战层。Scrape.do 形容这种组合“罕见且极难绕过”。
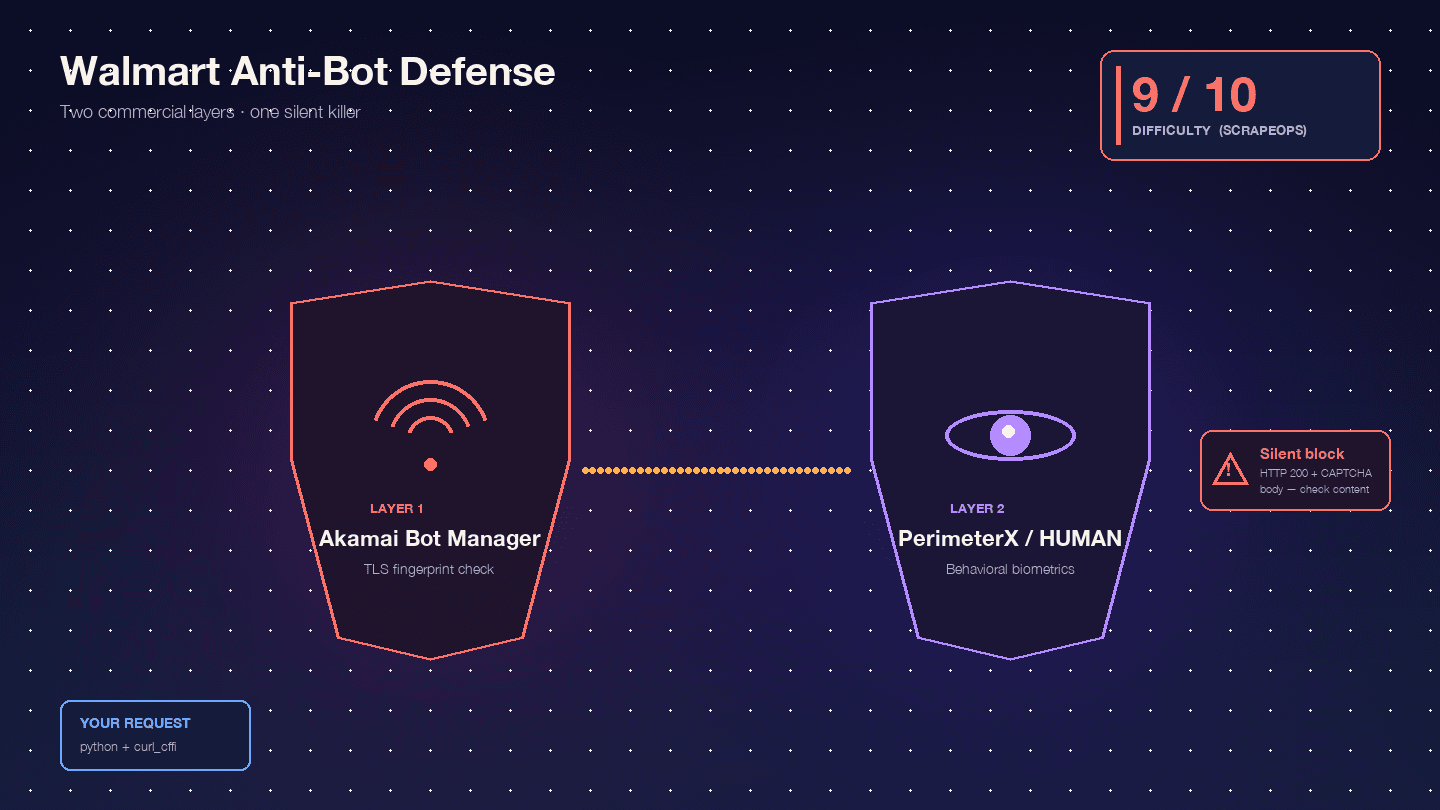
,其中单是 Akamai 就是 9/10。以我的经验来看,这个评分相当准确。
你实际面对的是这些:
Akamai Bot Manager 会检查你的 TLS 指纹(JA3/JA4 哈希)、HTTP/2 帧顺序、请求头顺序和大小写,以及会话 Cookie(_abck、ak_bmsc)。普通 Python requests 调用会发出真实浏览器不会生成的 TLS 指纹——Akamai 在你的请求到达 Walmart 服务器之前就会把它拦下。
PerimeterX/HUMAN 在 Akamai 之后运行,执行 JavaScript 指纹识别(px.js),检查 navigator 属性、canvas 渲染、WebGL、音频上下文,以及行为生物特征(鼠标移动、滚动速度、按键节奏)。最直观的失败表现就是臭名昭著的——你必须按住按钮大约 10 秒,系统会在期间采样行为信号。Oxylabs 说得很直接:“Walmart 使用的是 PerimeterX 提供的 ‘Press & Hold’ CAPTCHA 模式,从代码层面几乎不可能解决。”
真正危险的是 静默拦截。Walmart 会返回 HTTP 200 但内容是 CAPTCHA 页面,而不是 403。:“即使它返回的是 CAPTCHA 页面,Walmart 也会给出 200 OK 状态码。你不能只靠状态码判断请求是否成功。” 你的脚本会把 CAPTCHA HTML 当成“未找到商品”来解析,然后继续往下跑。结果是一半数据都成了垃圾,但你根本不知道。
还有 门店范围数据 问题。Walmart 的价格和库存跟地点有关,由 locDataV3 和 assortmentStoreId 之类的 Cookie 控制。没有正确的 Cookie,你拿到的会是“默认全国数据”,看起来很完整,但和真实购物者看到的并不一致。缺少这些 Cookie 不会触发拦截页——它会直接给你 错误数据,而且没有任何可见失败,这更糟。
从 Walmart 提取数据的三种方法(以及如何比较)
在开始分步教程之前,先看看三种主要提取方式。大多数竞品教程只讲一两种。我会把三种都讲清楚,这样你就能选出最适合自己的方案。
| 方法 | 可靠性 | 数据完整性 | 反爬难度 | 维护成本 |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ 低(每次部署选择器都可能失效) | 中等 | 高 | 高 |
__NEXT_DATA__ JSON | ✅ 好 | 高 | 中高 | 中等 |
| 内部 API 拦截 | ✅ 最佳 | 最高(变体、库存、评论) | 中高 | 低(结构化 JSON) |
| Thunderbit(无代码) | ✅ 好 | 高 | 低(由 AI 处理) | 无 |
对 Walmart 来说,HTML 解析是最差的选择——这个站点使用 Next.js 打包,CSS 类名带哈希,而且每次部署都会变化。__NEXT_DATA__ JSON 方法才是 2024–2026 年所有严肃的开源 Walmart 爬虫都会采用的务实方案。内部 API 拦截最强大,但也有大多数教程不会提到的前提条件。而如果你根本不需要自建管道,Thunderbit 就是更合适的选择。
配置 Python 环境来抓取 Walmart
你需要这些:
- 难度: 中级
- 所需时间: 搭建约 30 分钟,另外还要写代码
- 你需要准备: Python 3.10+、pip、代码编辑器,以及(用于生产环境)代理服务或抓取 API
先创建项目文件夹和虚拟环境:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Windows 上:venv\Scripts\activate安装所需库:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi 是 2025 年抓取高难目标站点的标准方案。它是一个 libcurl 绑定,可以精确模拟浏览器的 TLS 指纹。:“Walmart 会把 TLS 指纹识别作为反爬检测的一部分,即使把 User-Agent 设置成像真实浏览器,也绕不过去。” 普通的 requests 或 httpx 无论你怎么设置请求头,都过不了 Akamai。使用 curl_cffi 并设置 impersonate="chrome124" 才是关键。
你还会用到 json(内置)、csv(内置)、time、random 和 logging,后面讲生产模式时会用到它们。
分步教程:用 Python 抓取 Walmart 商品页
第 1 步:获取 Walmart 商品页
你的第一项任务,是发出一个不会立刻被拦截的 HTTP 请求。下面是 2024–2026 年 Scrapfly、Scrapingdog、Oxylabs 和 ScrapeOps 常用的标准请求头:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)这里真正起作用的是 impersonate="chrome124" 这个参数。它会告诉 curl_cffi 去匹配 Chrome 124 的精确 TLS ClientHello、HTTP/2 帧顺序和伪头顺序。没有它,Akamai 会识别出 Python 特有的 JA3 哈希,并在你的请求到达 Walmart 应用层之前就把你拦下。
被拦截的响应长什么样: 如果你在响应 HTML 标题里看到 "Robot or human?",或者响应跳转到了 walmart.com/blocked,说明你已经被识别出来了。麻烦之处在于,Walmart 常常会返回 200 状态码,但内容却是 CAPTCHA 页面——所以只检查 response.ok 远远不够。
如果是生产环境或重复性使用,你还需要 住宅代理。数据中心 IP 会被 Akamai 的 IP 信誉系统立刻拉黑。后面的生产环境部分会讲完整的错误处理和代理策略。
第 2 步:从 __NEXT_DATA__ JSON 解析商品数据
Walmart.com 是一个 Next.js 应用,服务端渲染的 HTML 会把完整的 hydration 负载放进一个脚本标签里:<script id="__NEXT_DATA__" type="application/json">。这就是金矿。
:“到了 2026 年,Walmart 使用 Next.js,并在 __NEXT_DATA__ script 标签中放入结构化 JSON,因此从隐藏数据中提取信息比传统 CSS 选择器解析更可靠。” 所有知名的开源 Walmart 爬虫——、、——都在用这种方法。
下面是提取方式:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})大多数教程讲到这里就结束了。下面是一份 完整的 JSON 路径映射,对应你真正关心的字段——我已经用 2024–2026 年的 Walmart 实际页面验证过:
| 数据字段 | JSON 路径(在 initialData 下) | 类型 | 备注 |
|---|---|---|---|
| 商品名称 | data > product > name | 字符串 | — |
| 品牌 | data > product > brand | 字符串 | — |
| 当前价格(数值) | data > product > priceInfo > currentPrice > price | 浮点数 | 可能因门店 Cookie 不同而变化 |
| 当前价格(字符串) | data > product > priceInfo > currentPrice > priceString | 字符串 | 格式化后的价格,例如 "$9.99" |
| 简短描述 | data > product > shortDescription | HTML 字符串 | 可用 BeautifulSoup 解析成文本 |
| 长描述 | data > idml > longDescription | HTML 字符串 | 在 idml 里,不在 product 里——这是老教程最容易踩的坑 |
| 全部图片 | data > product > imageInfo > allImages | 数组 | 由 {id, url} 对象组成的列表 |
| 平均评分 | data > product > averageRating | 浮点数 | 键名是 averageRating,不是旧版的 rating |
| 评论数 | data > product > numberOfReviews | 整数 | — |
| 变体 | data > product > variantCriteria | 数组 | 选项组(尺寸、颜色) |
| 可用性 | data > product > availabilityStatus | 字符串 | IN_STOCK、OUT_OF_STOCK、LIMITED_STOCK |
| 卖家 | data > product > sellerDisplayName | 字符串 | — |
| 制造商 | data > product > manufacturerName | 字符串 | — |
longDescription 这个路径最容易让人踩坑。2023 年的 ScrapeHero 文章把它放在 product.longDescription,但 2024 年之后的来源都一致把它放在同级的 idml 键下。请务必先读 idml.longDescription,再为更老的页面回退到 product.longDescription。
下面是使用 .get() 链的安全提取写法:
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }如果你根本不想处理 JSON 路径导航, 会自动识别并结构化这些字段——完全不用手动映射路径。你只要点一下“AI 推荐字段”,它就会读取页面并给出表格。但如果你在搭建自定义管道,上面的映射就是你的参考标准。
第 3 步:拦截 Walmart 的内部 API 端点以获取更丰富的数据
没有竞品文章把这个方法讲透。它是最强大的提取路径——也是最复杂的。
Walmart 前端调用的是。这些端点位于 www.walmart.com/orchestra/* 之下:
/orchestra/pdp/graphql/...—— 商品详情 hydration + 变体切换/orchestra/snb/graphql/...—— 搜索与浏览分页/orchestra/reviews/graphql/...—— 分页评论
这些接口会返回干净、结构化的 JSON,而 __NEXT_DATA__ 有时会截断其中的数据——比如变体级定价、实时库存数量、完整评论分页。
很多博客都会含糊带过的关键点: Walmart 使用的是。请求体里只发送 SHA-256 哈希(persistedQuery.sha256Hash),不会发送查询文本本身。如果这个哈希服务器不认识,你就会收到 PersistedQueryNotFound。Walmart 会在部署时轮换这些哈希。这也是为什么那些知名开源 Walmart 爬虫都不会直接公开可复制粘贴的 /orchestra/ 代码。
这种方法的实际可行版本,本质上就是一场 DevTools 操作:
- 在 Chrome 中打开 Walmart 商品页
- 打开 DevTools → Network 标签页,筛选 “Fetch/XHR”
- 正常浏览页面——点击变体、滚动到评论区、切换门店位置
- 观察返回商品数据的
/orchestra/*请求 - 右键请求 → “Copy as cURL”
- 用
curl_cffi把 cURL 命令转换成 Python
下面是重放 API 调用的样子:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# 先访问商品页,预热会话
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# 再重放内部 API 调用(从 DevTools 复制)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "你复制来的 correlation id",
14}
15payload = {
16 # 粘贴从 DevTools 复制的完整请求体
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "你复制来的哈希"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()会话预热这一步非常关键。Walmart 的 PerimeterX Cookie(_px3、_pxhd、ACID)必须先通过首个 HTML 请求设置好,后面的 API 调用才会成功。没有这些 Cookie,你就会收到 412 或 403。
什么时候用这种方法: 当你需要 __NEXT_DATA__ 不包含的数据时——深层变体定价、第一页以外的分页评论、或者实时库存数量。对大多数场景来说,__NEXT_DATA__ 已经足够,而且简单得多。
抓取 Walmart 搜索结果和多页内容
搜索结果也遵循类似的 __NEXT_DATA__ 模式,但 JSON 路径不同:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# 过滤赞助商品
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))分页通过递增 page 参数实现:&page=1、&page=2,以此类推。但这里有个没有文档说明的上限:无论总页数多少,Walmart 搜索结果最多只能访问 25 页。 :“Walmart 将可访问的结果页最大数量限制为 25 页,不管实际总页数是多少。”
如果要覆盖更深的内容,可以试试这些绕法:
- 切换排序顺序:同一个查询先用
&sort=price_low再用&sort=price_high,大约能拿到 50 页覆盖 - 按价格区间切分:添加
&min_price=X&max_price=Y,把目录切成更小的窗口 - 按类目切分:在特定类目内搜索,而不是全站搜索
注意 itemStacks 是一个数组。Scrapfly 在仓库里写死了 [0],但类目页和浏览页有时会包含多个堆栈(如“Top picks”、“More results”)。更稳健的写法是遍历所有堆栈:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # 处理 item
5 pass还有一点值得注意:Walmart 的 robots.txt 。商品详情页(/ip/...)和大多数类目页(/cp/...)并没有被禁止。如果你在意合规性,建议从商品页和类目树开始,而不是搜索页。
别让静默拦截毁掉你的数据:生产级错误处理
大多数教程都死在这里。它们会告诉你如何抓一页、解析一个商品,然后就此收工。可在生产环境里,你要抓的是成千上万页,而 Walmart 也在积极阻止你。演示版爬虫和真正可用的爬虫,区别就在于它如何处理失败。
在静默拦截污染数据之前把它们识别出来
Walmart 爬虫里最重要的函数,就是拦截检测器。根据 、、 和 的一致经验,你需要做四个独立检查:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. 重定向到专门的拦截端点
10 if "/blocked" in str(response.url):
11 return True
12 # 2. 明确的状态码
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK 但内容是 CAPTCHA 页面(静默拦截情况)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. 响应长度检查——真正的 PDP 通常有 300–900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return False第四个检查——响应长度——能抓住那些 Walmart 返回精简页面、既没有明显 CAPTCHA 标记,也没有你需要的商品数据的情况。
使用指数退避 + 抖动的重试逻辑
当请求失败时,你不应该立刻猛刷 Walmart。标准做法是用带抖动的指数退避来错开重试时间:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"限流:\{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("检测到静默拦截")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"第 {attempt + 1} 次尝试失败:\{e\}。将在 {wait:.1f} 秒后重试")
20 time.sleep(wait)
21 return None这个抖动(random.uniform(0, 3))不是装饰性的——它能让一组爬虫错开重试,避免在同一秒内一起重试,从而触发 Akamai 的速度检测。
限速
和 都给 Walmart 归纳出一个一致的策略:每次请求之间随机等待 3–6 秒。“通过在页面加载之间等待 3–6 秒并随机化延迟来限制请求频率。”
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return response在规模更大时,可以用 aiolimiter 做异步限速:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 每分钟 10 个请求数据校验
即使响应没有被拦截,解析出来的数据也可能是错的(门店不对、载荷退化)。写入输出前一定要校验:
1def validate_product(product):
2 """如果商品数据看起来可信,则返回 True。"""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return True会话日志记录
跟踪每个会话的成功率。当它连续 10 分钟跌到 80% 以下时,说明情况变了——要么你的 IP 已经被烧掉,要么 Cookie 过期了,要么 Walmart 部署了新的反爬规则。
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"成功率已降至 {self.success_rate:.1f}%——请考虑轮换代理或暂停")不够炫酷,但它能保证你的数据干净。
自建 Python、抓取 API、还是无代码:选择抓取 Walmart 的正确方式
很多开发者会直接开始写自定义爬虫,却没先问这是不是最合适的做法。。论坛用户也把它描述成“基本就是 9/10”,并且会问“专门的网页抓取 API 会不会有点杀鸡用牛刀”。答案取决于规模、预算和工程能力。
| 因素 | 自建 Python(requests + 代理) | 抓取 API(Oxylabs、Bright Data 等) | 无代码工具(Thunderbit) |
|---|---|---|---|
| 首行数据搭建时间 | 几小时 | 15–60 分钟 | 约 2 分钟 |
| 生产可用搭建时间 | 40–80 小时 | 4–16 小时 | 约 30 分钟 |
| 反爬处理 | 你自己管(很难) | 由服务商处理 | 自动处理 |
| 小规模成本(<1K 页/月) | 低(代理成本约 4–8 美元/GB) | 入门档 $40–$49/月 | 免费–$15/月 |
| 大规模成本(10 万+ 页/月) | 单页成本更低 | 单页成本更高 | 视情况而定 |
| 可定制性 | 完全可控 | 受 API 参数限制 | 受界面/字段限制 |
| 持续维护 | 每月 4–8 小时 | 几乎为零 | 无(AI 自动适应) |
| 最适合 | 构建自定义数据管道的开发者 | 中等规模生产抓取 | 商务用户、临时一次性提取 |
什么时候适合自建 Python
当你已经有代理合同、需要对请求头、邮编定位或卖家人群做严格控制、每月要索引数百万页导致按记录收费的 API 成本会累积、或者你需要本地部署/合规保障时,自建方案最划算。但代价也很现实:一个具备分页、重试、代理轮换、TLS 模拟和多页面类型 schema 的生产级 Scrapy 爬虫,需要,之后每月还要再花 4–8 小时维护,因为 Walmart 会轮换指纹。
什么时候抓取 API 能帮你省时间
抓取 API 会帮你处理反爬层,这样你就不用自己管了。显示,Walmart 上 ,。像 、 和 这类工具的入门套餐大约是每月 $40–$49。如果你是一个 2–5 人的小团队,每月抓取量在 1 万到 100 万页之间,API 几乎总是更合适的选择。你牺牲的是按次成本,换来零维护。
什么时候无代码才是正确选择
适合完全不同的一类用户。如果你是产品经理、分析师,或者电商运营,希望今天下午就把 Walmart 商品数据放进表格里,而不是等到下个迭代,那无代码工具就是最诚实的答案。
工作流程是这样的:安装 ,打开 Walmart 商品页或搜索页,点击“AI 推荐字段”,Thunderbit 的 AI 会读取页面并建议列(商品名称、价格、评分等)。再点“抓取”,数据就会填入表格。你还能免费导出到 Excel、Google Sheets、Airtable 或 Notion——没有付费墙。
Thunderbit 在云端处理反爬,所以你不用面对 CAPTCHA、代理或 TLS 指纹问题。AI 还会自动适应页面布局变化,因此几乎不需要维护。对于根本不想处理 JSON 路径的人来说,这就是阻力最小的路径。
诚实地说,它也有局限:Thunderbit 不是为每天抓 10 万+ 页而设计的。信用额度和云端上限会让超大规模采集在经济性上不如原生 API。你也不能固定某个邮编或 ASN,除非工具支持。对于持续、高量级的数据管道,自建或抓取 API 仍然更合适。
粗略价格估算: 用 Thunderbit 抓取 1000 条 Walmart 商品数据,大约消耗 2000 credits(Starter/Pro 方案约 $0.60–$1.10)。这个价格和 Oxylabs 的 Walmart API 差不多,而且在低量级场景下通常比大多数入门级抓取 API 更便宜。获取最新信息。
导出你抓到的 Walmart 数据
拿到数据之后,你需要把它放到真正有用的地方。大多数需求用三种格式就够了:
CSV —— 分析师真的会打开的最通用格式:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})请使用 utf-8-sig 编码以兼容 Excel。BOM 标记可以避免 Excel 把特殊字符弄乱。
JSONL —— 适合生产环境抓取管道的格式:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(写入中断时通常只会丢最后一行)、可流式写入且内存占用恒定,还能完整保留变体和评论这类嵌套数据。
Excel —— 适合一次性交给分析师:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["名称", "价格", "可用性", "评分", "评论数", "卖家"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)对非 Python 用户来说,Thunderbit 也把导出这件事解决了:一键导出到 Google Sheets、Airtable、Notion、Excel、CSV 和 JSON——基础套餐全部免费。对于持续监控,Thunderbit 的定时爬虫功能可以自动执行重复提取。
关于定时还有一个注意事项:。GitHub Actions 的运行环境使用的是 Azure IP 段,而 Walmart 的反爬会立刻把这些 IP 拦掉。请在 VPS 上使用 APScheduler,或者把所有流量都走住宅代理。
抓取 Walmart 的法律与伦理指南
论坛用户会很明确地提出这个担忧:“我不介意和开发者玩猫捉老鼠,但我担心和他们的法务团队较量。”
Walmart 的使用条款明确在没有“明确的书面许可”情况下,使用“任何机器人、蜘蛛……或其他手动或自动设备来检索、索引、‘抓取’、‘数据挖掘’或以其他方式收集任何材料”。
Walmart 的 robots.txt /search、/account、/api/ 以及数十个内部端点。商品详情页(/ip/...)和评论页(/reviews/product/)并未被禁止。
hiQ v. LinkedIn 先例(第九巡回法院,)确立了抓取公开可访问数据不太可能违反联邦 CFAA。但同一法院后来又裁定,并对其作出了。更近的 2024 年判决(、)进一步缩小了 CFAA 的适用范围,并引入了版权优先排除抗辩,但这些判决都依赖于特定的 ToU 语言,不能直接套用到 Walmart。
实用建议: 不要把服务器压垮。尊重限速规则。不要抓取个人或用户数据。负责任地使用数据。为了个人研究,以适中频率抓取公开的 Walmart 商品页,和在商业规模下违反 Walmart 条款抓取,风险画像完全不同。如果你要基于 Walmart 数据做产品,请先咨询律师,并了解 Walmart 官方的。
免责声明: 这只是教育信息,不构成法律建议。
结论与核心要点
由于 Walmart 采用了 Akamai + PerimeterX 的双层反爬栈,用 Python 抓取它是一个。不是不可能——但你需要合适的工具和方法。
核心要点:
__NEXT_DATA__JSON 提取是大多数场景下最务实的选择。 这也是 2024–2026 年所有严肃开源 Walmart 爬虫的做法。PDP 的基础路径是props.pageProps.initialData.data.product,搜索/浏览页则是searchResult.itemStacks。- 必须使用
curl_cffi并设置impersonate="chrome124"。 普通requests或httpx无论请求头怎么调,都过不了 Akamai 的 TLS 指纹识别。 - 静默拦截才是真正的危险。 Walmart 会返回 200 OK 但内容是 CAPTCHA 页面。检查响应内容,不要只看状态码。
- 生产级爬虫不能只写“成功路径”代码。 带抖动的指数退避、基于四个信号的拦截检测、每次请求 3–6 秒的限速、数据校验、以及会话健康监控,都是必需的。
- 通过
/orchestra/*拦截内部 API 很强大,但也很脆弱。 把它当成针对特定数据需求的 DevTools 练习,而不是主要提取方法。 - Walmart 把搜索结果限制在 25 页。 想拿更多内容,可以通过切换排序和按价格区间切片来扩大覆盖。
- 诚实选择方案: 如果你是有自定义需求且数据量大的开发者,就用自建 Python。中等规模团队但没有专职抓取工程师,就用抓取 API。如果你是希望今天下午就把数据导入 Google Sheets 的商务用户,就用 。
如果你想走无代码路线,有免费套餐——你可以先抓几页 Walmart 数据看看效果。如果你选择 Python 路线,这篇文章里的代码模式已经过生产验证。无论哪种方式,你现在都已经掌握了 Walmart 的防线,以及穿过去的三条路径。
想了解更多网页抓取技巧,可以查看我们关于、以及的指南。你也可以在 观看教程。
常见问题
抓取 Walmart 商品数据合法吗?
Walmart 的使用条款禁止在未经书面同意的情况下进行自动抓取。第九巡回法院在 hiQ v. LinkedIn(2022)中裁定,联邦 CFAA 很可能不适用于抓取公开页面,但同案最终还是以一项告终,判给了被抓取方。以适中频率抓取公开商品页用于个人研究,和商业规模提取数据,风险完全不同。如果你要基于 Walmart 数据做生意,请咨询律师。
为什么我的 Walmart 爬虫总是被拦?
最常见的原因包括:使用普通 requests 或 httpx(它们会发出 Akamai 一眼就能识别的 Python 特有 TLS 指纹)、请求头缺失或错误、没有代理轮换、每页请求速度快于 3–6 秒、以及缺少会话 Cookie(_px3、_abck、locDataV3)。请改用带 impersonate="chrome124" 的 curl_cffi,使用住宅代理,并实现本文描述的拦截检测和重试模式。
用 Python 能从 Walmart 抓到哪些数据?
商品名称、价格(当前价和回滚价)、图片、简短和长描述、评分、评论数、库存可用状态、卖家名称、制造商信息、变体选项(尺寸、颜色)以及类目位置。使用 __NEXT_DATA__ 方法,这些都可以作为结构化 JSON 获取。内部 API 拦截还能额外返回变体级定价、实时库存数量和分页评论数据。
抓取 Walmart 需要代理吗?
需要,只要是生产环境或重复性使用。——即使请求头完美,非住宅 IP 也会被 Akamai 的 IP 信誉系统标记。必须使用住宅代理或移动代理。数据中心 IP 几乎会立刻被烧掉。按你的代理服务商和套餐,预算大约为每 1000 页 3–17 美元。
不写代码也能抓 Walmart 吗?
可以。 是一个 AI 驱动的 Chrome 扩展,只需两步就能抓取 Walmart:“AI 推荐字段”会自动识别商品数据列,然后点击“抓取”即可提取数据。它在云端处理反爬挑战,并可直接导出到 Excel、Google Sheets、Airtable 或 Notion——全部免费。它最适合分析师、产品经理和业务用户,希望快速拿到数据而不想搭建自定义管道。对于高频或高度定制化抓取,Python 或抓取 API 仍然更合适。
了解更多