
Redfin 会在新上线的美国 MLS 房源发布后 。这种更新速度,对任何搭建房产数据管道的人来说都很有吸引力——也正因为如此,很多爬虫一盯上 Redfin,几分钟内就会被封。
我在 一直从事数据提取工具开发多年,可以很负责任地说:从“抓取 Redfin”到“抓取 Redfin 还不被封”之间,才是大多数教程翻车的地方。很多文章只会给你 BeautifulSoup 代码,却跳过 Cloudflare 如何拦截请求的关键部分,最后你只能盯着 403 页面一脸问号。这篇指南不一样。我会带你走通三种真实可用的方法——HTML 解析、Redfin 的隐藏 API,以及使用 Thunderbit 的无代码方案——并重点讲清楚真正重要的反爬防护。读完之后,你会明确知道哪种方式最适合你的技术水平、数据规模,以及你能接受多少维护成本。
Redfin 是什么?为什么它的数据这么重要?
Redfin 是一家技术驱动型房产经纪公司,拥有领薪经纪人,直接从 MLS 数据源获取房源信息。它覆盖 ,每月服务接近 5000 万访客。与只做聚合展示的平台不同,Redfin 的数据经过经纪人核验,其自有的 Redfin Estimate AVM 覆盖 ,在挂牌房源上的中位误差仅 1.96%。
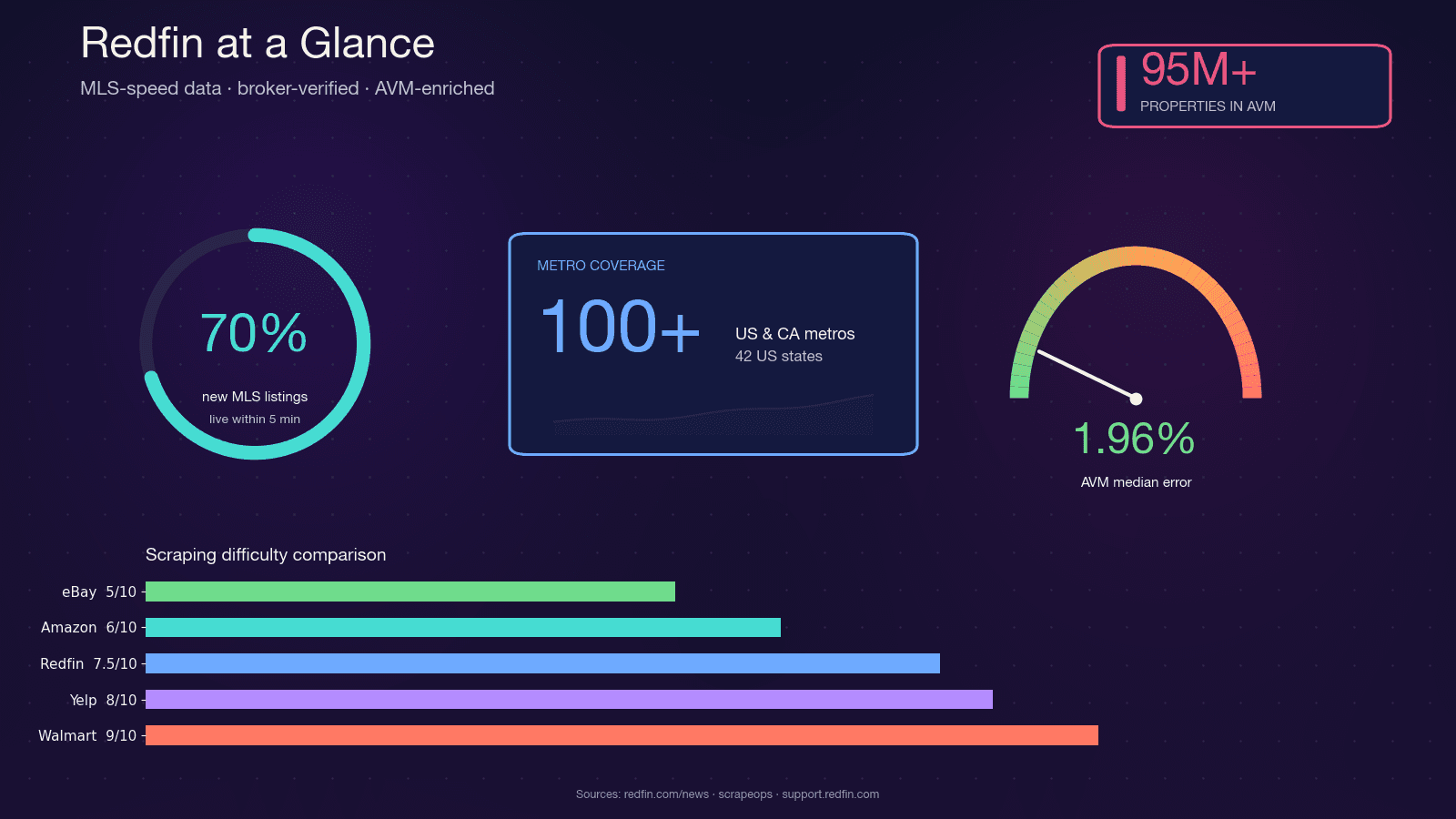
正因为它具备 MLS 级别的更新速度、经纪核验的数据质量,以及精度较高的 AVM,房地产投资人、经纪人、PropTech 初创公司和数据分析师都想以程序化方式获取 Redfin 数据。Python 是做这件事的自然选择:它的爬虫生态已经很成熟(requests、BeautifulSoup、Selenium、Playwright),社区支持强,而且可以直接接入 pandas 和 Jupyter 做分析。
为什么要用 Python 抓取 Redfin?
不同人使用 Redfin 数据的场景差别很大。下面是不同角色通常会怎样使用抓取到的 Redfin 数据:
| 受众 | 主要抓取目标 | 示例用途 |
|---|---|---|
| 房产经纪人 | 线索获取、市场情报 | 获取服务区域内的新挂牌和过期挂牌;抓取经纪人目录做竞争对标 |
| 房地产投资人 | 项目流、资本回报率分析 | 筛选租金收益、识别低估房产、每日新房源提醒 |
| PropTech 初创公司 | 产品数据管道 | AVM 训练数据、市场看板、iBuyer 收购引擎 |
| 数据分析师 | 市场研究、BI | ZIP 级中位价趋势、在售天数时间序列、成交价/挂牌价比 |
| 批发商 / 翻修商 | 低价房源追踪 | 降价监测、法拍房、非挂牌可比房源 |
更大的趋势也印证了这一点: 现在都在使用预测分析来识别机会和管理风险。PropTech 市场预计将在 ,年复合增长率为 16.4%。结构化房产数据早就不再是锦上添花,而是基本配置。
你能从 Redfin 抓到哪些字段?完整参考
在写代码之前,先要搞清楚到底有哪些字段可以拿。为了整理这份清单,我分析了 Redfin 的搜索结果页、房源详情页和经纪人资料页,并结合了开源 Stingray API 封装项目,比如 和 。跨页面类型统计下来,一共能拿到 117 个不同字段。
这张表很适合收藏。编码前先明确数据结构,能省下大量试错找选择器的时间。
搜索结果页字段
这些是房源卡片上就能看到的轻量字段——很多时候不需要完整渲染 JS 也能提取:
| 字段 | 数据类型 | 说明 |
|---|---|---|
| 房源 ID | 数字 | Redfin 内部整数,从 href 中的 /home/{id} 解析 |
| 挂牌价 | 数字 | |
| 完整地址 | 文本 | |
| 卧室 / 浴室 / 平方英尺 | 数字 | 三个数值按顺序出现 |
| 房屋类型 | 单选 | 独栋、Condo、Townhouse、Multi |
| 状态 | 文本 | 在售、待定、附条件成交 |
| 在售天数 | 数字 | |
| 降价标记 | 数字 | 相对原始挂牌价的变化 |
| 主图 | 图片 URL | 每张卡片 1 张图 |
| Hot Home 标识 | 布尔值 | |
| 开放看房日期/时间 | 文本 | |
| 经纪公司归属信息 | 文本 |
房源详情页字段
详情页才是真正内容最丰富的地方。很多字段需要 JavaScript 渲染,或者依赖 Stingray API:
| 字段 | 数据类型 | 说明 |
|---|---|---|
| Redfin Estimate(在售) | 数字 | 通过 /stingray/api/home/details/avm 获取 |
| Redfin Estimate(非在售) | 数字 | 通过 /stingray/api/home/details/owner-estimate 获取;中位误差 7.52% |
| 建造 / 翻新年份 | 数字 | |
| 土地面积 | 数字 | |
| HOA 费用 | 数字 | 如适用,按月计 |
| 房产税(年) | 数字 | |
| 评估价值 | 数字 | |
| 成交历史表 | 表格 | 价格、日期、事件类型 |
| 房源描述 | 文本 | 营销介绍段落 |
| 图片 URL(轮播) | 图片 URL | 每个房源 20 张以上 |
| 经纪人姓名、电话、邮箱 | 文本 / 电话 / 邮箱 | 电话通常会被隐藏 |
| 学校评分(小学/初中/高中) | 数字 | 还包括学区名称 |
| 步行 / 公交 / 自行车评分 | 数字 | |
| 气候风险评分 | 数字 | 洪水、火灾、热浪、风灾 |
| 相似在售 / 已售 / 附近房源 | URL | 轮播数据 |
| 停车、车库、供暖、制冷 | 文本 | 配套设施组 |
经纪人资料页字段
| 字段 | 数据类型 | 说明 |
|---|---|---|
| 经纪人姓名、头像、经纪公司、简介 | 文本 / 图片 | |
| 电话、联系表单 | 电话 / 文本 | 点击后显示 |
| 在售房源数量 | 数字 | |
| 过去 12 个月成交 / 总成交额 | 数字 | |
| 平均挂牌成交比 | 数字 | |
| 星级评分 / 评论数 | 数字 | |
| 从业年限 / 执照号 | 文本 / 数字 |
使用 Thunderbit 的 AI Suggest Fields 功能抓取 Redfin 页面时,它会自动识别大部分这些列,并分配正确的数据类型——不需要你手动映射 CSS 选择器。后面我会详细讲。
Redfin 的反爬机制拆解(不只是“上代理”这么简单)
这里我想特别强调一下,因为大多数教程都会轻描淡写地跳过封锁问题,直接说“去买我们赞助商的代理”。这没什么帮助。如果你不理解 Redfin 是怎么识别爬虫的,就算烧掉一堆代理额度,最后还是会被封。,而 ——“比 Zillow 的企业级 WAF 没那么激进,主要依赖自定义限流和 JavaScript 挑战”。
Redfin 采用的是分层防护:边缘层 Cloudflare(JS 挑战、Turnstile、TLS/JA3 指纹识别)加上 Redfin 自己的应用层限流器。他们的 robots.txt 里没有 Crawl-delay,因为真正的拦截发生在 WAF 层。
为什么简单的 requests + BeautifulSoup 在 Redfin 上会失败
如果你用默认请求头,直接对 Redfin 的房源页面发一个基础 requests.get(),通常会遇到这些情况:
- HTTP 403 —— Cloudflare 的 JS 挑战没有通过,返回的是挑战页而不是房源内容。
- 中间挑战页 —— HTML 正文里是 Cloudflare 的 Turnstile 组件,不是房源数据。
- HTTP 200 但 HTML 不完整 —— 你拿到的是一个壳,里面嵌了一大段 JSON,位置在
root.__reactServerState.InitialContext下,但没有预渲染的房源卡片、没有价格历史、没有学校评分。
Redfin 使用的是自己的 (不是 Next.js),渲染注水的关键字段也很有 Redfin 风格:root.__reactServerState.InitialContext,其中房源数据嵌套在 ReactServerAgent.cache.dataCache 下面。这不是 __NEXT_DATA__,也不是 window.__INITIAL_STATE__。
最常见的“静默 403”原因是什么?缺少 Sec-Fetch-* 请求头。 Redfin/Cloudflare 会明确校验 Sec-Fetch-Site、Sec-Fetch-Mode、Sec-Fetch-Dest 和 Sec-Fetch-User。如果缺了这些,基本会立刻被标记。
规避策略:延迟、请求头、代理和会话
下面是完整的防护机制拆解,以及对应的应对办法:
| Redfin 防护 | 作用 | 检测信号 | 应对策略 |
|---|---|---|---|
| Cloudflare JS 挑战 | 通过中间页下发 cf_clearance cookie | 403 + Cloudflare HTML 正文 | 使用 curl_cffi 并设置 impersonate="chrome120";先访问首页暖会话;使用美国住宅代理 |
| Cloudflare Turnstile | 高风险会话下的交互式验证码 | 403 + Turnstile 组件 | 使用带隐身特征的无头浏览器 + 住宅代理 |
| Cloudflare 错误 1020(ASN 封禁) | 在 WAF 层封掉被标记的 IP / ASN | 403 正文里显示 "Error 1020 Access Denied" | 切换到住宅 / 手机代理;不要使用数据中心 ASN |
| TLS/JA3 指纹识别 | 识别非浏览器的 TLS 栈 | 即使请求头完美也会静默 403 | 使用 curl_cffi 模拟,或者直接用真实浏览器 |
| HTTP/2 指纹识别 | 检查 HTTP/2 SETTINGS 和 HPACK 顺序 | 静默拦截 | curl_cffi 可像 Chrome 一样发送 HTTP/2 |
| 请求头校验(UA、Sec-Fetch-*) | 检查浏览器一致性请求头 | 首次请求就 403 | 使用完整 Chrome 请求头,包括 Sec-Fetch-Site/Mode/Dest/User,并设置真实的 Referer |
| Cookie / 会话连续性 | 跟踪 cf_clearance、RF_BROWSER_ID | 冷启动深层 URL 容易触发挑战 | 使用持久化 Session;先访问首页暖会话 |
| 应用层限流 | 按 IP 限制请求频率 | 429 | 每 2–5 秒请求一次,并加入随机抖动;指数退避 |
| 数据中心 IP 声誉 | 封禁已知数据中心 ASN | 立刻 1020 / 403 | 只用美国住宅或手机代理 |
| 并发检测 | 同一 IP 多个并发请求 | 突然升级为 Turnstile | 每个 IP 并发数不超过 2 |
社区测试得出的实用阈值:
- 安全节奏:每个 IP 每 2–3 秒 1 个请求
- 单个数据中心 IP 持续超过 20–30 次/分钟,几分钟内就会触发挑战
- 停止流量后,软限流通常在 5–15 分钟内解除
- 数据中心 IP 封禁(AWS、GCP、Azure、OVH)可能持续数小时到数天
默认的 Python requests(urllib3 + OpenSSL)会生成一个 ——即便请求头完全正确,也可能被静默封掉。业内常见的解决方案是使用 curl_cffi 并设置 impersonate="chrome120",它能模拟与 Chrome 一致的 TLS 和 HTTP/2 行为。
用 Python 抓取 Redfin 的三种方法(以及怎么选)
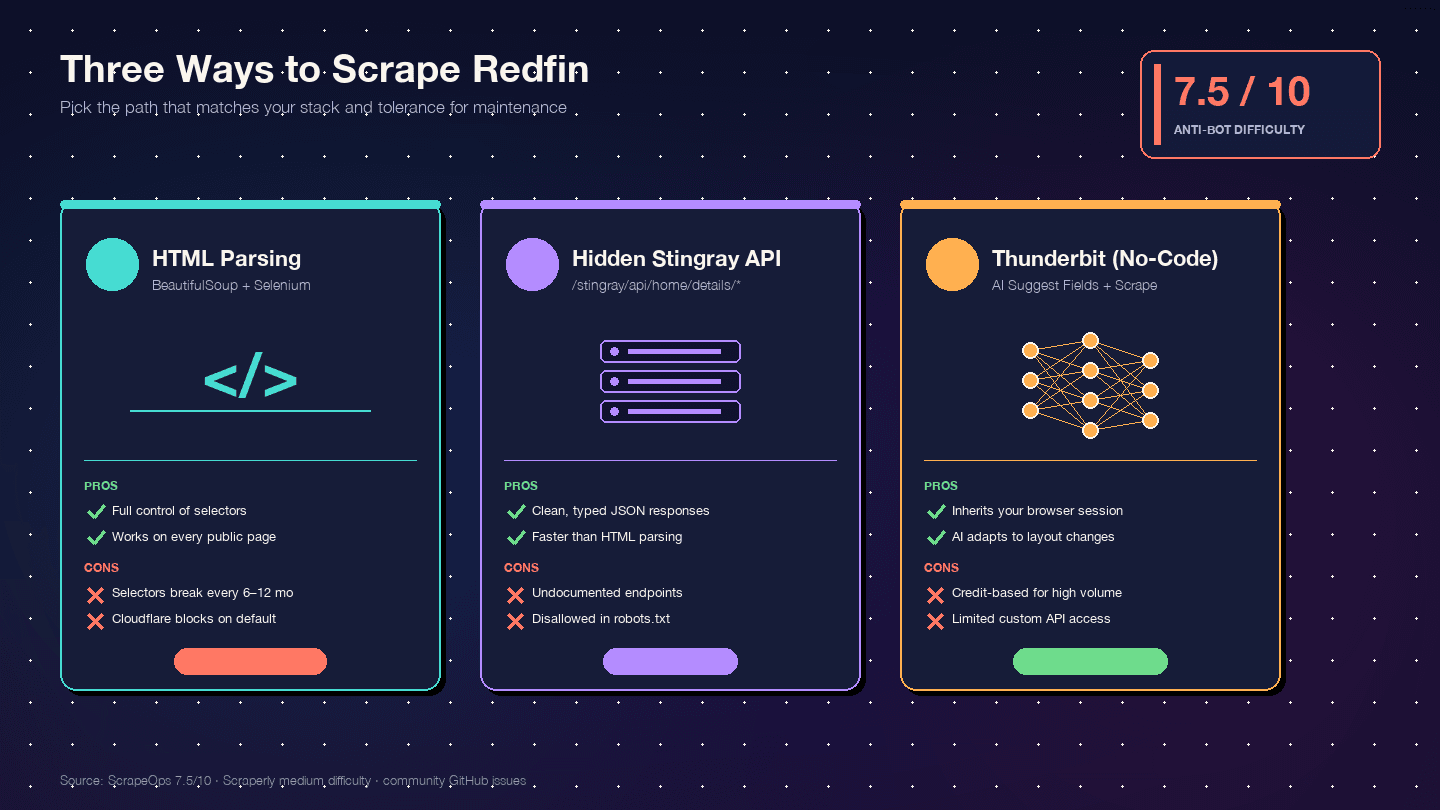
我还没见过有哪篇竞品教程能把这三种方式并排比较。下面是决策矩阵:
| 评估项 | HTML 解析(BS4 + Selenium) | Stingray 隐藏 API | Thunderbit(无代码) |
|---|---|---|---|
| 上手难度 | 中等(Python 环境 + 浏览器驱动) | 高(需要逆向接口) | 低(安装 Chrome 扩展即可) |
| 反爬风险 | 高(DOM 请求最容易暴露) | 中等(API 式请求更自然) | 最低(使用你真实的浏览器会话) |
| 数据结构质量 | 中等(HTML 不规则,需要手工解析) | 很高(天然结构化 JSON) | 高(AI 自动识别字段和类型) |
| 维护成本 | 高——页面结构一变选择器就失效 | 中等——接口可能悄悄变更 | 最低——AI 能适应页面变化 |
| 规模 | 低到中等(配代理可抓几百页) | 中到高(几千页,且请求更干净) | 中等(云端抓取一次最多 50 页) |
| 最适合谁 | 想完全掌控流程的开发者 | 需要干净 JSON 的开发者 | 非开发者、快速项目、需要持续数据但没有开发资源的人 |
维护成本这一点尤其值得强调。Redfin 已经经历过两代房源卡片 DOM:旧版(homecardV2Price)和当前版本(span.bp-Homecard__Price--value)。社区 GitHub issue 历史显示,CSS 选择器大约每 6–12 个月就会坏一次。发生这种情况时,BeautifulSoup 爬虫往往一夜之间失效;而基于 AI 的字段识别器则能自动适应。
开始之前
- 难度: 中级(方法 1 和 2),初级(方法 3)
- 所需时间: 方法 1 或 2 约 30 分钟;方法 3 约 5 分钟
- 你需要准备:
- Python 3.8+ 和 pip(方法 1 和 2)
- Chrome 浏览器(所有方法通用)
- (方法 3)
- 大规模抓取时需要美国住宅代理(方法 1 和 2)
方法 1:使用 HTML 解析抓取 Redfin(BeautifulSoup + Selenium)
这是一条“完全自己掌控”的路线。你来写选择器,你来管理浏览器,你来处理错误。
它是最适合学习原理的方法,但也是最脆弱的一种。
第 1 步:搭建 Python 环境
创建虚拟环境并安装所需库:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Windows 上:redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cffi这里 curl_cffi 是关键——它能让你的 HTTP 请求伪装成真实 Chrome 的 TLS 指纹,而不是 Cloudflare 一眼就能识别并拦截的默认 Python requests 指纹。
第 2 步:配置浏览器请求头和会话
这一步是很多新手最容易翻车的地方。你需要完整的 Chrome 请求头,尤其是 Redfin/Cloudflare 会明确校验的 Sec-Fetch-* 头:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# 先暖会话——获取 cf_clearance 和 RF_BROWSER_ID cookie
17session.get("https://www.redfin.com/")“暖会话”这一步非常关键——如果你一上来就直接访问深层房源 URL,没有前置 cookie、没有 Referer,Cloudflare 会直接给你降权。
一定要先访问首页。
第 3 步:抓取 Redfin 搜索结果页
会话暖好之后,就可以抓城市搜索页并解析房源卡片了。当前可用的选择器(2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # 第 1–5 页
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"第 {page_num} 页被拦截:HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # 随机延迟 2–5 秒
28 time.sleep(random.uniform(2, 5))
29print(f"已抓取 {len(listings)} 条房源")你应该会看到一个不断增长的字典列表,每个字典包含一条旧金山房源的价格、地址、卧室/浴室/面积和详情页 URL。如果结果为 0,先检查 HTTP 状态码——403 通常说明 Cloudflare 已经拦住你了,这时大概率需要住宅代理。
第 4 步:抓取单个房源详情页
搜索结果页只能拿到基础信息;详情页才有 Redfin Estimate、建造年份、HOA、成交历史、经纪人信息和图片。这类页面需要 JavaScript 渲染,所以要切换到 Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # 先丰富前 10 条
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # 等待 JS 渲染
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()执行到这一步后,前 10 条房源就应该被补充上 Redfin Estimate 和建造年份数据了。对于这些嵌套型的设施字段,XPath 往往比 CSS 选择器更稳一些,但依然很脆弱——页面 DOM 只要改动,还是会失效。
第 5 步:处理封禁和错误
使用指数退避实现重试逻辑:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"被拦截({resp.status_code})。{wait:.1f} 秒后重试...")
10 time.sleep(wait)
11 else:
12 print(f"异常状态码:{resp.status_code}")
13 break
14 return None被封的常见表现包括:HTTP 403 且正文里是 Cloudflare HTML,HTTP 429(明确限流),响应体为空,或者页面内容里出现 “Error 1020 Access Denied”。如果这些情况持续出现,就该上住宅代理,或者直接切换到 API 方案了。
方法 2:使用隐藏的 Stingray API 抓取 Redfin
这是我最喜欢的方法。Redfin 前端会和一个内部 JSON API 通信,接口位于 /stingray/api/home/details/*,返回的是干净、类型明确的 JSON——完全不需要解析 HTML。
如何找到 Redfin 的隐藏 API 接口
打开 Chrome DevTools → Network 面板 → 过滤 Fetch/XHR → 随便进入一个 Redfin 房源页。你会看到诸如下面这些接口请求:
api/home/details/initialInfo—— 解析 URL → propertyId、listingIdapi/home/details/aboveTheFold—— 价格、卧室、浴室、面积、图片、状态、经纪人、MLS 编号api/home/details/belowTheFold—— 设施、HOA、税费、停车、建造年份、土地、历史记录api/home/details/avm—— 在售 Redfin Estimateapi/home/details/owner-estimate—— 非在售 Redfin Estimateapi/home/details/descriptiveParagraph—— 房源营销描述
对于租赁页面,rentalId(一个 36 位 UUID)可以从 <meta property="og:image"> 标签的 URL 中提取出来。
通过 Stingray API 抓取房源数据
这里有一个关键细节:Stingray 的 JSON 响应前面会带上字面量字符串 {}&&,这是反 CSRF 处理的一部分。解析前必须先去掉:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# 先暖会话
6session.get("https://www.redfin.com/")
7# 先访问房源页,拿到 cookie 和 property ID
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# 然后调用 Stingray API
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# 去掉反 CSRF 前缀
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# 提取结构化数据
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))这个响应里包含的都是有类型的数据:价格是整数,卧室/浴室是数字,图片 URL 是数组,经纪人信息是嵌套对象。没有 BeautifulSoup、没有 CSS 选择器、也不用猜字段在哪里。
隐藏 API 方案的优缺点
优点:
- 原生结构化 JSON——比 HTML 解析干净得多
- 单次请求更快(负载更小,也没有渲染开销)
- 被封风险更低(看起来更像正常 API 请求)
局限:
- 接口可能会无预警变化——没有官方文档
robots.txt明确禁止通配符用户代理访问/stingray/- 需要通过逆向分析来发现新接口
- 仍然需要先暖会话并设置正确请求头,才能避开 Cloudflare
无代码替代方案:用 Thunderbit 抓取 Redfin
如果你需要 Redfin 数据,但不想维护 Python 脚本——或者你只想在 5 分钟内拿到结果——那就从这里开始。我们做 的初衷正是如此:从任意网站提取结构化数据,无需编程。
第 1 步:安装 Thunderbit 并打开 Redfin
先从 Chrome 网上应用店安装 。打开 Redfin,进入一个搜索结果页,比如旧金山在售房源页面。
第 2 步:点击“AI Suggest Fields”
点击浏览器工具栏里的 Thunderbit 图标,然后点 “AI Suggest Fields.” AI 会读取 Redfin 页面,并自动推荐诸如 “Address”、“Price”、“Beds”、“Baths”、“SqFt”、“Property Type” 和 “Listing Photo” 等字段,同时自动分配正确的数据类型。
你可以删掉不需要的列,也可以通过点击 “+ Add Column”,用自然语言描述你想要的字段,比如“listing agent name” 或 “days on market”。
此时你应该能看到一个表格预览,列结构已经配置好,随时可以填充数据。
第 3 步:点击“Scrape”,看数据自动进表
点击 “Scrape” 按钮。Thunderbit 会处理当前可见的房源,并把数据填入表格。对于分页结果,它会自动翻页,无需你写循环逻辑。
按我的测试,一个 50 行的表格大概 45 秒就能填满,拿到的还是结构化数据,可以直接导出。
Thunderbit 如何应对 Redfin 的反爬保护
因为 Thunderbit 运行在你自己的浏览器中,所以它会继承你现有的 Redfin cookie、会话状态和浏览器指纹。对 Cloudflare 来说,这看起来就像一个真实用户在浏览 Redfin——因为从技术上说,确实如此。没有无头浏览器、没有数据中心 IP、也没有 TLS 指纹不匹配的问题。对于公开页面,Thunderbit 的云端抓取模式一次可以处理 50 个页面。
这和在服务器上直接用 Python 脚本发 requests 完全不是一回事。
你的浏览器会话本来就已经是可信的。
使用 Thunderbit 抓取 Redfin 子页面
抓完搜索结果后,点击 “Scrape Subpages”,让 AI 逐个访问每个房源详情页,并为表格补充更多字段——Redfin Estimate、建造年份、HOA 费用、经纪人信息、房源图片和成交历史。
这相当于方法 1 里那段 40 行 Selenium 循环的功能,但现在只需要点一下,而且完全不用维护。
当 Redfin 的 DOM 从 homecardV2Price 改成 span.bp-Homecard__Price--value 时,AI 会自动适应;而你的 Python 选择器不会。
不止 CSV:把 Redfin 数据导出到 Google Sheets、Airtable 和 Notion
大多数教程讲到 df.to_csv() 就结束了。做一次性分析这没问题。但如果你是在房产团队里工作,你需要的是可协作、可持续更新的数据,而不是桌面上积灰的静态文件。
用 Python 导出(gspread + Airtable API)
通过 gspread 导出到 Google Sheets:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# 通过 IMAGE() 公式在表格内显示房源图片
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')提醒一下:Sheets 每个表格有 1000 万单元格的硬限制,而且 API 限制为每个项目 。如果数据超过几十行,尽量用 ws.batch_update(),不要逐格循环写入。
通过 pyairtable 导出到 Airtable:
一个关键变化是:Airtable 已在 。现在必须使用 Personal Access Token(PAT)——任何还在写 api_key=... 的教程都已经过时了。
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable 会抓取并重新托管
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Airtable 的速率限制是 ,违规后会锁 30 秒。附件字段接受 [{"url": ...}] 这种格式——Airtable 会由它的服务器去抓取该 URL,重新托管到自己的 CDN,并自动生成缩略图。
用 Thunderbit 导出(1 次点击到 Sheets、Airtable、Notion)
Thunderbit 原生支持一键导出到 Google Sheets、Airtable 和 Notion——而且这点我真的很自豪:房源图片会自动上传,并以内联图片形式显示在 Notion 和 Airtable 中。没有 =IMAGE() 公式的各种小技巧,也没有失效的 CDN 链接。你只需要点“Export to Airtable”,团队就能立刻得到一个带缩略图、可直接在手机上浏览的可视化房产数据库。
对于需要视觉化筛选房源的房产团队来说,这已经不只是一个工具,而是工作方式的升级。
抓取 Redfin 合法吗?ToS、robots.txt 和判例怎么说
我不是律师,以下内容也不构成法律建议。但在数据提取行业做了这么多年,我可以告诉你:“合法吗?”这几乎是每个人都会问的问题,而大多数教程都会刻意回避。
Redfin 的 robots.txt
Redfin 的 写得很细。重点如下:
- 明确封禁的机器人:
peer39_crawler/1.0、AmazonAdBot、FireCrawlAgent——Redfin 直接点名了当下很热门的 LLM 时代抓取服务 - 通配符
User-agent: *的禁止项包括:/stingray/(整个内部 API 命名空间)、/myredfin/、/api/v1/rentals/、/api/v1/properties/、/owner-estimate/ - 没有为任何用户代理设置
Crawl-delay: - 声明了 50+ 个 sitemap——站点地图是最干净、对 WAF 影响最小的 URL 枚举方式
Redfin 的服务条款
写道:“未经事先明确的书面许可,您不得以任何目的或任何方式自动抓取或查询服务……”
这属于一种 browsewrap 协议——即通过继续使用来视为接受,而不是点击式同意(clickwrap)。美国法院过去通常对“用户没有实际知情”的 browsewrap 条款持较为谨慎的态度(可参考 Nguyen v. Barnes & Noble, 第九巡回法院,2014)。
相关判例(简述)
- Van Buren v. United States(美国最高法院,2021):CFAA 中“超越授权访问”的判断采用“门是开还是关”的标准。用一扇本来就开着的门,只是为了一个不受欢迎的目的,并不等于联邦黑客行为。
- hiQ Labs v. LinkedIn(第九巡回法院,2022):抓取公开可见数据不构成 CFAA 违规。但 hiQ 最终仍因违约问题支付了 50 万美元和解金——因为它注册了 LinkedIn 账号并点击了“我同意”。
- Meta Platforms v. Bright Data(加州北区联邦法院,2024 年 1 月):法院支持 Bright Data 的简易判决——在登出状态下抓取公开数据,并不意味着 Bright Data 成为了受 Meta ToS 约束的“用户”。
- X Corp. v. Bright Data(加州北区联邦法院,2024 年 5 月):Alsup 法官驳回了 X 的主张,认为试图通过州法控制公开内容复制的诉求,已被《版权法》优先排除。
实用建议
- 只抓取公开可访问的数据——不要先注册账号再抓,这会带来 clickwrap 合同风险
- 尊重速率限制——过于激进的抓取量可能支持“侵入动产”类诉讼主张
- 不要大规模重新发布原始数据或图片—— 诉讼(2025 年 7 月提起,潜在赔偿超过 10 亿美元)说明图片版权问题非常严肃
- Thunderbit 的浏览器方案——在你自己的已登录会话里运行——更像是“以机器速度进行人工浏览”,而不是数据中心里的无头机器人;这是在没有授权 API 前提下,最容易被辩护的做法
技巧与常见坑
这些都是我在开发提取工具、看着成千上万用户抓房产网站时总结出来的经验:
- 一定要先暖会话。 在访问任何深层 URL 之前,先打开
redfin.com/。直接冷启动访问深层页面,是触发 Cloudflare 挑战的头号原因。 - 合理轮换 User-Agent。 不要一直用同一个,建议在 5–10 个当前主流 Chrome/Firefox UA 之间轮换。但也别轮换得太夸张(每次请求都换 UA 反而可疑)。
- 按房源 ID 去重。 Redfin 分页有时会重叠。先从每个房源 URL 中解析
/home/{id},再去重后补全数据。 - 尽量避开高峰时段。 按我的经验,美国本地深夜 / 凌晨的 WAF 盯得没那么紧。
- 如果收到 429,指数退避。 不要立刻重试——那样很容易把软限流升级成硬封禁。
- 大规模项目(1000+ 页面)要预留住宅代理预算。 数据中心 IP(AWS、GCP、Azure、OVH)会被 Cloudflare 的 ASN 声誉系统拉黑,你几乎会立刻撞上 Error 1020。
应该选择哪种 Redfin 抓取方式?
那到底该选哪种方法?这取决于你是谁,以及你需要什么。
HTML 解析(BeautifulSoup + Selenium): 适合想完全掌控流程、能维护 CSS 选择器、也不介意 Redfin 页面一改就重构代码的开发者。预计每 6–12 个月要回头维护一次。
隐藏 Stingray API: 适合需要干净结构化 JSON、并且能接受逆向未公开接口的开发者。维护成本低于 HTML 解析,但接口可能会悄悄变化。别忘了 /stingray/ 在 robots.txt 里是明确禁止的。
Thunderbit(无代码): 适合非开发者、快速项目,以及需要持续获取 Redfin 数据但没有开发资源的团队。AI 会自动适应布局变化,子页面抓取可一键补全数据,而且还内置导出到 、Airtable 或 Notion 的功能。如果你是一个需要“活数据”房产数据库的团队,而不是一次性 CSV 导出,那么这条路阻力最小。
无论你选哪条路:先理解 Redfin 的反爬机制,再开始动手;先明确你需要哪些字段;选择一个适合团队流程的导出格式;并且始终站在 这一侧。
准备试试无代码方案了吗? 可以让你几分钟内体验 Redfin 抓取效果。至于 Python 方案,上面的代码片段已经能作为可运行的起点——你只需要补上代理和耐心。
常见问题
Redfin 有公开 API 吗?
没有。Redfin 没有提供官方公开 API。隐藏的 Stingray API(/stingray/api/home/details/*)会返回结构化 JSON,也是 Redfin 前端实际使用的接口,但它并非官方文档、没有公开说明、可能随时变更,而且在 Redfin 的 robots.txt 中也被明确禁止。像 这类开源封装可以让你在 Python 中访问相关数据,但使用时要清楚其中风险。
不用 Python 也能抓 Redfin 吗?
可以。 是一个 AI Chrome 扩展,会继承你的浏览器会话,因此具备更强的反爬韧性——安装后打开 Redfin,点击“AI Suggest Fields”,即可导出到 Excel、Google Sheets、Airtable 或 Notion。如果你想探索替代方案,市场上也有其他无代码抓取工具和现成数据集提供商。
Redfin 的网页布局多久会改一次?
社区 GitHub issue 历史显示,CSS 选择器大约每 6–12 个月就会失效一次。Redfin 已经发布过两代房源卡片 DOM——旧版(homecardV2Price, homeAddressV2)和当前版本(bp-Homecard__Price--value, bp-Homecard__Address)。成熟的爬虫通常会按顺序尝试这两套选择器。
像 Thunderbit 这样的 AI 工具会 ,因为它们是根据内容识别字段,而不是依赖 CSS 选择器。
抓 Redfin 最适合用哪种代理?
如果是大规模抓取,推荐使用美国住宅代理——社区基准测试里成功率大约 80%。数据中心代理几乎会立刻撞上 Cloudflare Error 1020;AWS、GCP、Azure 和 OVH 的 IP 段通常都已被拉黑。手机代理成功率最高,但价格通常是普通代理的 5–10 倍。
如果只是小规模个人抓取(少于 100 页),配合正确请求头、curl_cffi 指纹模拟,以及 2–5 秒延迟,很多情况下甚至不需要代理。
可以抓 Redfin 的已售或非在售房源数据吗?
可以。已售房源数据和非在售的 Redfin Estimate(中位误差 )都能用同样的方法在详情页中抓到。不同之处在于字段不一样:非在售页面会显示成交价、成交日期、房产历史,以及 owner-estimate 接口结果,但没有当前挂牌价、在售天数和开放看房信息。非在售估值对应的 Stingray 接口是 api/home/details/owner-estimate,而不是 api/home/details/avm。
了解更多