

大概是在我第 50 次把 Indeed 上的职位标题复制粘贴到表格里时,我开始怀疑自己的职业选择了。如果你曾经试过用程序从 Indeed 抓取结构化数据,你一定懂这个笑点:403 错误不是 bug,而是 Indeed 防御系统的功能。
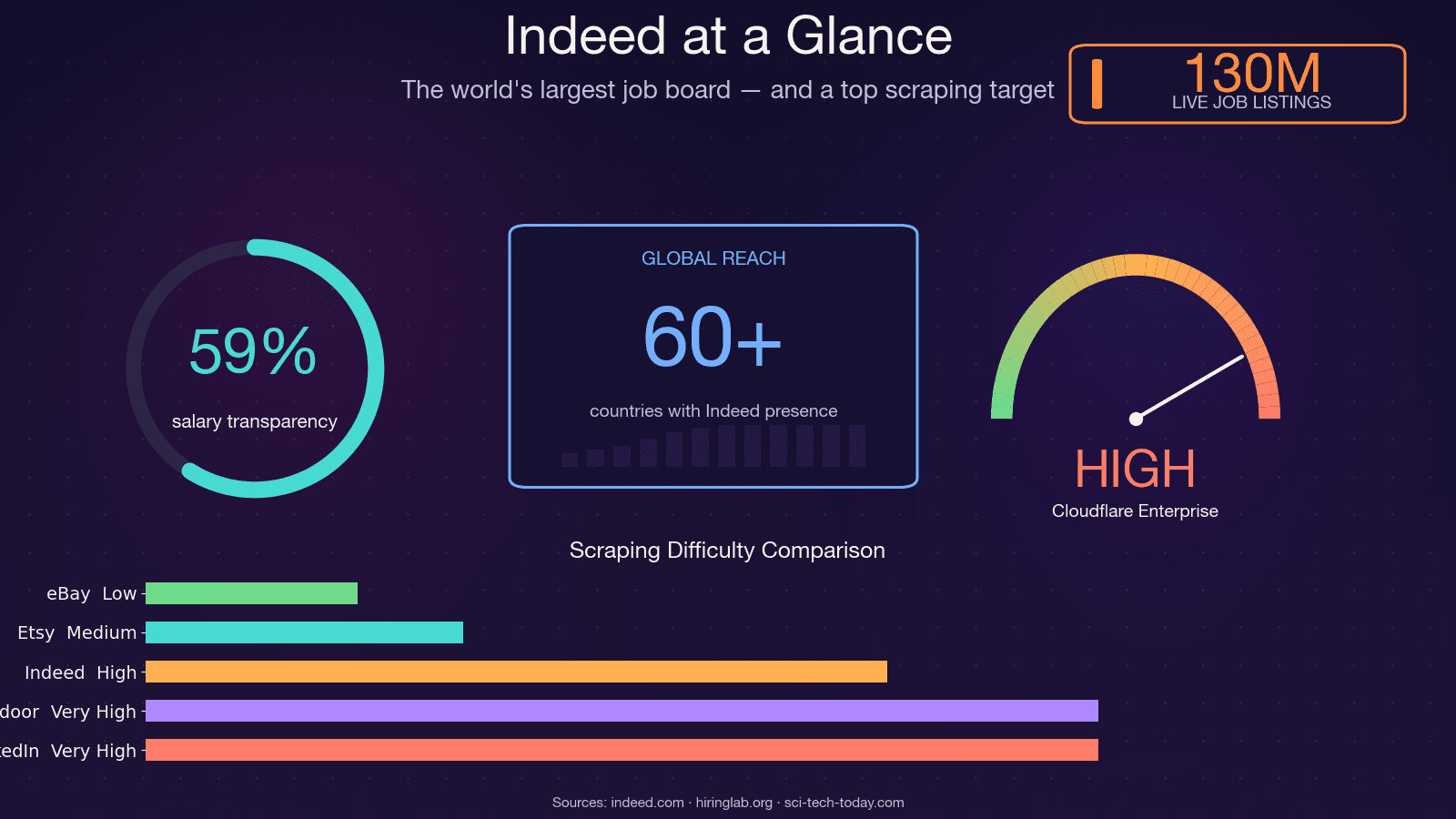
Indeed 是全球最大的招聘网站,月独立访客大约有 3.5 亿,任意时点有 1.3 亿个职位列表,业务覆盖 60 多个国家。这让它成为地球上最丰富的职位市场数据来源之一,也让它成为最难抓取的网站之一。开源爬虫 JobFunnel(GitHub 上有数千星标)在和反爬系统多年博弈后,甚至在 2025 年 12 月被维护者直接 归档 了。维护者原话是:“所有用户都能抓到一些职位,但很快就会碰到验证码,然后抓取失败,最后一个职位也拿不到。” 还有贡献者反馈,第一次请求就遇到了 CAPTCHA。所以没错——这绝对不是一个轻松的抓取目标。本文会带你走过用 Python 抓取 Indeed 的所有实用方法,教你如何真正熬过 403 大关;如果你更想直接跳过调试,我也会演示一个使用 Thunderbit 的无代码替代方案。
用 Python 抓取 Indeed 是什么意思?
网页爬虫的核心,就是自动从网页中提取结构化数据。当我们说“用 Python 抓取 Indeed”时,指的是写一个脚本去访问 Indeed 的搜索结果页和职位详情页,读取底层 HTML(或嵌入的数据),并把职位标题、公司、地点、薪资、描述等字段提取成可用格式——比如 CSV、数据库或 Google 表格。
常见的 Python 库包括 Requests(用于 HTTP 请求)、BeautifulSoup(用于 HTML 解析)以及 Selenium 或 Playwright(用于浏览器自动化)。但 Indeed 不是一个简单的静态网站。它是一个混合型站点:服务器渲染 HTML,里面嵌着一段 JSON 状态数据,前面还有 Cloudflare Bot Management。也就是说,你的爬虫在解析任何职位标题之前,必须先处理 JavaScript 渲染内容、会变化的 CSS 类名,以及激进的反爬保护。
到 2026 年,也没有官方、免费、只读的 Indeed API。以前的 Publisher Jobs API 大约在 2020 年被弃用,剩下的只面向雇主侧(Job Sync、Sponsored Jobs)。所以,抓取或者购买第三方数据服务,基本上是现实中的唯二选择。
为什么要抓取 Indeed 的职位数据?
抓取 Indeed 的商业价值很直接:手动浏览成千上万条职位信息根本不现实,而且这些列表里的数据确实很有价值。
| 使用场景 | 受益人群 | 示例 |
|---|---|---|
| 线索挖掘 | 销售与招聘团队 | 建立带联系方式的招聘公司名单 |
| 职位市场研究 | 分析师、HR 团队 | 找出趋势技能、按地区划分的薪资基准 |
| 竞争情报 | 雇主、猎头机构 | 监测竞争对手的招聘模式和薪资报价 |
| 个人求职自动化 | 求职者 | 汇总符合条件的多地区职位 |
| 机器学习模型训练数据 | 数据科学家 | 用历史职位数据构建薪资预测模型 |
Indeed Hiring Lab 自己的研究也 验证了 职位发布数据与 BLS JOLTS 高度相关,可作为美国劳动力市场状况的近实时替代指标。对冲基金会把职位发布速度作为另类数据。HR 团队会用抓取到的薪资区间做薪酬对标。招聘人员则会根据正在积极招聘的公司来建立潜在客户名单。
有一点需要注意:Indeed 上的薪资数据虽然在改善,但仍然不完整。到 2025 年中,大约 59% 的美国职位 会包含薪资信息,但只有约 22% 给出精确数值,其余都是区间。任何基于 Indeed 数据的薪资分析,都必须考虑这种稀疏性。
选择适合你的 Indeed Python 抓取方法
抓取 Indeed 没有唯一“正确”的方式。最佳方案取决于你的技术水平、数据量需求,以及你愿意承担多少维护成本。我测试了四种主流方法,比较如下:
| 标准 | BS4 + Requests | Selenium | 隐藏 JSON(window.mosaic) | 无代码(Thunderbit) |
|---|---|---|---|---|
| 难度 | 初级 | 中级 | 中级到高级 | 无(2 次点击) |
| 速度 | 快 | 慢(浏览器渲染) | 快 | 快(云端抓取) |
| JS 渲染内容 | 否 | 是 | 是(嵌入数据) | 是 |
| 反爬抗性 | 低 | 中(可被检测) | 中高 | 高(自动处理) |
| HTML 变化时的维护成本 | 高(选择器易坏) | 高 | 中(JSON 结构更稳定) | 无(AI 自适应) |
| 最适合 | 快速原型 | 动态页面、登录后内容 | 批量结构化数据 | 非开发者、快速出结果 |
本指南会逐一介绍这些方法。如果你是 Python 开发者,建议认真看 BS4、隐藏 JSON 和 Selenium 这几部分;如果你不是程序员,或者已经被 403 调试折磨得不行了,直接跳到 Thunderbit 那一节吧。
开始之前
- 难度: 初级到中级(Python 部分);无(Thunderbit 部分)
- 所需时间: Python 环境搭建和首次抓取约 20–60 分钟;用 Thunderbit 约 2 分钟
- 你需要: Python 3.9+、代码编辑器、Chrome 浏览器,以及(无代码方案)Thunderbit Chrome 扩展
为 Indeed 抓取搭建 Python 环境
在编写任何抓取代码之前,先把环境准备好。
安装所需库
创建虚拟环境并安装需要的包:
python -m venv indeed_env
source indeed_env/bin/activate # Windows 上:indeed_env\Scripts\activate
# HTTP + 解析方案
pip install requests beautifulsoup4 lxml httpx
# 隐藏 JSON 方案(推荐)
pip install curl_cffi parsel tenacity
# 浏览器自动化方案
pip install selenium
几点说明:
curl_cffi是 2026 年抓取受 Cloudflare 保护网站的默认选择。它能伪装成真实浏览器的 TLS 指纹,而普通requests和httpx做不到。这一点在后面的反爬章节里会解释。- Selenium 4.6+ 自带 Selenium Manager,所以你不再需要手动下载 ChromeDriver——它会自动管理浏览器二进制文件。
- BeautifulSoup 的解析后端建议使用
lxml。它大约比标准库的html.parser快 1.5 倍。
创建项目结构
保持简单即可:
indeed_scraper/
├── scraper.py
├── requirements.txt
└── output/
下面所有代码示例都基于 scraper.py。
如何用 BeautifulSoup 抓取 Indeed
这是最适合初学者的方法:用 requests 获取页面,再用 BeautifulSoup 解析 HTML。它上手最快,但在 Indeed 上也最脆弱。
步骤 1:构建 Indeed 搜索 URL
Indeed 的搜索 URL 遵循固定模式:
https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>
例如,在 “Austin, TX” 搜索 “data analyst”,并从第一页开始:
from urllib.parse import urlencode
params = {
"q": "data analyst",
"l": "Austin, TX",
"start": 0,
}
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
print(url)
# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0
Indeed 每 10 条结果分页一次,结果上限硬性封顶为 1000 条(start <= 990)。任何大于 990 的偏移量都会静默返回同一页。
步骤 2:用合适的请求头发送 HTTP 请求
Indeed 会立即拦截使用默认 Python user-agent 的请求。你需要更真实的请求头:
import requests
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.indeed.com/",
}
response = requests.get(url, headers=headers, timeout=30)
print(response.status_code)
如果返回 200,说明暂时进去了;如果返回 403,说明 Cloudflare 把你拦下来了。(后面会讲怎么应对。)
步骤 3:从 HTML 中解析职位列表
使用 BeautifulSoup 选择职位卡片元素。优先定位 data-testid 属性——它比 Indeed 随机变化的 CSS 类名稳定得多:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "lxml")
cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
jobs = []
for card in cards:
title_el = card.find("h2", class_="jobTitle")
title = title_el.get_text(strip=True) if title_el else None
company = card.find(attrs={"data-testid": "company-name"})
location = card.find(attrs={"data-testid": "text-location"})
link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
jobs.append({
"title": title,
"company": company.get_text(strip=True) if company else None,
"location": location.get_text(strip=True) if location else None,
"url": f"https://www.indeed.com{link}" if link else None,
})
print(f"找到 {len(jobs)} 个职位")
步骤 4:处理分页
通过递增 start 参数循环翻页:
import time, random
all_jobs = []
for page in range(0, 50, 10): # 前 5 页
params["start"] = page
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
response = requests.get(url, headers=headers, timeout=30)
# ... 按上面方式解析 ...
all_jobs.extend(jobs)
time.sleep(random.uniform(3, 6))
这种方法的局限
我先说结论:BS4 + Requests 是 2026 年抓取 Indeed 最弱的方法。普通 requests 使用的是 Python 标准库的 TLS 实现,它会产生 Cloudflare 一眼就能识别为“不是浏览器”的 JA3 指纹。它也不支持 Indeed 使用的 HTTP/2。你很可能抓了几页之后就被封。还有 CSS 选择器?Indeed 会频繁更换像 css-1m4cuuf 和 jobsearch-JobComponent-embeddedBody-1n0gh5s 这样的类名 频繁 —— 所以依赖它们的选择器随时可能爆炸。
这个方法适合单页快速原型验证。如果你要做任何规模化任务,建议用隐藏 JSON 方案。
如何用隐藏 JSON 数据抓取 Indeed
这是我最推荐给大多数 Python 开发者的方法。它不解析脆弱的 HTML 元素,而是从 Indeed 页面源码中提取一个 JavaScript 变量里的结构化数据:window.mosaic.providerData["mosaic-provider-jobcards"]。
你关心的每个字段——职位标题、公司、地点、薪资、职位 key、发布日期、远程标记——都已经在这个 JSON 里了,不需要执行 JavaScript。这个 schema 至少从 2023 年起 就很稳定,比 DOM 选择器抗折腾得多。
步骤 1:获取页面 HTML
用 curl_cffi 代替 requests——它会伪装真实浏览器的 TLS 指纹,这对躲过 Cloudflare 至关重要:
from curl_cffi import requests as cffi_requests
response = cffi_requests.get(
"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
impersonate="chrome124",
headers={
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.indeed.com/",
},
timeout=30,
)
print(response.status_code, len(response.text))
为什么用 curl_cffi?它是基于 curl-impersonate 的 Python 封装,可以复现真实浏览器的 TLS ClientHello、HTTP/2 SETTINGS 帧以及请求头顺序。它也是目前唯一仍在积极维护、能在一次调用中同时绕过 JA3/JA4 和 Akamai H2 指纹 的 Python HTTP 客户端。支持的伪装目标包括 chrome120、chrome124、chrome131、Safari 和 Edge 变体。
步骤 2:用正则提取 JSON
这个 JSON 块嵌在 <script> 标签里。用正则把它提取出来:
import re, json
MOSAIC_RE = re.compile(
r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
re.DOTALL,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
print(f"在隐藏 JSON 中找到 {len(results)} 个职位")
else:
print("没有找到隐藏 JSON——可能被拦截,或者页面结构变了")
步骤 3:从 JSON 中解析职位字段
results 里的每一项都包含比页面可见内容更多的数据:
jobs = []
for job in results:
jobs.append({
"jobkey": job["jobkey"],
"title": job["title"],
"company": job.get("company"),
"location": job.get("formattedLocation"),
"remote": job.get("remoteLocation"),
"salary": (job.get("salarySnippet") or {}).get("text"),
"posted": job.get("formattedRelativeTime"),
"job_type": job.get("jobTypes"),
"easy_apply": job.get("indeedApplyEnabled"),
"url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
})
这个 JSON 往往还包含薪资估算、分类属性(技能标签)以及公司评分,而这些并不总会显示在渲染后的 HTML 里。
步骤 4:抓取多页数据
先用 JSON 里的 tierSummaries 了解总结果数量,再循环抓取:
import time, random
all_jobs = []
for start in range(0, 50, 10): # 前 5 页
url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start={start}&sort=date"
response = cffi_requests.get(
url,
impersonate="chrome124",
headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
timeout=30,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
all_jobs.extend([{
"jobkey": j["jobkey"],
"title": j["title"],
"company": j.get("company"),
"location": j.get("formattedLocation"),
"salary": (j.get("salarySnippet") or {}).get("text"),
"url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
} for j in results])
time.sleep(random.uniform(3, 7))
print(f"总计抓取到:{len(all_jobs)} 个职位")
为什么隐藏 JSON 更稳
window.mosaic.providerData 的结构变化频率比 CSS 类名低得多。你可以直接拿到干净、结构化的数据,而不用解析乱糟糟的 HTML。即便如此,你还是需要做反爬应对(请求头、延迟、代理),这一点我们下一节会讲。
如何用 Selenium 抓取 Indeed
Selenium 属于浏览器自动化方案。当你需要和页面交互时——比如点击职位详情面板、处理登录后内容,或者抓取初始 HTML 里没有的动态加载描述——它会很有用。
什么时候该用 Selenium,而不是 HTTP 客户端
- Indeed 会动态加载部分内容(右侧面板里的完整职位描述)
- 你需要抓取需要会话状态或登录的页面
- 你做的是小规模抓取,对速度不那么敏感
快速示例
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
# options.add_argument("--headless=new") # 无头模式更容易被检测,谨慎使用
driver = webdriver.Chrome(options=options)
driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
time.sleep(3)
cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
for card in cards:
try:
title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
print(f"{title} | {company} | {location}")
except Exception:
continue
driver.quit()
局限性
Selenium 很慢——每个页面都要完整渲染浏览器。无头 Chrome 会被 Indeed 的反爬系统 检测到(Cloudflare 会检查 navigator.webdriver、WebGL 厂商字符串、插件数量等等)。即使是 undetected-chromedriver,也只是延迟被发现,并不能永久避免。和 BS4 一样,等 Indeed 更新 UI 之后,你的选择器也会失效。
对大多数场景来说,隐藏 JSON 方法能更快地拿到同样的数据,而且维护成本更低。只有在你确实需要浏览器时,才把 Selenium 留给那些边缘场景。
如何避免在抓取 Indeed 时遇到 403 错误
这一部分最关键。如果你是带着挫败感搜到这里的,那就来对地方了。
为什么 Indeed 会封你的爬虫
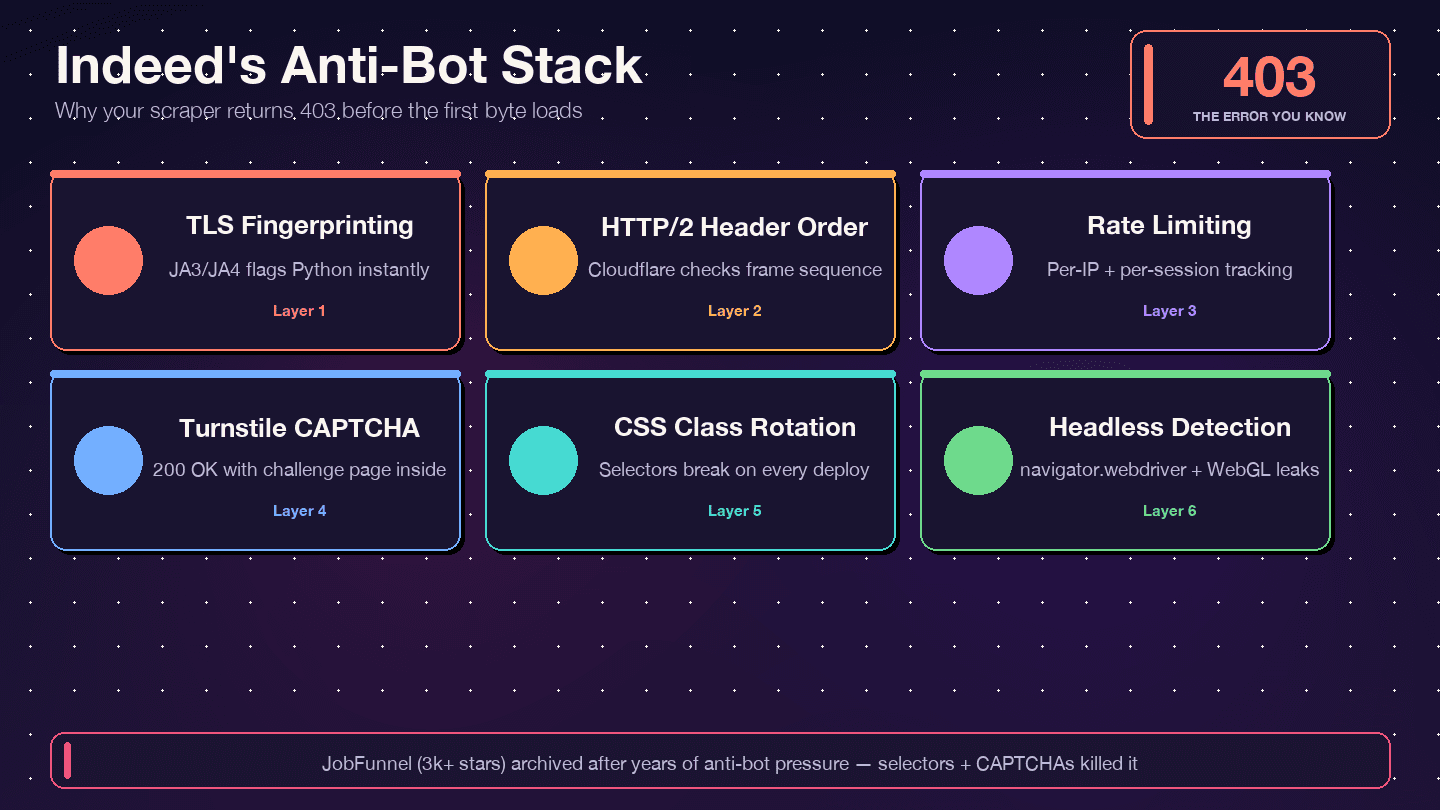
Indeed 使用的是 Cloudflare Bot Management 加 Cloudflare Turnstile,不是 DataDome,也不是 PerimeterX。响应头已经说明了一切:server: cloudflare、cf-ray,以及 __cf_bm 这个 bot 管理 cookie。Cloudflare 会检查你的 TLS 指纹(JA3/JA4)、HTTP/2 请求头顺序、请求模式以及浏览器行为信号。只要其中任何一项看起来不像真人,你就会收到 403、429、503,或者——更隐蔽的情况——返回 200 OK,但内容其实是 Turnstile 验证页,不是真正的职位数据。
轮换 User-Agent 和请求头
固定不变的 User-Agent 是最快被封的方式。应从一组当前、真实的字符串里轮换。注意:Chrome 的次版本号字段在 User-Agent Reduction 后被固定为 0.0.0——不要自己编造非零的次版本号,否则反爬系统会直接标红。
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
]
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Referer": "https://www.indeed.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
}
同时要确保你的 sec-ch-ua Client Hints 和 UA 版本一致。sec-ch-ua: "Chrome";v="131" 却配着一个声称是 Chrome 145 的 User-Agent,简直是送上门的红旗。
在请求之间加入随机延迟
固定间隔很容易被模式检测识别。用随机抖动:
import time, random
# 每次请求之间
time.sleep(random.uniform(3, 6))
# 被封后重试时
def backoff_sleep(attempt):
base = 4
sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
time.sleep(min(sleep_time, 60))
来自 ScrapeOps 和 WebScraping.AI 的经验共识是:同一 IP 每次请求间隔 3–6 秒,并且在轮换前单个 IP 每会话最好不要超过大约 100 次请求。
使用代理轮换
这往往是成败最大的决定因素。AWS/GCP 这类数据中心代理在 Cloudflare Enterprise 目标上的成功率大约只有 5–15%,几乎没法用在 Indeed 上。住宅代理加上正确的 TLS 指纹伪装,成功率可以升到 80–95%。
PROXIES = [
"http://user:pass@us.residential.example:7777",
"http://user:pass@us.residential.example:7778",
"http://user:pass@us.residential.example:7779",
]
proxy = random.choice(PROXIES)
response = cffi_requests.get(
url,
impersonate="chrome124",
headers=headers,
proxies={"https": proxy},
timeout=30,
)
到 2026 年,住宅代理的价格大约是 每 GB 4–8.5 美元,具体取决于服务商和套餐时长。针对 Indeed,建议先从一个小型代理池开始,按需扩展。
妥善处理 403、429 和 503 状态码
不要无脑重试。不同状态码代表不同问题:
def fetch_with_retry(url, proxy_pool, max_retries=5):
for attempt in range(max_retries):
proxy = random.choice(proxy_pool)
headers["User-Agent"] = random.choice(USER_AGENTS)
try:
r = cffi_requests.get(
url,
impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
headers=headers,
proxies={"https": proxy},
timeout=30,
)
# 检查“200 但其实是挑战页”的隐蔽情况
if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
return r
if r.status_code == 403:
print(f"403——被拦截了。切换代理,第 {attempt + 1} 次尝试")
elif r.status_code == 429:
print(f"429——请求过于频繁,放慢速度。")
elif r.status_code == 503:
print(f"503——服务器过载,或者遇到了 JS 挑战。")
backoff_sleep(attempt)
except Exception as e:
print(f"请求错误:{e}")
backoff_sleep(attempt)
raise RuntimeError(f"重试 {max_retries} 次后仍然失败:{url}")
“200 但其实是挑战页”是最棘手的情况。把 200 当成功之前,一定要先检查响应正文里有没有 cf-turnstile 或 Just a moment 这类标记。
更简单的替代方案:让 Thunderbit 帮你处理反爬
如果你不想自己搭建和维护代理池、请求头轮换以及 TLS 指纹伪装,Thunderbit 的云端抓取会自动处理 CAPTCHA、代理轮换和反爬保护。无需代理配置,无需 curl_cffi 配置,也无需 CAPTCHA 解决库。当你只想拿到数据时,这就是阻力最小的路线。
为什么你的 Indeed 爬虫总是坏掉,以及怎么修复
403 只是急性疼痛。慢性疼痛是维护——今天还能用的爬虫,下周就坏了,还会悄悄返回空数据或过时结果。
Indeed 是怎么把你的选择器弄坏的
Indeed 会频繁轮换 CSS 类名。Bright Data 的指南 明确警告 说,像 css-1m4cuuf 和 css-1rqpxry 这样的类名“看起来像是随机生成的——大概是在构建时生成”。A/B 测试意味着不同会话看到的页面布局可能不同。DOM 结构重组也会在没有通知的情况下发生。
JobFunnel 的经历很有代表性。某位贡献者说:“CaptchaBuster 已经成功缓解了验证码问题,而页面仍然抓取失败的原因是过时的 BeautifulSoup 选择器。” 也就是说,爬虫不是被封了,而是解析错了元素。
策略:优先使用隐藏 JSON,而不是 DOM 解析
window.mosaic.providerData 这个数据块至少从 2023 年起 schema 就比较稳定。metaData.mosaicProviderJobCardsModel.results[] 这个路径到 2026 年仍然是 标准路径。DOM 选择器按月坏,JSON 提取往往按年才坏一次,甚至根本不坏。
策略:优先使用数据属性,而不是类名
当你确实要操作 DOM 时,请优先选择功能性属性:
| 选择器 | 用途 |
|---|---|
[data-testid="slider_item"] | 每个职位卡片容器 |
[data-testid="job-title"] 或 h2.jobTitle > a | 职位标题链接 |
[data-testid="company-name"] | 雇主名称 |
[data-testid="text-location"] | 地点文本 |
每个卡片上的 data-jk="<jobkey>" | 最稳定的挂钩——自 2019 年以来都没变 |
加断言检查,及时发现失效选择器
千万不要让爬虫默默运行却拿到 0 条结果。每次抓取后都加一个检查:
results = parse_hidden_json(html)
assert len(results) > 0, (
f"Indeed 在 start={start} 时返回空结果集——"
"可能被拦截、遇到 CAPTCHA,或者选择器漂移。"
f"响应前 500 个字符:{html[:500]}"
)
失败时把原始响应的前 500–2000 个字符记录下来。这样你可以立刻看出到底是 Turnstile 挑战页、登录墙,还是 schema 变了。最好每天跑一次 CI 级别的冒烟测试,用一个固定查询(比如 q=python&l=remote)来断言结果非空。
AI 替代方案:永不失效的爬虫
Thunderbit 的 AI 每次都会重新读取页面结构——它不依赖硬编码选择器或正则模式。当 Indeed 改 HTML 时,Thunderbit 会自动适配。这正好解决了论坛用户一再提到的维护负担问题。如果你曾经被 Slack 消息吵醒,说“爬虫又返回空行了”,你就会知道不用修它的价值有多大。
不写 Python 也能抓取 Indeed:无代码替代方案
几乎所有竞品指南都默认你会写 Python。但论坛里的真实反馈不是这样的。用户会说类似 “总是有不停的 bug 和错误,真的太难了”,甚至有人建议干脆去 Fiverr 找人帮忙拿数据。如果这听起来像你,那这一节就是你的逃生出口。
用 Thunderbit 抓取 Indeed 的方法(步骤详解)
步骤 1: 从 Chrome 网上应用店安装 Thunderbit Chrome 扩展。可以免费开始。
步骤 2: 在浏览器里打开 Indeed 的搜索结果页,例如 https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX。
步骤 3: 点击浏览器工具栏里的 Thunderbit 图标,然后点击 “AI Suggest Fields”。Thunderbit 的 AI 会扫描页面,自动识别职位标题、公司、地点、薪资、职位 URL 和发布日期等列。你可以检查并调整它建议的字段——删掉不需要的列,或者用自然语言描述你想要的内容来添加自定义列。
步骤 4: 点击 “Scrape”。Thunderbit 会从页面中提取数据,并把它展示成结构化表格。你应该能看到按你配置的字段排列的职位列表行。
用子页面抓取扩展信息
抓完列表页后,点击 “Scrape Subpages”,Thunderbit 就会逐个访问每个职位详情页。它会提取完整职位描述、任职要求、福利和申请链接——不需要额外设置。这相当于你再写一个 Python 爬虫去访问每个 /viewjob?jk=<jobkey> URL,只不过它只需要点一下。
自动处理分页
Thunderbit 会自动处理 Indeed 的点击式分页。你不需要手动拼接 offset URL,也不用写分页循环。它会自动翻页并汇总结果。
导出到你常用的工具
你可以把抓取的数据免费导出到 CSV、Excel、Google Sheets、Airtable 或 Notion——完全免费。不用写 csv.writer() 或 pandas.to_csv() 代码。
什么时候该用 Python,什么时候该用 Thunderbit
| 场景 | 最佳工具 |
|---|---|
| 自定义数据管道、通过 cron/Airflow 做定时自动化 | Python |
| 集成到更大的代码库中 | Python |
| 高度定制的解析逻辑 | Python |
| 一次性研究或市场分析 | Thunderbit |
| 非技术团队成员也需要数据 | Thunderbit |
| 现在就要数据,不想调试 403 | Thunderbit |
| 零配置抓取子页面信息 | Thunderbit |
时间对比:Python 环境搭建 + 反爬调试 = 几小时到几天(尤其是第一次)。Thunderbit = 同样的数据不到 2 分钟。我不是说 Python 不对——我是说,这取决于你真正需要什么。
抓取 Indeed 合法吗?你需要知道这些
排名靠前的 Indeed 抓取指南几乎都不谈合法性,这挺让人意外的,毕竟论坛里经常有人问“抓取 Indeed 合法吗?”这不是法律意见,但下面是大致情况。
Indeed 的服务条款
Indeed 的 ToS(indeed.com/legal)并没有一条笼统的“禁止抓取”条款。唯一明确的自动化禁令是 A.3.5 条,禁止 “使用任何自动化、脚本或机器人来自动化 Indeed Apply 流程。” 这一条范围很窄,只针对申请流程,而不是被动读取公开职位列表。Indeed 主要靠技术手段来执行限制——Cloudflare 挑战、IP 封禁、设备指纹识别——而不是法庭诉讼。
相关法律判例
美国最常被引用的案例是 hiQ Labs v. LinkedIn。第九巡回法院在 2022 年 4 月 裁定,抓取公开可访问的数据“很可能不违反 CFAA”(《计算机欺诈和滥用法》)。不过,hiQ 后来又被认定 违反合同,因为其员工创建了假的 LinkedIn 资料并接受了服务条款。
更近一些,Meta v. Bright Data(加州北区法院,2024 年 1 月)给出了更清晰的裁定。Chen 法官 认定 Facebook 和 Instagram 的服务条款“并不禁止对公开数据进行已登出状态下的抓取”。Meta 在次月主动撤回了剩余主张。
Indeed 的 robots.txt
Indeed 的 robots.txt 对默认 User-agent: * 广泛禁止了 /jobs/ 和 /job/,但明确允许 Googlebot 和 Bingbot 访问 /viewjob? ——也就是单个职位详情页。AI 训练爬虫(GPTBot、CCBot、anthropic-ai)受到了严格限制。robots.txt 在美国不具有法律约束力,但遵守它属于最佳实践,也能体现善意。
负责任抓取的实用准则
- 只抓取公开可访问的数据——不要登录,不要创建假账号
- 尊重速率限制:每个 IP 每 3–6 秒 1 次请求,并发保持个位数
- 不要把抓取来的数据当成你自己的招聘网站重新发布
- 仅将数据用于个人或内部研究,不要在未经许可的情况下商业转售
- 丢弃或哈希处理不需要的个人身份信息(PII);对接近个人信息的数据设置保留上限
- 如果你要大规模运行,或者在欧盟/英国运营,请咨询律师——GDPR 第 14 条的透明度义务适用于抓取到的个人数据
风险层级也很清楚:个人求职自动化风险较低;大规模商业转售 Indeed 数据则风险较高。
结论与核心要点
用 Python 抓取 Indeed 是可行的,但这不是那种周末做完就能一劳永逸的项目。Indeed 的 Cloudflare 保护、轮换选择器和激进反爬措施意味着你必须用对工具,也要有正确预期。
我会从这篇文章里带走这些结论:
- Indeed 是网页上最丰富的职位市场数据来源之一——月访客 3.5 亿、职位列表 1.3 亿——但它对爬虫的反击也很强。
- 隐藏 JSON 提取(
window.mosaic.providerData)是最稳的 Python 方案。 这个 schema 多年来一直很稳定,而 CSS 选择器几乎每月都会坏。 - 带浏览器伪装的
curl_cffi是 2026 年 Cloudflare 保护网站的默认 HTTP 客户端。 普通requests和httpx仅凭 TLS 指纹就会被拦。 - 务必使用轮换请求头、随机延迟和住宅代理 来避免 403 错误。数据中心代理对 Cloudflare Enterprise 几乎没用。
- 加上断言检查,这样你能第一时间发现选择器失效,或者拿到的是挑战页而不是真数据。
- 如果你不是技术用户,或者只是想快速拿结果,Thunderbit 提供了无代码、AI 驱动的路径,并且会自动适配网站变化——无需代理、无需调试、无需维护。
如果你想试试无代码路线,Thunderbit 提供免费额度,你可以直接在 Indeed 上试用而不需要任何承诺。如果你选择 Python 路线,上面的代码示例是很好的起点——只是要记住,把反爬韧性当成一等公民,而不是事后补丁。
想了解更多网页爬虫方法和工具,可以看看我们的指南:如何使用 Python 做网页爬虫、最佳自动化网页爬虫工具 和 如何在不被封的情况下做网页爬取。你也可以观看 Thunderbit YouTube 频道 上的教程。
试试 Thunderbit,更快抓取 Indeed 数据 Get Started Free
常见问题
哪些 Python 库最适合抓取 Indeed?
对于 HTTP 请求,curl_cffi 是 2026 年最强的选择——它能伪装真实浏览器的 TLS 指纹,这对绕过 Cloudflare 至关重要。对于防护较弱的目标,带 HTTP/2 的 httpx 也可以作为备选。做 HTML 解析时,BeautifulSoup4 配合 lxml 仍然是标准方案。做浏览器自动化时,Playwright(配合 playwright-stealth)或 undetected-chromedriver 都能用,不过它们也越来越容易被检测到。隐藏 JSON 的正则方法(window.mosaic.providerData)则几乎可以完全绕开重度解析。
为什么我在抓取 Indeed 时总是遇到 403 错误?
Indeed 使用 Cloudflare Bot Management,它会检查你的 TLS 指纹(JA3/JA4)、HTTP/2 请求头顺序、请求模式和浏览器行为。如果你用的是普通 requests,你的 TLS 指纹一眼就会被识别成 Python 脚本——甚至在请求头被读取之前就会返回 403。解决办法是切换到带浏览器伪装的 curl_cffi、轮换真实的 User-Agent、加入随机延迟(3–6 秒),并使用住宅代理。还要检查“200 但其实是 Turnstile 挑战页”的情况——记得扫描响应正文里是否有 cf-turnstile 标记。
不写代码也能抓取 Indeed 吗?
可以。Thunderbit 这类工具能让你只用几次点击就提取 Indeed 的职位列表——安装 Chrome 扩展,打开 Indeed 搜索页,点击“AI Suggest Fields”,再点“Scrape”即可。Thunderbit 的 AI 会自动识别职位标题、公司、地点和薪资等字段。它还能自动处理分页、子页面扩展抓取(完整职位描述)和反爬保护。你还可以免费导出到 CSV、Google Sheets、Airtable 或 Notion。
Indeed 的 HTML 结构多久会变一次?
Indeed 会定期轮换 CSS 类名(例如 css-1m4cuuf 这类随机哈希字符串),并且不通知就重构 DOM 元素。A/B 测试意味着不同用户可能同时看到不同布局。隐藏 JSON 方案(window.mosaic.providerData)稳定得多——至少从 2023 年起 schema 就一直比较一致。当你必须使用 DOM 选择器时,请优先使用 data-testid 属性和 data-jk(职位 key),而不是 CSS 类名。
抓取 Indeed 合法吗?
基于第九巡回法院在 hiQ v. LinkedIn(2022)中的裁定以及 Meta v. Bright Data(2024)的判决,对公开可访问的 Indeed 职位 URL 进行已登出状态下的抓取,在美国不太可能构成 CFAA 责任。Indeed 的 ToS 明确禁止自动化 Apply 流程,但并没有禁止被动阅读公开列表。尽管如此,请始终负责任地抓取:不要登录,不要创建假账号,遵守速率限制,不要把数据重新发布成你自己的招聘网站,并且在 GDPR/CCPA 下谨慎处理任何个人数据(如招聘人员姓名、邮箱)。如果是商业规模运营,请咨询律师。
了解更多




