数据的价值远远超过系统本身,它的生命力更加持久。
- ,万维网之父、计算机科学家
每天,Google 要应对 搜索请求:这些不仅仅是人们日常疑问的答案,更是蕴藏着市场趋势、竞品动态和用户行为的巨大宝库。不管你是做销售、,还是市场营销,都能从中挖掘出有价值的信息,转化为实际的业务策略。
还在用复制粘贴的老办法收集这些数据?是时候升级你的工具箱了。
这篇文章会带你搞清楚什么是 Google SERP、它都包含哪些有用数据,并介绍三种抓取 Google SERP 的方法,包括最简单易用的无代码 AI 网页爬虫 。
什么是 Google 搜索结果页(SERP)?
(搜索引擎结果页)就是你在 Google、 或 等搜索引擎输入关键词后看到的页面。它是所有流量的起点,也是你点进任何链接前的第一站。
SERP 最大的特点就是实时变化:算法更新、新功能上线、关键词热度波动、网站内容调整都会影响结果。而且,搜索引擎还会根据你的历史记录和地理位置个性化展示内容,所以即使同一时刻,不同用户看到的 SERP 也可能完全不一样。正因为这样,普通用户想高效提取这些非结构化页面的数据其实挺难的。
而 Google 占据了全球 以上的搜索引擎市场份额,搞懂 Google SERP 的结构和用法,对企业来说非常关键。
Google SERP 都有哪些数据?
Google SERP 的结构
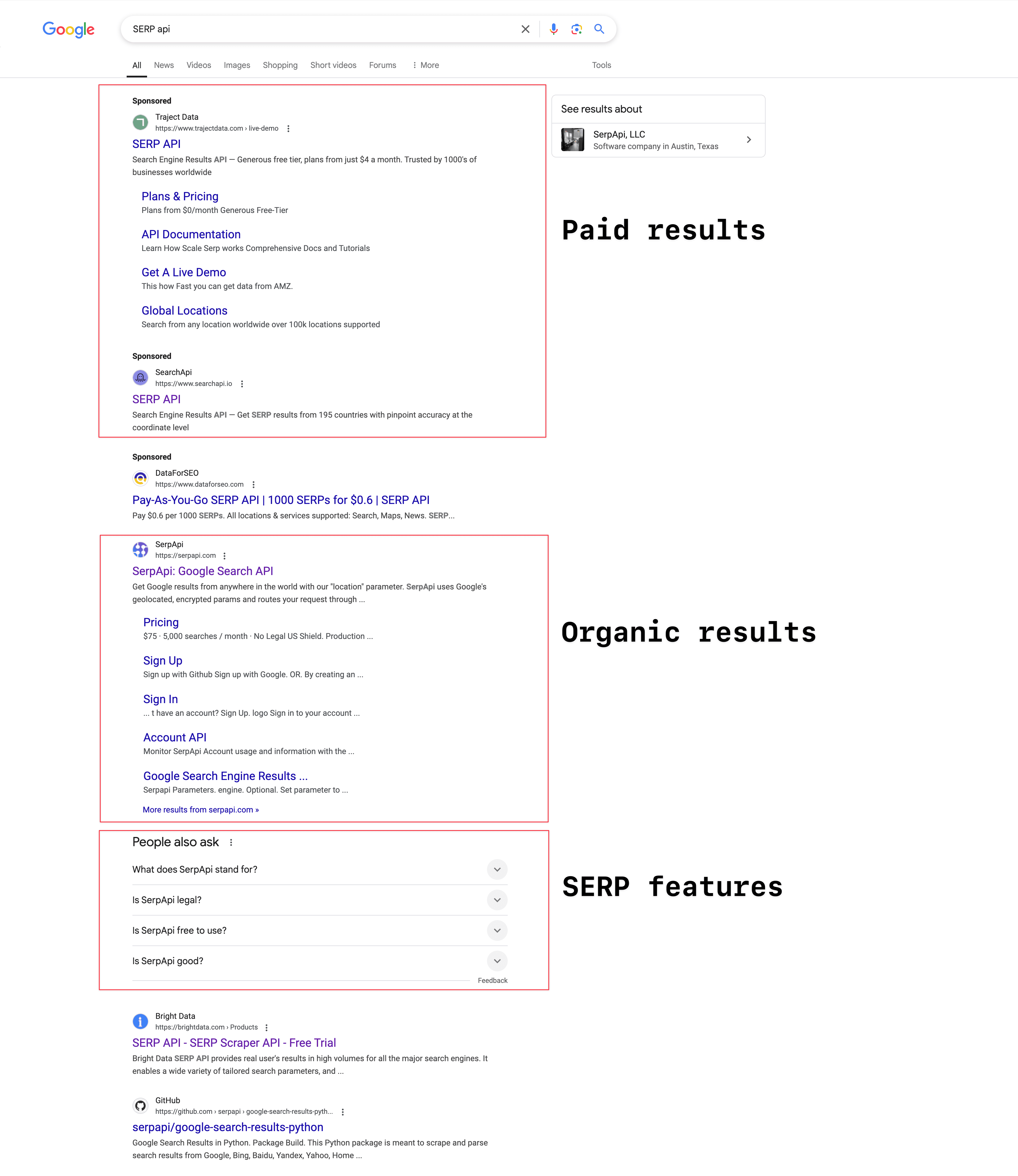
根据你搜索的内容不同,Google SERP 的结构也会有所变化。一般来说,主要分为三大块:
-
付费结果:带有“广告”或“Sponsored”标识的内容。网站通过付费让自己的页面排在自然结果的上方或下方。是否展示广告取决于用户的搜索内容。2023 年,Google 的广告收入高达 2645.9 亿美元(数据来源:)。
-
自然结果:根据相关性和页面排名自动展示的免费结果。每条结果通常包含标题、描述和网址。
-
SERP 功能区:Google 不断推出的新功能,提升用户体验,包括精选摘要、AI 概览、相关问题(PAA)、知识面板、本地商家信息、视频、图片、购物结果等。
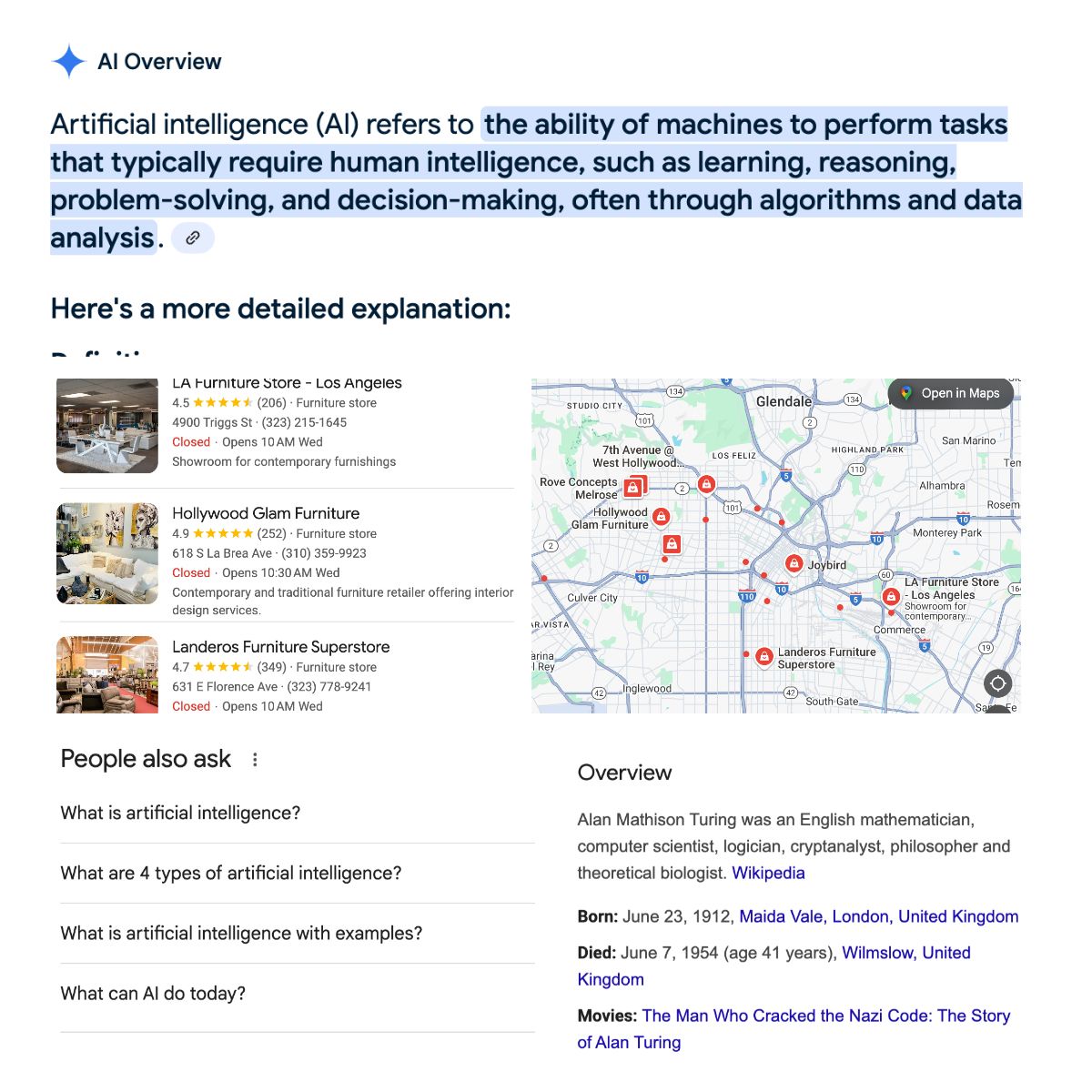
数据类型
了解了 SERP 的结构后,你可以抓取的信息类型包括但不限于:
- 广告
- 标题
- URL
- 描述
- 相关问题(PAA)
- 购物信息:价格、图片
- 邮箱
- 电话号码
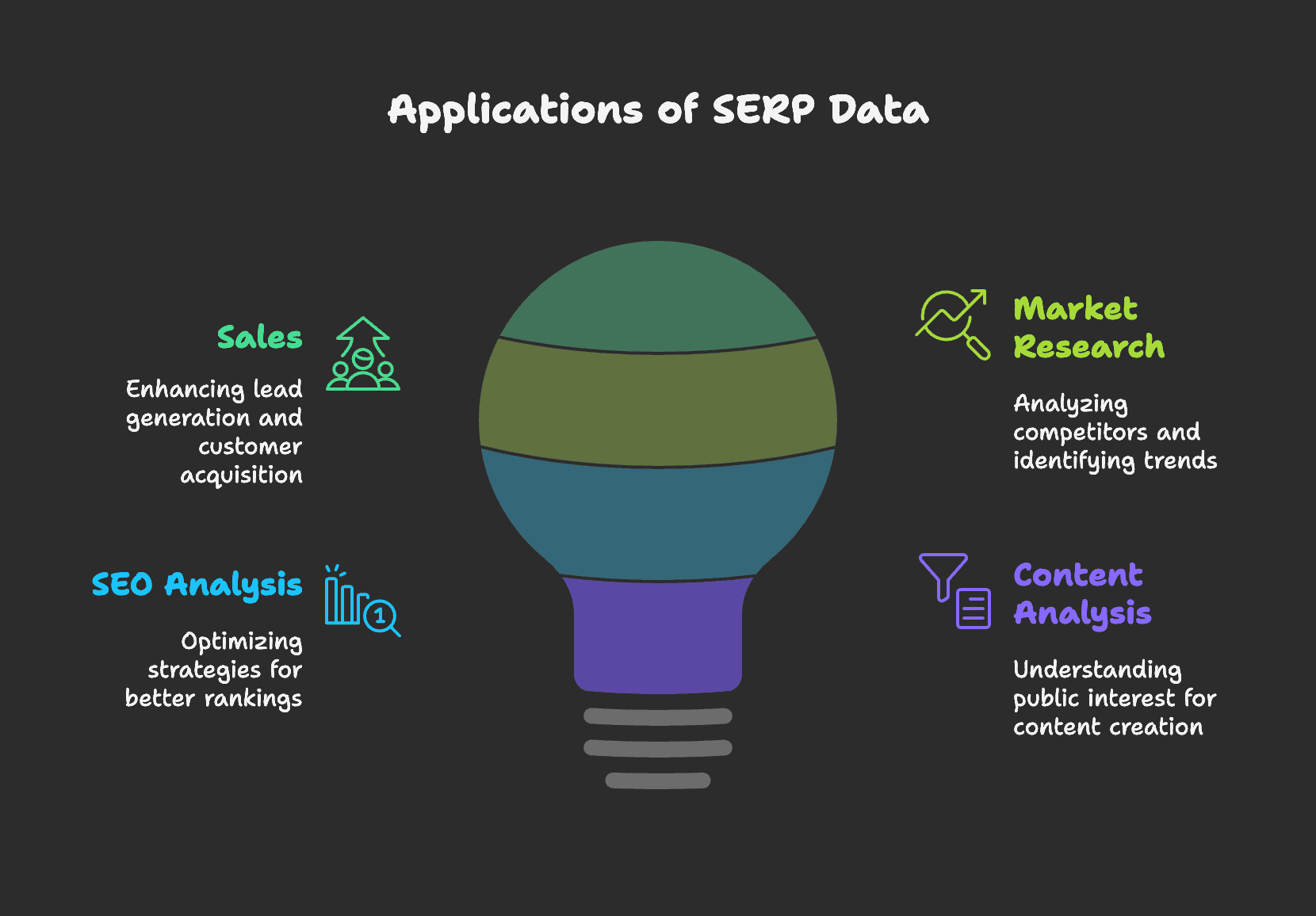
SERP 数据能做什么?
销售线索挖掘
通过精准的搜索指令,销售团队可以高效挖掘潜在客户,发现别人忽略的商机。Google 能帮你从社交平台中提取客户邮箱、电话等联系方式。下文我们会以 Instagram 为例,详细讲解如何用 SERP 抓取销售线索。
市场调研
SERP 结果能让市场人员更高效地分析竞争对手,比如抓取竞品的广告和产品信息,洞察其策略,从而优化自身的营销方案。
SERP 还是市场趋势的风向标。分析关键词热度变化,可以发现新兴市场机会。例如,如果你经营服装店,发现“可持续时尚”相关搜索量激增,就可以考虑增加相关产品。
SEO 分析
SERP 是 SEO 专家的基础数据。通过分析 SERP,可以调整关键词策略、优化网站内容,提升排名。
以 PAA(相关问题)为例,抓取这些问题并分析变化趋势,可以发现用户关注的新话题,进而优化内容布局。
内容分析
对于媒体和内容创作者,抓取 Google 新闻结果有助于分析热点趋势、把握大众关注点,指导选题方向。具体如何用网页爬虫抓取文章,可参考我们的详细教程。
如何抓取 Google 搜索结果页
了解了 SERP 数据的价值,接下来就是:怎么高效采集?
手动复制粘贴虽然能用,但面对大量数据时效率太低。现在有了 AI 网页爬虫,批量采集数据变得非常简单。下面介绍三种主流自动化方法:
方法一:使用 Thunderbit AI 网页爬虫
是一款无代码 AI 网页爬虫,能帮你从网页中提取任何你想要的数据。你可以直接用 ,也可以自定义字段。以销售线索挖掘为例,下面是用 Thunderbit 寻找高质量客户的详细步骤:
-
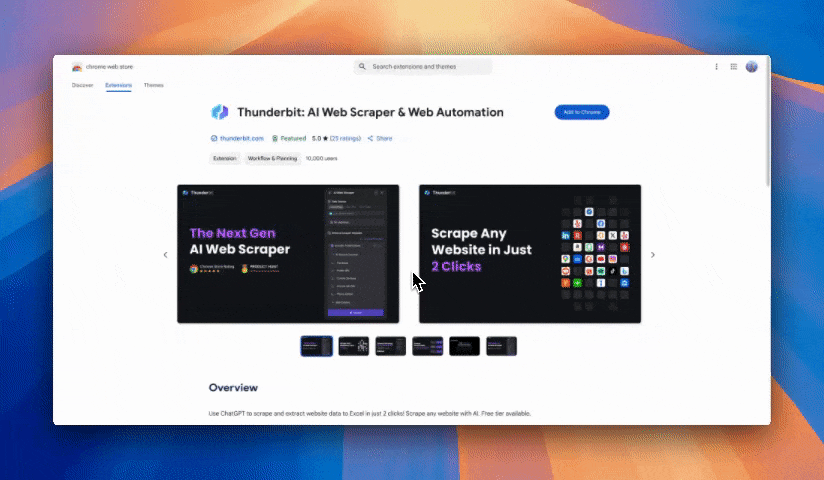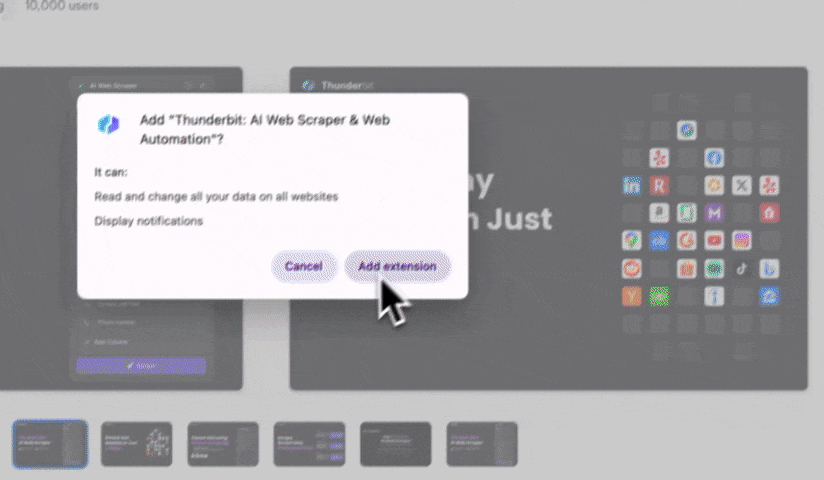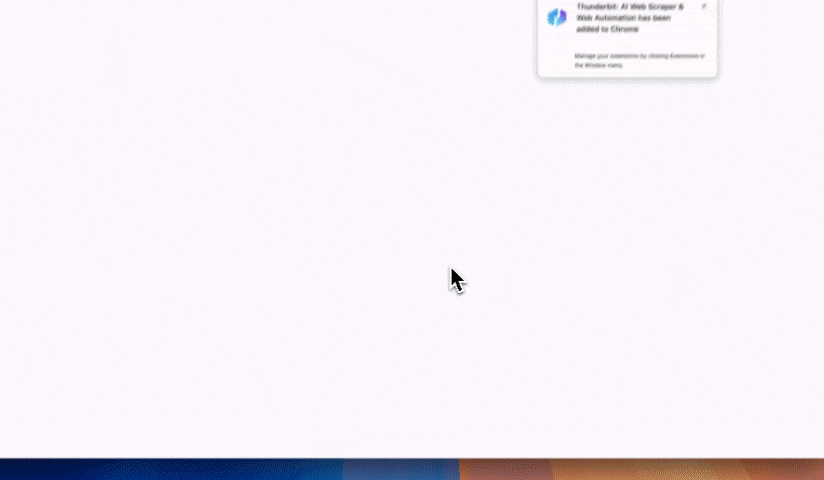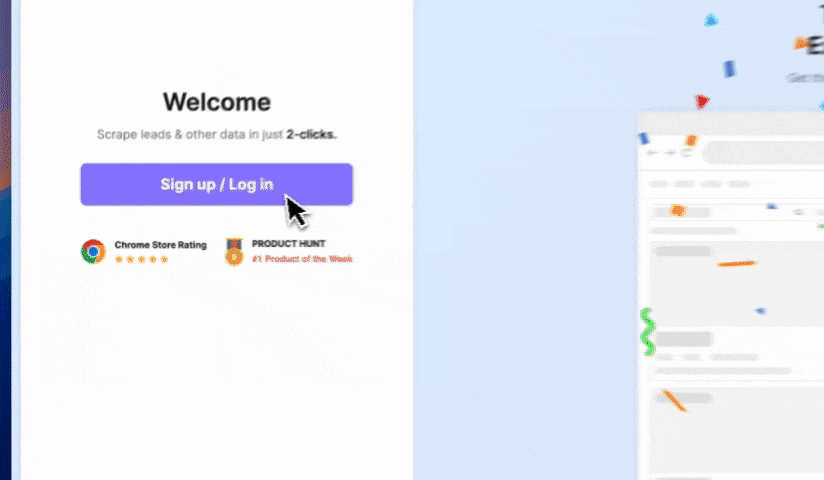
步骤 1:将 Thunderbit 添加为 Chrome 扩展,并用 Google 账号或邮箱登录。
-
步骤 2:输入你的搜索指令。
想精准筛选结果,非常有用。
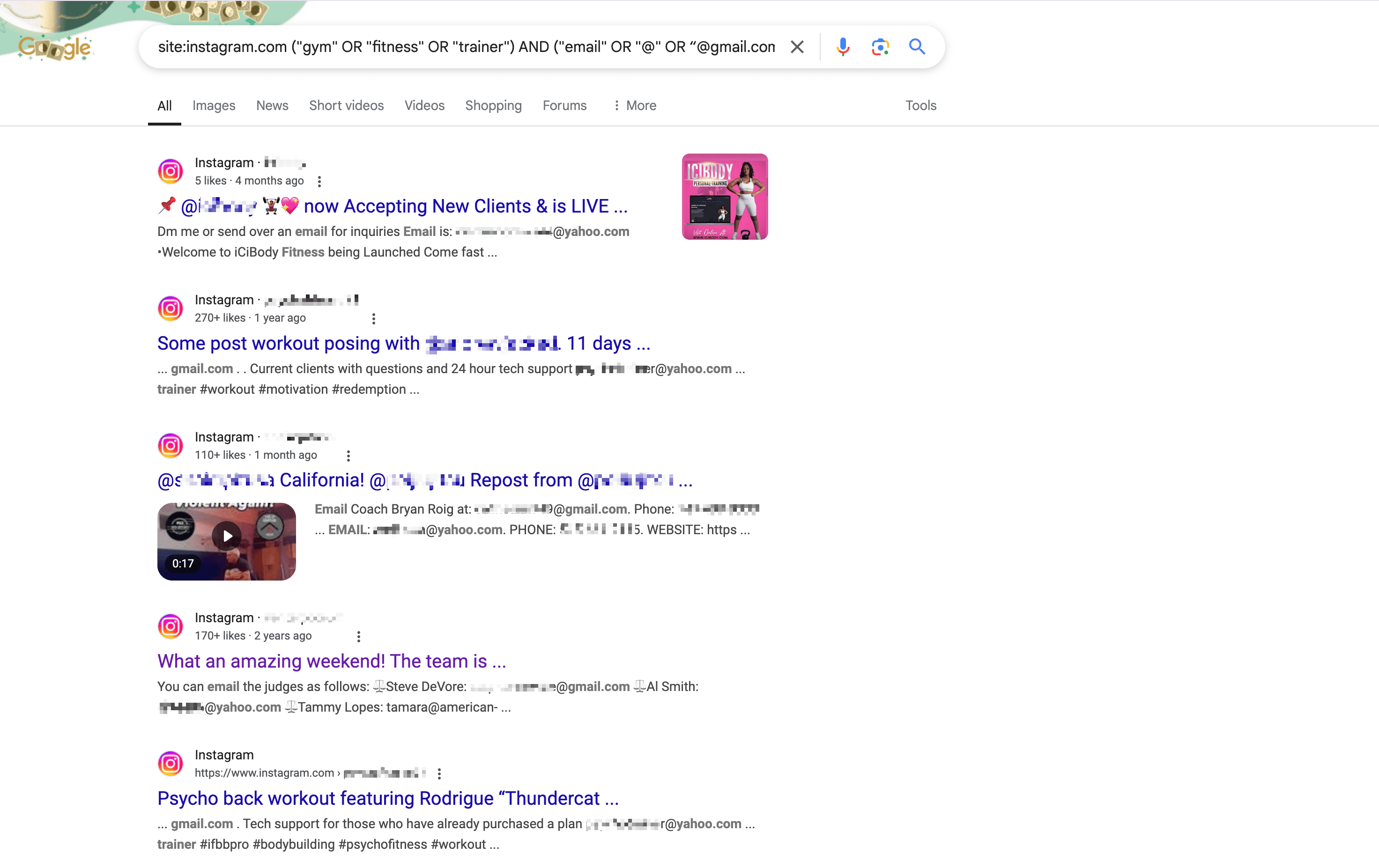
例如,以下是 生成的搜索指令,用于查找洛杉矶健身相关 Instagram 用户的邮箱:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")在 Google 输入上述指令并回车,即可看到所有相关信息。
-
步骤 3:启动 Thunderbit 开始抓取
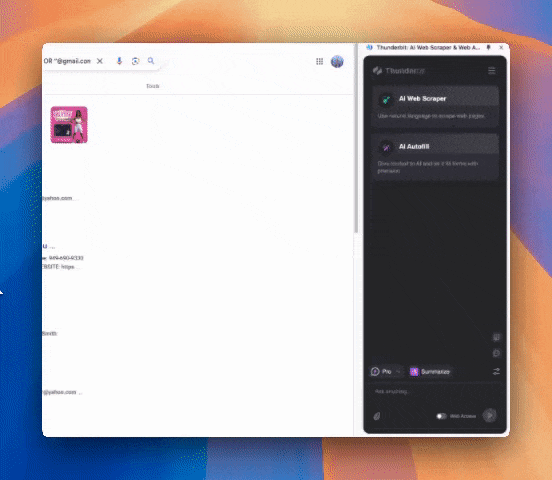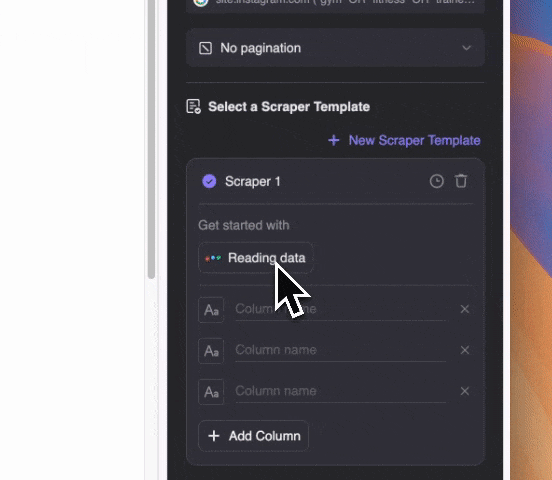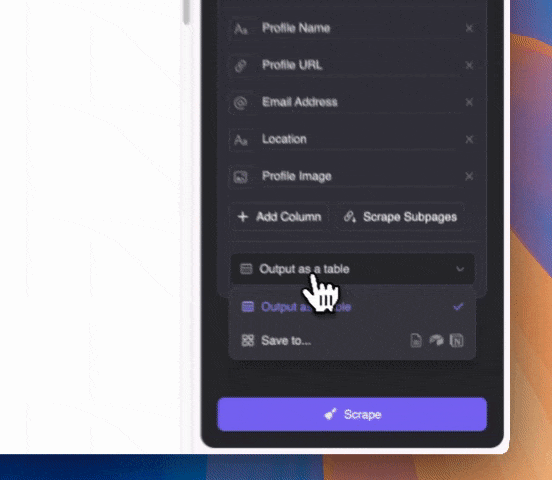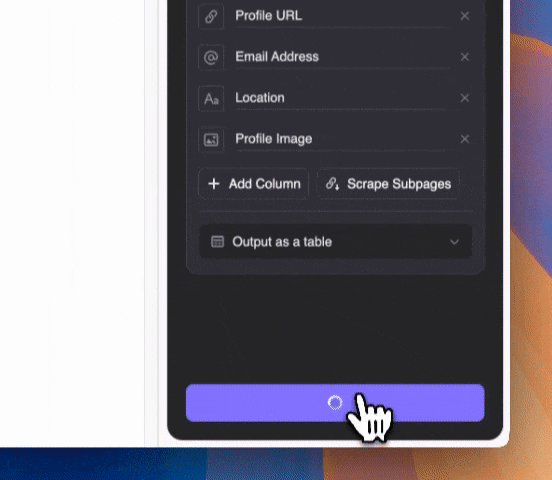 用自然语言描述你想抓取的内容类型(也可以点击“添加详细说明”补充描述)。支持导出为表格,或直接同步到 Notion、Airtable、Google Sheets。
用自然语言描述你想抓取的内容类型(也可以点击“添加详细说明”补充描述)。支持导出为表格,或直接同步到 Notion、Airtable、Google Sheets。值得一提的是,Thunderbit 利用 AI 技术,即使邮箱混在 Google SERP 的摘要文本中,也能精准提取。
点击“抓取”按钮,静待结果即可!
方法二:使用传统网页爬虫
传统网页爬虫同样可以批量抓取 Google SERP 数据。以 WebScraper.io 为例,操作流程如下:
- 安装 Web Scraper 扩展,打开 Chrome 开发者工具。
- 点击“创建新站点地图”,起始网址设为你的 Google 搜索结果页。
- 配置选择器,指定要提取的数据。
| 选择器名称 | 类型 | 选择器 | 多选? |
|---|---|---|---|
| name | 文本 | 选择用户名称 | 否 ❌ |
| profile | 文本 | 选择页面描述 | 否 ❌ |
-
运行爬虫并导出数据。
-
抓取到简介后,还需用正则公式在 Excel 中提取邮箱:
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(假设 A2 是简介文本)
这样就能提取出你想要的邮箱地址。
但这种方法的缺点是:你需要懂一些网页结构知识,而且只要网页结构有变(哪怕一天内),就得重新配置选择器。
方法三:使用 Google 官方 API 或第三方 SERP API
Google 提供了 ,可以通过编程方式获取搜索结果。你需要创建 ,获取 API key,并用 Python requests 库发起请求。但官方 API 返回内容有限,且有严格的访问额度限制。如果你需要高度自定义,这种方式可能不适合。
更常见的做法是用第三方 SERP 爬虫 API(如 Zen SERP、SerpApi、ScrapingBee)来实现。这同样需要一定的技术配置。安装后,你还需编写代码批量获取 Instagram 个人主页链接,再从简介中提取邮箱。对于不懂编程的商务人士来说,操作门槛较高。
1import requests
2from bs4 import BeautifulSoup
3import re
4# SerpApi 凭证
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# 步骤 1:用 SerpApi 获取 Instagram 个人主页链接
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# 步骤 2:从 Instagram 简介中提取邮箱
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# 示例用法
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("找到的 Instagram 主页:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"\{profile\} 中找到邮箱: \{emails\}")
44 else:
45 print(f"\{profile\} 未找到邮箱")三种方法对比
想要零技术门槛、快速获取数据?→ 选
想要完全自定义字段、懂点 HTML/CSS?→ 选传统网页爬虫
需要大规模、低成本采集且有技术支持?→ 选第三方 SERP API
Google 爬虫合法吗?
很多人关心网页爬虫是否合法。?简单来说:要看具体情况。不同国家/地区、用途、服务条款和数据类型,法律规定都不一样,没有统一答案。
Google 的明确禁止自动化抓取其服务内容。但一般来说,。抓取用途(商业或非营利)也会影响合法性。
建议你在抓取前仔细阅读服务条款,只采集公开数据,避免将数据用于非法用途。如果需要大规模抓取,最好咨询专业律师。
总结
数据被称为“”,而 Google SERP 就是一座还没被充分开发的金矿。谁能最快把 SERP 数据转化为行动,谁就能在激烈的市场竞争中抢占先机。线索挖掘、市场调研、SEO 优化,都是 SERP 数据的典型应用场景。
根据你的技术背景、预算、数据规模和实际需求,本文介绍了前沿的 AI 网页爬虫 Thunderbit、传统网页爬虫和 SERP API。
如果你是商务人士,想一键抓取所有结果,Thunderbit 绝对是你的首选——还等什么?。
FAQ
1. 我可以从 Google 搜索结果页(SERP)提取哪些数据?
你可以提取标题、URL、描述、广告、精选摘要、购物信息(如价格、图片)、相关问题(PAA)、邮箱、电话号码等多种数据。
2. Thunderbit 与传统网页爬虫或 SERP API 有何不同?
是一款无代码、AI 驱动的 Chrome 扩展,支持用自然语言描述要提取的数据,无需配置选择器或编写代码。传统爬虫需要技术设置,API 需编程且有数据访问限制。
3. 用 Thunderbit 抓取 Google 搜索结果需要技术基础吗?
不需要。Thunderbit 专为非技术用户设计,你只需用普通语言描述需求,AI 会自动帮你提取数据。
4. 抓取的数据可以导出到 Google Sheets 或 Notion 吗?
可以。Thunderbit 支持直接导出到 Google Sheets、Airtable、Notion,或下载为表格,方便你立即使用数据。
5. 抓取 Google SERP 数据有哪些实际应用?
常见应用包括销售线索挖掘、竞品分析、SEO 优化、趋势洞察、内容策划等。例如,销售团队可查找联系方式,市场人员可分析广告投放,SEO 可追踪关键词表现和相关问题。