如果你曾经想过搭建一份精准的销售名单、开拓新市场,或者对标竞争对手,你一定知道 Google 地图有多像一座数据金矿。问题在于:随着每月超过 15 亿次“附近”搜索,以及 76% 的本地搜索用户会在 24 小时内到店(),市场对最新、基于位置的商业数据需求从来没有这么强烈。
无论你做的是销售、营销还是运营,从 Google 地图提取结构化数据,都可能决定你拿到的是冷冰冰的陌生电话,还是高转化的温热线索。
我在 SaaS 和自动化领域工作多年,也亲眼见过团队如何借助 Python(以及现在的 AI 工具,比如 )把 Google 地图变成战略资产。
在这篇指南里,我会一步一步拆解如何在 2026 年用 Python 抓取 Google 地图数据——包含代码、合规建议,以及和无代码方案的对比。不管你是 Python 老手,还是只想最快拿到可用数据,这里都能帮到你。
用 Python 抓取 Google 地图,究竟是什么意思?
先从最基础的概念说起:用 Python 抓取 Google 地图,就是通过程序化方式从 Google 地图中提取商家信息——比如名称、地址、评分、评论、电话号码和坐标等——这样你就可以分析、筛选并导出,用于业务场景。

主要有两种做法:
- Google Maps Places API:这是官方授权的方式。你用 API 密钥向 Google 服务器发起查询,返回结构化的 JSON 数据。它稳定、可预测,而且在大多数情况下是合规的,但会有配额和费用。
- 抓取 HTML 页面:你用浏览器自动化工具(比如 Playwright 或 Selenium)打开 Google 地图,执行搜索,再解析渲染后的页面。这种方式更灵活,但也更脆弱——Google 经常改网站结构,抓取 HTML 还可能违反其条款。
你通常可以提取的数据字段包括:
- 商家名称
- 类别/类型
- 完整地址(含城市、州/省、邮编、国家)
- 纬度和经度
- 电话号码
- 网站 URL
- 评分和评论数
- 价格等级
- 商家状态(营业/歇业)
- 营业时间
- Place ID(Google 的唯一标识)
- Google 地图 URL
**为什么这很重要?**因为这些字段能支撑从线索挖掘、区域规划,到竞争对手对标和市场研究的几乎所有工作。关键在于:要围绕你的业务目标去抓数据,而不是盲目采集。
为什么销售和营销团队会用 Python 从 Google 地图提取数据
说得更实际一点。为什么 2026 年这么多销售和营销团队都盯着 Google 地图数据?
- 线索开发:构建高度精准的本地企业名单,附带联系信息和评分,直接用于外联活动。
- 区域规划:基于真实的商家密度和类型,规划销售区域、配送范围或服务半径。
- 竞争对手监测:持续追踪竞争对手的位置、评分和评论,发现趋势和机会。
- 市场研究:分析商家类别、营业时间和评论情绪,为市场进入策略提供依据。
- 选址分析:对房地产和零售业务来说,可以基于周边配套、人流和竞争情况评估候选位置。
现实影响:根据 ,92% 的销售组织计划增加 AI/数据投入,而使用精准本地数据的团队,其转化率比依赖普通冷名单的团队高出多达 8 倍()。一项针对加盟连锁的获客研究还发现,基于 Google 地图线索名单的投入,每花 1 美元可带来 15 美元新增收入。
将业务目标映射到 Google 地图字段:
| 业务目标 | 所需的 Google 地图字段 |
|---|---|
| 本地线索名单 | name, address, phone, website, category |
| 区域规划 | name, lat/lng, business_status, opening_hours |
| 竞品对标 | name, rating, userRatingCount, priceLevel, reviews |
| 选址分析 | category, lat/lng, review density, openingDate |
| 情绪/菜单情报 | reviews, editorialSummary, photos, types |
| 邮件/电话外联 | nationalPhoneNumber, websiteUri(再按需补充) |
搭建你的 Python Google 地图爬虫:工具与准备
开始抓取之前,你需要先配置好 Python 环境,并准备相关工具。下面是 2026 年你需要的东西:
1. 安装 Python 和所需库
**推荐的 Python 版本:**3.10 或更高。
安装核心库:
1pip install \
2 requests==2.33.1 httpx==0.28.1 \
3 beautifulsoup4==4.14.3 lxml==6.0.3 \
4 pandas==2.3.3 \
5 selenium==4.43.0 playwright==1.58.0 \
6 googlemaps==4.10.0 google-maps-places==0.8.0 \
7 schedule==1.2.2 APScheduler==3.11.2 \
8 python-dotenv==1.2.2 tenacity==9.1.4
9playwright install chromium这些库分别做什么:
requests、httpx:HTTP 请求(API 调用)beautifulsoup4、lxml:HTML 解析(用于网页抓取)pandas:数据清洗、分析、导出selenium、playwright:浏览器自动化(用于 HTML 抓取)googlemaps、google-maps-places:Google 地图 API 客户端schedule、APScheduler:任务调度python-dotenv:从.env文件安全加载 API 密钥tenacity:错误处理的重试逻辑
2. 获取 Google Maps API 密钥(用于基于 API 的抓取)
- 前往 。
- 创建或选择一个项目。
- 启用计费(即使是免费额度也需要)。
- 在 APIs & Services > Library 中启用 “Places API (New)”。
- 进入 Credentials > Create Credentials > API Key。
- 为安全起见,将密钥限制为特定 API 和 IP。
- 把 API 密钥存到
.env文件中(千万不要直接提交到代码仓库):
1GOOGLE_MAPS_API_KEY=your_actual_api_key_here**注意:**截至 2025 年 3 月,Google 已不再提供统一的每月 200 美元免费额度。现在改为按不同 API 层级提供每月免费阈值(见)。
如何用 Python 从 Google 地图提取数据:分步指南
下面我们把两种主流方式——基于 API 和 HTML 抓取——拆开讲,方便你选择最适合自己的方案。
方案 1:使用 Google Maps Places API(推荐)
步骤 1:安装并导入所需库
1import os
2import httpx
3import pandas as pd
4from dotenv import load_dotenv步骤 2:安全加载 API 密钥
1load_dotenv()
2API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]步骤 3:构建搜索查询
你会使用 Text Search 接口来查找符合条件的商家。
1URL = "https://places.googleapis.com/v1/places:searchText"
2FIELD_MASK = ",".join([
3 "places.id", "places.displayName", "places.formattedAddress",
4 "places.location", "places.rating", "places.userRatingCount",
5 "places.priceLevel", "places.types",
6 "places.nationalPhoneNumber", "places.websiteUri",
7 "nextPageToken",
8])步骤 4:发起 API 请求
1def text_search(query, lat, lng, radius=3000, min_rating=4.0):
2 body = {
3 "textQuery": query,
4 "minRating": min_rating, # 服务端筛选
5 "includedType": "restaurant",
6 "openNow": False,
7 "pageSize": 20,
8 "locationBias": {
9 "circle": {
10 "center": {"latitude": lat, "longitude": lng},
11 "radius": radius,
12 }
13 },
14 }
15 headers = {
16 "Content-Type": "application/json",
17 "X-Goog-Api-Key": API_KEY,
18 "X-Goog-FieldMask": FIELD_MASK, # 一定要设置!
19 }
20 r = httpx.post(URL, json=body, headers=headers, timeout=30)
21 r.raise_for_status()
22 return r.json()步骤 5:处理分页并收集结果
1def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
2 results = []
3 next_page_token = None
4 while True:
5 data = text_search(query, lat, lng, radius, min_rating)
6 places = data.get('places', [])
7 results.extend(places)
8 next_page_token = data.get('nextPageToken')
9 if not next_page_token:
10 break
11 return results步骤 6:用 Pandas 导出数据
1df = pd.DataFrame(collect_all_results("布鲁克林的咖啡店", 40.6782, -73.9442))
2df.to_csv("brooklyn_coffee_shops.csv", index=False)专业建议:
- 一定要设置
X-Goog-FieldMask请求头来控制成本。如果你请求评论或图片,每 1,000 次请求的价格可能会从 5 美元飙升到 25 美元(见)。 - 使用服务端筛选(例如
minRating、includedType、locationBias),避免把额度浪费在无关结果上。 - 缓存
place_id,方便去重和后续更新。
方案 2:抓取 Google 地图 HTML(适合教学/一次性使用)
**警告:**Google 地图是单页应用。你必须使用浏览器自动化(Playwright 或 Selenium),而且抓取 HTML 可能违反 Google 的条款。建议只用于研究,不要用于生产环境。
步骤 1:安装 Playwright 并启动浏览器
1from playwright.sync_api import sync_playwright
2import time, re
3def scrape_maps(query, max_results=100):
4 with sync_playwright() as pw:
5 browser = pw.chromium.launch(headless=True)
6 ctx = browser.new_context(
7 user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
8 locale="en-US",
9 )
10 page = ctx.new_page()
11 page.goto("https://www.google.com/maps", timeout=60_000)
12 page.fill("#searchboxinput", query)
13 page.click('button[aria-label="搜索"]')
14 page.wait_for_selector('div[role="feed"]')
15 feed = page.locator('div[role="feed"]')
16 prev = 0
17 while True:
18 feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
19 time.sleep(2)
20 count = page.locator('div[role="feed"] > div > div[jsaction]').count()
21 if count == prev or count >= max_results:
22 break
23 prev = count
24 if page.locator("text=You've reached the end of the list").count():
25 break
26 rows = []
27 cards = page.locator('div[role="feed"] > div > div[jsaction]')
28 for i in range(cards.count()):
29 c = cards.nth(i)
30 name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
31 rating_el = c.locator('span[role="img"]').first
32 raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
33 m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
34 rating = float(m.group(1)) if m else None
35 reviews = int(m.group(2).replace(",", "")) if m else None
36 rows.append({"name": name, "rating": rating, "reviews": reviews})
37 browser.close()
38 return rows提示:
- Google 会每隔几周随机调整 CSS 类名,所以这段代码可能需要定期更新。
- 使用接近真人的延迟,并避免过快抓取,以降低被封禁的风险。
- 千万不要尝试绕过验证码或 Google 的 SearchGuard 系统——这可能带来法律风险。
不要盲目抓取:如何精准锁定你真正需要的数据
什么都抓,通常只会浪费时间,还会把数据集搞得臃肿。下面是如何只抓真正有价值的数据:
- 先生成精准的 URL 列表:先用 Google 地图自带的搜索过滤器(类别、位置、评分、当前营业)缩小结果范围,再开始抓取。
- 使用短语匹配:搜索具体的商家类型或关键词(例如 “奥斯汀的纯素烘焙店”)。
- 位置过滤:指定城市、街区,甚至坐标和半径,实现更精确的定位。
- 服务端筛选(API):在 API 请求体中使用
minRating、includedType和locationBias。 - 客户端筛选(Python):抓取完成后,用 pandas 筛选评分高于 4.0、评论数超过 50,或属于特定类别的商家。
示例:只筛选曼哈顿评分高于 4.0 的餐厅
1df = pd.DataFrame(results)
2filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
3filtered.to_csv("manhattan_top_restaurants.csv", index=False)用 Python 库整理并导出 Google 地图数据
当你抓到数据后,就该把它清洗、分析并导出给团队使用了。
用 Pandas 清洗和结构化数据
1import pandas as pd
2df = pd.read_json("brooklyn_restaurants.json")
3df = (
4 df.dropna(subset=["name", "address"])
5 .drop_duplicates(subset=["place_id"])
6 .assign(
7 name=lambda d: d["name"].str.strip(),
8 phone=lambda d: d["phone"].astype(str)
9 .str.replace(r"\D", "", regex=True)
10 .str.replace(r"^1?(\d\{10\})$", r"+1\1", regex=True),
11 rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
12 user_ratings_total=lambda d: pd.to_numeric(
13 d["user_ratings_total"], errors="coerce"
14 ).fillna(0).astype("int32"),
15 )
16)分析和汇总数据
示例:按街区计算平均评分
1by_neighborhood = (
2 df.groupby("neighborhood", as_index=False)
3 .agg(avg_rating=("rating", "mean"),
4 n_places=("place_id", "nunique"),
5 median_reviews=("user_ratings_total", "median"))
6 .sort_values("avg_rating", ascending=False)
7)导出为 Excel 或 CSV
1df.to_csv("brooklyn_top.csv", index=False)
2df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")**数据量很大?**可以用 Parquet 格式,速度更快、体积更小:
1df.to_parquet("brooklyn_top.parquet", compression="zstd")Thunderbit:AI 驱动的 Python Google 地图爬虫替代方案
如果你此刻在想:“为了一个简单的线索名单,这套准备工作是不是太多了?”你不是一个人。我们正是因为这个问题,才做了 ——一款 AI 驱动、无需代码的网页爬虫,让你像点几下鼠标一样轻松提取 Google 地图数据(以及更多数据)。
为什么选 Thunderbit?
- 无需编程或 API 密钥:只要打开 ,进入 Google 地图,然后点击“AI 智能推荐字段”。
- AI 字段识别:Thunderbit 的 AI 会读取页面并自动建议合适的列——名称、地址、评分、电话、网站等等。
- 子页面抓取:如果你想把每个商家网站上的信息补充到表格里,Thunderbit 可以自动访问每个子页面并提取额外信息。
- 导出到 Excel、Google Sheets、Airtable 或 Notion:不用再折腾 pandas,直接点“导出”,数据就能给团队使用。
- 定时抓取:设置周期性任务,自动监控竞争对手或刷新线索名单。
- 零维护:Thunderbit 的 AI 会自动适应网站变化,你不用反复修补失效脚本。
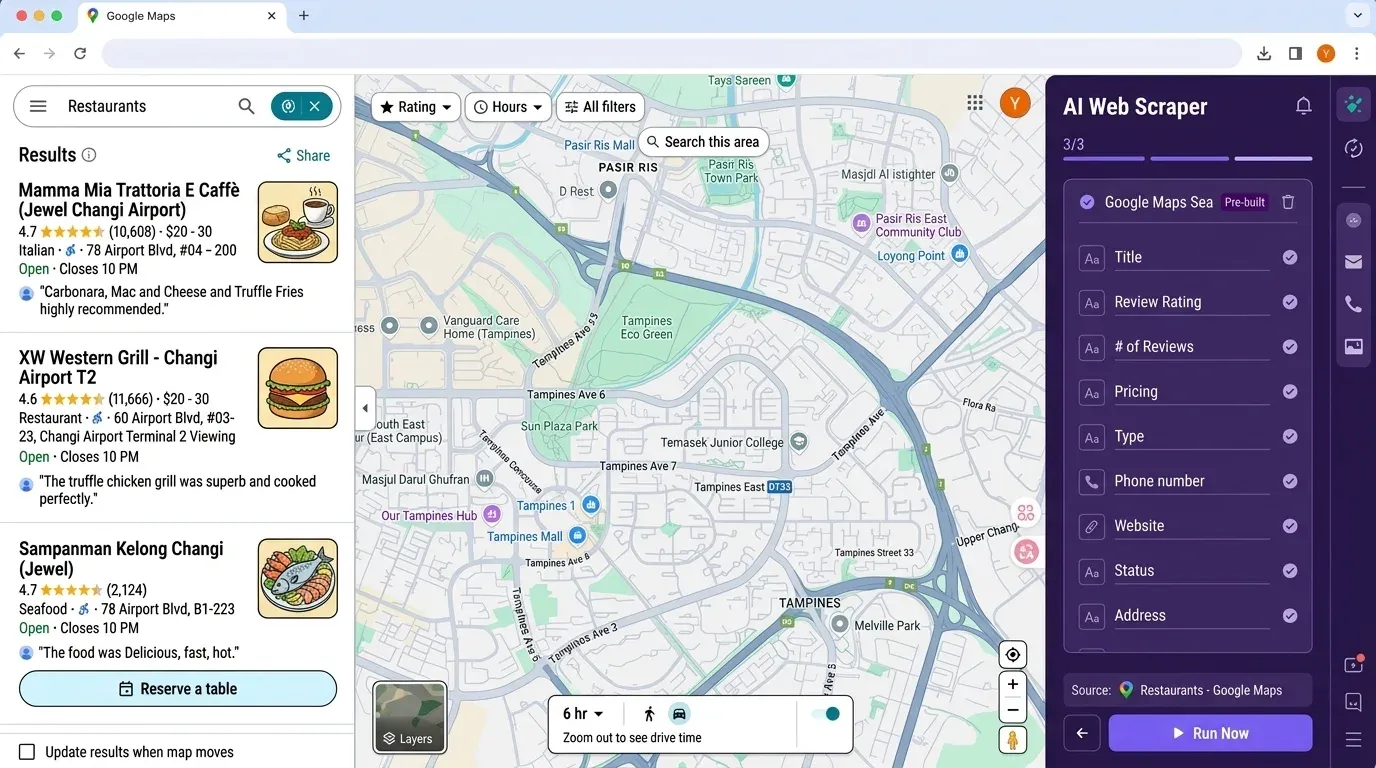
Thunderbit 与 Python 工作流对比:
| 步骤 | Python 爬虫 | Thunderbit |
|---|---|---|
| 安装工具 | 30–60 分钟(Python、pip、各类库) | 2 分钟(Chrome 扩展) |
| API 密钥设置 | 10–30 分钟(Cloud Console) | 不需要 |
| 字段选择 | 手写代码、字段掩码 | AI 智能推荐字段(1 次点击) |
| 数据提取 | 编写/运行脚本,处理错误 | 点击“抓取” |
| 导出 | 用 pandas 导出 CSV/Excel | 导出到 Excel/Sheets/Notion |
| 维护 | 网站变更时手动更新 | AI 自动适配 |
**额外福利:**Thunderbit 已经受到全球超过 信任,免费套餐可免费抓取最多 6 个页面(试用加成后可达 10 个)。
保持合规:Google 地图服务条款与抓取伦理
这部分往往是很多 Python 教程最容易过时、也最危险的地方。2026 年你需要知道这些:
- Google Maps Platform ToS §3.2.3 明确禁止通过官方 API 以外的方式抓取、缓存或导出数据()。唯一例外是:经纬度值最多可缓存 30 天;Place ID 可无限期保存。
- API 用户受合同约束:如果你使用了 API 密钥,就等于接受了 Google 的条款——即使你抓的是公开数据。
- 绕过技术限制(验证码、SearchGuard) 现在可能触发 DMCA §1201 违规,并可能带来刑事处罚()。
- GDPR 和隐私法:如果你从 Google 地图收集个人数据(邮箱、电话、评论者姓名等),你必须有合法依据,并尊重删除请求。法国 CNIL 曾在 2024 年因抓取 LinkedIn 联系人而对 KASPR 罚款 20 万欧元()。
- 最佳实践:
- 尽量优先使用 Places API。
- 限制请求频率(API ≤10 QPS,HTML 抓取每秒 1–2 次)。
- 绝不绕过验证码或技术封锁。
- 不要再分发抓取到的个人数据。
- 尊重退订和删除请求。
- 始终检查当地法律——GDPR、CCPA 等都在被积极执行。
**结论:**如果你担心合规,最好坚持使用 API,并尽量减少采集的数据。对大多数业务用户来说,像 Thunderbit 这样的无代码工具可以显著降低风险面(无需 API 密钥,也没有再分发风险)。
用 Python 对 Google 地图抓取进行定时与自动化
如果你需要保持数据新鲜——比如每周监控竞争对手,或每月更新线索名单——自动化就是你的好帮手。
使用 schedule 做简单调度
1import schedule, time
2from my_scraper import run_job
3schedule.every().day.at("03:00").do(run_job, query="布鲁克林的餐厅")
4schedule.every(6).hours.do(run_job, query="曼哈顿的咖啡店")
5while True:
6 schedule.run_pending()
7 time.sleep(30)使用 APScheduler 做生产级调度
1from apscheduler.schedulers.background import BackgroundScheduler
2from apscheduler.triggers.cron import CronTrigger
3sched = BackgroundScheduler(timezone="America/New_York")
4sched.add_job(
5 run_job,
6 CronTrigger(hour=3, minute=15, jitter=600), # 凌晨 3:15 ± 10 分钟
7 kwargs={"query": "布鲁克林的餐厅"},
8 id="brooklyn_daily",
9 max_instances=1,
10 coalesce=True,
11 misfire_grace_time=3600,
12)
13sched.start()安全自动化小建议
- 给调度任务加上随机抖动,避免形成可预测的模式。
- 对 HTML 抓取来说,绝不要超过每秒 1–2 次请求。
- 对 API 使用来说,要监控配额并设置计费提醒。
- 一定要记录错误,并为失败请求保留“死信”文件。
**Thunderbit 额外福利:**使用 Thunderbit,你可以直接在界面里设置周期性抓取——不用代码、不要 cron 任务,也不用搭服务器。
关键结论:高效、精准、合规地提取 Google 地图数据
最后我们来回顾一下重点:
- Google 地图是商业位置数据的头号来源,从线索开发到市场研究都离不开它。
- Python 抓取很灵活、可控,但也伴随着搭建、维护和合规成本——尤其是在 Google 的反爬措施和法律执行越来越严格的情况下。
- 基于 API 的提取对大多数团队来说最安全、也最可扩展。一定要使用字段掩码和服务端筛选来控制成本。
- HTML 抓取脆弱且有风险——只适合一次性研究,千万不要绕过技术限制。
- 要精准锁定你的数据:用短语匹配、位置筛选和 pandas 工作流,只提取你真正需要的内容。
- Thunderbit 是非技术用户最快的路径:AI 驱动、无需配置、可立即导出,还内置定时抓取。
- 合规很重要:遵守 Google 条款、隐私法规和速率限制,才能避免法律麻烦。
更多教程和技巧,可以查看 和我们的 。
常见问题
1. 2026 年用 Python 抓取 Google 地图数据合法吗?
通过官方 API 抓取 Google 地图数据,在遵守 Google 条款、配额限制且不再分发受限数据的前提下是允许的。Google 明确禁止 HTML 抓取 Google 地图;如果你绕过技术限制,或者在未经同意的情况下收集个人数据,法律风险会更高。务必查看当地法律(GDPR、CCPA 等),并遵循最佳合规实践。
2. 使用 Google Maps API 和抓取 HTML 有什么区别?
API 稳定、授权明确,且就是为数据提取而设计的,但需要 API 密钥,并受配额和费用约束。HTML 抓取则依赖浏览器自动化从渲染后的页面提取数据,但它很脆弱(网站经常变),也可能违反条款,法律风险更高。对大多数业务场景来说,API 是更推荐的路径。
3. 2026 年用 Python 提取 Google 地图数据要花多少钱?
Google Places API 按每 1,000 次请求计费,价格从 5 美元(Essentials)到 25 美元(Enterprise+Atmosphere)不等,具体取决于你请求的字段。虽然有每月免费阈值(Essentials 10,000 次、Pro 5,000 次、Enterprise 1,000 次),但大规模抓取的成本会很快累积。一定要用字段掩码和服务端筛选来控制费用。
4. Thunderbit 和基于 Python 的 Google 地图爬虫相比如何?
Thunderbit 是一款无需代码、AI 驱动的网页爬虫,无需编程、API 密钥或维护,就能提取 Google 地图数据(以及更多内容)。它非常适合需要快速、稳定导出到 Excel、Google Sheets、Airtable 或 Notion 的销售和营销团队。对需要自定义逻辑的技术用户来说,Python 更灵活,但也需要更多配置和合规管理。
5. 我怎么自动化定期提取 Google 地图数据?
使用 Python 时,可以用 schedule 或 APScheduler 这类调度库,按固定间隔(每天、每周等)运行爬虫。记得加入随机抖动,避免被识别,并监控 API 配额。使用 Thunderbit 时,你可以直接在界面里设置周期性抓取——无需代码,也不用服务器配置。
准备好把 Google 地图变成你的销售和营销超级武器了吗?无论你是 Python 爱好者,还是想要最快的无代码方案,2026 年你都已经有了现成工具。试试 ,体验即时的 AI 驱动抓取——或者直接卷起袖子,深入 API 世界。无论哪种方式,愿你的线索名单保持新鲜、导出干净利落,营销活动里满是高转化的本地潜客。祝你抓取顺利!
了解更多