Google 早在 2018 年就关闭了 Flights API,但机票价格还是一直在变——同一条国内航线在 48 小时内最多可能变动 。如果你想通过程序拿到这些数据,抓取基本上就是唯一可行的路。
我花了不少时间测试从 Google 抓取航班数据的不同方案,而且这个领域已经变了很多——尤其是在 Google 于 2025 年 1 月推出 SearchGuard 之后。在这篇指南里,我会带你用 Playwright 搭建一个能跑起来的 Google Flights Python 爬虫,演示如何应对大多数人都会踩坑的反爬机制,然后进一步把它扩展成带提醒功能的自动化价格追踪器。如果你想完全跳过代码,我也会介绍一个使用 的无代码捷径,大概两分钟就能做出同样效果。
为什么要用 Python 抓取 Google Flights?
Google Flights 在机票搜索这个领域几乎是绝对主力。它在美国移动端的可见度已经飙到 ,超过了所有主流 OTA 平台。背后的旅行元搜索市场在 2024 年估值达到 ,年复合增长率高达 30.2%。但自从 QPX Express API 于 后,就再也没有官方方式可以程序化访问这些数据了。
与此同时,同一行程的机票价格波动最高可达 ,最低价和最高价之间平均相差约 20 美元。像 Delta 这样的航空公司会用 77 个票价分层来做动态定价。到 2026 年初,美国往返机票均价为 408 美元,且票价同比上涨了 。
平台强势、没有 API、价格又特别爱跳。也正因为这样,使用 Python 抓取 Google Flights 已经成了 GitHub 和各种旅行论坛里最热门的话题之一。
下面先看看哪些人会受益,以及能带来什么价值:
| 用户类型 | 使用场景 | 核心收益 |
|---|---|---|
| 个人旅客 | 持续跟踪特定航线价格 | 平均每张机票可节省 50 美元 |
| 旅行社 | 竞争性票价情报分析 | 实时监控票价一致性 |
| 企业差旅团队 | 跨航线成本优化 | 企业差旅可节省 10–30% |
| 开发者 | 构建票价对比应用 | 程序化获取价格数据 |
| 研究人员 | 分析航空票价波动 | 学术与市场研究 |
论坛里的用户对自己为什么开始抓取说得很直白:“Google Flights API 已经停用了,所以我只能改用网页抓取。” 这种说法反复出现。投入产出比也确实挺高——,而 Expedia 的 2026 年数据则显示,提前 8–15 天预订国内航班大约能省 。
你能从 Google Flights 抓到哪些数据?
Google Flights 的结果页其实包含相当丰富的数据字段。通常可以拿到下面这些内容:
- 航空公司名称(以及 logo)
- 起飞时间 和机场代码
- 到达时间 和机场代码
- 总飞行时长
- 中转次数 以及转机详情(机场、时长、是否过夜)
- 票价(按币种显示)
- 碳排放(kg CO2e,并显示相对典型航班的百分比差异)
- 舱位等级、航班号、机型
- 腿部空间 信息
- 附加服务(Wi‑Fi、电源插座、媒体流)
- 价格等级 指示(低/一般/高)
- 延误提醒(“经常延误超过 30 分钟”)
具体能拿到哪些数据,会因航线、日期和票种(单程或往返)而异。下面是一个抓取到的单条航班记录 JSON 示例:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}配置 Python 环境
在写抓取代码之前,你需要先准备好几个东西。
前置条件:
- 难度: 中等
- 预计耗时: 完整教程约 1–2 小时
- 你需要: Python 3.7+、基础 Python 知识、一个基于 Chrome 的浏览器
安装所需库
这里我们用 Playwright 做浏览器自动化(Google Flights 100% 由 JavaScript 渲染,静态 HTTP 请求拿不到有用内容),另外还会用到几个辅助库:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — 无头浏览器自动化,负责 JavaScript 渲染,并带有等待机制
- playwright-stealth — 用来修补常见的机器人检测信号
- pandas — 后面做数据分析和导出 CSV 用
为什么选择 Playwright,而不是 Selenium 或 requests
只靠 requests + BeautifulSoup 根本抓不到 Google Flights——页面内容完全靠 JavaScript 渲染。你需要一个真正的浏览器。
Playwright 更快、更现代,而且异步支持也更顺手。就 Google Flights 来说,它明显是更合适的选择。
分步教程:如何用 Python 抓取 Google Flights
这是整篇教程的核心。我们会一步一步把爬虫搭起来。
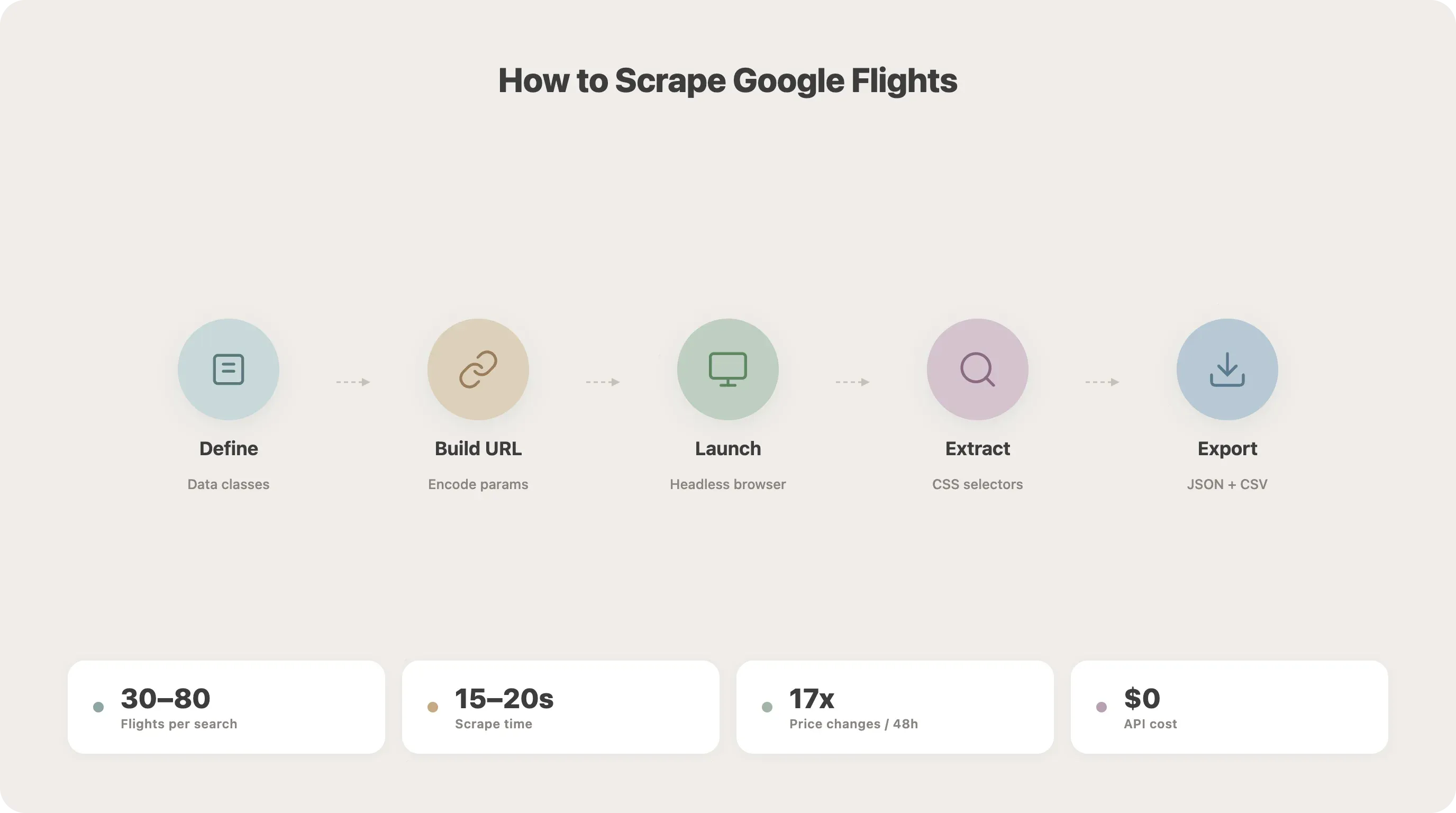
第 1 步:定义数据类
先用 Python dataclass 把搜索参数和航班数据结构化。这样代码会更清楚,后面扩展也更方便。
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # e.g., "SFO"
6 destination: str # e.g., "JFK"
7 departure_date: str # e.g., "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" or "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""每个字段都直接对应我们接下来要从页面里提取的信息。先把结构搭好,后面就不用在一堆乱七八糟的字典之间来回传了。
第 2 步:理解 Google Flights 的 URL 结构
Google Flights 会把搜索参数编码进 tfs URL 参数里,用的是 Base64 编码的 Protobuf。你可以去逆向这种编码方式,也可以走更简单的路:直接构造一个自然语言查询 URL。
最简单的方法是用搜索查询格式:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USD如果你想更灵活一点,也可以用程序动态生成 URL:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"另一种方案——逆向 Protobuf 编码——可以让你控制得更细,但一旦 Google 改了内部格式,这种方法就会失效。GitHub 上像 这样的库,会通过 Protobuf 解码直接绕过 HTML 解析,不过这属于更进阶的做法。
第 3 步:启动浏览器并进入 Google Flights
下面是 Playwright 的初始化代码。这里我们用 playwright-stealth 从一开始就降低被识别的风险。
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pre-set cookie consent to skip the popup
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()正式运行时建议用无头模式(调试时可以改成 headless=False),同时把视口和用户代理设得更像真实用户,并预先写入 SOCS cookie 跳过同意弹窗——反爬部分会继续讲这个。
第 4 步:跳转到搜索结果页
加载我们构造好的 URL,并等待航班结果出现:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Wait for flight results to load
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )如果这里超时,通常说明要么同意弹窗挡住了页面(见第 3 步的 cookie 修复),要么 Google 返回了验证码页面。反爬部分会把这两种情况都说清楚。
第 5 步:加载全部航班结果
Google Flights 会把更多结果藏在“显示更多航班”按钮后面。你需要反复点击,直到所有结果都出来:
1 # Click "Show more flights" until all results are loaded
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 break这段循环会点击按钮,等 2 秒让新内容渲染,再在按钮消失后退出。按我的测试,大多数航线会有 1–3 页结果。
第 6 步:用 CSS 选择器提取航班数据
现在开始解析页面里的真实航班数据。下面这些选择器在 2026 年 4 月仍然有效(维护部分会解释为什么这个日期很重要):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Airline name
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Departure time
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Arrival time
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duration
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Stops
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Price
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2 emissions
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flights要提醒你的是,像 pIav2d、sSHqwe 和 FpEdX 这种 class 名是 Google 的 Closure Compiler 生成的,随时可能在新版本里变。相比之下,aria-label 选择器稳定得多。下面我会给你完整的维护策略。
第 7 步:把结果保存为 JSON 或 CSV
最后,保存抓取结果并附上时间戳(做价格追踪时这一步特别关键):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Also save as CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())跑完之后,你应该会得到 flights.json 和 flights.csv。按我的测试,SFO-JFK 的查询通常会返回 30–80 个航班选项,整个过程大概需要 15–20 秒。
Google Flights 反爬生存指南
大多数教程讲到这里就结束了,但大多数爬虫也正是在这里翻车。Google 在 2025 年 1 月推出了 ,几乎一夜之间干掉了绝大多数 SERP 爬虫。Google 把它描述为“投入了数万小时人工与数百万美元成本的成果”。在抓取难度上,Google Flights 被评为 。
几乎没有竞品文章会深入讲这一块,但它恰恰是大多数爬虫失效的首要原因。下面看看你会遇到什么,以及怎么应对。

请求之间加入随机延迟
这是应对限流最简单的办法。只要两行代码,效果中等:
1import time
2import random
3time.sleep(random.uniform(3, 7))把它加在页面跳转之间。固定间隔(比如每次都正好 5 秒)会很可疑——一定要随机化。
轮换 User-Agent
每次请求都发同一个 user-agent 字符串,很容易暴露。可以从列表里随机挑选:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)绕过无头浏览器检测
Google 会检查 navigator.webdriver 标志和其他自动化信号。playwright-stealth 库已经处理了大部分问题,但你也应该加上第 3 步里提到的启动参数。关键参数如下:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]这能帮你绕过最基础的检测。SearchGuard 会更进一步——监控鼠标速度、键盘输入节奏和滚动模式——但如果抓取量不大,stealth 模式配合真实延迟通常就够了。
代理轮换:数据中心代理 vs. 住宅代理
只要搜索量不是零星几次,你就需要代理。两者差别很大:
在抓取受保护网站时,住宅代理的单位成功请求成本大约比前者 。2026 年常见服务商价格:Smartproxy 起价 7 美元/GB,Bright Data 8.40 美元/GB,Oxylabs 8 美元/GB。
在 Playwright 中加入代理的方法如下:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)处理 Cookie 同意弹窗
很多用户都会把“我同意条款”弹窗当成最大障碍:“Google 一开始会先弹出‘I agree to terms and conditions’。” 最干净的办法就是像第 3 步那样提前设置 SOCS cookie。如果这样不行,就直接点掉它:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # No popup present注意:按钮文案会随地区变化——德语是 “Alle akzeptieren”,法语是 “Tout accepter”。
反爬速查表
| 技术 | 难度 | 效果 | 需要代码吗? |
|---|---|---|---|
| 随机延迟(2–7 秒) | 低 | 中 | 2 行 |
| User-Agent 轮换 | 低 | 中 | 5 行 |
| 绕过无头检测 | 中 | 高 | Playwright 启动参数 |
| playwright-stealth 插件 | 中 | 基础站点 60–80% | pip install |
| 代理轮换(数据中心) | 中 | 中 | 配置 |
| 代理轮换(住宅) | 中 | 85–95% 成功率 | 配置 |
| 预设 Cookie 同意(SOCS) | 低 | 必需 | 1 行 |
建议的安全抓取频率:配合 IP 轮换时,每次请求间隔保持 10–20 秒。Google 的阈值大致是每个 IP 每分钟 100 次请求左右,超过这个数就可能触发 429;如果单 IP 每天持续超过 1,000 次请求,也可能触发临时封禁。
为什么你的 Google Flights 选择器总是失效(以及如何修复)
这几乎是最让人头疼的问题。论坛里到处都是类似“我最后只拿到了 14 个空列表”的吐槽。每篇教程都会给你一套选择器,但很少有人解释它们为什么会坏。
为什么 Google Flights 的选择器总会变
主要有三个原因:
-
Closure Compiler 混淆。 Google 使用 和
goog.setCssNameMapping()生成像BVAVmf、YMlIz这样的 class 名。这些名称每次构建都可能变化——有时甚至每周都变。 -
A/B 测试。 不同用户会同时看到不同的 HTML 结构。你的爬虫在自己机器上能跑,不代表别人或其他地区也能跑。
-
地区差异。 欧洲用户看到的术语、布局甚至数据字段,和美国用户都可能不同。
写更稳健的选择器
优先选择和“含义”相关、而不是和“外观”相关的选择器:
1# Fragile — breaks on every build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# More resilient — tied to accessibility labels
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Also resilient — text-based matching
6more_btn = page.locator('button:has-text("Show more flights")')选择器稳定性排序(从最稳到最不稳):
aria-label属性 —— 和无障碍相关,通常最少变动data-*属性 —— 明确为功能添加role属性 —— ARIA 语义角色- 基于文本的选择器 —— 匹配可见内容
- 子串 class 匹配 —— 例如
[class*="price"] - 完整混淆 class 名 —— 尽量避免
添加校验函数
不要让坏掉的选择器悄无声息地吐出空数据。尽早发现问题:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return valid对每条抓取到的航班都跑一次。如果开始出现警告,就说明该检查页面并更新选择器了。
选择器维护策略
- 每月检查一次选择器;如果输出质量下降,就马上检查
- 把选择器单独放在配置字典里,方便修改
- 本文中的选择器最后验证时间:2026 年 4 月
- 也可以考虑 作为替代——它通过 Protobuf 解码而不是 CSS 选择器来抓取,基本绕开了这个问题(不过当 Google 修改内部数据格式时,它也会有自己的脆弱性)
从一次性抓取,升级成自动化的 Google Flights 价格追踪器
大多数教程讲到“保存成 JSON”就结束了。但这篇文章标题里写的是“价格提醒”。现在我们把它补上。
![]()
让爬虫自动定时运行
方案 1:Python schedule 库(最简单,跨平台):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)方案 2:cron 任务(Linux/Mac):
1# 每天早上 6 点和晚上 6 点运行
20 6,18 * * * cd /path/to/scraper && python scraper.py方案 3:Windows 任务计划程序——创建一个基础任务,按你设定的时间运行 python scraper.py。
代价也很明显:这些方案都需要一台一直在线的机器。如果你是在会休眠的笔记本上跑,就会漏掉抓取。
保存历史价格数据
把“覆盖写入 JSON 文件”改成“追加写入 SQLite 数据库”:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()连续一周每天抓两次之后,你就会积累到足够的数据,开始看出价格走势了。
分析价格趋势并设置提醒
从历史数据中找出最低价选项:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)当价格低于你的阈值时,触发邮件提醒:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# After each scrape, check for deals
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")建议的抓取频率:个人价格监控每天两次就够了(随机时间可以降低被识别风险)。如果用于业务监控,可以每 4–6 小时抓一次。只有在短期促销期间才建议每小时抓取,而且也只是临时使用。
更省事的方案:Thunderbit 的定时爬虫
如果你觉得维护 cron、常驻服务器和代理配置太折腾, 的定时爬虫可以在完全不需要这些基础设施的情况下,完成同样的任务。你只需要用自然语言描述抓取频率,输入 Google Flights 的网址,爬虫就会在 Thunderbit 的云端基础设施上自动运行——内置反爬处理,并且结果可以直接导出到 。它并不能完全替代 Python 方案(灵活性会少一些),但如果你的目标只是“要一个价格追踪表格”,这无疑是最快的路。你可以先在 里试试。
如果你只想要结果:无代码抓取 Google Flights 的方式
把上面这些都搭好之后,我得坦白说:这套东西确实有不少组件。不是每个人都需要这么高的控制粒度。选择器会坏,代理要轮换,cron 也得盯着。如果你的目标只是“把机票价格定期放进表格里”,其实有更快的方案。
对比:自建 Python、API 服务和 Thunderbit
| 方案 | 搭建时间 | 是否需要写代码 | 能否处理反爬 | 定时能力 | 成本 |
|---|---|---|---|---|---|
| 自己写 Playwright(本教程) | 1–2 小时 | 需要 Python(中级) | 需手动配置 | 需手动(cron) | 免费 + 代理成本 |
| SerpApi Google Flights 接口 | 15 分钟 | 只需 API 调用 | 已处理 | 通过 API | 约 $50+/月 |
| Thunderbit Chrome 扩展 | 2 分钟 | 不需要 | 云端抓取 | 内置定时 | 提供免费套餐 |
关于 SerpApi 说明一点:Google 在 2025 年 12 月对 SerpApi 提起了 DMCA 诉讼,称其请求量两年内增长了 25,000%。如果你在评估 API 供应商,这种法律不确定性值得考虑。
Thunderbit 如何抓取 Google Flights
在 Chrome 中打开你的 Google Flights 搜索结果,点击 Thunderbit 的“AI Suggest Fields”按钮——AI 会读取页面并推荐像航空公司、价格、起飞时间、中转次数这样的字段;你只要检查这些建议字段,然后点击“Scrape”。结果会出现在表格里,你可以导出到 Excel、Google Sheets、Airtable 或 Notion——而且 就能用。
如果你的用途就是做价格追踪,Thunderbit 的定时爬虫和 (可同时处理 50 个页面)可以直接替代整套 cron + 代理 + 服务器架构。
Python 给你的是完整控制和无限定制。Thunderbit 给你的是速度和零维护。按你的真实目标来选就行。如果你想了解更多无代码抓取方式,可以看看我们关于 的指南。

抓取 Google Flights 合法吗?你需要知道这些
论坛用户经常会提出这个问题:“直接抓取 Google Flights 违反了 Google 的服务条款。” 这个担心不无道理——尤其是在官方 API 已停用、又没有被批准的替代方案的情况下。
违反服务条款 vs. 承担法律责任
Google 的服务条款(2024 年 5 月 22 日更新)规定,用户不得“通过任何自动化方式(如机器人、蜘蛛程序或爬虫)访问或使用服务或其中任何内容”。违反 ToS 属于违约(民事范畴)——并不等同于违法。
一个关键的法律先例是:hiQ v. LinkedIn(第九巡回法院,2022 年)确立了抓取公开可获取数据并不违反《计算机欺诈与滥用法案》(CFAA)。不过,该案件最终以和解收场,而 Google 在 2025 年 12 月对 SerpApi 的诉讼采用了不同的法律理论——DMCA 第 1201 条(规避技术保护措施)——这可能更加严重。
负责任抓取的最佳实践
- 对请求做限速——配合 IP 轮换,每次延迟 10–20 秒
- 不要抓取个人数据——机票价格属于公开展示的聚合数据
- 不要通过程序规避验证码(这是 DMCA 风险区域)
- 将数据用于个人研究,不要在没有适当授权的情况下做成竞争性的商业产品
- 尽可能使用官方 API
替代数据源
如果你觉得抓取对当前用途来说风险太高,可以考虑一些合法的 API 选项:
| 提供商 | 价格 | 免费额度 | 说明 |
|---|---|---|---|
| SerpApi | $75–$3,750+/月 | 每月 250 次搜索 | 直接返回 Google Flights JSON(目前存在法律审查) |
| Kiwi Tequila | 免费(联盟模式) | 无限制 | 适合初创公司和测试 |
| Amadeus | 按量计费 | 2,000 次请求/月 | 400+ 航空公司,支持预订 |
| Skyscanner | 定制 | 需审批 | 52 个市场,30 种语言 |
如果你想了解完整情况,我们还写过一篇更深入的 分析。
总结与关键要点
内容很多,我们来抓重点:
- Python + Playwright 是抓取 Google Flights 最灵活的方式,但需要持续维护
- 反爬措施(延迟、User-Agent 轮换、住宅代理)不是可选项,而是可靠运行的基础,尤其是在 SearchGuard 之后
- 选择器经常失效——尽量使用
aria-label和基于文本的选择器,做数据校验,并安排维护周期 - 用
schedule或 cron 自动化,就能把一次性抓取变成真正的价格追踪器,带历史数据和邮件提醒 - 提供了无代码替代方案,内置定时、云端抓取和反爬处理——如果你的目标是价格追踪表格而不是编程项目,这会非常合适
- 遵守法律边界——控制频率,只抓公开数据,商业用途时优先考虑 API 方案
你可以直接拿走本文代码,或者安装 走快捷路线。无论哪种方式,你都能把精力放在跟踪机票价格上,而不是手动刷新 Google Flights。
如果你想了解更多 Python 抓取技巧,可以看看我们关于 和 的指南。
常见问题
1. 不用 Python 也能抓取 Google Flights 吗?
可以。像 SerpApi 和 Kiwi Tequila 这样的 API 服务,可以通过 API 调用提供结构化的航班数据(不需要浏览器自动化)。如果你想要完全无代码的方式, 可以直接在浏览器里抓取 Google Flights 结果,并提供 AI 建议字段和一键导出。
2. Google 会阻止机票抓取吗?
Google 会使用机器人检测(SearchGuard)、验证码和限流。只要做好反爬措施——随机延迟、User-Agent 轮换、住宅代理和隐身浏览器设置——中等规模的抓取通常还是能稳定跑。具体技术和阈值请参考上面的反爬章节。
3. 做价格追踪时,应该多久抓一次 Google Flights?
如果是个人使用,每天两次、时间随机就够了,而且识别风险较低。用于业务监控时,可以每 4–6 小时抓一次并配合代理轮换。除非遇到短期促销,否则不建议每小时抓取,因为这会明显提高被封的概率。
4. 有没有免费的 Google Flights API?
官方的 Google QPX Express API 已在 。目前没有免费的官方替代品。最接近的免费选项是 (联盟模式,无限搜索)。SerpApi 提供每月 250 次免费搜索。对大多数用户来说,抓取或者使用 Thunderbit 这样的无代码工具更实际。
5. 为什么我的 Google Flights CSS 选择器总是返回空数据?
Google 使用 Closure Compiler 生成会在每次构建中变化的混淆 class 名。A/B 测试和地区差异也会让不同用户看到不同的 HTML 结构。解决办法是:不要依赖 class 名,改用 aria-label 属性和基于文本的选择器,添加校验函数尽早发现问题,并每月检查一次选择器。详细策略请见选择器维护部分。
了解更多