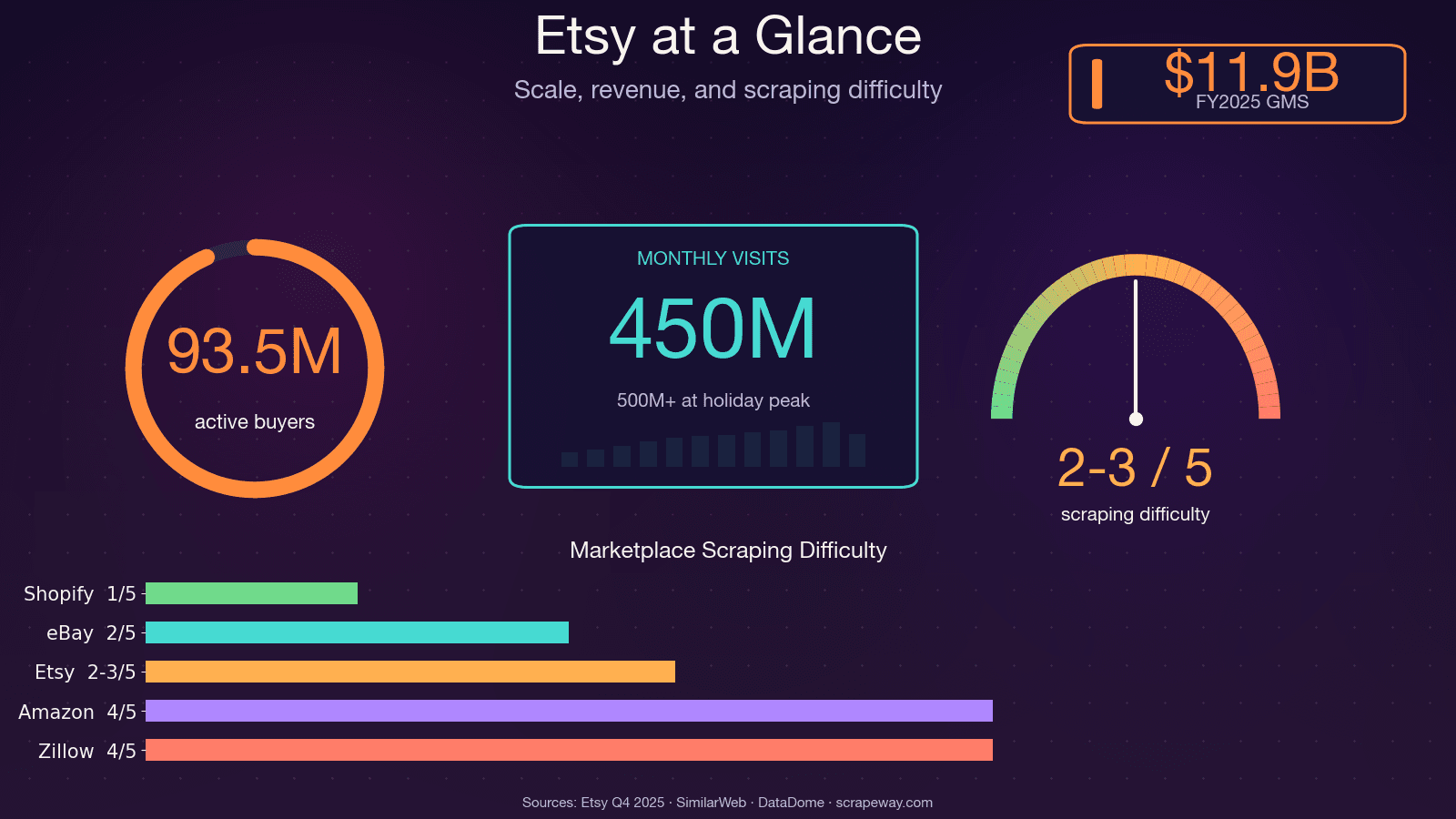
Etsy 拥有超过 1 亿个活跃商品列表、560 万卖家,以及每月大约 4.5 亿次访问。这意味着平台上有大量公开可用的数据——价格、趋势、评论和竞争对手信息;如果你曾经手动收集过这些内容,就知道那有多折磨。
我曾经花了一个周末,想为一个市场研究项目手动整理竞争对手的产品。做到第 30 个产品时,我已经开始怀疑自己做过的每一个人生选择,只因为眼前那张表格。问题在于,Etsy 数据对价格分析、产品开发、细分市场发现和卖家基准对比都非常有价值——但前提是你得真的把它规模化抓取出来。本指南就是为此而写:一篇教程,讲清楚如何用 Python 抓取 Etsy 的四种主要页面类型(搜索结果页、商品页、店铺页和评论页),同时也会坦诚介绍 Etsy 的反爬机制,以及面向不想写代码的人提供的无代码替代方案。
用 Python 抓取 Etsy 是什么意思?
简单来说,网页爬虫就是写代码去访问网页,并自动提取你关心的数据——商品名称、价格、描述、图片、评分、评论、店铺信息——再把它整理成表格或数据库这类结构化格式。
Python 是做这类工作的首选语言。它对初学者很友好,社区规模大,而且有一整套非常适合爬虫的库生态:Requests(用于获取网页)、BeautifulSoup(用于解析 HTML)、Selenium 和 Playwright(用于浏览器自动化),以及 pandas(用于整理和导出数据)。在 Stack Overflow 的年度开发者调查中,Python 一直稳居最受欢迎语言前三名,而它的爬虫库在 PyPI 上的下载量也名列前茅。
当你抓取 Etsy 时,你提取的是 Etsy 返回给浏览器的 HTML(有时还包括隐藏的 JSON)。你可以提取的数据包括:
- 商品名称、价格、描述、图片和变体
- 卖家/店铺信息(名称、销量、所在地、评分)
- 评分和完整评论文本
- 搜索结果列表、分类和趋势信号
为什么要抓取 Etsy?能带来实际回报的应用场景
抓取 Etsy 不只是一个技术练习,而是实实在在的竞争优势。无论你是卖家、产品经理还是数据分析师,手头拥有结构化的 Etsy 数据,都能直接影响你的业绩。
| 应用场景 | 你抓取什么 | 谁受益 | 业务影响 |
|---|---|---|---|
| 竞争性定价分析 | 搜索结果 + 商品价格 | 电商运营、卖家 | 动态定价平均可将收入提升 5–22% |
| 小众市场与趋势发现 | 搜索结果、热门商品 | 创始人、分析师 | 尽早发现热门细分领域(例如“preppy pajamas”的搜索增长达到 +1,112%) |
| 产品开发与优化 | 评论、商品详情 | 产品团队 | 某厨房用品品牌利用评论情绪数据,在 60 天内重新夺回 #1 畅销榜 |
| SEO 与关键词研究 | 搜索结果、商品标题/标签 | 营销团队 | 找出高需求、低竞争关键词 |
| 卖家基准对比 | 店铺页面、销量 | 销售团队、分析师 | 以每条记录 $0.01–0.10 的成本建立高质量潜在客户名单,而不是购买名单 |
| 库存与缺货监控 | 商品可用性 | 电商运营 | 更快响应竞争对手的库存变化 |
这些应用场景都需要来自不同 Etsy 页面类型的数据——这也正是本教程要覆盖全部四类页面的原因。
节省时间:手动 vs 自动化
- 手动做 Etsy 调研: 每个产品 30–45 分钟(100 个产品需要 50–75 小时)
- 自动抓取: 100 个商品列表只需 2–5 分钟
- AI 驱动的抓取速度可快 ,准确率最高可达 99.5%
Etsy API vs 网页爬虫:你该选哪个?
在你写第一行代码之前,值得先问一句:我应该用 Etsy 官方 API,还是直接抓取网站?这个问题我在论坛里经常看到,答案取决于你需要什么数据。
Etsy API 能做什么,不能做什么
Etsy 提供了带 OAuth 2.0 认证的 API v3。它适合访问你自己店铺的数据——商品列表、订单、收据——但限制也很明显:
- 竞争对手数据: API 基本只限于你自己的店铺,无法抓取其他卖家的价格、销量或商品列表。
- 评论: 没有适合批量获取完整评论文本的强力接口。
- 限流: 默认每秒 10 次请求、每天 10,000 次请求。偏移上限是 12,000 条记录。
- AI/ML 用途: 在应用审核中会被明确拒绝。
- 文档: 社区吐槽很多——示例差、接口过时、支持响应慢。
什么时候网页爬虫更合适
如果你需要竞争情报、评论情绪、跨店铺分析,或者 API 没有暴露的数据,抓取就是更好的路径。代价是:你会遇到 Etsy 的反爬防护(下面会详细说),而且需要投入一定的搭建成本。
对比表:API vs 抓取 vs 无代码
| 对比项 | Etsy 官方 API | Python 网页爬虫 | Thunderbit(无代码) |
|---|---|---|---|
| 获取商品价格 | ✅(字段有限) | ✅ 完整 HTML/JSON-LD | ✅ AI 可提取任意可见字段 |
| 评论数据 | ❌ 不支持批量获取 | ✅ 通过评论接口/HTML | ✅ 子页面抓取 |
| 竞争对手店铺数据 | ❌ 仅限自家店铺 | ✅ 任意公开店铺 | ✅ 任意公开店铺 |
| 是否需要认证 | ✅ OAuth 2.0 | ⚠️ 登录数据需要 Cookie | ⚠️ 登录需要浏览器抓取 |
| 反爬风险 | 无 | 高(DataDome) | 已处理(浏览器原生) |
| 搭建时间 | 中等(API 密钥、OAuth) | 高(代码 + 代理) | 约 2 分钟 |
如果你需要竞争对手数据、评论或跨店铺分析,API 确实覆盖不了。这就是现实情况。
写代码之前,先选好你的 Python 抓取方案
我在 Reddit 和 Stack Overflow 上经常看到一个问题:“我该用 Requests + BeautifulSoup、Selenium、代理 API,还是别的方案?”正确答案取决于你的技术水平、预算和使用场景。
| 方案 | 最适合 | 学习曲线 | 支持 JS? | 反爬处理 | 成本 |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | 想要完全掌控的开发者 | 中等 | ❌ | 手动处理(请求头、代理) | 免费 + 代理成本 |
| Selenium / Playwright | JS 较多的页面、登录流程 | 高 | ✅ | 部分支持(浏览器指纹) | 免费 + 代理成本 |
| 代理 API 服务 | 规模化 + 绕过反爬 | 中等 | ✅(通过 API) | ✅ 内置 | 每月 $49 起 |
| Thunderbit(无代码) | 非开发者、快速提取 | 很低 | ✅(浏览器原生) | ✅(浏览器会话) | 有免费额度 |
如果你想要完全控制,并且熟悉 Python,那就选 Requests + BeautifulSoup。如果需要 JS 渲染或登录流程,就用 Selenium。如果你想在规模化场景下绕过反爬,考虑代理服务。而如果你想在不编写或维护代码的情况下拿到 Etsy 数据,Thunderbit 值得一试——后面会详细说。
Etsy 如何反击:理解 DataDome 反爬防护
大多数爬虫教程都会告诉你“上代理就行”,然后就结束了。对 Etsy 来说,这远远不够。Etsy 使用的是 DataDome,这是全网最强势的反爬系统之一。 还把 Etsy 作为成功案例,指出爬虫一度占到 Etsy 计算成本的大约 1%。
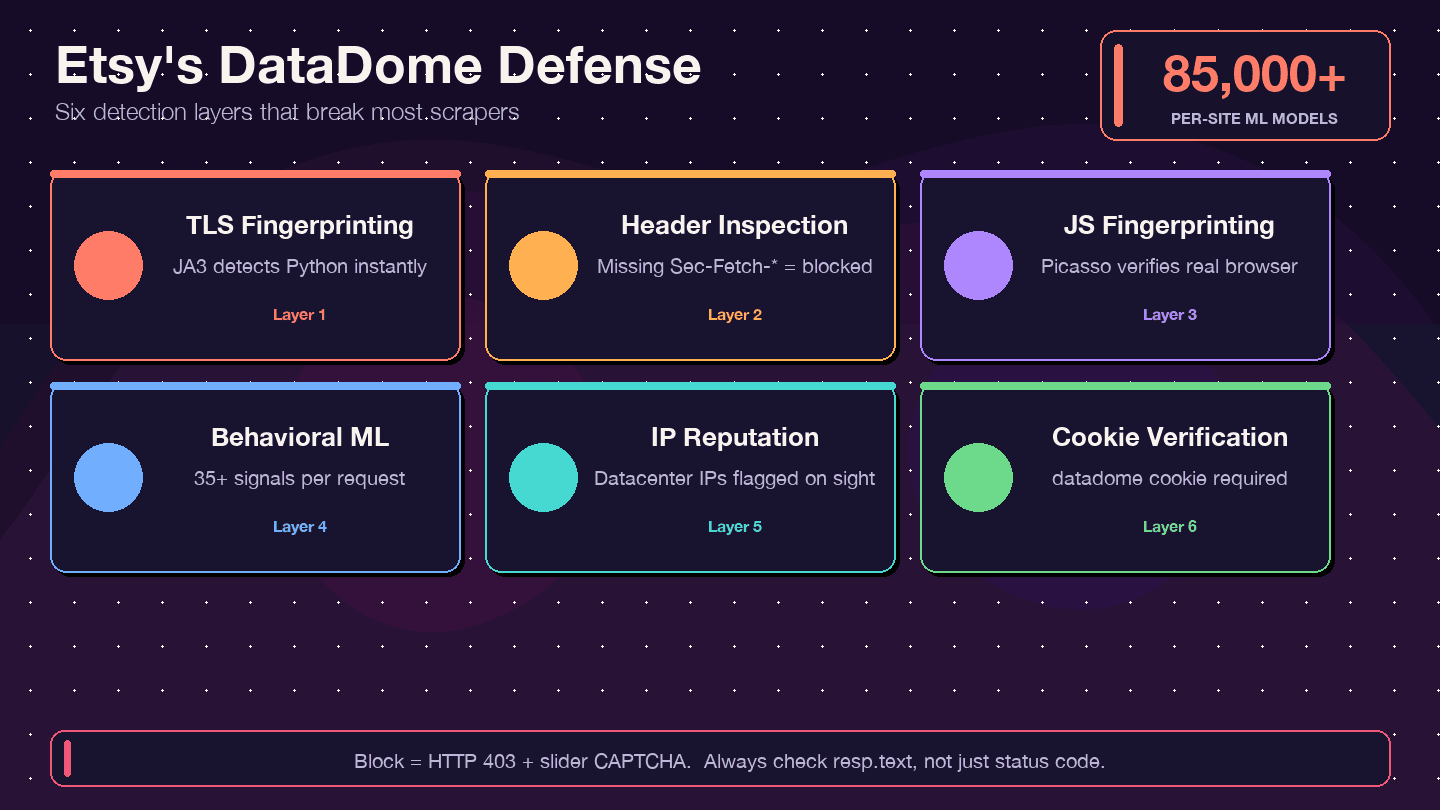
什么是 DataDome,它怎么工作?
DataDome 不只是检查你的 IP 地址,它运行的是多层检测体系:
- TLS 指纹识别(JA3): Python 的
requests库有独特的 TLS 签名,DataDome 可以立刻识别出来。 - HTTP 请求头/协议检查: 它会检查浏览器请求头是否完整且一致;缺失或顺序异常都是危险信号。
- JavaScript 指纹识别(Picasso 协议): 在浏览器里运行 JS 挑战,验证你是不是真人。
- 行为机器学习: 每个请求分析 35+ 个信号,并配有 85,000+ 个站点级模型。
- IP 信誉评分: 数据中心 IP 会被立即标记。
- Cookie 验证:
datadomeCookie 必须存在且有效。
你被拦截的迹象(以及如何检查)
最常见的坑之一是:你拿到了 200 OK 响应,但 HTML 实际上是一个验证码页面,而不是你想要的数据。其他迹象包括:
- 403 Forbidden 错误
- 重定向循环
- 响应正文里包含
ddJavaScript 对象,或者滑块验证码 HTML
一定要检查响应正文,而不仅仅是状态码。可以这样快速判断:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("被拦截了!拿到的是验证码页面,不是数据。")能降低识别率的请求头和 Cookie
你不能保证绝对不会被拦,但更真实的请求头和 Cookie 管理会大有帮助:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})另外还要注意:
- 使用
requests.Session()在请求之间保留 Cookie。 - 请求之间加入随机延迟(2–7 秒)。
- 模拟引用链: 先访问首页,再访问搜索页,最后访问商品页。
- 在规模化场景下,住宅代理轮换非常关键。数据中心 IP 几乎会立刻被标记。
这些技巧可以降低被识别的概率,但并不能彻底消除风险。对于高频抓取,你大概率还是需要代理服务或基于浏览器的方法。
配置 Python 环境,开始抓取 Etsy
开始之前:
- 难度: 中级
- 所需时间: 约 30–60 分钟(安装 + 第一次抓取)
- 你需要准备: Python 3.8+、pip、代码编辑器、Chrome 浏览器(用于 DevTools 检查)
安装依赖
创建项目文件夹,搭建虚拟环境,并安装所需库:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # 在 Windows 上:venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — 获取网页
- beautifulsoup4 — 解析 HTML
- lxml — 更快的 HTML 解析器(可选,但推荐)
- pandas — 将数据整理并导出为 CSV/Excel
如果后面你还需要浏览器自动化(用于登录或 JS 较重的页面),也安装:
1pip install selenium在写代码前先理解 Etsy 的页面结构
这里有一个非常省时间的技巧:Etsy 会在大多数页面的 <script type="application/ld+json"> 标签中嵌入结构化商品数据。这个 JSON-LD 数据已经组织好了——商品名称、价格、评分、图片——所以你不用为了每个字段都去折腾脆弱的 CSS 选择器。
打开任意 Etsy 商品页,右键选择“查看网页源代码”,然后搜索 application/ld+json。你会找到一个 @type: Product 的数据块,里面包含你需要的大部分信息。搜索结果页则是 @type: ItemList。
CSS 选择器仍然有用(比如处理 JSON-LD 中没有的数据:运费详情或评论文本),但 JSON-LD 应该是你的首选。
步骤 1:用 Python 抓取 Etsy 搜索结果
对于大多数 Etsy 抓取项目来说,搜索结果页是起点——无论你是在监控细分市场、追踪竞争对手定价,还是在构建商品数据库。
构建搜索 URL
Etsy 的搜索 URL 形式如下:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}对于多词查询,要把空格进行 URL 编码(例如 handmade+jewelry 或 handmade%20jewelry)。ref=pagination 参数会让请求更像真实浏览器导航。
其他有用的参数包括:order(most_relevant、price_asc、price_desc、date_desc)、min_price、max_price、ship_to、free_shipping=true。每一页会返回 48 个商品。
发送请求并解析 HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"第 \{page\} 页被拦截了。试试加延迟或代理。")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_products从 JSON-LD 中提取商品数据
itemListElement 数组会给出每个商品的名称、URL、图片、价格和货币单位。如果你还需要星级评分或结果数量(这些不总是在 JSON-LD 中),就退回使用 CSS 选择器:
- 商品卡片:
.v2-listing-card - 标题:
h3.v2-listing-card__title - 价格:
span.currency-value - 链接:
a.listing-link(href)
处理分页
循环遍历各页,并在每次请求之间加入随机延迟。Etsy 通常会根据查询返回 20–250 页不等。
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"抓取了 {len(results)} 个商品。")在我的测试里,抓取 5 页大约花了 20 秒;相比之下,手动复制粘贴要 30 多分钟。
步骤 2:用 Python 抓取 Etsy 商品页
一旦你从搜索结果中拿到了商品 URL,下一步就是抓取每个商品页的详细数据。
获取商品页
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return None处理价格区间
有些商品只有一个 offers.price。另一些商品(比如有尺寸或颜色变体)会使用 offers.lowPrice 和 offers.highPrice。上面的代码通过先取 price,再回退到 lowPrice 的方式兼容这两种情况。
使用 CSS 选择器解析额外字段
对于 JSON-LD 中没有的数据——运费信息、变体选项、完整卖家详情——你需要用 CSS 选择器:
- 标题:
h1[data-buy-box-listing-title] - 变体:
select[data-selector-id]或div[data-option-set] - 运费:运费区域附近的
div.wt-text-caption
权衡在于:JSON-LD 更干净,而且在页面布局变化时更稳定。CSS 选择器更脆弱,但能覆盖更多字段。
步骤 3:用 Python 抓取 Etsy 店铺页
这一部分通常是大多数竞争对手教程会直接跳过的,但它其实对销售团队和竞品分析师来说最有价值。
构建店铺 URL 并抓取页面
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # 从 HTML 中抓取店铺元数据(不在 JSON-LD 中)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # 从 JSON-LD 中抓取商品列表
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_data你能从店铺页提取什么
店铺页上的 JSON-LD 类型是 @type: ItemList——它包含商品列表,但不包含销量、所在地或评分这类店铺级元数据。对于这些字段,你需要 CSS 选择器:
| 数据点 | 选择器 | 说明 |
|---|---|---|
| 店铺名称 | h1 或 meta title | 通常在页面标题中 |
| 总销量 | div.shop-sales-reviews a | 文本类似“12,345 sales” |
| 星级评分 | input[name="initial-rating"] 的 value | 数值 1–5 |
| 所在地 | div.shop-location | 城市、国家 |
| 成为会员时间 | div.shop-info | 日期文本 |
店铺数据对于构建潜在客户名单、竞品基准对比,或者识别某个细分领域里的头部卖家,价值都非常高。
步骤 4:用 Python 抓取 Etsy 评论
评论是 Etsy 上最有价值、但也最棘手的数据之一。完整评论文本、评分和日期不会出现在初始页面 HTML 里;它们是通过内部 API 接口加载的。
方法 1:找到 Etsy 内部评论 API 接口
在 Chrome 中打开商品页,打开开发者工具(F12),切换到 Network 标签页,然后向下滚动到评论区域。你会看到一个 POST 请求,类似这样:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews这个接口会返回包含评论卡片的 HTML 片段。要使用它,你需要:
- listing_id —— 商品 URL 中的数字 ID
- shop_id —— 从商品页 HTML 中用正则提取
- csrf_nonce —— 从页面的
<meta>标签中提取
提取 ID 和 CSRF 令牌
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrf带分页抓取评论
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviews方法 2:直接从 HTML 解析评论(备用方案)
如果 API 方式失败了(例如因为 CSRF 令牌问题),你可以直接从商品页 HTML 中解析第一页评论。限制是:静态 HTML 里只有第一批评论。想抓更多,就需要 API 或 Selenium 这类浏览器自动化工具。
处理需要登录的数据:抓取你自己的 Etsy 店铺
这是一块其他教程几乎不会讲到的空白,但它是现实中的真实需求——尤其是 Etsy 卖家,他们往往想提取自己的订单、收入和店铺统计。
问题在于:只有 requests 的话,无法访问你的 Etsy 仪表盘,因为它不携带你的登录会话 Cookie。
方案 1:用 Selenium 手动登录并捕获 Cookie
使用 Selenium 打开浏览器,手动登录(或者自动登录),然后在认证状态下继续抓取:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# 在浏览器窗口里手动登录,然后:
5input("登录完成后按回车...")
6cookies = driver.get_cookies()
7# 然后可以用 driver.get() 访问你的仪表盘页面并抓取你也可以把 Selenium 会话中的 Cookie 保存下来,之后在 requests.Session() 里复用,这样在完成首次登录后,抓取会更快、更轻量。
方案 2:导出浏览器 Cookie 并交给 Requests 使用
使用浏览器扩展(例如“EditThisCookie”)导出你当前的 Etsy 会话 Cookie,然后加载到 Requests 会话中:
1import requests
2session = requests.Session()
3# 添加从浏览器导出的 Cookie
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... 按需添加其他会话 Cookie
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)更轻松的路径:Thunderbit 的浏览器抓取模式
因为 运行在你的 Chrome 浏览器中,它会自动继承你当前的 Etsy 会话。无需认证代码,也无需导出 Cookie——只要打开你的 Etsy 仪表盘,然后开始抓取即可。对于提取订单、收入、统计数据以及其他仅卖家可见的信息,这个功能真的非常实用,而且不需要任何脚本。
导出并使用你抓取到的 Etsy 数据
保存为 CSV 或 JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)最佳实践:文件名里带上时间戳,使用 UTF-8 编码,并处理商品名称中的特殊字符(Etsy 卖家很爱用表情符号和带重音的字符)。
导出到 Google Sheets、Airtable 或 Notion
对于 Python 用户来说,像 gspread(Google Sheets)或 Airtable API 这样的库都可以让你通过程序把数据推送过去。但如果你用的是 ,所有导出——到 Google Sheets、Excel、Airtable 和 Notion——都是免费的,而且只需一键完成。无需 API 密钥,也不需要 OAuth 配置。
跳过代码:如何用 Thunderbit 抓取 Etsy(无代码替代方案)
不是每个人都想写 Python 脚本、维护代理配置,或者在凌晨两点调试 CSS 选择器。如果你就是这种情况,下面教你如何用 获取 Etsy 数据。
安装 Thunderbit Chrome 扩展
前往 安装 Thunderbit。注册一个免费账号——免费版每月提供 ,而且所有导出都免费。
在任意 Etsy 页面上使用 AI 智能推荐字段
打开 Etsy 的搜索页、商品页或店铺页。然后在 Thunderbit 侧边栏点击 “AI 智能推荐字段”。AI 会扫描页面并推荐列——商品名称、价格、评分、图片、店铺名称、标签、运费信息等。你可以按需调整或新增列。
点击抓取并导出
点击 “抓取” 即可提取当前页面的数据。对于多页结果,可以使用 Thunderbit 的分页抓取功能。若要把商品 URL 列表补充为每个商品页的详细信息(描述、评论、运费),可以使用 子页面抓取——Thunderbit 会自动访问每个链接并提取额外数据。
导出到 Excel、Google Sheets、Airtable 或 Notion——全部免费。
为什么在 Etsy 抓取上 Thunderbit 比 Python 更好用
- 无需代理配置,也不用写反爬代码。 Thunderbit 运行在你真实的 Chrome 浏览器里,因此会继承你的会话,并且在 DataDome 看来就像正常用户。
- AI 会自动适应页面布局变化。 Etsy 更新前端时,不会因为选择器失效而崩掉。
- 非常适合一次性调研、竞品分析或非技术团队成员。 如果你只是需要一个快速数据集,就没必要搭 Python 环境。
- 子页面抓取 可以把商品 URL 列表丰富成包含详细数据的表格,而不用写嵌套循环。
想看实际操作,可以去看看 。
Python vs Thunderbit:6 个月成本对比
| 因素 | Python 自建 | Thunderbit |
|---|---|---|
| 搭建时间 | 8–20 小时 | 5 分钟以内 |
| 6 个月成本(含人力、代理) | $2,720–9,450 | $90–228 |
| 每月维护 | 4–10+ 小时(选择器更新 = 80%+ 开销) | 0–1 小时 |
| 反爬处理 | 住宅代理,信用成本是正常的 85 倍 | 基于浏览器,原生绕过 DataDome |
| 数据质量 | 高(但需要投入) | 高(AI 驱动) |
我不是在说 Python 是错误选择——如果你需要完全控制、自定义逻辑,或者要集成到更大的数据管道里,代码仍然是王道。但对于大多数只需要 Etsy 数据的业务用户来说,ROI 算下来无代码工具更划算。
抓取 Etsy 的法律与道德建议
每篇爬虫文章里都会有人问合法性,所以这里给你一个简短版本:
- Etsy 的服务条款明确禁止自动化访问。 不过 Etsy 主要依赖技术手段(DataDome)而不是诉讼,目前还没有已知针对爬虫的 Etsy 相关诉讼。
- 只抓取公开可用的数据。 不要绕过认证,也不要访问你不拥有的私密卖家仪表盘。
- 保持合理请求频率。 请求之间间隔 2–7 秒,不要猛轰 Etsy 服务器。
- 尊重
robots.txt。 Etsy 允许搜索页,但限制了部分路径。 - 按照 GDPR 等隐私法规妥善处理个人数据。
- 商业规模的抓取项目,建议咨询法律顾问。
更多背景可以看我们关于的文章——其中包括 Meta 诉 Bright Data(2024)案,法院确认了公开数据抓取的合法性。
总结:关键要点
这里讲了很多内容。你可以把这些要点带走:
- Etsy 的 JSON-LD 结构化数据 让大多数字段的提取,比直接解析原始 HTML 更干净。
- DataDome 是一个真正的障碍——如果你用 Python 大规模抓取,就要配合合适的请求头、延迟、Cookie 管理和住宅代理。
- Etsy API 功能有限。 如果你需要评论、竞争对手店铺或跨卖家分析,抓取才是更现实的路径。
- Thunderbit 提供了无代码替代方案,可以原生处理反爬和认证——如果你想拿到 Etsy 数据又不想维护脚本,非常值得一试。
- 始终负责任地抓取,并尊重 Etsy 的条款。
如果你想不写代码就开始,。或者直接用本教程里的 Python 代码,构建你自己的定制爬虫——愿你的选择器永远不要在周五下午崩掉。
想看更多抓取指南,可以查看我们的和合集。
常见问题
1. 用 Python 抓取 Etsy 合法吗?
抓取公开可用的数据,在最近的法律先例中通常是允许的(例如 Meta 诉 Bright Data、hiQ 诉 LinkedIn)。不过,Etsy 的服务条款禁止自动化访问,所以在抓取前一定要先查看他们的 ToS 和 robots.txt。如果是大规模或商业用途,建议咨询法律顾问。
2. 我能在不被封的情况下抓取 Etsy 吗?
Etsy 使用 DataDome,这是目前最强势的反爬系统之一。真实的请求头、请求延迟、Cookie 持久化以及住宅代理轮换,都有助于减少封禁。Thunderbit 的浏览器原生方式则能避开大部分识别,因为它是在你真实的 Chrome 会话中运行。
3. Etsy 有 API 可以替代抓取吗?
有,Etsy 提供了 API v3,但它基本只限于你自己的店铺数据,而且没有强力的评论访问能力。大多数竞争情报和跨店铺分析场景,还是需要抓取。
4. 抓取 Etsy 需要哪些 Python 库?
至少需要:requests、beautifulsoup4、pandas(用于导出)和 json(内置)。如果是 JS 较多或需要登录的页面,再加上 selenium。想更快解析 HTML,可以用 lxml。
5. 我该如何专门抓取 Etsy 评论?
Etsy 评论是通过内部 API 接口(/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews)加载的。你需要先从商品页提取 listing ID、shop ID 和 CSRF token,然后带分页向该接口发送 POST 请求。作为备用方案,你也可以直接从商品页 HTML 中解析第一批评论——这两种方式在本教程里都已经一步一步讲解。
延伸阅读