大多数 eBay 抓取教程的“保质期”大概只有三个月。我之所以这么说,是因为 Thunderbit 团队亲眼看着开发者不断踩坑:失效的代码片段、过时的 CSS 选择器,以及那些看起来“能用”的 GitHub 仓库,结果在 eBay 两次改版之后就悄悄失灵了。
eBay 目前大约有 ——这也意味着,它是仅次于 Amazon 的、开放网络上最大的长尾定价数据集。无论是转售定价、竞品分析,还是市场情报,这些数据都很有价值。但要用程序拿到这些数据并不轻松:eBay 基于 React 的前端会频繁更换 CSS 类名,A/B 测试会给不同用户展示不同的 DOM 结构,而 Akamai Bot Manager 还会挡在你和 HTML 之间。本文会给你一套今天还能用的 Python 代码,讲清楚 为什么 爬虫会失效,帮助你搭建更稳健的方案,客观比较 eBay API 和网页抓取的取舍,并在 Python 不值得折腾时,给你一个无需编码的替代方案。
用 Python 抓取 eBay 到底是什么意思?
用 Python 抓取 eBay,指的是编写脚本自动下载 eBay 网页,解析 HTML(或隐藏的 JSON),并把标题、价格、卖家信息、售出日期、变体信息等结构化数据提取出来,整理成你真正能用的格式,比如 CSV、表格或数据库。
你可以抓取几类 eBay 页面:
- 搜索结果页(例如所有 “AirPods Pro” 商品)
- 单个商品详情页(完整规格、图片、卖家信息)
- 已售出 / 已完成商品页(实际成交价格和日期)
- 卖家资料页和评价页
Python 是这类工作的首选语言。它的生态非常成熟——Requests、BeautifulSoup、lxml、pandas——都能帮你轻松请求页面、解析 HTML、整理数据。不过,直接抓网页 HTML 和使用 eBay 官方 API 之间有本质区别,这一点我会在后面展开说明。
为什么要抓 eBay?业务团队的真实使用场景
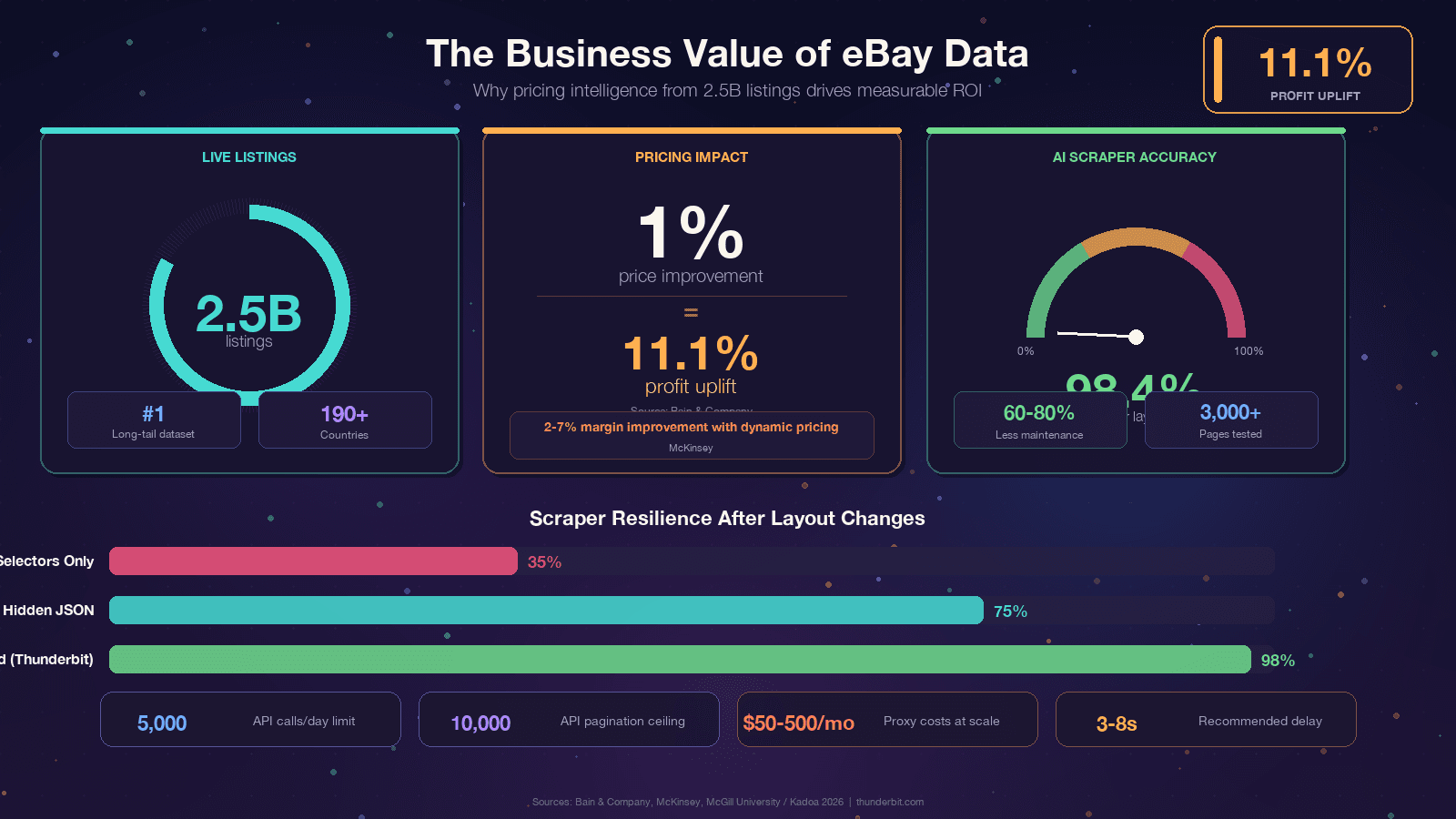
如果你在看这篇文章,大概率已经有自己的需求了。不过,我们还是把讨论放回到实际商业价值上,因为 eBay 数据的 ROI 确实很可观。Bain 研究发现,在成千上万家企业中,实际成交价格只提升 1% 就能带来 11.1% 的利润增长。McKinsey 也指出,零售业的动态定价可带来最高 5% 的销售提升,以及 2%–7% 的毛利改善。
最常见的使用场景包括:
| 使用场景 | 所需数据 | 业务收益 |
|---|---|---|
| 价格监控与重定价 | 在售价格、运费、成色 | 保持价格竞争力,守住利润空间 |
| 竞品分析 | 商品组合、促销、运费政策 | 制定更好的定位策略,发现品类缺口 |
| 市场研究与趋势洞察 | 上新速度、品类趋势、需求变化 | 发现新产品,预测市场需求 |
| 转售定价 / 估值 | 成交价、成交日期、成色 | 评估合理市价,辅助买入决策 |
| 情绪分析 | 评价、评分、退货政策 | 洞察产品质量和客户满意度 |
| 线索挖掘 | 卖家资料、店铺信息、联系方式 | 定向触达高 GMV 卖家 |
共同点很简单:eBay 有这些数据,但它们被锁在网页里。
抓取,就是把这些数据变成竞争优势的过程。
eBay 官方 API vs. Python 网页抓取:该怎么选?
这是我希望更多教程能认真回答的问题。eBay 提供官方 API——主要是 ——很多人会纠结到底该用 API 还是直接抓网页。答案完全取决于你需要什么数据。
| 对比项 | eBay Browse/Finding API | Python 网页抓取 |
|---|---|---|
| 已售出 / 已完成商品 | 有限——有 Marketplace Insights API,但 权限通常拿不到 | 可通过 LH_Sold=1&LH_Complete=1 URL 参数完整获取 |
| 频率限制 | 基础层级每天 5,000 次调用 | 自己控制(取决于代理) |
| 数据字段 | 预定义字段(标题、价格、类目、卖家基础信息) | 页面上看得到的都能抓(评价、完整规格、变体矩阵) |
| 上手复杂度 | OAuth 2.0、应用注册、API 密钥 | pip install + 代码即可 |
| 稳定性 | 接口稳定 | 页面 HTML 一变就可能失效 |
| 成本 | 有免费层,按量付费 | 代码免费,但大规模时代理有成本 |
| 变体 / MSKU 数据 | 部分可见——很多情况下只能拿到父 SKU | 可完整获取(通过解析隐藏 JSON) |
| 分页深度 | 10,000 条的硬上限 | 理论上无限 |
顺带一提:旧的 Finding API(包含 findCompletedItems)已经在 。如果你还在用 ebaysdk-python 或任何调用 Finding 模块的库,它现在在生产环境里已经不可用了。
我的建议: 对于稳定、适中频率、结构化的在售商品查询,优先用 Browse API。需要成交价、评价、变体数据,或者 API 不开放的字段时,再用 Python 抓取。很多团队会两者结合使用。
用 Python 抓 eBay 需要哪些工具和库?
在写代码之前,先把工具准备好。对大多数 eBay 页面来说,你并不需要无头浏览器——数据通常已经嵌在服务端渲染的 HTML 里了。
| 库 | 用途 |
|---|---|
requests 或 httpx | 下载 eBay 页面用的 HTTP 客户端 |
curl_cffi | 带真实浏览器 TLS 指纹的 HTTP 客户端(绕过 Akamai 的关键) |
beautifulsoup4 | 用 CSS 选择器提取 HTML 的解析器 |
lxml | BeautifulSoup 的高速解析后端 |
jmespath | 解析嵌套 JSON 的查询语言 |
pandas | 数据处理、导出 CSV/Excel |
gspread | 对接 Google Sheets |
一行命令安装全部依赖:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread建议使用 Python 3.11+——pandas 3.0 需要 3.10 及以上,而 3.11 在 I/O 密集型任务上通常能带来 10%–60% 的性能提升。
其中有一个库特别值得强调:curl_cffi。对 2026 年的 eBay 爬虫来说,它可能是最值得升级的一项。eBay 使用 ,而 Akamai 的主要识别方式之一就是 TLS 指纹。普通 requests 发出的 JA3 指纹很容易被识别成 Python 请求。curl_cffi 可以模拟真实 Chrome 浏览器的 TLS 握手,大约能绕过 90% 受 Akamai 保护的目标,而无需无头浏览器。
分步教程:如何用 Python 抓取 eBay 搜索结果
下面进入核心教程。我们会抓取 eBay 搜索结果页上的商品列表。
- 难度: 初级到中级
- 预计时间: 第一次跑通大约 30 分钟
- 你需要: Python 3.11+、上面的库、一个终端,以及目标 eBay 搜索 URL
第 1 步:搭建 Python 项目
创建项目目录并安装依赖:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandas新建一个名为 scrape_ebay.py 的文件,这就是你的工作区。
第 2 步:构建 eBay 搜索 URL
eBay 的搜索 URL 结构很直接,关键参数是 _nkw(关键词):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # 每页数量:60、120 或 240(240 可能触发风控)
7 "_pgn": "1", # 页码
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1其他常用参数:
LH_BIN=1—— 仅显示一口价商品_sacat=175673—— 指定类目_sop=12—— 按最佳匹配排序(10 = 价格+运费最低,13 = 最新上架)LH_Complete=1&LH_Sold=1—— 已售出 / 已完成商品(下文专门讲)
第 3 步:发送请求并处理响应
这一步就体现出 curl_cffi 的价值了。直接用 requests.get() 往往会被 Akamai 返回 403。换成 curl_cffi 后,我们就能伪装成真实 Chrome 浏览器:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" 状态码 {r.status_code},{sleep_for:.1f} 秒后重试...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" 请求出错:{e},准备重试...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"重试 {max_retries} 次后仍失败:{url}")指数退避加随机抖动非常重要——固定间隔本身就很像机器人行为。
第 4 步:解析搜索结果页中的商品列表
eBay 目前正在两个搜索结果布局之间过渡。一个稳健的爬虫必须同时兼容两种结构:
| 字段 | 旧版布局 | 新版布局 |
|---|---|---|
| 卡片容器 | li.s-item | li.s-card 或 div.su-card-container |
| 标题 | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| 价格 | span.s-item__price | .s-card__price |
兼容两种布局的解析代码如下:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # 标题——同时尝试两种布局
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # 跳过那个“Shop on eBay”的占位卡片
11 if not title or "Shop on eBay" in title:
12 continue
13 # 价格
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # 图片
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # 运费
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return results那个“第一张卡片是幽灵占位”的坑非常经典。很多 eBay 搜索页里的第一个 li.s-item 实际上是隐藏的占位卡片,标题是 “Shop on eBay”,没有真实价格。一定要过滤掉。
第 5 步:处理分页,抓取多页结果
eBay 通过 _pgn 参数分页。下一页链接使用 a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"正在抓取第 {page_num} 页:{url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" 第 {page_num} 页没有结果,停止抓取。")
12 break
13 all_results.extend(results)
14 print(f" 找到 {len(results)} 条商品(总计:{len(all_results)})")
15 # 礼貌性延迟——3 到 8 秒随机等待
16 time.sleep(random.uniform(3, 8))
17 return all_results3 到 8 秒的随机等待不是可选项。
eBay 的 Akamai 层会识别同一 IP 持续超过 1 req/s 的请求模式。
第 6 步:把抓取的数据导出到 CSV 或 JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"已将 {len(df)} 条商品导出为 CSV 和 JSON。")现在你应该已经拿到一份干净的 eBay 商品表格了。在我的机器上,抓取 3 页(360 条商品)连同延迟大约花了 45 秒。
如何用 Python 抓取 eBay 商品详情页
搜索结果只能看到摘要;商品详情页才有真正有价值的信息:完整描述、卖家反馈评分、商品细节、图片轮播以及变体数据。
解析单个商品详情页
eBay 商品页地址通常是 /itm/<ITEM_ID>。最稳定的提取方式是 JSON-LD——eBay 会嵌入一个 Product schema 结构块,这种数据几乎不受 CSS 改版影响:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD —— 最稳定的提取路径
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. JSON-LD 中没有的字段,再用 CSS 选择器兜底
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. 商品细节
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return item这里的核心思路——先抓 JSON-LD,再用 CSS 兜底——是构建不容易坏掉的爬虫的关键。下文我会进一步说明。
抓取 eBay 商品变体(MSKU 数据)
有些 eBay 商品会有多个变体——不同颜色、尺寸、存储容量等。页面可见 DOM 可能只显示一个价格区间,比如 “$899 到 $1,099”,直到用户点击某个选项。每个变体的真实价格其实藏在一个叫 MSKU 的隐藏 JavaScript 对象里。
这也是 eBay API 只提供部分数据(父 SKU)的地方,因此抓取往往是更好的选择。
1import re, json
2def extract_variants(html):
3 # 非贪婪匹配很关键——贪婪的 .+ 会把整页都吞掉
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skus这里正则里的非贪婪 (.+?) 是很多 eBay 爬虫最容易翻车的地方。贪婪的 .+ 会一直吞到页面里最后一个 "QUANTITY",导致 JSON 解析失败。我至少见过三篇“可用教程”都栽在这个 bug 上。
如何用 Python 抓取 eBay 已售出和已完成商品
这正是抓取比 API 更有价值的场景。已售商品数据——实际成交了什么、成交价多少、成交时间是什么时候——是市场研究、转售定价和估值的黄金标准。eBay Browse API 明确不提供这类数据。理论上, 可以提供,但它属于“有限开放”,而且 。
你需要的 URL 参数是 LH_Complete=1(已完成列表)和 LH_Sold=1(仅显示实际售出)。这两个参数必须同时传。 只传 LH_Sold=1 时,在某些类目里会悄悄回退到在售列表——这是社区里最常见的坑。
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"正在抓取已售出第 {page_num} 页...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # 只保留真正售出的商品(绿色 POSITIVE 价格)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # 未售出的已完成列表——跳过
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # 解析售出日期
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldHTML 里的关键区别在于:已售商品的价格会显示为绿色,并包在 .POSITIVE 容器里;而未售出的已完成商品则通常是红色删除线。一定要用 .POSITIVE 这个类来过滤。
为什么 eBay 爬虫会失效,以及如何构建更稳健的方案
如果你的 eBay 爬虫坏了,你并不孤单。我读过的每一篇 eBay 抓取论坛帖子,最核心的痛点都是这个。问题不是“会不会坏”,而是“什么时候坏”。
为什么会这样:
- eBay 使用基于 React 的渲染,部署时会生成变化的类名
- A/B 测试会给不同用户展示不同 DOM 结构(现在
s-item/s-card双布局就是现成例子) - 定期改版会改变 HTML 嵌套层级,即使数据本身没变
- 很多老教程里还在用
#itemTitle和#prcIsum这种早已移除的选择器
正如 所说:"eBay 网页抓取真正的挑战,在于处理 eBay 的 CSS 选择器变化。eBay 会定期更新前端,依赖特定类名的爬虫因此会失效。"
让 eBay 爬虫更耐用的防护策略
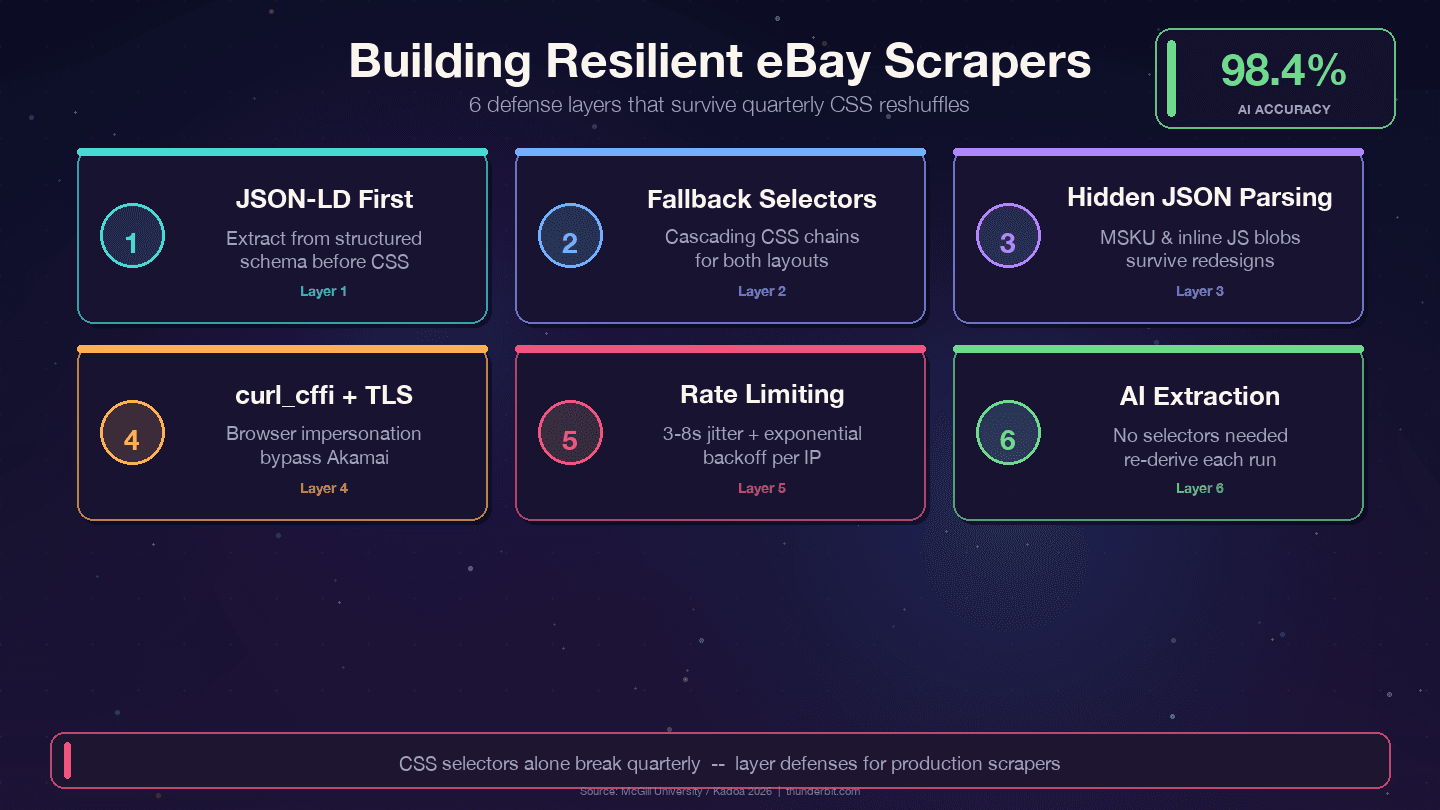
下面这四个策略,能帮助你扛住 eBay 的季度级改版:
1. 优先使用 JSON-LD,而不是 CSS 选择器。 eBay 会在商品页里嵌入结构化的 Product schema 数据。数据层比展示层稳定得多——设计师每季度都可能改 CSS 类名,但 price、name、seller 这类后端字段往往和内部 API 绑定,不太会改名。
2. 使用多层兜底选择器。 不要只依赖一个 CSS 选择器,要提供多个备选:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. 解析隐藏 JSON 数据块。 MSKU 变体对象和内联 JavaScript 数据不会因为 CSS 改版而消失,因为它们是服务端生成的。虽然从 <script> 标签里用正则提取更费工夫,但维护成本会低很多。
4. 记录选择器失败情况。 加上监控,这样你就能知道“什么时候”某个选择器失效,而不是只看到输出数据变空:
1if title is None:
2 print(f"WARNING: title selector failed for {url}")5. 使用带浏览器伪装的 curl_cffi。 它可以在不使用无头浏览器的前提下,处理 Akamai 的 TLS 指纹检测。
AI 驱动的替代方案:不用再维护选择器
如果你已经厌倦了每隔几个月就要修一遍选择器,那么其实有一种根本不同的思路。像 这样的工具,会用 AI 每次重新读取页面,并动态生成提取逻辑。McGill University 的一项研究对 3,000 个页面进行了 AI 与基于选择器的爬虫对比,结果发现:;行业基准也指出,维护工作可减少 。
| 方案 | eBay 改 HTML 后会坏吗? | 维护成本 |
|---|---|---|
| 硬编码 CSS 选择器 | 会,通常每季度都可能坏 | 高——需要持续修补 |
| 隐藏 JSON / JSON-LD 提取 | 很少 | 低 |
| 基于 AI 的抓取(Thunderbit) | 不会——每次运行都会重新推导选择器 | 几乎没有 |
后面我会详细介绍 Thunderbit 的工作流。先记住这一点:如果你要构建一个准备运行几个月的爬虫,应该优先采用 JSON 优先的提取策略和多层兜底选择器;如果你完全不想维护选择器,AI 方案非常值得一试。
如何自动化定期抓取 eBay,用于价格监控
一次性抓取当然有用,但价格监控、库存追踪和竞品分析需要的是持续采集。我读过的几乎所有竞品文章都会提到价格监控这个场景,但很少有人真的讲清楚怎么自动化。
方案 1:Cron 任务(Linux/macOS)或任务计划程序(Windows)
这是最简单的方式。把 Python 脚本包进 cron 任务里。一定要使用你虚拟环境里 Python 的绝对路径,因为 cron 运行时环境非常简洁:
1crontab -e
2# 每天 08:15 运行
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1在 Windows 上,可以用 PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T这种方式需要一台始终在线的机器,而且代理和反爬措施都得你自己管理。
方案 2:云函数(Serverless)
AWS Lambda 或 Google Cloud Functions 可以让你不用专门维护服务器也能跑爬虫。缺点是配置复杂一些——你要打包依赖、处理超时(Lambda 上限 15 分钟),而且代理依然要自己管理。不过,至少不用维护服务器本身。
方案 3:使用 Thunderbit 做无代码定时调度
的 Scheduled Scraper 功能允许你用自然语言描述抓取频率(例如“每天早上 8 点”),输入 eBay URL,然后点击 Schedule 即可。它在云端运行,并内置反爬处理。
| 方案 | 搭建难度 | 需要服务器吗? | 能处理反爬吗? |
|---|---|---|---|
| Cron + Python 脚本 | 中等 | 需要(始终在线的机器) | 代理需要自己管理 |
| 云函数(Lambda) | 高 | 不需要(无服务器) | 代理需要自己管理 |
| Thunderbit Scheduled Scraper | 低(用自然语言描述) | 不需要(云端) | 内置 |
如果你要存储周期性抓取的数据,针对价格历史,最合适的做法是本地 SQLite 数据库。使用 ON CONFLICT ... DO UPDATE,不要用 INSERT OR REPLACE,因为后者会 :
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);不想写代码?2 分钟用 Thunderbit 抓取 eBay
上面我花了两千多字讲 Python 代码。现在我想诚实地说:什么时候你其实根本不需要这些代码。
如果你是做一次性市场调研的业务人员、在比价的转售商,或者电商团队今天就急需数据、来不及走开发流程,那么 Python 其实有点大材小用。环境配置、选择器维护、代理管理——为了“我只是想把这 200 条商品放进表格里”,这些开销实在太高了。
Thunderbit 是怎么抓 eBay 的?(分步说明)
- 安装 —— 不需要信用卡。
- 在 Chrome 里打开任意 eBay 搜索结果页或商品页。
- 点击 Thunderbit 侧边栏里的 “AI Suggest Fields”。 AI 会自动读取页面并推荐列:Title、Price、Condition、Shipping、Seller、Rating。
- 点击 “Scrape”。 扩展会自动翻页并填充数据表。针对 eBay,Thunderbit 还提供了 ,一键即可使用。
- 导出 到 Google Sheets、Airtable、Notion、CSV、JSON 或 Excel——全部免费。
整个过程不到 2 分钟。
我真的计时过。
子页面补全:无需额外代码获取详情页数据
在抓取搜索结果页之后,Thunderbit 还能自动进入每条商品的详情页,继续补充更多字段——完整规格、卖家信息、描述、所有图片。这样就把我们前面写的 20 多行 Python 子页面抓取代码,压缩成了一次点击。
什么时候还是应该用 Python
Python 更适合这些场景:
- 大规模抓取(每次运行数万页面)
- 高度定制的解析逻辑 或数据转换
- 接入已有的数据管道(Airflow、dbt、Kafka)
- 更细粒度的 TLS / 会话控制,用于高级反爬处理
- 单位经济性——当数据量达到百万级时,自建维护栈通常比按额度收费的 SaaS 更划算
对于大多数一次性或中等规模项目,Thunderbit 更快也更省事;对于大规模生产级流水线,Python 给你的控制力更强。
用 Python 抓 eBay 时,如何尽量避免被封
eBay 的 Akamai 防护是真实存在的。实践中真正有用的方法如下:
- 使用
curl_cffi并设置impersonate="chrome124"—— 这是相较于普通requests最大的提升 - 轮换 User-Agent 字符串,使用当前浏览器版本列表(Chrome 143、Firefox 124、Safari 26)
- 在每次请求之间加入随机延迟, 比较合适——固定间隔本身就是特征
- 使用住宅代理或轮换代理,只要抓取量超过几十页就很有必要。数据中心 IP(AWS、GCP、DigitalOcean)很容易被 Akamai 标记
- 尊重
robots.txt——大多数带筛选条件的浏览页都明确禁止抓取;商品详情页(/itm/<id>)通常没有 - 优雅处理验证码——检测到后切换 IP 重试,或者使用验证码识别服务
- 不要猛刷服务器。 这个先例说明,如果抓取真的导致服务器性能下降,trespass to chattels 可能适用。把单 IP 频率控制在 1 req/s 左右,远离这个风险区。
如果是高频商业用途,建议对在售商品优先使用 Browse API,只对已售比价和 API 不提供的数据做定向抓取。技术和法律层面,这种混合方案都更稳妥。
用 Python 抓 eBay 合法吗?
我不是律师,本文也不构成法律建议。所以我简单说明一下。
当前法律环境整体更支持抓取公开可访问的数据。几个关键判例:
- (第九巡回法院,2022):抓取公开可访问的数据不违反 CFAA
- Van Buren v. United States(美国最高法院,2021):收窄了 CFAA 中“超越授权访问”的适用范围
- (加州北区联邦法院,2024):在未登录状态下抓取不构成平台条款违约,因为爬虫不是“用户”
不过,eBay 在 中明确禁止“代买代理、LLM 驱动机器人,或任何试图在没有人工审核下完成下单的端到端流程”。界限很清楚:只读抓取公开页面通常问题不大;自动化结账则不行。
最佳实践是:只抓公开可见的数据;不要注册虚假账号,也不要绕过登录墙;不要批量再分发受版权保护的商品图片;商业级项目务必咨询法律顾问。
结论与核心要点
Python 是抓取 eBay 最灵活的方式,但随着网站 HTML 变化,你需要持续维护。决策框架可以这样记:
- 使用 eBay Browse API:适合稳定、适中频率、结构化的在售商品查询
- 使用 Python 抓取:适合已售商品、评价、变体数据,以及 API 不开放的字段
- 使用 :如果你想要 eBay 数据,但不想写代码或维护代码
本文给出的代码优先考虑了稳定性:先抓 JSON-LD,再用多层 CSS 兜底,变体信息则通过隐藏 JSON 解析。这种分层方案能让你的爬虫不至于在 eBay 前端团队下一次改版时立刻失效。
如果你想先试试无代码方案, 现在就可以在 eBay 页面上测试。想看看 是怎么工作的,也只差一步。
想了解更多网页抓取工具,可以继续阅读我们的指南:、、以及 。你也可以在 上观看教程。
常见问题
1. 可以免费用 Python 抓取 eBay 吗?
可以。所有库(Requests、BeautifulSoup、curl_cffi、pandas)都是免费且开源的。真正的成本出现在规模化时——高频抓取通常需要住宅代理,费用一般在每月 50–500 美元之间,取决于带宽。对于小项目(几百页以内),只要做好限速,直接用家用 IP 也能跑。
2. 如何用 Python 抓取 eBay 已售和已完成商品?
在搜索 URL 参数里加入 LH_Complete=1&LH_Sold=1。这两个参数必须同时使用——只传 LH_Sold=1 时,在某些类目里会悄悄回退到在售商品。筛选结果时,检查价格元素上是否有 .POSITIVE CSS 类,它表示真实成交,而不是未售出的过期列表。
3. eBay 会屏蔽网页抓取吗?
eBay 使用 Akamai Bot Manager,主要通过 TLS 指纹和行为分析识别爬虫。普通 requests 请求经常会收到 403。使用 curl_cffi 做浏览器伪装、轮换 User-Agent、并在请求之间加入 3–8 秒随机延迟,通常可以解决大部分封禁问题。规模化时,住宅代理也很有帮助。
4. 我应该用 eBay API 还是网页抓取?
对于稳定、适中频率的在售商品查询(每天最多 5,000 次调用),优先用 Browse API。需要成交价历史、完整变体 / MSKU 数据、评价,或者 API 不提供的字段时,再用抓取。理论上 Marketplace Insights API 能提供已售数据,但权限受限,而且 。
5. 不写代码,抓 eBay 最简单的方法是什么?
会用 AI 读取 eBay 页面、自动推荐数据列,并一键提取商品列表。它支持自动翻页、子页面补全,还能导出到 Google Sheets、Excel、Airtable 或 Notion。预置的 让常见场景更快上手。
了解更多