执行摘要
提出的是一个政策问题:全球访问量最高的网站里,有多少正在告诉 AI 爬虫哪些能做、哪些不能做?
这篇后续报告追问的是它背后的运营问题:在如今被拿来承载这些政策的基础设施里,robots.txt 到底有多可靠?
答案并不乐观。robots.txt 之所以还能工作,是因为它公开、成本低、机器可读,而且爬虫早就认识它。但它现在被要求承担的职责,远远超出了最初设计。到了 2026 年,同一个纯文本文件里可能同时包含 SEO 爬取控制、站点地图索引、遗留搜索引擎扩展、AI 训练退出声明、Cloudflare 注入的政策词汇、版权保留条款,以及面向未来争议的法律措辞。
这就是配置债务。
本报告背后的数据集,仍然是最初 AI 爬虫研究中使用的 Tranco Top 10,000 抓取结果。在这 10,000 个域名中,有 6,638 个返回了可读取的 robots.txt;另有 610 个返回 404,按协议视为默认允许。这使我们获得了 7,248 个可分析站点用于机器人访问决策分析,以及 6,638 份具体文件用于配置复杂度分析。
有六个发现尤为突出:
-
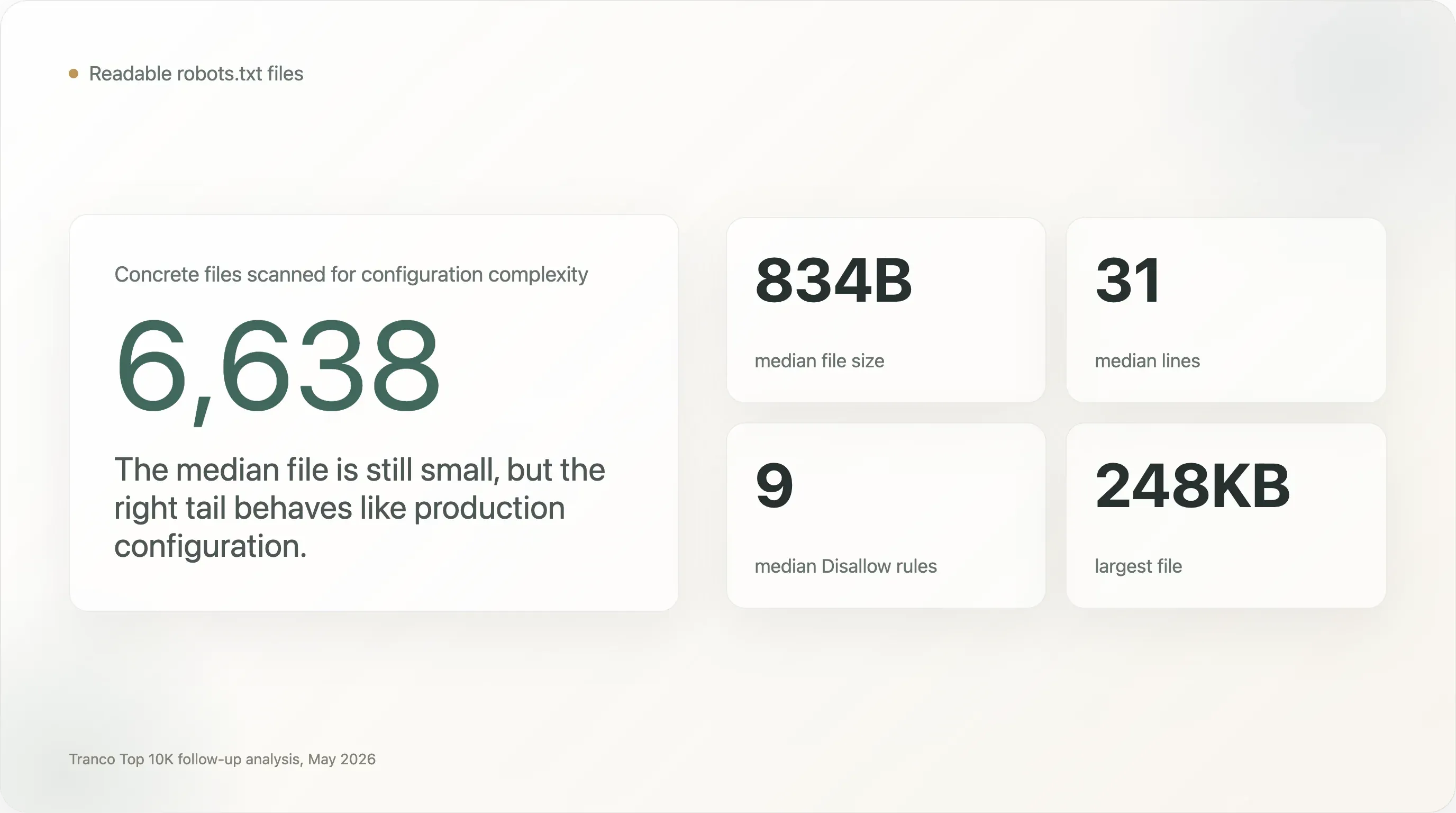
大多数
robots.txt文件都很小,但长尾极其复杂。 中位数文件只有 834 字节、31 行。但有 1,005 份文件至少 5 KB,273 份至少 20 KB,28 份至少 100 KB。样本中最大的文件达到 248 KB。 -
数百个头部网站运行的文件,已经更像生产配置而不是政策说明。 中位数文件只有 9 条
Disallow指令。但有 707 个站点至少有 100 条Disallow规则,13 个站点至少有 1,000 条,240 个站点列出了至少 50 个 user-agent,110 个站点列出了至少 100 个 user-agent。 -
协议漂移不是理论问题。 在 6,638 份可读取文件中,685 份包含
Crawl-delay,303 份包含Host,200 份包含Clean-param,9 份包含Request-rate,5 份包含Visit-time,271 份包含 Cloudflare 风格的Content-Signal语言。这些并不都属于同一个干净的标准,而是日积月累的爬虫民间约定。 -
Googlebot 被当成了特殊公民。 562 个可分析域名至少封锁了一个传统搜索爬虫。在这其中的 404 个案例里,Googlebot 被允许,而至少另一个搜索爬虫被封锁。AI 爬虫歧视并不是出现在一个中立生态里;
robots.txt早就编码了搜索引擎的层级关系。 -
AI 政策让这笔债务更加显眼。 1,377 份可读取文件包含 AI 政策语言;719 份包含版权、条款、许可或权限语言;501 份两者兼有。这个文件既成了机器接口,也成了法律文书。它很有用,但也很脆弱。
-
最风险最高的文件,不一定是最反 AI 的文件。 电子商务、旅行、社交、金融、学术和新闻站点,都会因为不同原因生成复杂文件:爬取预算控制、遗留路径、用户生成内容、权利保留,以及针对特定 bot 的例外。AI 规则只是叠加在一个本来就很混乱的基础之上。
核心结论是:robots.txt 仍然是开放网络上最重要的爬虫政策入口,但除非整个生态标准化爬虫身份、AI 使用词汇和政策可审计性,否则它并不是高风险 AI 治理的坚实基础。
方法论
本报告沿用了 Thunderbit 最初关于 Tranco Top 10,000 域名 AI 爬虫政策分析的数据集。
输入材料包括:
tranco_top10k.csv— 原始的 Tranco Top 10K 域名列表。out/fetch_meta.csv— 抓取状态、字节数、协议、重定向结果和错误元数据。out/sites.csv— 域名、排名、分类、语言和robots.txt状态。out/site_meta.csv— 每个站点一行分析数据,包括模板类型、AI 封锁标记、文件大小和机器人政策摘要字段。out/bot_status.csv— 每个域名与爬虫一行,包括该 bot 是否被封锁以及是否存在特定规则。raw_robots/— 6,638 个返回状态200的站点所缓存的robots.txt正文。
在这篇后续报告中,我们对每个可读的 robots.txt 文件扫描了以下内容:
- 文件大小和行数;
- 活跃的非注释行;
User-agent、Disallow、Allow和Sitemap指令数量;Crawl-delay、Host、Clean-param、Request-rate和Visit-time等遗留或非核心指令;- 包括
Content-Signal、llms.txt、AI、LLM、机器学习、TDM 和2019/790在内的 AI 时代词汇; - 包括版权、服务条款、许可、权限保留和权利保留措辞在内的法律词汇;
- 对 Googlebot、Bingbot、DuckDuckBot、Slurp、Baiduspider 和 YandexBot 的搜索爬虫处理方式。
报告还定义了一个简单的配置债务分数用于优先级排序。它综合了文件大小、user-agent 数量、Disallow 数量、Allow 数量、非标准指令数量,以及 AI 政策和法律语言的混合程度。这个分数并不是通用的正确性衡量标准,而是用来识别那些更难维护、审核或推理的文件。
所有派生表格和图表都包含在交付文件夹中。
发现 1:中位数文件很简单;尾部并不简单
头部网络中典型的 robots.txt 文件仍然很小。
在 6,638 份可读取文件中:
| 指标 | 中位数 | P90 | P95 | P99 | 最大值 |
|---|---|---|---|---|---|
| 文件大小 | 834 字节 | 6.7 KB | 15.8 KB | 76.0 KB | 248.3 KB |
| 行数 | 31 | 238 | 332 | 1,008 | 4,998 |
| 活跃行数 | 23 | 198 | 282 | 837 | 4,998 |
User-agent 指令 | 1 | 21 | 39 | 137 | 823 |
Disallow 指令 | 9 | 103 | 176 | 422 | 4,997 |
Allow 指令 | 1 | 17 | 33 | 69 | 890 |
这个分布很重要,因为人们常把 robots.txt 想象成一个很小的声明:
1User-agent: *
2Disallow: /private/但对于高流量网络中的一部分网站来说,这种想法并不成立。
在这份数据集中:
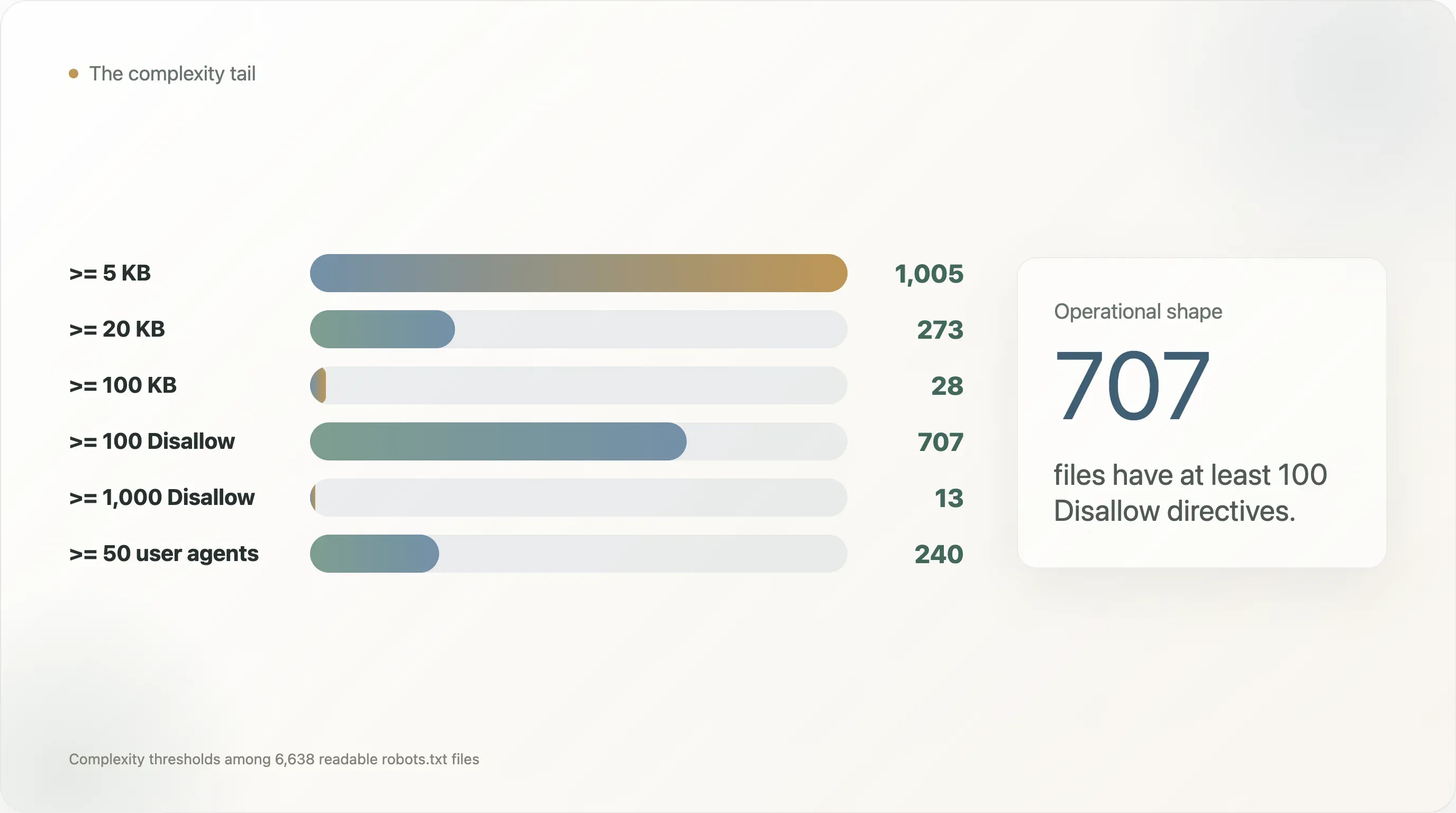
This paragraph contains content that cannot be parsed and has been skipped.
最大的、最复杂的文件并不是学术 curiosities。它们属于真实且高流量的网站:
| 域名 | 排名 | 类别 | 字节数 | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | 社交 | 114,341 | 76 | 4,184 | 281 |
runescape.com | 5,226 | 未知 | 113,393 | 1 | 4,997 | 0 |
academia.edu | 832 | 学术 | 57,384 | 63 | 2,044 | 227 |
etsy.com | 286 | 电子商务 | 51,320 | 3 | 1,621 | 120 |
thepaper.cn | 9,395 | 新闻 | 56,867 | 1 | 1,496 | 0 |
opentable.com | 4,137 | 未知 | 70,494 | 32 | 1,683 | 176 |
alfabank.ru | 2,625 | 金融 | 73,158 | 2 | 1,566 | 133 |
这些文件更像生产路由表,而不是政策口号。它们记录了多年产品发布、遗留路径、被屏蔽的参数模式、爬虫例外、SEO 实验、CDN 决策,以及现在的 AI 爬虫规则。
尾部并不只是 AI 故事。在 273 份至少 20 KB 的文件中,有 131 份包含 AI 政策语言,142 份没有。在 707 份至少包含 100 条 Disallow 指令的文件中,只有 207 份包含 AI 政策语言。换句话说,AI 并没有制造大型文件问题。它是在多年普通网站运维已经把文件填满路径规则、站点地图引用和爬虫例外之后才出现的。
这很关键,因为可维护性取决于结构,而不只是意图。一个包含直接 AI 封锁的小文件,可能很容易审核;而一个 70 KB 的电商或旅行文件,即使完全没提 AI,也可能很难审核。风险不在于每一个大文件都是错的,而在于真正的政策已经变得太难让责任人验证。
运营层面的风险很直接:随着 robots.txt 变大,发布者、平台工程师、律师或 SEO 负责人都更难回答一个基本问题:这个文件到底允许什么?
这个问题已经不再简单。按照 RFC 风格解析,爬虫可能匹配比 User-agent: * 更具体的用户代理组;更长的路径匹配可能覆盖更短的匹配;Allow 和 Disallow 指令会按优先级相互作用;而通用的全局禁止规则,可能会无意中把写文件时还不存在的新爬虫一并拦住。
对于一个 30 行的文件,人类还能推理;对于一个包含数十个命名 bot 的 4,000 行文件,就不该让任何人这么做了。
发现 2:robots.txt 承载的,不只是爬取规则
AI 爬虫争论让 robots.txt 在政治层面变得显眼,但这个文件本身早已开始承担无关的职责。
现代头部站点的 robots.txt 可能包含:
- 爬虫路径控制;
- 站点地图发现;
- 面向搜索引擎的扩展;
- 爬取速率提示;
- 主机规范化提示;
- URL 参数清理提示;
- CDN 注入的政策词汇;
- 版权保留文本;
- AI 训练退出声明;
- 面向人类的法律说明。
数据集把这种层叠展示得很清楚。
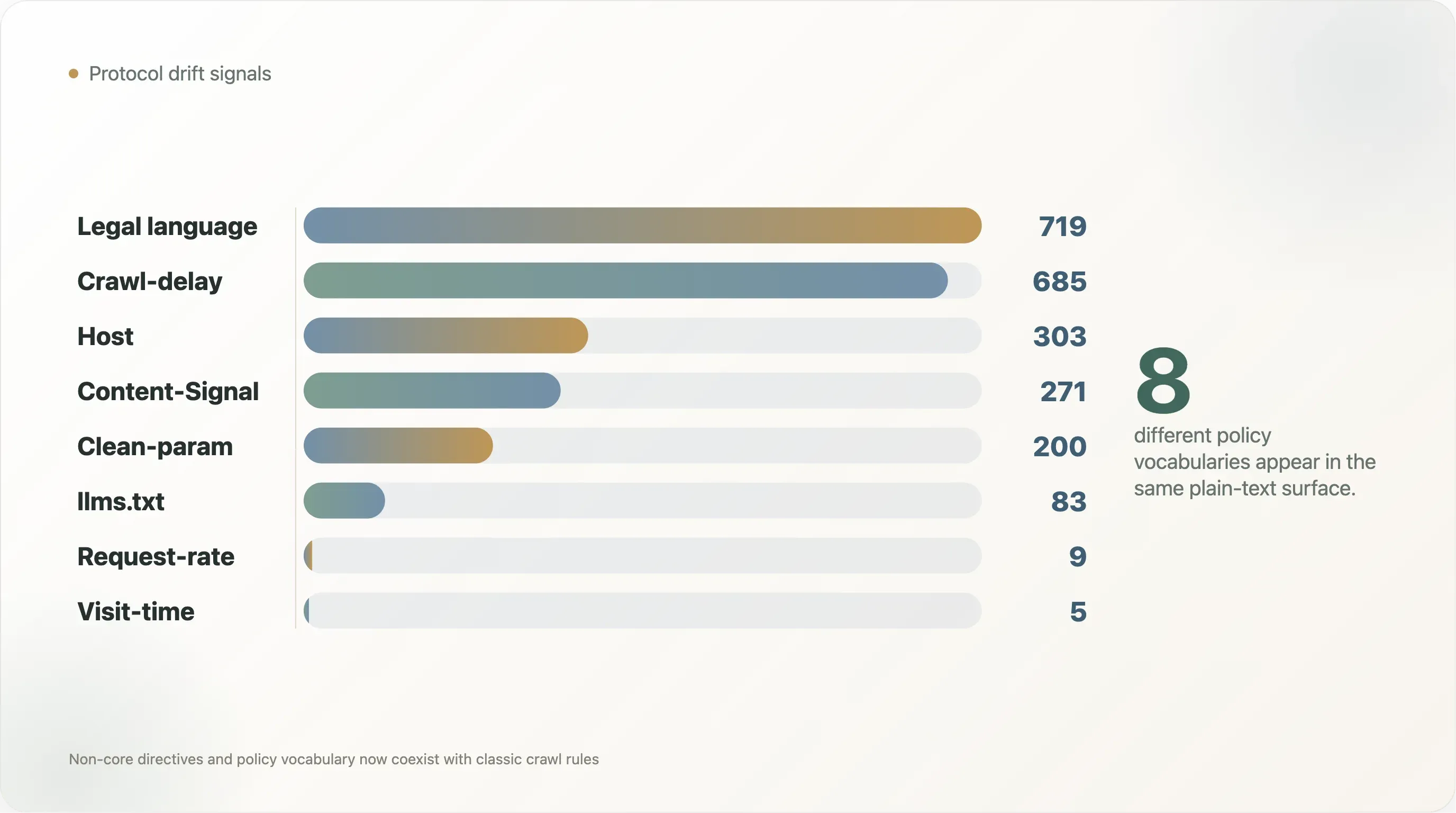
| 信号 | 文件数 | 可读取文件占比 |
|---|---|---|
Crawl-delay | 685 | 10.3% |
Host | 303 | 4.6% |
Clean-param | 200 | 3.0% |
Content-Signal | 271 | 4.1% |
Request-rate | 9 | 0.1% |
Visit-time | 5 | 0.1% |
提及 llms.txt | 83 | 1.3% |
| 版权、条款、许可或权限语言 | 719 | 10.8% |
| AI 政策语言 | 1,377 | 20.7% |
其中一些指令已被特定爬虫广泛识别。一些是遗留约定。一些是厂商专属。一些其实根本不是爬虫指令,而是嵌在注释里的法律或产品语言。
这就是协议漂移的样子。
Crawl-delay 是一个很好的例子。很多站点运营者都知道它,但在主流爬虫之间的支持并不一致。Host 和 Clean-param 传统上与 Yandex 行为有关。Content-Signal 属于 Cloudflare 的 AI 时代政策词汇。llms.txt 是一种提议中的邻近发现格式,并不是普遍遵守的标准。但这些内容都出现在同一种文件里,往往还和经典的 User-agent、Disallow 规则并排出现。
这些数字也说明,新旧约定如今是如何共存的。Crawl-delay 出现在 685 份文件中,比 271 份带有 Content-Signal 的文件多出两倍多。Host 出现在 303 份文件中,Clean-param 出现在 200 份文件中,主要反映的是搜索时代的约定。尽管 llms.txt 在 AI 搜索圈里被大量讨论,但在可读取文件中只出现了 83 次。真实互联网并没有收敛到一套词汇,而是在堆叠词汇。
问题不在于某个扩展本身是错的。问题在于,这个文件已经变成了一个没有版本控制的容器,装着多个重叠的治理系统。
这带来了三种债务:
- 语义债务。 不同爬虫可能对同一个文件有不同解释。
- 所有权债务。 SEO、法务、基础设施、安全和产品团队都可能有理由改这个文件,但未必有一个团队对整套政策负责。
- 审计债务。 一个站点可以发布看起来很有意图的政策,但其实际行为只有解析器才能确定。
AI 让这件事更重要,因为风险级别变了。当一个遗留爬取速率提示被忽略时,结果可能只是多了一些流量;当一个 AI 训练退出声明含糊不清时,结果可能会成为版权或许可争议中的证据。
发现 3:这个文件既是机器接口,也是法律文书
最初的 AI 爬虫报告显示,在可分析站点中,有 17.0% 写了明确的 AI 特定规则。这次后续报告关注的是这些政策带来的文本负担。
在 6,638 份可读取的 robots.txt 文件中:
- 1,377 份包含 AI 政策语言;
- 719 份包含版权、条款、许可、权利或权限语言;
- 271 份包含
Content-Signal; - 83 份提及
llms.txt。
真正有意思的是它们的重叠部分:
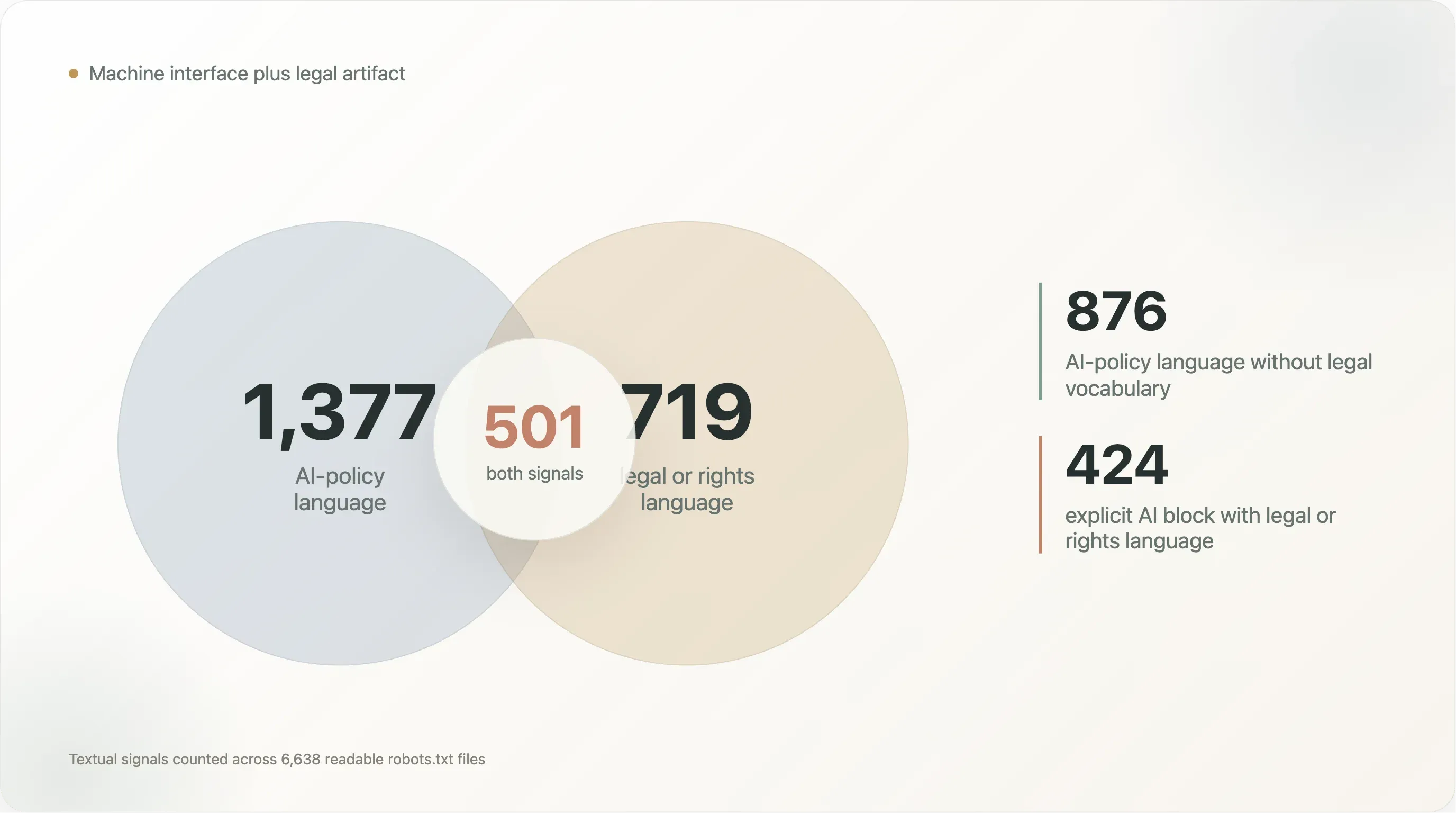
| 文本模式 | 文件数 |
|---|---|
| AI 政策语言与法律/权利语言并存 | 501 |
| 有 AI 政策语言但没有法律/权利语言 | 876 |
| 有法律/权利语言但没有 AI 政策语言 | 218 |
Content-Signal 与法律/权利语言并存 | 242 |
| 明确 AI 封锁与法律/权利语言并存 | 424 |
这是一种新的文件类型。
传统的 robots.txt 是写给爬虫看的。带法律前言的 robots.txt 则同时写给至少四类受众:
- 需要机器可读指令的爬虫运营者;
- 需要政策信号的搜索和 AI 厂商;
- 想明确保留权利的律师;
- 未来可能阅读这些注释作为意图证据的审计者、法院或记者。
这种多受众设计解释了为什么有些文件现在读起来像政策文件。但它也削弱了爬虫可解析内容与人类律师想声明内容之间的清晰分离。
那 876 份只有 AI 政策语言、没有法律词汇的文件,大多是机器政策文件:bot 名称、Disallow 封锁和模板化语言。那 501 份同时包含 AI 与法律语言的文件则不同。它们试图同时充当爬虫指令和权利保留声明。那 218 份只有法律语言、没有 AI 词汇的文件说明,这种模式并不是从 LLM 时代才开始的;robots.txt 早就被拿来表述条款、权限边界和权利主张。
例如,注释里可能写着禁止机器学习,但真正的指令块只禁止一部分已知 user-agent。站点可能在全局层面声明权利,但只点名几个爬虫。CDN 模板也可能把 AI 相关词汇注入一个运营者从未手写过法律语言的文件。站点还可能写出一个宽泛的 User-agent: * 规则,结果无意中封掉未来的爬虫。
从治理角度看,robots.txt 之所以有吸引力,正是因为它公开且机器可读。但它承载的政策越多,局限性就越明显:
- 没有认证层证明某项政策是权利人亲自审核的,而不是继承自基础设施;
- 没有原生版本历史;
- 没有用于表达预期用途的结构化字段,例如训练、检索、搜索索引、摘要、缓存或模型评估;
- 没有统一的 AI 爬虫身份注册表;
- 没有执行机制。
这并不意味着文件没用,而是意味着它很脆弱。
更合理的理解是:robots.txt 正在变成一个通知层——一种公开、可审查的偏好与意图声明。它本身并不是完整的权利管理系统。
发现 4:在 AI 到来之前,搜索就已经不平等了
最初报告里最强的发现之一是,许多发布者会区分 AI 训练爬虫和搜索爬虫。他们会封锁 CCBot、GPTBot 或 Google-Extended,同时保留 Google 搜索可见性。
这篇后续报告补充了一个不同的点:传统搜索爬虫本身也并不平等。
我们检查了六种搜索爬虫:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot。
在 7,248 个可分析站点中:
| 搜索爬虫处理情况 | 站点数量 |
|---|---|
| 至少封锁一个搜索爬虫 | 562 |
| 允许 Googlebot 但封锁至少一个其他搜索爬虫 | 404 |
| 封锁全部六个被检查的搜索爬虫 | 152 |
被封锁的 bot 分布并不均匀:
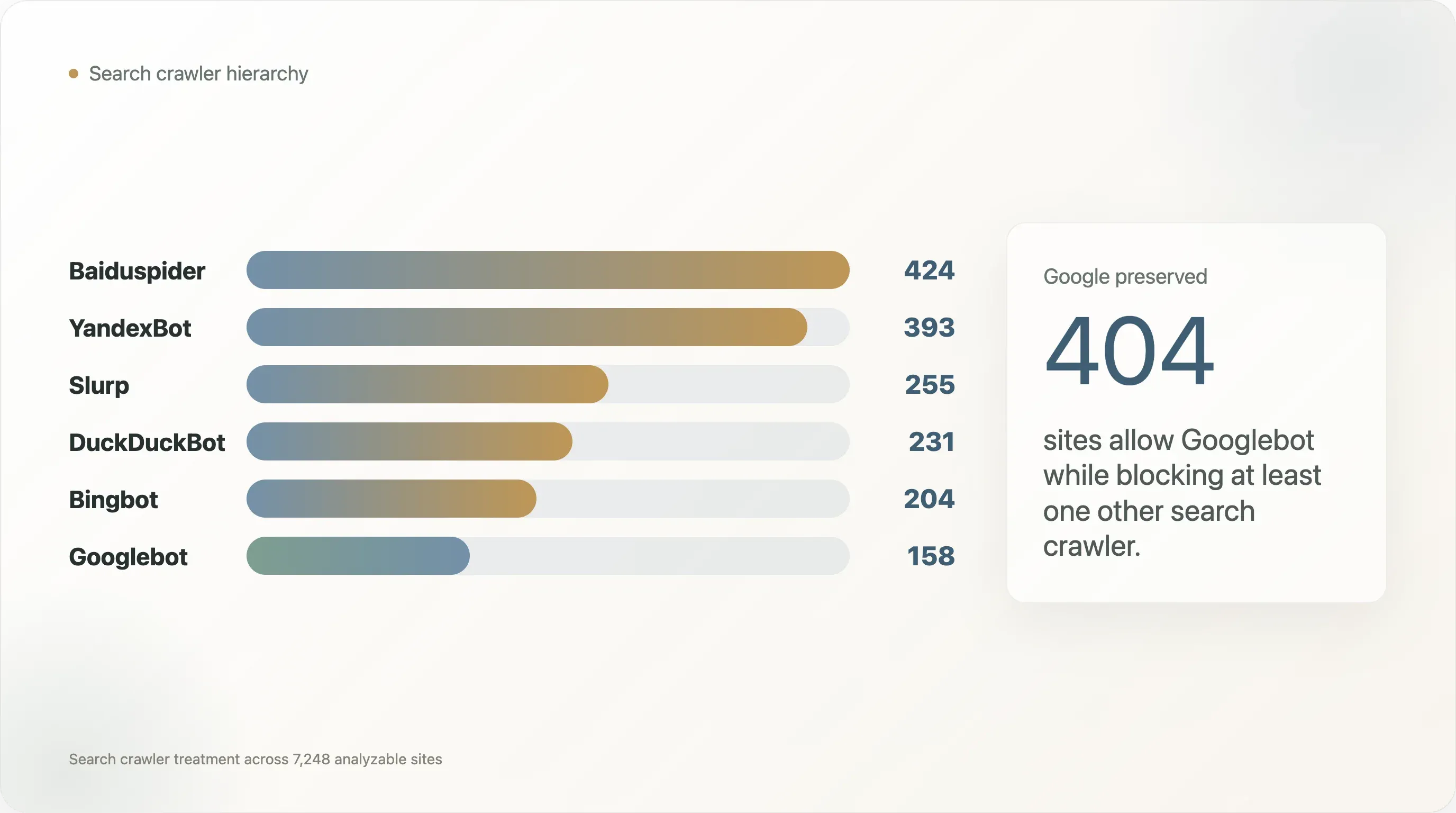
| 搜索爬虫 | 封锁它的站点数 |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
在这组样本里,Googlebot 是最少被封锁的爬虫。Baiduspider 和 YandexBot 更常被封,而在这些案例中,大多数仍然允许 Googlebot。404 个允许 Googlebot 但封锁其他搜索爬虫的站点里,有 269 个封锁 Baiduspider,240 个封锁 YandexBot。
这些例子都很知名:
| 域名 | 在允许 Googlebot 时被封锁的搜索爬虫 |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
这对 AI 争论很重要,因为它说明:即使在 LLM 爬虫到来之前,robots.txt 也从来不是一个中立的、普遍开放的访问协议。开放网络本来就有一套层级:
- Googlebot 常常被保留,因为 Google 搜索流量价值太高,不值得冒险;
- 区域性或竞争对手爬虫更容易被封;
- 一些站点把搜索爬虫访问视为按市场或按厂商做出的决定。
AI 爬虫进入的是一个已经习惯差异化访问的生态。
这也让政策转变更容易理解。一个写下“封锁 Google-Extended、允许 Googlebot”的发布者,并不是在发明一种新的歧视形式,而是在把旧模式应用到一种新的爬虫类别上:保留分发,限制提取。
未解决的问题是,这种旧模式是否可扩展。对于搜索来说,经济上重要的爬虫只有少数几个;而在 AI 领域,爬虫身份分散在模型厂商、检索 bot、数据经纪商、学术爬虫、合成浏览器代理和基础设施级抓取器之中。除非生态系统围绕更少、更基于用途的信号收敛,否则被命名的 user-agent 数量只会持续增长。
这就是配置债务如何累积的。
发现 5:复杂度会因行业而异,但不是按 AI 封锁率那样分布
最初报告显示,AI 封锁在行业之间差异巨大:新闻封锁率高;电信、政府和 SaaS 封锁率低。
配置复杂度切割网络的方式不同。
在一些有足够可读 robots.txt 文件、足以做有意义比较的类别中:
| 类别 | n | 中位字节数 | P90 字节数 | 中位 Disallow | P90 Disallow | 中位 User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| 电子商务 | 215 | 1,738 | 10,388 | 37 | 164 | 3 | 49 |
| 旅行 | 63 | 2,074 | 27,368 | 41 | 779 | 5 | 34 |
| 新闻 | 647 | 1,534 | 7,039 | 19 | 114 | 6 | 68 |
| 金融 | 121 | 1,002 | 8,337 | 17 | 132 | 2 | 23 |
| 学术 | 253 | 839 | 3,959 | 14 | 75 | 1 | 11 |
| 政府 | 151 | 1,227 | 3,263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12,606 | 4 | 56 | 1 | 10 |
| 开发工具 | 119 | 273 | 9,255 | 3 | 58 | 1 | 10 |
This paragraph contains content that cannot be parsed and has been skipped.
新闻在政治上更复杂,因为它写了明确的 AI 规则和法律文本。但电子商务和旅行在运营上更复杂,因为它们有大型目录、筛选式导航、搜索结果页、过滤器、用户账户路径和参数化 URL。
这个区别很重要。
旅行是最典型的例子。这个类别里只有 63 份可读取文件,但它的 P90 robots.txt 达到 27.4 KB,P90 Disallow 数量高达 779,远高于新闻。这并不代表旅行站点有更成熟的 AI 政策,而是说明旅行站点有更多爬虫运营者可能不小心浪费预算的表面:日期搜索、可用性页面、评论分页、预订流程、筛选组合和本地化库存路径。
SaaS 则是另一种意外。它的中位文件只有 485 字节,但 P90 文件会跃升到 12.6 KB。大多数 SaaS 站点是开放而轻量的;少数站点则带有很长的路径控制文件,通常是因为文档、登录界面、应用路由和营销页面都放在同一个域名下。
新闻在运营上处于中间,但在政策上几乎位于顶部。它的 P90 User-agent 数量是 68,高于这张表里的电子商务、旅行、金融、学术、政府、SaaS 和开发工具。这说明的是针对特定 bot 的政策,而不只是路径卫生。
发布者的 robots.txt 可能因为权利政策而复杂;市场平台的文件可能因为爬取预算管理而复杂;大学的文件可能因为一个域名下积累了数千条遗留路径而复杂;社交平台的文件可能因为必须大规模暴露某些面向,同时压制另一些面向而复杂。
AI 政策是在这一切之上叠加的,而不是替代文件复杂性的既有原因。
这也解释了为什么 AI 时代的 robots.txt 治理不能靠一个统一封锁名单解决。底层文件的工作各不相同:
- 电子商务站点管理重复路径和库存表面;
- 旅行站点管理列表、日历、评论和动态搜索页;
- 新闻站点管理版权、档案和许可立场;
- SaaS 和开发工具站点通常希望获得 AI 可见性;
- 政府网站往往需要公开访问,但仍可能有需要排除的敏感系统;
- 社交平台则管理用户生成内容、个人资料表面和反滥用问题。
同一条 AI 爬虫规则在每个环境中的含义都不同。
发现 6:配置债务指数识别的是审核风险,而不是道德失败
这项分析创建了一个简单的配置债务分数,用来识别那些可能很难审核的 robots.txt 文件。
该分数的权重包括:
- 文件大小;
User-agent指令数量;Disallow指令数量;Allow指令数量;- 非核心指令数量;
- 是否存在 AI 政策语言;
- 是否同时包含明确的 AI 封锁以及法律或版权语言。
这不是正确性分数。高复杂度文件完全可能是有意为之;低复杂度文件也仍可能有错。重点在于分流:如果一个文件大、政策密集、bot 特定、而且充满例外,它就更值得严格审核。
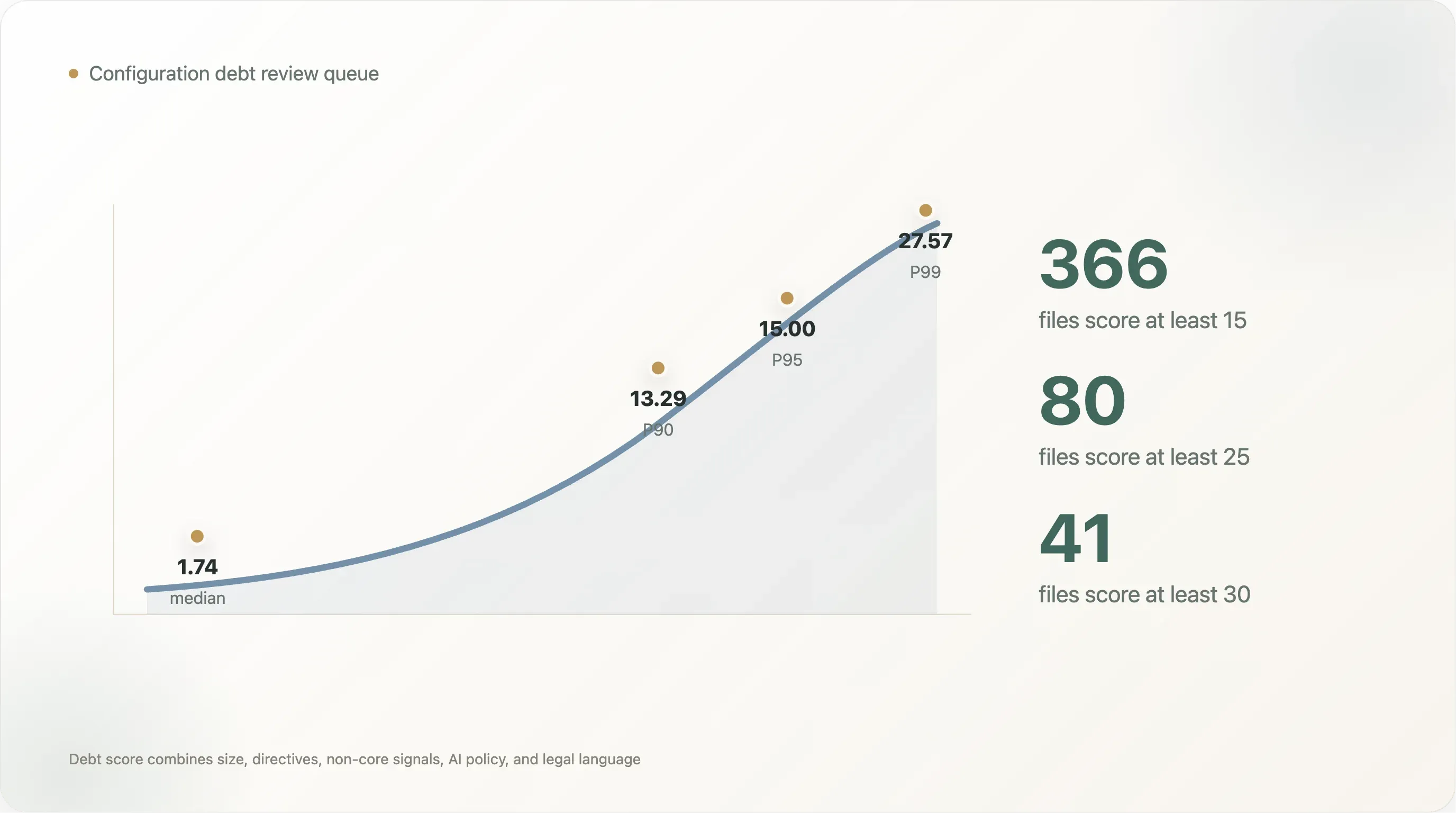
分数分布非常陡峭。可读取文件的中位数分数是 1.74。P90 分数是 13.29,P95 是 15.00,P99 是 27.57。只有 366 份文件分数至少 15,80 份至少 25,41 份至少 30。这就是实际的审核队列:不是每个站点都需要一个治理项目,但尾部那些需要。
类别视图也说明了为什么单一的“AI 封锁器”标签太过扁平:
| 类别 | 中位分数 | P90 分数 |
|---|---|---|
| 旅行 | 4.92 | 28.94 |
| 搜索 | 2.97 | 24.23 |
| 社交 | 2.25 | 15.00 |
| 新闻 | 4.91 | 14.92 |
| 金融 | 1.67 | 12.61 |
| SaaS | 0.98 | 11.85 |
| 电子商务 | 3.88 | 10.87 |
| 政府 | 1.57 | 6.38 |
旅行和搜索的 P90 分数最高,因为少数文件会变得非常大、规则非常多。新闻的中位分数之一最高,因为政策语言和 bot 特定处理在整个类别中更常见。电子商务的中位 Disallow 数量很高,但其 P90 债务分数低于旅行,因为它的复杂性更多集中在路径规则,而不是混合的政策/法律信号。
该数据集中分数最高的文件包括:
| 域名 | 高分原因 |
|---|---|
linkedin.com | 文件极大、路径规则成千上万、命名 user-agent 很多、明确的 AI 政策语言 |
lnkd.in | 与 LinkedIn 短链接基础设施共享相同的政策面 |
fragrantica.com | 数百个命名 user-agent 封锁块,加上 AI 政策语言 |
sovcombank.ru | 大量 user-agent 封锁块,以及法律/政策语言 |
academia.edu | 大型 allow/disallow 矩阵,以及明确的 AI 封锁政策 |
opentable.com | 大型路径规则集、许多站点地图指令、AI 相关政策面 |
etsy.com | 大型电商路径控制文件,包含超过 1,600 条 Disallow 规则 |
runescape.com | 一个 user-agent 组下有近 5,000 条 Disallow 指令 |
这些文件不该因为复杂而被嘲笑。复杂性往往反映了真实业务需求。但它们也说明,robots.txt 政策应该像其他生产配置一样接受工程纪律:
- 所有权应当明确;
- 变更应当经过审核;
- 生成的部分应当标注;
- 法律注释尽可能与机器指令分离;
- 应为关键爬虫建立测试用例;
- 应保留版本历史;
- 旧 bot 名称应退役或文档化;
- AI 训练、AI 检索、搜索索引和归档应被视为不同用途。
最后一点最重要。当前语法以 user-agent 为中心:它要求站点运营者去点名 bot。AI 时代真正需要的是以用途为中心:它要求站点运营者说明允许哪些使用方式。
这两者并不相同。
正因如此,更长的封锁名单并不会长久适用。发布者今天可以添加 GPTBot、ClaudeBot、CCBot、Google-Extended、Bytespider、Applebot-Extended 和 PerplexityBot,但明天就可能出现新的爬虫名称、检索代理或数据经纪商。以用途为基础的政策会让站点说“允许搜索索引,不允许 AI 训练,用户触发的检索视情况而定”,而不是把 robots.txt 变成一个 bot 通讯录。
这对 AI 治理意味着什么
公共讨论常把 robots.txt 描述成“有意义”或者“过时”。数据给出的答案更务实:
robots.txt 是有意义的,但它已经过载。
它之所以有意义,是因为大型网站在用,爬虫能够解析,研究人员、记者、厂商和法院都能看到政策选择。最初的报告发现,在可分析的头部站点中,有 17.0% 写了刻意的 AI 特定规则。这不是象征性的噪音。
它之所以过载,是因为这个文件现在要表达的不只是 bot 访问:
- “不要用这些内容训练模型。”
- “你可以用这些内容做搜索索引。”
- “你可以用这些内容做实时检索。”
- “你不能创建缓存数据集。”
- “这项法律保留适用于欧盟文本与数据挖掘法。”
- “这个由 CDN 管理的网站发送
Content-Signal: ai-train=no。” - “这个站点希望 Googlebot 可以访问,但不希望 YandexBot 访问。”
- “这个站点有 1,000 条遗留 URL 路径不应被抓取。”
这种语法本来就不是为这么多任务设计的。
有三个变化可以降低这笔债务:
-
爬虫身份需要注册表。 站点运营者不该被迫维护一份越来越长的名单,把
GPTBot、ClaudeBot、anthropic-ai、CCBot、Google-Extended、Applebot-Extended、Bytespider、OAI-SearchBot、ChatGPT-User等等都列进去。没有注册表,政策永远会落后于爬虫行为。 -
AI 使用需要结构化词汇。 训练、检索、索引、摘要、数据集转售、模型评估和用户触发浏览都是不同用途。用厂商专属的 user-agent 名称来表达这些用途,太脆弱了。
-
政策需要可审计性。 互联网需要一种方式,区分手写的权利保留声明、继承的 CDN 默认值、CMS 生成模板、过时的遗留规则和误伤性的全局封锁。这个区别对信任和诉讼都很重要。
这并不意味着要在一夜之间替换 robots.txt。更好的路径是分层:保留 robots.txt 作为发现和兼容层,同时为 AI 特定用途标准化相邻的机器可读政策。
llms.txt 是一种尝试,但在这份数据集里的采用率仍然很低:只有 83 份可读取文件提到它。Content-Signal 更显眼,是因为 Cloudflare 可以通过基础设施分发它,而且本次扫描中所有 271 份包含 Content-Signal 的文件也都匹配了 AI 政策语言。不过,分发并不等于共识。一个持久的解决方案大概率仍然需要标准化里那些乏味但关键的部件:清晰字段、清晰语义、爬虫承诺和公开测试套件。
结论
AI 爬虫之争已经把 robots.txt 变成了一个治理文物。这既有用,也有风险。
有用,是因为这个文件是公开的。研究者可以审计它,发布者可以修改它,爬虫可以遵守它,法院可以阅读它,基础设施提供商也可以大规模部署它。
有风险,是因为它承载得太多了。
Tranco Top 10K 中位数的 robots.txt 文件仍然小到足以理解。但高流量网络的长尾里充满了大文件、老文件、多层文件、厂商专属文件和带法律色彩的文件。如今,数百个站点维护的 robots.txt 配置,已经更适合被理解为生产政策系统,而不是简单的爬虫提示。
关键教训不是 robots.txt 失败了,而是互联网在没有重构它的情况下,已经把它升级了。
如果 AI 访问政策将依赖机器可读的公开声明,那么下一步不该是另一份更长的封锁名单,而应是更好的政策基础设施:基于用途的权限、稳定的爬虫身份、可审阅模板和审计轨迹。
在那之前,开放网络的 AI 治理层仍将继续建立在一份本来从未打算承担这么大重量的文本文件之上。
可复现性说明
交付文件夹包含:
source_data/analysis.json— 原始汇总指标。source_data/site_meta.csv— 原始站点级分析表。source_data/bot_status.csv— 原始域名-机器人政策表。source_data/fetch_meta.csv— 原始抓取元数据。source_data/sites.csv— 原始域名/类别/状态表。derived_data/robots_complexity_by_site.csv— 本报告生成的站点级复杂度指标。derived_data/search_bot_treatment.csv— 搜索爬虫处理矩阵。derived_data/category_complexity_summary.csv— 类别级复杂度汇总。derived_data/top_config_debt_sites.csv— 按上文所述分流分数排序的高分站点。derived_data/summary_metrics.json— 本报告引用的全部核心指标。
方法论修正、数据集问题和后续分析,欢迎发邮件至 support@thunderbit.com。本报告的发布独立于 Thunderbit 所持有的任何商业立场;我们打造的是 AI 驱动的网页爬虫,因此从结构上也希望 robots.txt 继续成为开放网络上有意义、机器可读的契约。本报告中的数据本身即可自洽。—— Thunderbit 研究团队,2026 年 5 月。