GitHub 现在能搜到 。看起来像是个自助餐。问题是:过去 12 个月里,只有大约 28% 的仓库显示出任何维护活跃度。过去几周,我一直在翻这些仓库、测试接口、阅读 issue 队列,并对照 Reddit 自己的政策更新。目标很简单:帮你避开克隆一个仓库、折腾 OAuth,然后在午夜发现整个项目早在 2024 年就悄悄坏掉的坑。到了 2026 年,Reddit 爬虫 GitHub 生态像是一片由美好愿望组成的墓地,里面夹着少数真正有用的工具。本指南会讲清楚哪些还在工作、哪些已经失效、什么时候该直接跳过代码方案,以及如何不踩 Reddit 越来越严格的执法红线。如果你想走捷径, 是我们专门为这类问题做的无代码方案——不过我也会坦白说明,哪些场景下代码方案仍然更合适。
什么是 Reddit 爬虫 GitHub 仓库(为什么这么多都坏了)
所谓 “reddit scraper github” 仓库,通常是一个开源的 Python(有时也会是 JavaScript)项目,用来自动抓取 Reddit 上的帖子、评论、用户数据或媒体内容。大致可以分成四类:
- API 封装器(比如 PRAW):使用 Reddit 官方 API,需要 OAuth,并遵守 Reddit 规则。
- Pushshift/PSAW 类工具:曾经用于调用 Pushshift 的 Reddit 海量历史档案。
- 公开
.json端点爬虫:给 Reddit URL 末尾加上.json,或直接访问公开端点,无需认证。 - 基于浏览器的爬虫:使用 Playwright、Selenium 或浏览器扩展加载 Reddit 页面并提取渲染后的内容。
为什么这么多都坏了?主要有三个原因。
- Reddit 在 2023 年中大幅调整了 API 定价。 免费 API 限额降到了 。更高的商业使用现在每 1,000 次 API 调用收费 0.24 美元。很多仓库都是为一个几乎不限流的世界写的——而那个世界已经不存在了。
- Pushshift 的公开访问被撤销了。 Pushshift 曾是 Reddit 历史数据研究的支柱。一旦 Reddit 限制了它,大量 “历史爬虫” 仓库就失去了主要数据源。虽然有些 README 还让这些工具看起来像能用,但对普通用户来说,底层依赖其实已经没了。
- Reddit 同时加强了政策和执行。 2024 年的 robots.txt 更新、2025 年的 ,以及 2026 年 3 月的 都在表明:Reddit 已经不再把批量抓取当成无害的背景噪音。他们甚至已经因为未经授权的数据访问问题,对 Anthropic 和 SerpApi 提出过投诉。。
结论就是:搜 “reddit scraper github” 会得到成百上千个结果,但最后提交时间和未解决 issue 数量会讲出完全不同的故事。
2026 年 Reddit 爬虫 GitHub 状态检查:哪些还在工作
多数对比文章都写于 2023 或 2024 年,之后再也没更新过。论坛用户仍在对着一年前还能用的仓库不断报错——有人发出的那句求助:“一直遇到 Reddit API 限制错误:\ 有什么办法能绕过去吗?” 基本就是 2026 年 Reddit 爬虫体验的缩影。
我做了一轮新鲜度审计,结果截至 2026 年 4 月确认如下。
PRAW:官方 Python 封装器
状态:✅ 仍可用,但有前提。
(Python Reddit API Wrapper)仍然是 Reddit 抓取最可靠的开源基础。它维护活跃——4,099 个 star,最后一次推送是 2026 年 4 月 20 日,只有 6 个 open issue,而且 (发布于 2024 年 10 月)。
优点: 官方、文档完整、能把大部分 Reddit API 复杂性封装起来。
2026 年限制:
- OAuth 要求更严格。你需要注册一个 Reddit 应用,并附带获批的用途说明。
- 2024 年后速率限制更低了(启用 OAuth 后每分钟 100 次请求,未启用仅 10 次)。
- 约 1,000 条帖子列表上限依然存在。r/redditdev 和 Stack Overflow 上的社区讨论都证实:每个列表端点 。
如果你能接受待在 API 的边界内,PRAW 是最稳妥的选择。
只是它已经不再是自由发挥的批量爬虫了。
如果你想看一条实用的官方 API 路线,这个教程很适合放在这一节:
Pushshift / PSAW:已经失联的档案库
状态:❌ 公开访问已消失。
曾是最常用的 Pushshift Python 封装器,而 Pushshift 以前是获取 Reddit 历史数据最简单的方式。到了 2026 年,这个仓库已经归档,README 里甚至直接写着 “THIS REPOSITORY IS STALE”,最近的 open issue 还包括 “Pushshift.io 无法连接” 和 “代码不能用了,可能是 Pushshift API 导致的”。
学术访问也许还能通过特定渠道获得,但对于今天搜索 “reddit scraper github” 的任何人来说,Pushshift/PSAW 已经不是可行方案。如果你需要深度的 Reddit 历史数据,就得去找获批的学术数据访问或授权路径。
snscrape(Reddit 模块):部分可用,但不稳定
状态:⚠️ 部分可用——时好时坏,且基本无人维护。
有 5,337 个 star,但最后一次推送是 2023 年 11 月 15 日。README 里仍写着可以 “通过 Pushshift” 抓取 Reddit。有关 Reddit 的 open issue 包括 “Reddit 抓取出错” 和 “Reddit 爬虫在 2022-11-03 之前返回不了 submissions”,而最近几乎没有实质性修复活动。
它在某些环境里还能做少量、一次性的抓取,但不适合生产环境或周期性任务。把它当成老旧方案即可。
Playwright 和 .json 端点爬虫:能绕过去,但不稳定
状态:✅ 能用,但脆弱。
这个思路很直接:用无头浏览器(Playwright、Puppeteer)加载 Reddit 页面并抓取渲染后的内容,或者给 Reddit URL 加上 .json 获取结构化数据,而不走官方 API。
优点: 不需要 API key,能绕过 1k 帖子上限,还能拿到渲染后的内容。
缺点: Reddit 一旦改前端布局或 JSON 结构就会坏,可能触发反爬措施,而且技术准备更多。我本月实测时,直接请求公开的 Reddit .json 端点返回了 403。这不代表所有环境都会被拦,但它确实说明 .json 这条捷径已经不能再默认“拿来就能用”。
像 这样的仓库在这方面就很诚实:README 直接提醒用户“要配合轮换代理使用,不然 Reddit 可能会送你一个 IP 封禁。” 这基本就是 2026 年 4 月的真实写照。
如果你在评估基于浏览器自动化的绕行方案,下面这个 Playwright 教程很适合作为补充:
Thunderbit:AI 驱动的浏览器抓取(无需代码、无需 API key)
状态:✅ 可用——会自动适应页面变化。
走的是完全不同的路线。它是一个 ,用 AI 读取 Reddit 页面,自动推荐数据字段(帖子标题、作者、赞、时间戳、URL 等),然后两次点击就能提取结构化数据。无需 OAuth 设置、无需注册 API key、无需 Python 环境、无需管理依赖。AI 每次都会重新读取页面,所以 Reddit 一旦改版,Thunderbit 会自动适应,而不是悄悄坏掉。
可免费导出到 CSV、Google Sheets、Airtable 或 Notion。支持分页和子页面抓取(例如先抓 subreddit 列表,再逐个打开帖子提取评论)。对于想要 Reddit 数据、但又不想维护 GitHub 仓库的人来说,这是阻力最小的路线。
(坦白说,这个产品是我们做的,所以我肯定有偏向——但我后面也会清楚说明,什么时候代码方案仍然更合适。)
并排状态汇总表
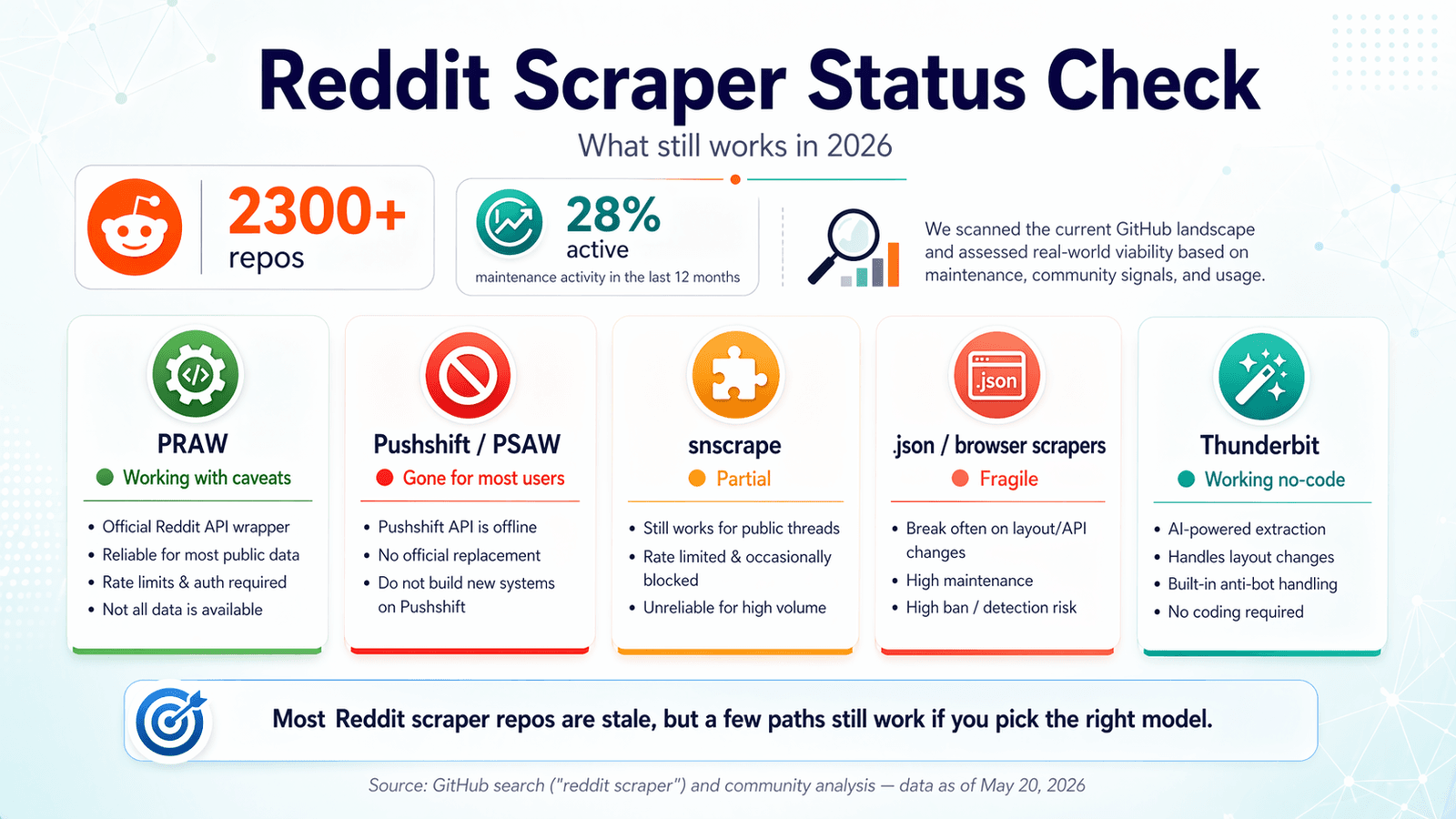
| 工具 / 类别 | 到 2026 年 4 月还可用吗? | 需要 API key 吗? | 说明 |
|---|---|---|---|
| PRAW | ✅ 是,但有前提 | 是(OAuth) | 维护最好的开源基础。受速率限制和 1k 帖子上限约束。 |
| Pushshift / PSAW | ❌ 否(对大多数用户) | 不适用 | 公开访问已消失。仓库已归档。 |
| snscrape(Reddit 模块) | ⚠️ 部分 / 不稳定 | 否 | 仍写着 Reddit “通过 Pushshift”。自 2023 年后维护停滞。 |
| .json / 公开端点爬虫 | ⚠️ 部分 | 否 | 有时可用,但直接请求越来越容易被拦。依赖代理。 |
| Playwright / 浏览器爬虫 | ✅ 是,但脆弱 | 通常否 | 最可行的无 API DIY 绕行方案。页面变化和反爬检查仍然重要。 |
| Thunderbit | ✅ 是 | 否 | AI / 浏览器工作流。无需 OAuth,无需选择器。最适合非开发者。 |
速率限制、1k 帖子上限,以及真正有用的办法
这几乎是任何使用 reddit 爬虫 GitHub 项目的人最头疼的问题。论坛里充满了抱怨:“跑到一半就因为速率限制挂掉了”“为什么我只能拿到大约 1,000 条?” 核心限制只有两个:Reddit API 的速率限制(每分钟请求数)和约 1,000 条帖子的列表上限(API 每个列表端点只返回最近约 1,000 条)。
速率限制管理最佳实践
Reddit 当前公开基线是:。实际操作可以这样处理:
- 指数退避。 如果收到速率限制响应,就先等待,再在每次重试时把等待时间拉长(1 秒、2 秒、4 秒、8 秒……)。不要一直猛打接口。
- 读取
X-Ratelimit-Remaining头。 Reddit API 响应里会包含头信息,告诉你还剩多少请求、窗口何时重置。请求节奏要根据这些值来定,而不是靠猜。 - 轮换 user-agent。 有些仓库建议这么做以避免被识别。它可能有帮助,但请有节制地使用——不要拿它去规避你本来就该被封的限制。
- 记录所有日志。 给 API 响应、速率限制头和错误都加日志。爬虫在凌晨 2 点挂掉时,日志就是你最好的朋友。
突破 1,000 帖子上限
对抗 API 约 1,000 条列表上限,最靠谱的办法是 按时间窗口切片:
- 用
before和after时间戳参数查询一个时间段。 - 把窗口向前(或向后)移动。
- 重复执行。
- 以帖子 ID 去重。
这不优雅,但比假装一个请求循环就能从列表端点抓任意历史要诚实得多。对于真正的历史数据,你需要获批的学术访问或授权路径——Pushshift 已经不再是默认答案。
基于浏览器的抓取(Playwright 或 Thunderbit)则能完全绕开这个上限,因为它抓的是页面渲染内容,而不是 API 返回值。Thunderbit 的分页功能可以让你逐页点击并收集所需的任意页数。
去重和错误恢复
大多数 reddit 爬虫 GitHub 仓库默认都不处理去重或错误恢复。用户会直接抱怨:“没有任何去重、错误后避免速率限制、检查文件是否已经下载。” 你可以这样做:
- 去重: 给每条帖子 ID(或 ID + 内容)做哈希。把见过的哈希存进一个简单的 SQLite 数据库,甚至是一个普通文本文件。在插入前先检查哈希是否已存在。这在按时间窗口切片或重新运行失败任务时尤其重要。
- 错误恢复: 每抓取 N 条记录就把进度写入一个 checkpoint 文件。如果任务失败,就从最后一个 checkpoint 继续,而不是从头再来。这样,一个在第 2 小时崩掉的 3 小时任务,可能只需要 1 小时就能续跑完。
不同方案如何应对这些限制

| 方案 | 速率限制处理 | 超过 1k 帖子? | 自动去重? | 错误恢复? |
|---|---|---|---|---|
| PRAW(原始用法) | 手动(sleep / retry) | ❌(API 上限) | ❌ | ❌ |
| PRAW + 时间窗口切片 | 手动 | ✅(绕行) | ❌ | ❌(除非你自己加) |
| Playwright .json 抓取 | 不适用(无 API) | ✅ | ❌ | ❌ |
| Thunderbit(浏览器抓取) | 内置(AI 节奏控制) | ✅(分页) | 不适用(可视化复核) | 内置 |
当 Reddit 爬虫 GitHub 仓库不是答案时:无代码路线
大多数 reddit 爬虫 GitHub 文章默认读者会 Python。但很多在找 Reddit 抓取方案的人其实是营销人员、销售、研究员,或者不每天写 Python 的独立创始人。对这类人来说,GitHub 仓库会带来隐性成本:
- 配置 OAuth 凭证和 Reddit 开发者应用
- 管理 Python 虚拟环境和依赖冲突
- PRAW 内部变化时调试晦涩的报错信息
- 如果 Reddit 认为你的用途未获批准,还要处理 API key 被撤销的问题
- 每次 Reddit 改动,都得维护脚本
这些都不是想象中的问题。 有 2,563 个 star 和 107 个 open issue。近期报告里包括“安装很困难”“PRAW 模块错误”以及“连认证都不行的异常”。
如果出现以下情况,就用 GitHub 仓库……
- 你需要定制抓取逻辑(例如特定的评论树遍历、定制 NLP 流水线集成)。
- 你想接入现有的 Python 数据管道。
- 你需要用自定义存储(数据库、数仓)进行超大规模抓取。
- 你熟悉代码维护,也能处理破坏性变更。
如果出现以下情况,就用无代码工具……
- 你需要尽快拿到 Reddit 数据——几分钟内,而不是花几个小时搭环境。
- 你不想管理 API key、OAuth 应用或 Python 环境。
- 你希望直接导出到表格、Notion 或 Airtable 立即使用。
- 你希望 Reddit 页面一改版,工具就自动适应。
Thunderbit 正好属于无代码路线。用户可以用 AI 推荐字段, ,免费导出到 CSV / Google Sheets / Airtable / Notion,并且无需写代码就能处理分页。它基于浏览器抓取,所以不需要 OAuth 设置,也不需要注册 API key。
快速上手:用 Thunderbit 抓取 Reddit(分步)
- 安装 。
- 打开你想抓取的 Reddit 页面(subreddit、搜索结果、用户主页)。
- 点击“AI 推荐字段”。 Thunderbit 会读取页面并推荐列——帖子标题、作者、赞数、时间戳、URL 等。
- 按需要调整字段,然后点击“抓取”。
- 检查数据表。 你也可以点击“抓取子页面”,逐个打开帖子并提取评论或更多细节。
- 导出 到你喜欢的目标:Google Sheets、Excel、Airtable、Notion、CSV 或 JSON。
两分钟。零行代码。如果你想看实际效果,可以看看 。
按任务匹配 Reddit 爬虫:使用场景决策矩阵
大多数 reddit 爬虫 GitHub 文章都是按工具来组织的。这个顺序是反的。
应该先从目标出发,再倒推最合适的工具。
线索生成与痛点挖掘
你需要: 带关键词过滤的帖子 + 评论、AI 标注/分类、导出为可直接导入 CRM 的格式。
最佳方案: 带 AI 增强的无代码爬虫。
推荐工具: (AI 标注 + 导出到 Google Sheets/Airtable,便于导入 CRM)。
示例流程: 抓取某个 subreddit 中提到特定痛点的帖子。用 Thunderbit 的字段 AI 提示词来给情绪分类或打主题标签。再导出到销售团队的 Airtable 或 Google Sheet。
市场研究与创意验证
你需要: 大量帖子标题 + 评分、subreddit 级趋势数据。
最佳方案: 用 PRAW 做时间窗口切片以满足体量需求,或者直接用 Thunderbit 快速抓取。
示例: 抓取 r/SaaS 或 r/startups,分析过去 90 天的热门话题和点赞模式。
图片与媒体归档
你需要: 媒体 URL、去重、定时运行。
最佳方案: 专门的 GitHub 仓库(例如 )+ cron 任务。
注意: 这里去重很重要——同一图片跨多个 subreddit 发布很常见。
学术研究与历史数据
你需要: 历史数据、完整评论树、大型数据集。
最佳方案: 获批的学术访问或授权数据路径。Pushshift 已经不是通用答案了。
现实情况: 受 Pushshift 限制和 Reddit 加强数据政策影响,这在 2026 年是最难处理的场景。
竞品监控与定时抓取
你需要: 按固定间隔重复抓取、变更检测。
最佳方案: Thunderbit 的 (用自然英语描述时间间隔,输入 URL,点击计划)或者代码用户用 cron + 脚本。
使用场景决策矩阵表
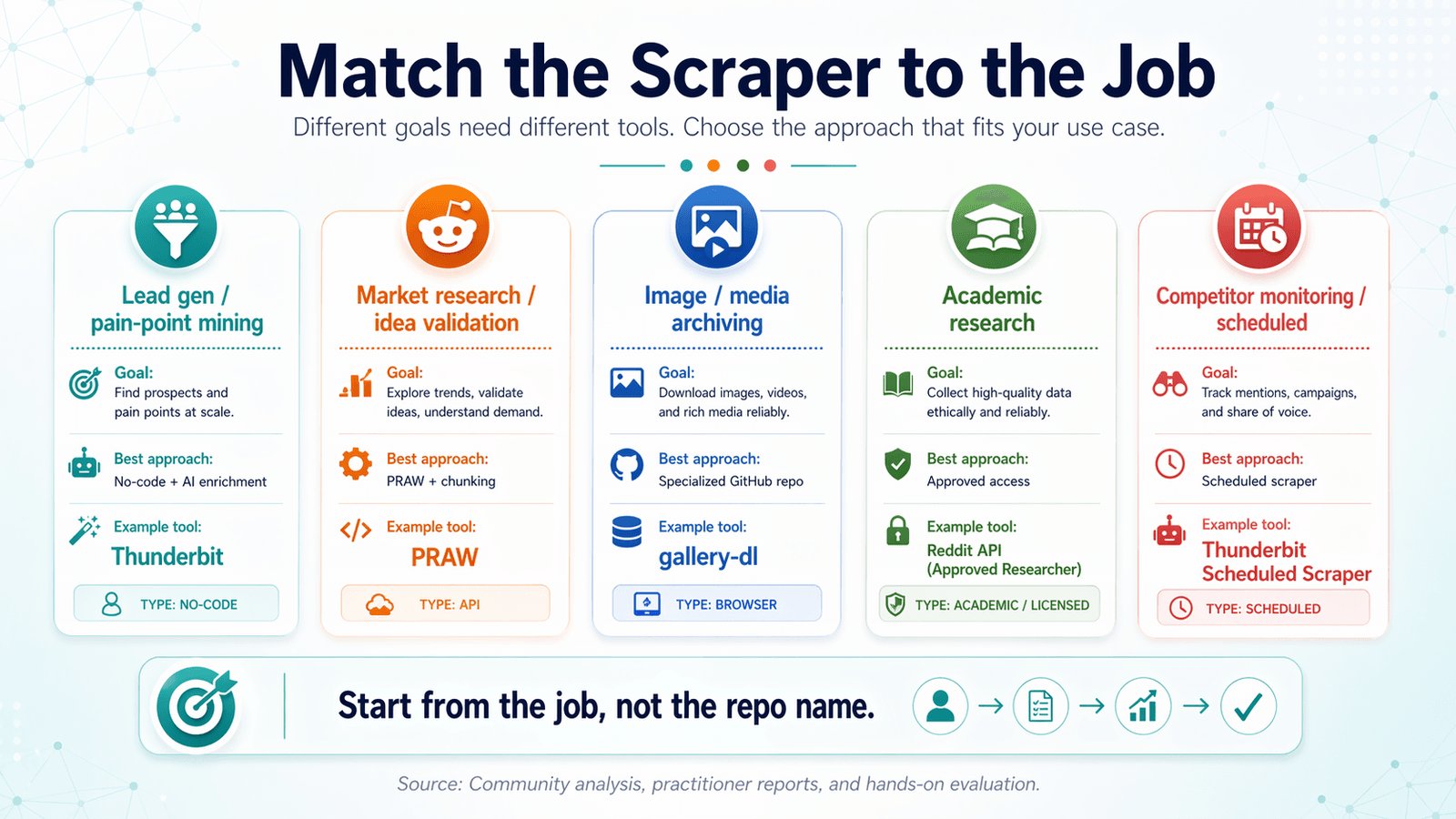
| 使用场景 | 你需要什么 | 最佳方案 | 示例工具 |
|---|---|---|---|
| 线索生成 / 痛点挖掘 | 帖子 + 评论、关键词过滤、AI 标注 | 无代码爬虫 + AI 增强 | Thunderbit |
| 市场研究 / 创意验证 | 大量帖子标题 + 评分、subreddit 级数据 | PRAW + 时间窗口切片,或 Thunderbit | PRAW 或 Thunderbit |
| 图片 / 媒体归档 | 媒体 URL、去重、定时运行 | 专门的 GitHub 仓库 + cron | bulk-downloader-for-reddit |
| 学术研究 | 历史数据、完整评论树 | 获批的学术访问或 Playwright | Pushshift 学术 API(若可访问) |
| 竞品监控 / 定时抓取 | 周期性抓取、变更检测 | 定时爬虫 | Thunderbit 定时爬虫或 cron + 脚本 |
在克隆之前,如何评估任何 Reddit 爬虫 GitHub 仓库
在你克隆仓库并开始调试之前,先跑一遍这个 5 分钟健康检查。它能帮你省下好几个小时。
5 分钟仓库健康检查
- 最后一次提交时间。 如果超过 6 个月没动,谨慎继续。Reddit API 变动很频繁。
- Open issue 与 closed issue 的比例。 大量未回复 issue 是红旗。看看最近的 issue 有没有提到认证失败、403 或 Pushshift 中断。
- LICENSE 文件。 看是否存在。没有许可证 = 法律上含糊不清(下面会讲更多)。
- 依赖项。 需要的库是否是最新?有没有用了已经废弃的包?一个充满 2022 年固定版本的
requirements.txt就是在提醒你。 - README 质量。 是否清楚解释了安装步骤?有没有使用示例?文档差 = 你要花更多时间调试。
- Star vs fork vs 最近活跃度。 Star 很高但近期活动很低,可能只是以前流行,现在已经无人维护。把 star 数和
pushed_at日期对照看。
举个快速例子: 有 364 个 star——乍一看很可信。但这个仓库已经归档,而且 README 明确写着 “THIS REPOSITORY IS STALE。”
光看 star 数并不能说明问题。
如何从你的 Reddit 爬虫 GitHub 方案中获得最大收益
如果你还是决定走代码路线,下面这些做法能少踩很多坑。
一定要使用虚拟环境
虚拟环境可以把爬虫依赖隔离开,避免和其他 Python 项目冲突。一个命令:python -m venv venv,然后在安装任何东西之前先激活它。这是基本卫生习惯,但我见过太多标题为“module not found”的 GitHub issue,足以说明这件事值得反复提醒。
安全存放凭证
不要把 Reddit API 的 client ID 或 secret 直接硬编码到脚本里。用环境变量或 .env 文件,并把 .env 加入 .gitignore。如果你不小心把凭证推到 GitHub,上线后要立刻轮换——机器人会扫描暴露的 API key。
记录一切日志
给 API 响应、速率限制头和错误都加日志。出了问题时,日志就是“我完全知道发生了什么”和“我完全不知道它为什么停了”之间的区别。
有计划地调度和自动化
如果要周期性抓取,可以用 cron(Linux / Mac)或任务计划程序(Windows)——但要监控失败情况。一个会悄悄失败两周的 cron 任务,比没有自动化还糟。
替代方案:Thunderbit 的 可以让你用自然语言描述间隔,不需要写 cron 语法。
Reddit 抓取的法律与伦理最佳实践
这不是随便写写的免责声明。自 2023 年 API 政策变化以来,Reddit 一直在强力执行条款;抓取个人数据也确实存在法律风险。
下面这些才是真正重要的。
Reddit 服务条款:它到底写了什么
Reddit 的 (截至 2026 年 3 月 31 日修订)明确禁止以自动化方式访问、搜索或收集服务中的数据,除非条款或单独协议允许。 和 进一步说明:Reddit 可以监控和审计开发者使用情况,变更或终止访问,并在使用过量或滥用时永久封禁访问。商业用途通常需要明确批准。
2026 年 3 月的 更进一步:通过 API 访问 Reddit 数据前需要获批,未经批准的商业化以及 AI / 数据挖掘用途都被禁止,执法措施甚至可以包括撤销 token、暂停应用或账户,以及暂停相关机器人或域名。
robots.txt 合规
Reddit 当前的 异常严格:
1User-agent: *
2Disallow: /这意味着对所有自动化 user-agent 一律禁止。它还引用了 。这比一些开发者仍沿用的旧式网页抓取宽松假设要严格得多。
最佳实践:抓取前一定要检查 robots.txt,即使你的工具不会自动强制执行。
个人数据与隐私(GDPR / CCPA)
如果你抓取用户名、帖子历史或任何可识别个人身份的信息,(欧盟)和 CCPA(加州)可能都适用。最佳实践:在存储前先对个人数据做匿名化或聚合。不要在没有合法依据的情况下为单个用户建立画像。
GitHub 仓库许可:开工前先确认
很多 reddit 爬虫 GitHub 仓库使用 MIT 或 Apache 这类宽松许可证,但也有一些根本没有 LICENSE 文件——法律上就意味着“保留所有权利”。在 fork、修改或基于某个仓库开发之前,一定先检查 LICENSE 文件。没有许可证,就意味着法律状态不明确,和 star 数量多少无关。
2025–2026 年的执法是真实存在的
Reddit 的执法并没有停留在 2023 年。Reddit 在 2025 年对 Anthropic 提起投诉,指控其未经授权抓取/使用 Reddit 内容,并且在 2025 年末也推进了 Reddit v. SerpApi 相关行动。这些都说明 Reddit 不只是会做技术封锁,也愿意走法律执法路线。
在 2026 年选择合适的 Reddit 爬虫 GitHub 路线
自 2023 年以来,Reddit 爬虫 GitHub 生态已经发生了巨大变化。多数仓库都过时了。速率限制和 1k 帖子上限是真实约束。Pushshift 对普通用户来说已经没了。而 Reddit 的政策栈比以往更明确、执行也更严格。
一句话总结:
- 如果你能接受 Reddit 的 API 限制,又想自己写定制逻辑,PRAW 仍然是最可靠的开源基础。
- Pushshift/PSAW 不再是通用答案。
- snscrape 的 Reddit 模块 属于老方案,而且不稳定。
- .json 和公开端点爬虫 在 2026 年很脆弱,而且经常被拦。
- 基于浏览器的工具——不论是 Playwright 仓库,还是像 这样的无代码方案——对很多用户,尤其是非开发者,都是最实用的路线。
先从你的使用场景出发,而不是从工具出发。在决定使用任何 GitHub 项目前,先跑一遍 5 分钟仓库健康检查。
如果你更想跳过搭建过程,几分钟内就开始抓 Reddit, 。
常见问题
2026 年 GitHub 上最好的开源 Reddit 爬虫有哪些?
仍然是最可靠的 API 封装器,维护活跃,文档也很好。 是一个基于 PRAW 构建、维护良好的 CLI 工具。基于 Playwright 的爬虫适合非 API 抓取,而 snscrape 的 Reddit 模块只算部分可用、且大多已无人维护。在使用任何仓库之前,都要检查最后提交时间和 open issue——GitHub 上 里,大多数都已经过时。
抓取 Reddit 合法吗?
抓取公开可访问的数据处在法律灰区,但 Reddit 自己的条款相当严格。、、、 以及 都在反对未经授权的批量抓取。商业再分发抓取到的数据可能还需要 Reddit 明确许可。如果你在抓取个人数据,GDPR 和 CCPA 也可能适用。
怎么绕过 Reddit 的 API 速率限制?
使用指数退避、监控 X-Ratelimit-Remaining 头,并考虑用时间窗口切片在限制内运行。基于浏览器的抓取(Playwright 或 )不走 API,所以能绕开 API 速率限制,但会有自己的一些代价(页面加载速度、反爬措施)。没有什么魔法可以完全移除速率限制——它们是服务器端强制执行的。
我可以不使用 API key 抓取 Reddit 吗?
可以。基于 Playwright 的爬虫和 .json URL 技巧都不需要 API key。 也不需要 API key,因为它是通过浏览器抓取的。代价是:到 2026 年 4 月,.json 端点越来越容易被拦(很多环境里会返回 403),而且基于浏览器的抓取比 API 调用更慢、资源消耗也更大。
Pushshift 的 Reddit 抓取怎么了?
Reddit 从 2023 年开始调整数据授权后,Pushshift 的公开 API 访问就被移除了。 封装器已归档且过时。虽然通过少数获批渠道可能还存在有限的学术访问,但对于今天搜索 “reddit scraper github” 的大多数用户来说,Pushshift 已经不是可行方案。如果你需要深度的 Reddit 历史数据,请查看 Reddit 批准的学术或授权数据路径。
了解更多