互联网的数据量大到让人头疼,谁还愿意一条条手动复制粘贴上千条商品或职位信息?正因如此,网页爬取已经成了销售、运营、电商等行业的“标配技能”。Python 因为语法简单、库又多,成了开发网页爬虫的首选。其实, 都在用 Python,远远甩开其他编程语言。
不过,虽然 Python 网页爬虫很强大,但新手刚入门时经常会被劝退——哪怕是有经验的开发者,也常常被动态网页、反爬机制、数据清洗等问题搞得头大。为此,我整理了这份循序渐进的实战教程。我们会从零开始,手把手演示一个python 网页爬虫示例,还会介绍如何结合 这样的 AI 工具,让数据采集变得更高效。不管你是想自动化获客、监控竞品价格,还是把网页数据整理进表格,这里都能找到实用的步骤和经验。
Python 网页爬取入门:环境搭建全流程
先从最基础的说起。网页爬取,其实就是让程序自动帮你收集网站上的数据。与其手动复制粘贴,不如让爬虫自动访问网页、解析 HTML,把你关心的信息(比如价格、联系方式、评论等)一键提取出来。对于企业来说,这意味着可以实时获取销售线索、监控价格、做市场调研,轻松提升竞争力()。
步骤 1:安装 Python
首先要安装 Python 3。大部分人可以直接去 下载最新版。Windows 用户安装时记得勾选“Add Python to PATH”。Mac 用户可以用 执行 brew install python,或者直接下载安装包。装好后,打开终端(或命令提示符),输入:
1python --version或者
1python3 --version如果看到类似 Python 3.11.0 的输出,说明安装没问题。
步骤 2:创建虚拟环境
虚拟环境能让你的项目依赖互不干扰,避免和其他 Python 项目“打架”。在项目文件夹下运行:
1# macOS/Linux
2python3 -m venv .venv
3# Windows
4py -m venv .venv激活方式:
- macOS/Linux:
source .venv/bin/activate - Windows:
.venv\Scripts\activate
这样后续安装的所有包都只会影响当前项目()。
步骤 3:安装核心库
推荐先装这几个常用包:
- Requests:用来请求网页内容。
- BeautifulSoup (bs4):用来解析 HTML。
- Scrapy:适合大规模、复杂的爬取任务。
安装命令:
1pip install requests beautifulsoup4 scrapy- Requests 让 HTTP 请求变得像读文件一样简单。
- BeautifulSoup 方便查找和提取 HTML 里的数据。
- Scrapy 是功能很全的爬虫框架,适合批量抓取、异常处理和数据导出。
新手建议先用 Requests + BeautifulSoup,等有更大需求再用 Scrapy。
步骤 4:整理项目文件夹
建议每个项目都单独建个文件夹,里面放脚本、数据文件和虚拟环境。结构清晰,后续维护也方便。
python 网页爬虫示例:基础脚本与代码结构
接下来我们写一个简单的爬虫,抓取网页并提取数据。以 为例,代码如下:
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # 非 200 状态会报错
6soup = BeautifulSoup(response.text, "html.parser")
7# 查找所有段落标签
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Paragraph {idx}: {p.get_text()}")代码说明:
- 导入需要的库。
- 用
requests.get获取网页内容。 - 用 BeautifulSoup 解析 HTML。
- 查找所有
<p>标签并输出文本。
常见问题:
- 忽略
response.status_code检查(一定要确认返回 200)。 - 对找不到的元素直接用
.get_text()会报错。 - 忘记激活虚拟环境导致导入失败。
这个流程——导入、请求、解析、提取、输出——就是大多数 Python 网页爬虫的基本套路。
用 Python 爬取网页:详细流程拆解
下面用实际场景分步讲解爬取流程。
1. 分析网页结构
在浏览器里右键目标数据,点“检查”打开开发者工具,查看 HTML 结构。重点关注独特的标签、class 或 id,方便后续精准定位()。
2. 获取网页内容
用 Requests 请求 HTML:
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()加上 User-Agent 可以绕过一些基础反爬机制。
3. 解析 HTML
1soup = BeautifulSoup(response.text, "html.parser")4. 定位并提取数据
比如要抓取职位信息,每条在 <div class="job-card"> 里:
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)可以用 .find()、.find_all() 或 .select()(支持 CSS 选择器)实现更复杂的查找。
5. 批量处理(列表数据)
遍历容器(比如商品列表、职位卡片等),提取需要的字段,建议存成字典列表,方便后续导出。
6. 常见排查方法
- 结果为空时,检查选择器是不是变了,或者内容是不是被 JavaScript 动态加载了。
- 打印
response.text[:500],确认拿到的 HTML 是否正确。
python 网页爬虫示例:数据存储与导出
数据抓取下来,通常需要保存。常见方式有:
控制台输出
适合调试,不建议正式项目用。
导出为 CSV
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)导出为 Excel
如果装了 pandas 和 openpyxl:
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)存入数据库
轻量需求可以用 Python 自带的 SQLite:
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()怎么选?
- CSV:适合表格、方便分享。
- Excel:适合格式化报表、多表单需求。
- 数据库:适合大规模或持续性项目。
建议始终用 encoding="utf-8",避免乱码()。
Thunderbit 与 Python:让爬取流程更高效
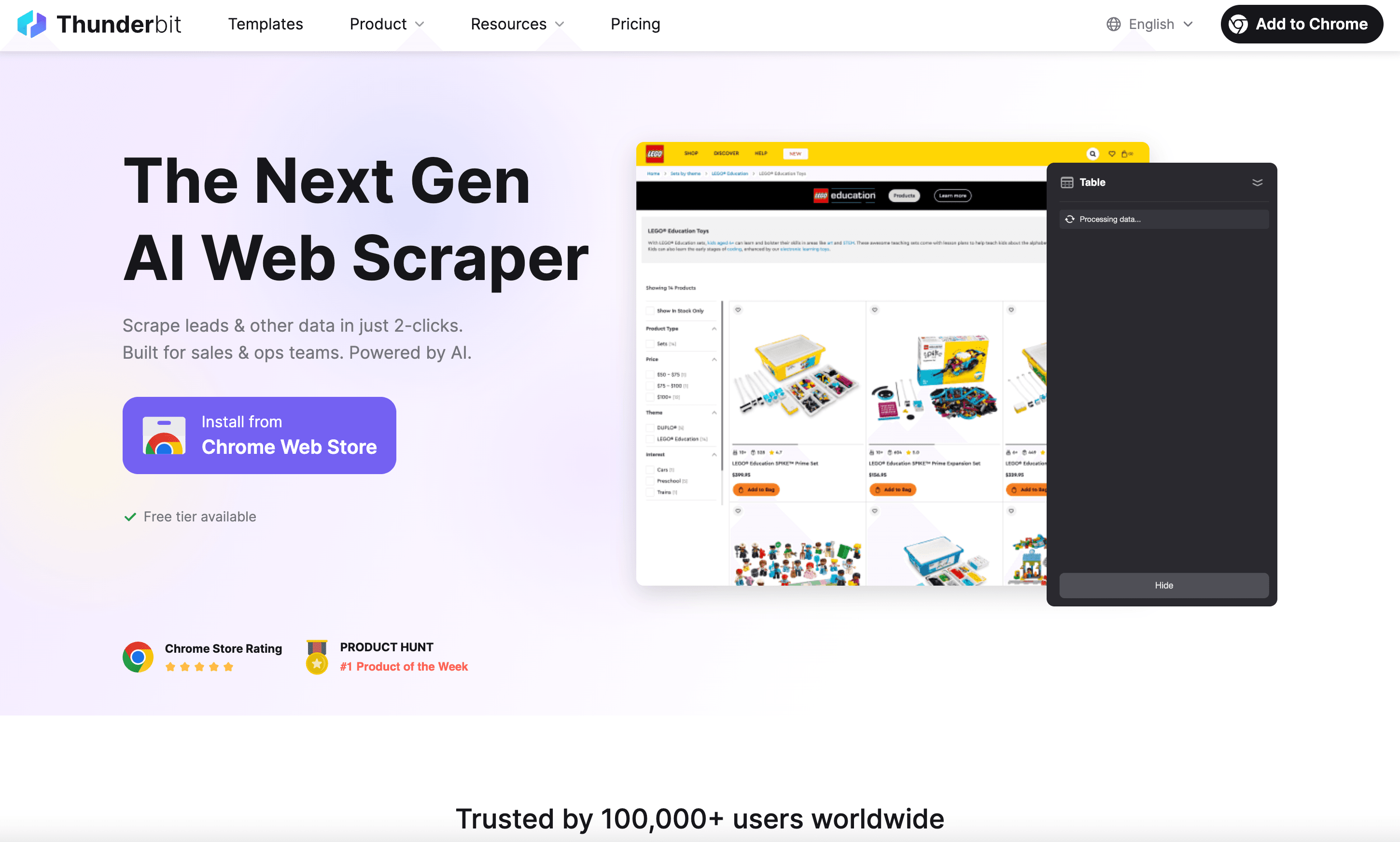 接下来介绍 ,这款 AI 网页爬虫 Chrome 插件正为企业用户带来全新体验。
接下来介绍 ,这款 AI 网页爬虫 Chrome 插件正为企业用户带来全新体验。
Thunderbit 有哪些独特优势?
- AI 智能字段推荐:AI 自动识别页面结构,推荐可提取的数据列,无需手动查找 HTML 或写选择器。
- 可视化操作:打开插件,AI 推荐字段,一键“抓取”,即可完成。
- 子页面自动爬取:Thunderbit 可自动访问详情页(如商品页、个人资料页),丰富数据维度。
- 多渠道导出:支持导出为 CSV、Excel,或直接同步到 Google Sheets、Notion、Airtable()。
Thunderbit 如何与 Python 协同?
比如你要爬取一个大量用 JavaScript、还需要登录的电商网站。传统 Python 脚本可能搞不定,但 Thunderbit 作为浏览器插件,能轻松应对这些复杂场景。数据抓取后,可以导出为 CSV,再用 Python 做分析、报表或自动化处理。
实用场景举例:
- 用 Thunderbit 抓取动态网站的商品列表(包括图片、价格、评论等)。
- 导出为 CSV。
- 用 Python 做趋势分析、数据整合或自动预警。
这种组合让你无论编程水平如何,都能搞定最棘手的爬取任务。
提升 Python 网页爬虫的准确性与稳定性
网页爬取不仅要抓数据,更要抓到对的数据,还要稳定。下面这些建议能帮你提升爬虫质量:
1. 适应网页结构变动
网站 HTML 经常更新。选择器尽量用唯一 id 或稳定 class,别太依赖标签顺序。
2. 加强异常处理
用 try/except 包裹请求和解析代码:
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Failed after 3 attempts: {e}")3. 随机 User-Agent 与代理
很多网站会屏蔽疑似爬虫的请求。可以随机 User-Agent,或者大规模爬取时用代理,降低被封风险()。
4. 遵守 robots.txt,合规爬取
一定要看目标网站的 robots.txt 和服务条款。只抓取公开数据,别采集个人信息,也不要给服务器带来压力()。
5. 日志与监控
用 Python 的 logging 模块记录错误和成功信息。定时运行爬虫时,建议设置异常或无数据报警。
Thunderbit AI 功能如何助力 Python 网页爬取
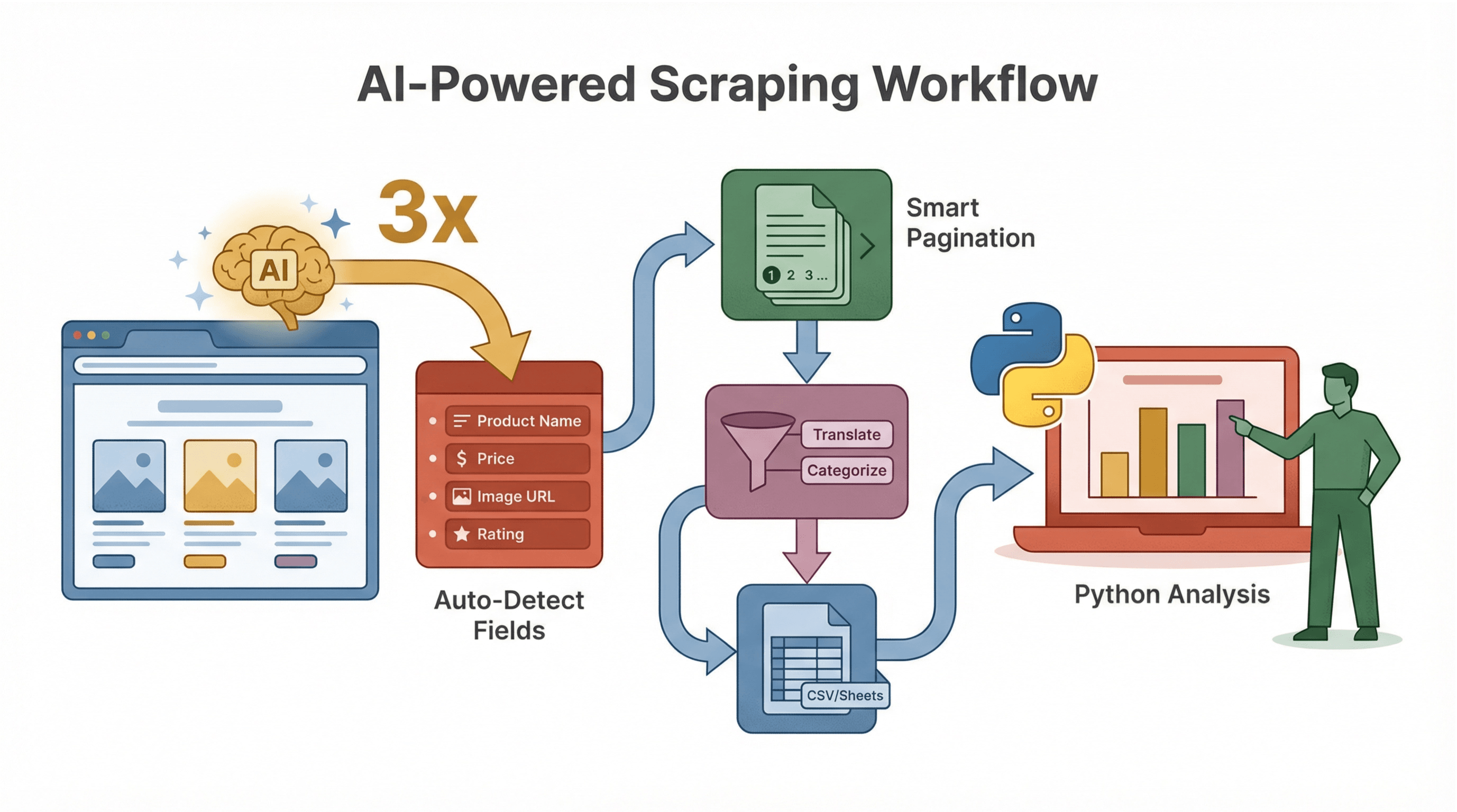 Thunderbit 不只是爬取,更让整个流程变得智能高效。
Thunderbit 不只是爬取,更让整个流程变得智能高效。
AI 智能字段识别
Thunderbit 的 AI 能自动识别页面可提取字段,无需你手动分析 HTML 或写选择器。例如在商品页,能自动检测“商品名”“价格”“图片链接”等。
子页面与分页自动处理
Thunderbit AI 能识别详情页或多页结果,自动批量爬取,无需额外编程。对电商、房产、获客等场景尤为高效。
AI 数据清洗与增强
想在爬取时自动翻译、摘要或分类?Thunderbit 支持为每个字段添加 AI 提示词,比如自动标记评论为“正面”或“负面”,或只提取价格中的数字。
工作流举例
- 用 Thunderbit 智能结构化数据(AI 推荐字段)。
- 导出为 CSV 或 Google Sheets。
- 用 Python 进一步分析、可视化或自动跟进。
这种流程非常适合团队协作——Thunderbit 负责爬取,Python 负责数据处理。
python 网页爬虫示例:进阶技巧与常见问题
想更进一步?下面是一些实战经验:
动态内容爬取
很多现代网站用 JavaScript 加载数据。如果 Requests + BeautifulSoup 得到的数据为空或不完整,可以试试:
- Selenium 或 Playwright:自动化真实浏览器渲染页面,再提取 HTML。
- 查找 API:有时候数据是通过后台 API(通常返回 JSON)加载的。用浏览器 Network 面板找接口,直接抓取更高效!
处理分页
通过修改 URL 参数(比如 ?page=2)循环翻页,或者用 BeautifulSoup 查找“下一页”链接,直到没有更多页面。
定时自动爬取
用 Python 的 schedule 库或 cron 定时运行爬虫。也可以用 Thunderbit 自带的定时功能,无需写代码。
常见问题
- 验证码:降低请求频率、用代理,或者考虑人工辅助。
- 编码问题:写文件时一定要指定
encoding="utf-8"。 - IP 被封:轮换代理、随机 User-Agent、控制请求频率。
总结与核心要点
其实掌握 Python 网页爬虫并不难。建议:
- 先搭好环境,装好核心库。
- 分析目标网站,规划好选择器。
- 写个简单脚本,实现抓取、解析、提取。
- 按需导出数据,满足业务需求。
随着经验提升,可以结合 这样的 AI 工具,轻松应对复杂、动态或大规模爬取任务。Thunderbit 的智能字段推荐、子页面爬取、极速导出等功能,能大大节省人工操作,让非技术用户也能高效采集数据。
记住:优秀的爬虫要稳定、合规,并以业务目标为导向。不管你是销售、运营还是数据爱好者,网页爬取都能带来全新洞察——从小做起,持续优化,不断进步。
想深入了解?欢迎访问 获取更多教程,或试用 ,体验 AI 网页爬取的强大。
常见问题解答
1. Python 网页爬取最简单的入门方式是什么?
建议先装好 Python 3,然后用 Requests 和 BeautifulSoup 库抓取、解析网页。从简单网站练手,逐步挑战更复杂的场景。
2. 如何应对用 JavaScript 加载数据的网站?
对于大量依赖 JavaScript 的网站,可以用 Selenium 或 Playwright 这类浏览器自动化工具,或者在浏览器 Network 面板找返回 JSON 的后台接口,直接抓取结构化数据。
3. 商业用途下,爬取数据导出最佳方式是什么?
CSV 是最通用的格式(可以用 Excel、Google Sheets 打开),也可以导出为 Excel、JSON 或 SQLite 数据库。Thunderbit 还支持直接导出到 Google Sheets、Notion、Airtable。
4. 如何避免爬取时被封禁?
轮换 User-Agent,大规模爬取时用代理,控制请求频率,并遵守 robots.txt。千万别抓取个人或敏感信息。
5. Thunderbit 如何让非技术用户也能轻松爬取网页?
Thunderbit 利用 AI 自动推荐字段、处理子页面和分页,几步就能导出结构化数据,无需写代码。非常适合追求高效、稳定结果的企业用户。
想自动化你的数据采集?现在就免费试用 ,让 AI 帮你轻松升级网页爬取流程。
延伸阅读