
互联网现在简直成了视觉大餐——每天都有数以十亿计的图片被上传,撑起了电商商品库、社交媒体爆款图等各种场景。如果你做销售、市场或者研究,肯定体验过一张张手动收集图片的枯燥和低效。我也曾经陷入“右键另存为”的死循环,心里直嘀咕:难道没有更省事的办法吗?其实,答案早就有了。Python 图片爬虫和像 这样的零代码工具,已经彻底颠覆了批量下载网页图片的方式。
这篇指南会带你了解怎么用 Python 抓取网页图片,怎么搞定动态网站的难题,以及为什么 Python 搭配 Thunderbit 能让你效率翻倍。不管你是要搭建产品图片库、做竞品分析,还是单纯受够了重复粘贴,这里都能找到实用的操作步骤、代码示例,还有一些轻松有趣的小技巧。
什么是 Python 图片爬虫?
This paragraph contains content that cannot be parsed and has been skipped.
谁会用 Python 图片爬虫?其实只要你需要大量图片,基本都用得上:
- 电商团队:从供应商网站批量下载商品图片,快速搭建产品库。
- 市场营销:收集社交媒体图片,用于活动策划或趋势分析。
- 科研人员:为 AI/机器学习项目或学术研究构建图片数据集。
- 房产经纪人:批量获取房源照片,方便发布或市场分析。
你可以把 Python 图片爬虫当成你的“数字实习生”——不会觉得无聊,也不会被猫咪表情包分心。
为什么用 Python 抓取网页图片?
 Python 在网页爬虫领域就像“瑞士军刀”一样万能。它之所以成为图片抓取的首选,主要有这些原因:
Python 在网页爬虫领域就像“瑞士军刀”一样万能。它之所以成为图片抓取的首选,主要有这些原因:
- 库生态丰富:Requests、BeautifulSoup、Selenium 等工具,能搞定从静态 HTML 到复杂 JS 网站的各种需求()。
- 入门门槛低:Python 语法简洁,教程和社区资源一大堆。
- 灵活又能扩展:既能抓单页,也能批量爬上千页面,自动下载和处理图片。
- 省时又省钱:有测试显示,用 Python 抓 100 张图片只要 12 分钟,手动操作得花 2 小时()。
来看看常见的商业应用场景:
| 应用场景 | 手动操作的痛点 | Python 爬虫优势 |
|---|---|---|
| 产品图片整理 | 反复复制粘贴耗时 | 几分钟内批量下载上千张图片 |
| 竞品图片分析 | 信息遗漏、效率低 | 批量对比图片,快速洞察 |
| 趋势研究 | 数据集不完整 | 轻松收集大量多样化图片样本 |
| AI/ML 数据集构建 | 标注繁琐 | 自动采集并为训练做准备 |
| 房产图片收集 | 数据分散、更新慢 | 图片集中管理,随时更新 |
Python 图片爬虫必备工具
下面这些是常用的 Python 图片爬虫工具包:
| 库名称 | 主要功能 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| Requests | 通过 HTTP 获取网页和图片 | 静态网站 | 简单高效 | 不解析 HTML,不支持 JS |
| BeautifulSoup | 解析 HTML,查找 <img> 标签 | 提取图片链接 | 易用且容错性强 | 不支持 JS |
| Scrapy | 全功能爬虫/爬取框架 | 大型项目 | 异步高效,内置导出功能 | 学习曲线较陡 |
| Selenium | 自动化浏览器(支持 JS、滚动等) | 动态/JS 网站 | 可渲染 JS,模拟用户操作 | 速度较慢,配置较多 |
| Pillow (PIL) | 下载后处理图片 | 图片校验/编辑 | 支持图片缩放、格式转换等 | 仅用于处理,不负责爬取 |
怎么选?
- 静态网站:
requests + BeautifulSoup是首选组合。 - 动态页面(无限滚动、JS 图集):
Selenium更合适。 - 大型、重复性项目:
Scrapy提供结构化和高效支持。 - 图片后处理:
Pillow让你轻松整理和校验图片。
实操:用 Python 批量下载网页图片
下面以静态网站为例,演示如何用 Python 批量下载图片。
环境准备
先确保你装好了 Python 3。建议新建个虚拟环境:
1python3 -m venv venv
2source venv/bin/activate # Windows 用户用 venv\Scripts\activate安装需要的库:
1pip install requests beautifulsoup4查找并提取图片链接
This paragraph contains content that cannot be parsed and has been skipped.
示例脚本如下:
1import requests
2from bs4 import BeautifulSoup
3from urllib.parse import urljoin
4import os
5url = "https://example.com"
6response = requests.get(url)
7soup = BeautifulSoup(response.text, "html.parser")
8img_tags = soup.find_all("img")
9img_urls = [urljoin(url, img.get("src")) for img in img_tags if img.get("src")]小提示:有些网站用 data-src 或 srcset 做图片懒加载,记得也要检查。
下载并保存图片
把图片保存到本地文件夹:
1os.makedirs("images", exist_ok=True)
2> This paragraph contains content that cannot be parsed and has been skipped.
3**整理建议:**
4- 文件名可以用产品编号或页面标题命名。
5- 不同类别或来源建议用子文件夹分类。
6- 保存前可以比对链接或用哈希值去重。
7### 常见错误与排查
8- **图片没抓到?** 可能是 JS 动态加载,见下节。
9- **请求被拦截?** 设置合适的 User-Agent,并适当延时(`time.sleep()`)。
10- **重复下载?** 用集合记录已下载链接或文件名。
11- **权限报错?** 检查脚本是否有目标文件夹的写入权限。
12## 动态/JS 网站图片抓取方法
13有些网站喜欢“藏猫猫”——图片通过 JS、无限滚动或“加载更多”按钮动态加载。用 Selenium 就能轻松搞定。
14### 用 Selenium 抓取动态内容
15先装好 Selenium 和浏览器驱动(比如 ChromeDriver):
16```bash
17pip install selenium下载 ,并配置到 PATH。
Selenium 脚本示例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import time
4import os
5driver = webdriver.Chrome()
6driver.get("https://example.com/gallery")
7# 滚动到底部加载更多图片
8last_height = driver.execute_script("return document.body.scrollHeight")
9while True:
10 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
11 time.sleep(2) # 等待图片加载
12 new_height = driver.execute_script("return document.body.scrollHeight")
13 if new_height == last_height:
14 break
15 last_height = new_height
16img_elements = driver.find_elements(By.TAG_NAME, "img")
17img_urls = [img.get_attribute("src") for img in img_elements if img.get_attribute("src")]
18os.makedirs("dynamic_images", exist_ok=True)
19for i, img_url in enumerate(img_urls):
20 # (下载逻辑同上)
21 pass
22driver.quit()进阶建议:
- 用
WebDriverWait等待图片元素出现。 - 需要点击才能显示图片时,可以用
element.click()。
其他选择: Playwright(Python 版)在处理复杂网站时更快更稳定()。
零代码方案:用 Thunderbit 抓取网页图片
不是每个人都喜欢写代码或者折腾浏览器驱动。这时候, 就特别好用——它是一款零代码、AI 驱动的网页爬虫 Chrome 扩展,让图片提取像点外卖一样简单。
Thunderbit 图片提取操作指南
- 安装 Thunderbit:获取 。
- 打开目标网页:进入你想抓取图片的页面。
- 启动 Thunderbit:点击扩展图标,打开侧边栏。
- AI 智能识别字段:点击“AI 智能识别字段”,Thunderbit 的 AI 会自动扫描页面,识别所有图片并生成“图片”列()。
- 开始抓取:点击“抓取”,Thunderbit 会自动收集所有图片,包括子页面和无限滚动内容。
- 导出数据:可以把图片链接或文件一键导出到 Excel、Google Sheets、Notion、Airtable 或 CSV——免费版也不限量。
加分项: Thunderbit 免费图片提取器可以一键抓取页面所有图片链接()。
Thunderbit 的优势:
- 不用写代码,也不需要懂 HTML。
- 自动搞定动态内容、子页面和分页。
- 导出速度快还不限量(免费版同样适用)。
- AI 自动适应网页变化,无需维护脚本。
Python + Thunderbit:强强联合的图片抓取方案
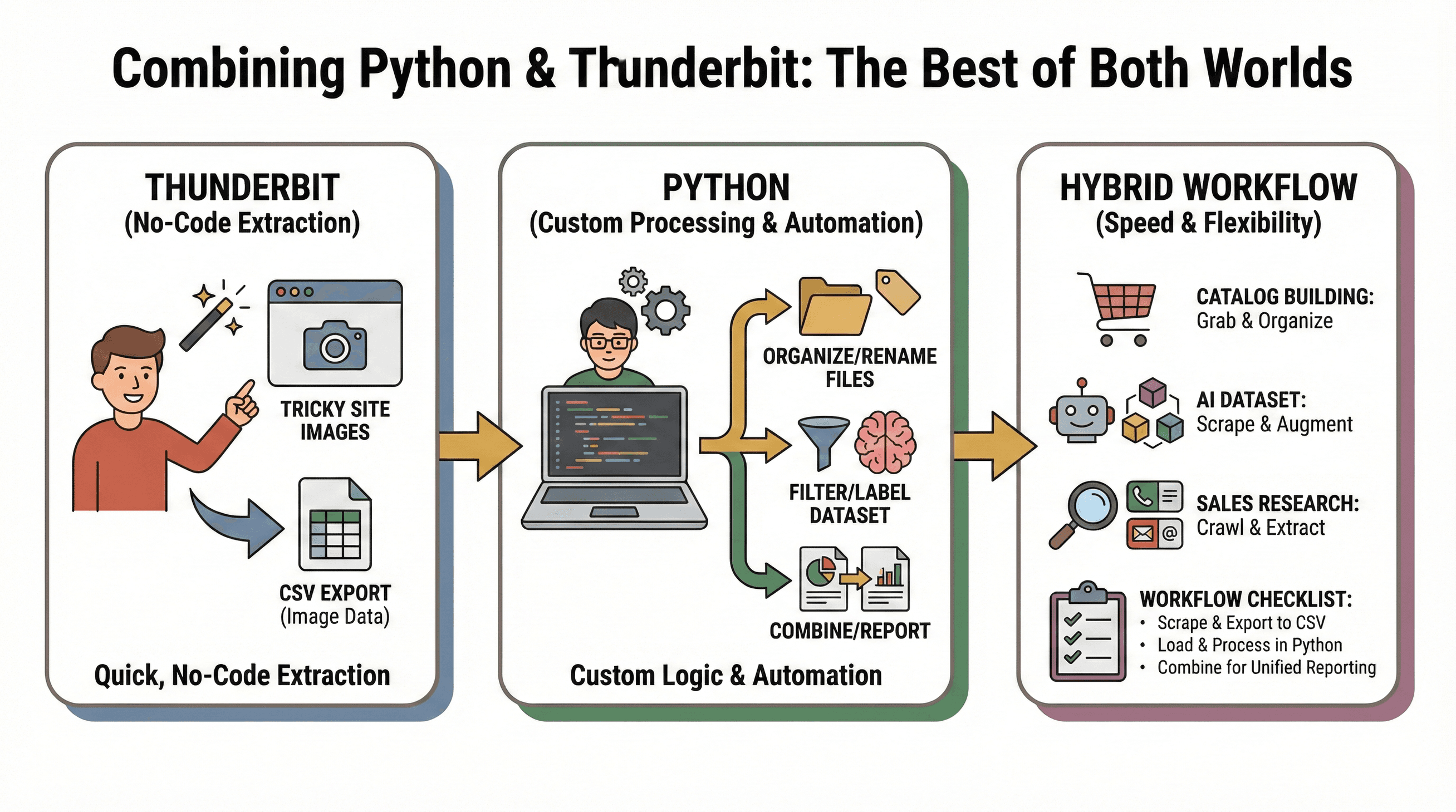 我最推荐的流程是:用 Thunderbit 快速无代码提取图片,再用 Python 做自定义处理或自动化。
我最推荐的流程是:用 Thunderbit 快速无代码提取图片,再用 Python 做自定义处理或自动化。
典型场景:
- 产品库搭建:用 Thunderbit 抓取难搞网站的图片,再用 Python 整理、重命名或批量处理。
- AI 数据集构建:Thunderbit 从多个站点抓图片,Python 脚本筛选、标注或增强数据集。
- 销售调研:Python 批量爬取公司网址,Thunderbit 提取每个站点的图片、邮箱或电话。
混合流程清单:
- 用 Thunderbit 抓取图片并导出为 CSV。
- 在 Python 里加载 CSV,做进一步分析或自动化处理。
- 合并多来源数据,实现统一报表。
这种组合方式既快又灵活,适应性超强,几乎能搞定所有网页图片抓取需求。
Python 图片爬虫常见问题与最佳实践
常见问题:
- 请求被拦截:设置 User-Agent,适当延时,遵守
robots.txt。 - 图片没抓到:遇到 JS 动态加载内容时,用 Selenium 或 Thunderbit。
- 重复下载:记录已抓取链接或用文件哈希去重。
- 文件损坏:用 Pillow 校验图片完整性。
最佳实践:
- 按网站、类别或日期清晰分类图片文件夹。
- 文件名尽量用产品编号、页面标题等有意义的命名。
- 过滤无关图片(比如广告、图标),可以通过文件大小或尺寸筛选。
- 抓取前一定要核查版权和网站服务条款,合规操作()。
Python 图片爬虫方案对比:代码 vs 零代码
来看看不同方案的对比:
| 对比维度 | Python(Requests/BS) | Selenium(Python) | Thunderbit(零代码) |
|---|---|---|---|
| 易用性 | 需编程,难度中等 | 需编程+浏览器自动化,难度较高 | 极易上手(点选+AI) |
| 动态内容支持 | 不支持 | 支持 | 支持 |
| 配置时间 | 安装+写代码,较长 | 驱动+代码,时间更长 | 安装扩展,极快 |
| 扩展性 | 手动,可并行 | 慢,浏览器开销大 | 高效(云端批量抓取 50 页) |
| 维护成本 | 高(网页变动易失效) | 高 | 低(AI 自动适应) |
| 导出方式 | 自定义(CSV、数据库) | 自定义 | 一键导出到 Excel、Sheets、Notion 等 |
| 成本 | 免费(开源) | 免费 | 免费版+高频付费 |
总结: 喜欢编程、追求极致自定义,Python 是不二之选。追求效率、简单和动态网页支持,Thunderbit 是救星。大多数团队结合两者用,效果最好。
总结与核心要点
互联网图片爆炸式增长,图片数据价值巨大但管理难度也随之提升。Python 图片爬虫让你高效自动化下载,Thunderbit 这类零代码工具则让图片抓取变得人人可用。
核心建议:
- 静态网站和自定义流程用 Python(Requests + BeautifulSoup)。
- 动态、JS 网站用 Selenium。
- 需要快速、零代码提取,尤其要导出到 Excel、Google Sheets、Notion 时,首选 Thunderbit。
- 两者结合,Thunderbit 负责数据采集,Python 负责后续处理和自动化,效率直接翻倍。
想提升图片抓取效率?不妨试试写个简单的 Python 脚本,或者,体验省时省力的图片采集。更多技巧和深度教程,欢迎访问 和 。
祝你抓图愉快,图片文件夹永远整整齐齐!
常见问题解答
This paragraph contains content that cannot be parsed and has been skipped.
2. 抓取网页图片常用的 Python 库有哪些?
最常用的有 Requests(获取网页)、BeautifulSoup(解析 HTML)、Selenium(处理动态内容)、Pillow(下载后图片处理)。
3. 如何抓取 JS 动态加载或无限滚动网站的图片?
用 Selenium 自动化浏览器,滚动页面,等内容加载后提取图片链接。Thunderbit 也能用 AI 自动处理动态内容。
4. 有零代码抓取网页图片的方法吗?
有!Thunderbit 是一款零代码 Chrome 扩展,利用 AI 自动识别并提取任意网站图片,只需点选即可导出到 Excel、Google Sheets、Notion 或 Airtable。
5. 可以结合 Python 和 Thunderbit 抓取图片吗?
当然可以。用 Thunderbit 快速无代码提取图片,再用 Python 进行高级处理或自动化。把 Thunderbit 导出的数据用 Python 脚本进一步处理,灵活又高效。
了解更多