

网页爬取已经从一项小众技能,变成了销售、运营或市场研究从业者的必备超能力。随着网页数据量暴增——全球数据创建量在 2019 年到 2023 年间几乎增长了 193%——难怪 81% 的公司 现在都把数据视为决策的“核心”。但问题在于:95% 的组织 表示,处理非结构化数据(比如杂乱的 HTML)是一大难题。我见过太多团队陷在漫长的复制粘贴里,拼命把网站信息整理进表格——相信我,这过程一点都不优雅。
用 AI 从任何网站抓取数据 Get Started Free
这时,Python 的 BeautifulSoup 就派上用场了。在这篇实战教程里,我会带你了解如何使用 BeautifulSoup 进行网页爬取,并给你一个可以直接套用到自己业务中的 Python Beautiful Soup 实例。因为我一直相信要更聪明地工作,而不是更辛苦,所以我还会演示如何把 BeautifulSoup 和 Thunderbit——我们的 AI 驱动网页爬虫——结合起来,帮你加快工作流程,拿到更干净、更结构化的数据;无论你的编程水平如何,都能上手。
什么是 BeautifulSoup,为什么要用它来做网页爬取?
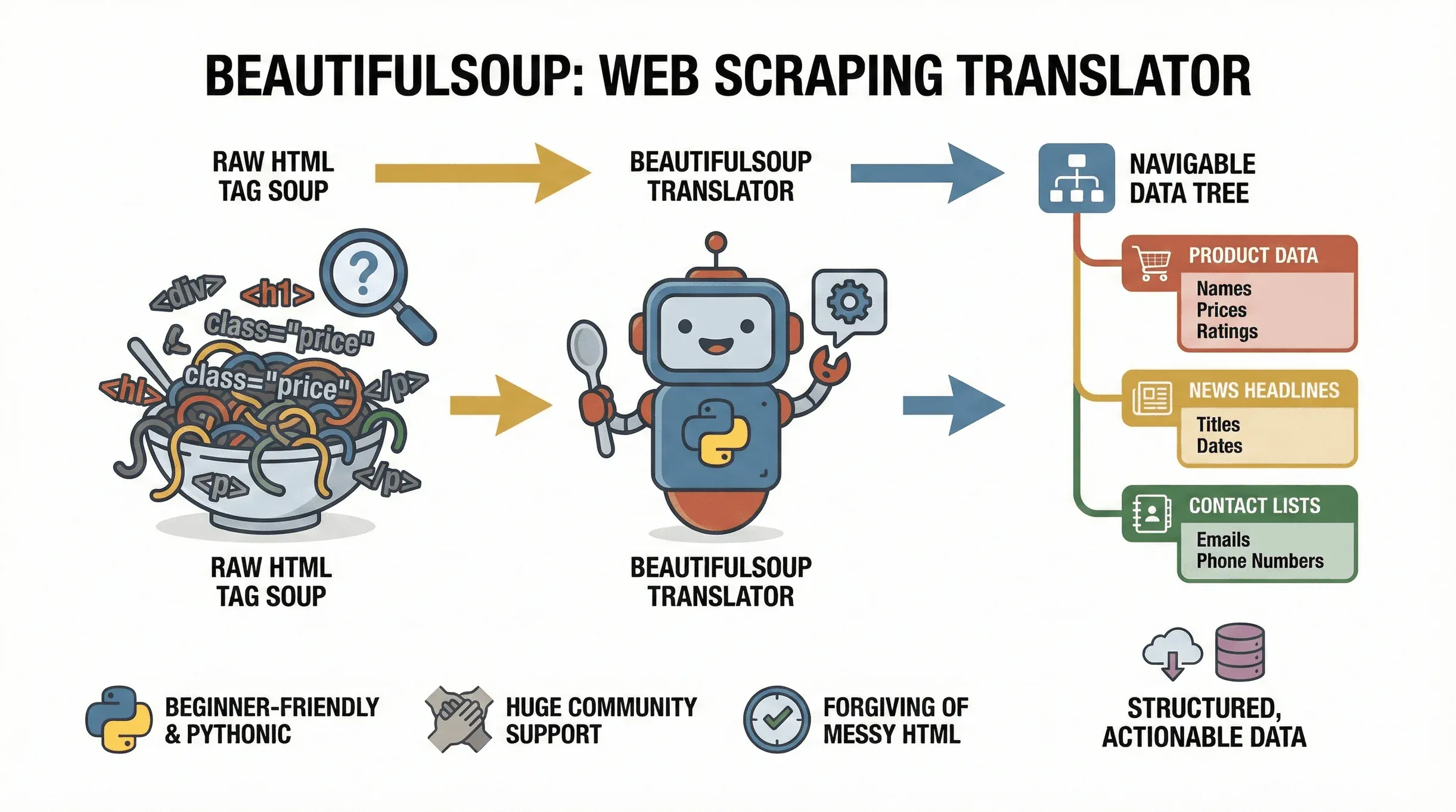 先从基础讲起。BeautifulSoup 是一个 Python 库,专门用来轻松解析 HTML 和 XML 文档。你可以把它理解成一个“翻译器”:它会把网页里乱七八糟的标签内容变成一棵可导航的树,这样你就能轻松查找、提取和处理所需数据。这个项目至今仍在积极维护——
先从基础讲起。BeautifulSoup 是一个 Python 库,专门用来轻松解析 HTML 和 XML 文档。你可以把它理解成一个“翻译器”:它会把网页里乱七八糟的标签内容变成一棵可导航的树,这样你就能轻松查找、提取和处理所需数据。这个项目至今仍在积极维护——beautifulsoup4 4.14.3 已于 2025 年底发布到 PyPI——所以你在这里学到的内容依然是最新的。无论你是想从电商网站提取商品价格、收集新闻标题,还是从商业目录网站抓取潜在客户,BeautifulSoup 都是把网页转成结构化、可行动数据的首选工具。
它为什么这么受欢迎?首先,它对新手非常友好。BeautifulSoup 对杂乱的 HTML 很宽容(说真的,网页本来就常常很乱),而且它的 Python 风格语法意味着你只需要几行代码,就能从零开始抓取数据。它的支持也很广泛,下载量巨大,社区也很活跃——所以如果你卡住了,去 Google 一搜通常就能找到答案。
BeautifulSoup 的典型使用场景包括:
- 从电商页面提取商品名称、价格和评分
- 从新闻网站抓取标题、作者和发布时间
- 解析表格或名录(比如公司列表或联系人列表)
- 从分类信息网站收集邮箱或电话号码
- 监测更新(价格变化、新职位发布等)
如果你的数据藏在静态 HTML 里,BeautifulSoup 就是你做网页爬取的好帮手。
BeautifulSoup 做网页爬取的独特优势
Python 网页爬虫库有很多——那为什么偏偏选 BeautifulSoup?它和其他工具相比,优势主要体现在这些方面:
- 简单易用: BeautifulSoup 轻量、上手快。你不需要搭建整套框架,也不必写一大堆样板代码。它特别适合快速、一次性的爬取任务,也很适合刚入门的新手。
- 容错性强: 它能处理损坏或不规范的 HTML,这种情况比你想象的更常见。
- 灵活: 你不必被固定的爬虫架构束缚。只要把 HTML 喂给它,再提取你需要的内容就行。
- 易集成: BeautifulSoup 能和其他 Python 库很好地配合,比如
requests(抓取网页)、csv(保存数据)和pandas(数据分析)。
它和其他工具相比如何?
| 工具 | 最适合 | 优点 | 缺点 |
|---|---|---|---|
| BeautifulSoup | 静态 HTML 解析、新手入门 | 简单、上手快、容错性强、灵活 | 不适合大量 JavaScript 的网站 |
| Scrapy | 大规模、异步任务 | 功能强、可扩展、内置爬取能力 | 学习曲线更陡,配置更多 |
| Selenium | JavaScript/动态内容 | 能与 JS 交互、填写表单、点击按钮 | 更慢、更重、资源消耗更高 |
如果你刚开始学,或者只需要快速解析静态页面,BeautifulSoup 就像网页爬取里的“瑞士军刀”(medium.com)。对于更复杂或动态的网站,你也许会把它和 Selenium 或 Scrapy 结合使用——但要学会入门,BeautifulSoup 是最好的起点。
为 BeautifulSoup 配置 Python 环境
准备开始了吗?下面是配置环境的方法:
-
安装 Python: 从 python.org 下载最新版本。
-
创建虚拟环境(可选,但推荐):
python -m venv venv source venv/bin/activate # 在 Windows 上:venv\Scripts\activate -
安装 BeautifulSoup 和依赖项:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4:主库requests:用于抓取网页lxml或html5lib:更快/更稳定的 HTML 解析器
-
故障排查建议:
- 如果你遇到“找不到 pip”的错误,可以试试
pip3或py -m pip。 - 在 Mac/Linux 上,你可能需要使用
sudo才有权限。 - 如果你用的是 Windows,记得把 Python 加入 PATH。
- 如果你遇到“找不到 pip”的错误,可以试试
要验证环境是否配置成功,可以运行这段快速测试代码:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
如果你看到 <title>Example Domain</title>,那就说明一切正常了(Thunderbit Blog)。
一步一步的 Python Beautiful Soup 示例
下面我们来看看一个真实的 python beautiful soup 示例。假设你想从一个公开新闻网站提取最新新闻标题,做法如下:
1. 抓取网页
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. 解析 HTML
soup = BeautifulSoup(html, "html.parser")
3. 检查 HTML 结构
打开浏览器的开发者工具(右键 → 检查),找出包含标题的标签。在很多新闻网站上,标题会放在带有特定类名的 <h3> 标签里。
比如,你可能会看到:
<h3 class="gs-c-promo-heading__title">标题</h3>
4. 提取数据
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
这样就会把页面上的所有新闻标题打印出来。
5. 将数据保存为 CSV
把这些标题保存下来,方便后续分析:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["headline"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
这样你就得到了一个可以直接导入 Excel 或 Google Sheets 的 CSV 文件。
理解 HTML 结构,才能高效提取数据
在写任何代码之前,都要先检查页面的 HTML。方法如下:
- 打开开发者工具: 在页面上右键,选择“检查”。
- 找到数据: 把鼠标悬停在元素上,看看哪些标签包含你要的信息(比如标题、价格、作者)。
- 注意标签和类名: 留意像
class="product-title"或id="main-content"这样的唯一标识。 - 测试选择器: 使用 BeautifulSoup 的
.find()、.find_all()或.select()方法来定位这些元素。
小技巧:可以用 soup.prettify() 在 Python 控制台里输出更易读的 HTML。
使用 BeautifulSoup 提取并结构化数据
假设你想从一个博客页面提取标题和作者:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
现在你得到的是一个字典列表——非常适合导出到 CSV,或者继续做进一步分析。
你还可以这样提取链接、图片或任何属性:
for link in soup.find_all("a"):
print(link.get("href"))
或者提取图片:
for img in soup.find_all("img"):
print(img.get("src"))
保存提取的数据:从 Python 到 Excel 或 CSV
数据结构整理好之后,导出就很简单了。下面是用 csv 模块保存的方法:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
如果你更喜欢 pandas,也可以这样做:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
一定要使用 UTF-8 编码,避免出现奇怪的字符问题,尤其是在处理国际化数据时。
案例研究:使用 BeautifulSoup 抓取新闻网站数据
下面我们来走一遍一个实用的 python beautiful soup 示例:从新闻网站抓取文章标题、作者和发布日期。
假设你想从 CNN 抓取文章数据:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
这段脚本会抓取最新文章,提取标题、日期和作者,并保存到 CSV 文件中——前提是 CNN 当前的页面结构仍然和上面的标签匹配。大型新闻网站会经常更换类名和 DOM 结构,所以在正式抓取生产数据之前,最好重新检查页面。结构本身(先用 <article> 容器,再对其子标签使用 find)才是更稳妥的模式;而像 "date" 和 "author" 这样的具体类名只是占位符,你需要根据当前网页实际内容进行调整。
提升你的工作流:把 BeautifulSoup 和 Thunderbit 结合起来
现在我们来聊聊,怎么把你的爬取流程做得更顺滑。Thunderbit 是一款 AI 驱动的网页爬虫 Chrome 扩展,可以帮你省去数据提取中的大量猜测。使用 Thunderbit,你可以:
- 使用“AI 建议字段”: Thunderbit 会读取页面,并自动建议该提取哪些数据字段——再也不用在 HTML 里翻来翻去或反复调选择器了。
- 抓取子页面: Thunderbit 可以跟随链接进入子页面(比如单个商品页或文章页),为你的数据集补充更多细节。
- 一键导出: 只需点击一次,就能把数据直接发送到 Excel、Google Sheets、Airtable 或 Notion。
- 处理分页: Thunderbit 可以跨多个页面抓取数据(包括无限滚动)。
- 定时抓取: 设置周期性任务,让数据保持最新。
下面是我很喜欢的一种混合工作流:
- 先用 Thunderbit: 打开目标网站,点击 Thunderbit 图标,让“AI 建议字段”识别合适的列(比如标题、作者、日期)。
- 导出数据: 将结果下载为 CSV,或者直接发送到 Google Sheets。
- 再用 BeautifulSoup 做自定义处理: 如果你还需要更深入的分析(比如文本清洗、去重,或者和其他数据源合并),就把导出的 CSV 导入 Python,然后使用 BeautifulSoup 或 pandas 做后处理。
这个组合能让你两头兼得:既有 Thunderbit 的速度和 AI 驱动字段识别,又有 BeautifulSoup 在自定义逻辑上的灵活性。
速度和数据质量:为什么要把 Thunderbit 和 BeautifulSoup 一起用?
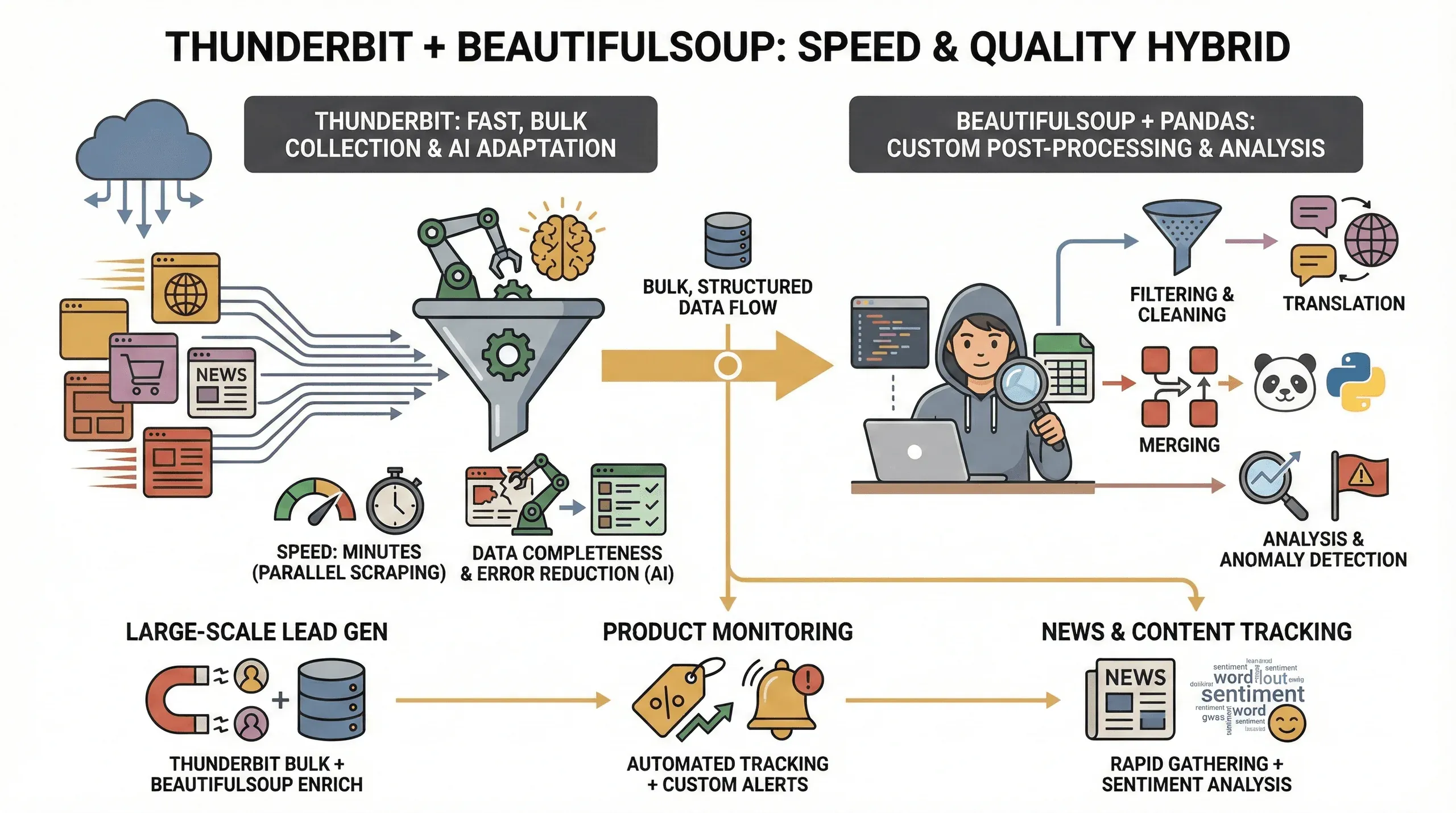 为什么要同时用这两个工具?以下是我的经验:
为什么要同时用这两个工具?以下是我的经验:
- 速度快: Thunderbit 可以并行抓取几十个页面(云端模式下最多可同时 50 个),让你在几分钟内拿到数据,而不是几小时。
- 数据更完整: Thunderbit 的 AI 会适应页面布局变化,即使面对复杂网站也能提取结构化数据,减少遗漏字段的概率。
- 错误更少: 类名一变脚本就坏掉的情况再也没那么烦人了——Thunderbit 的 AI 每次都会重新评估页面。
- 自定义后处理: 如果你有更高级的需求(比如过滤、翻译或合并数据集),BeautifulSoup 和 pandas 能让你完全掌控流程。
这种混合方案尤其适合:
- 大规模线索挖掘: 用 Thunderbit 抓取主体数据,再用 BeautifulSoup 清洗和补充。
- 商品监测: Thunderbit 负责重复性抓取,BeautifulSoup 则帮你分析趋势或标记异常。
- 新闻和内容跟踪: 先用 Thunderbit 快速收集文章,再用 Python 做情感分析或关键词提取。
BeautifulSoup 网页爬取常见问题排查
试用 Thunderbit Chrome 扩展 2 次点击即可用 AI 抓取任何网站。 Get Started Free
网页爬取并不总是一帆风顺——下面是一些常见坑和解决办法:
- 动态内容: 如果网站用 JavaScript 加载数据(无限滚动、AJAX),单靠 BeautifulSoup 是看不到的。这种情况下可以用 Selenium,或者使用 Thunderbit 的浏览器模式。
- 反爬机制: 有些网站会拦截自动化请求。你可以尝试设置自定义 User-Agent 请求头、在请求之间加入延迟,或者使用 Thunderbit 的云端抓取来绕过一些简单限制。
- HTML 结构变化: 如果脚本突然坏了,很可能是网站的 HTML 变了。重新检查页面并更新选择器。Thunderbit 的 AI 也能在这方面帮上忙,因为它会自动适应变化。
- 数据缺失: 在调用
.get_text()之前,先判断元素是否存在。属性值请用.get()而不是[],这样可以避免 KeyError。 - 编码问题: 保存文件时使用 UTF-8 编码,才能正确处理特殊字符。
还有一点始终要记住:一定要遵守 robots.txt 和网站的服务条款。负责任地抓取数据——没人喜欢没礼貌的机器人。
结论与要点总结
在如今这个数据驱动的世界里,使用 BeautifulSoup 进行网页爬取,是你能学到的最实用技能之一。下面是这篇 beautifulsoup web scraping 教程里我们讲到的重点:
- BeautifulSoup 是解析静态 HTML、用 Python 提取结构化数据的理想起点。
- 环境配置 非常简单——安装 Python、pip 和几个库就够了。
- 检查 HTML 是精准定位数据的关键。
- 导出到 CSV/Excel 能让你的数据立刻用于业务分析。
- 结合 Thunderbit 可以获得 AI 驱动的字段识别、更快的抓取速度和更轻松的导出——非常适合业务用户和非程序员。
- 混合工作流(Thunderbit 负责批量提取,BeautifulSoup 负责自定义处理)能在速度、数据质量和灵活性上取得最佳平衡。
如果你已经准备好提升你的网页爬取能力,不妨把两个工具都试一试:先写一个简单的 BeautifulSoup 脚本练手,再看看使用 Thunderbit 的 AI 网页爬虫 能把效率提升到什么程度。想看更多实操指南,也可以访问 Thunderbit Blog。
祝你爬取顺利——愿你的数据始终干净、结构清晰,并随时可用。
试用 Thunderbit AI 网页爬虫 Get Started Free
常见问题
1. 什么是 BeautifulSoup,它有什么用途?
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库。它可以帮你从网页中提取数据,并把数据整理成列表或表格等结构化格式,非常适合网页爬取项目。
2. BeautifulSoup 和 Selenium、Scrapy 比起来有什么区别?
BeautifulSoup 轻量、易上手,适合静态 HTML 页面。Selenium 更适合抓取动态、JavaScript 较多的网站,而 Scrapy 则是一个功能完整的框架,适合大规模、异步爬取。对于新手和快速任务来说,BeautifulSoup 是最佳选择。
3. 我可以把 BeautifulSoup 和 Thunderbit 一起用吗?
当然可以。Thunderbit 可以借助 AI 快速识别并提取网页字段,而你可以用 BeautifulSoup 对导出的数据进行自定义后处理或更深入的分析。
4. 使用 BeautifulSoup 进行网页爬取时,常见挑战有哪些?
常见问题包括处理动态内容、应对反爬措施,以及适应 HTML 结构变化。使用 Thunderbit 的 AI 功能或浏览器模式,可以帮助你解决很多这类难题。
5. 如何把用 BeautifulSoup 抓取的数据导出到 Excel 或 CSV?
你可以使用 Python 内置的 csv 模块,或者 pandas 库,把提取的数据写入 CSV 或 Excel 文件。记得始终使用 UTF-8 编码,这样才能处理特殊字符,并保证和表格工具兼容。
想自己试试吗?下载 Thunderbit 的 Chrome 扩展,今天就开始更聪明地抓取数据吧。想看更多教程和技巧,请访问 Thunderbit Blog。
了解更多




