

在网上冲浪时,谁没遇到过各种要填的表单、反复刷的仪表盘,还有一堆要处理的数据?我自己就经常在心里吐槽:“难道每次都得手动点来点去?”其实你不是一个人在战斗。2024 年,Python 正式超越 JavaScript,成为 GitHub 上最受欢迎的编程语言,差不多有四分之一的 Python 开发者都在用它搞自动化和网页爬取(GitHub Octoverse, JetBrains Survey)。为啥?因为 Python 让网站自动化变得又简单又实用,哪怕你不是程序员也能轻松上手。
这篇文章会带你系统了解 python 自动化网站操作的全流程。我们会聊聊为啥 Python 是首选,怎么搭建自动化环境,Selenium 填表单和网页导航的实用技巧,还有像 Thunderbit 这样的 AI 工具怎么让自动化更上一层楼。不管你是厌倦重复操作的打工人,还是想提升效率的开发者,都能在这里找到用 python 自动化网页任务的实用方法、代码例子和我的亲身经验。
为什么用 Python 做网站自动化?
使用 AI 从任何网站抓取数据 Get Started Free
先说重点:为啥选 Python?我的体会和开发圈的共识是,Python 就像自动化领域的“瑞士军刀”。理由很简单:
- 语法简单易懂: Python 代码清晰,容易上手。就算你不是专业开发者,也能看懂、改动 Python 脚本,不会有“天书”那种挫败感(Monterail)。
- 生态丰富: Python 有一堆专门做网页自动化的库,最常用的三大件:
- Selenium: 模拟真实用户在浏览器里的各种操作,比如点击、输入、跳转等(BlazeMeter)。
- Requests: 直接发 HTTP 请求,获取网页或 API 数据,不用开浏览器(Requests Docs)。
- BeautifulSoup: 解析和提取 HTML 或 XML 数据(BeautifulSoup Docs)。
- 社区活跃: 遇到问题,Stack Overflow 或各种博客上基本都能找到答案。
- 跨平台兼容: Python 脚本能在 Windows、macOS、Linux 上无缝跑。
和 Java、C# 这些语言比,Python 用更少的代码就能搞定更多自动化任务,开发效率高。虽然 JavaScript 也能做浏览器自动化,但 Python 的库和文档对大多数业务自动化场景更友好(ActiveBatch)。
Python 自动化环境搭建指南
在开始自动化之前,先把工具准备好。无论你用的是 Windows、macOS 还是 Linux,推荐这样搭建 Python 自动化环境:
1. 安装 Python 和 Pip
- Windows: 去 python.org 下载 Python 3,安装时记得勾选“Add Python to PATH”。
- macOS: 可以用官方安装包,或者 Homebrew 用户直接
brew install python3。 - Linux: 大多数发行版自带 Python。如果没有,用包管理器装:
sudo apt-get install python3 python3-pip。
验证安装:
python3 --version
pip --version
如果找不到 pip,可能要单独装一下(Ubuntu 下:sudo apt-get install python3-pip)。
2. 安装 Selenium 及其他依赖库
Python 和 pip 搞定后,装常用库:
pip install selenium requests beautifulsoup4
- Selenium:浏览器自动化
- Requests:HTTP 请求
- BeautifulSoup:HTML 解析
3. 下载浏览器驱动(Selenium 专用)
Selenium 需要浏览器驱动。用 Chrome 就下 ChromeDriver,用 Firefox 就下 geckodriver。
- 把驱动放到系统 PATH 目录,或者在脚本里指定路径:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="/path/to/chromedriver")
新版 Selenium 如果驱动在 PATH 里,通常能自动识别。
4. 建立虚拟环境
用虚拟环境(比如 venv 或 virtualenv)可以隔离项目依赖,避免版本冲突(Real Python)。
创建并激活虚拟环境:
python3 -m venv myenv
source myenv/bin/activate # Windows 下用 myenv\Scripts\activate
之后,pip install 只影响当前项目。
5. 各系统常见问题与小技巧
- Windows: 如果
python或pip无法识别,检查是否加到 PATH,或者用py启动。 - macOS: 用
python3替代python,避免和系统自带版本混淆。 - Linux: 服务器没界面时,Selenium 可以用 headless 模式或配 Xvfb。
遇到驱动版本或依赖问题,建议查查兼容性并及时更新。
用 Selenium 自动化表单填写与网页导航
接下来就是实操环节:让浏览器听你指挥。Selenium 是主力,可以自动化从简单登录到多步骤流程的各种操作。
启动浏览器并打开网页
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
这段代码会打开 Chrome 并进入登录页。
定位和操作页面元素
Selenium 支持按 ID、name、CSS 选择器、XPath 等多种方式查找元素:
username_box = driver.find_element(By.ID, "username")
password_box = driver.find_element(By.NAME, "pwd")
login_button = driver.find_element(By.XPATH, "//button[@type='submit']")
- 输入文本:
username_box.send_keys("alice") - 点击按钮:
login_button.click() - 下拉选择:
from selenium.webdriver.support.ui import Select
select_elem = Select(driver.find_element(By.ID, "country"))
select_elem.select_by_visible_text("Canada")
- 跳转页面:
driver.get("https://example.com/profile")
元素选择的最佳实践
- 优先用 ID 或唯一属性,定位更稳定。
- CSS 选择器 简洁高效。
- 避免用绝对 XPath,页面结构一变就容易失效(Medium)。
处理动态内容与等待
现在的网站经常异步加载内容。如果脚本太快,按钮还没出来就会报错。推荐用 显式等待:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "loginBtn")))
这样最多等 10 秒,直到登录按钮可点击。显式等待比 time.sleep() 更智能、更靠谱(BrowserStack)。
示例:自动化多步骤网页表单
以一个两步注册流程为例(用公开演示站点):
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://practicetestautomation.com/Practice-Signup")
# 第一步:填写第一个表单
driver.find_element(By.ID, "name").send_keys("Alice")
driver.find_element(By.ID, "email").send_keys("alice@example.com")
driver.find_element(By.ID, "password").send_keys("SuperSecret123")
driver.find_element(By.ID, "nextBtn").click()
# 第二步:等待并填写第二个表单
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "address")))
driver.find_element(By.ID, "address").send_keys("123 Maple St")
driver.find_element(By.ID, "phone").send_keys("5551234567")
driver.find_element(By.ID, "submitBtn").click()
# 第三步:确认注册成功
WebDriverWait(driver, 5).until(EC.text_to_be_present_in_element((By.TAG_NAME, "h1"), "Welcome"))
print("注册成功!")
driver.quit()
这个脚本会自动填写两步表单,等待每一步加载,并检查是否注册成功。这种模式在实际项目中非常常见。
Thunderbit:AI 驱动的复杂网页自动化
试用 Thunderbit Chrome 插件 用 AI 几步搞定网页数据提取和自动化流程,无需写代码。 Get Started Free
说到这里,很多人会问:如果遇到结构混乱的网站、需要从 PDF 或图片中提取数据,或者根本不想写代码怎么办?这就是 Thunderbit 的用武之地。
Thunderbit 是一款 AI 网页爬虫 Chrome 插件,只需几步点击就能自动提取网页数据、执行网页操作,无需编程。它对企业用户尤其友好,原因如下:
- 自然语言指令: 只需描述你想要的数据(比如“产品名、价格、评分”),Thunderbit 的 AI 就能自动识别并提取(Futurepedia)。
- 子页面抓取: 需要每个产品详情页的数据?Thunderbit 能自动访问子页面并汇总到表格。
- 一键模板: 针对 Amazon、Zillow 等热门网站,内置一键模板,开箱即用。
- 支持 PDF 和图片: 能直接提取 PDF(包括扫描件)和图片中的文字,Python 需要额外配置才能实现。
- 定时爬取: 用自然语言设置定时任务(比如“每周一上午 9 点”)。
- 免费导出数据: 支持导出到 Excel、Google Sheets、Airtable、Notion、CSV、JSON,完全免费。
Thunderbit 特别适合把杂乱无章的网页内容转成结构化数据,也能让非技术同事自己动手自动化流程。就像有个 AI 助理,帮你搞定所有重复性工作。
什么时候用 Thunderbit,什么时候用 Python 脚本?
-
用 Python(Selenium/Requests/BeautifulSoup):
- 需要自定义逻辑、集成或精细控制时。
- 需要做网页爬取以外的工作(比如数据分析、API 调用、复杂条件判断)。
- 熟悉编程、希望用版本管理工具维护代码时。
-
用 Thunderbit:
- 需要快速、无代码提取数据或自动化网页操作。
- 面对结构混乱、格式多样(比如 PDF、图片)的网站。
- 希望让非开发同事也能轻松自动化,或需要频繁、临时性的数据采集。
实际工作中,我经常两者结合:用 Thunderbit 快速原型或赋能销售/运营团队,用 Python 脚本做深度集成和定制化流程。
如何让 Python 自动化脚本更稳定可靠
自动化的价值在于稳定可靠。以下是我保证脚本长期运行顺畅的经验:
错误处理与重试机制
用 try/except 包裹容易出错的操作:
try:
element = driver.find_element(By.ID, "price")
except Exception as e:
print("查找价格元素出错:", e)
driver.save_screenshot("screenshot_error.png")
# 可选择重试或跳过
遇到网络波动或元素偶尔加载失败时,加个简单的重试逻辑:
import time
max_retries = 3
for attempt in range(max_retries):
try:
driver.get(url)
break
except Exception as e:
print(f"第 {attempt+1} 次尝试失败,正在重试...")
time.sleep(5)
全程用显式等待
不要假设元素总是立刻可用。每次操作前都用显式等待:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "result"))).click()
日志与监控
长时间运行的脚本建议用 Python 的 logging 模块记录进度和错误。遇到严重故障可以发邮件或 Slack 通知自己。出错时记得截图,方便排查。
资源管理
脚本结束时一定要调用 driver.quit(),避免后台残留浏览器进程。
限速与友好爬取
批量抓取时,建议加点随机延时(比如 time.sleep(random.uniform(1,3))),避免被封。遵守 robots.txt,不要给服务器带来压力。
适应网站变化
网页会变,ID 会改,布局会调整,弹窗会冒出来。我的建议:
- 用灵活的定位方式: 优先选稳定属性或
data-*属性,少用脆弱的 XPath。 - 集中管理选择器: 把所有选择器集中放在脚本顶部,方便统一维护。
- 定期测试: 定期跑脚本,及时发现问题。
- 版本管理: 用 Git 跟踪脚本变更,出问题能快速回滚。
如果是内部系统,可以和前端同事沟通,专门加上 data-automation-id 这类钩子。
Python 自动化工具对比:Selenium、Requests、BeautifulSoup 与 Thunderbit
下面这张表帮你快速选对工具:
| 工具 | 优势与适用场景 | 局限与注意事项 |
|---|---|---|
| Selenium (WebDriver) | 全浏览器自动化,支持动态 JS,模拟真实用户操作,适合多步骤流程 | 速度较慢、资源占用高、需配置驱动,选择器不稳时易出错 |
| Requests + BeautifulSoup | 静态页面/API 抓取快且轻量,HTML 解析简单,适合批量数据提取(无 JS 需求) | 无法处理动态 JS,不能模拟用户操作,需手动解析逻辑 |
| Thunderbit | 无代码、AI 驱动,支持结构混乱网站、PDF、图片、子页面抓取,一键模板,免费导出,适合非开发者 | 灵活性略逊,依赖外部服务,AI 建议有时需微调 |
实战流程:用 Python 自动化网站操作的 7 步法
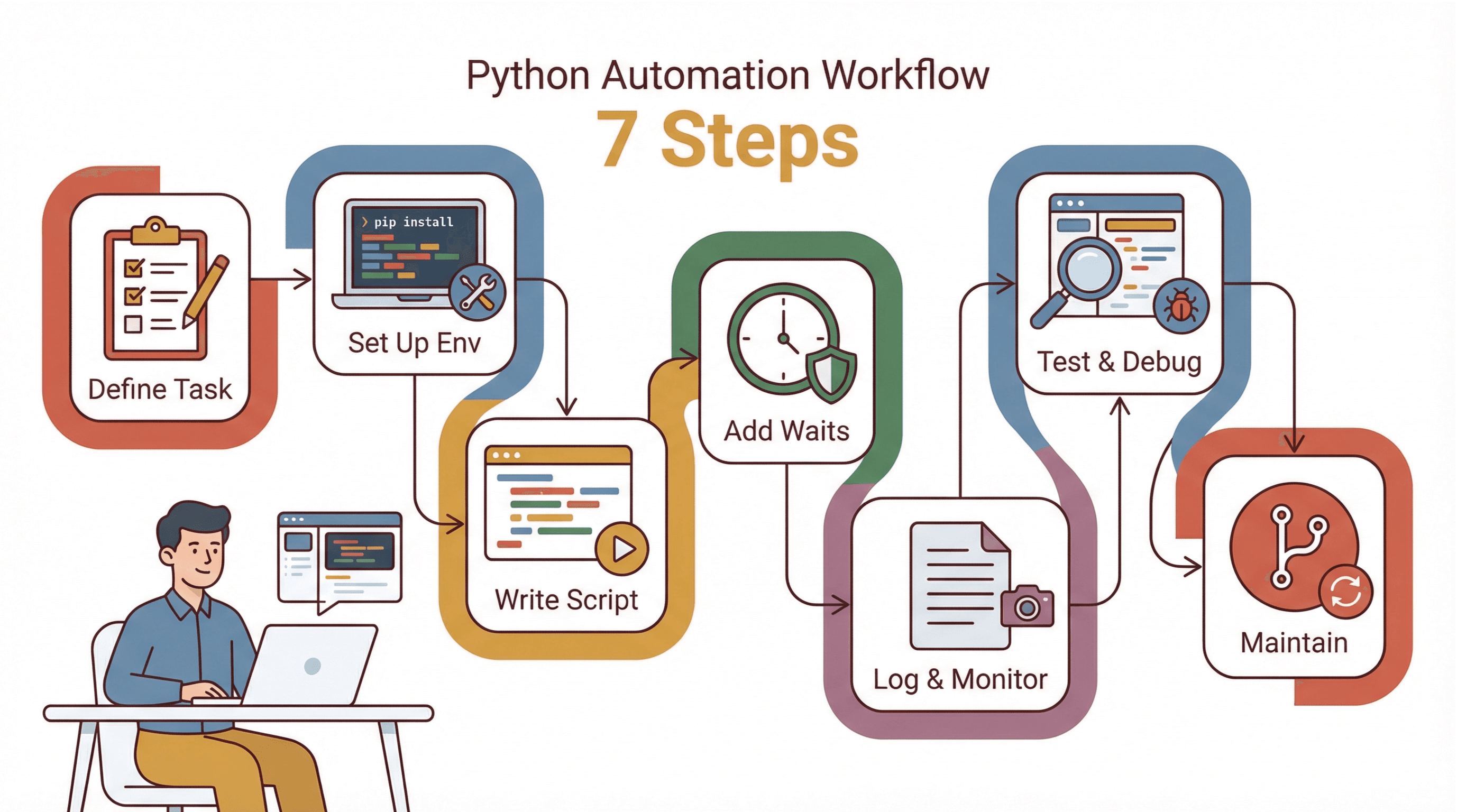 我的常用自动化网站任务清单如下:
我的常用自动化网站任务清单如下:
- 明确任务目标: 先写下手动操作的每一步,找出难点(比如登录、弹窗、动态内容)。
- 环境搭建: 安装 Python、pip、虚拟环境、Selenium 和浏览器驱动。
- 逐步编写脚本: 先实现基础导航,再逐步添加交互,每加一步都测试。
- 加等待与错误处理: 用显式等待,关键步骤加 try/except。
- 日志与监控: 记录进度和错误,出错时截图。
- 测试与调试: 用浏览器开发者工具验证选择器,建议可视化运行,观察弹窗或跳转。
- 维护与更新: 选择器集中管理,用版本控制,定期检查脚本。
新手建议从小任务入手,比如自动登录测试站点或填写简单表单。每完成一次,信心和技能都会提升。
总结与实用建议
用 Python 自动化网站操作,是提升效率、解放双手的绝佳方式。Python 语法友好,库强大,无论是简单表单还是复杂多步骤流程都能轻松搞定。社区资源丰富,生产力提升立竿见影——每天省下 15 分钟,一年就是近 90 小时(LinkedIn)。
但别忘了,有时候最快的办法是用 AI 工具,比如 Thunderbit。面对结构混乱的网站,或想让非技术同事也能自动化,Thunderbit 只需几步点击就能搞定数据提取和网页操作。
我的建议:从你最常做、最烦的网页任务入手。用 Python 或 Thunderbit 试着自动化一次,你会发现“又要重复操作”很快就能变成“几秒钟搞定”。
想深入了解网页爬取,欢迎访问 Thunderbit 博客 获取更多实用教程和技巧。
常见问题解答
1. 为什么 Python 在网站自动化领域这么受欢迎?
Python 语法易读,库丰富(如 Selenium、Requests、BeautifulSoup),社区活跃,是网页自动化和脚本开发的首选(GitHub Octoverse)。
2. Selenium、Requests 和 BeautifulSoup 有什么区别?
Selenium 用于自动化真实浏览器,适合动态页面和用户操作。Requests 用于无浏览器抓取网页或 API,适合静态内容。BeautifulSoup 主要解析 HTML,通常和 Requests 搭配使用。
3. 什么时候用 Thunderbit,什么时候用 Python 脚本?
需要无代码、AI 驱动的数据提取(比如结构混乱网站、PDF、图片)或让非技术同事参与时选 Thunderbit。需要自定义逻辑、集成或复杂流程时选 Python 脚本。
4. 如何让 Python 自动化脚本更稳定?
用显式等待、try/except 错误处理、网络重试和日志监控。选择器集中管理,网站变动时及时更新。
5. Thunderbit 和 Python 可以结合用吗?
当然可以!用 Thunderbit 快速采集数据,再用 Python 进一步处理分析;或用 Python 实现复杂逻辑,Thunderbit 负责高效无代码爬取。
想马上体验网页自动化?试试 Thunderbit 免费 Chrome 插件,或者动手写个 Python 脚本。不管哪种方式,你都能更高效地完成工作。
试用 AI 网页爬虫 Get Started Free
延伸阅读




