

在电商行业飞速发展的今天,紧盯竞争对手的价格波动、追踪新品上架、分析客户评价趋势,早已不是可有可无的选项,而是生存的必修课。过去,想要搞到这些情报,往往得面对一堆复杂工具、杂乱无章的表格,甚至还得硬着头皮啃开发者写的 Python 脚本。现在,随着像 Playwright 这样的浏览器自动化工具出现,网页数据采集变得前所未有的强大,但对大多数业务用户来说,技术门槛依然不低。好在现在有了 AI 驱动的工具,比如 Thunderbit,就算你不会编程,也能几分钟内轻松搞定所需数据。
这篇指南会带你快速了解如何用 Playwright 做网页爬取(以 eBay 实战为例),剖析新手常见的难题,并展示 Thunderbit AI 网页爬虫如何让数据采集变得又快又简单——特别适合销售、市场、运营等只想拿到数据、又不想变身 Python 工程师的你。
什么是 Playwright?新手入门介绍
先来聊聊:Playwright 到底是啥?
Playwright 是微软推出的一款浏览器自动化框架。你可以把它当成网页浏览器的“遥控器”——不仅能用代码控制,还支持多种浏览器(Chromium、Firefox、WebKit)和多种语言(Python、JavaScript/Node.js、Java、C#)。有了 Playwright,你可以自动化点击按钮、填写表单,甚至抓取那些需要 JavaScript 渲染后才显示的动态内容。
为什么 Playwright 对网页爬取这么重要?传统的爬虫工具像 requests 和 BeautifulSoup 只适合静态页面,遇到现代、依赖 JavaScript 的网站就束手无策了。而 Playwright 能模拟真实用户操作,轻松搞定动态元素。它就像一个永远不喊累、也不用加薪的“机器人实习生”。
Playwright 和 Selenium、Puppeteer 有啥区别?
- Selenium:浏览器自动化的“老大哥”,支持多语言,但速度慢、操作繁琐。
- Puppeteer:谷歌出品,专注于 Chromium 浏览器,速度快但默认只支持 Chrome/Chromium。
- Playwright:天生跨浏览器,速度比 Selenium 快,API 设计更现代、好用,已经成了很多自动化和爬虫项目的首选(数据参考)。
为什么用 Playwright 做网页爬取?
如果你是销售、运营、电商从业者,Playwright 能带来哪些好处?
Playwright 的亮点有:
- 轻松搞定 JavaScript 动态网站:特别适合抓取 eBay 这类电商巨头,产品数据都是动态加载的。
- 自动化用户操作:比如点击“下一页”、滚动页面、筛选、登录等,完全模拟真人操作。
- 支持无头模式:不用打开浏览器窗口,后台静默运行,效率更高。
- 智能等待机制:自动等内容加载完再抓取,减少出错和数据丢失(详细说明)。

实际案例:
假如你经营一家电商店铺,想实时监控 eBay 上笔记本电脑的价格。用 Playwright,你可以自动搜索“laptop”,批量提取所有商品标题和价格,甚至自动翻页采集。这些数据能帮你灵活调整定价策略,再也不用担心竞争对手突然搞促销时措手不及(81% 的消费者会先上网比价)。
常见业务场景:
- 价格监控:实时追踪竞争对手,灵活调整自家价格。
- 产品目录采集:批量搭建或更新自有商品库。
- 竞品分析:洞察热销趋势、库存情况、营销手法。
- 线索收集:从目录或平台抓取卖家信息、联系方式等。
自动化价格监控的企业,普遍实现了 5–25% 的营收增长(数据来源)。
Playwright Python 环境搭建:快速上手
下面带你一步步用 Python 配置 Playwright 环境(新手友好)。
1. 环境准备
你需要:
- 安装 Python 3.7+(用
python --version检查) - 安装 pip(Python 包管理器)
2. 安装 Playwright 及浏览器内核
打开终端或命令行,输入:
pip install playwright
python -m playwright install
这样就安装好了 Playwright 以及所需的浏览器引擎(Chromium、Firefox、WebKit),可以开始自动化啦!
3. “Hello World” 脚本示例
让我们用 Playwright 打开 eBay 首页:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True) # 后台运行浏览器
page = browser.new_page()
page.goto("https://www.ebay.com/")
print(page.title())
browser.close()
运行后,你会在终端看到 eBay 首页的标题。恭喜,已经完成了第一个自动化浏览器操作!
常见安装问题及解决办法
再好用的工具,也难免遇到小插曲。常见 Playwright 安装问题有:
- 找不到 Python 或 pip:确保 Python 已加入系统 PATH。
- 权限不足:试试用管理员身份运行终端,或在 Mac/Linux 下用
sudo。 - 浏览器内核未安装:确认已执行
python -m playwright install。 - 防火墙或代理限制:有些公司网络会屏蔽下载,建议切换到个人网络。
遇到卡壳时,强烈推荐查阅 Playwright 官方故障排查文档。
实战演练:用 Playwright 抓取 eBay 商品数据
下面以 eBay 为例,演示如何用 Playwright Python 抓取商品标题和价格。
1. 定义搜索关键词
比如我们要采集“laptop”相关商品。
2. 脚本示例
from playwright.sync_api import sync_playwright
search_term = "laptop"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(f"https://www.ebay.com/sch/i.html?_nkw={search_term}")
page.wait_for_selector("h3.s-item__title") # 等待商品加载
page_num = 1
results = []
while page_num <= 2: # 这里只采集前两页做示例
print(f"Scraping page {page_num}...")
titles = page.locator("h3.s-item__title").all_text_contents()
prices = page.locator("span.s-item__price").all_text_contents()
for title, price in zip(titles, prices):
results.append({"title": title, "price": price})
print(f"{title} --> {price}")
# 跳转到下一页
next_button = page.locator("a[aria-label='Go to next search page']")
if next_button.count() > 0:
next_button.click()
page.wait_for_selector("h3.s-item__title")
page_num += 1
page.wait_for_timeout(2000) # 友好延迟,防止被封
else:
break
print(f"Found {len(results)} items in total.")
browser.close()
脚本解析:
- 启动无头浏览器,搜索“laptop”,等待商品标题加载。
- 批量提取当前页所有商品标题和价格。
- 自动点击“下一页”按钮,继续采集。
- 加入延迟,降低被识别为爬虫的风险。
这就是 Playwright 爬虫的基本流程:导航、等待、提取、循环。
处理分页与动态内容
现代电商网站常用无限滚动和动态加载。Playwright 的智能等待(wait_for_selector)很有用,但你还需要:
- 点击“下一页”:如上例所示。
- 等待 AJAX 内容加载:用
wait_for_selector或wait_for_timeout确保数据已出现。 - 处理无限滚动:通过代码滚动页面,等待新内容加载。
这些都需要多次尝试和耐心调试。
应对反爬机制
像 eBay 这样的大型网站,对爬虫并不友好。常见防护措施有:
- 验证码(CAPTCHA)
- User-Agent 检查
- 限流与 IP 封禁
Playwright 能模拟真实浏览器,但如果大规模采集,建议:
- 切换 User-Agent:让爬虫伪装成不同浏览器。
- 使用代理:更换 IP,降低被封风险。
- 降低请求频率:加入随机延迟。
即便如此,遇到大规模采集时,还是可能被封(eBay 的限流机制很强)。
Playwright 自动化对新手的挑战
说到底,Playwright 虽然强大,但对非技术用户并不算友好。新手常遇到这些难题:
- 需要编程基础:要懂 Python(或其他支持的语言)、会用 HTML/CSS 选择器,还得能调试代码。
- 脚本维护麻烦:网站结构一变,脚本就可能失效。
- 动态内容处理复杂:等待 AJAX、处理无限滚动、超时管理都很考验耐心。
- 资源消耗大:无头浏览器占用 CPU 和内存,采集量大时尤其明显。
- 反爬机制难搞:验证码、代理、封禁等问题需要额外解决方案。
我自己也曾无数次熬夜修复失效的选择器,排查脚本为啥突然抓不到数据。这几乎是每个爬虫新手的“必经之路”,但不是每个人都有时间和精力去折腾。
Thunderbit:AI 网页爬虫,零代码也能轻松采集
接下来聊聊新一代工具:Thunderbit。
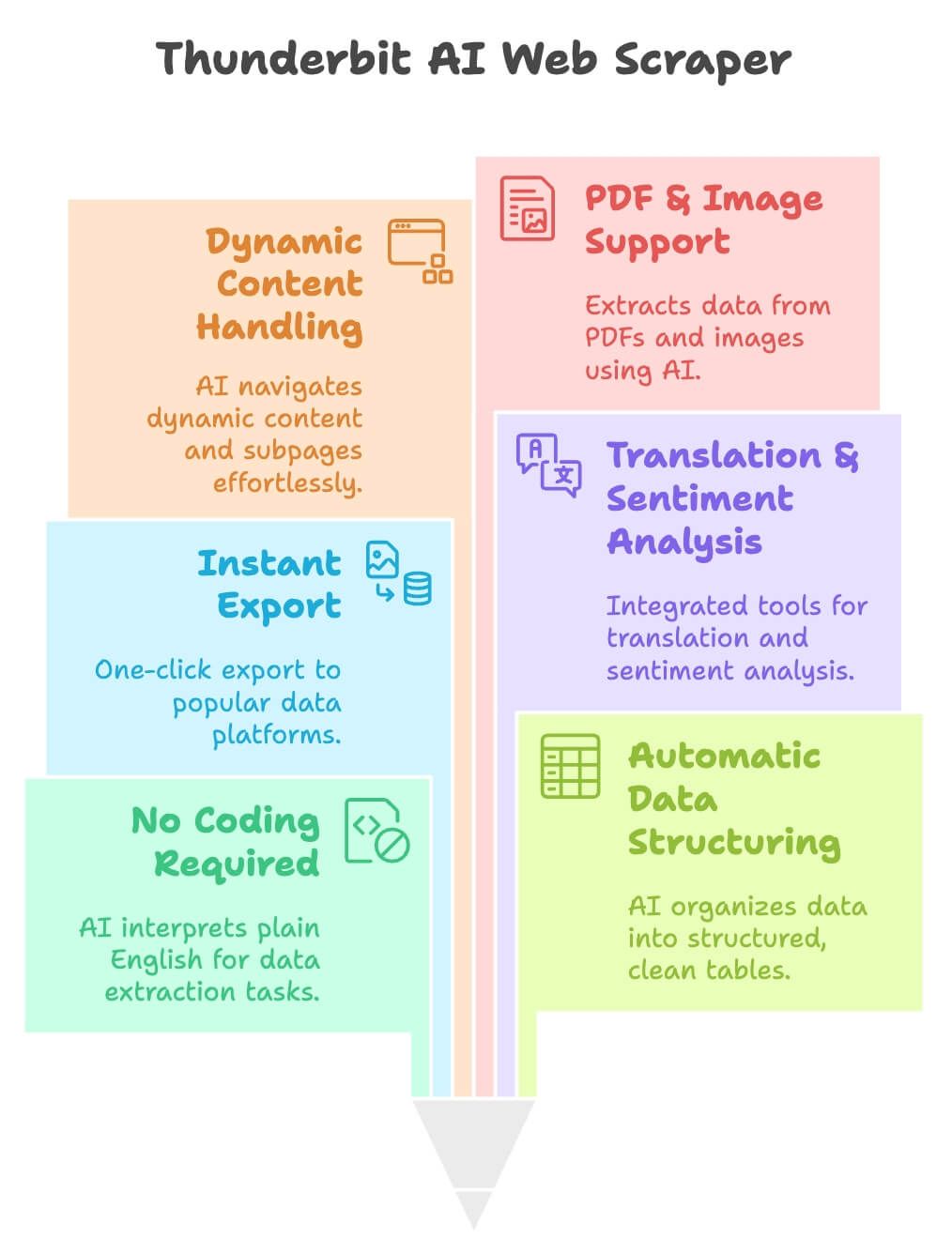
Thunderbit 是专为业务用户打造的 AI 网页爬虫 Chrome 插件——无论你是销售、市场还是运营,只需描述想要的数据,剩下的交给 AI。它的优势包括:
- 无需编程:用自然语言描述需求,AI 自动识别并采集。
- 智能结构化数据:AI 自动推荐字段(如商品名、价格、评分),一键生成干净表格。
- 一键导出:数据可直接导出到 Excel、Google Sheets、Airtable 或 Notion。
- 内置翻译与情感分析:无需额外工具,采集时即可自动翻译商品描述、分析评论情感。
- 自动处理动态内容、分页、子页面:AI 能识别“下一页”、无限滚动,甚至自动点击进入详情页。
- 支持 PDF 和图片:不仅限于网页,Thunderbit 还能用 OCR+AI 从 PDF、图片中提取数据。
它就像一个多语种、永不疲倦、乐于重复劳动的数据小助手。
Thunderbit 与 Playwright 对比
以 eBay 采集为例,来看两者的差异:
| 对比项 | Playwright(代码) | Thunderbit(AI 无代码) |
|---|---|---|
| 上手时间 | 30 分钟以上(安装、写代码、调试) | 5 分钟内(装插件,点“AI 推荐字段”,再点“采集”) |
| 技能要求 | 需懂 Python、HTML/CSS 选择器、调试 | 无需技术基础,只需会用浏览器 |
| 维护成本 | 手动维护(网站结构变动需改脚本) | 极低——AI 自动适应,模板由 Thunderbit 团队维护 |
| 动态内容与分页 | 需手动编写导航与等待逻辑 | AI 全自动处理 |
| 数据增强 | 需自行编写翻译/情感分析或接 API | 内置——UI 勾选即可翻译、分类、情感分析 |
| 导出方式 | 需写导出代码或用 API | 一键导出到 Excel、Google Sheets、Airtable、Notion |
| 扩展性 | 可扩展(并发脚本、代理),但资源消耗大 | 适合常规业务场景(百/千级数据),云端处理更高效 |
| 成本 | 免费(开源),但需开发者时间和代理费用 | 订阅制(约 $9–15/月),小规模有免费额度 |
对于业务用户来说,体验完全不同。用 Playwright 需要学代码、调试、维护脚本;用 Thunderbit,只需点几下按钮,就能拿到结构化数据,还能自动翻译和情感分析,完全不用写代码。
高阶数据处理:Thunderbit 的翻译与情感分析
Thunderbit 在业务场景下的优势特别明显。
比如你想分析 eBay 卖家的多语言客户评论。用 Playwright,你需要:
- 先采集评论内容;
- 再写代码调用翻译 API;
- 还要写代码做情感分析(比如用 Google Cloud Natural Language);
- 最后把所有结果合并到一个表格里。
而用 Thunderbit,只需在界面上勾选“翻译”和“情感分析”,AI 自动完成所有流程,输出干净的表格。
业务价值:
- 全球市场分析:一键翻译任意语言的商品信息或评论。
- 客户反馈分类:快速发现用户关注点和痛点。
- 决策更高效:无需切换多工具,直接获得可用洞察。
过去需要开发、数据分析师和大量时间的流程,现在几分钟就能搞定。
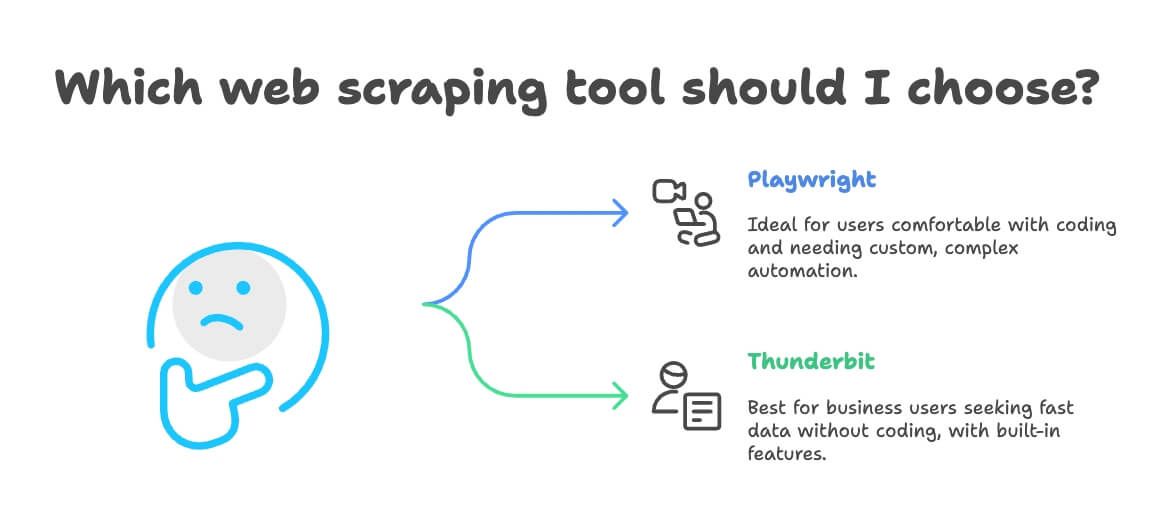
何时选择 Playwright,何时用 Thunderbit?
没有绝对的答案,适合自己的才是最好的。我的建议:
适合用 Playwright 的场景:
- 你(或团队)有编程能力;
- 需要高度定制、复杂自动化(如自动登录、验证码处理、系统集成等);
- 追求极致灵活和控制力;
- 大规模采集或需嵌入大型软件项目。
适合用 Thunderbit 的场景:
- 你是业务用户,只想快速拿到数据;
- 不想写代码、也不想维护脚本;
- 需要内置翻译、情感分析或数据结构化;
- 希望一键导出到 Excel、Google Sheets、Airtable、Notion;
- 典型业务需求如销售、市场、电商运营、房产(如线索采集、价格监控、目录采集等)。
说实话,大多数销售和运营团队只想要一份表格数据,而不是编程技能勋章。Thunderbit 就是为他们量身打造的。
总结:让网页爬取真正服务于业务
2025 年最佳网页爬虫工具与软件推荐 Get Started Free
最后总结一下:
- Playwright 是功能强大、灵活的网页爬取和浏览器自动化工具,适合技术用户深度定制。
- Thunderbit 是面向业务用户的 AI 网页爬虫,无需代码,几步就能搞定数据采集、翻译、情感分析。
如果你喜欢技术折腾,Playwright 是不可多得的利器;但如果你在销售、市场、运营岗位,只想高效拿到结果,Thunderbit 就是你的捷径。
想体验 Thunderbit 吗?
你可以免费试用 Thunderbit Chrome 插件,或者在 Thunderbit 博客 了解更多工具对比。
还在犹豫?记住:最好的工具,是能帮你高效拿到所需数据、格式合适、又不占用你整个下午(或让你抓狂)的那一个。祝你采集顺利!
想了解更多网页爬虫、AI 与自动化实用技巧?欢迎阅读 Thunderbit 博客 的其他指南,比如 什么是数据爬取及 2025 年最新方法 和 如何用 AI 抓取亚马逊商品与评论(2025 最新)。
AI 网页爬虫,专为业务用户打造 Get Started Free




