

很多开发者第一次接触网页爬虫,往往是因为好奇,想抓取竞争对手网站上的商品信息。BeautifulSoup 这类工具很快就会出现在搜索结果里,但刚开始用的时候,难免有点摸不着头脑。等你多试几次,能顺利跑通 pip install beautifulsoup4 并成功提取出一个简单的 HTML 元素(比如标题),那种“原来就这么回事!”的感觉,真的很让人兴奋。很多 Python 新手正是从这里开始,慢慢喜欢上了数据爬取。
如果你刚开始了解网页爬虫,BeautifulSoup 很可能是你听到的第一个工具。原因很简单:它上手快、功能强大,而且十几年来一直是 Python 爬虫领域的经典库。本文会手把手教你怎么用 pip 安装 beautifulsoup4,带你用真实代码体验入门,还会聊聊为什么它依然被开发者和数据分析师广泛使用。当然,我也会实话实说 BeautifulSoup 的短板,以及为什么现在越来越多团队(尤其是非技术背景的同学)会选择像 Thunderbit 这样的 AI 网页爬虫工具。
什么是 BeautifulSoup,为什么开发者还在用?
BeautifulSoup 与 AI 网页爬虫:全面对比 Get Started Free
先来科普一下:BeautifulSoup 到底是什么?你可以把它理解成 Python 的“HTML 解析小帮手”。你把一段 HTML 或 XML 扔给它,它就能帮你把网页内容变成结构化的树状数据,方便你用 Python 代码查找、遍历和提取。就像给网页装上了“透视眼”,原本杂乱的标签和属性都能一目了然。
BeautifulSoup 为什么这么受欢迎?
虽然现在有很多新型爬虫框架,但 BeautifulSoup 依然是大多数 Python 新手的首选。它每月在 PyPI 上的下载量超过 1.5 亿次,而且在 Stack Overflow 上,带有“beautifulsoup”标签的问题超过 3.2 万条,社区活跃,资源丰富,新手遇到问题也很容易找到答案。
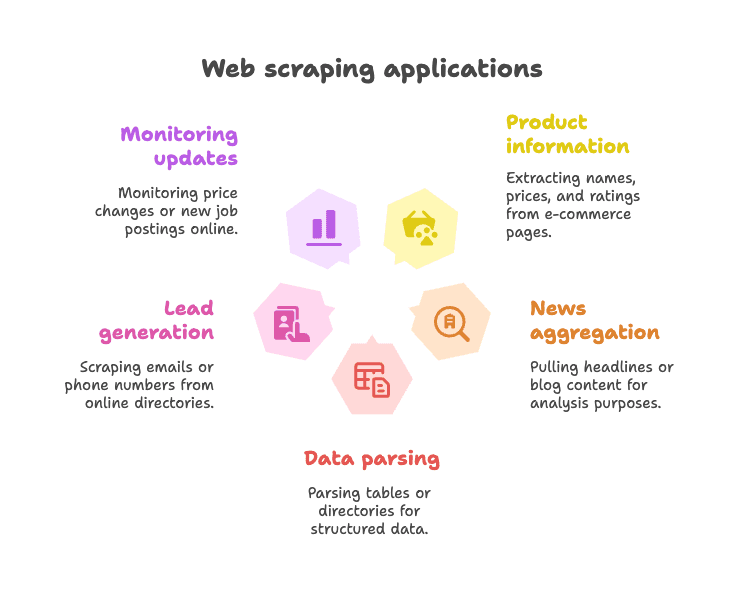
常见应用场景:
- 抓取电商商品信息(比如名称、价格、评分等)
- 采集新闻标题或博客内容,方便聚合或分析
- 解析表格或目录,提取结构化数据(比如企业名录)
- 线索收集,比如从黄页抓邮箱或电话
- 监控网页更新(比如价格变动、新职位发布等)
BeautifulSoup 特别适合处理静态网页——也就是你要的数据直接写在 HTML 里。它灵活、容错性强(HTML 再乱也能解析),也不强制你用什么框架。所以即使到了 2025 年,BeautifulSoup 依然是很多 Python 爬虫爱好者的“初恋” (了解更多)。
pip 安装 BeautifulSoup:最简单的入门方式
什么是 pip,为什么要用它?
如果你是 Python 新手,pip 就是 Python 的包管理器,能帮你从官方仓库(PyPI)安装各种库。就像 Python 版的“应用商店”。用 pip 安装 BeautifulSoup 是最快、最靠谱的方式。
小提醒:正确的包名是 beautifulsoup4(不是 beautifulsoup),一定要带“4”,这样才能装到最新版。
步骤详解:如何安装 BeautifulSoup
1. 检查 Python 版本
BeautifulSoup 需要 Python 3.7 及以上。你可以在终端输入:
python --version
或者
python3 --version
2. 用 pip 安装 beautifulsoup4
打开终端或命令行,输入:
pip install beautifulsoup4
如果你电脑上有多个 Python 版本,可能需要:
pip3 install beautifulsoup4
Windows 用户也可以用:
py -m pip install beautifulsoup4
3. (可选但推荐)安装解析器
BeautifulSoup 默认支持 Python 自带的 "html.parser",但为了更快更准,建议再装上 lxml 和 html5lib:
pip install lxml html5lib
4. (可选)安装 Requests
BeautifulSoup 只负责解析 HTML,不负责下载网页。大多数人会用 Requests 库来获取网页内容:
pip install requests
5. 检查安装是否成功
在 Python 里试试:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
如果你看到 <title>Example Domain</title>,说明一切正常。
在虚拟环境中安装 BeautifulSoup
强烈建议你为每个 Python 项目创建 虚拟环境,这样依赖不会乱,也能避免“只在我电脑上能跑”的尴尬。
创建方法如下:
python -m venv venv
# Windows 下激活:
venv\Scripts\activate
# macOS/Linux 下激活:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
这样所有依赖都只在当前项目文件夹内,避免包丢失或冲突。
其他安装方式(如 Conda 等)
如果你用的是 Anaconda,可以这样安装 BeautifulSoup:
conda install beautifulsoup4
解析器也可以这样装:
conda install lxml
记得先激活你的 conda 环境。
BeautifulSoup Python:代码实战入门
下面用实际代码演示如何用 BeautifulSoup 抓取网页。
示例 1:获取网页并提取标题
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# 获取页面标题
title_text = soup.title.string
print("Page title:", title_text)
这段代码会抓取 Python 维基百科页面,解析 HTML 并打印标题。
示例 2:提取所有超链接
links = soup.find_all('a')
for link in links[:10]: # 只显示前 10 个链接
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
会输出前 10 个链接的文本和 URL。
示例 3:提取所有二级标题
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
想获取所有 <h2> 标题?这样就够了。
示例 4:使用 CSS 选择器
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
select() 方法支持常见的 CSS 选择器。
示例 5:获取属性和嵌套标签
first_link = soup.find('a')
print(first_link['href']) # 直接访问(缺失会报错)
print(first_link.get('href')) # 安全访问(缺失返回 None)
示例 6:提取页面所有文本
text_content = soup.get_text()
print(text_content)
可以快速获取页面全部文本,便于分析。
BeautifulSoup 新手常用操作
常见的 BeautifulSoup 用法有:
-
查找单个元素:
soup.find('div', class_='price') -
查找所有元素:
soup.find_all('p', class_='description') -
获取文本内容:
element.get_text() -
获取属性值:
element.get('href') -
用 CSS 选择器:
soup.select('table.data > tr') -
处理缺失元素:
price = soup.find('span', class_='price') if price: print(price.get_text())
语法简洁,易读,对新手很友好,即使 HTML 很乱也能解析(官方文档 也很详细)。
BeautifulSoup 在现代网页爬虫中的局限
说到这里,也得聊聊现实问题。BeautifulSoup 虽然适合静态页面和小型项目,但并不是万能的。
主要痛点有:
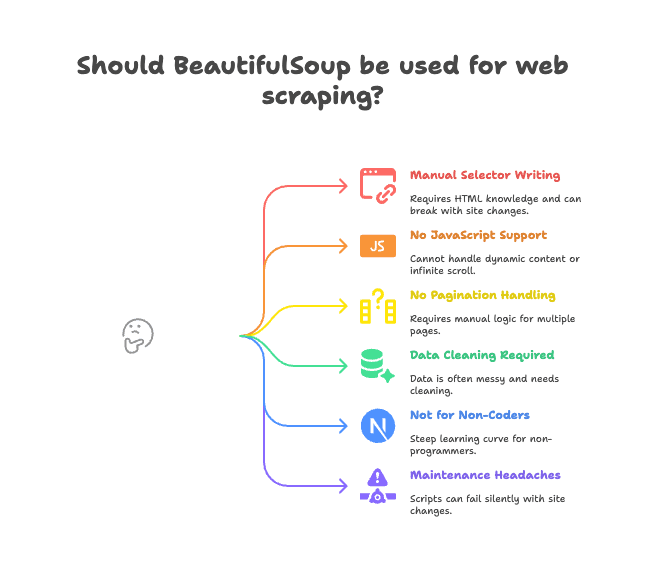
- 需要手动写选择器: 你得自己分析 HTML,写标签/类路径,网站结构一变脚本就失效。
- 不支持 JavaScript 渲染: BeautifulSoup 只能看到服务器返回的 HTML,遇到 JS 动态加载(比如无限滚动、动态内容)就没辙(了解详情)。
- 没有内置翻页或子页面处理: 想抓多页或点进详情页?逻辑全靠你自己写。
- 数据清洗要自己做: 抓到的数据经常有多余空格、乱码、格式不统一。
- 不适合非技术人员: 如果你是做销售、市场、运营,不会写代码,BeautifulSoup 上手门槛高。
- 维护成本高: 网站结构一变,脚本可能悄悄失效或漏数据。
这些“小问题”积累起来,常常让团队效率大打折扣。我见过不少项目因为脚本频繁出错而被搁置。
为什么越来越多团队选择 Thunderbit 进行网页数据采集
试用 Thunderbit AI 网页爬虫 用 AI 抓取任意网站,无需写代码。 Get Started Free
那有没有更简单的办法?这就是 Thunderbit 的用武之地。Thunderbit 不是另一个 Python 库,而是一个 Chrome 扩展,像 AI 助手一样帮你采集网页数据。
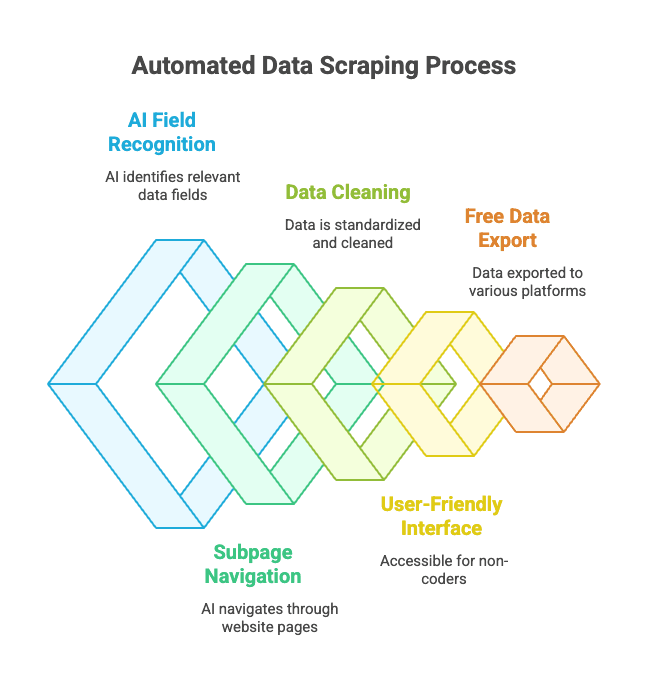
它怎么用?
- 打开你想抓取的网站。
- 点击“AI 智能识别字段”——Thunderbit 的 AI 会自动识别页面上的关键信息(比如“商品名”、“价格”、“地址”等)。
- 你可以自定义字段名称和类型。
- 点击“抓取”,Thunderbit 会自动采集、清洗并结构化数据。
- 一键导出到 Excel、Google Sheets、Notion、Airtable 等常用工具。
无需写代码,无需手动选标签,无需担心维护。
Thunderbit 的核心优势:
- AI 智能字段识别: 就算 HTML 很乱,AI 也能自动找出你要的数据。
- 支持子页面和翻页抓取: 能自动点击详情页或“下一页”,批量采集。
- 自动数据清洗与格式化: 电话、邮箱、图片等字段自动标准化。
- 零代码门槛: 只要会用浏览器就能上手。
- 免费数据导出: 一键导出到 Excel、Google Sheets、Airtable、Notion 等,无需付费即可体验基础功能。
- 定时自动抓取: 支持定时任务,自动采集无需人工干预。
对于企业用户来说,这彻底改变了网页数据采集的方式。无需折腾 Python 脚本,只需点点鼠标,数据就到手。
Thunderbit 与 BeautifulSoup:如何选择?
一图对比:
| 功能 | BeautifulSoup(Python 编码) | Thunderbit(零代码 AI) |
|---|---|---|
| 安装方式 | 需安装 Python、pip、写代码 | Chrome 扩展,2 步搞定 |
| 数据到手速度 | 第一次写脚本需数小时 | 每个网站几分钟搞定 |
| 支持 JavaScript | 不支持(需额外工具) | 支持(浏览器内运行) |
| 翻页/子页面 | 需手动写代码 | 内置,开关即可 |
| 数据清洗 | 需手动处理 | AI 自动完成 |
| 导出方式 | 需自己写导出代码 | 一键导出到 Sheets、Notion 等 |
| 适合人群 | 开发者、技术爱好者 | 商业用户、零代码人士 |
| 费用 | 免费(但耗时) | 免费+付费(小量免费) |
适合用 BeautifulSoup 的场景:
- 你熟悉 Python,想要完全自定义流程。
- 目标网站是静态页面,或需要复杂逻辑。
- 需要将爬虫集成到更大的 Python 项目中。
适合用 Thunderbit 的场景:
- 你想快速拿到数据,不想写代码。
- 需要抓取动态(JavaScript)网站。
- 你是销售、市场、运营等非技术岗位。
- 希望数据直接导入业务工具。
说实话,即使作为开发者,有时我也会用 Thunderbit 快速采集数据,省得搭建 Python 项目。它就像浏览器里的“外挂”。
安装与使用 BeautifulSoup 的最佳实践
如果你决定用 BeautifulSoup,下面这些建议能帮你少踩坑:
- 一定要用虚拟环境: 保证依赖干净,避免“只在我电脑上能跑”的问题。
- 定期更新 pip 和包: 多用
pip install --upgrade pip和pip list --outdated。 - 推荐安装解析器:
pip install lxml html5lib,性能更好更稳定。 - 代码要模块化: 抓取和解析分开写,方便调试。
- 遵守 robots.txt 和限速: 不要频繁请求,适当
time.sleep()。 - 选择器要稳健: 避免过于具体的路径,减少因网页变动导致的失效。
- 先下载页面本地测试解析: 避免频繁请求目标网站。
- 多用社区资源: Stack Overflow 是排查问题的好帮手。
BeautifulSoup 安装常见问题排查
遇到问题?快速自查:
- “ModuleNotFoundError: No module named bs4”
- 是否在正确的环境下安装了
beautifulsoup4?试试python -m pip install beautifulsoup4。
- 是否在正确的环境下安装了
- 装错包(装了 beautifulsoup 而不是 beautifulsoup4)
- 卸载旧包:
pip uninstall beautifulsoup - 安装正确包:
pip install beautifulsoup4
- 卸载旧包:
- 解析器警告或编码报错
- 安装
lxml和html5lib,并指定解析器:BeautifulSoup(html, "lxml")
- 安装
- 找不到元素
- 目标数据是否由 JavaScript 动态加载?BeautifulSoup 看不到。请查看网页源代码而不是浏览器渲染后的 DOM。
- pip 报错或权限问题
- 用虚拟环境,或试试
pip install --user beautifulsoup4 - 升级 pip:
pip install --upgrade pip
- 用虚拟环境,或试试
- Conda 相关问题
- 试试
conda install beautifulsoup4,或在 conda 环境中用 pip 安装。
- 试试
还没解决?BeautifulSoup 官方文档 和 Stack Overflow 基本能覆盖所有场景。
总结:安装与使用 BeautifulSoup 的要点
-
BeautifulSoup 是最受欢迎的 Python 网页爬虫库,简单灵活,非常适合新手。
-
用 pip 安装即可:
pip install beautifulsoup4 lxml html5lib requests -
建议用虚拟环境,保持环境干净。
-
BeautifulSoup 适合静态页面和小型项目, 但对 JavaScript、翻页和维护不太友好。
-
Thunderbit 是面向商业用户和零代码人士的现代 AI 网页爬虫, 无需写代码,数据一键到手。
-
选对工具最重要:
- 开发者、技术爱好者:BeautifulSoup 灵活可控。
- 商业用户、团队:用 Thunderbit 快速搞定。
两种方式都可以试试——有时候,最省事的方案才是最优解。
免费试用 Thunderbit AI 网页爬虫 Get Started Free
常见问题:pip 安装 BeautifulSoup 及相关解答
Q: beautifulsoup 和 beautifulsoup4 有什么区别?
A: 一定要装 beautifulsoup4,这是最新版且支持 Python 3。老的 beautifulsoup 包已经不维护,也不兼容 Python 3。导入时用 from bs4 import BeautifulSoup(详细说明)。
Q: BeautifulSoup 需要安装 lxml 或 html5lib 吗?
A: 虽然不是必须,但强烈推荐。它们能让解析更快更稳。用 pip install lxml html5lib 安装(原因详解)。
Q: BeautifulSoup 能抓取 JavaScript 动态网站吗?
A: 不能——它只能看到静态 HTML。遇到 JS 动态内容,建议用 Selenium 这类浏览器自动化工具,或者试试 Thunderbit 这样的 AI 浏览器爬虫(了解详情)。
Q: 如何卸载 BeautifulSoup?
A: 在终端输入 pip uninstall beautifulsoup4 即可(详细步骤)。
Q: Thunderbit 免费吗?
A: Thunderbit 采用免费+付费模式,小量任务免费体验,高级功能和大批量数据需付费。你可以直接在浏览器免费试用(价格详情)。
想了解 Thunderbit 和 BeautifulSoup 在实际场景下的对比,可以参考我们的 深度对比。如果你想进一步了解网页爬虫,也别错过我们的其他指南,比如 什么是数据爬取 和 如何抓取亚马逊商品及评论。
祝你爬虫顺利!无论你是 Python 老手,还是只想把数据导入表格,总有合适的工具和社区帮你实现目标。




