
优化 apollo lists 的列表查询不只是技术细节——对任何依赖实时新闻数据、自动化新闻提取,或者需要销售与运营流程高速运转的人来说,这更像一项“生存技能”。我亲眼见过:一个反应慢半拍的列表查询,能把原本顺滑的仪表盘直接拖成卡顿现场,销售同事盯着转圈加载器干着急,运营同事只能在表格里临时找替代方案硬撑。在一个连的世界里,每一毫秒都很要命。

那问题来了:怎么才能让 apollo Client 的列表查询又快又稳、还能扩展——尤其是当你要抓取新闻、跟踪线索,或者支撑关键业务看板的时候?这篇指南会把我总结的最佳实践(也包括踩坑换来的经验)拆开讲清楚:从查询设计到缓存策略、分页方式,再到如何结合像 这样的无代码工具,把新闻提取这类“脏活累活”自动化。无论你是开发者、产品经理,还是那个“看板一慢就被点名”的人,这都会是你提升 apollo GraphQL 列表性能的作战手册。
为什么要优化 Apollo 列表查询?(apollo client list performance, optimize apollo list queries)
讲真:没人想等新闻标题或销售线索慢慢加载。在企业场景里——尤其是依赖或实时数据的团队——Apollo 列表查询慢不只是“体验差”,它会直接抬高成本、拖慢决策节奏,还会把人逼回手工流程里。提到,办公室员工大约 三分之一的工作时间花在低价值任务上,其中一个常见原因就是工具慢、工具碎片化。
当列表查询没优化时,常见会踩这些坑:
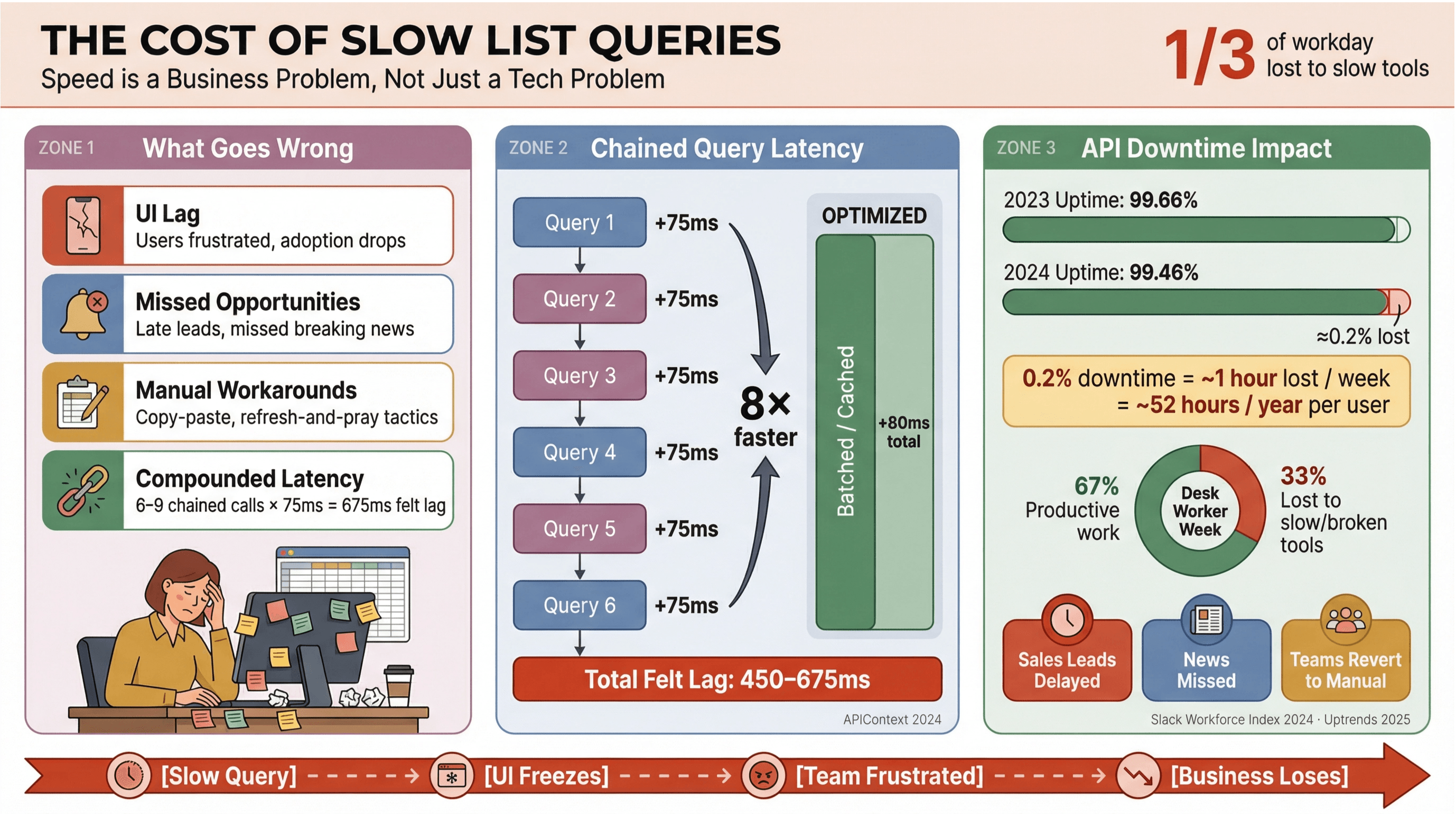
- **界面卡顿:**加载延迟让人烦躁,使用意愿直线下降。
- **错失机会:**在销售或新闻监控里,慢几秒就可能错过热门线索或突发新闻。
- **手工绕路:**团队回到复制粘贴、表格拼凑,或者“刷新祈祷”式操作。
- **延迟叠加:**每一次慢 API 调用都会累积——如果你的流程会触发 6–9 个相互依赖的查询,即便每次只慢 75ms,最终用户感知的延迟也会膨胀到 450–675ms()。
而且这不只是速度问题。,平均可用性在一年内从 99.66% 掉到 99.46%——对重度列表应用来说,换算下来每周可能接近一小时的生产力损失。要是你的业务依赖实时新闻数据,这种风险真的不能当没看见。
选择合适的数据结构与字段(apollo graphql list best practices)
我最常见到的错误之一(我自己也踩过)是:把每个列表查询都当成详情查询来写。GraphQL 的优势就是“按需取数”,所以一定要用起来。过度取数是性能的头号敌人,尤其在新闻抓取工具和实时看板里更明显。
为自动化新闻提取量身定制字段
假设你在做一个新闻流:列表查询真的需要把全文、所有标签、评论、作者简介都一次性拉下来吗?大概率不需要。对比一下:
高效的列表查询:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}低效的列表查询(别这么写):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}第一个查询足够轻量,非常适合排序、筛选和渲染列表行。第二个看起来“省事”,其实是披着列表外衣的详情查询:载荷巨大,整体性能直接被拖垮(参考 、)。
**小技巧:**用“两层加载”——列表只取轻字段;当用户点开某条新闻或悬停时,再加载重字段(比如全文或 NLP 增强结果)。
利用 Apollo Client 缓存加速查询(apollo client list performance)
Apollo Client 的缓存是让列表“秒开”的关键武器。配置得当时,它可以:
- 让重复查询几乎瞬间返回(不用网络往返)
- 降低服务端压力与 API 成本
- 让前进/后退、切换筛选更顺滑
但缓存不是玄学——需要一些配置和规范。
设置合适的缓存策略
Apollo 支持多种 :
| Policy | 作用 | 新闻列表的典型场景 |
|---|---|---|
| cache-first | 优先读缓存,缺失时再走网络请求 | 回到列表、切换筛选、前进/后退导航 |
| network-only | 每次都从网络拉取 | 手动刷新、“最新头条” |
| cache-and-network | 先返回缓存,再用网络结果更新 | 首屏更快 + 后台更新(非常适合新闻流) |
| no-cache | 每次都拉取且不写入缓存 | 一次性且敏感的查询(列表场景较少) |
对于实时新闻数据,我更偏向 cache-and-network:用户能立刻看到结果,同时后台悄悄刷新。但要注意:如果刷新后数据顺序变化,UI 可能会闪一下(见 )。
缓存配置建议:
- 用稳定 ID(
id或_id)做规范化()。 - 面对大列表时,调整缓存大小与垃圾回收策略()。
- 别把巨大的、未规范化的 blob 全堆在
ROOT_QUERY下,不然应用更新可能被拖慢()。
实现分页并限制单次加载数量(apollo graphql list best practices)
如果你一次性加载几百、几千条新闻或线索,那基本就是在给自己挖坑。分页不只是体验优化,更是性能刚需。
Apollo 同时支持 和。对比如下:
| 分页类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Offset-based | 简单直观、实现成本低 | 数据变动时可能跳过/重复 | 数据稳定或小列表 |
| Cursor-based | 更稳定,能更好应对数据变化 | 实现略复杂 | 新闻流、大列表 |
对大多数实时新闻或线索列表来说,基于 cursor 的分页更合适。就算有新内容插入或旧内容删除,也更容易保持一致性(参考 )。
Apollo 分页要点:
- 配置
keyArgs,控制分页字段的缓存 key()。 - 实现
merge函数,把多页结果合并进缓存。 - 用
fetchMore拉取下一页,避免覆盖已有结果。
新闻抓取工具的实用分页模式
一个典型的新闻抓取 UI 通常会:
- 首屏展示最新 20–50 条标题(只取轻字段)
- 滚动加载或点击“下一页”继续拉取
- 只有在需要时才请求详情
这样 UI 更快、API 更轻松、用户也更高效。
集成 Thunderbit,实现自动化新闻提取
接下来聊一个绕不开的问题:这些结构化新闻数据到底从哪里来?这正是 的用武之地。
Thunderbit 是一款无代码的 AI 网页爬虫 Chrome 扩展,几乎可以从任何网站提取新闻标题、链接、来源、作者、发布时间、摘要和图片等信息——不需要写代码。我见过不少团队用 Thunderbit 把新闻提取全流程自动化:把非结构化网页直接变成干净、可用的结构化数据,然后喂给数据库或 GraphQL API。
将 Thunderbit 与 Apollo 结合,构建实时新闻数据流
我很喜欢的一套流程,特别适合需要“随时掌握最新动态”的销售与运营团队:
- **提取层:**用 Thunderbit 的定时从目标网站抓取结构化新闻数据。
- **存储层:**把抓取结果写入一个便于快速检索的数据库。
- **GraphQL 层:**在 API 中提供
newsFeed列表字段与newsArticle(id)详情字段。 - **客户端层:**Apollo Client 拉取列表(精简字段 + 分页),需要时再拉取详情。
这条“抓取 → 存储 → 查询”的流水线,让 Apollo 查询始终面对新鲜、结构化的数据——不再依赖手工复制粘贴或脆弱脚本。
**加分项:**Thunderbit 还能通过 AI 字段建议为列表补充额外字段(例如情绪、分类),让你的新闻流更“聪明”。
分步指南:优化 Apollo 列表查询
准备上手实操?下面是我常用的 Apollo 列表查询优化清单:
-
把查询“瘦身”
- 只请求渲染列表所需字段(标题、URL、时间戳等)。
- 重字段(全文、图片、增强信息)放到详情查询。
-
实现分页
- 大列表或动态列表优先用 cursor 分页。
- 配置
keyArgs与merge,确保缓存合并正确。
-
用好 Apollo 缓存
- 用稳定 ID 做实体规范化。
- 选择合适的 fetch policy(新闻场景
cache-and-network很好用)。 - 根据数据量调整缓存大小与 GC。
-
接入自动化提取
- 用 Thunderbit 自动抓取新闻,持续保持数据新鲜。
- 结构化数据可直接导出到数据库或表格。
-
监控与排障
- 用 查看查询、缓存与性能。
- 留意大规模缓存写入、过多 watched queries、以及 UI 卡顿。
- 关注 p95/p99 延迟与错误率(、)。
监控与排查查询性能
Apollo Devtools 在这里真的很救命,你可以:
- 查看活跃查询与缓存状态
- 发现重复查询或过多 watcher
- 定位大块缓存数据或规范化问题
如果你看到 UI 卡顿或更新很慢,优先检查:
- 列表查询是否过大(先瘦身)
- 缓存规范化是否做对(修正 ID)
- 分页合并是否有问题(审计
keyArgs与merge)
另外别只盯平均值,要测“尾部延迟”(tail latency)——真正的用户痛点往往就藏在这里。
传统新闻抓取 vs AI 驱动的新闻抓取
过去抓取新闻数据,往往意味着写定制脚本、折腾无头浏览器,然后祈祷网站布局别一夜之间改版。现在有了 Thunderbit 这类 AI 驱动工具,很多流程可以直接自动化——无代码、少折腾。
| 方式 | 优势 | 对业务用户的限制 |
|---|---|---|
| 脚本抓取 | 可高度定制、规模化成本低 | 维护成本高、需要工程投入 |
| 托管式抓取平台 | 上手快、反爬处理交给平台 | 仍需配置、用量越大成本越高 |
| AI 驱动提取(Thunderbit) | 能处理复杂页面、无需写代码 | 输出需要质检、需对接你的数据结构 |
| 无代码可视化爬虫 | 非工程人员也能用 | UI 变化易失效、扩展性有限 |
| 代理/解锁基础设施 | 可绕过封锁、支持高吞吐 | 仍需提取逻辑、合规风险更高 |
**法律提示:**抓取公开数据通常是合法的,但务必遵守网站服务条款与访问频率限制(参考 )。
Apollo GraphQL 列表最佳实践要点
核心要点回顾:
- **以速度与清晰为目标:**列表查询要精简、分页要到位、缓存要积极。
- **结构决定性能:**只取必要字段,重字段放到详情查询。
- **缓存是加速器:**用好 Apollo 的规范化与 fetch policy,让数据“秒回”。
- **自动化提取:**像 这样的工具,让新闻抓取与列表增强人人可用。
- **持续监控迭代:**用 Devtools 与可观测性面板尽早发现瓶颈。
对销售、运营和新闻团队来说,这些实践意味着更少等待、更多行动,也会少很多“怎么又这么慢?”的 Slack 消息。
结语:下一步如何继续优化 Apollo 列表查询
如果你还在使用字段很重、没有分页、或对缓存不友好的列表查询,现在就该做一次审计与升级。可以从小处开始:先裁剪字段、加上分页、再调好缓存。之后再进一步,把 这类自动化提取工具接进来,让数据持续新鲜、可执行。
想深入学习?可以看看 、,或加入 获取真实场景的经验与排障建议。如果你准备把新闻提取自动化,强烈建议试试 Thunderbit 的——对需要实时数据、又不想被脚本折磨的人来说,它真的能大幅省心。
祝你查询顺滑——也希望你的列表永远比咖啡凉得更快加载出来。
常见问题(FAQs)
1. 为什么在实时新闻或销售看板里,Apollo 列表查询会变慢?
列表查询变慢通常是因为一次取数过多、缺少分页,或缓存策略/规范化没做好。在新闻监控这类高频场景里,哪怕很小的延迟也会不断叠加,最终造成 UI 卡顿与效率下降。
2. 做自动化新闻提取时,Apollo 列表查询最好的结构是什么?
只请求渲染列表所需字段(如标题、URL、时间戳)。把重字段(例如全文、图片)放到详情查询,并对结果做分页,确保载荷小、响应快。
3. Apollo Client 的缓存如何提升列表性能?
缓存会保存已获取的数据,让重复查询可以直接命中缓存、快速返回。配合正确的实体规范化与 fetch policy(如 cache-and-network),能显著加速列表视图并降低服务端压力。
4. Thunderbit 如何帮助新闻抓取并与 Apollo 集成?
Thunderbit 是无代码的 AI 网页爬虫,可从任意网站提取结构化新闻数据。你可以用它自动化新闻提取,然后把数据写入数据库或 GraphQL API,供 Apollo Client 使用。
5. 有哪些工具可以监控与排查 Apollo 列表查询性能?
可以实时查看查询、缓存状态与性能表现。再结合 New Relic、Uptrends 等可观测性面板跟踪延迟与错误率,持续优化查询设计。
想获取更多关于网页抓取、自动化与实时数据工作流的技巧?欢迎阅读 ,里面有深度解析、教程以及 AI 提效的最新实践。
了解更多