

AI 助手和 agentic 框架的发展快得惊人,但有一点一直没变:大家都希望它们更快、更轻,也更好安装。我对此感受很深——无论你是折腾 Raspberry Pi 的独立开发者,还是想控制云成本的 IT 负责人,大家对“最小化安装”方案的需求都很强烈。最近,我被问到 OpenClaw 轻量级替代方案的次数多到数不过来。很多人都想知道:有没有办法在不背上沉重安装包、内存开销和运维负担的前提下,依然用上 OpenClaw 的能力?
如果你正在找 OpenClaw 轻量级替代方案,或者在意 openclaw 占用小的安装方式,那你来对地方了。在这篇指南里,我会拆解“OpenClaw 最小化安装”到底是什么意思、为什么它重要,以及你该怎么根据自己的需求挑出最合适的轻量级方案——无论你是在老旧硬件上运行、要大规模部署,还是只是想别让服务器里再多一团“依赖乱炖”。
什么是 OpenClaw 轻量级替代方案?
先从基础说起:我们说的“OpenClaw 轻量级替代方案”到底指什么?
OpenClaw 是一个自托管的网关和编排层,面向 agentic 助手。简单说,它是一个把聊天界面(比如网页、桌面端或消息应用)连接到 AI 模型和工具的平台,同时负责管理记忆、状态和安全执行等功能(OpenClaw Docs)。但问题在于:标准版 OpenClaw 的安装基于 Docker,包含多个服务,而且光网关本身就建议至少预留 2GB 内存——这还没算你开始跑大型语言模型之前。
轻量级替代方案,指的是任何能提供和 OpenClaw 类似“助手”或“agent”能力,但安装体积更小、内存/CPU 占用更低、配置更简单的工具、框架或平台。你可以把它理解成:单容器部署、依赖更少,而且能在普通硬件或资源受限环境里跑起来。
标准版 OpenClaw 安装和轻量级/最小化替代方案之间的核心差异,通常体现在这几个方面:
- 安装复杂度: 轻量级方案通常只要一个 Docker 容器,甚至一个简单的二进制文件就能部署;而 OpenClaw 默认配置可能需要多个容器和持久化卷。
- 资源占用: 最小化替代方案就是为了更少的 RAM、CPU 和磁盘空间而设计的——整套栈有时只要 1–2GB 内存。
- 功能范围: 为了换来更轻、更好管的安装,你可能要舍弃一些高级网关或沙箱功能。
简单来说,OpenClaw 轻量级替代方案的核心,就是在不臃肿的前提下,保住 AI 聊天、工具集成和记忆这些核心能力。
为什么用户会寻找 OpenClaw 占用小的方案
那为什么大家突然都开始追求最小化安装和轻量级框架?根据我和用户、IT 团队的交流,原因其实很现实:
- 更快的部署和上手: 没人愿意花几个小时折腾 Docker Compose 文件,或者排查依赖冲突。最小化安装意味着你可以几分钟上线,而不是几个小时。
- 更低的资源消耗: 不管你部署在云 VM、Raspberry Pi 还是旧笔记本上,RAM 和 CPU 的每一点资源都很宝贵。更小的占用意味着你能跑更多实例、少付云账单,或者至少不会卡得离谱。
- 更容易维护: 组件越少,出问题的地方就越少。轻量级替代方案通常也更容易更新、备份和加固安全。
- 更适合边缘和离线场景: 如果你需要在本地、实验室里,或者在隐私敏感环境中运行助手,最小化安装简直就是救星。
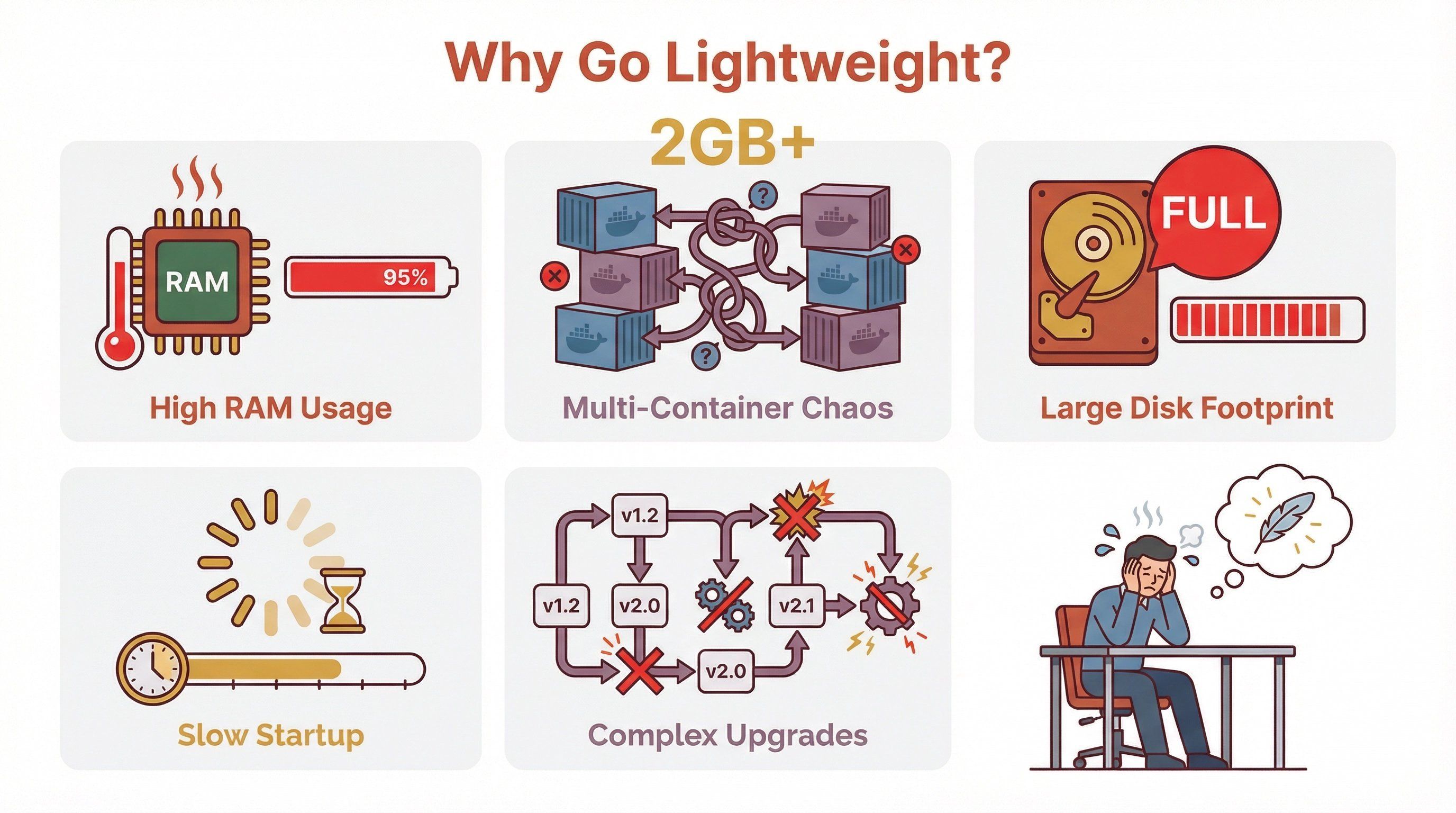
| 痛点 | 为什么重要 |
|---|---|
| RAM/CPU 要求高 | 限制在老旧或小型硬件上的部署 |
| 多容器部署 | 增加复杂度,也抬高维护和安全成本 |
| 磁盘占用大 | 对边缘设备或存储有限的环境不友好 |
| 启动慢 | 不利于快速原型和横向扩展 |
| 升级复杂 | 组件越多,升级时越容易出麻烦 |
如果你曾经试过在 2GB 内存的云 VM 上跑 OpenClaw,然后看着它慢得像蜗牛一样,你肯定懂我在说什么。
OpenClaw 最小化安装如何影响系统性能
我们稍微技术一点说。你的助手平台有多大、多复杂,会直接影响系统性能、稳定性和可扩展性。
标准版 OpenClaw 安装(带 Docker、内存存储和沙箱)光平台本身就很容易吃掉 2GB 以上 RAM,而这还没算你加载语言模型或向量数据库之前(OpenClaw Docker Guide)。再加上本地 LLM 推理或文档导入,内存需求很快就会涨到 4GB、8GB 甚至更多。
最小化安装替代方案的设计目标是:
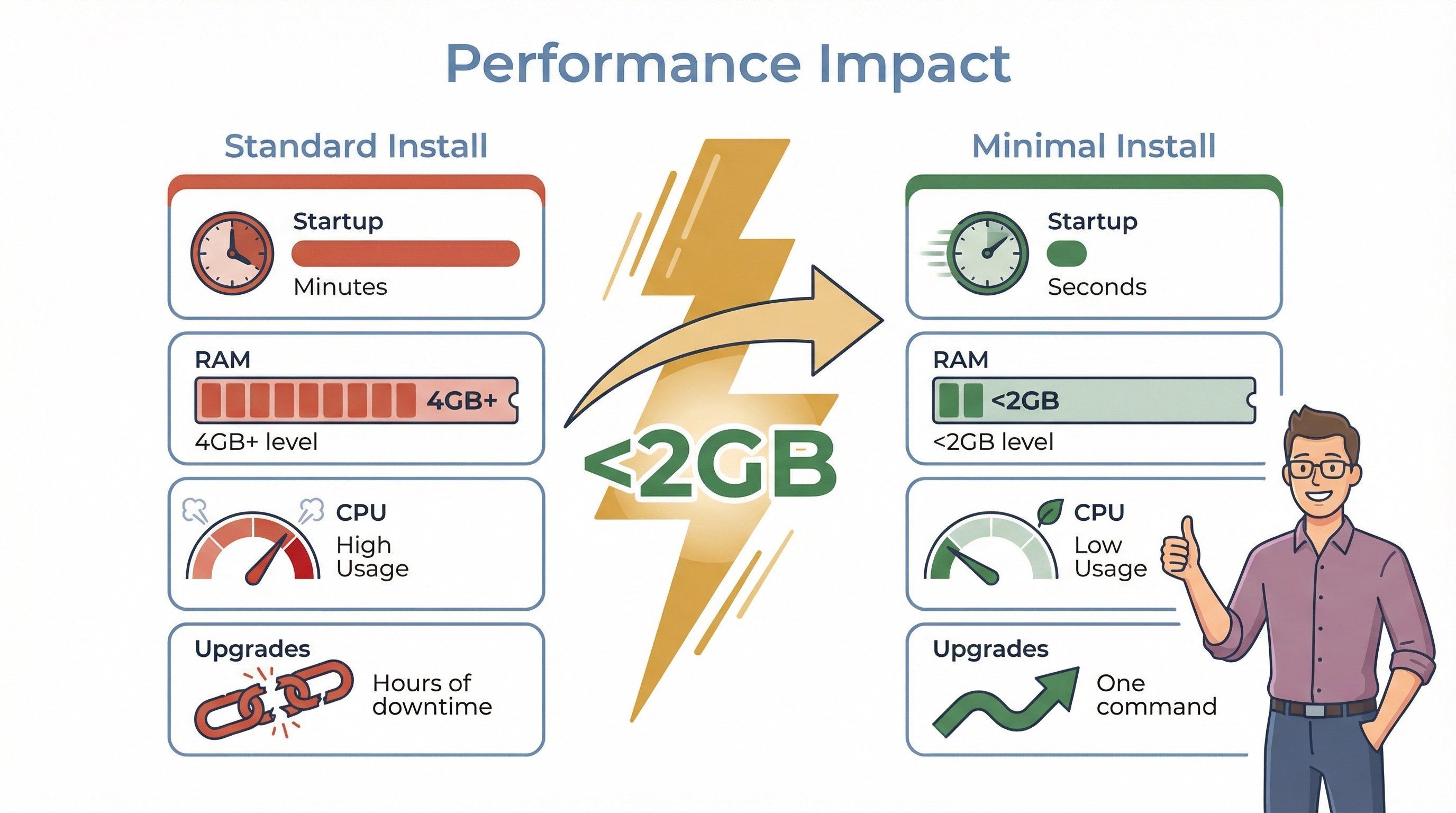
- 启动更快: 单容器或二进制安装可以在几秒内就绪,而不是几分钟。
- 内存更省: 把 LLM 推理交给外部 API,或者使用更小的本地模型,你就能把整套栈的 RAM 占用控制在 2GB 以下(Open WebUI Quick Start)。
- CPU 负载更低: 编排开销更少,就意味着更多资源可以留给真正的 AI 任务。
- 冲突更少: 服务更少,端口冲突、依赖不匹配或升级意外也会更少。
这里有个真实例子:LibreChat 建议至少 2GB 内存(推荐 4GB),而 Dify 则建议至少 4GB。相比之下,Open WebUI 可以在单用户模式下用单容器运行,内存占用要小得多——尤其是你用的是远程 LLM API 时。
你可能会看到的性能提升:
- 启动时间从几分钟缩短到几秒
- RAM 占用减少 50% 甚至更多
- 空闲时 CPU 占用更低
- 升级更快,停机更少
选择 OpenClaw 轻量级替代方案的关键标准
并不是所有“轻量级”方案都一样。下面这些,是我建议你在评估时重点看的内容:
- 安装体积: 下载包有多大?能不能只用一个 Docker 容器或一个二进制文件部署?
- 内存占用: 平台的基础 RAM 占用是多少(不含 LLM 推理)?
- 启动速度: 从“docker run”到可用助手,需要多久?
- 升级难度: 升级过程是否简单,还是每个月都得和依赖问题死磕?
- 兼容性: 是否支持你需要的 LLM、工具和集成?
- 功能集: 你拿到的是自己真正需要的核心助手功能,还是为了极简牺牲太多?
- 安全和隔离: 平台是否为工具执行提供沙箱或隔离能力?
下面是一个你可以直接拿去用的快速清单:
| 标准 | 为什么重要 | 要关注什么 |
|---|---|---|
| 安装体积 | 部署更快,所需存储更少 | <500MB 镜像,单二进制 |
| 内存占用 | 能在更小的硬件上运行,云成本更低 | 基础占用 <2GB |
| 启动速度 | 便于快速原型,停机更少 | <30 秒即可就绪 |
| 更新 | 维护更少,意外更少 | 一条命令升级,API 稳定 |
| 兼容性 | 避免厂商锁定,便于未来扩展 | OpenAI/Ollama API,插件模型 |
| 功能 | 不要为了极简丢掉必需功能 | 记忆、工具、认证、RAG |
| 安全 | 工具执行更安全,风险更低 | 容器或进程隔离 |
关键是,在你真正需要的功能和最小化占用之间找到平衡。有时候“少即是多”,但有时候“少”也可能就是“不够用”。
适合最小化安装的热门 OpenClaw 轻量级替代方案
根据近期的行业盘点和我自己的研究,下面这些是针对不同场景比较出色的 OpenClaw 轻量级替代方案:

1. Open WebUI
- 最适合: 单用户、资源占用极低的安装
- 轻量的原因: 单 Docker 容器,可选单用户模式,数据用持久化卷保存,还可以用远程 LLM API 尽量降低 RAM/CPU 占用
- 独特优势: 支持离线使用,兼容 Ollama 和 OpenAI 兼容端点,社区活跃(Open WebUI GitHub)
- 取舍: 不能原生复刻 OpenClaw 的网关/多界面模型;工具隔离能力比较基础
2. LibreChat
- 最适合: 想要熟悉的“ChatGPT 克隆”体验的多用户团队
- 轻量的原因: Docker 部署,官方公布了最低要求(2GB RAM),小团队可以按单服务方式运行
- 独特优势: 安全的多用户认证,支持广泛的提供商,近期还加强了安全性(LibreChat GitHub)
- 取舍: 更偏向 Web 应用;不是面向多聊天界面的网关;部分功能需要额外服务
3. AnythingLLM
- 最适合: 私有化、开箱即用的一体化 AI 工作区,且希望尽量少配置
- 轻量的原因: 支持 Docker 或桌面端安装,内置向量数据库,基础使用时 2GB RAM 就能跑
- 独特优势: 支持多用户、agents、文档流水线,隐私优先(AnythingLLM Docs)
- 取舍: 不是聊天界面网关;工具隔离取决于你的架构设计
4. PrivateGPT
- 最适合: 私有文档问答和上下文感知应用
- 轻量的原因: 支持 Docker Compose 配置文件,如果用外部 LLM API,可以在适度资源下运行
- 独特优势: 兼容 OpenAI API,隐私姿态很强,向量存储选项灵活(PrivateGPT GitHub)
- 取舍: 不是 OpenClaw 消息网关的即插即用替代品
5. Flowise
- 最适合: 想要最小化安装的可视化工作流/agent 构建器
- 轻量的原因: 支持 NPM 或 Docker 安装,默认使用 SQLite,可作为单服务运行
- 独特优势: 可视化工作流画布,插件生态,方便本地测试(Flowise Docs)
- 取舍: 不是现成的助手;你需要自己搭建连接器
对比 OpenClaw 占用小替代方案:功能表
我们把这些选项并排放在一起,快速对比一下:
| 平台 | 安装方式 | 最小 RAM(平台) | 启动速度 | 多用户 | LLM 后端支持 | 工具/插件模型 | 安全/隔离 | 最适合 |
|---|---|---|---|---|---|---|---|---|
| Open WebUI | Docker(单容器) | 低到中等 | 快 | 可选 | Ollama、OpenAI 兼容 | Python 工具 | 基础 | 单用户、极简 |
| LibreChat | Docker(多服务) | 最低 2GB(推荐 4GB) | 快 | 是 | 多家提供商 | agents、插件 | 多服务 | 团队、聊天导向 |
| AnythingLLM | Docker/桌面端 | 2GB 以上 | 快 | 是 | 本地 + 托管 | agents、API | 内置向量数据库 | 私有化、一体化 |
| PrivateGPT | Docker Compose | 中等 | 快 | 可选 | 本地 + 托管 | RAG API | API 隔离 | 私有文档问答 |
| Flowise | NPM/Docker | 低到中等 | 快 | 可选 | 提供商节点 | 可视化构建器 | SQLite/数据库 | 可视化工作流构建器 |
注:如果你运行本地 LLM 或导入大量文档,RAM 占用可能会飙升。想要真正的最小化安装,最好使用远程 LLM API 或小模型。
评估和测试 OpenClaw 最小化安装方案的实用步骤
准备试试轻量级替代方案了吗?这是我常用的评估框架:
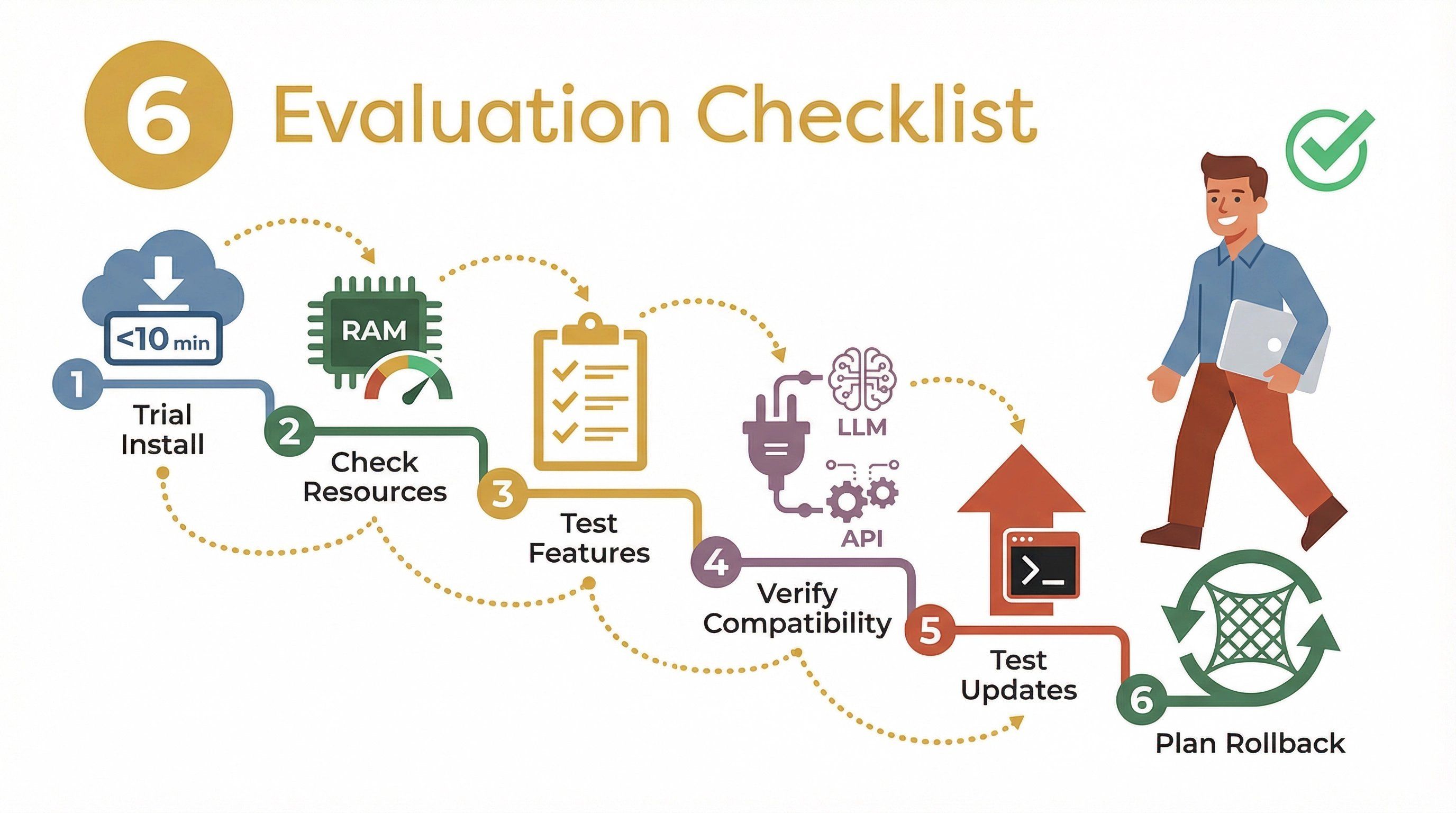
- 试装: 在沙箱或测试 VM 中部署平台,记录安装和启动所需时间。
- 测资源占用: 用系统工具(如
htop或docker stats)监控空闲和基础使用时的 RAM 与 CPU。 - 跑基础工作流: 测试核心功能——聊天、工具/插件执行、文档导入等。
- 检查兼容性: 连接你常用的 LLM、插件或外部 API。
- 测试更新: 尝试升级平台,看看过程是否顺畅。
- 沙箱测试: 如果可能,在可丢弃的环境里运行,这样一旦出问题就能轻松回滚。
下面是一个快速清单:
| 步骤 | 要关注什么 |
|---|---|
| 安装/启动 | <10 分钟,无复杂依赖 |
| 资源占用 | 基础 RAM <2GB,空闲时 CPU 占用低 |
| 功能测试 | 核心助手功能按预期工作 |
| 兼容性 | 可连接你的 LLM 和工具 |
| 更新流程 | 一条命令升级,或原地升级 |
| 回滚 | 容易恢复到上一版本 |
切换到 OpenClaw 轻量级替代方案时的常见坑
切换到最小化安装并不总是一帆风顺。下面是一些常见坑,以及怎么避开它们:
- 功能缺失: 一些轻量平台会省略高级网关或沙箱功能。一定要确认你没有丢掉工作流里真正关键的东西。
- 文档有限: 小项目的文档可能比较少。可以去社区论坛或 GitHub issues 里找帮助。
- 集成挑战: 并不是所有插件或工具都开箱即用。要尽早测试你最需要的集成。
- 安全取舍: 更简单的安装有时意味着更少的隔离,或者默认安全配置更弱。记得加固部署(认证、TLS、防火墙)。
- 迁移麻烦: 把聊天记录或文档这类数据从 OpenClaw 迁移到新平台,可能并不轻松。要预留迁移窗口,并做好完整备份。
我的建议是:先做试点项目,认真测试,在你对新方案有十足把握之前,旧环境先别急着下线。
结论:如何为你的最小化安装需求做出正确选择
OpenClaw 轻量级替代方案的兴起,正是对重型、复杂安装在现实中各种痛点的直接回应。无论你是独立开发者、小团队,还是企业 IT 负责人,总会有一款最小化安装方案,能在不臃肿的前提下提供你需要的助手能力。
我会这样建议你:
- 先定义必需功能: 明确哪些能力是你不能没有的(多用户、插件支持、安全性等)。
- 用上面的标准和对比表 来筛选最适合的替代方案。
- 先试点,再衡量: 在自己的环境里测试,测资源占用,并检查兼容性。
- 规划迁移: 不要着急,慢慢把数据和工作流迁过去。
别忘了,最好的 OpenClaw 最小化安装方案,永远是最适合你的使用场景、硬件和团队技能组合的那个。轻量级不代表能力弱,只是更聚焦而已。
用 Thunderbit 自动化网页数据提取 Get Started Free
如果你也想把网页数据提取自动化整合进你的助手工作流,可以看看 Thunderbit。它是我们基于 AI 的网页爬虫,专为最小化配置和高效生产力而设计。想了解更多关于自动化、爬取和 AI 工具的深度内容,也欢迎访问 Thunderbit 博客。
常见问题
1. 什么是 OpenClaw 轻量级替代方案?
OpenClaw 轻量级替代方案,是指在提供和 OpenClaw 类似 AI 助手能力的同时,安装体积更小、内存/CPU 占用更低、配置更简单的工具或框架——非常适合最小化安装场景或资源受限环境。
2. 为什么我需要关注 OpenClaw 占用小的方案?
占用小的方案部署更快、更省 RAM/CPU、更容易维护,而且还能在老旧硬件或边缘/离线环境中运行——非常适合快速原型或对成本敏感的部署。
3. 轻量级替代方案的主要取舍是什么?
你可能会失去一些高级功能(比如多界面网关或带沙箱的工具执行),而且为了和 OpenClaw 完全对等,可能需要额外组件。一定要确认你的必需功能都受支持。
4. 我该如何判断某个轻量级替代方案是否适合我?
测试安装过程、测资源占用、跑你的核心工作流、检查与常用 LLM/工具的兼容性,并确认平台满足你的安全和更新要求。
5. 最受欢迎的 OpenClaw 轻量级替代方案有哪些?
一些热门选项包括 Open WebUI、LibreChat、AnythingLLM、PrivateGPT 和 Flowise。它们各自在不同的最小化安装需求上都有自己的优势。
如果你已经准备好减轻技术栈负担、释放 RAM,不妨试试这些最小化安装方案中的一个。如果你想零折腾地自动化网页数据提取,Thunderbit 随时都能帮你。
试用 Thunderbit AI 网页爬虫 Get Started Free
了解更多




