
上周我整整折腾了一个下午,想让一个 AI 代理在一个需要登录的门户网站里填写供应商表单。到了第三个小时,我盯着“Connection Refused”错误,VPS 也已经内存爆掉了,最后甚至认真考虑过,干脆直接手动把整件事做完算了。
这几乎就是 OpenClaw 浏览器自动化的入门体验。这个工具可以浏览网页、抓取数据、填写表单,还能用自然语言指令串起复杂工作流——确实很强。但真正让大多数人卡住的,往往不是功能本身,而是“听起来很厉害”和“我这台机器上真的能跑起来”之间的那道坎。
我在这条坎的两边都踩过不少坑:一边是在 Thunderbit 做自动化工具,一边是在测试开源生态到底能提供什么。所以我写了这篇指南,希望补上我当年最需要的那份资料:完整安装流程、最容易踩坑的浏览器模式选择、适合 Windows 的原生方案(毕竟没必要把 WSL 当成前置条件)、反爬生存指南、真实输出示例、常见报错和修复办法,以及 OpenClaw 到底什么时候该用、什么时候其实有点过度设计。
用 AI 从任何网站抓取数据 Get Started Free
什么是 OpenClaw 浏览器自动化?
OpenClaw 是一个免费、开源的 AI 代理平台(MIT 许可证),可以代替你控制浏览器。你不需要写 Selenium 脚本或 Puppeteer 代码,只要用自然语言描述你想做什么——比如“打开这个页面,提取所有商品名称和价格”——AI 就会自己想办法完成。它采用编号快照系统,代理会先识别页面元素,给它们分配引用编号,然后一步一步与之交互。
它的架构由三部分组成,所以安装时不只是“装个插件”那么简单:
- Gateway(VPS/服务器): 处理你的指令并连接 LLM 的“大脑”。默认运行在 18789 端口。
- Node Host(本地机器): 一个转发节点,让 Gateway 能把浏览器指令发到你本地的 Chrome。通常通过 Tailscale 之类的安全隧道连接。
- Chrome 扩展(Browser Relay): 让代理直接控制你真实浏览器里的标签页。
另外还有 Control Service(18791)、CDP Relay(18792)以及托管浏览器 CDP(18800–18899,最多支持 100 个并行配置文件)。
没错,组件确实不少。但一旦你理解每一部分是干什么的,整个设置过程就顺了。可以把它想成遥控车:Gateway 是遥控器,Node Host 是无线信号,Chrome 扩展就是那辆车本身。

为什么 OpenClaw 浏览器自动化对业务团队很重要
知识型工作者最多有 60% 的时间都耗在日常行政事务上,而不是高价值工作,其中每天还有 1.8 小时只是花在搜索和收集信息上。Smartsheet 发现,超过 40% 的员工 每周至少有四分之一的时间花在手动、重复的任务上。光是手动录入数据,美国企业每位员工每年估计就要损失 8,500 美元。
这正是 OpenClaw 浏览器自动化要解决的问题。放到实际业务里,它对应的是这些具体场景:
| 使用场景 | OpenClaw 的作用 | 业务结果 |
|---|---|---|
| 潜在客户开发 | 从目录和公司页面抓取联系方式 | 更快填满销售管道 |
| 竞品价格监控 | 每天浏览产品页并提取价格 | 实时获取竞争情报 |
| 表单填写 / 数据录入 | 填写重复性的网页表单(CRM、门户、申请表) | 每周节省数小时 |
| 内容监控 | 检查竞品博客、招聘页、新闻稿 | 更早捕捉竞争信号 |
| QA / 测试 | 跑完整个网页流程,验证是否正常 | 降低用户体验损坏的概率 |
AI 代理市场在 2025 年已经达到 73.8 亿美元,相比 2023 年的 37 亿美元几乎翻倍,而且 88% 的组织 已经在至少一个业务环节使用 AI 自动化。它早就不是小众玩法了。
Sandbox Chromium、Browser Relay 和 Chrome Remote Debugging:如何选对模式
根据我的经验,新手在使用 OpenClaw 时最大的挫败感,往往就来自选错浏览器模式。我见过不少人花几个小时调试连接问题,而这些问题其实只要一开始换个模式就能避免。OpenClaw 提供三种连接方式,每一种都有真实的取舍:
- Sandbox Chromium(托管配置文件): OpenClaw 在服务器上自己启动一个无头浏览器。没有登录状态,上手快,设置简单——但更容易被反爬系统识别。
- Browser Relay(现有会话): 在你本地机器上运行一个节点,把 VPS 的指令转发到你实际的 Chrome 浏览器。支持登录状态和 Cookie,保留真实浏览器指纹。
- Chrome Remote Debugging(远程 CDP): 通过 WebSocket URL 连接远程浏览器。可以完整访问会话,配置复杂度最高。适用于 Browserless 或 Browserbase 这类云服务。

对比表:三种浏览器模式
| 因素 | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| 登录支持 | ❌ 不支持(全新配置文件) | ✅ 支持(真实会话) | ✅ 支持(预先认证) |
| 反爬风险 | ⚠️ 中高 | ✅ 低(真实指纹) | ✅ 低(由服务商托管) |
| 速度 | ✅ 快 | ⚠️ 较慢(网络转发) | ⚠️ 视情况而定 |
| 配置复杂度 | 低 | 中 | 高 |
| 完整功能支持 | ✅ 是(全部功能) | ⚠️ 有限制(不支持批量、下载拦截) | 取决于服务商 |
| 最适合 | 公开页面、快速抓取 | 需要登录的网站、表单填写 | 云端基础设施、全天候监控 |
决策流程:你该选哪一种?
按顺序回答这几个问题:
- “你需要登录吗?”——不需要 → Sandbox Chromium。需要 → 下一题。
- “网站反爬机制很强吗?”——是 → Browser Relay(你的真实浏览器指纹更不容易被识别)。不是 → Browser Relay 或 Remote CDP 都行。
- “你需要一个持久在线、全天候运行的会话吗(比如 24/7 监控仪表盘)?”——需要 → 搭配云服务使用 Remote CDP。不需要 → Browser Relay。
真实场景对应:
- 抓取公开的 Amazon 商品列表 → Sandbox Chromium
- 填写登录后的 CRM 表单 → Browser Relay
- 全天候监控内部分析仪表盘 → 配合 Browserless/Browserbase 使用 Remote CDP
一开始把这个模式选对,真的能帮你省下好几个小时的调试时间。
开始之前
- 难度: 中级(需要会用 CLI)
- 预计耗时: 完整安装 45–75 分钟;每一步约 10–15 分钟
- 你需要准备: 一台 VPS(至少 2GB RAM,推荐 4GB)、Node.js v22.12.0+、一个 Tailscale 账号(免费)、Chrome 浏览器,以及耐心
第 1 步:在 VPS 上运行 OpenClaw(也可以本地运行)
VPS 是 OpenClaw 的“大脑”所在。把它跑起来有两条路:
方案 A:一键 VPS 托管
有些服务商提供预配置好的 OpenClaw 镜像:
| 服务商 | 起步价格 | 说明 |
|---|---|---|
| Hostinger | 起价 $6.99/月 | 预配置镜像 |
| 腾讯云 Lighthouse | 促销期间约 $0.08/年 | 推荐 2 核 / 4GB |
| Hetzner | 起价 $4.09/月(CX22) | 性价比高;需手动安装 |
| DigitalOcean | 起价 $4/月 | 需手动安装 |
| Vultr | 起价 $3.50/月 | 需手动安装 |
方案 B:手动 CLI 安装
# 通过 npm 安装(需要 Node.js v22.12.0+)
npm install -g openclaw
# 运行初始化向导
openclaw onboard
# 生成 gateway token(请保存好,node host 会用到)
openclaw doctor --generate-gateway-token
# 验证配置
openclaw doctor --fix
最低配置: 2GB RAM(1GB 很容易崩溃),推荐 4GB。每个无头浏览器实例闲置时也会占用 400–800 MB。若使用 Docker,请设置 shm_size: '2gb'——这对稳定性非常关键。
完成这一步后,你应该已经把 OpenClaw 跑起来了,并且保存好了 Gateway token。(我一般放在密码管理器里,千万别丢。)
第 2 步:用 Tailscale 连接 VPS 和本地机器
Tailscale 会在你的 VPS 和本地设备之间建立一个私有加密通道,这样浏览器指令就不会暴露到公共互联网。考虑到 OpenClaw 在 2026 年初被 Kaspersky 标记了 512 个漏洞,这一步最好别跳过。
# 在 VPS 上
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# 记下 VPS 的 Tailscale IP(100.x.x.x)
# 将 Gateway 配置为监听 Tailscale 网络
openclaw config set gateway.listen "100.x.x.x:18789"
在本地机器上从 tailscale.com/download 安装 Tailscale。两台设备必须登录同一个 Tailscale 账号。
如果你不想用 Tailscale,可以选这些替代方案:
| 因素 | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| 配置时间 | 5 分钟 | 10–15 分钟 | 20–30 分钟 |
| 费用 | 免费(个人使用) | 免费 | 免费 |
| NAT 穿透 | 自动 | 自动 | 手动 |
现在你应该已经能从本地机器 ping 通 VPS 的 Tailscale IP 了。如果不行,先检查两台设备是否在同一个 Tailscale 账号下。
第 3 步:在本地设备上安装 Node Host
Node Host 的作用是把 VPS Gateway 发来的浏览器指令转发给你本地的 Chrome——它相当于服务器和浏览器之间的翻译器。
# 安装 node host 包
npm install -g @openclaw/node-host
# 设置第 1 步生成的 gateway token
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# 启动 node host,并指向 VPS 的 Tailscale IP
openclaw node install --host 100.x.x.x --port 18789
# 从 VPS 端批准连接
openclaw node approve <node-id>
你应该会看到节点已连接并批准的提示。如果批准步骤卡住了,重启 VPS 上的 Gateway 进程。
第 4 步:安装 OpenClaw Chrome 扩展
这个扩展可以让代理直接控制浏览器标签页。你也可以在 Chrome 网上应用店搜索 “OpenClaw Browser Relay” 找到它。
# 安装扩展文件
openclaw browser extension install
# 或者手动安装:
# 1. 打开 chrome://extensions
# 2. 开启“开发者模式”(右上角开关)
# 3. 点击“加载已解压的扩展程序”→ 选择扩展目录
# 4. 固定到工具栏
# 5. 确认角标显示“ON”
如果角标显示“ON”,说明一切正常。如果还是“OFF”,就直接看下面的排错部分。
第 5 步:运行你的第一个 OpenClaw 浏览器自动化任务
先打开目标标签页,然后在 OpenClaw 的聊天界面里试一个简单任务:
打开 https://books.toscrape.com,并提取页面上每本书的标题和价格
预期流程: 下达指令 → 代理截取页面快照(识别带编号的页面元素)→ 代理提取数据 → 返回结构化输出,格式为 JSON 或 CSV。
根据我的经验,建议先从非常简单的提示词开始。把需求描述得过头,反而可能把 AI 搞糊涂——只有在代理误解你的意图时,再补充细节。
如果第一页有 20 本书,大概需要 30–60 秒。能拿到结构化数据?说明你的 OpenClaw 浏览器自动化环境已经跑通了。
Windows 上的 OpenClaw 浏览器自动化:原生安装路径
大多数 OpenClaw 教程默认你用的是 macOS 或 Linux。要是你在 Windows 上,这点你大概率已经发现了。某个论坛用户说得很准确:“很多方案从概念上看都说得通,但没有一个是为原生 Windows 设计的。”
下面说说真正能用的方法。
方案 A:Windows 上的 Chrome Remote Debugging(推荐的原生方案)
这是最稳定的 Windows 原生做法。打开 PowerShell,带上远程调试参数启动 Chrome:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
如果 Chrome 不在这个路径,试试下面这个:
# 检查其他安装位置
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# 或检查 AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
然后在 openclaw.json 配置里,把 cdpUrl 设为 ws://localhost:9222,让 OpenClaw 通过 Remote CDP 连接。
方案 B:Windows 上用 Docker Desktop 兜底
如果原生方案不稳定,可以在 Windows 上用 Docker Desktop 跑一个无头 Chromium 容器:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# 将 OpenClaw 指向:cdpUrl: "ws://localhost:9222"
这会多一层复杂度,但对某些用户来说更稳定。能用,但不算优雅。
Windows 常见错误清单
| 错误 | 原因 | 修复方法(PowerShell) |
|---|---|---|
| 9222 端口已被占用 | 另一个 DevTools 会话已经打开 | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| 找不到 Chrome 二进制文件 | 路径不对 | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Tailscale 连接被拒绝 | Windows 防火墙拦截 | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| npm 权限错误 | 没有以管理员身份运行 | 以管理员身份运行 PowerShell,或使用 nvm-windows |
上面所有命令都是 PowerShell,不是 bash。可以直接复制粘贴。
OpenClaw 浏览器自动化反爬生存指南
反爬检测是 OpenClaw 用户最常遇到的痛点。OpenClaw 默认的 Chromium 没有内置隐身机制——网站可以通过 WebDriver 标志、屏幕尺寸、字体指纹和 IP 信誉来识别它。我见过代理在某些网站上几秒内就被拦下。
不过应对方法是分层的。先用最简单的修复,再按需升级。
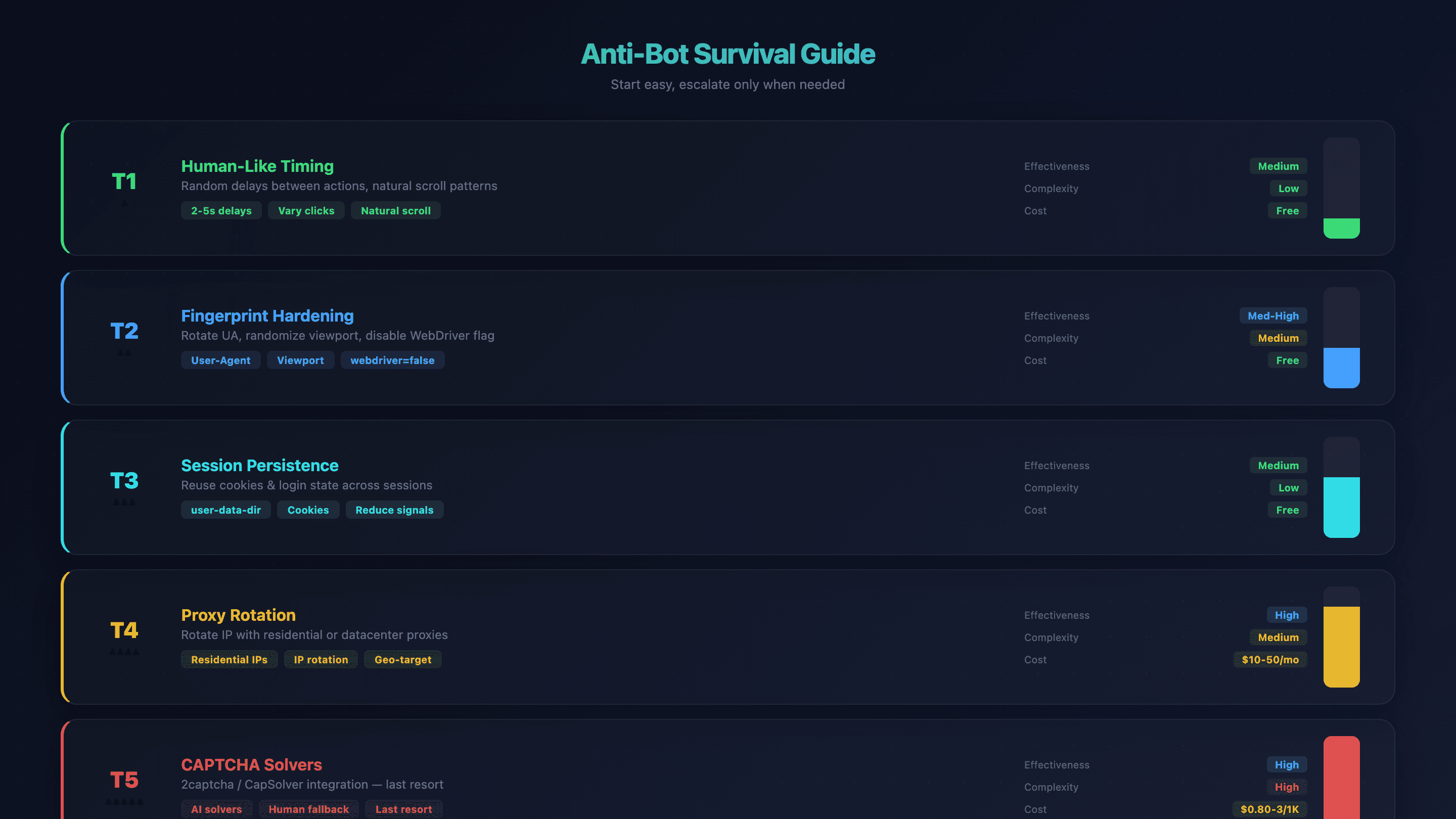
第 1 层:像真人一样的操作节奏
在提示词里给动作之间加随机延迟。不要让代理像机器一样飞快点击,而是直接告诉它:“每次点击之间等待 2–5 秒。” AI 本身就会在一定程度上变化节奏,但明确要求会更稳。
效果: 中等 | 复杂度: 低 | 成本: 免费
第 2 层:强化浏览器指纹
轮换 user-agent 字符串,随机化视口大小,并让 OpenClaw 自动关闭 navigator.webdriver 标志(通过 --disable-blink-features=AutomationControlled)。
# 设置自定义请求头
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# 随机化视口
openclaw browser set viewport 1366 768
# 设置时区和语言环境
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
如果想进一步提升隐蔽性,社区推荐 Camoufox(基于 Firefox 的反检测浏览器,带有 C++ 引擎级指纹伪装)。
效果: 中高 | 复杂度: 中 | 成本: 免费
第 3 层:保持会话持久化
使用 user-data-dir 来跨会话保留 Cookie 和登录状态。这样可以减少“全新浏览器”信号,降低触发反爬的概率。
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
效果: 中等 | 复杂度: 低 | 成本: 免费
第 4 层:代理轮换
当节奏和指纹都不够时,就轮换 IP。住宅代理更难被识别;数据中心代理速度更快、价格也更便宜。
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
注意:浏览器级代理配置目前仍然只是一个功能请求(GitHub Issue #8079)。当前必须在操作系统层面或环境变量层面设置代理。
| 服务商 | 住宅代理 | 数据中心代理 | 适合场景 |
|---|---|---|---|
| Bright Data | $4–8.40/GB | $0.43–0.60/GB | 企业级,高质量需求 |
| Oxylabs | $6–8/GB | $0.48–5/GB | 大规模抓取 |
| Decodo(Smartproxy) | $4–5.50/GB | $0.70–5/GB | 中等预算 |
| IPRoyal | $5–7/GB | -- | 预算友好 |
| DataImpulse | $1/GB | -- | 最低成本 |
效果: 高 | 复杂度: 中 | 成本: 每月 $10–50
第 5 层:CAPTCHA 识别服务
最后手段。可以集成 2captcha 或 CapSolver 这类服务。
| 服务 | reCAPTCHA v2 | Cloudflare Turnstile | 延迟 |
|---|---|---|---|
| 2Captcha | $2.99/1K | $2.99/1K | 15–45 秒(人工解答) |
| CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5–10 秒(AI) |
FlareSolverr(开源 Cloudflare 绕过工具)在 2025–2026 年被认为不太可靠,因为 Cloudflare 的防护在不断升级。
效果: 高 | 复杂度: 高 | 成本: 每 1K 次 $0.80–3
反爬总结表
| 技术 | 效果 | 复杂度 | 成本 |
|---|---|---|---|
| 像真人一样的操作节奏 | 中等 | 低 | 免费 |
| 指纹强化 | 中高 | 中 | 免费 |
| 会话持久化 | 中等 | 低 | 免费 |
| 代理轮换 | 高 | 中 | 每月 $10–50 |
| CAPTCHA 识别服务 | 高 | 高 | 每 1K 次 $0.80–3 |
如果你反复碰到反爬墙、只是想拿到数据:Thunderbit 的云端抓取对公开网站已经默认处理好反爬问题——不需要代理配置,也不用调指纹。这是一种完全不同的方法(AI 通过托管云基础设施每次读取页面),可以在标准数据提取任务里直接绕开这场反爬军备竞赛。
真实输出:OpenClaw 浏览器自动化到底能产出什么?
在你花 45–75 分钟做安装前,肯定会想先看看最终结果长什么样。很合理——下面给你三个工作流示例和真实输出。
示例 1:网页抓取——提取商品数据
提示词: “打开 https://books.toscrape.com,并提取页面上每本书的标题和价格”
输出(前 5 行):
| 标题 | 价格 |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
耗时: 大约 45 秒可得到 20 行(单页)。如果要翻页,需要继续指令:“点击 Next 按钮并重复 5 页。” 总计:大约 3 分钟拿到约 100 行数据。
示例 2:表单自动化——填写多字段网页表单
场景: 填写一个供应商咨询表单,包括公司名称、联系方式和感兴趣的产品。
代理会先对表单进行快照,再根据引用编号识别每个字段并按顺序填写。填写前:表单为空。填写后:所有字段都已填好,并显示确认消息。下拉菜单或复选框也由快照系统处理——代理会“看到”选项,并选择正确答案。
耗时: 6 个字段的表单大约 30 秒。
示例 3:翻页抓取——跨多页采集数据
初始结果: 第 1 页有 20 行。向代理下达“点击 Next 并重复所有页面”后:在 books.toscrape.com 上抓到 50 页共 1,000 行。代理通过快照识别“Next”按钮,并循环点击。
耗时: 完整 1,000 行数据大约 12 分钟。
同样的抓取任务在 Thunderbit 中是什么体验?
以 books.toscrape.com 为例,在 Thunderbit 里的流程如下:
- 安装 Thunderbit Chrome 扩展(约 30 秒)
- 打开页面
- 点击“AI 推荐字段”→ AI 自动识别标题、价格、库存、评分
- 点击“抓取”→ 提取 20 行
- 使用翻页控制 → 抓取全部页面
- 导出到 Google Sheets(免费)
总耗时:从零到导出数据大约 3 分钟,而且不需要 VPS、CLI 或任何配置。
重点不是谁“更好”,而是你真正想完成什么。
什么时候 OpenClaw 浏览器自动化其实有点大材小用(以及该用什么替代)
OpenClaw 擅长处理复杂、多步骤、具备代理式决策能力的自动化——比如需要登录的网站流程、把浏览器操作和 shell 命令串起来、或者在 VPS 上 24/7 持续运行。但如果目标只是“从列表页提取商品数据”或“从目录中抓邮箱”,那整套 VPS + Tailscale + node host 方案大概率就是过度设计了。
我见过有人为了一个两分钟就能完成的任务,花了 60 多分钟来搭环境。这个交换一点都不划算。

选对工具:对比表
| 因素 | OpenClaw 浏览器自动化 | Thunderbit |
|---|---|---|
| 搭建时间 | 45–75 分钟(VPS + Tailscale + node host) | 约 2 分钟(安装 Chrome 扩展) |
| 是否需要写代码 | 需要 CLI + 自然语言提示 | 完全不需要——点“AI 推荐字段”→“抓取” |
| 反爬处理 | 手动配置(代理、指纹等) | 内置云端抓取 |
| 登录墙页面处理 | ✅ Browser Relay / 远程调试 | ✅ 浏览器抓取模式 |
| 子页面补充采集 | 每个工作流都要自定义脚本 | 一键子页面抓取 |
| 定时 / 7×24 运行 | 基于 VPS,持续运行 | 内置定时爬虫 |
| 月成本 | $8–14(轻度)到 $110–280(重度) | $0(免费套餐)到 $15/月 |
| 维护负担 | 高(更新、VPS、调试) | 几乎为零——AI 会适应页面变化 |
| 最适合 | 复杂代理式工作流、自定义管道 | 数据提取、表单填写、线索开发、价格监控 |
按场景选工具
- 你需要多步骤的代理式工作流,要把浏览器操作和 shell 命令、消息应用、数据库串联起来 → OpenClaw 更合适。
- 你想抓网页数据、填写表单或监控价格,而且不想碰终端 → Thunderbit 会更快帮你完成。 你也可以看看 Thunderbit YouTube 频道 的快速演示。
- 你只需要一个针对某个 API 端点的轻量脚本 → 也许一个简单的 Python requests 脚本就够了。
这就是我在团队里有人问“这个该用什么工具?”时,真正会用的判断框架。
常见 OpenClaw 浏览器自动化报错及修复方法
建议把这一段收藏起来。它按症状分类,方便你直接 Ctrl+F 找解决方案。
“Connection Refused” 或 Node Host 连接不上
可能原因(按这个顺序排查):
- 两台设备上的 Tailscale 没有运行 → 在两台机器上都执行
tailscale status - Gateway 仍然只监听 localhost,没有绑定到 Tailscale 网络 →
openclaw config set gateway.listen "100.x.x.x:18789" - IP 地址填错了 → 用
tailscale ip -4再确认一次 - 防火墙拦截了 18789 端口 →
sudo ufw allow 18789/tcp(Linux)或添加 Windows 防火墙规则
扩展角标一直是“OFF”,或者标签页没被识别
- 扩展没有在开发者模式下加载 → 打开
chrome://extensions→ 开启开发者模式 → 重新加载 - Node host 没有运行 → 用
openclaw node start重启 - Chrome 实例冲突 → 关闭所有 Chrome 实例,重新启动浏览器,再重新加载扩展
代理返回空数据或错误数据
- 页面还没完全加载: 提示代理“导航后先等 3 秒再提取”。很多 SPA 需要时间渲染。
- 遇到反爬拦截: 看看是不是 CAPTCHA 页面,而不是实际内容。把模式从 Sandbox Chromium 切换到 Browser Relay。
- 快照过期: 让代理“重新截取快照”——页面跳转后引用编号会失效。
“9222 端口已被占用”
通常是 Chrome DevTools 或其他自动化工具已经在用这个端口。
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
VPS 内存耗尽
每个无头浏览器实例会占用 400–800 MB 内存。多个实例同时运行时,小型 VPS 很容易崩溃。
修复方法:
- 禁用图片/CSS/字体加载:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - 并发实例数不要超过内存承受范围
- 在 Docker 配置里设置
shm_size: '2gb' - 启用会话休眠:
OPENCLAW_HIBERNATE_AFTER=300 - 如果你需要更大余量,升级到 4GB 以上 RAM 的 VPS
让 OpenClaw 浏览器自动化稳定运行的小技巧
这些是我长期搭建和维护这类环境时总结出来的一些最佳实践:
- 对于只做数据提取的任务,关闭图片、样式表和字体。 这样能显著降低资源消耗,也能提速。
- 复用浏览器实例,不要每个任务都新开一个。 新实例很耗内存,而且更容易触发反爬信号。
- 先从简单提示词开始。 只有在代理理解错了时再补充细节。描述太多反而更容易把 AI 搞混。
- 监控 VPS 的资源使用情况(CPU、RAM),在触顶之前提前扩容。凌晨两点去修一个崩掉的 VPS,体验真的很糟。
- 保持 OpenClaw 和 Chrome 扩展更新。 但最好先在测试环境里验证更新。OpenClaw 大约每月会发布 13 个版本,并不是每次更新都很顺。
- 对于持续、重复的任务(每天查价格、每周拉线索),Thunderbit 的定时爬虫 可以让你直接用自然语言设置间隔,然后彻底忘掉 VPS 维护这件事。
伦理与法律注意事项
内容简短,但很重要。请尊重 robots.txt(它已在 RFC 9309 中被正式标准化),控制请求频率,查看目标网站的服务条款,并按照 GDPR / 隐私法规处理个人数据。hiQ v. LinkedIn 案例先例(2022 年)确认了抓取公开可访问数据并不违反 CFAA,但这不代表可以随意操作。负责任地使用自动化,既保护你自己,也保护你的业务。想了解更多,可以看看我们关于网页抓取法律影响的指南。
总结
OpenClaw 浏览器自动化是一个很强大的选择,适合用自然语言控制复杂的多步骤网页流程。最关键的是这几点:
- 一开始就选对浏览器模式(Sandbox、Relay、Remote CDP)——这一个决定就能帮你省下大量调试时间。
- Windows 用户也有可行路径,但必须使用 Windows 专用命令,并留意防火墙和路径问题。
- 反爬处理是真难点——先从最简单的方法入手(节奏、指纹),不够再逐层升级。
- 先看输出,再决定要不要投入。 如果你只需要列表页的结构化数据,像 Thunderbit 这样的无代码工具几分钟就能搞定,而且几乎不用维护。
- 把维护成本算进去。 OpenClaw 大约每月发布 13 个版本,VPS 费用会累积,调试也是使用的一部分。
如果你想先走更简单的路线,可以先试试 Thunderbit 的免费套餐——安装扩展、抓一页数据,看看它是否已经满足你的需求,再决定要不要投入完整的 VPS 方案。如果你最终还是选择 OpenClaw,建议把这篇指南收藏起来。你迟早会用到错误排查清单——也祝你的浏览器实例永远有足够的内存。
常见问题解答
OpenClaw Sandbox Chromium 和 Browser Relay 有什么区别?
Sandbox Chromium 会在服务器上运行一个无头浏览器——速度快、配置简单,但每次都会生成全新配置文件(没有登录会话),也更容易被反爬系统识别。Browser Relay 会把指令转发到你本地机器上的真实 Chrome 浏览器,因此支持登录、保留真实浏览器指纹,也更不容易被网站识别成自动化操作。代价是它会因为网络转发而更慢一些,而且功能上有一些限制(不支持批量操作和下载拦截)。
我能在不使用 WSL 的情况下,在 Windows 上运行 OpenClaw 浏览器自动化吗?
可以,但有一些限制。最可靠的原生 Windows 路径是通过 PowerShell 使用 Chrome Remote Debugging(chrome.exe --remote-debugging-port=9222)。如果这个方案不稳定,可以用 Docker Desktop 作为兜底。Windows 上完整的原生 Node Host 支持可能还会有一些边角问题——请查看最新文档,并做好面对 Windows 专属问题的准备,比如防火墙拦截和二进制路径差异。本指南 Windows 部分里的命令全部都是 PowerShell,不是 bash。
OpenClaw 浏览器自动化里怎么处理 CAPTCHA?
先尽量降低被识别的风险:增加像真人一样的等待节奏,强化浏览器指纹,并使用会话持久化,避免“全新浏览器”信号。如果 CAPTCHA 还是频繁出现,就集成 2captcha(每 1K 次 $2.99)或 CapSolver(每 1K 次 $0.80–1.50,AI 驱动)这类解题服务。对于你只想拿到公开网站数据的场景,Thunderbit 的云端抓取可以自动处理反爬,不需要任何代理或 CAPTCHA 配置。
OpenClaw 浏览器自动化是免费的吗?
OpenClaw 本身是开源的(MIT 许可证),因此免费。但运行它需要基础设施支持——比如每月 $4–15 的 VPS,加上可选的代理轮换服务(每月 $10–50)或 CAPTCHA 解题服务(按次计费)。综合起来,月成本大概从轻度使用的 $8–14 到重度自动化的 $110–280 不等。相比之下,Thunderbit 的免费套餐 可以覆盖基础抓取,而且没有基础设施成本。
如果我的 OpenClaw 代理一直返回空结果,我该怎么办?
按这个顺序检查三件事:第一,页面可能还没加载完——告诉代理“导航后先等 3 秒再提取”。第二,你可能撞上了反爬墙——如果代理看到的是 CAPTCHA 页面而不是实际内容,就把模式从 Sandbox Chromium 切换到 Browser Relay。第三,快照引用可能已经过期——每次跳转后都让代理“重新截取快照”。如果这些都不行,再检查 VPS 的内存占用——浏览器实例崩溃时,经常会悄悄返回空结果。
试试 Thunderbit,更快提取网页数据 Get Started Free




