

到 2026 年,网页世界已经有点乱套了——现在一半的互联网流量都来自机器人,而开源网页爬虫正是背后默默干活的英雄,支撑着从价格监控到 AI 训练的各种场景。我在 SaaS 和自动化领域折腾了很多年,最深的体会就是:选对自托管爬虫,能帮团队省下几个月的摸索时间,也许还能少熬好几个通宵排查问题。无论你是只想抓几页商品信息,还是要爬几百万个 URL 做研究,这份开源 Firecrawl 替代方案清单都能帮到你——不管你的规模、技术栈,还是对复杂度的容忍度如何。
但关键在于:并没有一套放之四海而皆准的方案。有些团队需要 Scrapy 的强大性能,或者 Heritrix 的归档能力;也有些团队会觉得维护开源库的成本太高。所以,接下来我们就来拆解 2026 年最值得关注的 9 款开源 Firecrawl 替代方案,看看每一款各自擅长什么,并帮你把工具和业务需求精准对上号,省去反复试错的痛苦。
如何为你的业务选择最佳开源 Firecrawl 替代方案
在进入清单之前,先聊聊策略。开源网页爬取领域比以往任何时候都更丰富,你的选择应该取决于以下几个关键因素:
- 易用性: 你想要点一点就能用的界面,还是更习惯写 Python、Go 或 JavaScript?
- 可扩展性: 你是在抓一个网站,还是需要跨数百个域名爬取数百万页面?
- 内容类型: 目标网站是静态 HTML,还是依赖大量 JavaScript 和动态加载?
- 集成需求: 你希望怎么使用数据——导出到 Excel、写入数据库,还是接入分析流水线?
- 维护成本: 你有能力维护自定义代码吗,还是希望工具能自动适应网站变化?
这里有一份速查表,帮你快速决定:
| 场景 | 最佳工具 |
|---|---|
| 无代码、离线浏览 | HTTrack |
| 大规模、多域名爬取 | Scrapy、Apache Nutch、StormCrawler |
| 动态 / JavaScript 很重的网站 | Puppeteer |
| 需要表单自动化 / 登录 | MechanicalSoup |
| 静态网站下载 / 归档 | Wget、HTTrack、Heritrix |
| Go 开发者,高性能需求 | Colly |
现在,让我们深入看看 2026 年最值得关注的 9 款开源 Firecrawl 替代方案。
1. Scrapy:大规模 Python 爬取的最佳选择

Scrapy 是开源网页爬取领域的重量级选手。它基于 Python 构建,是需要大规模爬取的开发者首选框架之一——比如数百万页面、频繁更新,以及复杂的网站逻辑。
为什么选 Scrapy?
- 超大规模能力: Scrapy 每秒可处理成千上万次请求,许多公司都用它来抓取每月数十亿页面的数据(Zyte)。
- 可扩展、模块化: 你可以编写自定义 spider,接入代理中间件,处理登录,并将结果输出为 JSON、CSV 或数据库。
- 社区活跃: 插件、文档和 Stack Overflow 上的答案都非常丰富。
- 经过实战检验: 全球电商、新闻和研究团队都在生产环境中使用它。
局限: 对非开发者来说,上手门槛较高;而且随着网站变化,你需要持续维护 spider。不过,如果你想要完全控制力和可扩展性,Scrapy 很难被超越。
2. Apache Nutch:企业级搜索引擎的最佳选择
Apache Nutch 是开源爬虫界的老前辈,专为企业级、互联网级别的爬取任务而设计。如果你想搭建自己的搜索引擎,或者要爬取数百万个域名,Nutch 就是你的好帮手。
为什么选 Apache Nutch?
- Hadoop 驱动的大规模能力: 基于 Hadoop 构建,Nutch 能在服务器集群上爬取数十亿页面(Common Crawl 就用它来爬取公开网络)。
- 批量爬取: 只要给它一组种子 URL,剩下交给它自动运行——非常适合定时的大规模任务。
- 集成能力: 可与 Solr、Elasticsearch 和大数据流水线配合使用。
局限: 配置复杂(要面对 Hadoop 集群、Java 配置文件等),而且它更偏向原始爬取,而不是结构化数据提取。对小项目来说有点大材小用,但在网页级别的大规模爬取上几乎无可匹敌。
3. Heritrix:网页归档与合规场景的最佳选择
Heritrix 是 Internet Archive 自家的爬虫,专为网页归档和数字保存打造。
为什么选 Heritrix?
- 归档级完整性: 可捕获每个页面、资源和链接——非常适合法律合规或历史快照保存。
- WARC 输出: 将所有内容存成标准化的 Web ARChive 文件,便于回放或分析。
- 网页管理界面: 通过浏览器 UI 就能配置和监控爬取任务。
局限: 体量大、很吃磁盘和内存,不执行 JavaScript,输出的是原始归档而不是结构化表格。它更适合图书馆、档案馆或受监管行业。
4. Colly:高性能 Go 开发者的最佳选择
Colly 是 Go 开发者的心头好——速度快、轻量、并发能力强,是一款高效的网页爬虫。
为什么选 Colly?
- 飞快: Go 的并发特性让 Colly 能以极低的 CPU / 内存开销抓取成千上万页面(Oxylabs)。
- API 简洁: 你可以为 HTML 元素定义回调,自动处理 cookie 和 robots.txt。
- 特别适合静态站点: 对服务器渲染页面、API,或把爬取功能集成进 Go 后端都很合适。
局限: 没有内置 JavaScript 渲染(动态网站需要配合 Chromedp 之类的工具),而且你得会 Go。
5. MechanicalSoup:简单表单自动化的最佳选择

MechanicalSoup 是一个 Python 库,介于简单 HTTP 请求和完整浏览器自动化之间。
为什么选 MechanicalSoup?
- 表单自动化: 很容易实现登录、填写表单和维持会话——特别适合抓取登录后的内容。
- 轻量: 底层基于 Requests 和 BeautifulSoup,速度快、部署简单。
- 非常适合交互式网站: 如果你需要提交搜索表单,或者登录后再抓取数据,MechanicalSoup 是个不错的选择(Apify Blog)。
局限: 不执行 JavaScript,所以不适合 JavaScript 很重的网站。它更适合带有简单交互的静态或服务器渲染页面。
6. Puppeteer:动态网站与 JavaScript 重站点的最佳选择
Puppeteer 是现代 JavaScript 重网站爬取的瑞士军刀。它是一个 Node.js 库,让你可以完全控制无头 Chrome 浏览器。
为什么选 Puppeteer?
- 处理动态内容: 可抓取 SPA、无限滚动页面,以及通过 AJAX 加载数据的页面(Browserless Guide)。
- 模拟用户行为: 可点击按钮、填写表单、截图,甚至还能借助插件解决验证码。
- 自动化能力强: 非常适合测试、监控,以及抓取任何真实用户能看到的内容。
局限: 资源消耗高(要运行完整 Chrome 实例),速度比纯 HTTP 爬虫慢,而扩展规模则需要强大的硬件或云端编排能力。
7. Wget:快速命令行下载的最佳选择

Wget 是经典的命令行工具,用来下载静态网站和文件非常方便。
为什么选 Wget?
- 简单: 一条命令就能下载整个网站或目录——无需编写代码。
- 速度快: 用 C 语言编写,运行高效。
- 非常适合静态内容: 适合文档站、博客或批量文件下载(HuggingFace Guide)。
局限: 不执行 JavaScript,也不处理表单,而且它下载的是原始页面,不是结构化数据。可以把它想成静态网站的数字吸尘器。
8. HTTrack:离线浏览的最佳选择(无代码)
HTTrack 是 Wget 的更友好版本,提供图形界面来镜像网站。
为什么选 HTTrack?
- GUI 简单易用: 分步向导让非技术用户也能轻松上手。
- 支持离线浏览: 它会自动调整链接,让你可以在本地浏览镜像站点。
- 非常适合归档: 适合研究人员、营销人员,或任何想保留网站快照但不想写代码的人(Reddit DataHoarder)。
局限: 不支持动态内容,大型网站上可能比较慢,而且它并不是为结构化数据提取而设计的。
9. StormCrawler:实时分布式爬取的最佳选择

StormCrawler 是面向现代分布式场景的爬虫,适合那些需要实时、持续获取大规模网页数据的团队。
为什么选 StormCrawler?
- 实时爬取: 基于 Apache Storm 构建,以流式方式处理数据——非常适合新闻监控或搜索引擎(Wikipedia)。
- 模块化且可扩展: 可按需加入解析、索引和自定义处理 bolt。
- 被 Common Crawl 使用: 为全球最大公开网络档案之一的新闻数据集提供支持。
局限: 需要 Java 开发能力和 Storm 集群,因此更适合有分布式系统经验的团队。对小项目来说仍然有点大材小用。
开源 Firecrawl 替代方案对比:哪款免费竞品最适合你?
下面是这 9 款工具的横向对比:
| 工具 | 最佳使用场景 | 核心优势 | 缺点 | 语言 / 环境 |
|---|---|---|---|---|
| Scrapy | 大规模、高频爬取 | 强大、可扩展、社区庞大 | 上手门槛高,需要 Python | Python 框架 |
| Apache Nutch | 企业级、网页规模爬取 | Hadoop 驱动,经大规模验证 | 配置复杂,偏批量处理 | Java/Hadoop |
| Heritrix | 归档、合规爬取 | 网站捕获完整,支持 WARC 输出 | 体量大、无 JS、原始归档 | Java 应用、Web UI |
| Colly | Go 开发者,高性能抓取 | 速度快、API 简洁、并发能力强 | 不支持 JS,需要 Go | Go 库 |
| MechanicalSoup | 表单自动化、登录后抓取 | 轻量、支持会话管理 | 不支持 JS、规模有限 | Python 库 |
| Puppeteer | 动态 / JavaScript 很重的网站 | 完整浏览器控制、自动化能力强 | 资源消耗高,需要 Node.js | Node.js 库 |
| Wget | 静态网站下载、离线访问 | 简单、快速、命令行 | 不支持 JS、只下载原始页面 | 命令行工具 |
| HTTrack | 非技术用户、网站归档 | 图形界面、离线浏览方便 | 不支持 JS、大站较慢 | 桌面应用(GUI) |
| StormCrawler | 实时、分布式爬取 | 可扩展、模块化、实时 | 需要 Java / Storm 经验 | Java / Storm 集群 |
你应该自己开发,还是直接使用现成的开源 Firecrawl 替代方案?
说实话:自己造一个爬虫听起来很酷——直到你深陷维护、代理和反爬问题之中。上面这些开源工具,凝聚了多年的实战经验和社区智慧。根据行业报告,使用现成方案是最快、最可靠的出结果方式,也能避免重复造轮子(IveerData)。
- 适合采用开源方案的情况: 你的需求与现有工具高度匹配,想缩短开发时间,并且重视社区支持。
- 适合自己开发的情况: 你有真正独特的需求、深厚的内部技术能力,而且爬取本身就是业务核心。
不过,当你把工程人力、服务器维护以及为对抗反爬而不断更新的成本都算进去后,开源方案并不算“免费”。如果你想在不用写代码的情况下获得强大爬虫的好处,还有另一个选择。
额外推荐:当开源方案太复杂时,试试 Thunderbit
虽然上面列出的工具对开发者来说都非常强大,但它们有几个共同的限制:都需要编程知识,难以应对动态的 AI 反爬机制,而且还需要持续维护。
Thunderbit 是我最推荐给想绕开这些限制的人的工具。它在强大爬取能力和易用性之间搭起了一座桥。
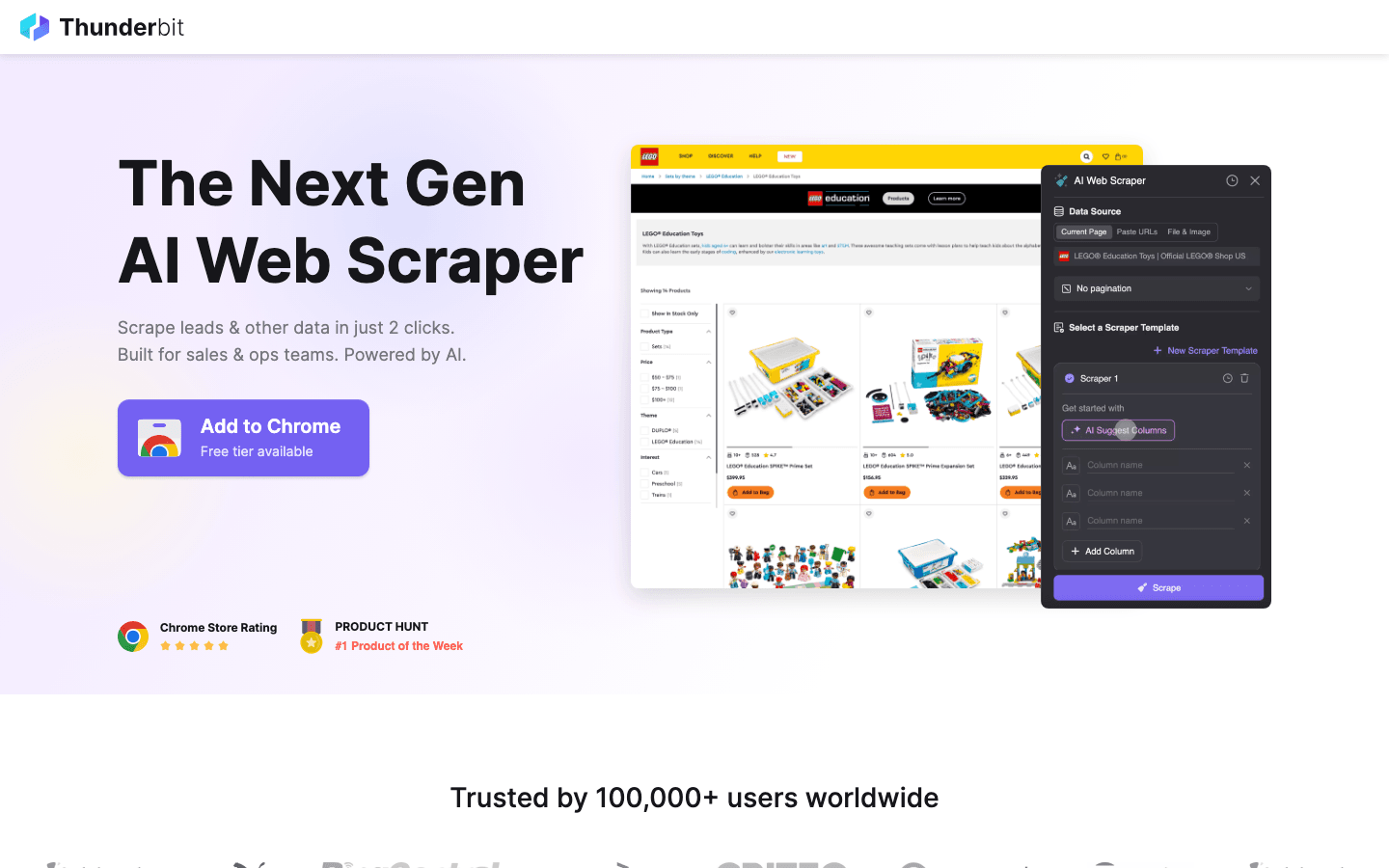
为什么要用 Thunderbit,而不是开源方案?
- 完全无需编程: 不像 Scrapy 或 Puppeteer,Thunderbit 是一款由 AI 驱动的 Chrome 扩展。你只要点击“AI 推荐字段”,它就会帮你生成爬虫。
- 难题自动搞定: 动态内容、无限滚动和分页都会由 AI 自动处理,帮你省下大量编写自定义脚本的时间。
- 一键导出: 两次点击就能把网站数据导出到 Excel、Google Sheets 或 Notion。
- 无需维护: 网站改版时,你不用更新代码——Thunderbit 的 AI 会自动适配。
如果你是销售、营销人员或研究人员,想立刻拿到数据,而不想学习 Python 或 Go,那么 Thunderbit 正好能和这份清单里的开源工具互补。
想看看实际效果?下载 Chrome 扩展 并亲自试试。
结语:为 2026 年找到合适的自托管网页爬虫
查看更多网页爬取指南 Get Started Free
开源 Firecrawl 替代方案的世界比以往任何时候都更丰富。无论你需要 Scrapy 或 Nutch 的极致规模,还是 Heritrix 的归档保真度,总有一款方案适合你的业务场景。关键在于把工具和需求匹配起来——只是想快速抓点数据,就别过度设计;如果你要爬的是互联网级规模,也别在投入上过于保守。
别忘了,如果开源路线对你来说太技术化、太耗时,像 Thunderbit 这样的 AI 工具已经准备好帮你补位。
准备开始了吗?下一次大型数据项目可以试试 Scrapy;或者直接试用 Thunderbit,体验简单、AI 驱动的网页爬取。如果你还想了解更多网页爬取技巧,欢迎查看 Thunderbit 博客 上的深度文章和教程。
常见问题
1. 使用开源 Firecrawl 替代方案的主要优势是什么?
开源替代方案提供了灵活性、成本优势,以及自托管和自定义爬虫的能力。你可以避免被供应商绑定,还能获得活跃的社区支持和更新。
2. 哪个工具最适合非技术用户快速见效?
HTTrack 是一个很不错的开源离线浏览选择。不过,如果你需要结构化数据提取(比如 Excel 表格),我们更推荐额外工具 Thunderbit,因为它具备 AI 能力。
3. 如何处理动态、JavaScript 很重的网站?
Puppeteer 是最合适的选择——它控制的是真实浏览器,因此可以抓取用户能看到的一切内容,包括 SPA 和通过 AJAX 加载的页面。
4. 什么时候应该使用 Apache Nutch 或 StormCrawler 这种重量级爬虫?
如果你需要跨多个域名爬取数百万页面,或者需要实时、分布式爬取(例如搜索引擎或新闻监控),这些工具就是为规模和稳定性而设计的。
5. 我应该自己开发爬虫,还是使用现成的开源方案?
对大多数团队来说,使用并定制现成的开源工具更快、更便宜,也更可靠。只有在你有非常特殊的需求,而且有能力长期维护时,才建议自己开发。
祝你爬取顺利——愿你的数据始终新鲜、结构清晰,并随时可用。
免费试用 Thunderbit AI 网页爬虫 Get Started Free
了解更多




