现在,互联网对数据的需求比以往任何时候都要强烈。到了 2025 年, 已经成为高效网页数据抓取的主流选择。不管你是做销售、电商,还是像我一样热爱数据分析,你肯定发现,网页爬虫早就不只是“拿到数据”这么简单了——速度、规模和反反爬能力才是核心竞争力。预计网页爬虫市场会从 2025 年的 74.8 亿美元一路飙升到 2034 年接近 384 亿美元(),竞争和挑战也会越来越激烈。
但问题也随之而来:现在的网站充满了动态内容、反爬机制,还有不断变化的页面结构。我见过太多爬虫“翻车”,大多都是因为忽略了最佳实践,或者低估了网站的反爬策略。接下来,我会结合实际案例、一些有趣的细节和实用建议,聊聊 Node.js 网页爬虫高效实战的那些事儿。
为什么用 Node.js 做高效网页爬取?
如果你试过同时爬取上百甚至上千个页面,就会明白速度和并发能力有多重要。这正是 Node.js 的拿手好戏。它的 异步非阻塞 I/O 模型,天生适合处理大量并发网络请求——可以说是网页世界里的“多线程达人” ()。别的语言可能在等待请求时卡住,而 Node.js 就像杂技演员一样,在事件循环里灵活切换任务。
在需要实时更新和大规模数据提取的场景下,尤其是目标网站大量用 JavaScript 时,Node.js 的表现往往比 Python 和 Java 更胜一筹。事实上, 现在都在用 Node.js 做后端和自动化任务,让它成为全球最受欢迎的网页技术之一。
Node.js 和其他网页爬虫框架对比
来点技术对比,看看 Node.js 和其他主流方案的优缺点:
| 框架 | 优势 | 劣势 | 最佳应用场景 |
|---|---|---|---|
| Node.js | 异步并发能力强,npm 生态丰富,原生 JS 适合动态站点 | 内存消耗较大,没用 async/await 容易回调地狱 | 实时爬取、JS 动态站点、可扩展微服务 |
| Python | 爬虫库多(如 BeautifulSoup、Scrapy),语法简洁 | 大规模并发慢,处理 JS 动态站点有难度 | 静态 HTML、数据研究、原型开发 |
| Java | 强类型,企业级稳定 | 代码冗长,脚本开发灵活性差 | 大型、企业级爬取任务 |
| Go | 并发高效,速度快 | 生态小,学习曲线陡峭 | 高性能、低延迟爬取 |
对大多数企业来说,Node.js 兼具速度、灵活性和对现代 JS 网站的适配性,是理想选择 ()。
如何搭建高效 Node.js 网页爬虫环境
高效的爬虫,离不开扎实的基础。我的推荐配置如下:
- 项目结构: 模块化管理,常用
/src、/libs、/config等目录。敏感信息(API 密钥、代理)用dotenv存成环境变量()。 - HTTP 客户端: 推荐 、 或 。
- HTML 解析: 静态页面用 ,动态内容用 或 Playwright。
- 工具库: 数据处理用 ,数据校验用 或 。
- 测试与代码规范: 测试用 Mocha,代码质量用 ESLint ()。
Node.js 必备网页爬虫库
- axios/got/node-fetch: 负责 HTTP 请求。axios 支持 Promise,处理 JSON 很方便。
- Cheerio: 类 jQuery 的 HTML 解析器,适合静态页面,解析速度超快(约 0.5 秒)()。
- Puppeteer/Playwright: 无头浏览器,专治 JS 动态页面。速度慢点(每页约 4 秒),但处理复杂内容必不可少 ()。
- dotenv: 管理环境变量。
- csv-writer/jsonfile: 数据导出。
避开 Node.js 网页爬虫常见坑
爬虫被封、崩溃或数据乱套的情况很常见。下面这些问题和应对方法一定要注意:
- 忽略 robots.txt 和服务条款: 开始爬取前一定要检查,违规可能被封 IP,甚至有法律风险 ()。
- 请求太频繁: 别一股脑并发,建议设置 1–3 秒的随机延迟,控制并发,别像机器人一样狂刷 ()。
- 错误处理不到位: 所有请求都要 try/catch,处理 HTTP 错误并记录失败。临时性错误建议指数退避重试 ()。
- 请求头设置不合理: 用真实的 User-Agent,并定期更换。加上 Accept-Language、Referer 等头部,模拟真实浏览器 ()。
如何绕过反爬机制
现在的网站反爬越来越厉害,下面这些招数很实用:
- 代理池和 IP 轮换: 用代理池,定期换 IP,降低被封风险 ()。
- 请求头随机化: 每次请求都换 User-Agent、Accept-Language 等头部。
- 无头浏览器隐身插件: 比如
puppeteer-extra-plugin-stealth,隐藏自动化痕迹。 - 模拟人类操作: 加入随机延迟、鼠标移动、滚动、甚至偶尔输错字 ()。
Node.js 爬虫如何模拟人类行为
这部分既有趣又实用。别让爬虫一口气点到底,可以这样做:
- 操作间隔随机等待(
await page.waitForTimeout(randomDelay)) - 鼠标小幅度、抖动式移动(
page.mouse.move(x, y)) - 输入时加延迟,偶尔打错字(
page.type(selector, text, {delay: random(100,200)})) - 滚动页面时不规则,而不是直接拉到底
这些技巧能大大提升在有防护网站上的爬取成功率 ()。
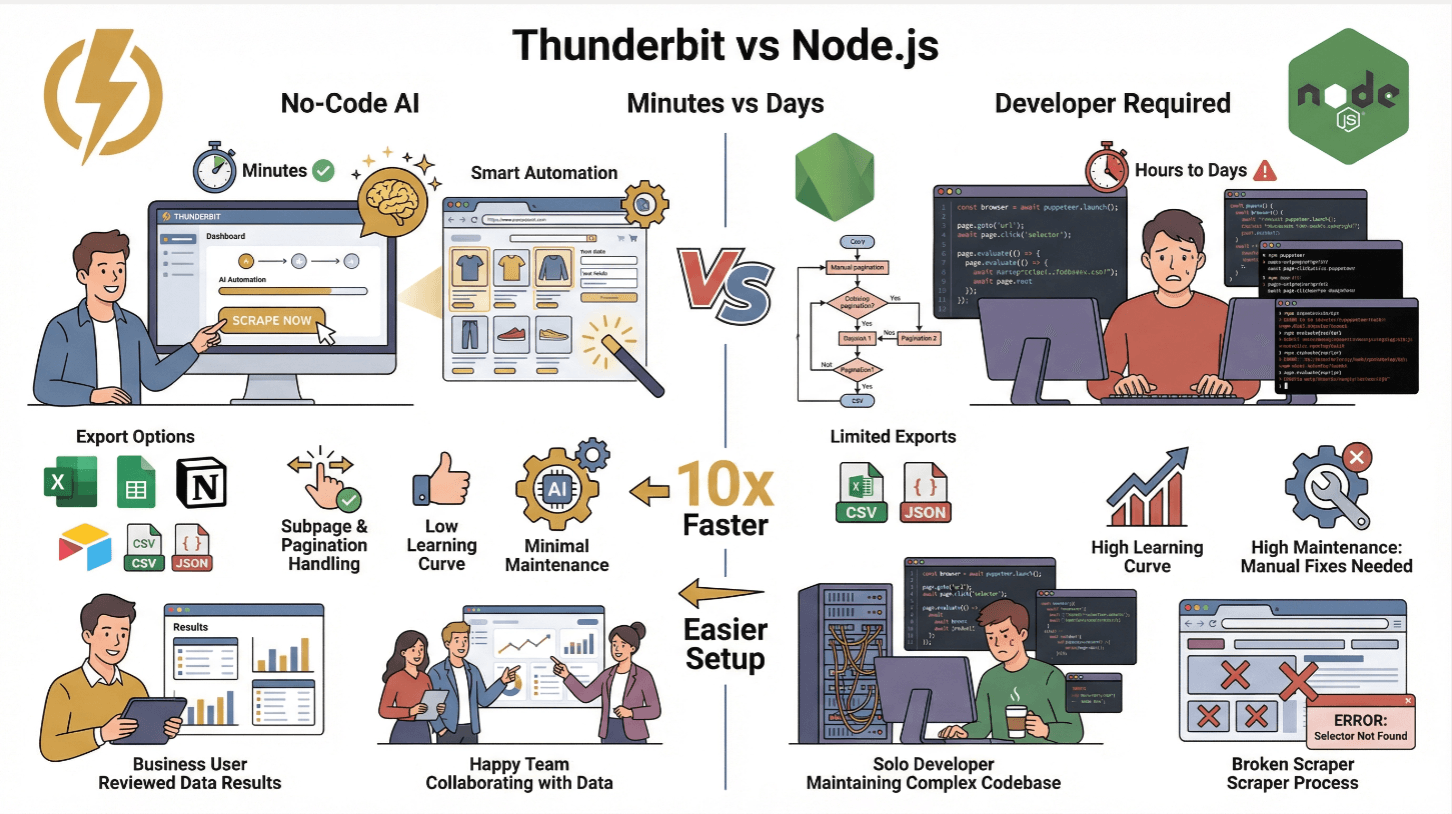
用 Thunderbit 让复杂数据提取变简单
说到底,网页爬取其实挺难的。但其实也可以很简单——这就是我们开发 的初衷。
Thunderbit 是一款 AI 网页爬虫 Chrome 扩展,让你用自然语言就能从任意网站提取数据。只要点一下“AI 智能识别字段”,AI 会自动分析页面结构,然后一键“抓取”就搞定。就像请了个永不加班、永不抱怨的初级开发者。
更厉害的是,Thunderbit 还提供 API,可以无缝集成到你的 Node.js 流程里。你不用再手写成千上万行爬虫代码,Thunderbit 自动帮你搞定动态内容、子页面、分页等复杂场景。你只需要拿到结构化数据(CSV、JSON,或者直接导入 Google Sheets、Airtable、Notion),数据采集轻松搞定 ()。
Thunderbit 和传统 Node.js 爬虫对比
| 功能 | Thunderbit | 传统 Node.js 爬虫 |
|---|---|---|
| 上手时间 | 几分钟(无需编码) | 数小时到数天(需开发和测试) |
| 动态内容处理 | 支持(AI+浏览器) | 支持(需 Puppeteer/Playwright) |
| 子页面与分页 | 一键操作 | 需手动编码实现 |
| 数据导出 | Excel、Sheets、Notion、Airtable、CSV、JSON | CSV/JSON(需自定义代码) |
| 学习门槛 | 低(适合业务用户) | 高(需开发经验) |
| 维护成本 | 极低(AI 自动适应) | 高(网站变动需手动修复) |
Thunderbit 特别适合非技术团队,或者想快速拿到数据、专注分析的用户。进阶用户也可以通过 Thunderbit API 实现大规模自动化爬取 ()。
Cheerio + Puppeteer 动态内容爬取组合
这是我最喜欢的 Node.js 爬虫“黄金搭档”。操作流程如下:
- 用 Puppeteer 加载页面并执行 JavaScript(等到
networkidle,确保内容加载完)。 - 获取 HTML,用
await page.content()。 - 用 Cheerio 解析:把 HTML 交给 Cheerio,快速提取你要的数据。
这种混合方式既有 Puppeteer 动态渲染的能力,又有 Cheerio 的解析速度 ()。
性能建议: 只选你需要的元素。Cheerio 会把整个 DOM 加载到内存,避免用太宽泛的选择器,重复爬同一页面时建议缓存结果 ()。
优化 HTML 解析和数据提取
- 精准选择器: 避免
$('body *'),只抓目标元素。 - 大页面流式处理: HTML 太大可以分块或流式处理。
- 缓存渲染结果: 反复访问同一 URL 时缓存 HTML,减少重复请求。
- 数据校验和清洗: 用校验库保证数据质量,避免脏数据入库 ()。
云端大规模部署 Node.js 网页爬虫
想大规模爬取?云原生部署才是王道。
- Docker 化爬虫: 写个
Dockerfile,复制代码、装依赖、设置入口。 - 部署到云端: 简单任务用 AWS EC2、Google Cloud Compute、Azure VM。大规模任务建议用 Kubernetes 或 AWS ECS/EKS、Google Cloud Run、Azure Kubernetes Service ()。
- Kubernetes 编排: 多 pod 并发,自动扩容,用负载均衡分发 URL。
- 定时任务调度: 用云端调度器(CloudWatch Events、Cloud Scheduler)或 cron 定时触发爬取。
实际案例里,把 Kubernetes pod 数从 5 提到 10,400 页的爬取时间从几分钟缩短到不到一分钟 ()。
云端爬虫监控和自动扩容
- 日志监控: 日志流式输出到 CloudWatch、Stackdriver 或 Datadog,设置错误和性能告警。
- 健康检查: 用 Prometheus、Grafana 监控爬取速率、错误率和 pod 状态。
- 自动扩容: 配置 Kubernetes HPA(水平自动扩容),根据 CPU 或请求量动态调整 pod 数量。
建议所有请求都实现指数退避重试,防止网络波动或临时封禁导致任务失败。
数据存储和后处理最佳实践
数据爬下来,存储和清洗同样重要:
- 小型任务: 导出为 CSV、JSON,或直接推到 Google Sheets、Airtable、Notion(Thunderbit 原生支持)。
- 大型任务: 结构化数据用 SQL(MySQL/PostgreSQL),半结构化或灵活结构用 NoSQL(MongoDB、DynamoDB)()。
- 云存储: S3 或 Google Cloud Storage 存原始文件和备份。
- 数据清洗: 校验字段、统一格式(如日期、数字)、去重。用 schema 校验器保证数据质量 ()。
建议同时保留原始和清洗后的数据,方便后续复查或调试。
总结:Node.js 网页爬虫高效实战要点
最后,核心要点总结如下:
- 充分利用 Node.js 异步能力,实现大规模并发爬取,特别适合 JS 动态站点。
- 工具组合灵活: 请求用 axios/got,静态解析用 Cheerio,动态内容用 Puppeteer,混合用法提升效率和灵活性。
- 规避反爬陷阱: 代理和请求头轮换,模拟人类操作,遵守 robots.txt。
- 用 Thunderbit 简化流程: 业务用户或快速原型开发,借助 用 AI 轻松提取复杂数据,还能通过 API 集成到 Node.js。
- 大规模部署: Docker 化,Kubernetes 编排,实时监控保障稳定性。
- 数据存储和清洗: 选合适的存储方案,使用前一定要校验数据。
互联网只会越来越复杂,但只要掌握这些最佳实践,你的 Node.js 网页爬虫就能一直高效、稳定,领先反爬技术。如果你不想再凌晨两点调试选择器,别忘了 Thunderbit 的 AI 随时帮你搞定。
想继续学习?欢迎访问 深入了解,或者试试 ,体验高效爬取的乐趣。
常见问题解答
1. 为什么 Node.js 在 2025 年特别适合网页爬虫?
Node.js 的异步事件驱动模型,能高效处理成千上万的并发请求,非常适合大规模或实时数据爬取。它庞大的 npm 生态和原生 JavaScript 支持,完美适配现代 JS 动态网站 ()。
2. 用 Node.js 爬虫怎么避免被封?
用代理池轮换 IP、随机化请求头、设置随机延迟、用 Puppeteer 等工具模拟人类操作(鼠标移动、滚动、输入)。始终遵守 robots.txt 和网站条款 ()。
3. Node.js 爬虫里 Cheerio 和 Puppeteer 怎么选?
静态 HTML 数据用 Cheerio 解析速度快;动态内容用 Puppeteer 渲染后再用 Cheerio 解析效果最好 ()。
4. Thunderbit 怎么简化 Node.js 网页爬虫?
Thunderbit 让你用 AI 和自然语言提示词,从任意网站提取结构化数据,无需编码。支持动态内容、子页面、分页,还提供 API 方便 Node.js 集成。数据可直接导出到 Excel、Google Sheets、Airtable 或 Notion ()。
5. 如何在云端扩展和监控 Node.js 爬虫?
把爬虫 Docker 化,部署到 Kubernetes 或云服务,利用自动扩容应对高峰。用 CloudWatch、Prometheus 等工具监控日志和指标,设置错误和性能告警 ()。
想让你的网页爬虫更强大?不妨试试 Thunderbit,让你的爬虫更快、更隐蔽,始终领先一步。
延伸阅读