

每篇 Node.js fetch 教程几乎都会先教你 await fetch(url),然后就戛然而止。等真到了生产环境,你的应用悄悄吞掉一个 500 错误,请求卡了 90 秒都不超时,而你却只能在周五晚上排查一个本来一眼就该看出来的问题。
我在 Thunderbit 做内部工具和数据管道已经有一阵子了,可以很肯定地说:从“教程里能跑”到“生产环境能跑”之间的落差,恰恰是大多数痛苦的来源。Reddit 上有位开发者说得很到位:“一旦进入生产环境,你就会发现自己需要比原生 fetch 更可靠的东西。”
还有人坦白说:“做了 3 年 Web 开发,才知道 fetch API 的 catch 块根本不是用来处理 HTTP 错误的。” 这篇指南会覆盖大多数教程会跳过的五件事——错误陷阱、AbortController 超时、重试逻辑、连接复用,以及什么时候该超越 fetch,转向结构化数据提取。如果你也曾在生产环境里遇到 fetch 调用静默失败,这篇就是给你的。
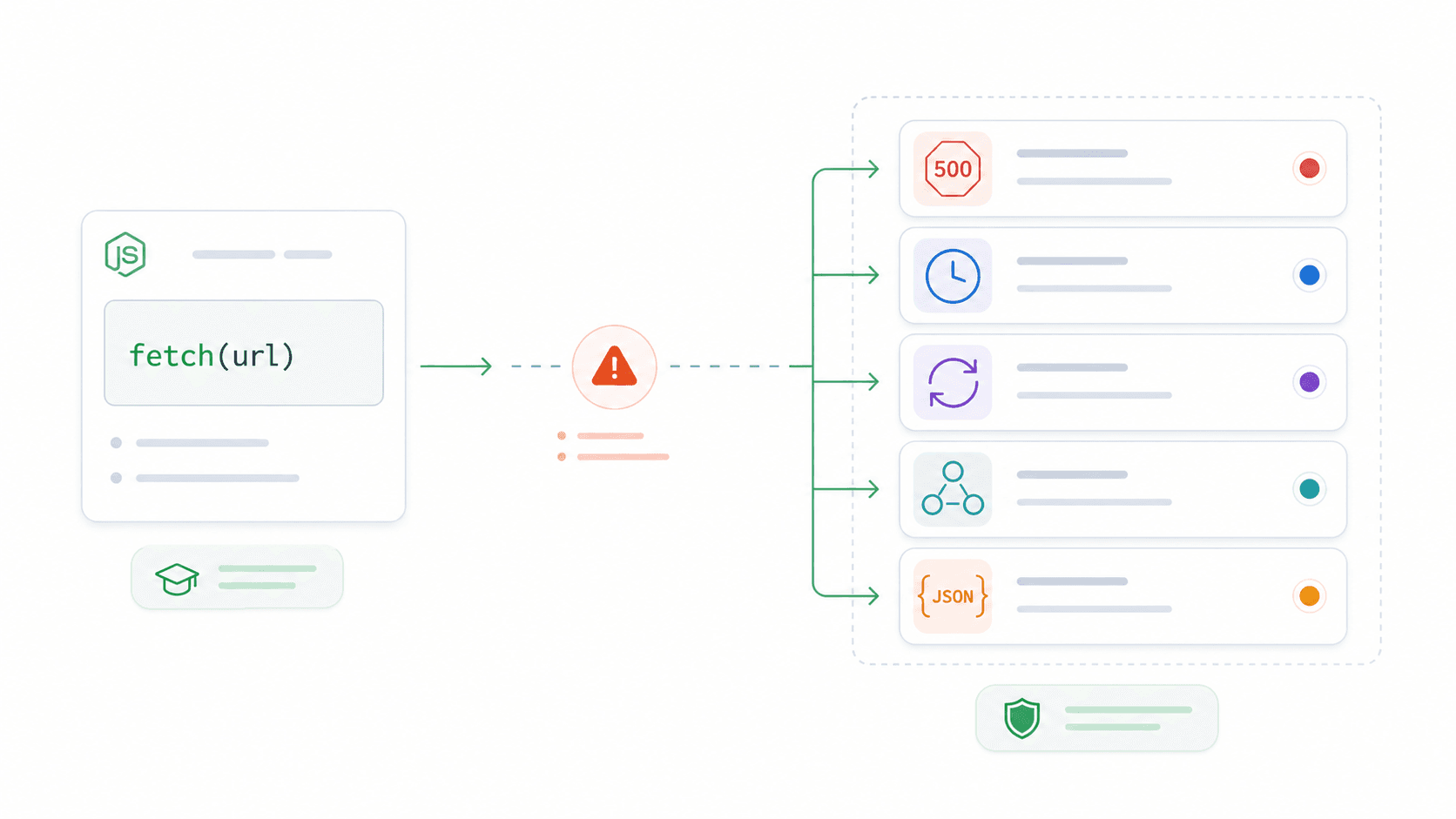
什么是 Node.js Fetch API?
Node.js Fetch API 是 Node.js 内置、并且和浏览器兼容的 HTTP 请求方式(GET、POST、PUT、DELETE 等),不需要安装 Axios、node-fetch 或其他任何包。只要你在浏览器里用过 fetch(),你就已经熟悉它的语法了。现在,同样的 API 也能直接在服务端使用。
先快速看一下版本演进:
| 里程碑 | Node 版本 | 发生了什么 |
|---|---|---|
| 实验性 fetch 标志 | v17.5.0 / v16.15.0 | 在 --experimental-fetch 后添加了 fetch |
| 默认全局 fetch | v18.0.0 | 实验性 fetch 可全局使用,由 Undici 驱动 |
| 稳定版 fetch | v21.0.0 | 不再是实验特性 |
| 2026 生产基线 | v22 LTS / v24 LTS | 生产环境推荐使用;v20 现已 EOL |
在底层,Node 的 fetch 由 Undici 提供支持——这是一个专为 Node.js 打造的高性能 HTTP 客户端。它不依赖更老的内置 http 模块。实际收益很直接:你会得到一个现代、基于 Promise 的 HTTP API,而且在浏览器代码、Express 后端、无服务器函数和 CLI 脚本里都能用同一套写法。
为什么 Node.js Fetch API 对你的项目很重要
在 Node 18 之前,每个新项目的开局都差不多:npm install axios 或 npm install node-fetch。到了 2026 年,如果你的项目跑在受维护的 Node LTS 上,基础 HTTP 请求已经不需要任何依赖。这对包体积、供应链安全和新成员上手体验来说,都是实打实的提升(前后端开发者终于可以共享同一个 API 了)。
原生 fetch 的优势主要体现在这些场景:
| 场景 | 为什么原生 fetch 很适合 | 生产环境注意事项 |
|---|---|---|
| Express/Fastify 后端调用 REST API | 熟悉的 async/await 写法,无需依赖 | 添加超时和 response.ok 检查 |
| 无服务器函数(Lambda、Vercel 等) | 冷启动开销小,无需安装包 | 超时要低于平台最大执行时长 |
| CLI 脚本和自动化任务 | 简单 GET/POST,无需项目初始化 | 为不稳定 API 添加重试/退避 |
| Webhook 发送或转发 | 标准 HTTP 方法和请求头 | 不要对非幂等 POST 盲目重试 |
| 报表和仪表盘 | 很适合从 API 拉取 JSON | 循环场景要使用分页和连接池 |
| 微服务通信 | 适合简单的内部 HTTP 调用 | 如需重试、钩子或 HTTP/2,可考虑直接用 Got 或 Undici |
对于新的 Node 22+ 项目,原生 fetch 是最合理的默认选择——除非你明确需要它不提供的功能(拦截器、内置重试、HTTP/2 等)。npm 下载量也说明了行业正在变化:node-fetch 仍然有每周约 1.449 亿次下载,但其中很多来自历史项目和传递依赖。Axios 约 1.086 亿,Undici 约 1.06 亿,Got 约 3600 万,Ky 约 560 万。趋势很清楚:原生 fetch 正在成为新基线,而第三方客户端则更多用于特定需求。
原生 Fetch vs node-fetch vs Axios vs Got vs Ky:2026 选型矩阵
开发者论坛里最常见的问题之一就是:“在 Node.js 里我该用哪个 HTTP 客户端?” 有位 Reddit 用户总结得很精辟:“语言/框架已经内置了功能,为什么还要再导入一个库?” 这是个合理的问题——但答案取决于你到底需要什么。
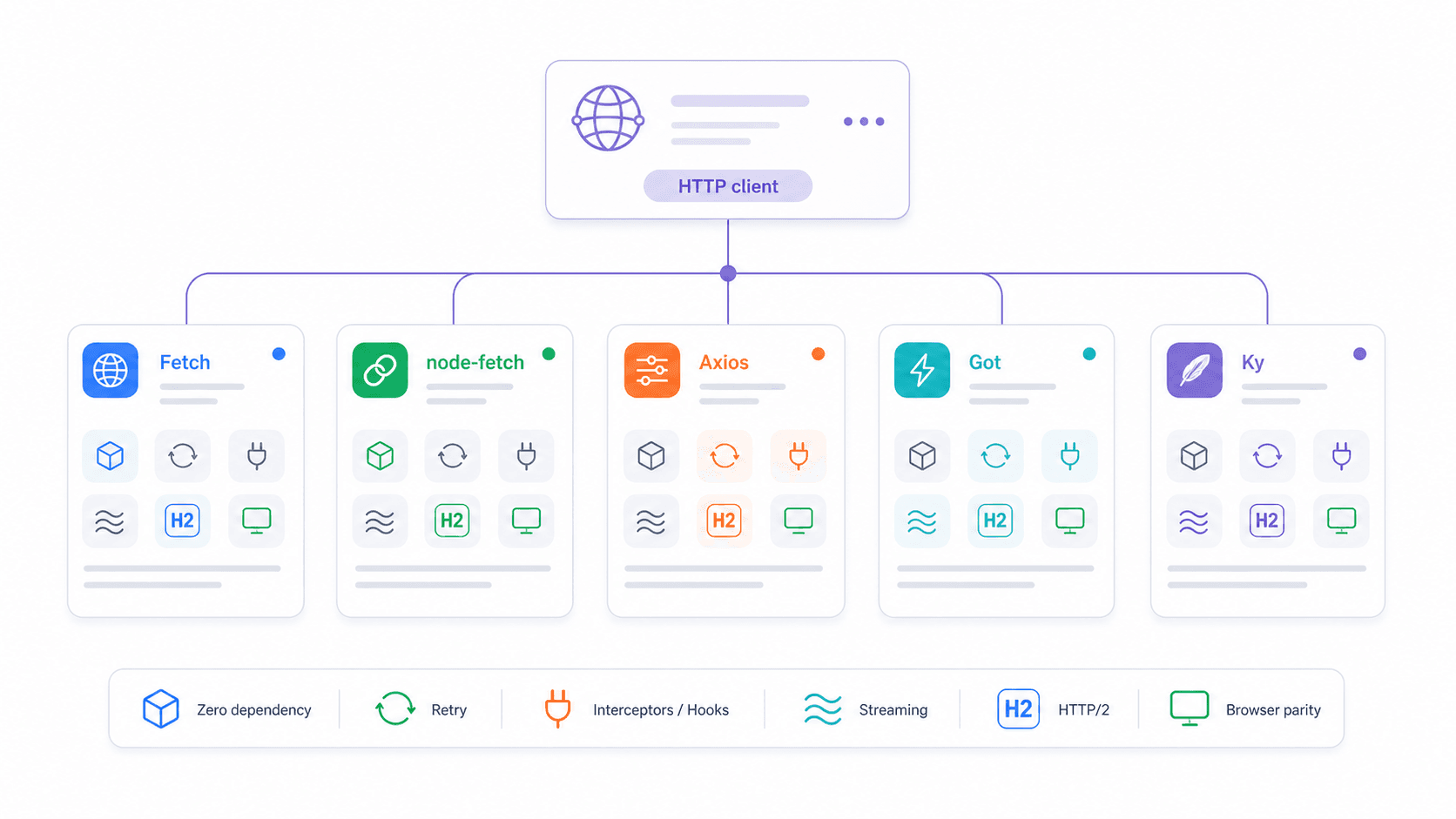
| 功能 | 原生 fetch | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Node.js 版本 | ≥18(推荐 22/24 LTS) | ≥12.20 | 广泛支持 | ≥22 | ≥22 |
| 是否需要安装 | 否 | 是 | 是 | 是 | 是 |
| ESM + CJS 支持 | 两者都支持(全局) | 仅 ESM(v3) | 两者都支持 | 仅 ESM | 仅 ESM |
| 4xx/5xx 自动拒绝 | 否 | 否 | 是 | 是 | 是 |
| 内置重试 | 否 | 否 | 否 | 是 | 是 |
| 请求拦截器 | 否 | 否 | 是 | 是(hooks) | 是(hooks) |
| 流式支持 | Web ReadableStream | 是 | 有限 | 强大的 Node streams | 基于 fetch |
| 包体积/安装开销 | 0 KB | 约 107 KB,3 个依赖 | 约 2.8 MB,4 个依赖 | 约 355 KB,12 个依赖 | 约 405 KB,0 个依赖 |
| HTTP/2 支持 | 通过 Undici dispatcher | 否 | 否 | 是 | 否(fetch 包装器) |
关于 ESM/CJS 的麻烦,再补一句:node-fetch v3 只支持 ESM,这让很多使用 require() 的项目直接受影响。原生 fetch 是全局可用的——无论是 CJS 还是 ESM 文件都能直接用,不需要额外的导入处理。如果你因为 CommonJS 被迫停留在 node-fetch v2,原生 fetch 可以一次性把这个问题解决掉。
至于早期稳定性的担忧:确实,Node 18 初版 fetch 实现里曾经有过真实 bug。有位开发者在 Reddit 上说:“最近原生 node 18 fetch 遇到一个离谱的 bug,只好把我们的应用改掉了。” 那是 2023 年。到了 2026 年,在 Node 22 和 24 LTS 下,这些问题已经解决。原生 fetch 已经可以用于生产环境。
什么时候坚持用原生 Fetch
当满足以下情况时,优先用原生 fetch:
- 你的项目运行在 Node 22 LTS 或 Node 24 LTS。
- 请求很简单,就是标准 REST 调用(GET、POST、PUT、DELETE)。
- 你愿意自己加一个小封装来处理
response.ok、JSON 解析、超时和重试。 - 你希望零依赖,尽量减少供应链风险。
- 你重视浏览器/服务端 API 的一致性。
- 你在无服务器或边缘环境中开发,倾向使用内置 API。
什么时候 Axios、Got 或 Ky 更合适
Axios 适合团队依赖请求/响应拦截器的场景(例如自动刷新认证令牌、租户头信息、统一日志记录),或者你希望 HTTP 错误默认就会拒绝 Promise,或者需要兼容更老的 Node 运行时。
Got 面向高吞吐的 Node 服务,内置重试、hooks、进阶超时阶段、流、分页辅助、Unix socket、代理/缓存工作流或 HTTP/2 支持时尤其合适。它是 Node-only HTTP 工作流里的瑞士军刀。
Ky 则是你喜欢 fetch 的简洁性、又想少写样板代码时的甜点位——它以很小的包体积和零依赖,提供重试、超时、hooks 和 HTTPError。
如何使用 Node.js Fetch API 发起 GET 请求
用 async/await 发起 GET 请求,大概是这样:
const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
const post = await response.json();
console.log(post.title);
// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"
如果你更喜欢 .then() 链式写法,也可以这样:
fetch('https://jsonplaceholder.typicode.com/posts/1')
.then(response => response.json())
.then(post => console.log(post.title))
.catch(error => console.error(error));
两种都能用。但它们都还不够适合生产环境(马上就会讲原因)。
你应该了解的响应读取方式:
| 方法 | 适用场景 |
|---|---|
response.json() | 服务端返回 JSON |
response.text() | 服务端返回 HTML、纯文本、CSV、Markdown |
response.arrayBuffer() | 你需要二进制数据(图片、文件) |
response.body | 你需要流式/分块处理 |
更好的模式——真正会检查错误的写法:
async function getPost(id) {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts/${id}`);
if (!response.ok) {
throw new Error(`HTTP ${response.status} ${response.statusText}`);
}
return response.json();
}
const post = await getPost(1);
console.log(post.title);
这行 if (!response.ok),就是教程代码和生产代码之间的分界线。也正是这点,把我们带到最大的坑。
如何使用 Node.js Fetch API 发送 POST 请求
POST 请求的结构是一样的——只是你需要设置 method、headers 和 body:
const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
title: 'Node fetch 指南',
body: '生产环境中的 fetch 需要错误处理。',
userId: 1,
}),
});
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const created = await response.json();
console.log(created.id); // → 101
发送其他请求类型(PUT、DELETE、PATCH)
PUT、PATCH 和 DELETE 只需要把 method 改掉,结构完全一样:
// PUT — 完整替换
await fetch('https://jsonplaceholder.typicode.com/posts/1', {
method: 'PUT',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ id: 1, title: '已替换', body: '完整替换', userId: 1 }),
});
// PATCH — 部分更新
await fetch('https://jsonplaceholder.typicode.com/posts/1', {
method: 'PATCH',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ title: '部分更新' }),
});
// DELETE
await fetch('https://jsonplaceholder.typicode.com/posts/1', {
method: 'DELETE',
});
Express body-parser 陷阱: 如果你正在向 Express 服务器 POST JSON,而 req.body 变成了 undefined,通常的修复办法只有一个:用 express.json(),不要只用 express.urlencoded()。服务器必须在路由之前加上 express.json() 中间件,才能解析 Content-Type: application/json 的请求体。这是 Stack Overflow 上关于 Express 最常见的问题之一,而且每次都能把人坑到。
import express from 'express';
const app = express();
app.use(express.json()); // ← JSON POST 请求体需要这个
app.post('/api/posts', (req, res) => {
res.json({ received: req.body });
});
会让生产应用出问题的 fetch() 错误陷阱
这就是大多数生产环境 fetch bug 的来源。
fetch() 不会在 HTTP 4xx 或 5xx 错误时拒绝 Promise。 它只会在网络层失败时拒绝——比如 DNS 错误、没有网络、请求被中止。如果服务器返回的是 403 Forbidden 或 500 Internal Server Error,fetch 仍然会把它当成一次 成功 的响应。你的 .catch() 根本不会执行。你的 try/catch 也捕获不到。你的代码会愉快地处理服务器返回的任何内容。
MDN 文档 说得很清楚,但大多数教程都一笔带过。结果就是?下面这样的代码看起来没问题,实际上却会静默吞掉错误:
try {
const response = await fetch('https://api.example.com/private');
const data = await response.json(); // ← 即使是 403,这里也会执行
console.log('看起来成功了:', data);
} catch (error) {
// 只有网络层失败才会进来
console.error('捕获到:', error);
}
下面快速拆解一下,每种模式到底能捕获什么:
| 模式 | 能捕获网络错误 | 能捕获 4xx/5xx | 能安全解析 JSON | 可复用 |
|---|---|---|---|---|
原始的 .then(res => res.json()) | 是(通过 .catch()) | 否 | 没有内容类型保护 | 否 |
带 await fetch() 的 try/catch | 是 | 否 | 没有内容类型保护 | 否 |
每次调用都手写 if (!res.ok) | 是 | 是 | 取决于每次调用 | 部分 |
自定义 fetchJSON() 封装 | 是 | 是 | 是 | 是 |
构建可复用的 fetchJSON() 封装
做一个封装,哪里都引入它。别再把 if (!response.ok) 复制到每个文件里:
export class HTTPError extends Error {
constructor(message, { status, statusText, url, body }) {
super(message);
this.name = 'HTTPError';
this.status = status;
this.statusText = statusText;
this.url = url;
this.body = body;
}
}
export async function fetchJSON(url, options = {}) {
const response = await fetch(url, {
headers: {
Accept: 'application/json',
...options.headers,
},
...options,
});
const contentType = response.headers.get('content-type') || '';
const isJSON = contentType.includes('application/json');
const body = isJSON ? await response.json().catch(() => null) : await response.text();
if (!response.ok) {
throw new HTTPError(`HTTP ${response.status} ${response.statusText}`, {
status: response.status,
statusText: response.statusText,
url: response.url,
body,
});
}
return body;
}
现在,当服务器返回 403 时:
try {
const data = await fetchJSON('https://api.example.com/private');
} catch (error) {
if (error instanceof HTTPError) {
console.error(`服务器返回了 ${error.status}:`, error.body);
} else {
console.error('网络或其他失败:', error);
}
}
这个错误对象里带着状态码、响应体和 URL——做日志、告警或面向用户的提示时,你需要的信息都齐了。封装一次,处处可用。
AbortController 和超时:Node.js Fetch API 的生产环境模式
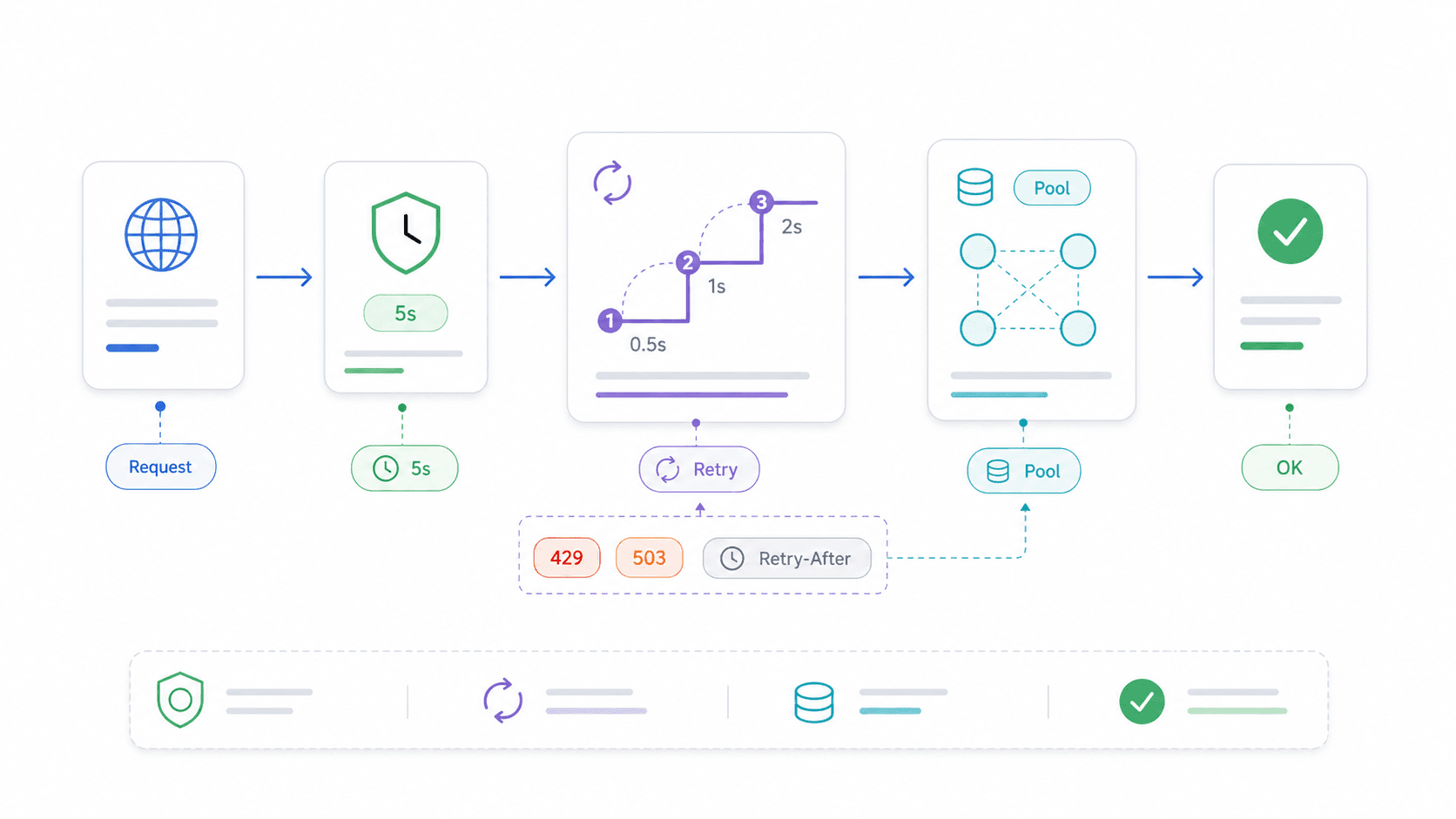
没有超时的话,一旦远端服务器没响应,fetch 请求就会一直挂着。你的 Express 路由会被卡住。你的 Lambda 会把执行预算耗光。你的脚本就这样……干坐着。
我看了搜索结果前几页:没有一篇面向 Node.js 的 fetch 教程会讲请求取消或超时。但超时恰恰是很多开发者坚持用 Axios 或 Got 的原因之一。Reddit 上甚至有一个帖子标题就叫 “Node fetch does not timeout”。
使用 AbortSignal.timeout()(Node 18.11+)
最简单的方法——只需要多加一个选项:
try {
const response = await fetch('https://api.example.com/data', {
signal: AbortSignal.timeout(5000), // 5 秒
});
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const data = await response.json();
console.log(data);
} catch (error) {
if (error.name === 'TimeoutError') {
console.error('请求在 5 秒后超时。');
} else {
throw error;
}
}
注意:AbortSignal.timeout() 抛出的是 TimeoutError,不是 AbortError。这个细节连一些有经验的开发者都会弄错。
用 AbortController 手动超时
如果你想要更多控制,或者你需要根据用户操作来取消请求,而不只是计时器:
const controller = new AbortController();
const timeout = setTimeout(() => controller.abort(), 5000);
try {
const response = await fetch('https://api.example.com/data', {
signal: controller.signal,
});
const data = await response.json();
console.log(data);
} catch (error) {
if (error.name === 'AbortError') {
console.error('请求被手动中止了。');
} else {
throw error;
}
} finally {
clearTimeout(timeout);
}
区分 AbortError 和 TimeoutError
这个区别对日志记录和用户提示非常重要:
| 中止方式 | catch 块里的错误名 |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| DNS/网络失败 | 通常是 TypeError: fetch failed |
下面是一个实用场景——一个调用外部 API 的 Express 路由,而且必须在 3 秒内响应:
app.get('/dashboard', async (req, res, next) => {
try {
const data = await fetchJSON('https://api.example.com/report', {
signal: AbortSignal.timeout(3000),
});
res.json(data);
} catch (error) {
if (error.name === 'TimeoutError') {
res.status(504).json({ error: '上游 API 超时' });
return;
}
next(error);
}
});
如果没有这个模式,一个缓慢的上游 API 就会把整个路由堵死,直到客户端放弃。
重试逻辑和连接复用:把 Node.js Fetch API 变成生产级
原生 fetch 没有内置重试。一次网络抖动或临时性的 503,都会直接失败。对于生产环境里的大多数读操作来说,这还不够。
一个可组合的重试封装,带指数退避
下面的代码刻意写得很短——实际逻辑大约 10 行:
const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
export async function fetchWithRetry(url, options = {}, retries = 2) {
for (let attempt = 0; ; attempt++) {
try {
const response = await fetch(url, options);
if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
return response;
}
if (attempt >= retries) return response;
} catch (error) {
if (attempt >= retries) throw error;
}
await wait(250 * 2 ** attempt); // 250ms、500ms、1000ms……
}
}
什么时候重试,什么时候不该重试
- 应该重试: 幂等的 GET 和 HEAD 请求、临时性状态码(408、429、500、502、503、504)、网络抖动。
- 不应该重试: 会创建记录、扣款或触发副作用的非幂等 POST 请求——除非你使用幂等键。
- 尊重 Retry-After: 对于 429(限流)和 503(服务不可用),退避前先检查
Retry-After请求头。
如果你不想自己造重试逻辑,Ky 是一个轻量级的 fetch 封装,开箱即带重试、超时、hooks 和 HTTPError——而且零依赖。
使用 Undici 的 Agent 和 Pool 复用连接
对于高吞吐循环——例如抓取几百个页面、批量调用 API、轮询某个服务——复用 TCP 连接能省下很多时间。每建立一个新连接,都意味着新的 DNS 查询、TCP 握手,以及(对 HTTPS 来说)TLS 协商。
由于 Node 的 fetch 由 Undici 驱动,你可以传入自定义 dispatcher:
import { Agent } from 'undici';
const agent = new Agent({
keepAliveTimeout: 10_000,
keepAliveMaxTimeout: 60_000,
});
const response = await fetch('https://api.example.com/data', {
dispatcher: agent,
});
如果你想对某个特定 origin 进行更精细的控制:
import { Pool } from 'undici';
const pool = new Pool('https://api.example.com', { connections: 10 });
const response = await fetch('https://api.example.com/data', {
dispatcher: pool,
});
// 完成后:
await pool.close();
Undici README 的基准测试 显示,连接复用和连接池能显著提升吞吐量——他们本地基准里 undici - dispatch 约为 22,234 req/sec,而 undici - fetch 约为 5,904 req/sec。真实环境的数字会有所不同,但方向很明确:如果你在对同一个 origin 发起大量请求,连接池很重要。
还有一件事:一定要消费或取消响应体。未消费的响应体可能会导致 Node HTTP 内部资源泄漏。
使用 Node.js Fetch API 处理流式响应
大文件下载、分块 JSON 数据流、Server-Sent Events、LLM 输出——这些场景里,如果你非要等完整响应回来再处理,就会浪费时间和内存。流式处理可以让你边到边处理。
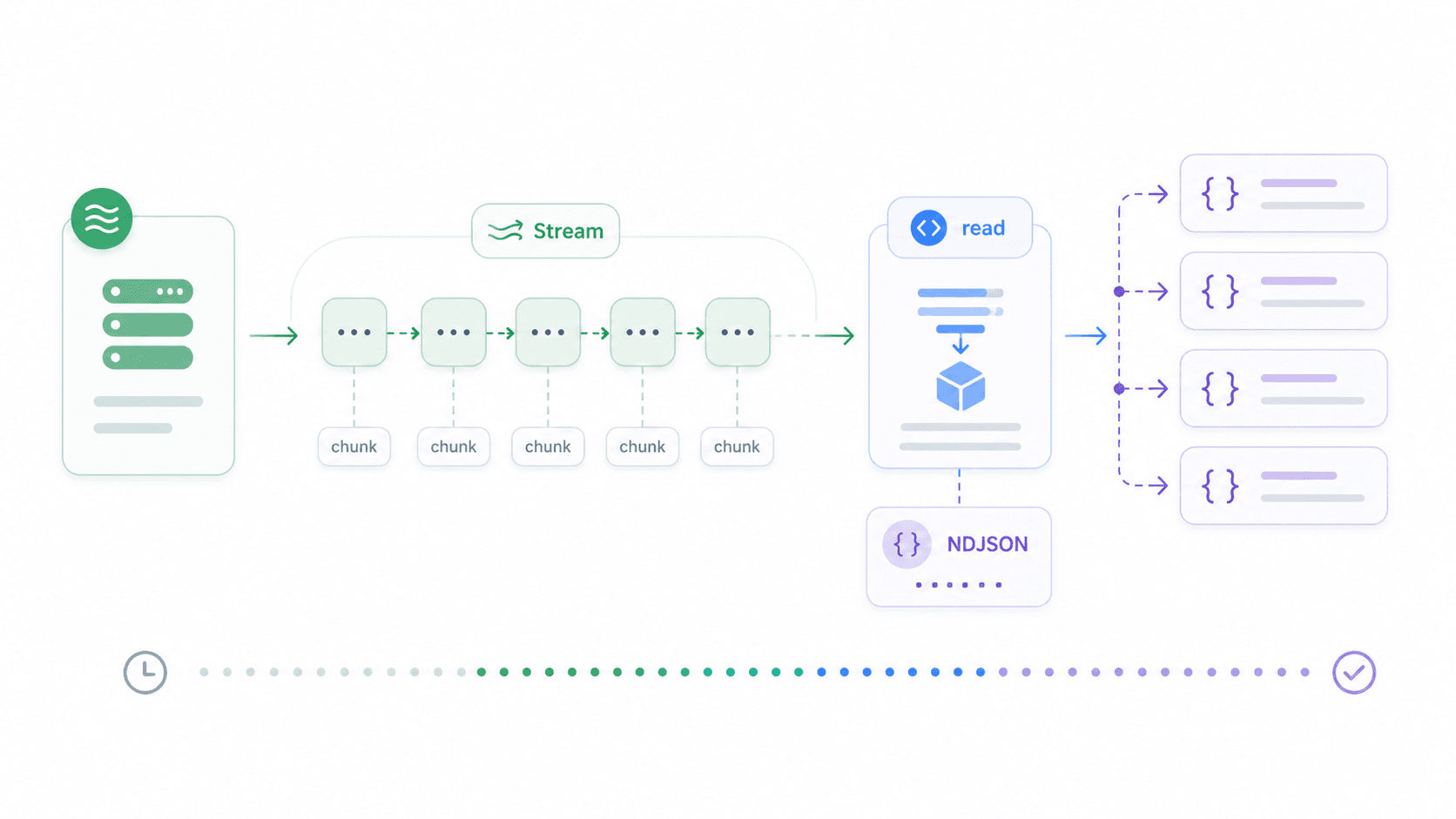
Node 18+ 已经包含与浏览器兼容的 ReadableStream。下面是如何流式读取一份以换行分隔的 JSON 响应,并在每一行到达时立刻处理:
const response = await fetch('https://example.com/large-file.ndjson');
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
while (true) {
const { value, done } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
let newlineIndex;
while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
const line = buffer.slice(0, newlineIndex).trim();
buffer = buffer.slice(newlineIndex + 1);
if (line) {
const item = JSON.parse(line);
console.log('已处理:', item.id);
}
}
}
如果只是更简单的文本流式处理(例如把 LLM 输出直接写到 stdout):
const response = await fetch('https://example.com/stream');
const reader = response.body.getReader();
const decoder = new TextDecoder();
for (;;) {
const { value, done } = await reader.read();
if (done) break;
process.stdout.write(decoder.decode(value, { stream: true }));
}
流式处理是原生 fetch 和 Got 都很擅长的领域。Axios 的流式支持则相对有限。
当 fetch() 到达极限:用 API 做结构化网页抓取
总有那么一刻,fetch 不再是瓶颈。真正的问题变成了:“我已经拿到 HTML 了,然后呢?”
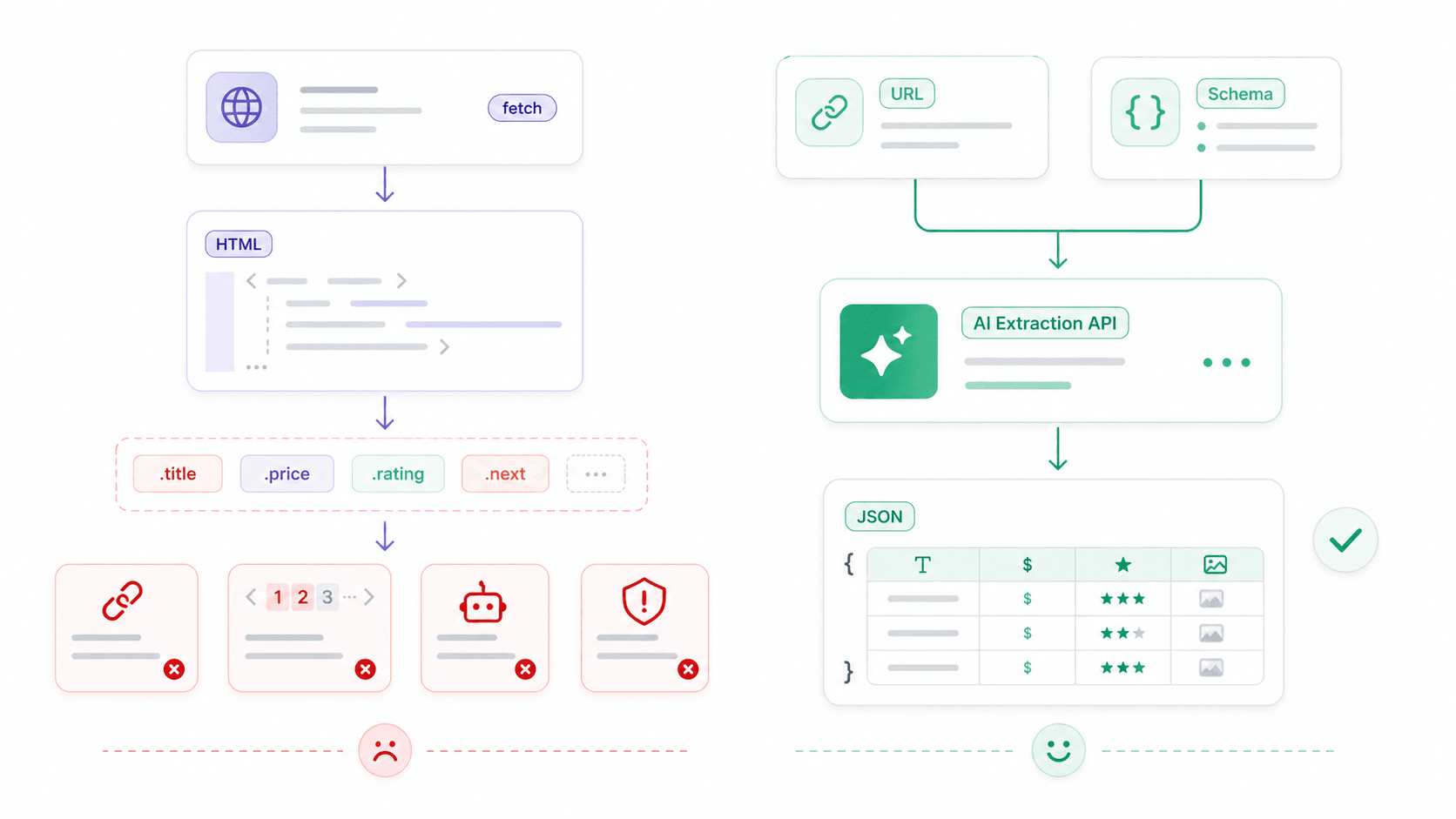
Fetch 只是一个 HTTP 客户端——它能拿到字节、文本、JSON 或 HTML。它并不知道什么是商品卡片、价格、评分或联系人表格。对于结构化网页抓取,典型的原始技术栈是这样:
- 用
fetch()下载 HTML - 用 Cheerio(或类似工具)通过 CSS 选择器选取元素
- 自己写分页逻辑
- 页面由客户端渲染时还要执行 JavaScript
- 处理代理/反爬/CAPTCHA
- 网站布局一变,就得维护选择器
下面是一个典型的 fetch + Cheerio 示例——抓取商品标题大约要 15 行:
import * as cheerio from 'cheerio';
const response = await fetch('https://example-store.com/products');
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const html = await response.text();
const $ = cheerio.load(html);
const products = $('.product-card')
.map((_, el) => ({
name: $(el).find('.product-title').text().trim(),
price: $(el).find('.price').text().trim(),
url: new URL($(el).find('a').attr('href'), response.url).href,
}))
.get();
console.log(products);
这对 HTML 稳定、结构可预测的页面是可行的。但它很快就会变脆弱——JavaScript 渲染内容、变化中的 class 名、反爬机制和分页,都会让复杂度迅速上升。
Thunderbit 的开放 API:一次调用,把原始 HTML 变成结构化数据
这时候就需要另一类工具了。在 Thunderbit 里,我们做了一层 API,帮你处理那些麻烦事——JavaScript 渲染、反爬保护、布局变化——让你专注于真正想要的数据。
Distill API(POST /distill):把任意 URL 转成干净的 Markdown。适合喂给 LLM、构建知识库或做内容分析——不需要 HTML 解析器。
Extract API(POST /extract):定义一个描述你想要的结构化数据的 JSON Schema(商品名、价格、评分),然后由 AI 来提取。不需要 CSS 选择器,也不会因为页面布局变化而坏掉。
下面是使用 Thunderbit Extract API 完成同样商品抓取任务的方式——直接用原生 fetch 调用:
const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
method: 'POST',
headers: {
Authorization: `Bearer ${process.env.THUNDERBIT_API_KEY}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
url: 'https://example-store.com/products',
renderMode: 'basic',
schema: {
type: 'object',
properties: {
products: {
type: 'array',
items: {
type: 'object',
properties: {
name: { type: 'string', description: '商品名称' },
price: { type: 'string', description: '页面展示的商品价格' },
rating: { type: 'number', description: '平均用户评分' },
},
required: ['name', 'price'],
},
},
},
required: ['products'],
},
}),
});
if (!response.ok) throw new Error(`Thunderbit API: ${response.status}`);
const result = await response.json();
console.log(result.data);
对比一下:大约 15 行的 fetch + Cheerio(外加脆弱的选择器),和一次就能返回干净 JSON 的 API 调用。对于批量任务,Thunderbit 支持单次批量 Extract 最多 50 个 URL,单次批量 Distill 最多 100 个 URL。
Thunderbit 不是 fetch 的替代品——fetch 是传输层。而当原始 HTML 解析本身成了问题时,Thunderbit 就是你该用的提取层。如果你关心价格,免费套餐 提供 600 个 API 单位供你试用,付费方案从每月 6 美元起。你也可以查看 Thunderbit Chrome 扩展,直接在浏览器里做无代码提取。
如果你想进一步了解结构化抓取方案,我们关于 最佳数据提取工具、如何创建网页爬虫 和 从网站抓取数据到 Excel 的指南,覆盖了更具体的工作流。
快速参考:Node.js Fetch API 速查表
这一部分建议你收藏。需要复制粘贴某个模式时再回来查。
| 模式 | 代码片段 |
|---|---|
| 基础 GET | const res = await fetch(url); const data = await res.json(); |
| 基础 POST | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| HTTP 错误检查 | if (!res.ok) throw new Error(\\HTTP ${res.status}\); |
| 超时(简单版) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| 手动中止 | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| 重试状态码 | 重试 408、429、500、502、503、504。不要盲目重试 POST。 |
| JSON 封装 | 用 fetchJSON() 检查 ok、解析内容类型、抛出 HTTPError。 |
| 连接池 | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| 流式分块 | const reader = res.body.getReader(); 循环 await reader.read() |
| 结构化提取 | 当目标是网页字段而不是原始 HTML 时,使用 Thunderbit Extract API。 |
结论与要点总结
到了 2026 年,Node.js 原生 fetch 已经可以用于生产环境——新项目不再需要 node-fetch,也不再默认依赖 Axios。可光靠原始 fetch() 本身,还不能算一套完整的生产级 HTTP 策略。
大多数教程会跳过的五件事,而这篇指南都讲到了:
- 错误陷阱:
fetch()不会在 4xx/5xx 时抛错。务必检查response.ok,或者使用像fetchJSON()这样的封装。 - 超时: 简单场景用
AbortSignal.timeout()。AbortSignal.timeout()抛出的是TimeoutError;手动controller.abort()抛出的是AbortError。 - 重试逻辑: 原生没有。对幂等请求和临时性失败加指数退避。或者直接用 Ky,开箱即带 fetch 风格重试。
- 连接复用: 在高吞吐循环里,通过
dispatcher选项使用 Undici 的Agent或Pool。 - 结构化提取: 当你需要的是网页里的数据(而不只是原始 HTML)时,与其维护脆弱的 CSS 选择器,不如考虑像 Thunderbit 这样的提取 API。
一句话版的决策矩阵:大多数项目用原生 fetch,拦截器用 Axios,内置重试和 HTTP/2 用 Got,想要更好默认值的 fetch 用 Ky,而当你的基于 fetch 的抓取脚本复杂到难以维护时,就用 Thunderbit 的 API。
试试这篇指南里的这些模式。如果你想看看 Thunderbit 如何处理结构化提取,免费套餐 是个不错的起点——或者去 Thunderbit YouTube 频道 看一段实操演示。
试用 Thunderbit 进行 AI 网页爬虫 Get Started Free
常见问题
1. fetch 是内置在 Node.js 里的,还是需要安装?
Fetch 从 Node.js 18 开始就是内置的——不需要安装。它在 Node 21 中变成稳定版,并在 Node 22 LTS 和 Node 24 LTS 中得到完整支持。对于更老的 Node 版本,你可以使用 node-fetch 这个 npm 包,但新项目最好目标设定为受维护的 LTS 版本。
2. fetch 遇到 404 或 500 响应会抛错吗?
不会。Fetch 只会在网络层失败时拒绝 Promise(DNS 错误、无网络、请求被中止)。像 404、403、500 这类 HTTP 响应会正常 resolve,只是 response.ok === false。你必须显式检查 response.ok 或 response.status——或者像本指南里展示的那样,使用 fetchJSON() 这样的封装。
3. 我该如何给 Node.js 的 fetch 加超时?
最简单的方法是 AbortSignal.timeout(ms),Node 18.11+ 可用:await fetch(url, { signal: AbortSignal.timeout(5000) })。如果请求超过 5 秒,它会抛出 TimeoutError。如果想要更多控制,可以手动创建 AbortController,再通过 setTimeout 调用 controller.abort()。手动模式捕获 AbortError,AbortSignal.timeout() 则捕获 TimeoutError。
4. 我可以在 Node.js 里用 fetch 做网页爬虫吗?
可以,但 fetch 只会返回原始 HTML。你还需要像 Cheerio 这样的解析器来提取特定元素,并为分页、JavaScript 渲染页面和反爬措施写额外逻辑。如果你要做大规模的结构化数据提取——希望拿到商品名、价格或联系信息这类干净 JSON——可以考虑 Thunderbit 的 Extract API,它能用 AI 返回结构化数据,而不需要 CSS 选择器或依赖布局的代码。
5. 到了 2026 年,我应该从 Axios 换成原生 fetch 吗?
对于运行在 Node 22+ 上的新项目,原生 fetch 是很强的默认选择。它零依赖、基于 Promise,而且和浏览器的 fetch API 一样。只有当你依赖请求/响应拦截器、默认 HTTP 错误拒绝,或者需要兼容更老的 Node 版本时,才保留 Axios。两者都合理——关键取决于你的项目实际用了哪些功能。
了解更多




