
一项基于抓取的研究,考察高流量网站如何为大语言模型发布机器可读的指引、早期实现看起来是什么样,以及为什么衡量采用情况不能只看 HTTP 200 响应数量。
- 数据集:
data/llms_probe_results_top_10000.csv - Tranco 列表下载时间:2026 年 5 月 6 日
- 范围:根路径级别的
/llms.txt和/llms-full.txt
关键指标
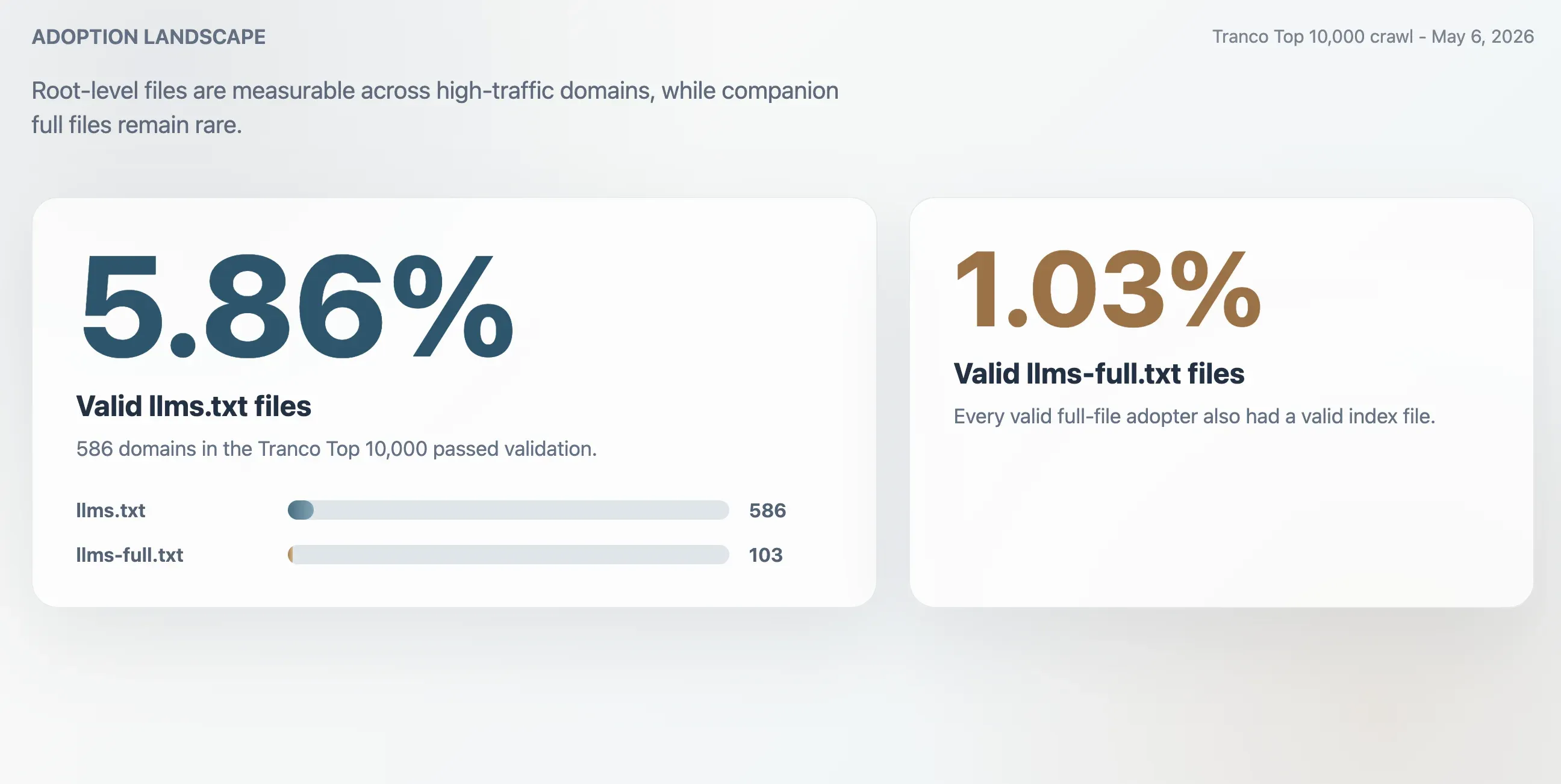
- 5.86%:Tranco 前 10,000 中有效
llms.txt的采用率,共 586 个域名。 - 1.03%:有效
llms-full.txt的采用率,共 103 个域名。所有有效的完整文件采用者也都有有效的索引文件。 - 63.51%:
/llms.txt返回的 HTTP 200 响应中,未通过验证的占比。 - 2.74 倍:如果只按原始 HTTP 200 响应统计,采用率大约会被高估的倍数。
执行摘要
llms.txt 仍然是一种早期的网络约定,但它已经不再是边缘实验。2026 年 5 月 6 日对 Tranco 前 10,000 域名的抓取中,本研究发现了 586 个有效的 llms.txt 文件,实际采用率为 5.86%。配套的 llms-full.txt 文件要少得多:只有 103 个域名拥有有效的完整文件,采用率为 1.03%。
最重要的方法论发现是,状态码并不是衡量采用情况的好代理。爬虫观察到 /llms.txt 有 1,606 个 HTTP 200 响应,但只有 586 个通过了验证。剩下的 1,020 个大多是跳转到无关页面、通用 HTML 页面、空响应体或其他无效响应。如果天真地把每个 200 响应都算作采用,真实的有效采用率会被高估约 2.74 倍。
在有效采用者中,实现质量比“只是占位符”的叙事要高。有效文件的中位大小约为 7.1 KB,61.77% 的有效文件大于 5 KB,70.82% 包含 6 个或更多 Markdown 分区,77.47% 包含 11 条或更多 Markdown 链接。早期采用者包括 Cloudflare、Azure、GitHub、DigiCert、WordPress.org、Adobe、Dropbox、PayPal、Stripe、Salesforce、Slack、Zendesk、Okta、Datadog 和 Cloudinary。
llms.txt最适合被理解为面向 AI 系统的说明和导航信号,而不是robots.txt的替代品。它的价值不只是文件是否存在,更在于它能否帮助机器找到权威、简洁、最新的信息。
背景:Web 正在添加面向 AI 的信号
网站长期以来一直用 robots.txt 表达爬虫偏好,用 sitemap.xml 提升 URL 发现效率,并通过结构化数据帮助搜索和平台系统理解页面。生成式 AI 带来了一个不同的问题。内容可能会被用于训练、检索、摘要、智能体浏览、代码辅助、客服和答案生成。这带来了两个同时存在的需求:发布方既希望对自动化使用有更多控制,也希望当 AI 系统确实访问他们的网站时,能找到正确的权威信息。
,由 Jeremy Howard 于 2024 年提出,将该文件描述为放在网站根目录下的 Markdown 文档,用于在推理时向 LLM 提供易于理解的信息。该提案认为,HTML 页面通常包含导航、广告、脚本和其他噪音,会让语言模型更难处理。一个简洁的 Markdown 文件可以把模型引向最重要的页面、文档、API、示例、政策和产品信息。
外部网络研究提供了更大的背景。 描述了 robots.txt 和服务条款中与 AI 相关限制的快速增加,并指出现有的 Web 同意机制并不是为大规模 AI 数据复用而设计的。 也让 AI 爬虫和 robots.txt 模式在前 10,000 域名层面变得可见。在这样的环境里,llms.txt 站在 AI 信号的建设性一侧:它不是在说“不要抓取这个”,而是在说“如果你需要理解这个网站,请从这里开始”。
外部证据与采用争议
围绕 llms.txt 的公开讨论主要分成两种观点。乐观观点认为,这个文件能为 AI 系统提供更干净、更高效的权威内容路径。怀疑观点则认为,没有任何主要 LLM 提供方公开承诺会把它作为排序、抓取或引用信号,因此发布方不应仅凭这个文件期待流量增长。本次更新审阅的三项外部参考支持一种更细腻的结论:llms.txt 是有用的基础设施,但其直接流量影响的证据仍然有限,而且高度依赖场景。
外部采用基准正在快速变化
报告称,截至 2025 年 6 月 22 日,前 1,000 个网站中的采用率为 0.3%,即 1,000 个站点中有 3 个。它描述的是每月自动扫描 domain.com/llms.txt,并通过验证排除重定向和 HTML 响应。这种方法与本研究的保守验证方法在方向上相似。
结果差异很大:本研究在 2026 年 5 月 6 日对 Tranco 前 1,000 的抓取中发现了 75 个有效 llms.txt,即 7.50%。这两个数字不应被当作严格的时间序列,因为排名来源、实现细节、验证逻辑和抓取时间都可能不同。即便如此,这种对比仍然表明,2025 年中期到 2026 年 5 月之间采用情况发生了显著变化,尤其是在开发者、SaaS、云、安全和文档密集型网站中。
| 来源 | 快照时间 | 样本 | 报告的有效采用率 | 解读 |
|---|---|---|---|---|
| Rankability | 2025 年 6 月 22 日 | 前 1,000 个网站 | 0.3% | 2025 年中期的早期公开基准,显示采用极少。 |
| 本研究 | 2026 年 5 月 6 日 | Tranco 前 1,000 | 7.50% | 后来的抓取显示高流量网站中已出现明显采用。 |
| 本研究 | 2026 年 5 月 6 日 | Tranco 前 10,000 | 5.86% | 更大样本显示采用可测量,但尚未普及。 |
流量实验仍然结论不一
在 2026 年 1 月发布了一项对 10 个站点的分析,跟踪这些站点在实施前 90 天和实施后 90 天的表现。文章报告称,两个站点的 AI 流量分别增长了 12.5% 和 25%,八个站点没有可测量的提升,另有一个下降了 19.7%。其核心判断是要谨慎看待因果关系:那两个看似成功的案例同时还推出了新模板、重建了资源中心、增加了可提取的对比表、获得了媒体报道、修复了技术问题或发布了新的 FAQ 风格内容。在这种框架下,llms.txt 记录了更强的内容与技术工作;但看起来并不是它单独导致了增长。
基于更小规模的网站观察,得出了更积极的结论。该实验比较了在加入 llms.txt 和 llms-full.txt 之后,Yandex.Metrica 中两个四个月周期的表现。LLM 引荐会话从 75 增至 92,增长了 23%,同时用户数从 51 增至 64。Perplexity 会话从 29 增至 55,而 ChatGPT 会话从 31 降至 26。该文章还指出,总引荐流量增长更快,从 160 增至 290 次会话,因此 LLM 会话占比从 47% 降至 32%。
| 证据类型 | 观察结果 | 主要注意事项 | 对本报告的影响 |
|---|---|---|---|
| Search Engine Land 的 10 站点前后对比研究 | 2 个站点上升,8 个没有可测量变化,1 个下降。 | 正向案例同时存在内容、PR 和技术变更。 | 支持将 llms.txt 视为基础设施,而不是单独的增长杠杆。 |
| Alimbekov 个人博客前后观察 | LLM 引荐会话在后期增长了 23%。 | 没有对照组;总引荐流量增长了 81%,且 LLM 占比下降。 | 暗示技术博客可能受益,尤其是来自 Perplexity 的流量,但因果关系未被隔离。 |
| 本次基于抓取的采用研究 | 发现 586 个有效文件和大量结构化实现。 | 衡量的是存在与结构,而不是下游流量影响。 | 说明采用度和实现成熟度,但不能单独证明投资回报。 |
争议真正澄清了什么
外部证据让这份数据集的解读更清楚了。一个结构良好的 llms.txt 文件可以降低机器解析摩擦,尤其适用于开发者文档、API 参考和知识库内容。但最强的流量案例似乎仍然取决于内容本身是否有用、可提取、权威且能在文件之外被发现。因此,实际问题不是孤立地问“llms.txt 有用吗?”,而是要看它是否是更广泛的、可被 AI 读取的内容系统的一部分。
更新后的解读:
llms.txt应该被视为低成本、面向 AI 的基础设施来实施。它不应被定位为更好文档、结构化内容、技术可访问性、引用、链接或品牌权威的替代品。
方法
本研究使用 Tranco 前 10,000 域名作为样本。Tranco 是一个面向研究的 Top Site 排名,设计上比许多传统榜单更稳定,也更能抵抗人为操纵。Tranco 源文件下载于 2026 年 5 月 6 日,源文件的 Last-Modified 时间戳为 2026 年 5 月 5 日 22:17:59 GMT。
爬虫对每个域名测试了两个根路径:
https://example.com/llms.txt,必要时使用 HTTP 回退。https://example.com/llms-full.txt,必要时使用 HTTP 回退。
对每次探测,爬虫记录了状态码、最终 URL、抓取方式、响应字节数、内容类型、错误信息、耗时以及验证结果。成功的响应正文会保存到 raw_llms_txt/,供复查和二次分析。
验证规则
只有在返回了成功正文且看起来不是通用网页回退时,响应才会被计为有效文件。最终 URL 路径必须保持为 /llms.txt 或 /llms-full.txt。空正文会被拒绝。明显的 HTML 文档和应用壳会被拒绝。内容类型只作为辅助证据,而不是唯一标准,因为少量有效的文本类文件使用了非标准内容类型。
采用格局
在 Tranco 前 10,000 中,爬虫发现了 586 个有效的 llms.txt 文件,有效采用率为 5.86%。更小的配套文件 llms-full.txt 在 103 个域名上存在且有效,占样本的 1.03%。
| 指标 | 数量 | 占前 10,000 的比例 |
|---|---|---|
| 抓取的域名数 | 10,000 | 100.00% |
| 有效 llms.txt 文件 | 586 | 5.86% |
| 有效 llms-full.txt 文件 | 103 | 1.03% |
| /llms.txt 的 HTTP 200 响应 | 1,606 | 16.06% |
| 被判定为无效的 HTTP 200 响应 | 1,020 | 10.20% |
采用并不只是顶层集中
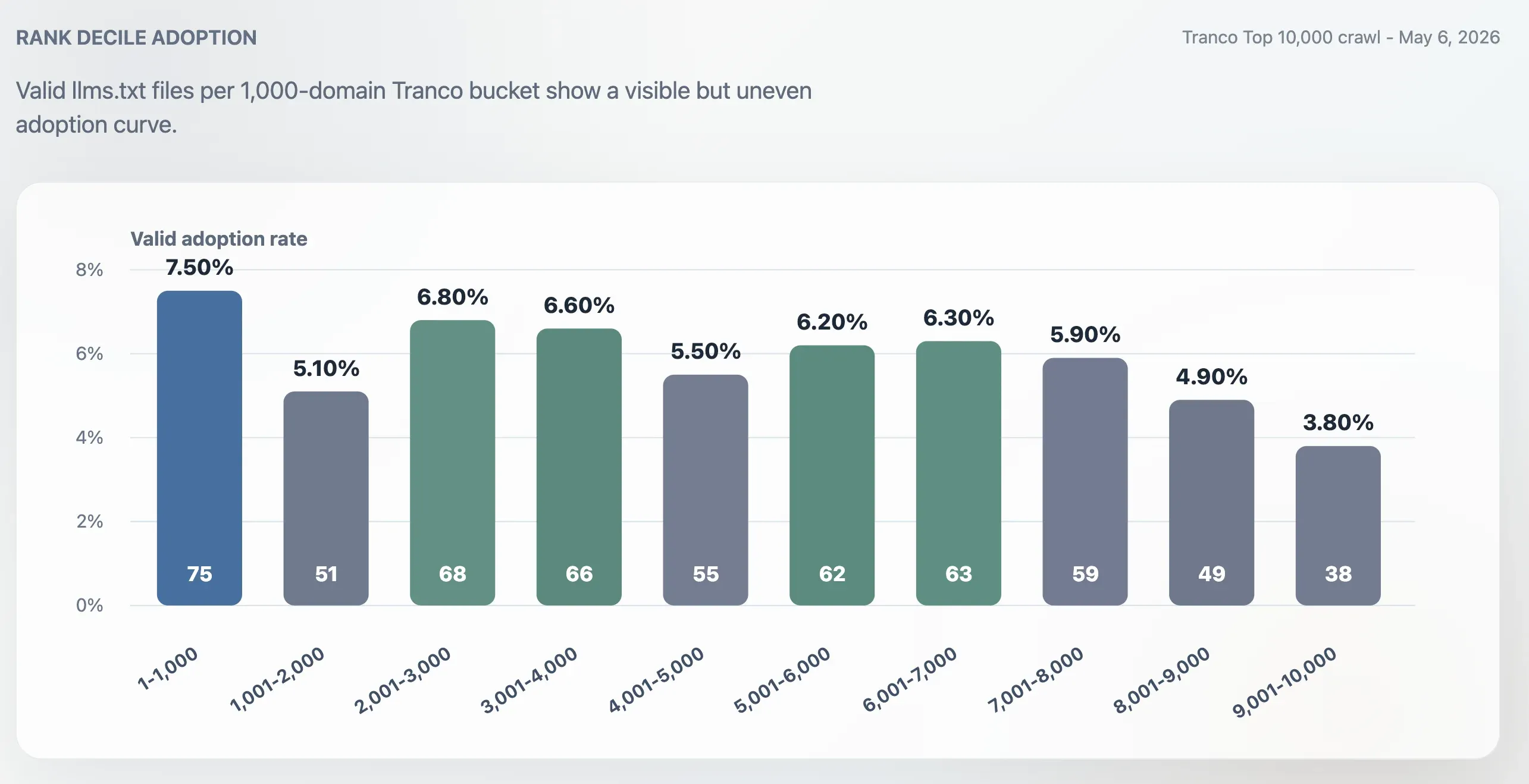
前 1,000 的采用率高于整个前 10,000,但并不只集中在最顶端的大站。前 1,000 的采用率为 7.50%。排名 9,001-10,000 的最后 1,000 个域名区间则降至 3.80%。排名中段依然活跃:2,001-3,000、3,001-4,000、5,001-6,000 和 6,001-7,000 这些区间都大约在 6% 左右。
早期采用者
排名最高的有效采用者是 Tranco 排名第 4 的 Cloudflare。其他高排名采用者包括 Azure、GitHub、DigiCert、WordPress.org、Adobe、Sentry、Dropbox、PayPal、Shopify、Taboola、Avast、Weather.com、Oxylabs、SourceForge、Cisco、Stripe、Slack、Dell、NVIDIA、Indeed、Zendesk、Calendly、Palo Alto Networks、Okta、Braze、Klaviyo、Intercom、Datadog、Cloudinary、ClassLink 和 OneSignal。
这些采用者并不是随机出现的。它们通常拥有大量文档内容、需要解释的产品线、API 或开发者生态、支持内容、定价页面、安全与隐私材料,以及足够的品牌权威,会在意 AI 系统如何理解它们的网站。
| 排名 | 域名 | 文件大小 | 观察到的模式 |
|---|---|---|---|
| 4 | cloudflare.com | 4,225 B | 紧凑的产品、开发者、公司和定价索引。 |
| 26 | azure.com | 47,037 B | 开发者工具、AI、计算、存储、安全、监控和可选资源。 |
| 28 | github.com | 27,108 B | 程序化访问、Copilot、MCP、REST API、Actions、仓库和 CLI 链接。 |
| 248 | stripe.com | 64,229 B | 支付、Connect、Checkout、Billing、Tax、Atlas、Radar 和开发者文档。 |
| 265 | salesforce.com | 1.02 MB | 大型产品与 Agentforce 链接目录,没有 Markdown 分区标题。 |
前 1,000 采用者的类别
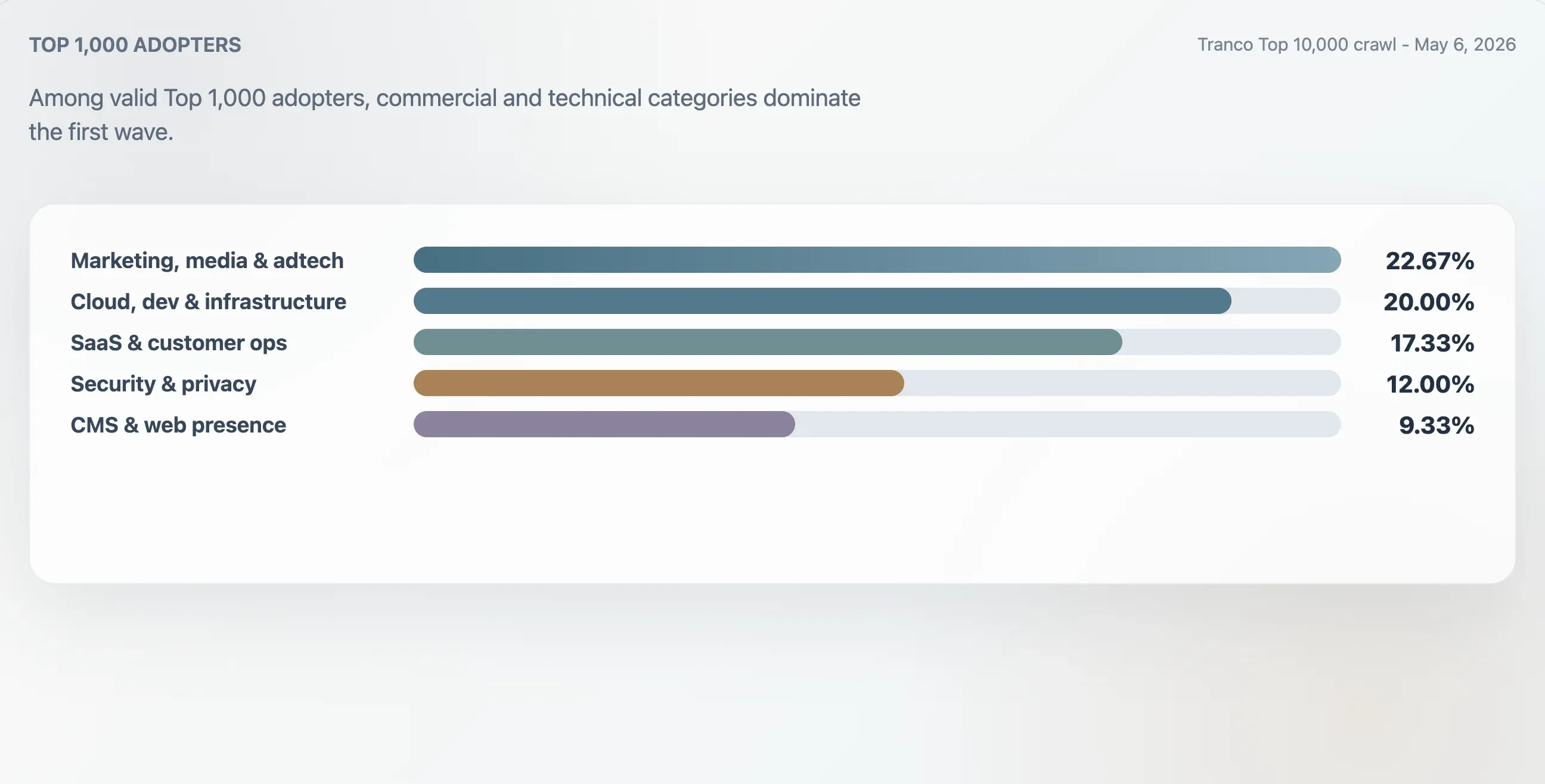
本研究使用域名上下文、首个标题、原始文件结构和内容关键词,对 Tranco 前 1,000 中的 75 个有效采用者进行了分类。占比最大的类别是营销、媒体和 adtech,占 22.67%。云、开发者和基础设施网站占 20.00%。SaaS、生产力和客户运营类网站占 17.33%。安全、身份和隐私类网站占 12.00%。
| 类别 | 域名数 | 占前 1,000 采用者的比例 | 质量中位数 | 链接中位数 |
|---|---|---|---|---|
| 营销、媒体与 adtech | 17 | 22.67% | 94 | 25 |
| 云、开发者与基础设施 | 15 | 20.00% | 94 | 62 |
| SaaS、生产力与客户运营 | 13 | 17.33% | 94 | 46 |
| 安全、身份与隐私 | 9 | 12.00% | 98 | 78 |
| CMS、主机与网站存在 | 7 | 9.33% | 100 | 24 |
TLD 模式
顶级域名并不是行业标签,但它们可以提供方向性信号。在样本中至少包含 50 个域名的 TLD 里,.io 的有效采用率最高,为 14.44%。.com 以 8.19% 紧随其后。.gov、.edu 和 .net 的采用率较低,说明早期采用者基础更偏商业和技术,而不是机构型。
实现质量
有效采用并不意味着实现质量一致。有些文件是简洁、分区清晰的索引。有些主要是说明文字。有些是原始链接目录。有些几乎是空占位符。有些则是多 MB 的内容倾倒,可能很完整,但抓取和解析成本高。
在有效的 llms.txt 文件中,有 362 个大于 5 KB,占有效采用者的 61.77%。文件大小中位数约为 7.1 KB。P90 文件大小为 156 KB,P95 为 356 KB,P99 为 2.54 MB,观察到的最大文件为 7.97 MB。
常见内容信号
对有效文件进行关键词扫描后发现,许多网站并不只是发布一个声明,而是在把模型引向具有实际操作价值的材料。支持或帮助相关词汇出现在 70.31% 的有效文件中。博客、指南或教程相关词汇出现在 67.92%。安全、隐私、合规或条款相关词汇出现在 61.43%。定价出现在 53.92%,文档出现在 52.22%,API 相关词汇出现在 33.96%,更新日志或发布信号出现在 27.30%。
质量评分与类型
为了从“是否存在”推进到“是否成熟”,本研究创建了一个轻量级实现评分。该评分综合了内容类型、文件大小、Markdown 结构、链接数量、主题覆盖,以及诸如缺少标题、没有 Markdown 链接、异常内容类型、过小文件、过大文件和链接倾倒行为等警示信号。这不是正式标准,而是用于比较观察到的实现情况的研究评分模型。
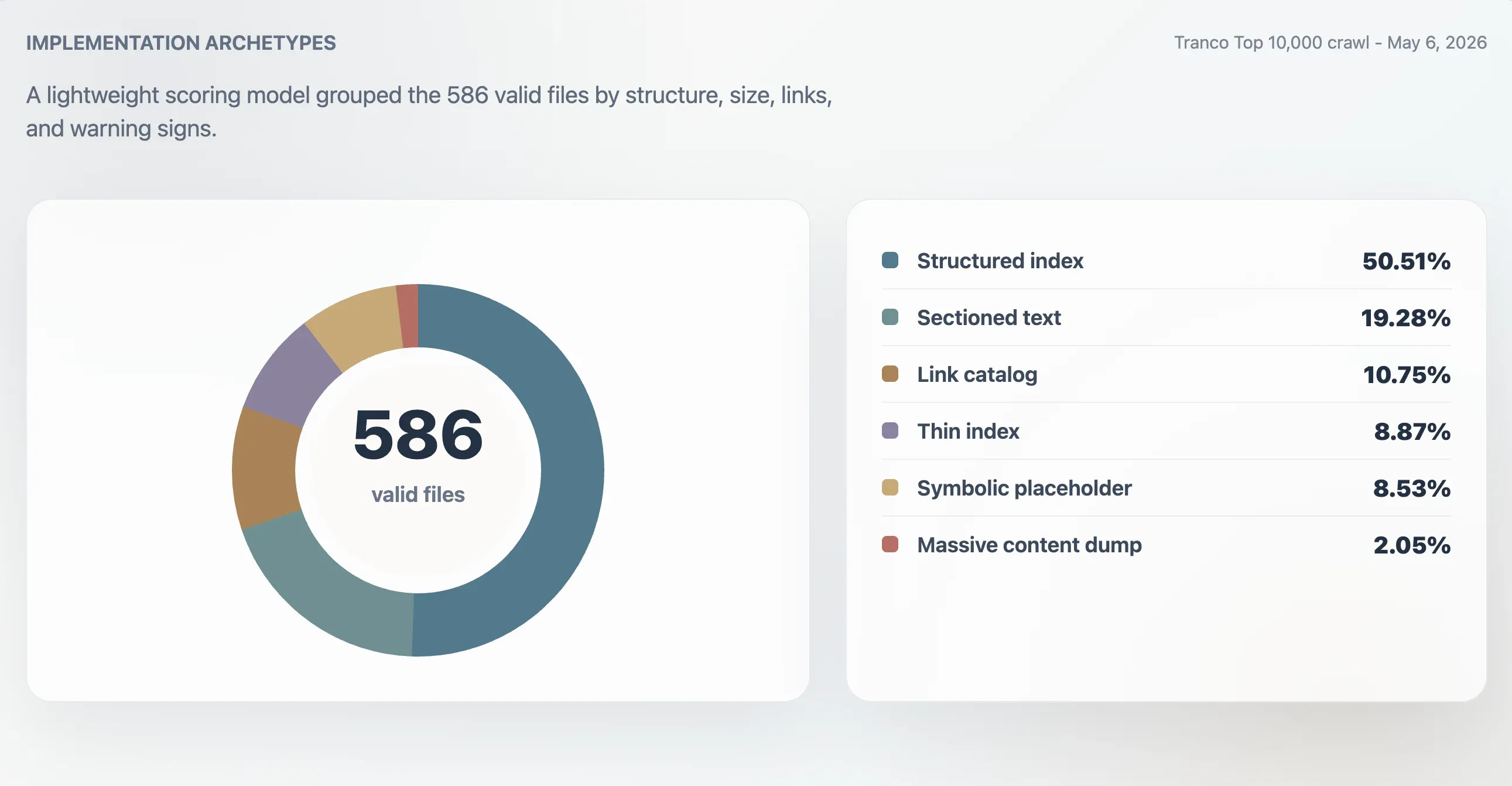
使用该模型,416 个有效文件被归类为强结构化索引,107 个为可用索引,24 个为薄弱或不规则,39 个为象征性或低效用。另一项类型分析发现,296 个结构化索引、113 个分段文本文件、63 个链接目录、52 个薄索引、50 个象征性或占位文件,以及 12 个大规模内容倾倒文件。
| 类型 | 域名数 | 占有效文件比例 | 质量中位数 | 文件大小中位数 | 链接中位数 |
|---|---|---|---|---|---|
| 结构化索引 | 296 | 50.51% | 98 | 11,241 B | 61.5 |
| 分段文本 | 113 | 19.28% | 78 | 4,718 B | 0 |
| 链接目录 | 63 | 10.75% | 86 | 4,160 B | 23 |
| 薄索引 | 52 | 8.87% | 66 | 2,814 B | 0 |
| 象征性或占位符 | 50 | 8.53% | 27 | 15 B | 0 |
| 大规模内容倾倒 | 12 | 2.05% | 74 | 2.84 MB | 7,259.5 |
顶级采用者的实现更密集
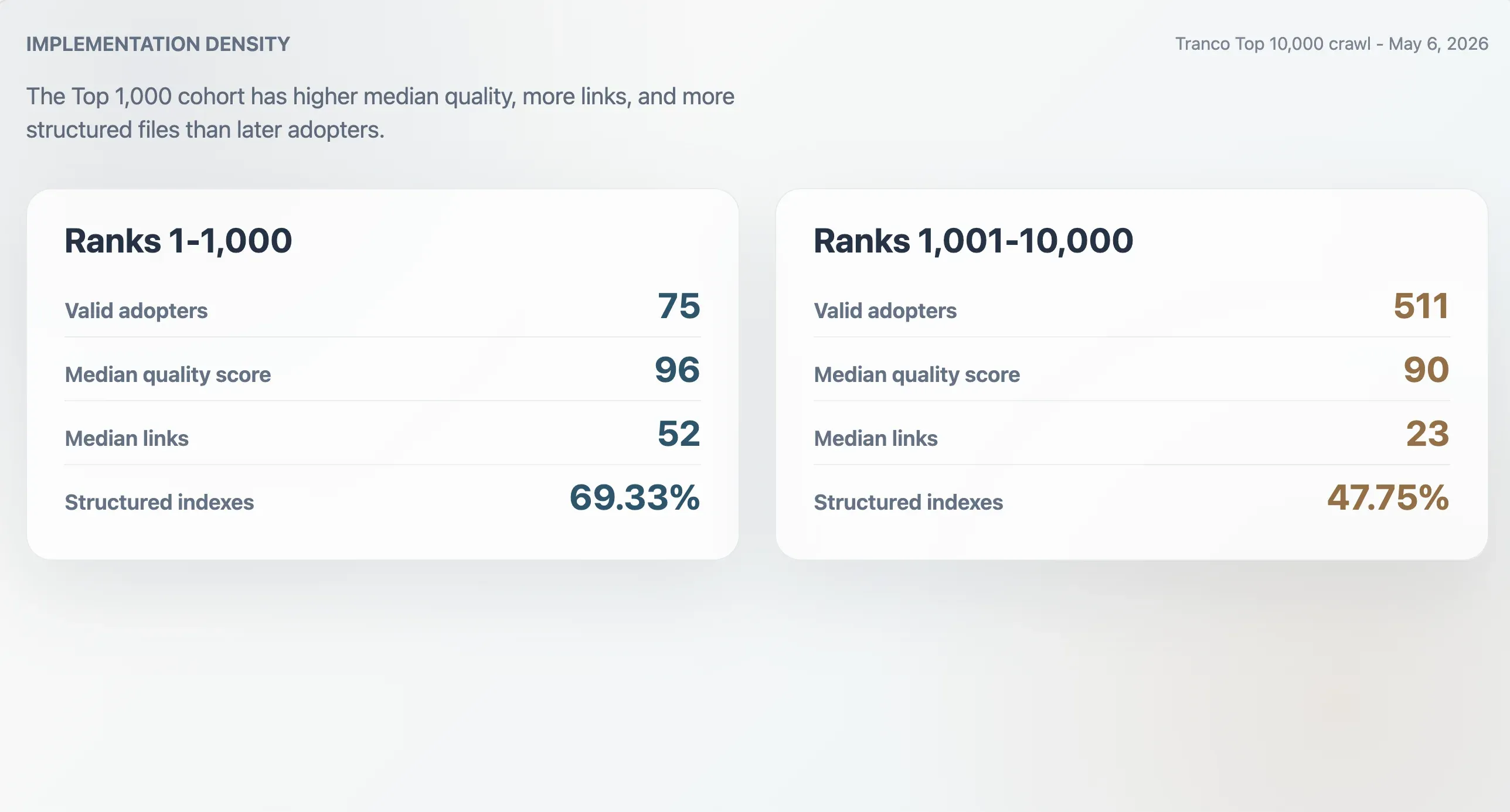
Tranco 前 1,000 中的 75 个有效采用者,质量中位数为 96,文件大小中位数为 9,068 字节,Markdown 链接中位数为 52,分区数量中位数为 11。排名 1,001-10,000 的 511 个采用者中位数更低:质量 90、文件大小 6,506 字节、Markdown 链接 23 个、分区 9 个。前 1,000 采用者也更可能是结构化索引:这一比例为 69.33%,而后续区间为 47.75%。
误报问题

最大的测量风险是误报。在返回 /llms.txt 的 1,606 个 HTTP 200 域名中,有 1,020 个未通过验证。最常见的无效原因是跳转到无关目标,共 618 个案例。另有 367 个响应是通用 HTML 文档。29 个返回空正文,6 个是其他或未分类的无效响应。
这很重要,因为许多大型网站会把未知路径路由到登录页、主页、应用壳、地区页面、同意提示层或营销回退页。对于只看状态码的爬虫来说,这些响应看起来“正常”,但其中并没有有效的 llms.txt 信号。
llms-full.txt:更稀少,也更不均衡
配套的 llms-full.txt 文件比 llms.txt 少得多。抓取发现了 103 个有效完整文件,占有效 llms.txt 采用者的 17.58%,占整个前 10,000 样本的 1.03%。
完整文件的实现很不均衡。在 103 个双文件采用者中,57 个的 llms-full.txt 比索引文件更大,但 46 个要么完整文件不大于索引文件,要么完整文件小于 100 字节。完整文件与索引文件大小比的中位数为 1.43,但极端情况要高得多。Supabase 的完整文件大约是其索引文件的 7,139.3 倍。Made-in-China.com 的完整文件高达 89.89 MB。
| 域名 | llms.txt | llms-full.txt | 比例 |
|---|---|---|---|
| made-in-china.com | 4.49 MB | 89.89 MB | 20.0x |
| sendbird.com | 281.86 KB | 11.99 MB | 42.5x |
| taboola.com | 286.78 KB | 11.73 MB | 40.9x |
| supabase.co | 1.26 KB | 8.98 MB | 7,139.3x |
| neon.tech | 27.44 KB | 5.01 MB | 182.7x |
建议: 只有在网站已经拥有稳定的文档生产流水线、版本管理纪律,并且有明确理由要把大量内容放进单个机器可读文件时,才发布
llms-full.txt。
llms.txt、robots.txt 与 sitemap.xml
llms.txt 不应被视为新的 robots.txt。它们都是根路径级别的机器可读文件,但传达的信息不同。robots.txt 是爬虫偏好和访问控制信号。sitemap.xml 是 URL 发现信号。llms.txt 则是说明和导航信号。
| 信号 | 主要作用 | 典型读取方 | 本研究中的解释 |
|---|---|---|---|
robots.txt | 声明爬虫偏好和路径级限制。 | 搜索爬虫、AI 爬虫、归档爬虫、通用机器人。 | 治理与访问信号。 |
sitemap.xml | 为索引系统列出可发现的 URL。 | 搜索引擎和索引流水线。 | 发现信号。 |
llms.txt | 提供简洁的网站背景、重要链接、文档、API、示例和政策参考。 | LLM 应用、AI 智能体、开发者工具、检索系统。 | 说明和导航信号。 |
建议
对于考虑使用 llms.txt 的网站,这份数据集中的强实现和外部流量证据都指向一个务实模式:
- 在根目录发布
/llms.txt,并确保无需登录、无需执行 JavaScript、无需穿过同意墙,也不会跳转到无关路径即可访问。 - 在可能的情况下,以
text/plain或text/markdown方式提供。 - 先写一段简短的网站说明,然后按产品、文档、API、定价、更新日志、示例、支持、政策和公司资源分组链接。
- 优先使用规范链接,而不是穷举式 URL 列表。
- 避免空的象征性文件;它们最多只能算弱信号。
- 除非有强烈的机器消费场景和可靠的生成流程,否则避免大而无差别的内容倾倒。
- 发布后验证最终 URL、响应正文、内容类型、Markdown 结构、链接数量和文件大小。
团队也应该谨慎设定预期。现有公开实验并不能证明 llms.txt 会独立提升 AI 引荐流量。如果团队想测试业务影响,应该同时跟踪 LLM 引荐、被引用页面、机器人请求、索引新鲜度和内容变化。一个有用的实验是比较匹配页面组,在可能的情况下保持内容更新不变,并区分不同平台的流量,例如 Perplexity、ChatGPT、Gemini、Claude 和 Bing/Copilot。
局限性
这是一份基于抓取的快照,而不是永久事实。网站可以随时添加、删除或修改 llms.txt 文件。一些域名可能会阻止自动请求,或者因地理位置、TLS 配置、重定向逻辑、用户代理或机器人缓解机制而表现不同。本研究只测试了根路径文件,没有搜索子域名或非标准路径。
质量评分和类型划分是研究工具,不是官方合规标签。主题分析基于关键词,应当只作为方向性参考。该研究不能证明任何特定 AI 平台当前是否在生产环境中读取、遵守或使用 llms.txt。
本版本审阅的外部流量证据也有局限。Search Engine Land 的分析更适合被看作谨慎的多站点观察,而不是随机实验。Alimbekov 的结果适合作为透明的网站级案例研究,但它缺少对照组,而且包含总引荐流量显著上升的时期。这些参考有助于界定争议,但并不能把这次抓取变成一项因果流量研究。
文件与可复现性
| 文件 | 用途 |
|---|---|
crawl_llms_txt.py | 用于 /llms.txt 和 /llms-full.txt 的爬虫。 |
analyze_llms_txt.py | 主要采用分析与图表生成。 |
deep_analyze_llms_txt.py | 用于排名十分位、TLD、主题信号、质量评分、类型和双文件行为的二次分析。 |
deep_dive_early_quality.py | 早期采用者分类与实现质量深度分析。 |
data/llms_probe_results_top_10000.csv | 主要抓取结果数据集。 |
data/deep_analysis_top_10000.json | 二次分析摘要。 |
data/deep_early_quality_analysis.json | 早期采用者类别、质量队列对比、类型细节和案例研究。 |
来源
- ,Jeremy Howard,2024。
- 。
- 。
- 。
- ,Data Provenance Initiative。
- 。
- ,Search Engine Land,2026 年 1 月。
- ,Rankability,2025 年 6 月。
- ,Renat Alimbekov。
如需更正方法、数据集问题或后续分析,欢迎联系 support@thunderbit.com。本报告独立发布,不代表 Thunderbit 所持有的任何商业立场。本报告中的数据自成体系。— Thunderbit 研究团队,2026 年 5 月。