

“从网站抓数据到底合不合法?”——这个问题,几乎每周都有人来问我,尤其是做销售、运营、市场的小伙伴。现在,网页爬虫已经成了线索挖掘、竞品分析等业务的标配工具,大家都想要一个明确的答案。但现实比想象中复杂得多。有的法院说抓取公开数据没问题,有的却警告“非法采集”。难怪很多团队都担心一不小心就踩了法律红线。
其实,现在有超过三分之二的企业都在用网页爬虫做数据分析和 AI 项目,甚至有 78% 的电商公司靠网页抓取来定价。但 LinkedIn 和 hiQ Labs 这些案件频频上新闻,合规风险也越来越受关注。那怎么才能既不违法,又能把网页数据的价值挖掘到极致?这篇文章就帮你梳理下相关法律框架、合规自查清单和实用建议。当然,也会聊聊 Thunderbit 怎么让合规数据抓取变得更简单。
法律环境解析:网页数据抓取到底合不合法?
网页爬虫法律影响 深入了解网页爬虫的法律风险及合规建议。 Get Started Free
直接说重点:网页数据抓取合不合法,关键看你抓什么、怎么抓、你在哪个国家/地区。 目前没有全球统一的法律说“抓取数据就是合法”或者“抓取数据就是违法”。你面对的是一套很复杂的规则体系——包括反黑客法、隐私法规、版权保护,甚至网站自己的服务条款(Thunderbit 博客)。
下面这几个因素,直接决定你的爬虫项目合不合规:
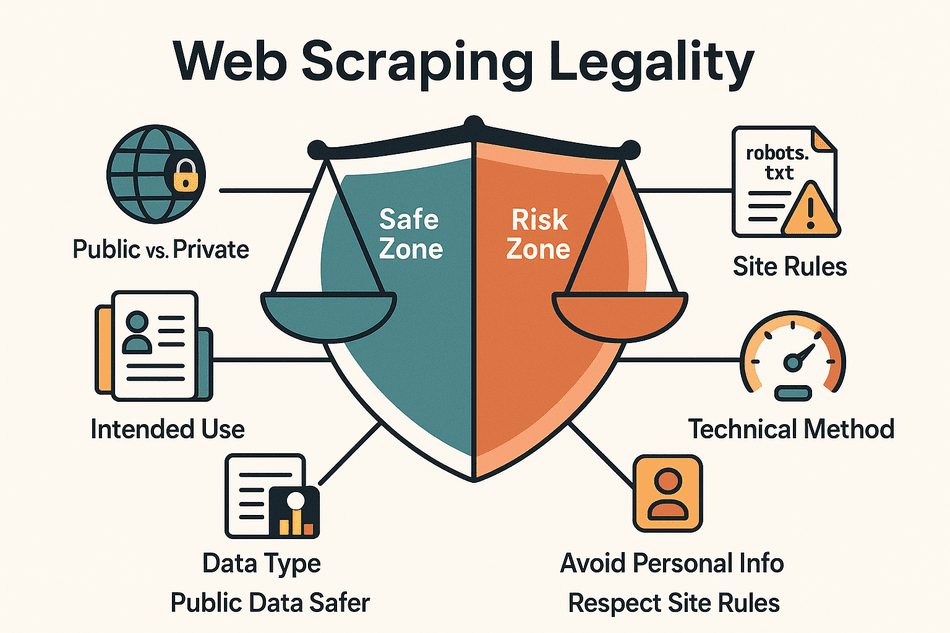
- 公开数据 vs. 私有数据: 抓取不需要登录、没有付费墙的公开数据,风险一般比较低。如果你要访问需要登录的内容,那基本就是高风险甚至违法了。
- 数据类型: 涉及个人信息(比如姓名、邮箱、社交账号)或受版权保护的内容(文章、图片)风险高,抓取事实性信息(比如价格、产品参数、企业名录)相对安全。
- 用途: 只在公司内部分析或研究用,风险远低于对外发布或销售。
- 遵守网站规则: 如果你违反了网站的服务条款或者无视 robots.txt 文件,即使抓的是公开数据,也可能惹麻烦。
- 技术手段: 抓取速度接近人工,不绕过安全措施(比如验证码、IP 限制),更容易站在合规一边。
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
总的来说,抓取公开、非个人数据并且只做内部分析,在很多地方都是被接受的,但还是要注意隐私、版权和抓取频率等问题(Thunderbit 博客)。
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
总的来说,抓取公开、非个人数据并且只做内部分析,在很多地方都是被接受的,但还是要注意隐私、版权和抓取频率等问题(Thunderbit 博客)。
数据抓取的法律框架:全球主要法规速览
 来看看全球主要地区对网页爬虫的法律怎么说:
来看看全球主要地区对网页爬虫的法律怎么说:
美国:CFAA、版权和合同法
- 计算机欺诈与滥用法(CFAA): 这个反黑客法禁止“未经授权”访问计算机系统。但法院已经明确,抓取公开网站内容不算违反 CFAA,因为不需要授权(California Lawyers Association)。
- 典型案例: 在 hiQ Labs v. LinkedIn 案里,法院判定抓取 LinkedIn 公开资料不违反 CFAA。但 LinkedIn 还是可以用违反服务条款或侵犯版权来起诉。
- 其他风险: 如果抓取太频繁(比如 eBay v. Bidder’s Edge 案里机器人每天请求 10 万次),可能被认定为“非法侵占服务器资源”(Wikipedia)。
欧盟:GDPR 和数据库权利
- GDPR: 欧盟的《通用数据保护条例》对公开的个人数据同样适用。抓取能识别个人身份的信息,必须有合法依据(比如同意或合法利益),还要严格遵守隐私规定。
- 数据库指令: 欧盟还保护数据库整体结构。抓取“实质性部分”结构化数据库(比如房产网站所有房源)可能侵犯数据库权利,即使单个数据不受版权保护(Thunderbit 博客)。
英国:UK GDPR 和数据保护法
- UK GDPR: 脱欧后,英国的规则和欧盟差不多。抓取公开、非个人数据一般没问题,但涉及个人信息就要严格监管。
- 计算机滥用法: 类似 CFAA,未经授权访问可能构成刑事犯罪。
中国:个人信息保护法和数据安全法
- 个人信息保护法(PIPL): 收集个人信息必须获得同意。未经许可抓取中国网站的个人数据属于严重违规。
- 数据安全法: 针对损害数据权利人或不正当竞争的数据抓取行为进行打击。
其他地区
- 加拿大、澳大利亚、亚太地区: 大多数国家有类似欧盟/英国的反黑客和隐私法规。一定要提前了解本地法律。
核心建议: 最保险的做法就是只抓取公开、非个人数据做内部分析,并且随时核查本地法规(Thunderbit 博客)。
合规检查清单:怎么确保你的数据抓取合法?
动手抓取前,记得先做这几步自查:
- 看清网站服务条款: 如果 ToS 明确禁止抓取,建议别动手,或者先拿到许可(Thunderbit 博客)。
- 只抓取公开数据: 不要抓取需要登录或付费才能访问的内容,除非有明确授权。
- 检查 robots.txt: 访问
site.com/robots.txt,看看哪些区域禁止爬虫。虽然不是法律强制,但业界都默认要遵守。 - 避免抓取个人信息: 没有合法依据和隐私保护措施,别采集姓名、邮箱等个人数据。
- 不要复制创意内容: 只抓取事实性数据。转载文章、图片或大段内容很容易惹上版权纠纷。
- 优先用官方 API: 如果网站有 API,优先用,通常更安全、稳定。
- 温和抓取: 避免高频请求,模拟人工操作速度,不要绕过技术防护。
- 记录操作过程: 保留抓取内容、时间和用途的记录,方便后续追溯。
- 随时准备停止: 收到禁止函时,立刻暂停并重新评估项目。
Thunderbit 合规抓取实践:让数据采集更安全靠谱
我们在做 Thunderbit 的时候,合规性是第一位的。Thunderbit 怎么帮你规避法律风险?
- 基于浏览器的抓取: Thunderbit 只抓你在浏览器里能看到的内容——不会调隐藏 API,也不会破解登录。如果你看不到,Thunderbit 也抓不到(Thunderbit 博客)。
- 内置风险提示: 遇到反爬虫严格的网站,Thunderbit 会自动弹窗警告,相当于有合规专家帮你把关。
- AI 字段推荐: Thunderbit 的 AI 会智能识别页面,只推荐相关字段,帮你避开敏感或无关数据(Thunderbit 博客)。
- 模拟人工速度: 不管本地还是云端抓取,Thunderbit 都会自动控制频率,避免给目标网站带来压力。
- 数据不存储在服务器: 你的数据直接导出,Thunderbit 不会留副本,隐私合规更有保障。
- 合规导出选项: 可以直接导出到 Google Sheets、Excel、Airtable 或 Notion,方便内部分析。
- 子页面与分页处理: Thunderbit 像真人一样点击页面和子页面,不暴力破解接口。
- 定时抓取有节制: 支持定时任务,但默认间隔合理,避免频繁请求。
- 多语言支持: Thunderbit 支持 34 种语言,全球用户都能轻松获取合规指引。
简单来说,Thunderbit 把合规性“写进”了产品里,就算你不是法律专家,也能放心合规抓数据(Thunderbit 博客)。
数据抓取 vs. 数据再利用:法律边界在哪?
 抓取数据做内部分析是一回事,把数据对外发布、转卖或再利用又是另一回事。法律风险的分界线就在这里:
抓取数据做内部分析是一回事,把数据对外发布、转卖或再利用又是另一回事。法律风险的分界线就在这里:
- 内部使用: 只做内部分析(比如销售线索、价格监控)一般比较安全——前提是不涉及个人信息或违反隐私法规。
- 再分发或转售: 把抓取的数据对外发布(比如放在自己网站、产品里或直接卖掉)可能会引发版权、数据库权利或合同纠纷。
- 版权和数据库权利: 在美国,事实本身不受版权保护,但数据的选择和编排可能受保护。在欧盟/英国,抓取数据库“实质性部分”可能侵犯数据库专有权。
- 合理使用: 美国法律在特定情况下允许“合理使用”(比如评论、分析),但大规模复制内容基本不算合理使用。
- 署名引用: 公开用抓取数据时要注明来源,但光署名并不能规避其他法律风险。
- 避免卖原始数据: 直接卖未经处理的抓取数据风险极高。建议用数据生成洞察,而不是把原始数据当产品卖。
实用建议: 抓取数据主要用来做内部决策和分析。如果要对外分享,建议做聚合或转换,并提前确认是否需要授权(Thunderbit 博客)。
行业案例分析:怎么规避法律风险
来看看真实案例——从别人的经历里学合规:
LinkedIn vs. hiQ Labs
- 案例回顾: hiQ Labs 抓取 LinkedIn 公开资料,用来分析员工流失。LinkedIn 尝试封禁,但法院判定抓取公开数据不违反 CFAA。
- 启示: 在美国,抓取公开数据有法律依据,但还是要注意服务条款和隐私风险(California Lawyers Association)。
eBay vs. Bidder’s Edge
- 案例回顾: Bidder’s Edge 大规模抓取 eBay 拍卖数据(每天 10 万次请求),违反了 eBay 的服务条款和 robots.txt。法院判定其“非法侵占服务器资源”。
- 启示: 就算抓的是公开数据,频率太高或违反网站规则,也可能违法(Wikipedia)。
Facebook(Meta)vs. Power Ventures
- 案例回顾: Power Ventures 在获得用户同意后抓取 Facebook 数据,但被 Facebook 撤销授权并封禁 IP 后还继续抓。法院认定其为“未经授权访问”。
- 启示: 网站方要求停止抓取时,必须立刻停手,否则可能违反反黑客法。
合规成功案例
很多欧洲比价网站通过只抓取事实数据、尊重网站拒绝、避免抓取整个数据库等方式,合法合规地运营。没有被起诉,说明遵守公开、非个人数据和网站规则是可行的路子。
Thunderbit 如何助力
Thunderbit 的风险提示、频率限制和基于浏览器的抓取方式,能有效帮用户规避这些法律风险,自动提醒并引导合规操作。
商业场景下数据抓取合规自查清单
下面这份自查表,做爬虫项目时可以直接用:
- 数据是公开的吗?(不需要登录就能访问)
- 网站条款怎么说?(有没有反爬虫条款?)
- 检查过 robots.txt 吗?(目标区域有没有被禁止?)
- 涉及个人信息吗?(如果有,有没有隐私保护方案?)
- 抓取内容量大吗?(避免抓整个数据库)
- 用途是什么?(内部分析更安全,对外发布风险高)
- 抓取方式温和吗?(模拟人工速度,没有技术规避)
- 有官方 API 吗?(优先用)
- 如果被要求停止,准备好了吗?(有应对方案)
- 数据怎么存储和保护?(限制访问,保障隐私)
- 有操作记录吗?(方便合规追溯)
如果有任何一项不确定,建议先暂停,进一步确认(Thunderbit 博客)。
Thunderbit 用户合规数据抓取流程示例
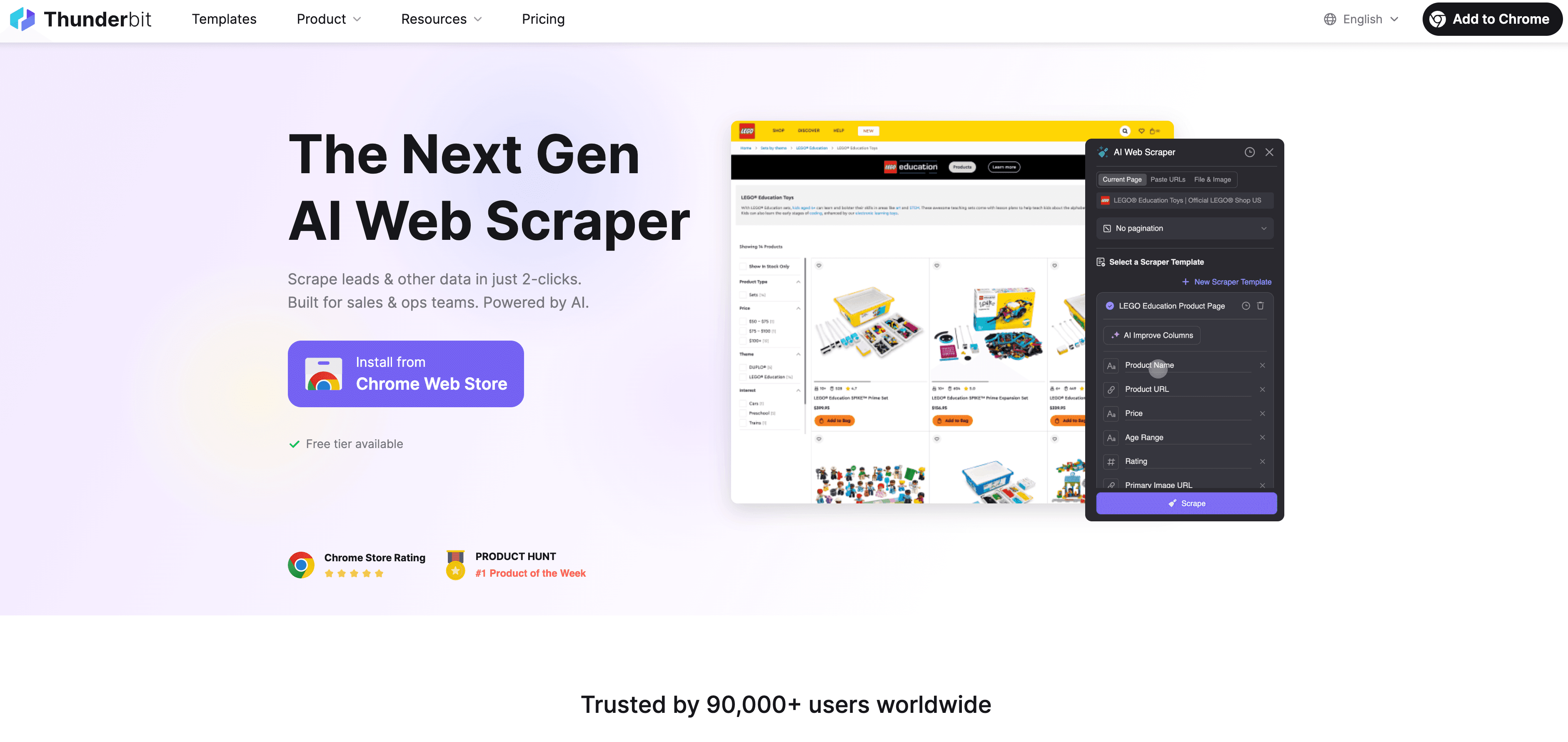 Thunderbit 合规抓取的标准流程如下:
Thunderbit 合规抓取的标准流程如下:
- 抓取前检查: 先看目标网站的 robots.txt 和服务条款,没有反爬虫限制再继续。
- 打开 Thunderbit: 进入目标页面,启动 Thunderbit Chrome 扩展。
- AI 字段推荐: 让 Thunderbit 的 AI 推荐相关且非敏感字段,确保不采集个人信息,除非有合法依据。
- 自定义字段: 根据需要调整列和数据类型,只采集真正需要的信息。
- 开始抓取: 点击“抓取”,Thunderbit 以人工速度提取数据,遵循网站结构。
- 子页面抓取: 需要补充数据时,可以用子页面功能,依然只抓公开信息。
- 导出数据: 直接导出到 Google Sheets、Excel、Airtable 或 Notion,方便内部分析。
- 定时任务(可选): 合理设置定时抓取频率,避免太频繁。
- 记录操作: 保留抓取内容、时间和用途的记录。
Thunderbit 会在每一步自动提醒合规注意事项,帮你全程合规操作。
总结与关键建议:安全合规释放数据价值
网页爬虫是推动业务增长的利器,但绝不是“法外之地”。虽然法律环境很复杂,但核心原则其实很清楚:
- 尽量只抓取公开、非个人数据,并且只做内部分析。
- 每次抓取前都要核查网站条款、robots.txt 和相关法律。
- 如果要抓个人信息或创意内容,必须有合法依据和隐私保护方案。
- 用像 Thunderbit 这样的合规工具,规范操作,降低风险。
- 记录操作流程,如果被要求停止,立刻配合。
把合规当成日常习惯,你就能安全高效地释放网页数据价值,远离法律风险。如果想体验合规爬虫的便捷,不妨试试 Thunderbit。你的法务团队和未来的你都会感谢这个选择。
想了解更多关于网页爬虫、合规和自动化的深度内容,欢迎访问 Thunderbit 博客。
体验 AI 网页爬虫,合规高效采集数据 Get Started Free
常见问题解答
1. 抓取任何网站的数据都合法吗?
并不是所有情况都合法。抓取公开、非个人数据并且只做内部分析,在很多地区一般是合法的。但抓取个人信息、受版权保护内容或登录后数据,风险就很高,甚至违法。抓取前一定要核查网站条款和本地法律(Thunderbit 博客)。
2. 数据抓取和数据再利用有什么区别?
抓取是指收集数据,再利用是指发布、销售或分发这些数据。只做内部用风险较低。对外发布或销售抓取数据,可能会引发版权、数据库权利或合同纠纷(Thunderbit 博客)。
3. Thunderbit 怎么保障合规?
Thunderbit 只抓取浏览器可见内容,自动提示高风险网站,智能推荐相关(非敏感)字段,并控制抓取频率,避免服务器压力。同时不存储你的数据,导出选项也专为内部分析设计(Thunderbit 博客)。
4. 收到禁止函怎么办?
要立刻停止抓取并重新评估项目。收到明确要求后还继续抓,可能就从法律灰色地带变成明确违规了(Thunderbit 博客)。
5. 公开的个人信息可以抓取吗?
没有合法依据不可以。GDPR、CCPA 等隐私法规对公开个人数据同样适用。你需要获得同意或有充分的合法利益,并妥善处理数据(Thunderbit 博客)。
本指南仅供参考,不构成法律建议。如果涉及复杂或高风险项目,建议咨询熟悉本地数据和隐私法规的专业律师。
延伸阅读




