
坦白说,如果你做销售、市场、电商或者运营,肯定听过网页爬虫——甚至你可能已经在用它来找客户、盯竞争对手,或者自动搞定那些枯燥的数据录入。作为一个在 SaaS 和自动化圈子里混了多年的老兵,我可以很负责任地说,网页爬虫已经成了职场标配。事实上,都来自机器人——其中就有大量网页爬虫。但大家最关心的还是:网页爬虫到底合法吗?
答案其实是:要看具体情况。(是不是很像律师的说法?)但别急着关掉页面,因为这里面的门道确实不少。网页爬虫合不合法,得看你在哪、抓什么数据、怎么抓、用来干嘛。下面我就给你拆解清楚,让你用得放心,晚上睡得香。
什么是网页爬虫?给商业用户的通俗解释
网页爬虫其实就是“自动帮你从网站上采集数据”的神器。你可以想象,有个超能实习生帮你逛遍成千上万个网页,把你想要的联系人、价格、商品信息等内容一键搬进表格——这就是网页爬虫的本质。
像 这样的网页爬虫工具(小小自夸一下,我们就是为你们这些商业用户量身打造的),让数据采集变得人人都能上手。你不用写代码,也不用折腾复杂配置。用 Thunderbit,点几下,AI 就能自动识别并推荐可提取的数据。就像有个贴心的数据小助手——而且不用发工资。
你能抓到哪些数据?
- 联系方式(邮箱、电话)
- 商品详情和价格
- 用户评价和评分
- 新闻、招聘、房产等信息
- 图片、PDF 等等
这些数据都能直接导出到 Excel、Google Sheets、Airtable 或 Notion。如果你想更深入了解,欢迎看看我们的。
为什么企业都在用网页爬虫工具?
说真的,没人喜欢手动录数据。(如果你喜欢,欢迎帮我填几张表。)但网页爬虫的价值远不止省时间。现在,企业用网页爬虫工具能搞定很多业务目标:
| 业务目标 | 网页爬虫应用场景 |
|---|---|
| 搭建销售线索库 | 抓取目录或 LinkedIn 上的潜在客户信息(姓名、邮箱、电话),精准获客。 |
| 竞争性定价 | 实时监控竞争对手的价格和库存,灵活调整自家定价策略。 |
| 市场趋势分析 | 收集评论、社交帖子或论坛数据,洞察市场趋势,优化产品决策。 |
| 合规与尽职调查 | 抓取公开记录或黑名单,用于 KYC、风险管理或合规审查。 |
| 内容聚合 | 将多渠道的房产、旅游、招聘等信息集中到一个看板。 |
最棒的是,像 Thunderbit 这样的工具让非技术团队也能几分钟内搭建爬虫。再也不用等 IT 或外包开发帮你拉名单了。
网页爬虫合法吗?简短回答:视情况而定
说实话:**网页爬虫本身不违法,但也不是总是合法。**它就像一把锤子——可以用来盖房子,也能砸玻璃。合不合法,主要看:
- 司法管辖区: 你和目标网站分别在哪个国家?
- 用途: 你是做生意、科研还是个人用?
- 网站条款: 网站的服务条款(ToS)怎么写的?
- 数据类型: 是公开数据、私密数据、受版权保护内容还是个人信息?
来看一张速查表:
| 爬取场景 | 合法性(一般参考) |
|---|---|
| 公开数据(无需登录) | 在美国通常合法,但需注意版权和隐私法规。 |
| 登录或付费墙后的数据(无授权) | 风险极高,通常违法(可能违反反黑客法)。 |
| 无视禁止爬虫的 ToS | 有风险,可能构成违约(民事责任,依然麻烦)。 |
| 抓取并转载受版权保护内容 | 大概率违法,除非获得授权或属于合理使用(如科研)。 |
| 商业用途抓取个人数据 | 受严格监管,尤其在欧盟(GDPR)。 |
| 用爬取数据做垃圾邮件或歧视 | 违法且不道德,坚决不要做。 |
所以,“数据爬取合法吗?”的答案是:**要看具体情况。**下面我给你详细拆解。
影响网页爬虫合法性的关键因素
1. 公开数据 vs. 私密数据
这是最关键的分界线。抓取公开数据(也就是任何人都能直接访问的内容),在美国等地一般比较安全。比如,法院曾判定抓取 LinkedIn 公开资料不算“黑客行为”()。
但如果你抓取登录、付费墙或技术屏障(比如验证码)后的数据,那就属于“未授权访问”,风险极高。就像你只买了普通票,却偷偷溜进了后台。
2. 网站服务条款(ToS)
很多网站在 ToS 里明确禁止爬虫。如果你无视这些条款,尤其是点了“同意”,就可能构成违约。即使你没注册账号,只要条款公开,部分法院也会支持网站方维权。
3. 用途(商业 vs. 个人)
你是自己研究,还是做竞品?商业用途的爬虫更容易被盯上。非商业、学术或新闻用途,尤其是有“公共利益”属性时,通常更宽容。
4. 数据类型(版权、隐私、敏感性)
不是所有数据都一样。抓取事实类数据(比如价格、商品名)通常没问题。抓取受版权保护的文章、图片或个人信息(姓名、邮箱、照片)则可能触发版权或隐私法规,尤其是在欧盟。
5. 技术手段
如果你模拟正常用户访问,温和抓取,风险较低。但如果你高频请求、绕过安全措施,就可能被指控“非法侵入”或违反反规避法律。
公开数据 vs. 受限数据:怎么区分?
简单来说:
- 公开数据: 任何人无需登录、付费或特殊操作就能看到的内容,比如公开招聘、商品页、政府数据库。
- 受限数据: 需要登录、付费或技术手段才能访问的内容。只要需要密码,就是受限数据。
举例:
- 抓取公开房产信息?一般没问题。
- 抓取会员专属目录或私密 Facebook 群组?风险极高。
法院对此区分很明确。hiQ v. LinkedIn 案件中,抓取公开资料被判合法,但抓取登录后数据则不被允许()。
网站服务条款:爬取前一定要看
我知道没人爱看“用户协议”,但 ToS 可能决定你的爬虫项目能不能顺利推进。很多网站明确禁止爬虫或自动化访问。如果你违反这些条款,可能会遇到:
- 账号被封或 IP 被拉黑
- 收到律师函
- 被起诉违约
实用建议:
- 查找“禁止爬虫”或“禁止自动访问”条款
- 如果网站有 API,优先用 API,通常更合规
- 不确定时,主动发邮件申请授权,有时候一句礼貌的请求就能搞定
商业用途 vs. 个人用途:目的真的重要吗?
当然重要。如果你只是做个人研究或学术用途,通常更宽松(被起诉的风险也低)。法院和监管机构对“公共利益”或非商业用途的爬虫更宽容。
但如果你是为了盈利,比如做竞品或转售数据,被追责的概率会大大增加。毕竟,没有公司愿意让竞争对手搭自己便车。
总结:
- 商业爬虫 = 风险更高
- 个人/学术爬虫 = 风险较低,但不是完全免责
国际视角:各国网页爬虫法律差异
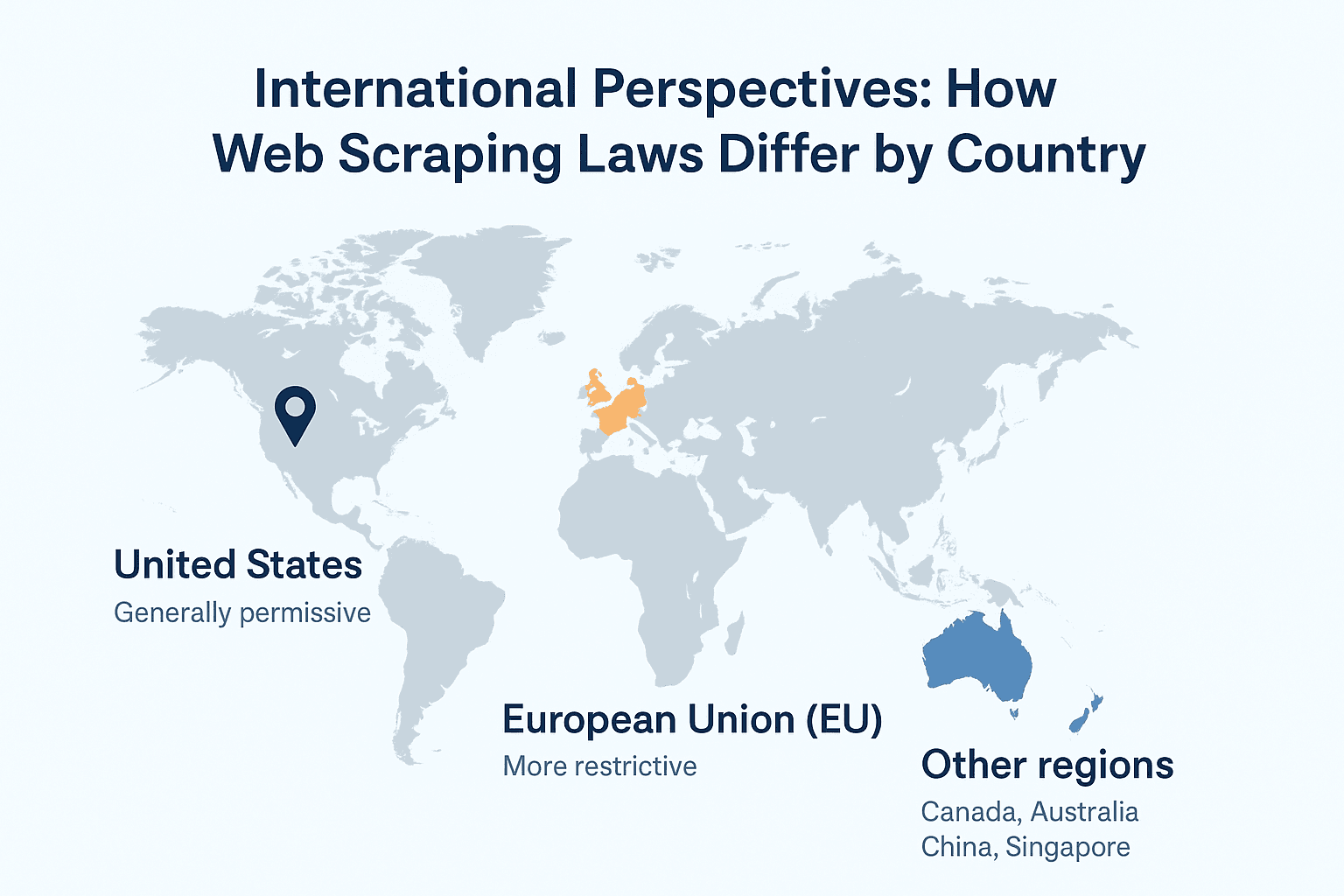
这里就更复杂了。不同国家对网页爬虫的法律规定差异很大。
美国
- 对公开数据的爬取总体较宽松
- 绕过登录或技术屏障会触发反黑客法(CFAA)
- 隐私法规不统一,需关注各州法律(如伊利诺伊州生物识别法)
欧盟
- 对个人数据管理极为严格
- 规定,即使是公开的个人数据也属于“处理”,通常需要合法依据(如同意)
- 数据库权利也可能限制大规模结构化数据的爬取
其他地区
- 加拿大、澳大利亚:个人数据受隐私法保护
- 亚洲:差异较大,日本较开放,中国非常严格,新加坡对大规模未授权爬虫有刑事处罚
**如果你要跨国抓取数据,务必咨询当地法律专家。**尤其在欧盟,违规代价极高。
合规与道德:如何合法使用网页爬虫工具?
想避免麻烦?这里有一份合规爬虫清单:
- 阅读 ToS: 爬取前务必查阅网站规则
- 只抓取公开数据: 需要登录的内容要三思
- 控制抓取频率: 模拟正常用户访问,避免高频请求
- 避免收集个人数据: 没有同意时尤其要注意。如必须收集,尽量匿名化、汇总处理
- 不要原样发布或出售爬取数据: 增加价值、加工处理或获得授权
- 优先使用官方 API: 这是最合规的方式
- 保留操作记录: 以备后续合规审查
- 关注法规变化: 法律在不断更新,及时了解新规和判例
- 大规模或敏感项目请咨询律师: 尤其是涉及受监管行业
最重要的是:**要有道德底线。**能做不代表应该做。
Thunderbit 如何助力合规爬虫?

在 ,我们开发的 始终把合规和道德放在第一位。我们怎么帮你合法合规地用爬虫:
- 专注公开数据: Thunderbit 只抓取你在浏览器里能看到的内容,不会破解登录或绕过权限
- 用户提醒: 我们会提醒你注意 ToS,避免抓取受限或个人数据。如果你试图抓取规则严格的网站,会收到预警
- 模拟人工抓取: Thunderbit 在浏览器端运行,抓取速度自然,降低被封号或被指控“攻击服务器”的风险
- 自定义设置: 你可以灵活选择抓取内容、频率和导出方式,方便数据最小化和透明管理
- 隐私与安全: 你的数据只属于你自己,我们不会存储或二次利用
- 合规模板: 针对热门网站的模板已预设合规规则和最佳实践
- 持续教育: 我们定期发布,让你随时掌握最新动态
我们不是律师,但会尽力为你提供合规建议。如果遇到大规模或敏感项目,建议一定要咨询专业法律人士。
总结:商业用户必知要点
回顾一下:
- 网页爬虫本身不违法,但也不是总是合法。 合法与否取决于你的位置、抓取内容、操作方式和用途
- 抓取公开数据通常被允许, 尤其在美国,但要遵守版权、隐私和网站条款
- 商业用途风险更高, 个人或学术用途风险较低
- 各国法律差异大, 尤其欧盟对个人数据极为严格
- 合规操作很重要: 阅读 ToS、只抓取公开数据、控制频率、避免个人或敏感数据
- Thunderbit 致力于合规爬虫, 提供合规功能和指引
一句话总结:理性爬取、合规操作,遇到疑问及时咨询。 合理用好网页爬虫,能让你的业务如虎添翼,无需担心法律风险。
想了解更多关于网页爬虫、合规和自动化的内容?欢迎访问我们的 ,或者直接体验 。准备好了吗?快来安装我们的 ,体验高效、合规的数据采集,无需担心法律风险。
常见问题:网页爬虫与合法性
-
抓取公开网站合法吗?
有时候可以。公开≠免费。美国通常允许抓取公开数据,但要查阅网站服务条款,避免个人数据,不要转载受版权保护内容。
-
最大法律风险是什么?
抓取私密数据、无视ToS、或在未获同意情况下将个人信息用于商业,尤其是在欧盟 GDPR 下。
-
可以抓取 LinkedIn 或 Amazon 吗?
视情况而定。LinkedIn 抓取在法院(hiQ 案)中被认可,但平台依然会封禁。Amazon 允许部分数据被抓取,但对机器人有限制。务必查阅 ToS。
-
Thunderbit 如何助力合规?
Thunderbit:
- 只抓取可见、公开数据
- 浏览器端运行(非服务器端机器人)
- 提醒 ToS 风险
- 数据只属于你本人