
互联网的发展速度真的让人惊叹。到了 2024 年,全球网站数量已经超过了11 亿个,数据总量更是高达149 ZB(泽字节),预计明年还会突破 181 ZB。信息量大到什么程度?就连全世界的披萨菜单都数不过来。但有趣的是,只有大约4% 的网页内容被搜索引擎收录。剩下的内容都藏在“深网”里,普通搜索根本找不到。那么,搜索引擎和企业到底是怎么在这片数字丛林里找到有用信息的?这就要靠网页爬虫了。
这篇指南会带你全面了解网页爬虫是什么、它是怎么工作的,以及为什么它不仅对技术人员有用,对任何想用网络数据的人都非常重要。我们还会讲清楚网页爬虫和网页爬虫(Web Scraper)到底有什么区别(别小看这个差别),结合实际案例,带你了解代码和无代码两种解决方案(我最推荐的就是 Thunderbit)。不管你是刚入门的小白,还是想高效利用网络数据的企业用户,这里都能找到答案。
什么是网页爬虫?快速了解 Web Crawling 基础
先从最基础的说起。网页爬虫(有时也叫蜘蛛、机器人、网站爬虫)其实就是一种自动化程序,能系统地浏览网页,抓取页面内容并跟踪链接,发现更多新内容。你可以把它想象成一个机器人图书管理员,手里拿着一份书单(URL),一本本地看,然后根据书里的参考文献继续找新书。爬虫的工作方式就是这样——只不过它抓的是网页,不是书,图书馆也变成了整个互联网。
核心流程其实很简单:
- 从一组 URL(种子)开始
- 访问每个页面,下载内容(HTML、图片等)
- 查找页面上的超链接,把新链接加入队列
- 循环往复——访问新链接,发现更多页面
网页爬虫的主要任务就是发现和整理网页。对于搜索引擎来说,爬虫会复制页面内容,回传给服务器做索引和分析。在其他场景下,专用爬虫还能提取特定数据(这就是网页爬虫的用武之地,后面会详细讲)。
一句话总结:
网页爬虫的本质是发现和绘制网络地图,而不仅仅是抓数据。它是 Google、Bing 等搜索引擎了解互联网内容的基础。
搜索引擎如何运作?爬虫的作用
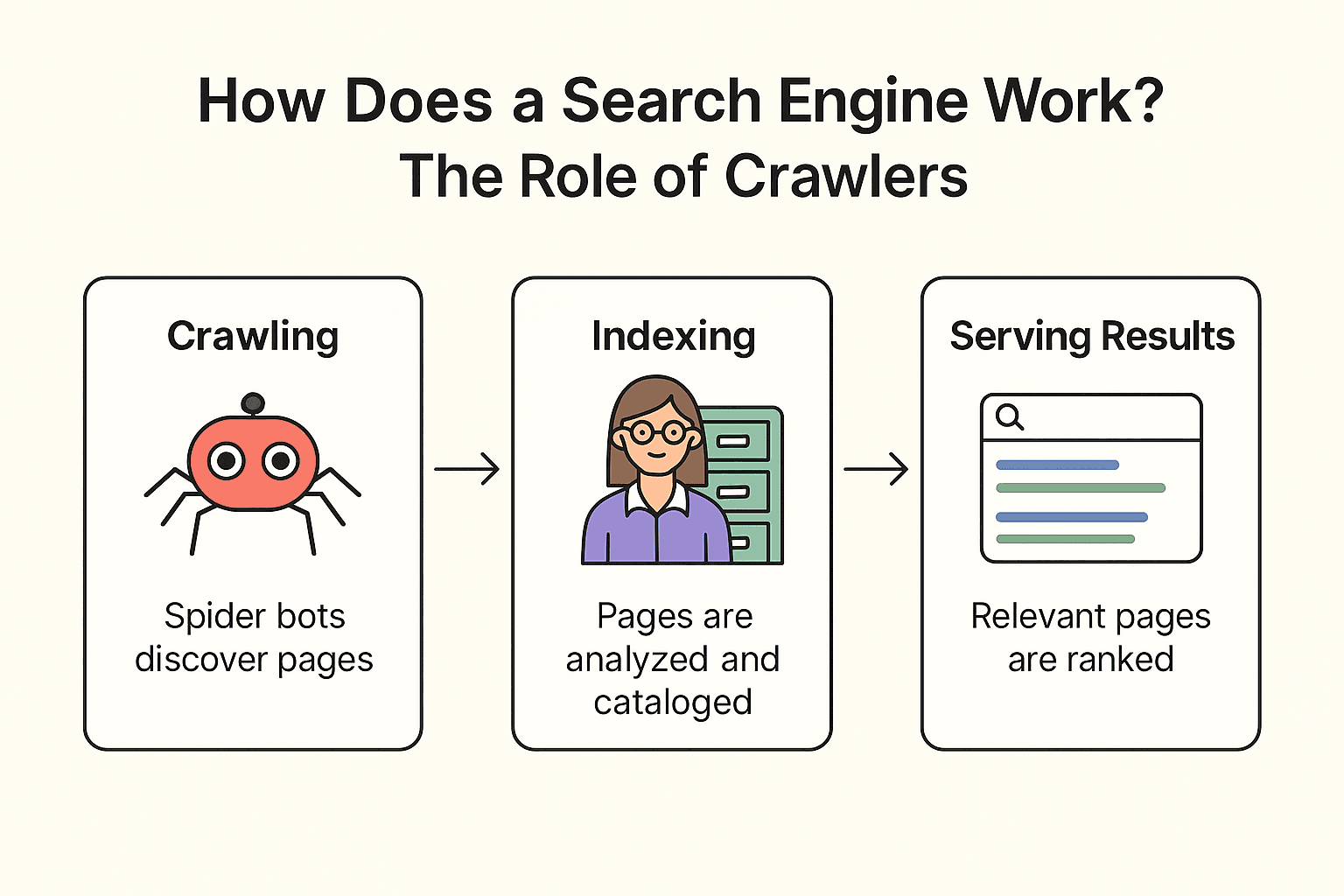
那 Google(或者 Bing、DuckDuckGo)到底是怎么工作的?其实分三步:爬取、索引、展示结果(Google 官方文档)。
还是用图书馆的比喻:
-
爬取:
搜索引擎会派出“蜘蛛机器人”(比如 Googlebot)在网络上探索。它们从已知页面出发,抓取内容,并跟踪链接发现新页面——就像图书管理员查阅每个书架,并根据脚注找到更多书。
-
索引:
找到页面后,搜索引擎会分析内容,判断主题,并把关键信息存进庞大的数字卡片库(索引)。不是所有页面都能被收录——被屏蔽、质量低或重复的页面会被跳过。
-
展示结果:
当你搜索“附近最好吃的披萨”,搜索引擎会从索引中查找相关页面,并根据数百个因素(比如关键词、热度、新鲜度)进行排序,最后给你一份有序的网页列表。
小知识:
搜索引擎其实不会抓取所有网页。登录后才能访问的页面、被 robots.txt 屏蔽的内容、没有外部链接的页面,可能永远不会被发现。这也是为什么很多企业会主动向 Google 提交网址或站点地图。
网页爬虫 vs. 网页爬虫(Web Scraper):有什么区别?
这里很多人会搞混。很多人把“网页爬虫”和“网页爬虫(Web Scraper)”当成一回事,其实两者差别很大。
| 方面 | 网页爬虫(Spidering) | 网页爬虫(Web Scraping) |
|---|---|---|
| 目标 | 尽可能发现和索引更多页面 | 从一个或多个网页提取特定数据 |
| 比喻 | 图书管理员为图书馆建目录 | 学生从几本相关书籍抄重点笔记 |
| 输出 | URL 列表或页面内容(用于索引) | 结构化数据集(CSV、Excel、JSON)含目标信息 |
| 典型用户 | 搜索引擎、SEO 审核、网页归档 | 销售、市场、调研等业务团队 |
| 规模 | 超大(百万/十亿级页面) | 有针对性(几十、几百或几千页面) |
简单来说:
- 网页爬虫 关注发现页面(绘制网络地图)
- 网页爬虫(Web Scraper) 关注提取你想要的数据(导出到表格)
大多数企业用户(尤其是销售、电商、市场部门)其实更关心数据抓取——获取结构化数据用于分析,而不是爬遍全网。爬虫适合搜索引擎和大规模发现,爬虫(Web Scraper)则专注于定向数据提取。
为什么要用网页爬虫?企业真实应用场景
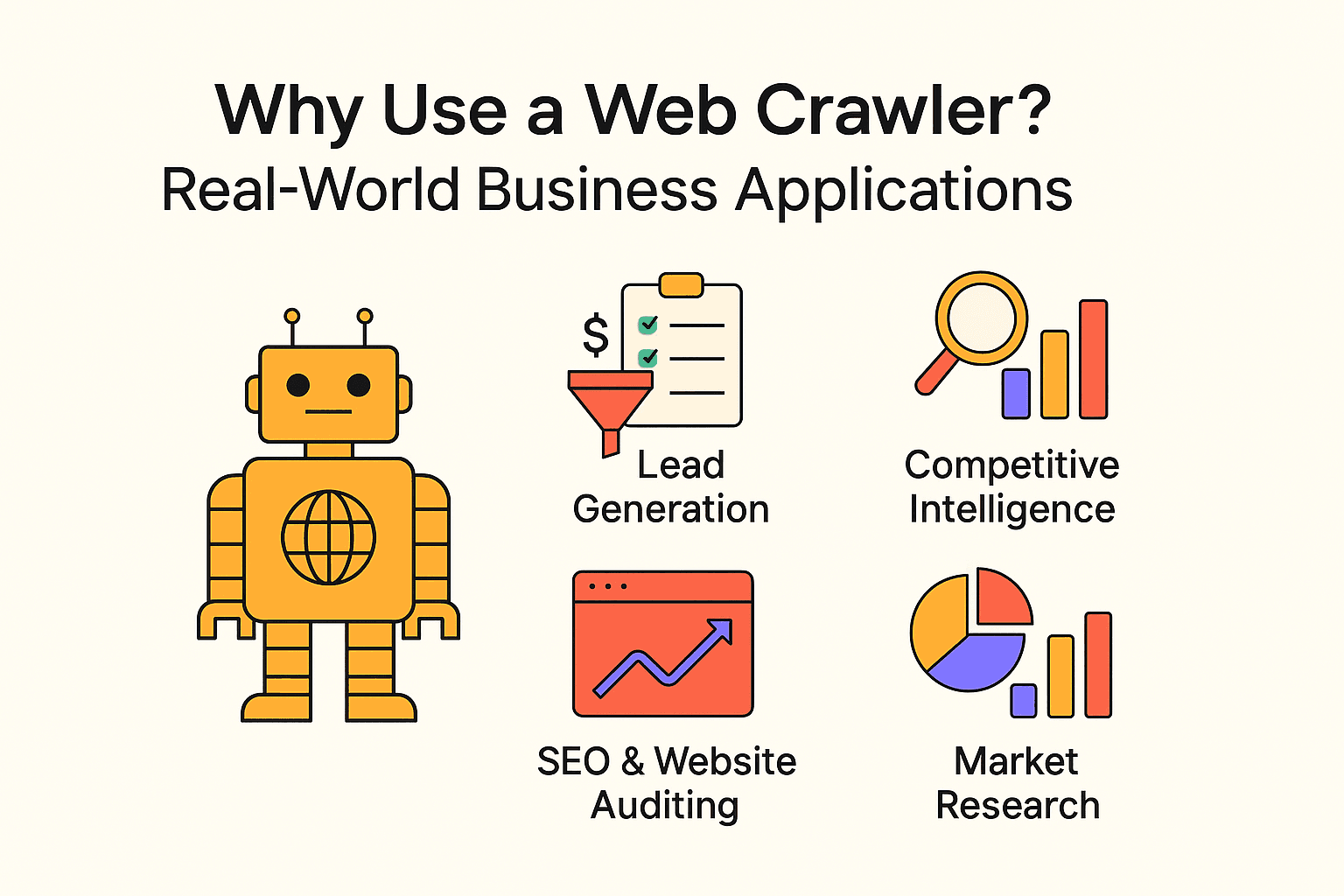
网页爬虫可不是搜索引擎的专利。各种企业都在用爬虫和爬虫(Web Scraper)来挖掘价值、自动化繁琐任务。常见应用包括:
| 应用场景 | 目标用户 | 预期收益 |
|---|---|---|
| 线索挖掘 | 销售团队 | 自动化获客,CRM 持续补充新线索 |
| 竞品情报 | 零售、电商 | 监控竞品价格、库存、产品变动 |
| SEO & 网站体检 | 市场、SEO 团队 | 查找死链,优化网站结构 |
| 内容聚合 | 媒体、调研、HR | 汇总新闻、招聘、公开数据集 |
| 市场调研 | 分析师、产品团队 | 大规模分析评论、趋势或情感 |
- Groupon 通过自动化线索挖掘让入站线索翻倍。
- 82% 的电商企业和71% 的金融服务公司都依赖网页爬虫辅助决策。
- 网页爬虫能让数据采集基础设施成本降低 90%,用时减少 60%。
一句话总结:如果你还没用上网络数据,你的竞争对手很可能已经在用了。
用 Python 编写网页爬虫:你需要知道什么?
如果你有编程基础,Python 是自定义网页爬虫的首选语言。基本流程如下:
- 用 requests 获取网页内容
- 用 BeautifulSoup 解析 HTML,提取链接和数据
- 用循环(或递归)跟踪链接,继续爬取新页面
优点:
- 灵活度高,完全可控
- 能处理复杂逻辑、自定义数据流、对接数据库
缺点:
- 需要编程能力
- 网站结构一变,脚本就容易失效,维护成本高
- 反爬机制、延迟、异常处理都要自己搞定
新手友好的 Python 爬虫示例:
下面是一个抓取 quotes.toscrape.com 上名言和作者的小脚本:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
如果要爬多页,只需要加上查找“下一页”按钮的逻辑,循环直到没有新页面。
常见坑点:
- 忽略 robots.txt 或爬取间隔(别做那个不讲规矩的人)
- 被反爬机制封禁
- 不小心陷入无限循环(比如日历页面永远翻不完)
手把手:用 Python 搭建简单网页爬虫
如果你想亲自试试,下面是基础爬虫的搭建流程。
步骤 1:环境准备
确保已经安装 Python,然后安装所需库:
pip install requests beautifulsoup4
遇到问题时,检查 Python 版本(python --version)和 pip 是否可用。
步骤 2:编写核心爬虫逻辑
基本模式如下:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取链接
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
小贴士:
- 限制爬取深度,避免无限循环
- 记录已访问 URL,防止重复抓取
- 遵守 robots.txt,请求间隔加上 time.sleep(1)
步骤 3:数据提取与保存
可以将数据写入 CSV 或 JSON 文件:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# 在爬取循环中写入:
writer.writerow([text, author])
也可以用 Python 的 json 模块输出 JSON 格式。
网页爬虫的注意事项与最佳实践
网页爬虫很强大,但“能力越大,责任越大”(还有被封 IP 的风险)。怎么合规、友好地爬取数据?
- 遵守 robots.txt: 一定要查看并尊重网站的 robots.txt 文件,了解哪些内容不能抓取。
- 温和爬取: 请求之间加延迟(至少几秒),别给服务器添麻烦。
- 控制范围: 只爬你需要的内容,设置深度和域名限制。
- 标明身份: 用有描述性的 User-Agent。
- 合法合规: 不要抓取私人或敏感信息,只采集公开数据。
- 讲究道德: 别整站复制,也别用数据做垃圾营销。
- 慢慢测试: 先小规模试爬,没问题再扩大范围。
更多建议可以参考这份最佳实践指南。
什么时候选用网页爬虫(Web Scraper):Thunderbit 为企业用户而生
使用 AI 从任何网站抓取数据 Get Started Free
我的建议很直接:除非你要做搜索引擎或者需要绘制整站结构,大多数企业用户更适合用网页爬虫(Web Scraper)工具。
这正是 Thunderbit 的用武之地。作为联合创始人兼 CEO,我可能有点偏心,但我真心觉得 Thunderbit 是非技术用户提取网页数据最简单的方式。
为什么选 Thunderbit?
- 两步操作: 点“AI 智能识别字段”,再点“抓取”就行。
- AI 驱动: Thunderbit 自动识别页面,推荐最佳提取字段(比如商品名、价格、图片等)。
- 批量 & PDF 支持: 能抓取当前页面、批量 URL,甚至 PDF 文件。
- 多样导出: 支持 CSV/JSON 下载,或者直接同步到 Google Sheets、Airtable、Notion。
- 零代码门槛: 会用浏览器就能用 Thunderbit。
- 子页面抓取: 需要更详细数据?Thunderbit 能自动访问子页面补充信息。
- 定时任务: 用自然语言设置定期抓取(比如“每周一上午 9 点”)。
什么时候该用爬虫?
如果你的目标是绘制整站地图(比如做搜索索引或站点地图),那就需要用爬虫。但如果你只想抓取特定页面的结构化数据(比如商品列表、评论、联系方式),网页爬虫(Web Scraper)更快、更简单、更高效。
总结 & 重点回顾
最后总结一下:
- 网页爬虫 是搜索引擎和大数据项目发现、绘制网络地图的基础,追求广度——尽可能多地发现页面。
- 网页爬虫(Web Scraper) 追求深度——从页面中提取你关心的具体数据。大多数企业用户更需要数据抓取,而不是全网爬取。
- 你可以自己写爬虫(Python 很适合),但需要时间、技术和维护。
- 无代码、AI 驱动的工具(比如 Thunderbit)让数据抓取变得人人可用,无需编程。
- 最佳实践很重要: 始终合规、友好地爬取和抓取,尊重网站规则,合理使用数据。
如果你刚入门,可以先做个小项目——比如抓取商品价格,或者从目录网站收集客户线索。用 Thunderbit 这样的工具快速上手,或者用 Python 深入学习底层原理。
互联网是信息的宝库。只要方法得当,你就能挖掘出有价值的洞察,提升决策效率,节省时间,让企业始终领先一步。
常见问题解答
- 网页爬虫和网页爬虫(Web Scraper)有什么区别?
爬虫负责发现和绘制页面地图,**爬虫(Web Scraper)**则提取具体数据。爬虫=发现,爬虫(Web Scraper)=提取。
- 网页爬虫合法吗?
抓取公开数据一般没问题,只要遵守 robots.txt 和网站服务条款。别抓私人或受版权保护的内容。
- 抓取网页一定要会编程吗?
不需要。像 Thunderbit 这样的工具,点点鼠标、用 AI 就能抓取,无需写代码。
- 为什么 Google 没有收录全部网页?
因为大部分内容都在登录、付费墙后或被屏蔽。实际上只有约 4% 被收录。
延伸阅读
- FreeCodeCamp – 用 Python 和 BeautifulSoup 做网页爬虫
- Scrapy 官方教程
- Real Python – 用 Selenium 和 Python 自动化网页抓取
- Apify Academy:网页爬虫与自动化
试用 AI 网页爬虫 Get Started Free




