
什么是 Amazon 网页爬虫
Amazon 网页爬虫是一种非常实用的工具或软件,能自动从 Amazon.com 获取数据。这些数据可以包括商品详情、价格、评论、库存状态等。使用 Amazon 网页爬虫的核心目的,就是批量收集数据,用于市场调研、价格对比或竞品分析。你也可以抓取用户评论做关键词研究,更全面地了解产品的优缺点。
Amazon 网页爬虫的核心功能
- 自动采集数据:不用再手动复制粘贴,省时又省力。网页爬虫可以自动抓取网页里你需要的信息。
- 可自定义抓取:你可以按自己的需求调整爬虫,只提取指定的数据字段,方便做更精准的分析。
- 数据导出:抓取完成后,可以轻松导出为 Excel、CSV 或 JSON 等常用格式,方便接着用各种数据工具分析。
- 定时更新:设置定时抓取,持续更新 Amazon 商品数据库,确保数据始终是最新的。
- 评论抓取:很多时候,你需要从评论区提取优缺点,用于竞品分析。

为什么要使用 Amazon 网页爬虫
Amazon 是全球电商领域的重要平台,以商品种类丰富、价格有竞争力、购物体验顺畅而出名。它帮助企业触达全球潜在客户,扩大市场覆盖面。消费者也普遍把 Amazon 视为主要的线上购物渠道之一,商家因此能在相对稳定、可信赖的销售环境中开展业务。此外,Amazon 的物流体系还能让企业借助高效配送服务提升客户满意度。平台还提供了多种营销工具,例如赞助商品广告和品牌推广,帮助提升商品曝光和销量。
对电商企业来说,分析 Amazon 上的销售数据非常关键。借助 Amazon 网页爬虫,企业可以收集数据,洞察市场趋势和消费者行为,并进一步优化产品策略和库存管理。这有助于企业在 Amazon 平台上更高效地扩张,提升销量和品牌认知度,实现长期增长。下面介绍如何用 Amazon 网页爬虫进行分析:
市场调研
-
SKU 选品
选对 SKU(库存单位) 对电商成功至关重要,它会影响商品组合、供应链效率和库存管理。借助 Amazon 网页爬虫,你可以从海量商品中提取精准数据,分析销售趋势和客户偏好。比如,抓取 Amazon 商品详情页后,你可以轻松获取商品价格、评论数量、卖家评分等关键信息,用于深入的市场分析。这些数据能帮助判断某个 SKU 是否有市场潜力,并找出哪些产品表现最好。通过比较同类商品,企业可以优化选品,提高热销 SKU 的备货量,减少滞销商品库存,从而提升库存周转率。
-
识别客户趋势
通过抓取大量商品评论、评分和客户反馈,网页爬虫可以帮助你快速识别消费需求的变化。比如,分析评论数据时,你可以找出消费者最看重的产品特性,例如“价格实惠”或“耐用”。这些信息对产品开发、定价策略和营销策略都很重要。此外,抓取购买频率和随时间变化的销售趋势数据,还可以帮助你预测季节性销量波动,并提前安排库存和营销活动。

竞品分析
-
价格监控
在竞争激烈的市场里,价格监控对电商企业来说非常关键。Amazon 网页爬虫可以帮助你抓取实时商品数据,追踪竞争对手的价格变化,确保你的定价始终有竞争力。这项功能在执行动态定价策略时尤其有价值。通过收集相似商品的价格信息,企业可以建立灵活的定价模型,根据市场需求、库存水平和竞品价格自动调整售价,以最大化利润。
-
评论抓取
客户评论 不仅会影响销量,也能反映市场需求的变化。Amazon 网页爬虫可以帮助企业收集大量客户反馈。基于 AI 的网页爬虫还能协助总结内容并进行情感分析,帮助你洞察用户对自家产品和竞品的真实看法,从而及时调整产品设计或营销策略。
成本对比
借助 Amazon 网页爬虫,企业可以收集相似商品的价格、运费和促销信息,做更全面的成本对比。分析这些数据有助于优化成本结构,避免不必要的支出,并提升利润率。对于在 Amazon 上寻找供应商的企业来说,这些数据还能帮助了解不同供应商的运费和销售价格,降低采购成本,保持市场价格竞争力,最终提升毛利率。
试试用 AI 进行网页抓取
试试看!你可以边看边点击、探索并运行整个流程。
为什么要用 AI 抓取 Amazon 商品数据
随着 AI 的快速发展,AI 驱动的 Amazon 网页爬虫正在开启数据抓取的新阶段,也给传统网页抓取带来不少便利。AI 不仅让数据采集更高效、更准确,也大幅降低了技术门槛,为电商企业带来更多创新机会。
对非技术人员更友好
对于没有技术背景的用户来说,AI 支持的 Amazon 网页爬虫特别好上手。不同于传统爬虫需要手写代码和调用 API,用户只要说明抓取需求并选择想要的列名,AI 就会自动生成合适的抓取方案和建议,省去了编程和复杂设置的麻烦。这种友好的使用方式,帮助电商团队在没有专业技术人员的情况下也能高效获取数据,提升团队效率,让非技术人员也能轻松使用先进的数据采集工具。
更快、更高效
使用 AI 从任何网站抓取数据 Get Started Free
AI 网页爬虫 会把整个数据提取流程自动化,大幅提升抓取速度和效率。它们可以快速处理复杂的网站结构和动态内容,精准捕获目标数据,减少人工干预,并提升整体抓取准确率。此外,AI 网页爬虫 还能显著降低运营成本并优化工作流程,让企业以更低成本获得高质量数据,为决策提供更准确的支持。
智能分析与建议
和传统网页爬虫相比,AI 网页爬虫 的优势在于可以实现更智能的工作流自动化。AI 工具可以自动分类数据、总结内容,并提供数据洞察。比如,企业可以利用 AI 将不同商品自动归类到预设类别中,或者分析大量评论数据,提取关键词和情感趋势,帮助更好地理解消费者反馈并优化产品。AI 还能基于抓取到的数据生成个性化报告,自动输出市场分析,帮助企业更快识别热门产品特征和潜在商机。
更智能的输出与导出选项
使用基于 AI 的 Amazon 网页爬虫,可以获得更灵活、更智能的数据输出方式。传统编码方式通常只能导出 CSV 文件,而 AI 工具不仅支持 CSV 格式,还能把抓取结果自动导出到 Google Sheets、Notion 等协作平台,大大方便数据分析和分享。比如,你可以直接把数据导入 Google Sheets 做实时分析,或者同步到团队协作工具中,确保部门之间的信息流转更顺畅。这种智能化的数据导出方式,能帮助团队更快做出决策,提升企业整体的灵活性和响应速度。
使用 Thunderbit 抓取:AI 网页爬虫
Thunderbit 是一款新推出的强大而全面的 AI 驱动网页爬虫工具,旨在满足你的各种数据需求。借助 Thunderbit,用户可以轻松采集 Amazon 上的数据,无论是商品详情、价格变化还是客户评论,都能快速转化为有价值的商业洞察。下面看看 Thunderbit 如何帮助电商企业提升竞争力。
首先,访问 Thunderbit 网站,并将 Thunderbit 网页爬虫扩展 添加到 Chrome 浏览器中。你可以使用 Google 账号或其他邮箱登录。
 接着,你可以使用 Thunderbit 内置的预置网页爬虫或 AI 网页爬虫 来 抓取 Amazon 商品数据和评论。方法如下:
接着,你可以使用 Thunderbit 内置的预置网页爬虫或 AI 网页爬虫 来 抓取 Amazon 商品数据和评论。方法如下:
方案 1:使用 Thunderbit 预置网页爬虫
Thunderbit 根据用户需求设计并优化了多种预置网页爬虫,其中就包括专门针对 Amazon 的爬虫模块。这些工具为 Amazon 复杂的数据结构预先准备好了模板,并且已经收集了大量数据,因此你无需自己设计抓取逻辑,就能更快、更高效地完成采集。
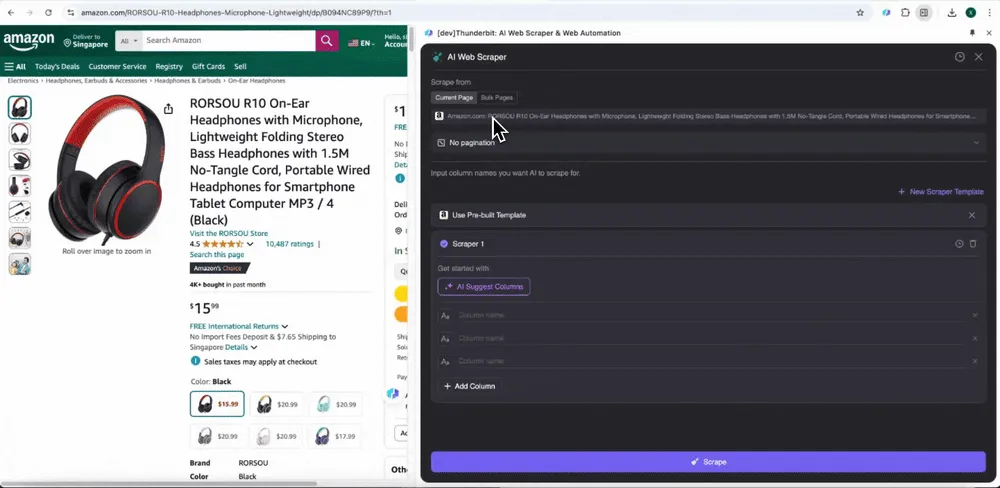
当你打开 Amazon 上的任意页面时,启动 Thunderbit 扩展中的网页爬虫功能。你会看到两个带有丰富列名的预置爬虫,只需勾选你想提取的列名,剩下的交给 Thunderbit 即可。
-
Amazon 采集 SKU 评论
这个工具提供了预置列名,例如商品名称、商品 URL、整体评分、详细评分拆分、评分人数、评论标题、作者名称、评论内容、评论国家和关键词。你只需勾选想要提取的列名,点击抓取,就能快速获得做产品评论分析所需的 SKU 评论数据。
-
Amazon 采集 SKU 详情
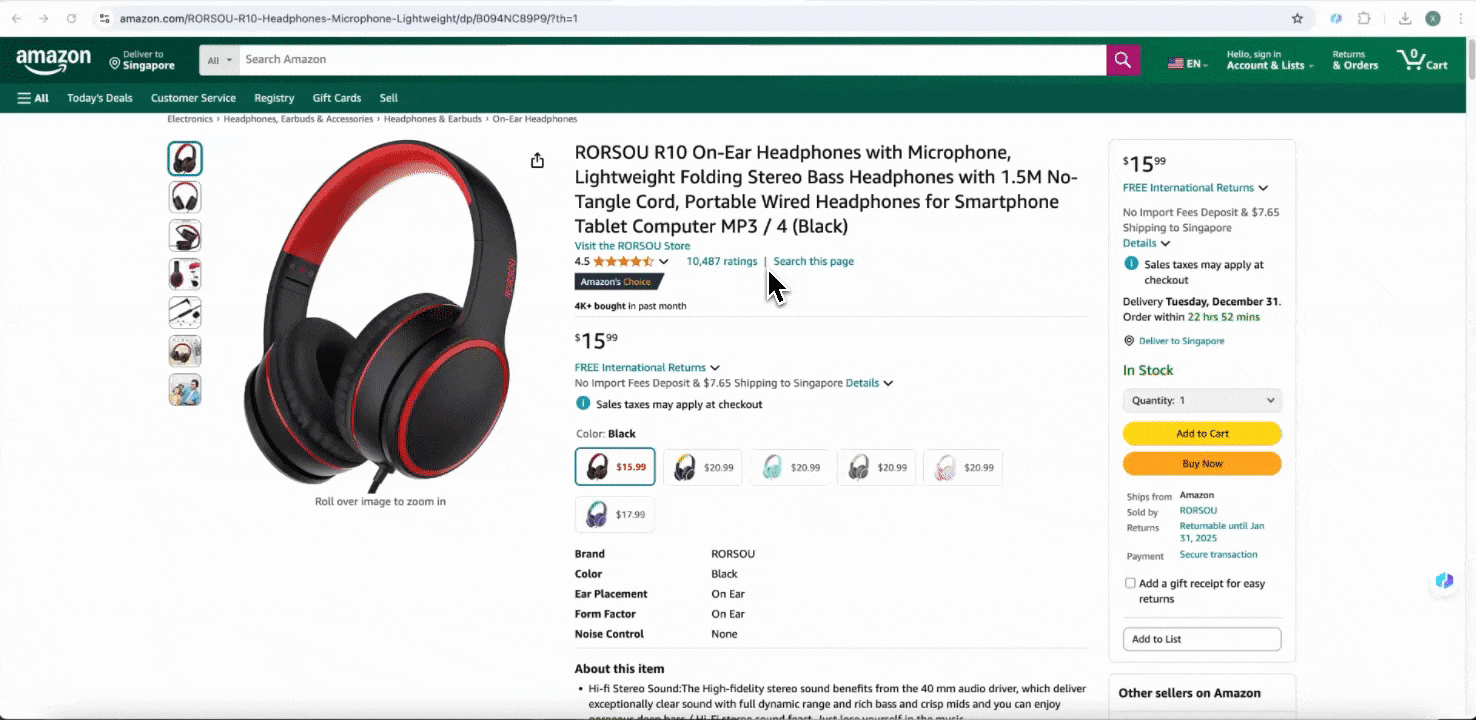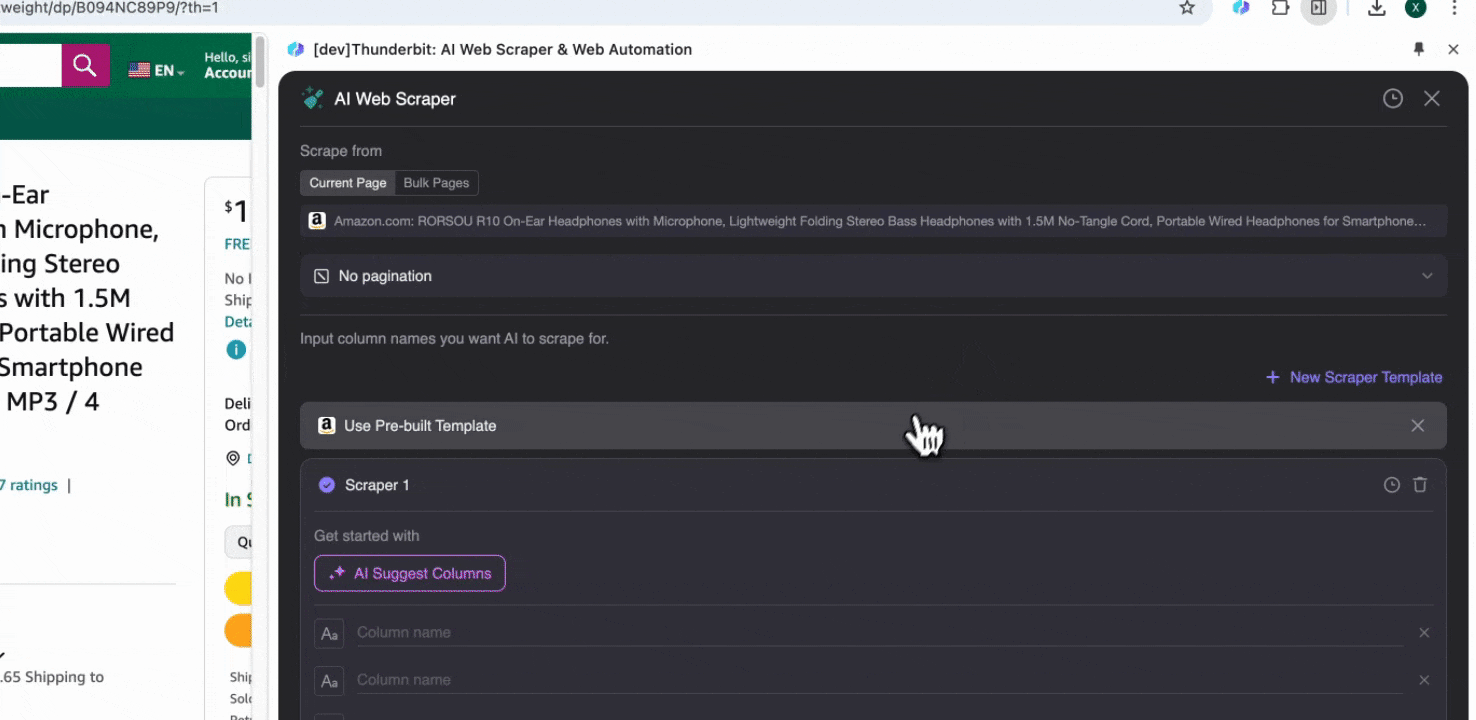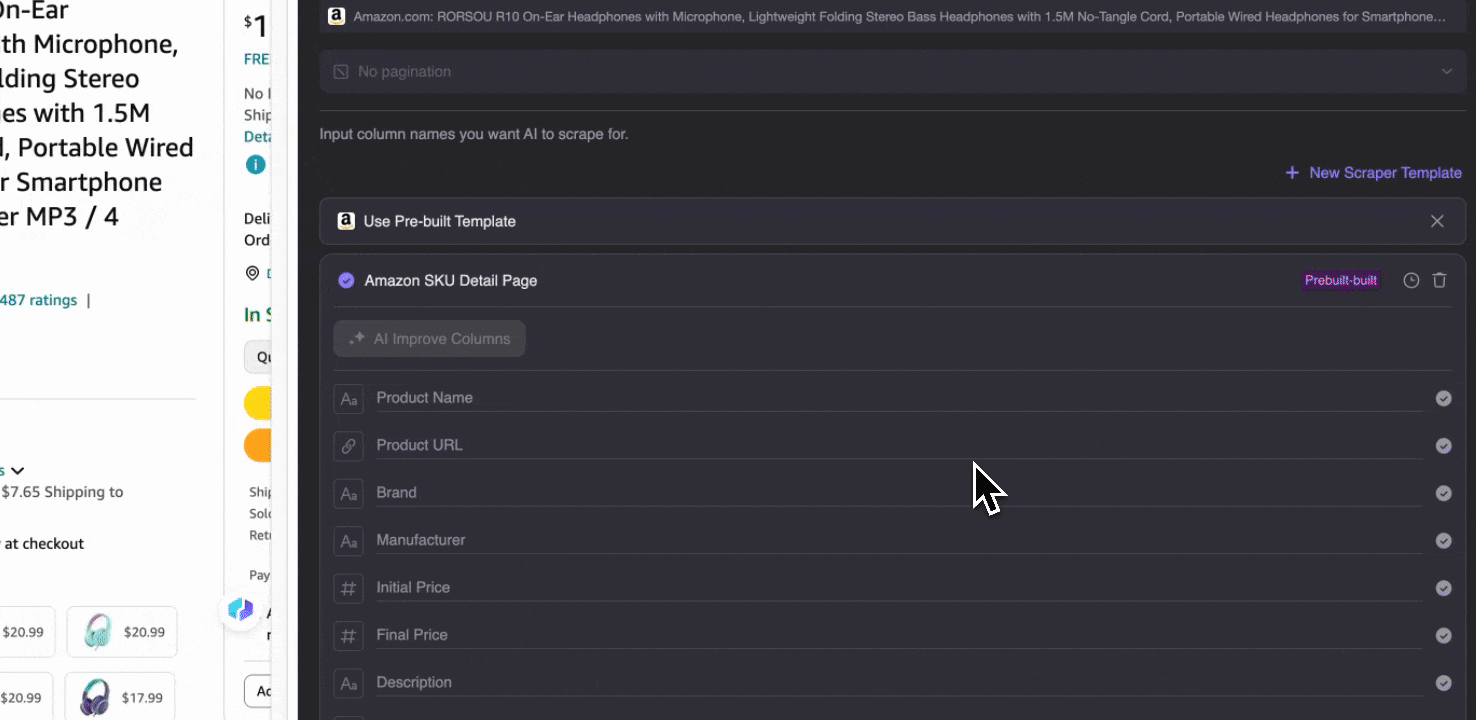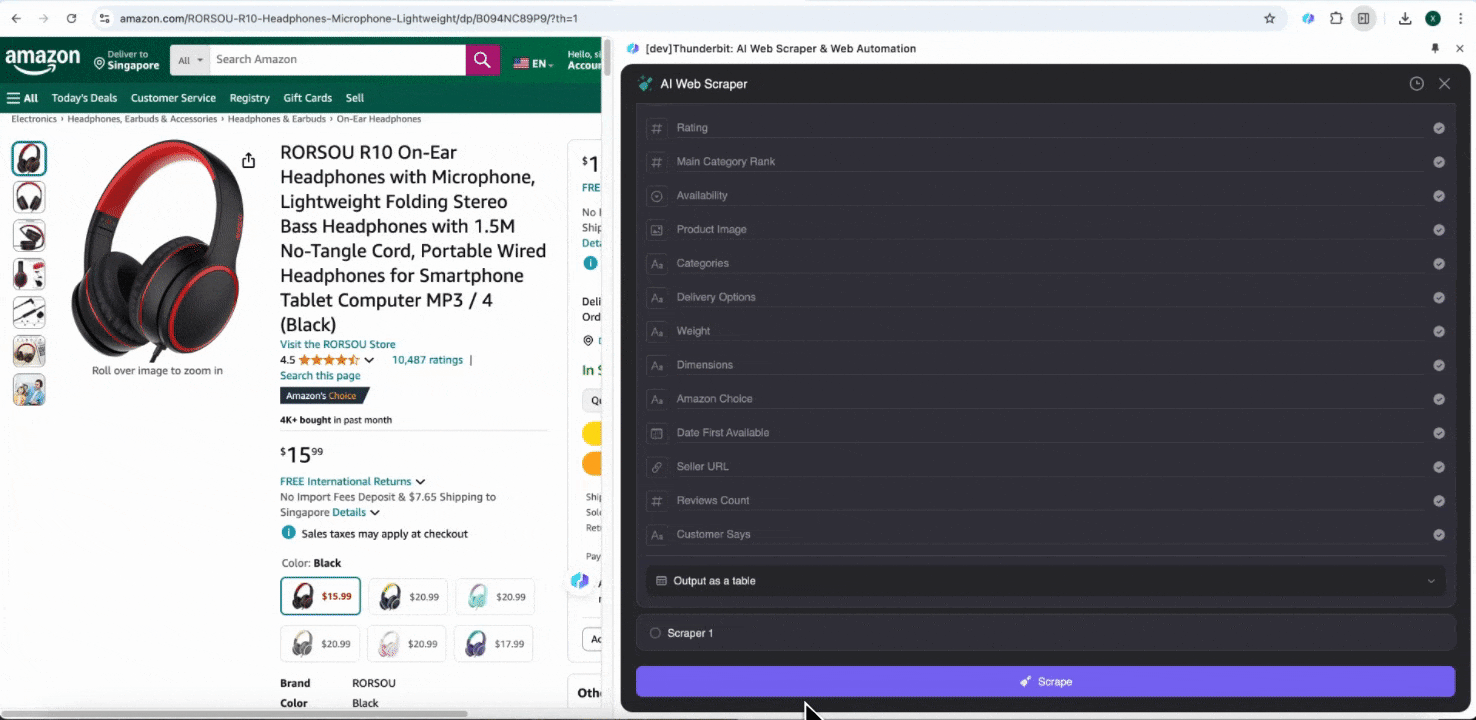
这个工具提供了预置列名,例如商品名称、商品 URL、品牌、制造商、原价、现价、描述、评分、分类、配送选项和卖家 URL。勾选你想提取的列名,点击抓取,就能快速获取所需的 SKU 详情数据。无论你是想比较卖家、制造商和配送选项,做市场调研,评估 SKU 的价格竞争力,还是了解最新销售趋势,这些 SKU 详情数据都能为分析提供帮助。
方案 2:使用 Thunderbit 的 AI 网页爬虫
步骤 1:打开 Amazon.com 并在侧边栏点击“AI 网页爬虫”
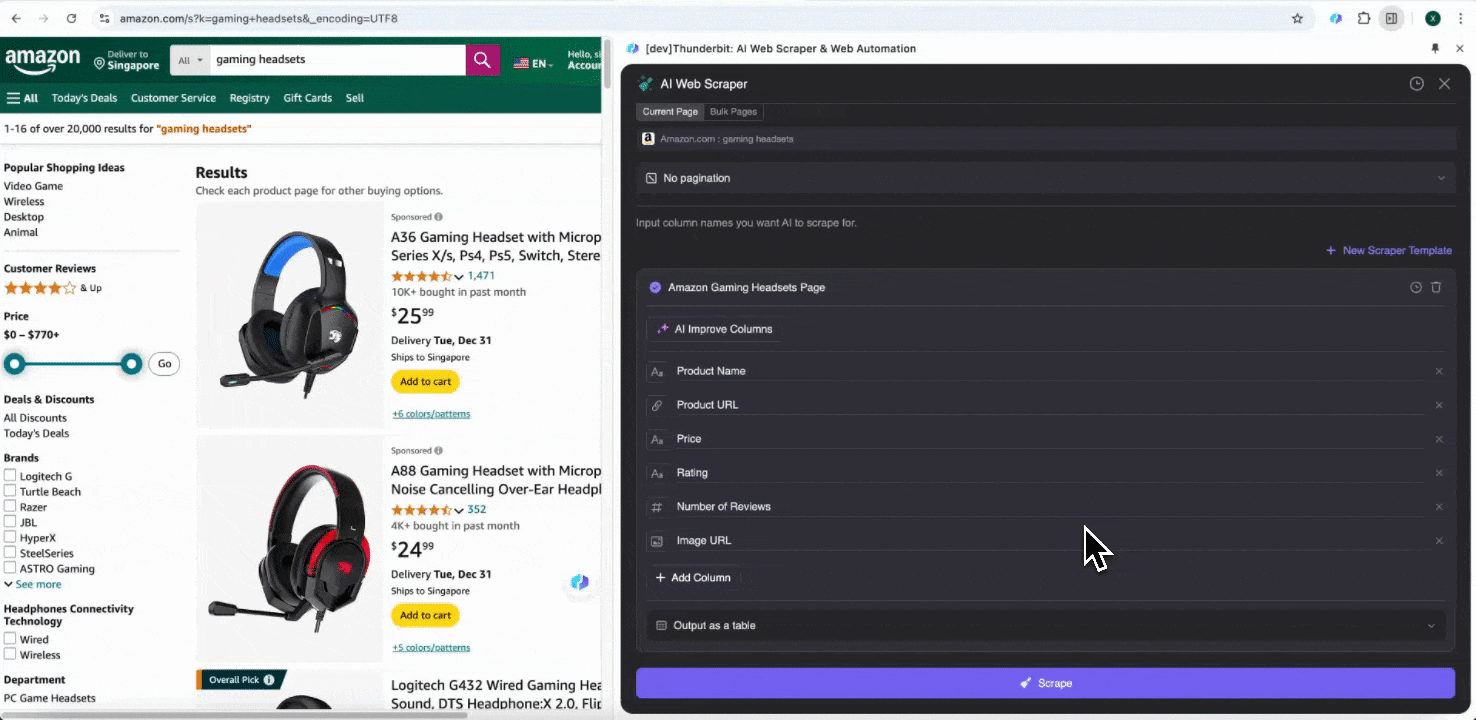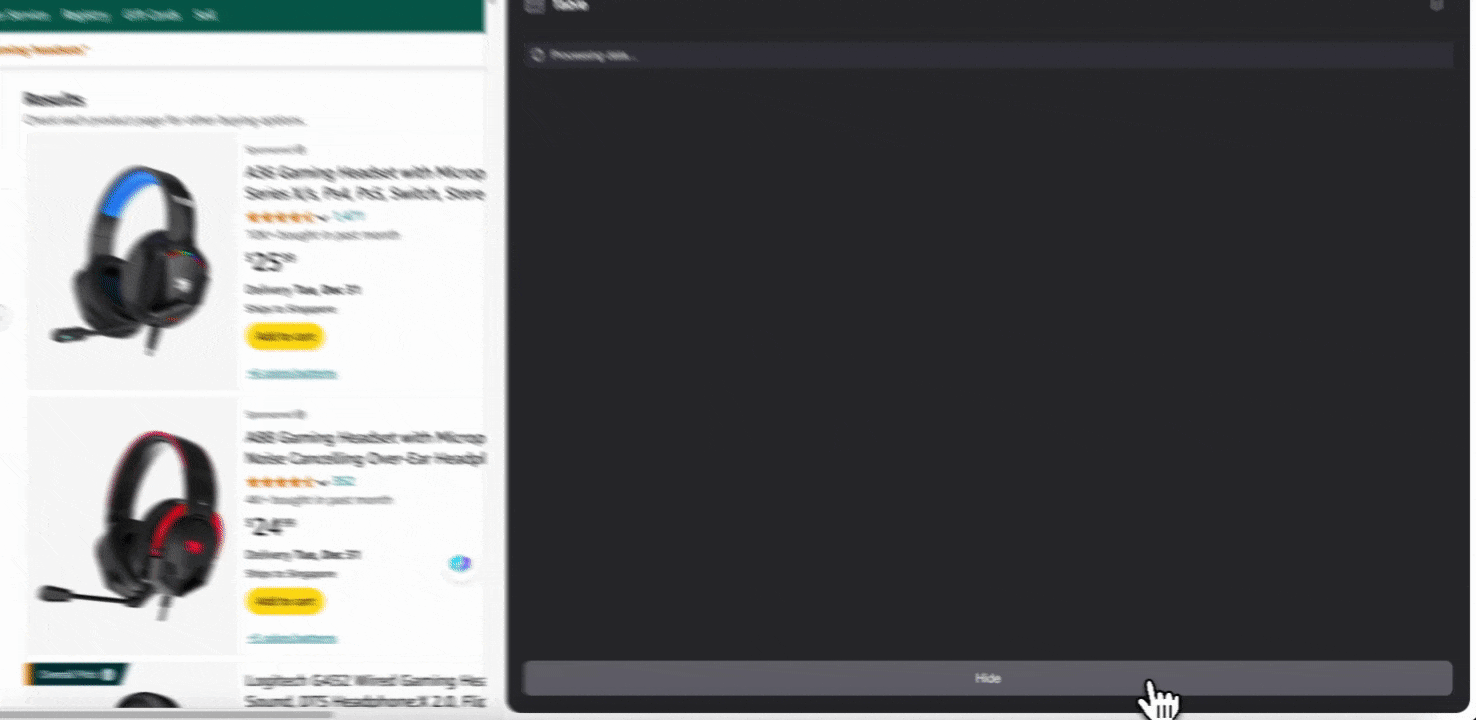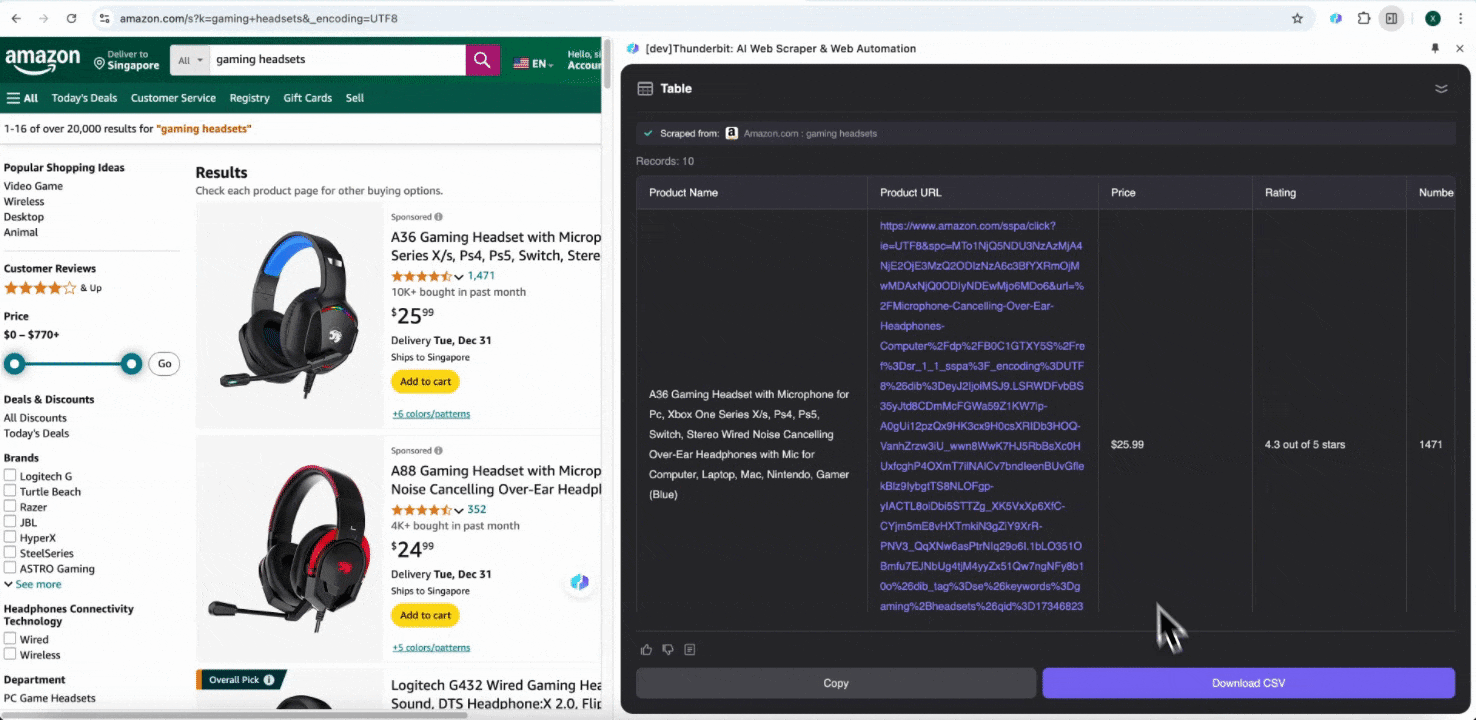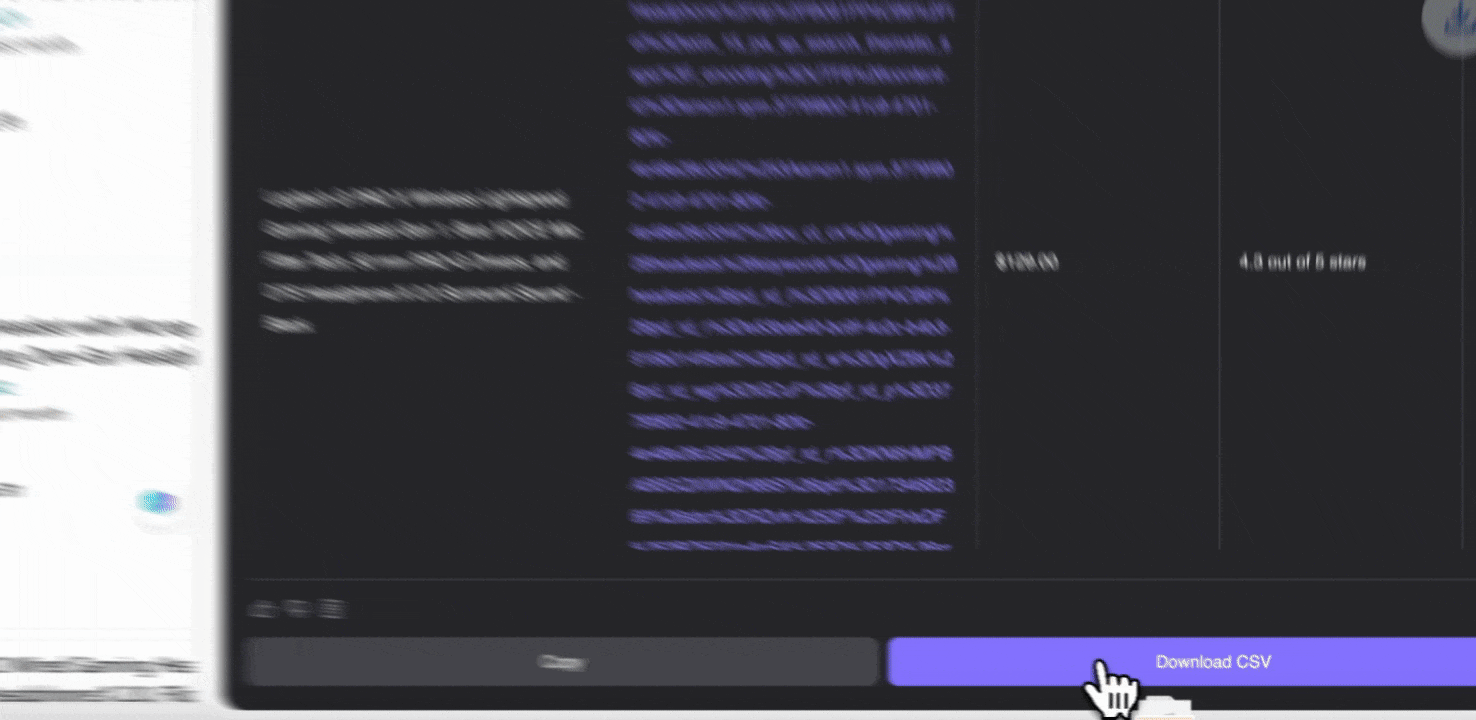
在 Chrome 浏览器中打开 Amazon 网站,搜索或浏览到你想抓取数据的页面,然后点击浏览器右上角的 Thunderbit 图标,打开扩展并点击“AI 网页爬虫”。
步骤 2:自定义你要提取的数据字段
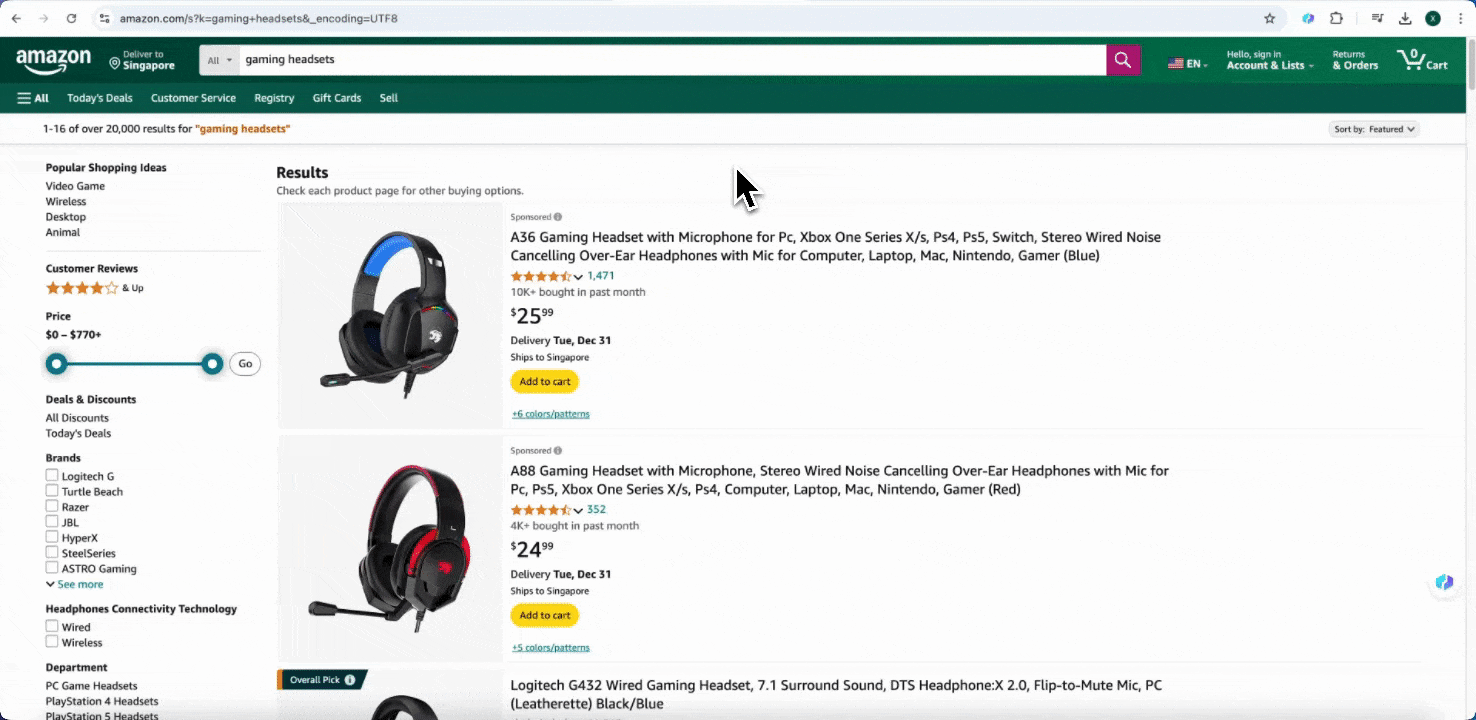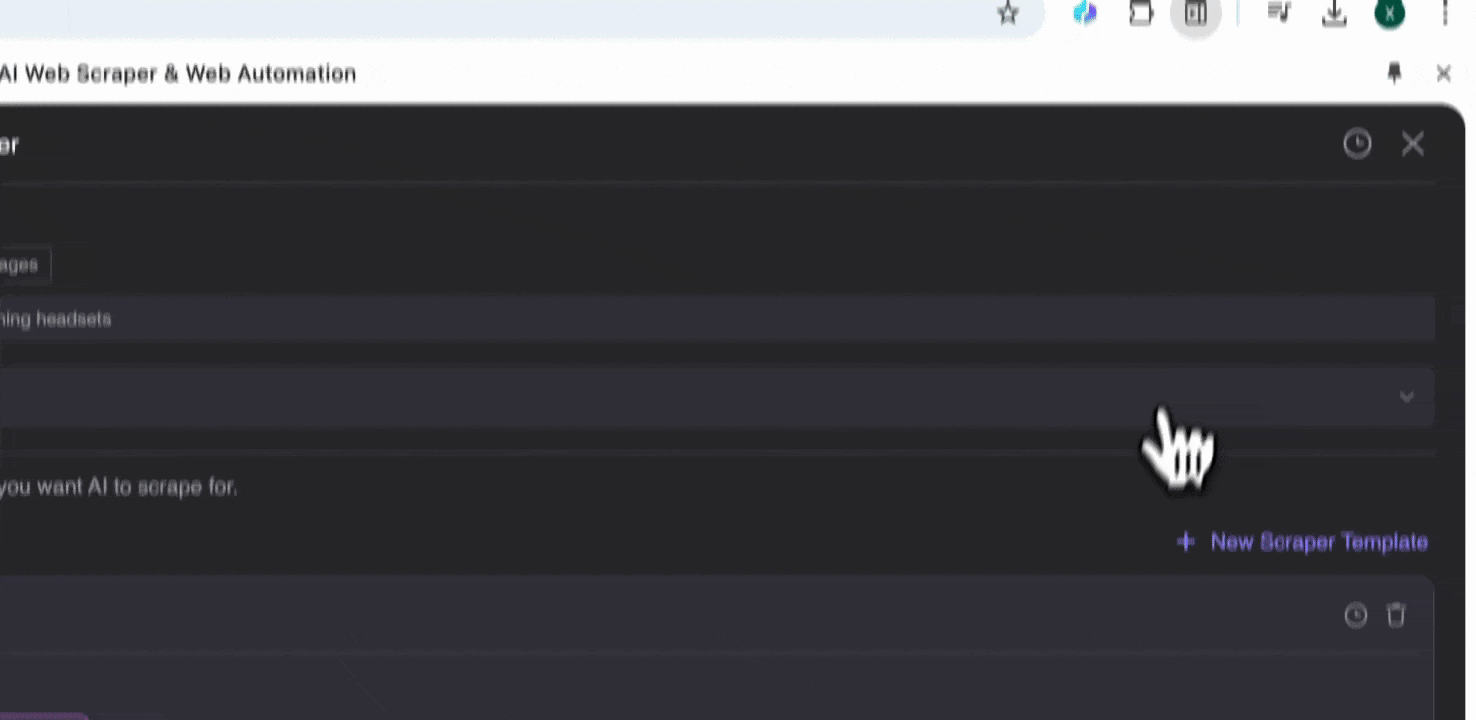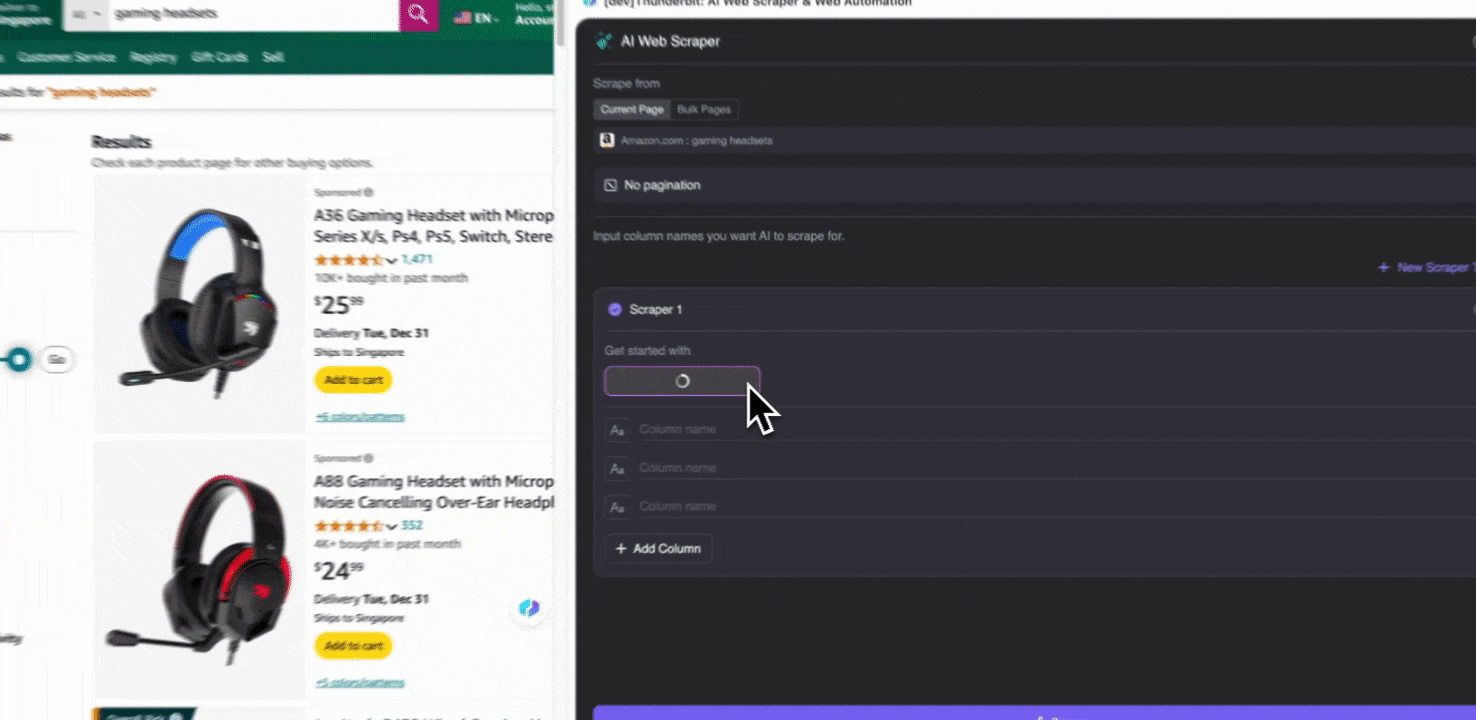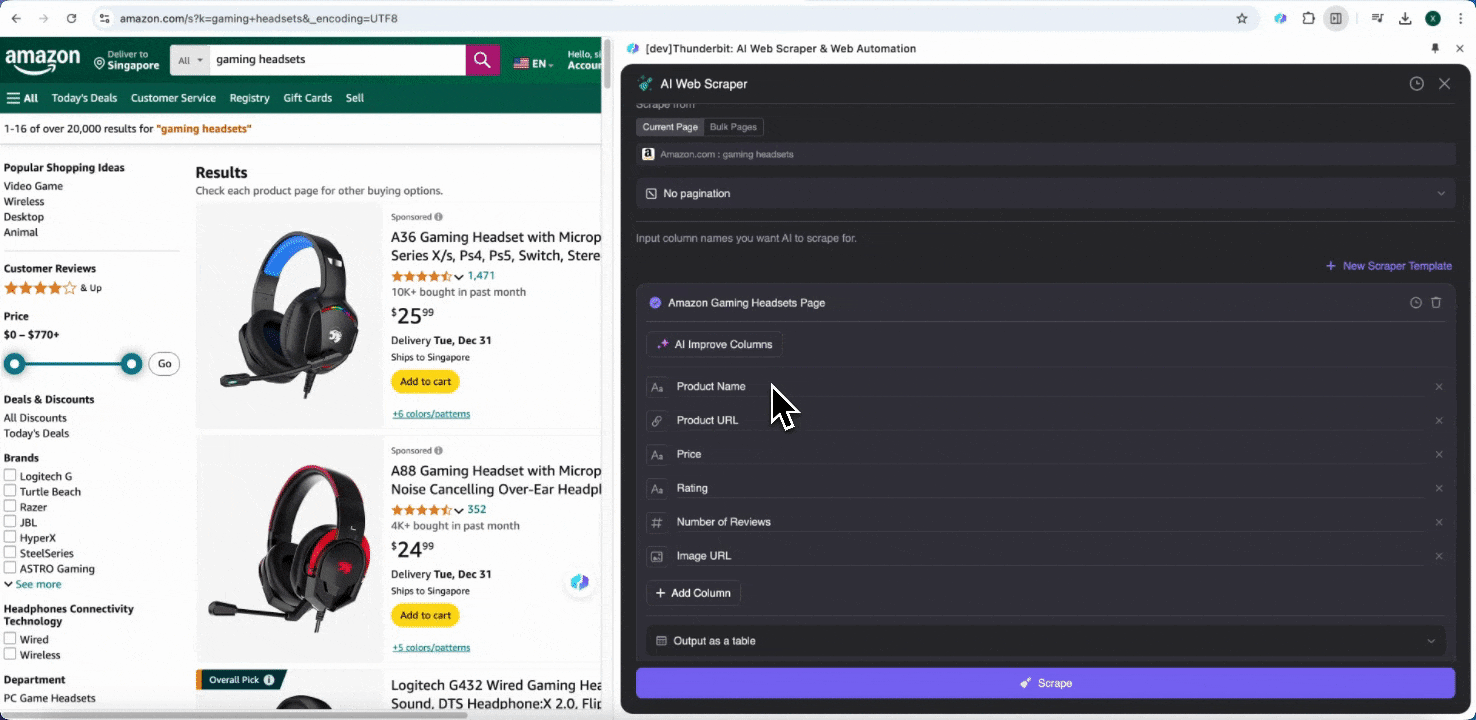
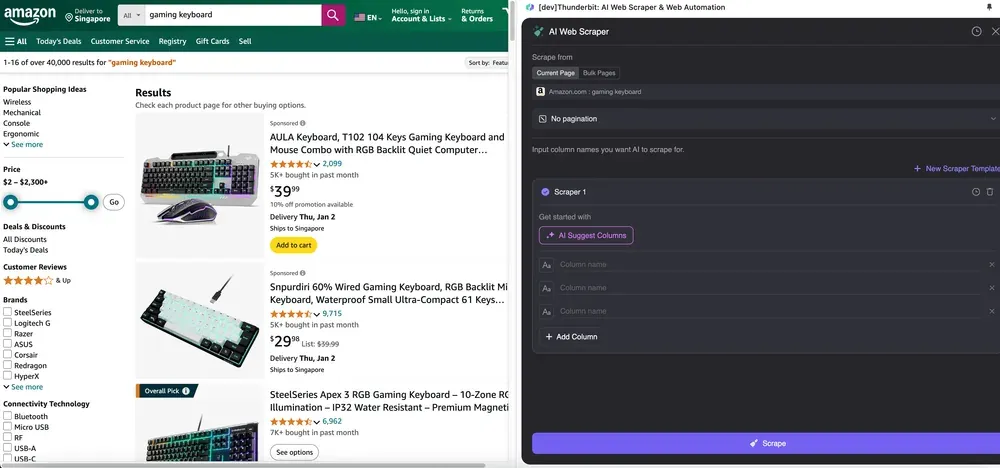
如果你不确定要抓取哪些数据字段,可以点击 AI Suggest Columns,让 Thunderbit 的 AI 自动生成可靠的列名。你也可以用自然语言描述想要的数据标签,然后填入列名字段。通过图标切换你想要的数据类型,比如图片、URL、文本、数字或其他类型,然后抓取对应数据。
填写好初始列名后,你还可以选择 AI Improve Columns,让 AI 进一步优化你的字段设置。你也可以添加列的详细说明,按自己的需求来定制。比如,你可以要求产品类型列将商品分类为男装、女装、童装和其他类别,Thunderbit 会把该列中的每条数据自动归入你定义的四个类别。你还可以让 Thunderbit 按当前汇率把价格列中的所有价格转换为你想要的币种,这样就能轻松得到适合分析的数据,不必担心币种不一致。
最后,你还可以自定义要抓取的数据量。对于 Amazon 商品页,你可以选择点击分页并设置要抓取的页数。Thunderbit 会自动翻页并提取每一页的数据。
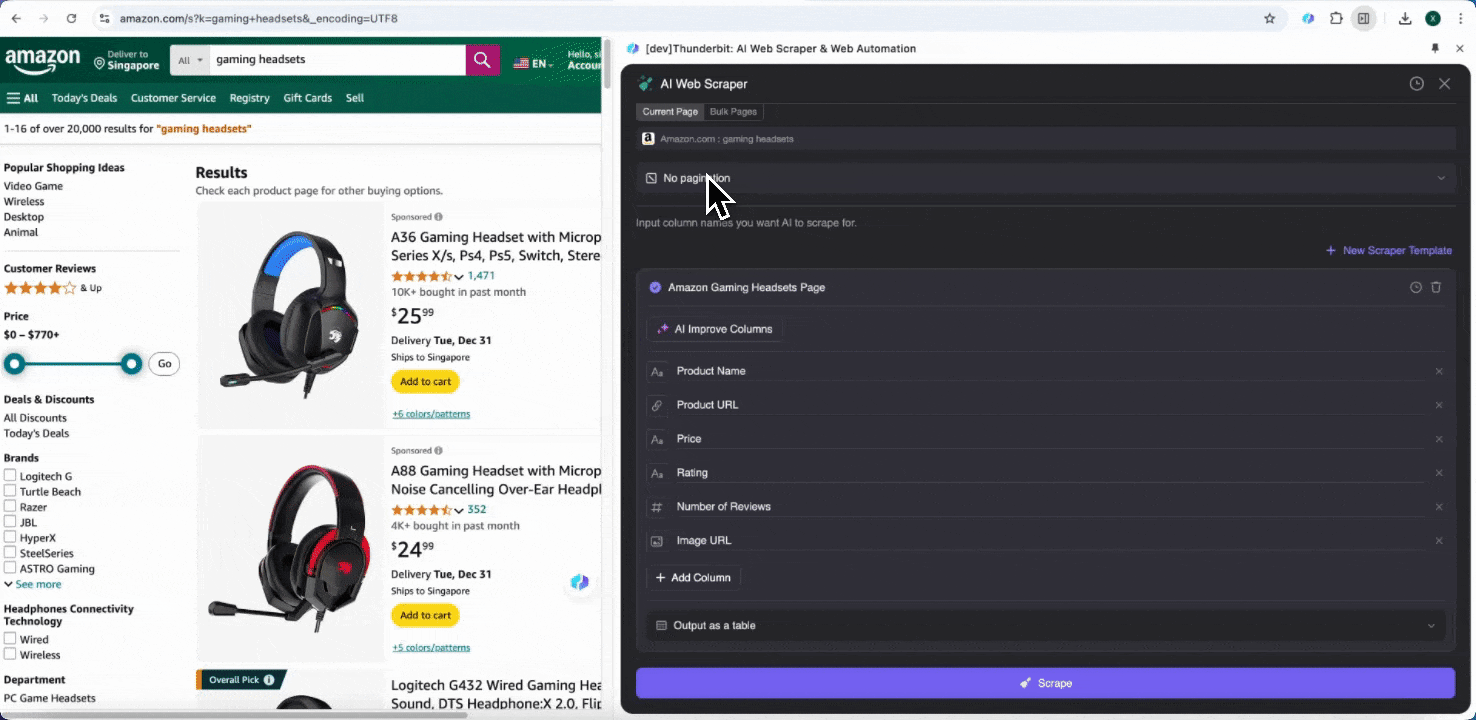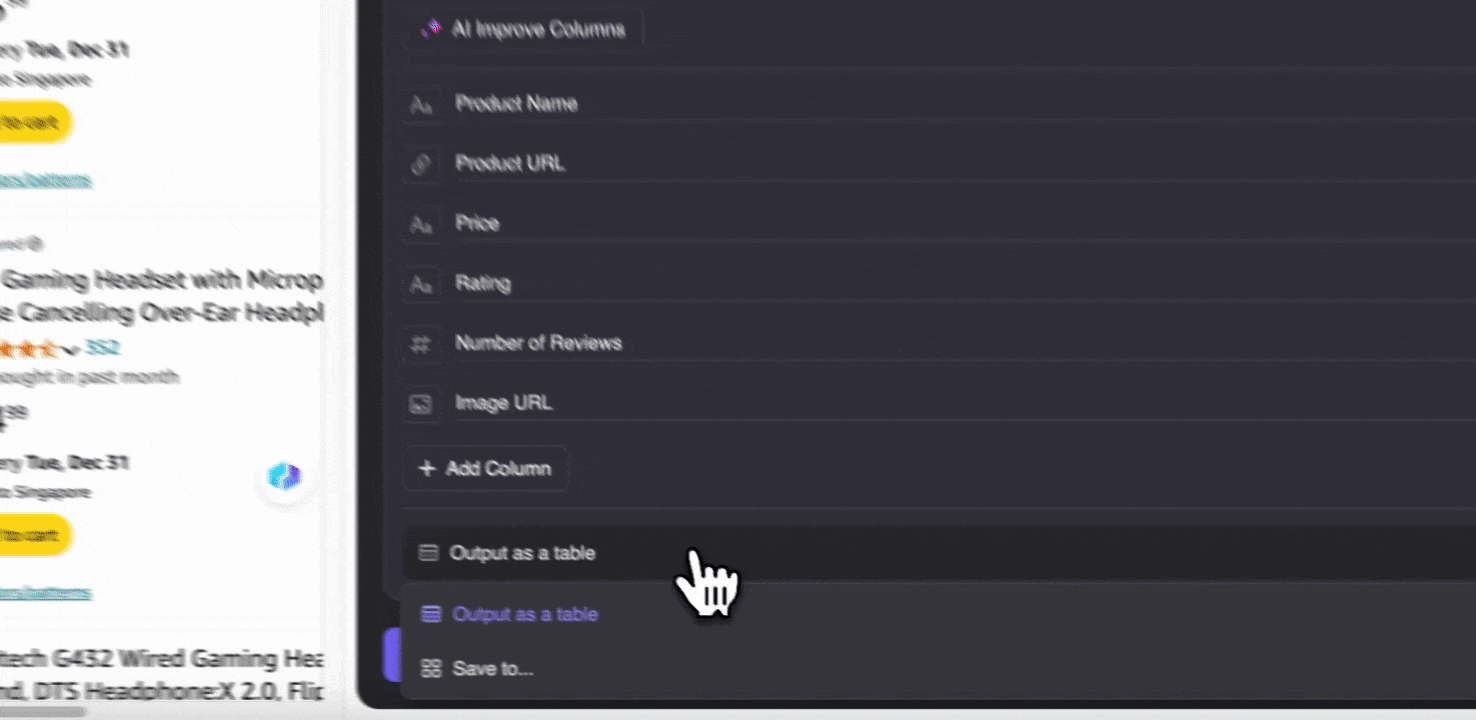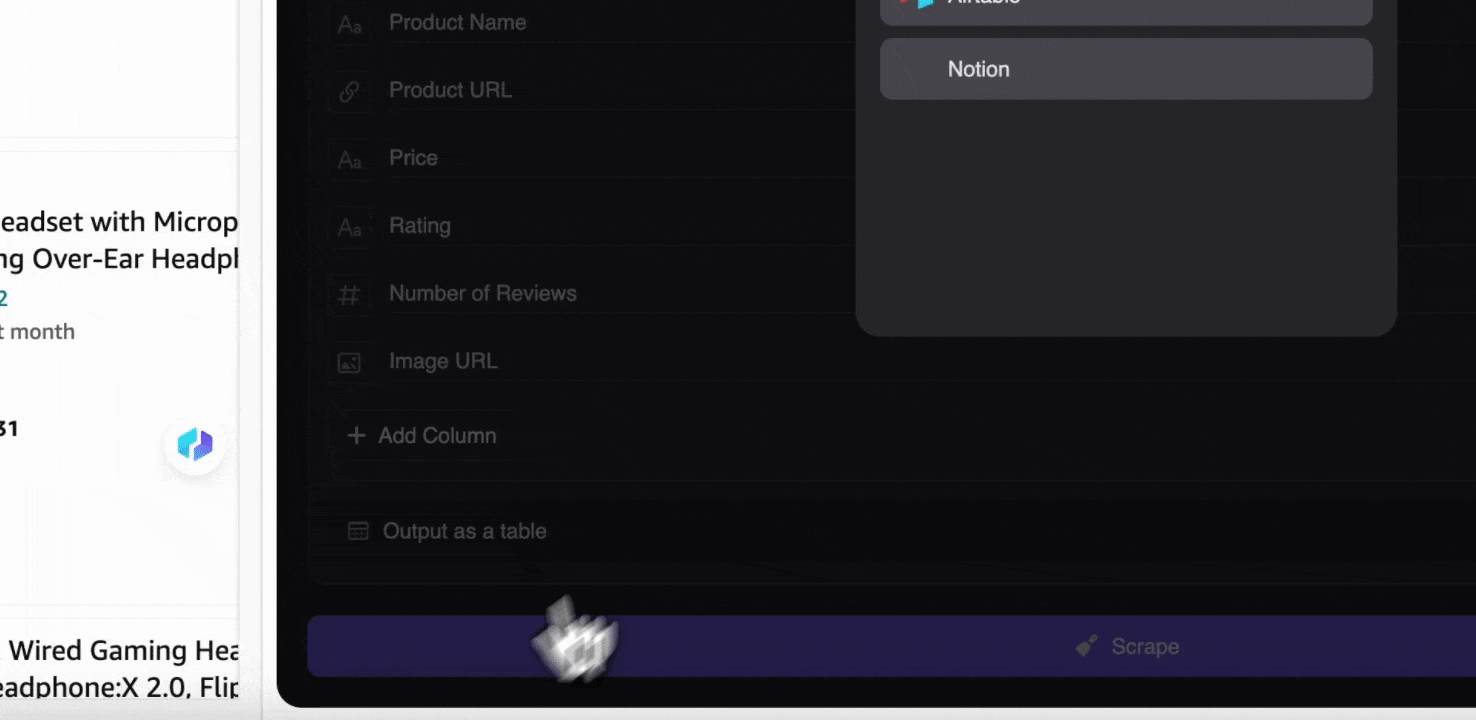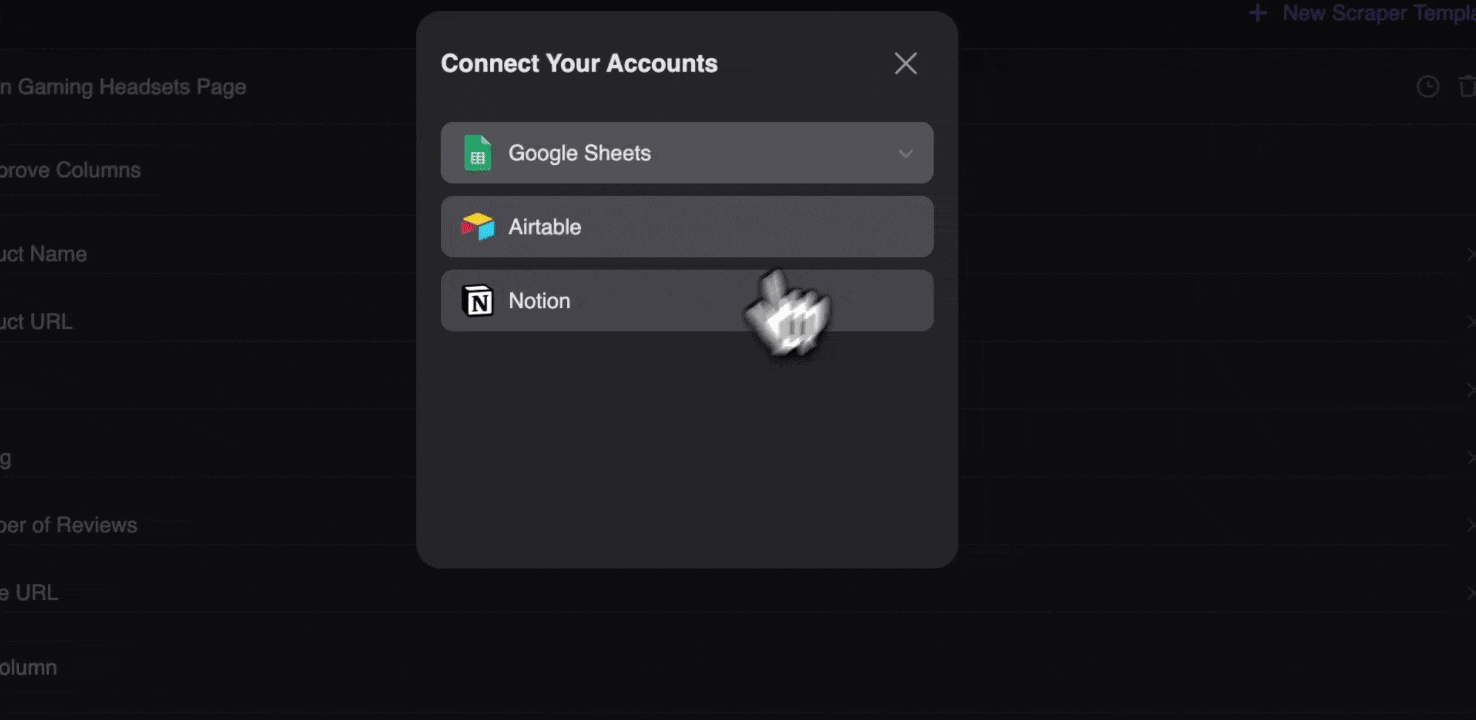
步骤 3:下载抓取的数据或导出为表格
使用 Thunderbit 网页爬虫扩展后,你可以用多种方式导出抓取数据。你可以选择以表格形式输出,然后将 CSV 文件下载到本地,或者选择保存到 Google Sheets、Notion 或 Airtable。登录账号后,就能直接导出到这些在线协作和文件管理平台。
使用传统网页爬虫抓取
除了最新的 AI 工具之外,你也可以通过轻量级代码和 API 使用传统网页爬虫工具来抓取 Amazon 商品数据。
ScraperAPI:通过 API 以 JSON 格式获取 Amazon 商品数据
ScraperAPI 提供了高效的 Amazon 数据采集 API,可以帮助你抓取 Amazon 的商品详情、评论、搜索结果和价格信息,并以结构化 JSON 格式返回。下面介绍如何使用这个 API 进行抓取。
步骤 1:搭建 Python 环境
首先,确保你已安装 Python 3.8 或更高版本。然后安装常用的数据分析库,例如 Pandas,以及网页抓取库,例如 requests 和 BeautifulSoup。这些库可以帮助你轻松提取网页数据。
步骤 2:创建 ScraperAPI 账号
访问 ScraperAPI 网站 注册免费账号并获取 API 密钥。你可以在代码中使用这个密钥访问 ScraperAPI。
步骤 3:准备代码
在本地创建一个独立目录,然后编写 Python 脚本来实现数据抓取。基本流程如下:
- 获取 Amazon 搜索 URL:在 Amazon 上搜索你想要的商品,复制搜索结果页的网址。
- 构建请求:ScraperAPI 会自动循环抓取搜索结果的前五页。每一页的 URL 都是在基础地址后添加 &page= 和对应页码生成的。
- 发送请求并解析数据:使用 get() 方法向 ScraperAPI 发送请求。如果请求成功(返回状态码 200),就解析页面内容,提取所需的 ASIN(Amazon 标准识别号)。
- 获取详细商品数据:通过调用结构化数据接口,你可以获得每个 ASIN 的详细商品信息,便于后续分析。
步骤 4:参考更多教程
如果你想了解更详细的使用方法,可以查看 ScraperAPI 官方博客教程 获取更多说明。
ScrapFly:防封锁并实现大规模抓取
在抓取 Amazon 数据时,IP 封锁、CAPTCHA 验证和动态内容加载等反爬机制,常常会给爬虫开发者带来挑战。ScrapFly 提供了强大的 API,帮助你绕过这些反爬限制,确保数据抓取顺利进行。
ScrapFly 的核心功能包括:
- 轮换住宅代理:自动切换 IP,防止被封。
- JavaScript 渲染:处理动态内容加载,抓取由 JavaScript 渲染的网页。
- 完整浏览器自动化:控制浏览器进行滚动、输入和点击操作。
- 格式转换:可抓取为 HTML、JSON、Text 或 Markdown。
只需几行代码,你就能使用 ScrapFly 抓取 Amazon 数据。下面是一个简单示例:
import scrapfly_sdk
# Create a client
client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
# Send a request
response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
# Get the returned data
print(response.json())
借助 ScrapFly,你的爬虫可以应对 Amazon 各种反爬机制,提高数据抓取成功率。无论是基础的商品信息抓取,还是复杂的评论分析,ScrapFly 都是一款非常实用的工具。更详细的使用教程可参考 ScrapFly 官方指南。
使用 Python 抓取:传统编码方式
如果你熟悉编程,也可以尝试直接写 Python 代码来抓取 Amazon 商品数据。下面是一个简单示例供你参考。
步骤 1:准备运行环境
首先,为你的项目创建一个独立文件夹。
mkdir amazonscraper
然后在这个文件夹中安装所需库。
pip install beautifulsoup4
pip install requests
接下来,创建一个你喜欢命名的 Python 文件,它将作为存放代码的主文件。这里我们将它命名为 amazon.py。
步骤 2:向目标页面发送 GET 请求
接下来,使用 requests 库向目标页面发送 GET 请求。
import requests
from bs4 import BeautifulSoup
target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
headers = {
"accept-language": "en-US,en;q=0.9",
"accept-encoding": "gzip, deflate, br",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
}
response = requests.get(target_url, headers=headers)
步骤 3:抓取 Amazon 商品数据
现在我们需要决定要从 目标页面 提取哪些内容。
# Check if the request was successful
if response.status_code == 200:
# Parse the page content
soup = BeautifulSoup(response.content, 'html.parser')
# Find all product listings
products = soup.find_all('div', {'data-component-type': 's-search-result'})
# Iterate over each product and extract details
for product in products:
# Extract product title
title = product.h2.text.strip()
# Extract product price
price = product.find('span', 'a-price')
if price:
price = price.find('span', 'a-offscreen').text.strip()
else:
price = "Price not available"
# Extract product rating
rating = product.find('span', 'a-icon-alt')
if rating:
rating = rating.text.strip()
else:
rating = "Rating not available"
# Print product details
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")
print("-" * 40)
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
常见问题
1. 抓取 amazon.com 合法吗?
是的,抓取 Amazon 的公开数据是合法的!和许多其他网站一样,Amazon 会向所有访问者公开商品列表和其他可浏览的信息。你可以自由抓取和收集这些公开可访问的数据,而不会违反 Amazon 的服务条款。
2. 我可以免费试用 Thunderbit 吗?
可以,Thunderbit 提供免费的页面抓取和数据提取功能。虽然某些高级功能可能需要付费,但基础的数据提取通常是免费的。
3. 我可以从 Amazon 抓取哪些数据?
你可以从 Amazon 抓取多种数据,包括商品标题、价格、描述、评论、评分和卖家信息。这些数据可用于市场调研、价格监控和竞品分析。
4. 我应该多久抓取一次 Amazon 数据?
频率取决于你想获取的数据类型。如果你是监控价格或竞品动态,可能需要每天或每周抓取一次;如果只是商品详情这类变化较少的信息,每月抓取一次通常就够了。
了解更多
试用 AI 网页爬虫 Get Started Free




