

周二中午还没到,我的 OpenRouter 仪表盘就已经显示花了 47 美元。那天我大概只跑了十来个编码任务——一点都不夸张,也就是些重构和少量 bug 修复。就在那一刻我才发现,OpenClaw 的默认设置其实在偷偷把每一次交互都路由到 Claude Opus,连后台心跳 ping 也没放过,而它的价格高到每百万 tokens 15 美元以上。
如果你也碰到过这种“惊喜”——而且看论坛就知道,很多人都踩过坑(有用户直接写道:“我已经花了 40 美元了,但根本没怎么用”)——这篇指南会带你完整走一遍我实际用过的审计和优化流程,最后把月度开销压低了大约 90%。它不只是简单地“换个便宜模型”,而是系统性拆解 token 到底花在哪、怎么监控、哪些低价模型真的能胜任 agent 工作,以及 3 套可以直接复制的配置。我整个过程只花了一个下午。
什么是 OpenClaw token 使用量?为什么默认情况下这么高?
Token 是 OpenClaw 里所有 AI 交互的计费单位。你可以把它理解成很小的文本片段——大致相当于每个 token 4 个英文字符。你发出的每条消息、收到的每个回复、每个后台触发的流程,都会按 token 计费。
问题在于,OpenClaw 的默认配置追求的是“能力拉满”,而不是“成本最低”。开箱即用时,主模型被设成了 anthropic/claude-opus-4-5——这可是当前最贵的选项。心跳 ping 也用 Opus?子代理做边角任务也用 Opus?这就像请神经外科医生来贴创可贴。技术上没问题,但价格真的离谱。
大多数用户并没意识到,他们其实是在为那些几乎没什么价值的后台任务付高价。默认配置本质上是在假设:你希望任何时候、任何任务都用最强模型——而账单也会照这个逻辑来。
为什么降低 OpenClaw token 使用量,省的不只是钱
最直观的收益当然是成本下降。但随着时间拉长,还有一些连带效果也很重要。
更便宜的模型往往也更快。Gemini 2.5 Flash-Lite 的速度大约是 214 tokens/s,而 Opus 约为 51,单次交互就快了 4 倍。Cerebras 上的 GPT-OSS-120B 能跑到 1,917 tokens/s,大约比 Opus 快 35 倍。对于一个有 50 多轮工具调用的 agent 循环来说,这种速度差意味着你几分钟就能跑完,而不是每轮都忍受 Opus 那种让人头大的 13.6 秒首 token 等待时间。
你还会得到更宽裕的速率限制、更少的请求被限流,以及更容易扩容的使用空间,而不至于一看到账单就心里发紧。
不同使用强度下的预估节省如下:
| 用户类型 | 默认配置下的月支出估算 | 完成全面优化后 | 每月节省 |
|---|---|---|---|
| 轻度用户(约 10 次查询/天) | 约 $100 | 约 $12 | 约 88% |
| 中度用户(约 50 次查询/天) | 约 $500 | 约 $90 | 约 82% |
| 重度用户(200+ 次查询/天) | 约 $1,750 | 约 $220 | 约 87% |
这些不是纸上谈兵。有开发者记录了自己从 每月 600–750 美元降到每天 3–4 美元——实打实节省了 90%——做法就是把模型路由优化和本文后面会讲到的那些“隐形耗费”一起处理掉。
OpenClaw token 使用量解剖:每个 token 到底花到哪了
这部分是大多数优化指南会跳过的,但恰恰是最关键的。你看不见,就没法优化。
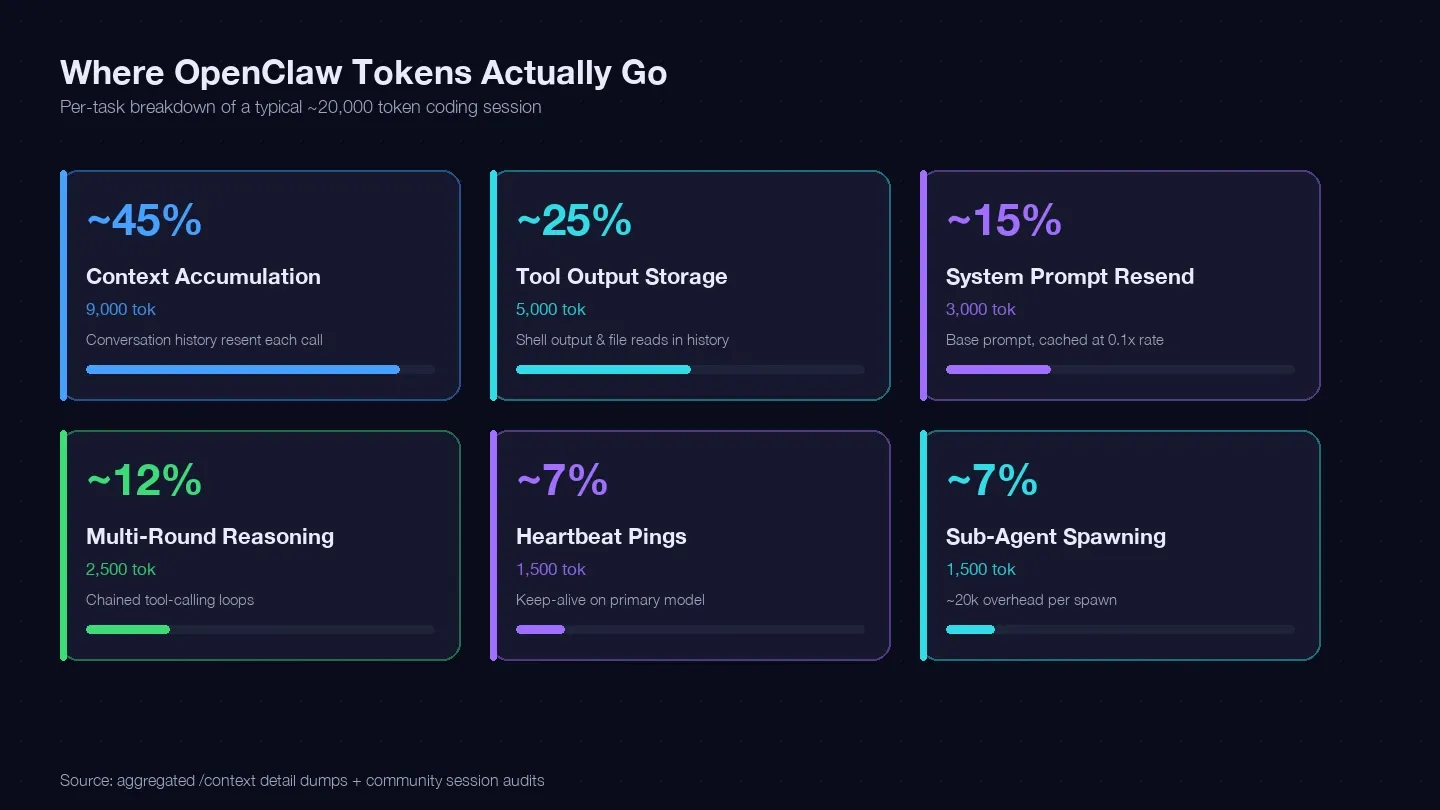
我审计了多个会话,并结合 LaoZhang 的成本优化指南 和社区 /context 导出内容,整理出一个典型单次编码任务的 token 账本。大约 20,000 个 token 主要花在这些地方:
| Token 类别 | 通常占总量比例 | 示例(1 个编码任务) | 能否控制? |
|---|---|---|---|
| 上下文累积(每次调用都会重发历史对话) | 约 40–50% | 约 9,000 tokens | 可以 — /clear、/compact、缩短会话 |
| 工具输出存储(shell 输出、文件读取内容留在历史中) | 约 20–30% | 约 5,000 tokens | 可以 — 减少读取内容、收紧工具范围 |
| 系统提示词重发(约 15K 基础内容) | 约 10–15% | 约 3,000 tokens | 部分可以 — 缓存读可按 0.1 倍计费 |
| 多轮推理(串联工具调用循环) | 约 10–15% | 约 2,500 tokens | 取决于模型选择 + 更好的提示词 |
| 心跳 / 保活 ping | 约 5–10% | 约 1,500 tokens | 可以 — 改配置 |
| 子代理调用 | 约 5–10% | 约 1,500 tokens | 可以 — 做模型路由 |
| } |
最大的一块耗费——上下文累积——就是每次 API 调用都会把整段对话历史重新发送一遍。有一份真实会话导出显示,仅 Messages 这一项就有 185,400 tokens,而模型当时甚至还没开始回复。再加上系统提示词和工具内容,又额外产生了约 35,800 tokens 的固定开销。
结论很直接:如果你不在无关任务之间清空会话,那你每一轮都在为重发整段历史付费。
如何监控 OpenClaw token 使用量(看不见,就减不掉)
在你改任何东西之前,先搞清楚 token 究竟流向哪里。直接跳到“换便宜模型”而不监控,就像减肥却从不称体重。
先看 OpenRouter 仪表盘
如果你是通过 OpenRouter 路由,那个 Activity 页面 是最省事、几乎不用配置的看板。你可以按模型、提供商、API key 和时间段筛选。Usage Accounting 视图会把每次请求里的 prompt、completion、reasoning 和 cached tokens 拆开显示。它还支持导出(CSV 或 PDF),方便做更长周期的分析。
重点看什么:哪个模型消耗的 token 最多,以及心跳或子代理请求里有没有异常大的账单项。
审计本地 API 日志
OpenClaw 会把会话数据保存在 ~/.openclaw/agents.main/sessions/sessions.json,其中包含每个会话的 totalTokens。你也可以运行 openclaw logs --follow --json 来实时记录每次请求。
有个要注意的坑:sessions.json 的 totalTokens 在 compaction 后不会更新,所以仪表盘可能显示的是压缩前的旧值。与其看存储总数,不如信 /status 和 /context detail。
使用第三方追踪工具(适合中重度用户)
LiteLLM proxy 能在 100 多家提供商前面提供一个 OpenAI 兼容端点,并且会自动记录每个虚拟 key、模型、用户和团队的支出。它最强的功能是:你可以给每个 key 设硬预算,而且即使执行 /clear 也不受影响——某个失控的子代理也别想突破你的上限。
Helicone 更简单,只要替换一行 base URL 就能得到一个 Sessions 视图,把相关请求归在一起。一个“帮我修这个 bug”的提示词如果拆成 8 次以上子代理调用,也会以一条会话记录出现,并显示真实总成本。免费套餐:每月 10,000 次请求。
OpenClaw 内部快速抽查
日常监控时,下面 4 个会话内命令就够用了:
/status— 显示上下文使用情况、最近输入/输出 tokens、预估成本/usage full— 每次回复的 usage 页脚/context detail— 按文件、技能、工具拆分 token 明细/compact [guidance]— 强制压缩上下文,可附带聚焦说明
在改配置前后都跑一遍 /context detail。这就是判断优化到底有没有效果的方式。
OpenClaw 最便宜模型大比拼:哪些低价 LLM 真能干 agent 工作
大多数指南都会在这里走偏。它们拿出一张价格表,指着最便宜那一行,然后就结束了。但基准测试并不能预测真实世界里的 agent 表现——社区已经反复强调这一点了。正如一位用户所说:“benchmark 并不能真正说明哪个最适合 agentic AI。”
关键洞察是:最便宜的模型,不一定是最便宜的结果。 一个会失败并重试四次的模型,花的钱可能比一个中档模型还多,而后者一次就能成功。在生产级 agent 系统里,要预留 5–10% 的重试率——如果五次 LLM 调用是串联执行的,而第 4 步失败了,简单粗暴的重试会把前面五步全部再跑一遍。
下面是我的能力矩阵,加入了基于真实用户反馈而不是合成 benchmark 的“真实 agent 得分”:
| 模型 | 输入价 / 100 万 tokens | 输出价 / 100 万 tokens | 工具调用可靠性 | 多步推理 | 真实 Agent 得分(1–5) | 适合场景 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 一般 — 偶尔会循环 | 基础 | ⭐2.5 | 心跳、简单查询 |
| GPT-OSS-120B | $0.04 | $0.19 | 尚可 | 尚可 | ⭐3.0 | 预算实验、对速度敏感的任务 |
| DeepSeek V3.2 | $0.26 | $0.38 | 不稳定(有 6 个公开问题) | 不错 | ⭐3.0 | 偏推理、少工具调用 |
| Kimi K2.5 | $0.38 | $1.72 | 不错(通过 :exacto) | 尚可 | ⭐3.5 | 轻到中等强度编码 |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | 不错 | 不错 | ⭐4.0 | 日常通用编码主力 |
| Claude Haiku 4.5 | $1.00 | $5.00 | 很好 | 不错 | ⭐4.5 | 可靠的中档回退模型 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 很好 | 很好 | ⭐5.0 | 复杂多步任务 |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | 很好 | 很好 | ⭐5.0 | 只留给最难的问题 |
关于 DeepSeek 和 Gemini Flash 工具调用的提醒
DeepSeek V3.2 在纸面数据上很漂亮——SWE-Bench 上有 72–74% 的成绩,价格比 Sonnet 低 11–36 倍。但在实际使用中,Cline、Roo Code、Continue 和 NVIDIA NIM 的 6 个独立 GitHub 问题 都记录了它工具调用行为异常。Composio 的正面对比结论是:“DeepSeek V3.2 做出了应用的一部分,但在执行、速度和可靠性上跌了跟头。” Zvi Mowshowitz 的一句话总结是:“还行,也便宜,但……”。
Gemini 2.5 Flash 也有类似问题。Google AI Developers Forum 上一篇题为“Very frustrating experience with Gemini 2.5 function calling performance”的帖子开头就写道:“Gemini 模型的 function calling 行为已经变得完全不稳定、不可预测."
OpenRouter 还特别指出了一个关键细节:“同一权重模型在不同 host 上,调用工具的倾向和准确性可能差异极大.” 如果你通过 OpenRouter 路由低价模型,记得关注 :exacto 标签——一次静默的 provider 切换,可能会把一个便宜且稳定的模型,悄悄变成高价重试循环。
什么时候用哪个模型
- Gemini Flash-Lite: 心跳、保活 ping、简单问答。不要拿它做多步工具调用。
- MiniMax M2.5/M2.7: 日常通用编码的主力。它在 SWE-Pro 56.22、Terminal-Bench 2 57.0% 的表现很能打,价格却只有 Sonnet 的一小部分。
- Claude Haiku 4.5: 当便宜模型在工具调用上“卡壳”时,用它做可靠回退。工具调用能力优秀,而且价格比 Sonnet 便宜大约 3 倍。
- Claude Sonnet 4.6: 复杂多步 agent 任务的主力。这类场景才是真正值回票价的地方。
- Claude Opus: 只留给最难的问题。不要让它成为任何任务的默认选项。
(模型价格经常变动——在确定配置之前,请先到 OpenRouter 或各提供商页面核实最新价格。)
大多数指南都会漏掉的隐形 token 黑洞
论坛用户普遍反馈,关闭某些特性后成本会明显下降,但我还没见过哪份指南能把所有“隐形耗费”及其真实 token 影响整理成统一清单。下面就是完整拆解:
.enabled: false\` | | Agent Teams(计划模式) | [约为标准会话成本的 7 倍](https://www.mindstudio.ai/blog/claude-code-agent-teams-parallel-agents) | 仅在真正需要并行时使用 | 尽量改为顺序执行 |`} />其中,heartbeat 的耗费尤其值得单独说明。默认情况下,heartbeat 每 30 分钟就会在主模型(Opus)上触发一次。把 isolatedSession 设为 true 后,这一项会从每次约 100,000 tokens降到 2,000–5,000 tokens——单这一项就能减少 95–98%。
两分钟内最值钱的三项快速优化
下面三项都几乎零风险,而且每项不到两分钟:
-
无关任务之间执行
/clear(5 秒)。 这是最能省 token 的单项操作。论坛共识认为,仅靠在开始新任务前清空会话历史,就能减少 50–70% 的消耗。还记得前面 /context 导出里那 185k token 的 Messages 桶吗?/clear会直接清掉它。 -
把体力活切到
/model haiku-4.5(10 秒)。 这种战术性切换模型的做法,可让日常任务的成本降低 60–80%。Haiku 处理大多数简单编码、文件查询和提交信息都绰绰有余。 -
把
.clawrules缩到 200 行以内 + 添加.clawignore(90 秒)。 你的规则文件会在每条消息里都被加载。200 行大约就是每轮 1,500–2,000 tokens;如果写到 1,000 行,那么每次请求都会永久背负 8,000–10,000 tokens 的开销。再配合.clawignore排除node_modules/、dist/、锁文件和生成代码,有开发者声称仅靠这一招就实现了 92% 的 token 降幅。
一步一步来:3 套可直接复制的配置,迅速降低 OpenClaw token 使用量

下面给出 3 套完整、带注释的 openclaw.json 配置——从“先省钱再说”到“全量优化栈”都有。每套都包含行内注释和月度成本预估。
开始前先看:
- 难度: 初级(配置 A)→ 中级(配置 B)→ 高级(配置 C)
- 所需时间: 配置 A 约 5 分钟,配置 C 约 15 分钟
- 你需要准备: 已安装 OpenClaw、文本编辑器、可访问
~/.openclaw/openclaw.json
配置 A:入门版——先把钱省下来
只要五行,几乎零复杂度。把默认模型从 Opus 换成 Sonnet,关闭 memory 开销,并把 heartbeat 隔离到 Haiku。
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // 原本是 Opus——成本立刻降 3-5 倍
"heartbeat": {
"every": "55m", // 与 1 小时 cache TTL 对齐,尽量提高缓存命中率
"model": "anthropic/claude-haiku-4-5", // ping 用 Haiku,别用 Opus
"isolatedSession": true // 每次约 100k → 2-5k tokens
}
}
},
"memory": { "enabled": false } // 每个会话可省约 500-2k tokens
}
应用后你应该看到什么: 运行 /status 前后对比。每次请求的成本应该会明显下降,OpenRouter Activity 页面里的 heartbeat 条目也应该从 Opus 变成 Haiku。
| 使用层级 | 默认配置(Opus) | 配置 A(Sonnet + Haiku heartbeats) | 节省 |
|---|---|---|---|
| 轻度(约 10 次/天) | 约 $100 | 约 $35 | 65% |
| 中度(约 50 次/天) | 约 $500 | 约 $250 | 50% |
| 重度(约 200 次/天) | 约 $1,750 | 约 $900 | 49% |
配置 B:进阶版——聪明的三层路由
主模型用 Sonnet 处理真正的工作。子代理和 compaction 用 Haiku。Claude 被限流时,再用 Gemini Flash-Lite 当低价回退。回退链会自动处理提供商故障。
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // 如果 Sonnet 被限流,就切这里
"google/gemini-2.5-flash-lite" // 超低价终极备选
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 分钟 < 1 小时缓存 TTL = 更容易命中缓存
"model": "google/gemini-2.5-flash-lite", // 每次 ping 只要几分钱
"isolatedSession": true,
"lightContext": true // heartbeat 调用尽量带更少上下文
},
"subagents": {
"maxConcurrent": 4, // 从默认 8 降下来
"model": "anthropic/claude-haiku-4-5" // 子代理没必要上 Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // 压缩摘要交给 Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
预期结果: 日志里的子代理条目应该都按 Haiku 计费。heartbeat 的成本会接近于零。回退链还能确保 Claude 出问题时不会卡死整个会话——它会优雅降级到 Gemini。
| 使用层级 | 默认配置 | 配置 B | 节省 |
|---|---|---|---|
| 轻度 | 约 $100 | 约 $20 | 80% |
| 中度 | 约 $500 | 约 $150 | 70% |
| 重度 | 约 $1,750 | 约 $500 | 71% |
配置 C:进阶玩家版——完整优化栈
按子代理单独指定模型、把上下文压缩固定到 Haiku、视觉任务路由到 Gemini Flash、收紧 .clawrules + .clawignore、关闭没用的技能。这套配置可以把节省幅度推到 85–90%。
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // 备用提供商
"minimax/minimax-m2-7", // 便宜的日常主力回退
"anthropic/claude-haiku-4-5" // 最后兜底
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // 夜间不发 heartbeat
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // 从默认 20000 降下去
"imageModel": "google/gemini-3-flash" // 视觉任务用便宜模型
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // 尽量保留最小记忆
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
按子代理覆盖模型的示例——粘贴到 ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: 运行 lint/format 检查,并修复简单问题
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
最小可用版 .clawignore——单这一项就能把典型 bootstrap 从 150k 字符压到 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| 使用层级 | 默认配置 | 配置 C | 节省 |
|---|---|---|---|
| 轻度 | 约 $100 | 约 $12 | 88% |
| 中度 | 约 $500 | 约 $90 | 82% |
| 重度 | 约 $1,750 | 约 $220 | 87% |
这些数字与两份独立的真实用户报告相吻合:Praney Behl 记录的结果是从 每月 $600–750 降到每天 $3–4(减少 90%),而 LaoZhang 的案例研究则显示,在部分优化下可实现 从 $943 降到 $347(63%)、从 $1,750 降到 $1,000(64%)、从 $200 降到 $70(65%)。
用 /model 命令实时控制 OpenClaw token 使用量
/model 命令会在保留完整对话上下文的前提下,切换下一轮要使用的模型——不会重置,也不会丢历史。这是那种越用越省钱的日常习惯。
实际工作流可以这样安排:
- 在处理复杂的多文件重构?继续用 Sonnet。
- 只是想快速问一句“这个正则到底干嘛的?”?
/model haiku,问完再切回/model sonnet。 - 要写提交信息或润色文档?
/model flash-lite,直接搞定。
你还可以在 openclaw.json 的 commands.aliases 里配置别名,把短名称(haiku、sonnet、opus、flash)映射到完整 provider 字符串。每次切换都能少敲几个字。
算一笔账:每天 50 个查询都用 Sonnet,大约是每天 3 美元。同样 50 个查询如果按 70/20/10 分配到 Haiku/Sonnet/Opus,大约是每天 1.10 美元。按月算就是从 90 美元降到 33 美元——便宜了 63%,而你什么工具都不用换,只需要改习惯。
加餐:用 Thunderbit 追踪不同提供商的 OpenClaw 模型价格
使用 AI 追踪不同提供商的模型价格 Get Started Free
随着模型和提供商越来越多——OpenRouter、Anthropic 直连 API、Google AI Studio、DeepSeek、MiniMax——价格变动也越来越频繁。Anthropic 曾一夜之间把 Opus 的输出定价砍了约 67%。Google 也在 2025 年 12 月把 Gemini 免费层限制下调了 50–80%。手工维护静态价格表,几乎注定会被现实打脸。
Thunderbit 不需要写任何爬虫代码就能解决这个问题。它是一款 Chrome 扩展,本质上就是为这种结构化数据提取场景而生的 AI 网页爬虫。
我常用的工作流是:
- 在 Chrome 里打开 OpenRouter 的模型页面,然后点 Thunderbit 的“AI Suggest Fields”。它会读取页面并自动建议列,例如模型名称、输入价格、输出价格、上下文窗口、提供商。
- 点击 Scrape,然后直接导出到 Google Sheets。
- 用自然语言设置定时抓取——比如“每周一上午 9 点重新抓取 OpenRouter 模型列表”——它就会自动在云端运行。
从那以后,你自己的价格跟踪表就能自动更新。任何突然降价 30% 的模型,或者带上 Exacto 标签的提供商,都会在你周一早上的表格里自动出现,完全不用你动手。我们还在博客里写过更多关于 面向企业的 AI 数据提取 用法。
如果你要对比各个直连提供商页面(Anthropic、Google、DeepSeek)的价格,Thunderbit 的子页面抓取会沿着每个模型链接进入详情页,提取各提供商费率——当你想知道把 Kimi K2.5 通过 OpenRouter 路由,是否比直接通过 NVIDIA Build 更便宜时,这个功能特别有用。到 Thunderbit pricing 查看免费层和套餐详情。
降低 OpenClaw token 使用量的核心总结
整体框架就是:理解 → 监控 → 路由 → 优化。
按影响程度从高到低,最值得做的事如下:
- 不要默认用 Opus。 把主模型切到 Sonnet 或 MiniMax M2.7,单这一项就能把成本降低 3–5 倍。
- 把 heartbeats 隔离出来。 设置
isolatedSession: true,并把 heartbeat 路由到 Gemini Flash-Lite。这样原本约 10 万 token 的耗费会变成约 2–5k。 - 把子代理路由到 Haiku。 每次生成子代理,都会先加载约 20k token 的上下文,然后才开始干活。别让这种事在 Opus 上发生。
- 认真执行
/clear。 免费,只要 5 秒,而且社区普遍认为它比任何单项操作都更能省钱。 - 添加
.clawignore。 排除node_modules、锁文件和构建产物,会显著减少 bootstrap 上下文。 - 在改动前后用
/context detail监控。 你测不到,就优化不了。
最便宜的模型要看任务而定。心跳用 Gemini Flash-Lite。日常编码用 MiniMax M2.7。需要稳定工具调用时用 Haiku。复杂多步任务交给 Sonnet。最难的问题才用 Opus——仅此而已。
大多数读者只要用配置 A 或 B,在一个下午内就能看到 50–70% 的节省。要达到完整的 85–90%,就需要把上面这些都叠加起来——模型路由、隐形耗费修复、.clawignore、会话纪律——但这完全可行,而且效果能持续保持。
常见问题
1. OpenClaw 每月大概要多少钱?
这完全取决于你的配置、使用量和模型选择。轻度用户(约 10 次查询/天)在优化后通常每月花 $5–30;默认配置下则常常是 $100+。中度用户(约 50 次查询/天)大约在每月 $90–400。重度用户默认情况下可能会达到 每月 $600–2,000+——有个极端案例单月甚至花了 $5,623。Anthropic 自己的内部遥测显示,中位数大约是 每位开发者活跃日 $13。
2. 目前最便宜、但还能用于编码的 OpenClaw 模型是哪一个?
MiniMax M2.5/M2.7 是最适合作为日常主力的选择——工具调用可靠性不错,SWE-Pro 56.22,价格大约是每百万 tokens 输入 $0.28、输出 $1.10。对于 heartbeat 和简单查询,Gemini 2.5 Flash-Lite(输入 $0.10、输出 $0.40)几乎没有对手。如果你需要很稳定的工具调用,又不想付 Sonnet 那么贵的价格,Claude Haiku 4.5(输入 $1、输出 $5)是最稳妥的中档回退。
3. 能在 OpenClaw 里用免费层模型吗?
技术上可以。GPT-OSS-120B 在 OpenRouter 的 :free 标签和 NVIDIA Build 上都是免费的。Gemini Flash-Lite 也有免费层(15 RPM、每天 1,000 次请求)。DeepSeek 注册时会送 500 万免费 tokens。但免费层通常限流更严、速度更慢,而且可用性不够稳定。对于日常使用来说,每百万 tokens 只要几分钱的低价付费模型,反而可靠得多。
4. 用 /model 在对话中途切换模型,会丢上下文吗?
不会。/model 会保留整个会话上下文——下一轮会在完整历史不变的情况下路由到新模型。OpenClaw 的概念文档里也验证了这一点,Claude Code 的行为也是一样。你可以在 Haiku 和 Sonnet 之间自由切换,不会丢任何内容。
5. 今天最快降低 OpenClaw 账单的方法是什么?
在无关任务之间输入 /clear。它免费,只要五秒,而且会清掉每次 API 调用都会重新发送的对话历史。有个真实会话显示,累计消息历史达到了 185,000 tokens——这些内容在每一轮里都被重新传输、重新计费。在开始新工作前先清空它,是你能养成的最高回报习惯。
试试 Thunderbit,轻松搞定 AI 网页爬取 Get Started Free




