

互联网里到处都是数据,而大家想把这些数据抓下来并加以利用的需求也在快速增长——不过,如果你去找一个单一的市场规模数字,会发现不同分析师给出的估算差别大得惊人,甚至能差出一个数量级,具体取决于他们统计的是软件、服务、代理,还是三者都算上。更准确地说:网页爬虫已经成了数据栈里那个“朴素但必不可少”的角落。
无论你是业务分析师、市场人员,还是单纯好奇的初学者,从网站获取数据的能力都正在变成一项必备技能。要是你跟我一样,大概也想跳过没完没了的复制粘贴,直接进入正题:可执行的洞察、干净整齐的表格,也许再来一点自动化的魔法。
这就是 Python 登场的地方。它是数据世界里的瑞士军刀——对初学者来说足够简单,对从单页抓取到成千上万页的爬取任务又足够强大。在这篇实战教程里,我会带你了解用 Python 进行网页爬虫的基础知识,演示如何处理动态网站,还会介绍我们的 Thunderbit——一款由 AI 驱动、无需代码的网页爬虫,让数据提取像点外卖一样简单。无论你是想学代码,还是只想找条快捷路,这里都适合你。
什么是网页爬虫?为什么要用 Python 从网站获取数据?
使用 AI 从任何网站抓取数据 Get Started Free
网页爬虫是一个自动化过程:从网站中提取信息,并把它转换成结构化格式——比如电子表格、CSV 或数据库——以便分析或用于业务场景 (PromptCloud)。爬虫不会像人工那样手动复制粘贴数据,而是模拟人类的操作,只不过速度更快、规模更大。
为什么这件事这么有价值?因为在当今商业世界里,数据驱动决策就是主旋律。规模越大,越需要用真实数字而不是感觉来支撑决策——而这些数字中的很多,最初都躺在别人的网页上。
想象一下:你可以每天监控竞争对手价格、汇总房源信息,或者构建定制化的潜在客户名单,而且几乎不费吹灰之力。
那为什么选 Python?下面是它成为网页爬虫首选语言的原因:
- 易读、简单: Python 语法简洁,对初学者很友好,写起爬虫脚本来既容易又好懂 (PromptCloud)。
- 生态丰富:
requests、BeautifulSoup、Scrapy和Selenium等库,让抓取、解析和自动化浏览器操作都变得轻而易举。 - 社区支持强: Python 长期稳居全球最受欢迎的编程语言之一,教程、论坛和代码示例多到数不清,随时都能帮到你。
- 可扩展性强: 从一次性的简单脚本,到大规模爬虫,Python 都能胜任。
一句话总结:无论你是完全的新手,还是经验丰富的分析师,Python 都是你进入网页数据世界的入场券。
入门:Python 网页爬虫教程基础
在开始写代码之前,我们先梳理一下用 Python 从网站获取数据的基本流程:
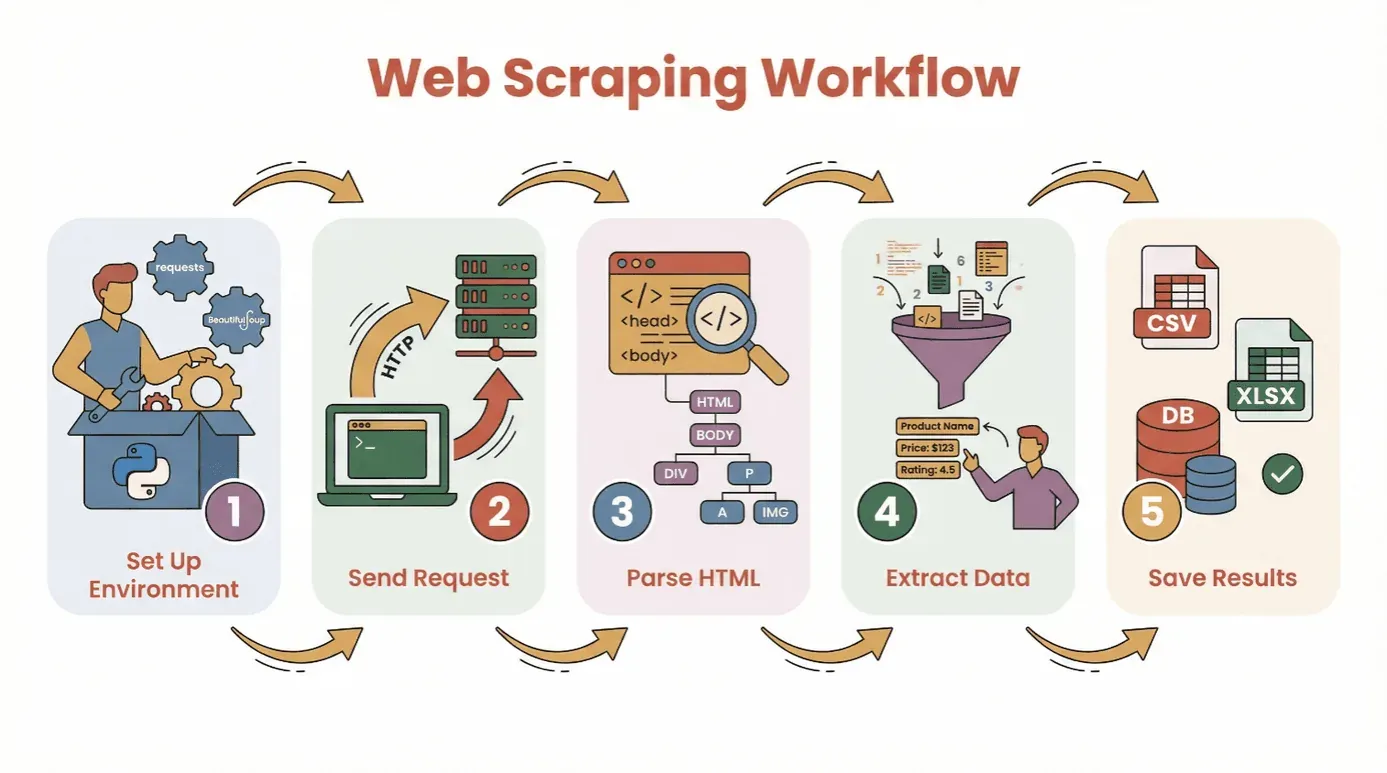
- 搭建环境: 安装 Python 和所需库(
requests、BeautifulSoup等)。 - 发送请求: 用 Python 获取目标网页的 HTML 内容。
- 解析 HTML: 使用解析器浏览页面结构。
- 提取数据: 定位并抓取你需要的信息。
- 保存结果: 将数据存入 CSV、Excel 文件或数据库中,便于分析。
你不需要是编程高手也能上手。只要你会安装 Python 并运行脚本,就已经成功一半了。对完全的新手来说,我建议使用 虚拟环境 或 Jupyter Notebook,不过你也可以用任何基础文本编辑器。
必备库:
requests— 用于获取网页BeautifulSoup— 用于解析 HTMLpandas— 用于保存和清洗数据(可选,但强烈推荐)
如何选择合适的 Python 网页爬虫库:BeautifulSoup、Scrapy 还是 Selenium?
并不是所有 Python 爬虫工具都一样。下面快速看看三种最受欢迎的选择:
| 工具 | 最适合 | 优势 | 不足 |
|---|---|---|---|
| BeautifulSoup | 简单、静态页面;初学者 | 易用、配置少、文档好 | 不适合大规模爬取或动态内容 |
| Scrapy | 大规模、多页面爬取 | 速度快、异步、内置数据管道、同时处理爬取和存储 | 学习曲线更陡,对小任务来说有点大材小用,也不执行 JavaScript |
| Selenium | 动态网站、JavaScript 密集型网站、自动化 | 能渲染 JS、模拟用户操作、支持登录和点击 | 更慢、更耗资源、配置更复杂 |
BeautifulSoup:简单 HTML 解析的首选
BeautifulSoup 非常适合初学者和小项目。它只用几行代码就能解析 HTML 并提取元素。如果你的目标网站基本是静态页面(没有复杂的 JavaScript 加载),那么 BeautifulSoup + requests 就够了。
示例:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
适用场景:一次性抓取、简单博客、商品页面或目录站点。
Scrapy:适合大规模或结构化爬取
Scrapy 是一个完整框架,适合爬取整站或处理成千上万页数据。它是异步的(也就是快),支持数据清洗和保存的管道,还能自动跟踪链接。
示例:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
适用场景:大型项目、定时爬取,或者你需要速度和结构化处理的时候。
Selenium:处理动态和 JavaScript 密集型网站
Selenium 控制的是真实浏览器(比如 Chrome 或 Firefox),因此它可以处理用 JavaScript 加载数据、需要登录或要点击按钮的网站。
示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
适用场景:社交媒体、股票网站、无限滚动页面,或者任何“查看源代码”时看起来空空如也的网站。
分步教程:如何使用 Python 从网站获取数据(适合初学者)
我们来用 requests 和 BeautifulSoup 做一个真实示例。接下来会爬取一个简单的图书列表网站,提取标题、作者和价格。
步骤 1:搭建 Python 环境
首先,安装你需要的库:
pip install requests beautifulsoup4 pandas
然后在脚本中导入它们:
import requests
from bs4 import BeautifulSoup
import pandas as pd
步骤 2:向网站发送请求
获取 HTML 内容:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"获取页面失败:{response.status_code}")
步骤 3:解析 HTML 内容
创建 BeautifulSoup 对象:
soup = BeautifulSoup(html, 'html.parser')
查找所有图书容器:
books = soup.find_all('article', class_='product_pod')
print(f"在此页面找到 {len(books)} 本书。")
步骤 4:提取你需要的数据
遍历每本书并抓取详情:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"标题": title, "价格": price})
步骤 5:保存数据供分析
转换成 DataFrame 并保存:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
现在你已经得到一个干净的 CSV 文件,可以直接用于分析了!
排错提示:
- 如果结果为空,检查数据是不是由 JavaScript 加载的(见下一节)。
- 一定要用浏览器开发者工具检查 HTML 结构。
- 对缺失数据使用
get_text(strip=True)和条件判断进行处理。
处理动态内容:从 JavaScript 渲染的网站获取数据
现代网站都很爱用 JavaScript。有时候,你想要的数据并不在最初的 HTML 里,而是在页面加载后才出现。如果你的爬虫抓不到内容,很可能就是遇到了动态内容。
处理方法:
- Selenium: 模拟真实浏览器,等待内容加载,还能点击按钮或滚动页面。
- Playwright/Puppeteer: 更高级,但思路类似(无头浏览器)。
Selenium 简明指南:
- 安装 Selenium 和浏览器驱动(例如 ChromeDriver)。
- 使用显式等待,让内容有时间加载。
- 提取渲染后的 HTML,必要时再用 BeautifulSoup 解析。
示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 按前面的方式提取数据
driver.quit()
什么时候需要 Selenium?
- 如果
requests.get()返回的 HTML 里没有数据,但你在浏览器里能看到。 - 如果网站使用无限滚动、弹窗,或者需要登录。
用 AI 简化网页爬虫:借助 Thunderbit 从网站获取数据
试用 Thunderbit AI 网页爬虫 只需 2 次点击,就能从任何网站获取数据——无需代码。 Get Started Free
说实话,有时候你只想要数据,不想写代码。这时 Thunderbit 就派上用场了。Thunderbit 是一款由 AI 驱动的 Chrome 扩展,只需点几下,就能从任何网站抓取数据——完全不需要 Python。
Thunderbit 的工作方式:
- 安装 Thunderbit Chrome 扩展。
- 打开目标网站。
- 点击 Thunderbit 图标,然后选择“AI 建议字段”。 Thunderbit 的 AI 会扫描页面,并推荐要提取哪些数据(例如商品名称、价格、邮箱)。
- 按需调整字段,然后点击“抓取”。
- 将数据直接导出到 Excel、Google 表格、Notion 或 Airtable。
Thunderbit 的优势:
- 无需编写代码。 连我妈都会用(虽然她还是会因为 Wi‑Fi 问题来问我)。
- 支持子页面和分页。 需要抓取多页商品详情?Thunderbit 可以自动点进去,并帮你把数据合并好。
- 自然语言指令。 只要告诉它你要什么(比如“提取所有商品标题和价格”),AI 就会自己处理。
- 热门网站一键模板。 Amazon、Zillow、领英等网站,点一下就能开始。
- 免费导出数据。 可以下载为 CSV、Excel,或者直接推送到你常用的工具中。
Thunderbit 已获得全球超过10 万用户信赖。它提供免费层级,你可以先试用,无需付费——当前可用额度请查看价格页面,因为限制条件这段时间调整过几次。对企业用户来说,它能节省大量时间;对 Python 用户来说,它也是在决定是否要自己写爬虫前,用来评估项目范围的好帮手。
爬取后:用 Pandas 和 NumPy 清洗并分析数据
获取数据只是第一步。原始网页数据通常很乱——重复项、缺失值、奇怪的格式都会出现。这正是 Python 的 pandas 和 NumPy 大显身手的时候。
常见清洗任务:
- 去重:
df.drop_duplicates(inplace=True) - 处理缺失值:
df.fillna('Unknown')或df.dropna() - 转换数据类型:
df['Price'] = df['Price'].str.replace('$','').astype(float) - 解析日期:
df['Date'] = pd.to_datetime(df['Date']) - 筛选异常值:
df = df[df['Price'] > 0]
基础分析:
- 汇总统计:
df.describe() - 按类别分组:
df.groupby('Category')['Price'].mean() - 快速作图:
df['Price'].hist()或df.groupby('Category')['Price'].mean().plot(kind='bar')
如果你需要更高级的数学计算或快速数组操作,NumPy 也很有用。不过对大多数商业用户来说,pandas 已经能覆盖 95% 的需求。
资源: 如果你刚接触 pandas,可以看看10 分钟上手 pandas这份指南。
成功进行 Python 网页爬虫的最佳实践与建议
网页爬虫很强大,但也伴随着责任。下面是我常用的检查清单,帮助你专业地抓取数据(而不是被封或被起诉):
- 尊重 robots.txt 和服务条款。 一定先确认网站是否允许爬取 (PromptCloud)。
- 不要给服务器施加过大压力。 在请求之间加延迟(
time.sleep(2)),并以接近人工的速度抓取。 - 使用真实的请求头。 设置 User-Agent 字符串来模拟浏览器。
- 妥善处理错误。 使用 try/except 结构,并对失败请求进行重试。
- 必要时轮换代理。 对于大规模爬取,可以考虑使用代理池,避免 IP 被封。
- 保持合乎伦理并遵守法律。 未经许可,不要抓取个人数据或登录后才能看到的内容。
- 记录你的流程。 记下抓了什么、从哪里抓、什么时候抓的。
- 能用官方 API 就用。 有时候,处理 HTML 之外还有更好的方式。
想了解更多技巧,可以看看终极网页爬虫指南。
结论与核心要点
对任何想把杂乱的互联网内容变成结构化、可执行数据的人来说,Python 网页爬虫都是一种超能力。无论你使用代码(requests、BeautifulSoup、Scrapy 或 Selenium),还是像 Thunderbit 这样的免代码工具,你都能从网站中获取数据,解锁新的洞察。
记住:
- 从简单开始——先爬一个页面,再挑战大项目。
- 根据需求选择合适工具(基础用 BeautifulSoup,规模化用 Scrapy,动态网站用 Selenium,免代码用 Thunderbit)。
- 用 pandas 和 NumPy 清洗并分析数据。
- 始终以负责任、合乎伦理的方式进行爬取。
准备好自己试试了吗?先从一个小项目开始——比如抓取今天的新闻标题或一份商品列表——看看你能多快从原始网页走到干净的电子表格。如果你想跳过写代码这一步,下载 Thunderbit,让 AI 帮你完成繁重工作。
想了解更多教程、技巧和网页爬虫知识,可以看看 Thunderbit 博客。
常见问题
1. 什么是网页爬虫,为什么 Python 如此受欢迎?
网页爬虫是指从网站中自动提取数据。Python 之所以受欢迎,是因为它语法易读、库强大(如 BeautifulSoup、Scrapy 和 Selenium),并且拥有活跃的社区支持 (PromptCloud)。
2. 我应该用哪个 Python 库来做网页爬虫?
简单、静态页面用 BeautifulSoup;大规模或多页面爬取用 Scrapy;动态或 JavaScript 密集型网站用 Selenium。根据你的需求,它们各有优势 (IPRoyal)。
3. 如何处理用 JavaScript 加载数据的网站?
对于由 JavaScript 渲染的内容,可以用 Selenium(或 Playwright)模拟浏览器,在提取数据前等待内容加载。有时,通过查看网络请求,还能找到底层 API 接口。
4. Thunderbit 是什么?它如何简化网页爬虫?
Thunderbit 是一款由 AI 驱动的 Chrome 扩展,可以让你无需编程就从任何网站抓取数据。它会用 AI 建议字段、处理子页面和分页,并能直接导出到 Excel、Google 表格、Notion 或 Airtable。
5. 如何在 Python 中清洗和分析抓取到的数据?
使用 pandas 去重、处理缺失值、转换数据类型并进行分析。NumPy 适合数值运算。做可视化时,pandas 可与 Matplotlib 集成,快速生成图表 (10 分钟上手 pandas)。
祝你抓取顺利——愿你的数据始终干净、结构清晰,并随时可用。
试用 AI 网页爬虫 Get Started Free
了解更多




