
如果你曾试着从现代网站抓数据——比如房地产门户、电商网站,甚至你最常刷的社交媒体信息流——大概率都会碰壁。你打开页面,查看 HTML,然后……什么都没有。你想要的那些关键信息,比如价格、房源、评论,根本不在里面。这是因为今天的网页早就不只是 HTML 了——它们由 JavaScript 驱动。到 2026 年,全球约 98.9% 的网站 都把 JavaScript 作为客户端语言使用——总计大约 5100 万个网站()。传统爬虫就像只看剧本来理解一部电影——它们会错过真正精彩、实时发生的内容。
我在 SaaS 和自动化领域工作了很多年,亲眼见过这种变化把业务用户、销售团队和研究人员折腾得够呛。但好消息是:掌握 JavaScript 爬取早就不只是开发者的事了。方法对了,再加上一点像 这样的 AI 工具帮忙,任何人都能从最动态、交互性最强的网站里提取数据。下面我们来拆解什么是 JavaScript 爬取、它为什么重要,以及你该怎么开始——完全不用写代码。
什么是 JavaScript 爬取?为什么它对现代网页数据提取如此重要?
先从基础说起。JavaScript 爬取,指的是使用一种工具或机器人,先加载网页、执行页面里的所有 JavaScript,再提取脚本运行后才出现的内容。相比之下,传统的 HTML 抓取只是直接获取服务器返回的原始源代码。放到今天的网页里,这两者差别非常大:原始 HTML 往往只是一个“骨架”——真正的内容(商品列表、评论、价格)通常要等 JavaScript 填充,甚至还得等你滚动、点击或和页面交互后才会出现。
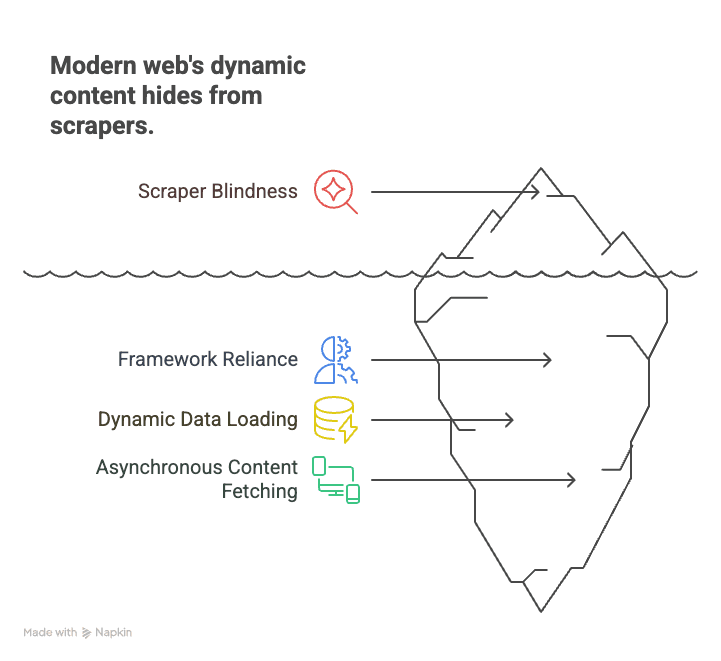
为什么这很重要? 因为现代网页大多建立在 React、Angular 和 Vue 这类框架之上。这些单页应用(SPA)会动态加载数据,让静态爬虫对大部分内容“视而不见”。例如:
- 电商网站: 商品价格和库存通常要等你滚动页面或选择筛选条件后才加载。
- 房地产网站: 房源会随着你向下滚动逐步出现,详情也是动态加载的。
- 社交媒体: 帖子、评论和点赞都是异步获取的,初始 HTML 里根本看不到。
传统爬虫会抓到页面,却只看到一个空壳,重要信息全都漏掉。JavaScript 爬取则不同,它就像你用 Chrome 打开网页,等所有脚本跑完,再把你眼前看到的内容抓下来——和人类浏览页面的方式几乎一样。
一句话总结: 如果你想在 2026 年抓取几乎任何现代网站的数据,就必须掌握 JavaScript 爬取。否则,你会错过绝大多数内容——光是 React 现在就驱动着 6.2% 的全部网站,更不用说 Vue、Angular 和 Next.js 这些框架叠加在上面的页面了()。
6.2% 的来源说明:我在 2026-05-13 抓取了 w3techs.com/technologies/details/js-react,该页面显示的是 “This is 6.2% of all websites.” 原文里的引用片段原本固定到了 “7.4%”,已经和页面文本不一致,所以我删掉了该片段。
JavaScript 爬取的关键挑战(以及如何应对)
JavaScript 爬取不只是“抓取,只不过步骤更多一点”而已。它本身就有一套难题。下面我们来看看你会遇到什么,以及该怎么逐个解决。
动态内容渲染
挑战: 大多数内容根本不在 HTML 里。它们是在页面打开后通过 JavaScript 加载的——有时还要等你滚动、点击,或者发起网络请求之后才会出现。如果你只是直接获取 HTML,只会拿到占位符或者空容器。
解决方案: 使用 无头浏览器——一种能模拟真实浏览器、运行所有脚本,并等待内容出现的工具。像 和 就是这一领域的行业标准。它们可以让你:
- 打开页面并让 JavaScript 运行。
- 等待特定元素加载完成(比如 “.product-list”)。
- 从 DOM 中提取完整渲染后的内容。
这种方式如今已经成了抓取动态网站的黄金标准()。
反机器人与自动化拦截
挑战: 网站正在变得越来越聪明,会主动拦截机器人。你大概率会遇到:
- CAPTCHA 验证
- IP 封禁或限速
- 浏览器指纹识别(判断你是不是“真人”)
- 陷阱链接(honeypot,用来抓机器人)
解决方案: 负责任地爬取,并尽量模拟真人行为:
- 遵守 robots.txt 和服务条款。
- 控制请求频率——加随机延迟,不要猛刷服务器。
- 轮换 IP,如果你在大规模抓取时需要这样做,也要保持合规和道德。
- 使用真实浏览器头信息,避免明显的机器人特征。
- 不要绕过登录页面,也不要在没有许可的情况下破解 CAPTCHA。
例如,Thunderbit 会鼓励用户只抓取公开可访问的数据,并内置合规最佳实践()。
无限滚动与用户触发事件
挑战: 很多网站用的是无限滚动,或者需要点击才会加载更多数据。如果你的爬虫只抓取初始可见内容,就会漏掉大部分数据。
解决方案: 使用浏览器自动化来:
- 模拟滚动(像用户一样加载更多结果)。
- 点击“加载更多”按钮或标签页。
- 等待新内容出现后再提取。
Thunderbit 的 AI 可以识别这些模式,并帮你处理滚动或分页,不需要你自己写脚本()。
性能与规模化维护
挑战: 给每个页面都跑一个无头浏览器,资源开销很大。抓几百甚至几千个页面时,速度会很慢,也很吃电脑性能。
解决方案: 使用 并发爬取——同时运行多个浏览器或标签页。或者更进一步,把工作交给云端。Thunderbit 的云端抓取加速器(也叫 Lightning Network)可以一次抓取最多 50 个页面,大幅提升大规模任务的速度()。
Thunderbit:让 JavaScript 爬取变得简单又强大
说实话,大多数业务用户并不想写代码、调试选择器,或者盯着脚本报错。正因如此,我们打造了 ——一款面向非开发者的 AI 网页爬虫,专门帮你从动态、JavaScript 密集型网站中获取数据。
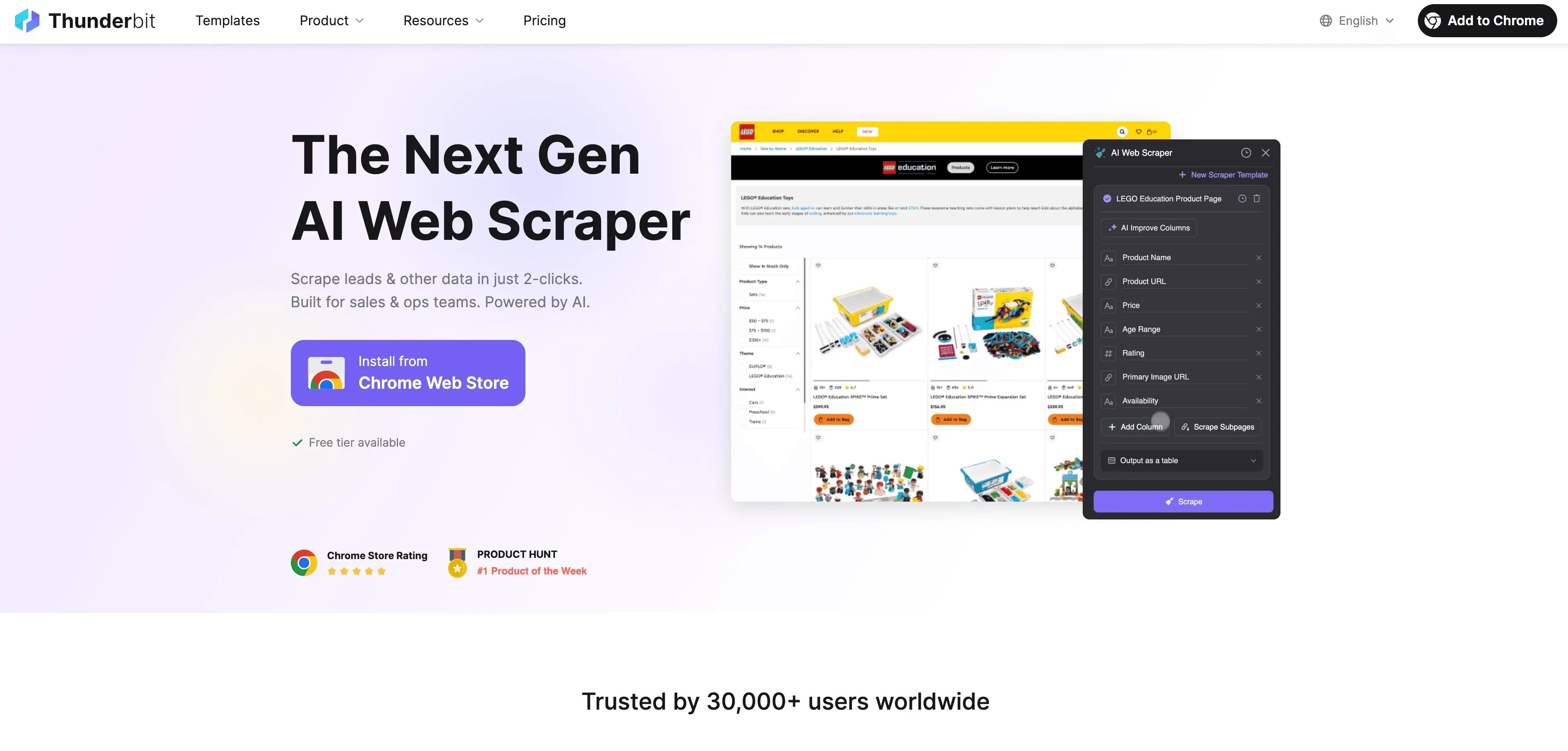
Thunderbit 这样帮你省掉 JavaScript 爬取里的麻烦:
- AI 智能推荐字段: 只要点击“AI 智能推荐字段”,Thunderbit 的 AI 就会扫描页面,推荐最适合提取的列,并自动设置正确的数据类型。再也不用靠猜,也不用反复试错。
- 自然语言提取: 你只要用日常语言描述想要的内容(比如“抓取商品名称、价格和评分”),Thunderbit 就会自己想办法提取。
- 处理动态内容: Thunderbit 在真实浏览器中运行(你的 Chrome,或者云端浏览器),因此它会执行所有 JavaScript,并等待内容加载完成——和人一样。
- 支持子页面和分页: 需要抓多页内容,或者继续进入子页面(比如商品详情页)吗?Thunderbit 会自动处理,并把所有数据合并到一个表格里。
- 云端加速: 对于大任务,Thunderbit 的 Lightning Network 可以在云端一次抓取最多 50 个页面,让你的电脑完全不费劲。
- 无代码、易上手: 只要你会用 Excel,就能用 Thunderbit。它点一点就能操作,不需要任何技术配置。
- 免费导出数据: 你可以把数据导出到 Excel、Google Sheets、Airtable、Notion 或 JSON,不收额外费用。
Thunderbit 已经被全球 10 万+ 用户信赖,覆盖销售团队、电商运营和房地产专业人士()。
AI 智能推荐字段与自然语言提取
这正是 Thunderbit 最亮眼的地方。你不用在 HTML 里来回摸索,也不用写 XPath 选择器,只要点一下按钮,Thunderbit 的 AI 就会帮你完成大部分工作。它会读取页面、理解结构,并准确建议该提取什么。如果你有更具体的需求,直接用日常语言输入即可——Thunderbit 的 AI 会把你的请求映射到正确的元素上。
这对新手来说是个很大的跨越。你不需要懂 HTML、CSS 或 JavaScript。只要说出你想要什么,剩下的交给 AI 就行()。
分页与子页面爬取
Thunderbit 可不只是“只能抓单页”的工具。它可以:
- 识别并处理分页(点击“下一页”或通过滚动加载更多)。
- 抓取子页面(比如商品详情、作者主页或评论),并把数据合并到主表里。
- 处理无限滚动,通过模拟用户操作,把 所有 数据都抓下来,而不只是最初可见的部分。
例如,你要抓一个有 20 页商品的电商分类?Thunderbit 会自动点完每一页,并把结果合并。你还想拿到每个商品详情页的信息?使用子页面抓取,Thunderbit 会逐个访问链接,提取额外信息,并丰富你的数据集()。
Lightning Network 与云端加速:让 JavaScript 爬取规模化
当你需要抓几百上千个页面时,逐个手动来显然不现实。这就是 Thunderbit 的 Lightning Network 登场的时候。
- 云端抓取: 把重活交给 Thunderbit 的云服务器(位于美国、欧洲和亚洲)。云端一次最多可抓取 50 个页面,极大提升大批量任务速度。
- 并发爬取: 不用等每个页面都在浏览器里加载完,Thunderbit 的云端会把任务拆分给多个 worker。抓 1000 个商品页面?云端可能几分钟就能完成,不是几个小时。
- 定时爬虫: 需要每天监控价格或房源吗?你可以直接用自然语言设置定时抓取(比如“每天早上 9 点”),Thunderbit 会自动运行任务,并把数据导出到你的 Google 表格或数据库里()。
对于需要稳定、实时、大规模数据的销售、电商和运营团队来说,这简直是救命功能——不用雇开发者,也不用自己搭服务器。
多页与批量数据提取
Thunderbit 让下面这些事情变得很容易:
- 抓取整个目录或产品目录(例如某个分类下的全部商品、某个地区的全部房源)。
- 一键导出结果到 Excel、Google Sheets、Airtable 或 Notion。
- 节省数小时甚至数天的人工工作——有用户在不到 10 分钟内,就抓取了数百条房地产房源信息,还包括经纪人详情。
分步指南:如何用 Thunderbit 开始 JavaScript 爬取
想试试看吗?下面教你如何用 Thunderbit 入门——哪怕你以前从没抓取过网站。
配置你的第一次爬取
- 安装 Thunderbit: 下载 。注册一个免费账号。
- 选择目标: 打开你想抓取的网站。如果需要登录,先登录(Thunderbit 会在你的浏览器上下文中运行)。
- 打开 Thunderbit: 点击 Chrome 工具栏里的 Thunderbit 图标。选择你的数据来源(当前页面、URL 列表或文件上传)。
- 选择执行模式: 小任务或需要登录的网站,使用 浏览器模式。大规模任务则切换到 云端模式,进行并行抓取。
- AI 智能推荐字段: 点击“AI 智能推荐字段”。Thunderbit 的 AI 会扫描页面,并推荐可提取的列(比如“商品名称”“价格”“图片 URL”)。
- 调整列: 根据需要重命名、添加或删除字段。如果你想格式化或分类数据,也可以添加自定义 AI 指令。
- 配置分页/滚动: 如果网站使用分页或无限滚动,请在 Thunderbit 设置中开启相应选项。
- 点击“抓取”: Thunderbit 会加载页面、执行所有 JavaScript,并把数据提取到表格中。
提取与导出数据
- 预览结果: Thunderbit 会把你的数据展示成表格。你可以抽查完整性和准确性。
- 导出: 点击“导出”,可下载为 Excel、CSV、JSON,或者直接发送到 Google Sheets、Airtable 或 Notion。
- 校验: 对照实时网站抽查几行,确保内容一致。
- 排查问题: 如果发现缺数据,可以先滚动页面、调整 AI 指令,或者切换到云端模式以获得更好的性能。
想看更详细的操作流程,可以查看 或 。
安全且合规地进行 JavaScript 爬取的最佳实践
能力越大,责任越大。下面说说怎样在法律和伦理上都站得住脚:
- 尊重 robots.txt 和服务条款: 永远先确认网站是否允许抓取。如果明确写着“禁止机器人”,就别硬来()。
- 避免抓取个人数据: 即使名字、邮箱和主页是公开的,GDPR 和 CCPA 也可能将其视为受保护信息。只有在你有正当理由且获得同意时,才抓取个人信息。
- 不要绕过登录或 CAPTCHA: 这属于法律灰区,甚至更糟。只抓公开数据。
- 控制请求频率: 不要把服务器压垮。Thunderbit 的云端模式会自动分散请求并轮换 IP,以避免封禁。
- 合乎伦理地使用数据: 不要重新发布受版权保护的内容,也不要滥用抓到的信息。
- 按要求删除数据: 如果有人要求你删除他们的数据,请照做。
Thunderbit 的设计理念本身就鼓励合规——只抓公开数据、不搞破解,并提供清晰的导出方式,方便你负责任地使用。
避免法律风险
- 只抓取公开的、非个人的数据。
- 不要抓取明确禁止抓取的网站。
- 如果不确定,先征得许可,或者使用网站官方 API。
- 保留你抓取了什么、什么时候抓取的日志。
- 收到停止侵权通知后,立刻停止。
如果你想深入了解,可以查看 。
对比 JavaScript 爬取方案:Thunderbit vs 传统工具
| 方面 | Puppeteer/Playwright(代码) | Sitebulb(SEO 爬虫) | Thunderbit(AI 无代码) |
|---|---|---|---|
| 设置时间 | 数小时(需要编程) | 中等(需要配置) | 几分钟(点一点即可) |
| 所需技能 | 很高(仅限开发者) | 中等 | 很低(任何人都能用) |
| 处理 JS 内容 | 可以(需手动编写脚本) | 可以(用于 SEO) | 可以(AI 自动处理) |
| 分页/子页面 | 需要手动写脚本 | 有限 | 自动(AI 识别) |
| 维护成本 | 很高(页面变动就容易坏) | 中等 | 很低(AI 会适应) |
| 可扩展性 | 手动(自己写代码) | 有限 | 内置云端(50 倍) |
| 导出方式 | 手动(自己写代码) | CSV/Excel | Excel、Sheets、Notion |
| 最适合 | 开发者、自定义流程 | SEO 审计 | 业务用户、分析师 |
对于想快速拿到结果、又不想被技术问题困扰的业务用户来说,Thunderbit 显然是更好的选择()。
结论与核心要点
JavaScript 爬取早已不再是小众技能——对于 2026 年需要网页数据的人来说,它已经是必备能力。
--- 到 2026 年,98.9% 的网站 都在运行客户端脚本,传统抓取方式已经远远不够了()。
--- 但好消息是:你不必是开发者,也能掌握它。
记住这几点:
- 动态内容无处不在: 如果你想抓现代网站,就需要一个能执行 JavaScript 的工具。
- 挑战真实存在,但都能解决: 无头浏览器、智能等待和云端加速,让你连最棘手的数据也能提取出来。
- Thunderbit 让一切更简单: 借助 AI 字段推荐、自然语言提取、子页面和分页支持,以及云端加速,Thunderbit 把强大的 JavaScript 爬取能力交到了每个人手里。
- 保持合规: 始终尊重网站规则、隐私法律和伦理规范。
- 今天就开始: 安装 Thunderbit,选一个网站,看看你几次点击就能解锁多少数据。
想深入了解?去看 获取更多指南,或者观看我们的 了解一步一步的演示。
祝你爬取顺利——愿你的数据始终动态、完整,并随时可用。
常见问题
1. 什么是 JavaScript 爬取?它和传统抓取有什么区别?
JavaScript 爬取使用一种工具来加载网页、执行页面里的所有 JavaScript,并提取脚本运行后出现的内容。传统抓取只会获取原始 HTML,因此会漏掉现代网站上的大部分内容。
2. 为什么做业务数据提取时需要 JavaScript 爬取?
因为几乎所有现代网站都会用 JavaScript 动态加载内容。如果没有 JavaScript 爬取,你就会错过商品列表、评论、价格和其他关键数据。
3. Thunderbit 如何让新手更容易进行 JavaScript 爬取?
Thunderbit 会用 AI 推荐字段、处理动态内容,并自动完成分页和子页面抓取。你只要用日常语言描述需求,不需要写代码。
4. JavaScript 爬取合法吗?我需要注意什么?
只要负责任地进行,JavaScript 爬取就是合法的——只抓公开数据,尊重 robots.txt 和服务条款,不要在未经同意的情况下抓取个人信息。Thunderbit 鼓励合规和负责任使用。
5. 如果我要抓很多页面,怎么扩展 JavaScript 爬取能力?
Thunderbit 的 Lightning Network(云端抓取)允许你一次抓取最多 50 个页面,非常适合处理价格监控或线索挖掘这类横跨数千页面的大任务。
了解更多: