

互联网里到处都是数据——多到已经成了现代商业的命脉。无论你是做销售、电商、房地产,还是只是想随时掌握竞争对手的动向,手边有合适的数据,往往就能决定成败。说实话,没人愿意花几个小时把网站上的信息复制粘贴到表格里。这正是网页爬虫派上用场的时候,而且相信我,它比听起来简单得多。
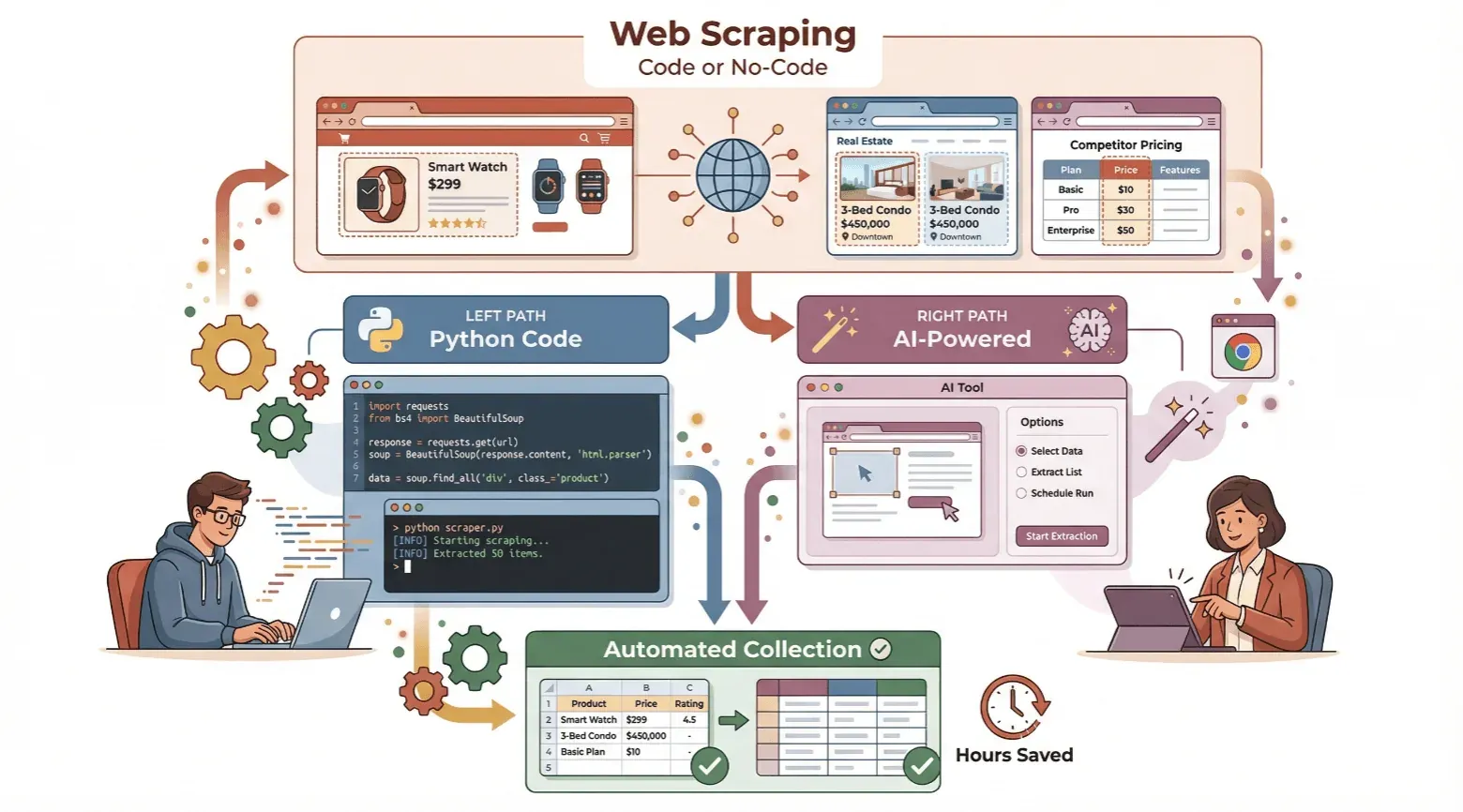
在这篇指南里,我会带你一步步了解如何创建网页爬虫——不管你是想用 Python 试试写代码的新手,还是更想跳过代码,直接用像 Thunderbit 这样的无代码 AI 工具。我会把基础概念拆开讲,分别演示这两种方法,并帮你判断哪条路更适合你。准备好节省时间,释放自动化数据采集的威力了吗?我们开始吧。
什么是网页爬虫?先理解基础概念
网页爬虫,本质上就是一种工具——软件或服务——它可以自动从网站中提取信息。想象一下,你需要整理出你所在城市所有咖啡店的名单,还要包含地址和电话号码。你可以花几个小时一页页点开、手工复制每一项信息(你好,Ctrl+C 疲劳),也可以让网页爬虫替你完成这些繁琐工作。
你可以把网页爬虫想成一个数字助手:它会读取网页,找到你想要的数据(比如价格、商品名或联系方式),然后把数据整整齐齐地整理成电子表格或数据库。你不用再手动在浏览器标签页和 Excel 之间来回切换,爬虫会自动完成抓取、解析和保存,速度快得多。
它在底层大致是这么工作的:
- 请求: 爬虫向网页发送请求,下载原始 HTML。
- 解析: 它分析 HTML,找到你要的具体数据(比如
<span>标签里的价格)。 - 提取: 它把数据提取出来,并保存成结构化格式(CSV、Excel、Google Sheets 等)。
手动复制粘贴,就像用勺子挖坑。网页爬取,则像是直接开来一台挖掘机。
为什么创建网页爬虫对业务很重要
网页爬取不只是技术人员或数据科学家的专属技能——它已经成为任何需要可靠、最新信息的人都离不开的工具。几乎 97% 的大型组织 现在都在投资数据驱动决策,而且分析师对网页爬取市场的覆盖也一直预测,到本十年末仍将保持多年持续增长。
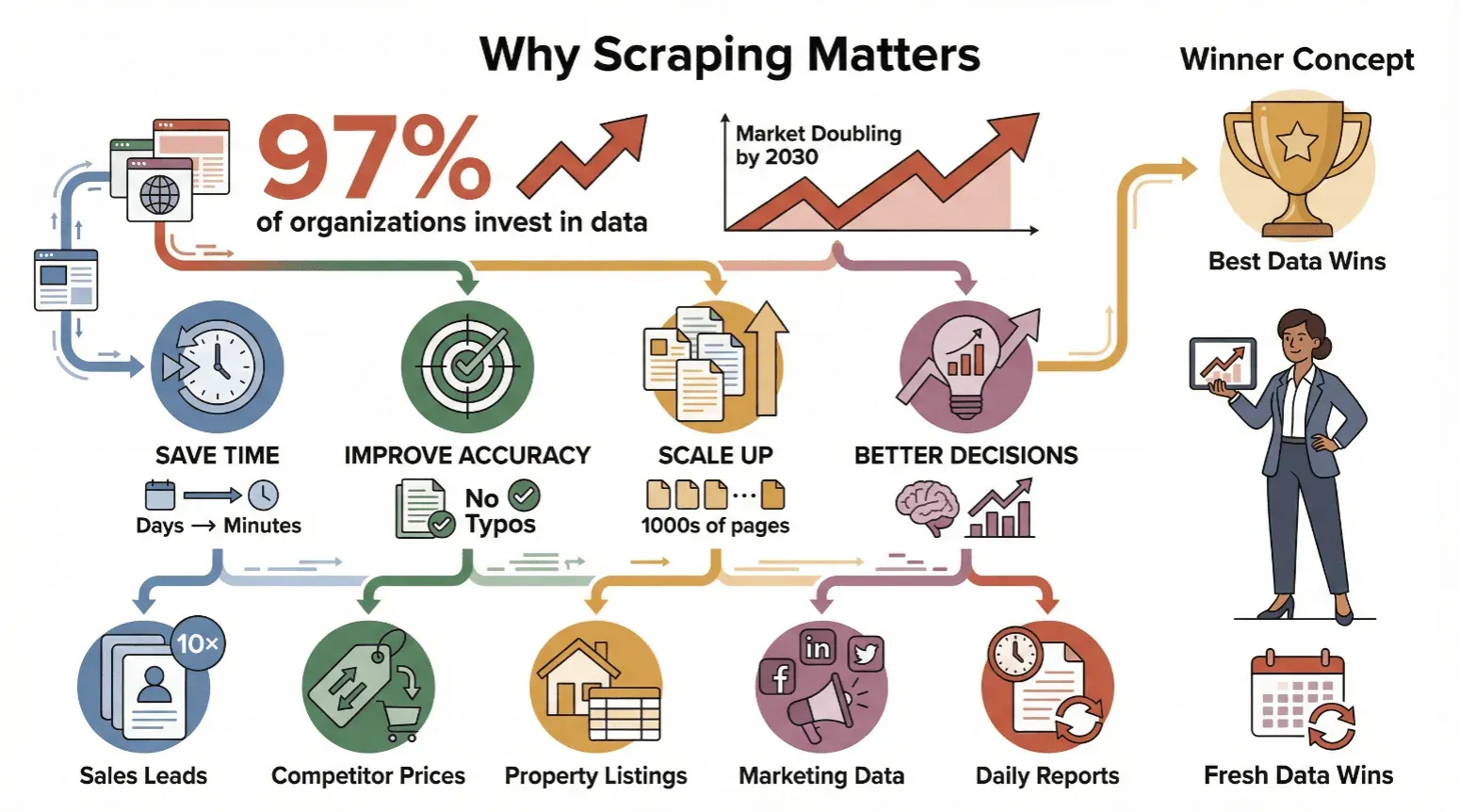
以下是各类企业都在拥抱网页爬取的原因:
- 节省时间: 自动化爬取能把原本要花几天的人工工作压缩成几分钟。
- 提高准确性: 软件不会疲劳,也不会手滑打错字。
- 轻松扩展: 可以抓取成千上万的页面,而不只是寥寥几个。
- 做出更好的决策: 新鲜数据意味着更聪明的行动——无论是调价、找线索,还是追踪趋势。
下面看看一些真实的应用场景:
| 使用场景 | 受益对象 | 典型结果 |
|---|---|---|
| 从名录中提取销售线索 | 销售团队 | 线索数量提升 10 倍,节省大量开发客户时间 |
| 监控电商网站上的竞品价格 | 电商经理 | 实时调价,保护利润率 |
| 汇总房地产房源信息 | 房地产中介机构 | 更快发现交易机会,获取最新市场数据 |
| 收集网页/社交媒体营销数据 | 营销团队 | 更精准的活动投放,更好的效果追踪 |
| 自动生成每日网页数据报告 | 运营、分析师 | 降低人力成本,减少错误,报告持续且及时 |
一句话总结:谁拥有最好的、最新的数据,谁就赢。
新手指南:如何用 Python 创建一个简单的网页爬虫
如果你想了解网页爬取在“底层”是怎么运作的,Python 是一个很好的起点。哪怕你是刚接触编程,也能在几个步骤内搭出一个基础爬虫。方法如下:
配置你的环境
首先,你需要在电脑上安装 Python。前往 python.org 下载最新版本,并按照你的操作系统(Windows 或 Mac)提示完成安装。安装时记得勾选“Add Python to PATH”。
接下来,打开终端或命令提示符,安装所需的库:
pip install requests
pip install bs4
pip install pandas
requests用来获取网页内容。bs4(Beautiful Soup)帮助你解析 HTML。pandas很适合把数据保存到 CSV 或 Excel。
检查网站结构
在写代码之前,你需要先知道数据在 HTML 里的位置。用 Chrome 打开目标网站,右键点击你想抓取的内容(比如职位名称),然后选择“检查”。你会看到对应的 HTML 元素被高亮显示——可能是一个 <a> 标签,class 名叫 jobtitle。记下这些标签和 class,之后你会用它们告诉爬虫要找什么。
编写并运行爬虫
假设你想从职位列表页面抓取职位名称和公司名。下面是一个简单脚本:
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # 替换成你的目标网址
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有职位名称和公司名(按需更新选择器)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# 保存为 CSV
df = pd.DataFrame({'职位名称': titles, '公司': companies})
df.to_csv('jobs.csv', index=False)
print("抓取完成!数据已保存到 jobs.csv")
- 根据你的目标网站调整网址和 class 名称。
- 在终端运行脚本:
python yourscript.py - 打开
jobs.csv查看结果。
专业提示: 如果网站更复杂(比如有分页或动态内容),你可能需要加入循环,或者使用 Selenium 之类的工具。不过对于很多静态页面,这种方法已经足够好用。
无代码的简单方式:如何用 Thunderbit 创建网页爬虫
那如果你根本不想碰代码呢?这正是 Thunderbit 的用武之地——它是一款面向商务用户的无代码、AI 驱动网页爬虫。对于结构清晰、页面规整的网站,Thunderbit 能让你从“我需要这些数据”直接走到一张可用的表格,只需要点几下;而面对带登录、反爬机制或布局特别奇怪的网站时,仍然需要一些调优,但相比手写解析器,门槛已经低得多。
用 AI 从任何网站抓取数据 Get Started Free
它的工作方式如下:
第 1 步:安装 Thunderbit Chrome 扩展
前往 Thunderbit Chrome 扩展下载页 并添加到浏览器中。注册一个免费账户(免费版可以抓取少量页面,方便你试用)。
第 2 步:打开你的目标网站
用 Chrome 打开你想抓取的页面。如果需要,先登录,然后向下滚动以加载动态内容。
第 3 步:描述你的数据需求
点击 Thunderbit 图标打开侧边栏。你可以:
- 点击 “AI 推荐字段”,让 Thunderbit 的 AI 扫描页面并自动建议列名(比如“商品名称”“价格”“图片”)。
- 或者直接输入一句自然语言提示词(例如:“提取本页所有书名和作者”)。
Thunderbit 的 AI 会自动推荐字段和数据类型。你也可以按需重命名、添加或删除字段。
第 4 步:运行你的第一次抓取
字段设置好之后,直接点击 “抓取”。Thunderbit 会提取数据,按需处理分页,并把所有内容整齐地展示成表格。如果你想从子页面获取更多详情(比如单个商品页面),点击 “抓取子页面”——Thunderbit 会逐个访问链接并抓取额外信息。
第 5 步:检查并导出结果
在 Thunderbit 表格里检查你的数据。满意后,点击 “导出”,然后选择格式:Excel、CSV、Google Sheets、Airtable、Notion 或 JSON。导出完全免费且不限次数。
就这么简单。无需代码,无需模板,也没有头疼问题。
传统网页爬虫方案 vs. 无代码方案对比
来看看这两种方法的表现如何:
| 方案 | 设置时间 | 所需技能 | 维护成本 | 灵活性 | 导出选项 |
|---|---|---|---|---|---|
| Python + Beautiful Soup | 数小时/数天 | 编程、HTML 基础 | 高(容易失效) | 非常高 | CSV、Excel、JSON(通过代码) |
| 早期无代码工具 | 30–60 分钟 | 一些技术知识 | 中等(需手动修复) | 适合静态页面 | CSV、Excel |
| Thunderbit(AI 无代码) | 几分钟 | 无(自然语言即可) | 低(AI 可自适应) | 高(适合动态网站) | Excel、CSV、Sheets、Notion... |
Thunderbit 这种 AI 驱动的方式,意味着你花在配置和修复爬虫上的时间更少,把更多时间真正用在数据上。
解决传统网页爬虫的常见难题
传统爬虫有几个出了名的痛点:
- 网站改版: 如果网站更新了布局,你的代码可能就失效了。Thunderbit 的 AI 会自动适应大多数变化,你不用重新写代码。
- 反爬机制: 很多网站会拦截自动化脚本。Thunderbit 可以在浏览器里运行(使用你的登录态),也可以在云端运行以提升速度。
- 动态内容: 有无限滚动或“加载更多”按钮的页面,基础爬虫常常抓不下来。Thunderbit 的 AI 默认支持自动滚动和交互元素。
- 需要登录的数据: 使用 Thunderbit 的浏览器模式,只要你在 Chrome 里看得到,基本就能抓到。
简单说,Thunderbit 就是为应对现代网站那些复杂、杂乱的现实情况而设计的——这样你就不用自己折腾了。
提升效率:Thunderbit 的高级网页爬取功能
Thunderbit 不只是为了拿到数据,更是为了让数据来得快、干净,而且随时可用。下面是我很喜欢的一些功能:
自动分页和子页面抓取
需要跨多个页面抓取数百个商品?Thunderbit 能识别分页(“下一页”按钮、无限滚动)并一次性抓全。想从子页面获取更多细节?点击“抓取子页面”,Thunderbit 会逐个访问链接,提取额外字段(比如卖家信息或商品规格)。
AI 字段建议和数据结构化
Thunderbit 的 AI 不只是猜列名,它能理解上下文。它可以自动给列命名、分配数据类型(文本、数字、图片、邮箱),甚至应用自定义指令(比如“只保留 100 美元以上的价格”或“把描述翻译成英文”)。你还可以添加提示词,在抓取过程中对数据进行分类、总结或重新格式化。
模板与即点即抓
对于热门网站(Amazon、Zillow、Google Maps、Instagram),Thunderbit 提供现成模板——只要选中网站,字段就已经预配置好了,无需设置。
定时与自动化
需要每天都有新数据?你可以设置定时任务(比如“每周一上午 9 点”),Thunderbit 就会自动抓取,并把结果更新到你的 Google Sheet 或数据库里,完全不用你动手。
云端抓取 vs. 本地抓取
你可以选择在浏览器中运行抓取(适合登录后页面或交互式网站),也可以在云端运行(抓公开数据更快,单次最多可处理 50 个页面)。
什么是数据抓取,以及 2025 年如何操作 Get Started Free
Thunderbit 的这些高级功能,使它成为需要可靠、可扩展、又易上手的网页爬取方案的商务用户首选。
分步骤指南:如何用 Thunderbit 创建网页爬虫
这是你的快速上手清单:
- 安装 Thunderbit: 添加 Chrome 扩展 并注册账号。
- 打开目标网站: 如有需要先登录,滚动页面加载内容。
- 打开 Thunderbit 侧边栏: 点击扩展图标。
- 描述你的数据: 点击“AI 推荐字段”或输入提示词。
- 检查字段: 按需重命名、添加或删除列。
- 点击“抓取”: 让 Thunderbit 自动完成。
- (可选)抓取子页面: 如需更深入的数据,点击“抓取子页面”。
- 检查结果: 核对表格中的准确性。
- 导出数据: 选择 Excel、CSV、Google Sheets、Notion、Airtable 或 JSON。
- 保存/模板/定时: 保存你的设置以便下次使用,或者设置重复抓取。
排查小贴士:
- 如果数据缺失,试着重新措辞提示词,或者使用自定义指令。
- 对于动态内容,请确认你处于浏览器模式。
- 如果碰到免费额度限制,可以考虑升级以抓取更多页面。
结论与核心要点
创建网页爬虫已经不再只是程序员的事了。无论你是想亲自上手写 Python,还是更愿意让 AI 承担繁重工作,现在的工具都比以往任何时候更容易上手。
你只要记住这些:
- 网页爬取能节省时间、提高准确性,并帮助你做出数据驱动的决策。
- Python 很适合学习和定制项目,但需要编程和维护。
- Thunderbit 提供了快速、无代码的解决方案——只要描述你要什么,然后点击“抓取”。
- 自动分页、子页面抓取和 AI 字段建议等高级功能,让 Thunderbit 成为商务用户的高效工具。
- 你可以免费试用 Thunderbit,并在几分钟内看到结果。
准备好告别复制粘贴,开始自动化了吗?下载 Thunderbit ,看看网页爬取能有多简单。如果你想深入了解,还可以查看 Thunderbit 博客 获取更多教程和技巧。
免费试用 Thunderbit AI 网页爬虫 Get Started Free
常见问题
1. 创建网页爬虫一定需要会编程吗?
不需要!虽然编程(比如 Python + Beautiful Soup)能让你完全掌控流程,但像 Thunderbit 这样的无代码工具,任何人都可以通过自然语言提示词和几次点击,创建强大的网页爬虫。
2. 我可以用 Thunderbit 抓取哪些类型的数据?
Thunderbit 可以从几乎任何网站中提取文本、数字、图片、邮箱、电话号码等内容——包括分页列表和子页面。你还可以为热门网站使用模板。
3. Thunderbit 如何处理布局变化的网站?
Thunderbit 的 AI 会自动适应大多数布局变化。和传统爬虫不同,网站一更新就失效,Thunderbit 依靠语义理解继续工作,只需极少调整。
4. 网页爬取合法吗,安全吗?
只要你抓取的是公开可获得的数据,并遵守网站的服务条款,网页爬取就是合法的。Thunderbit 鼓励负责任地使用,并提供功能帮助你保持合规。
5. 我可以设置定时抓取或自动导出吗?
可以!Thunderbit 允许你按任意间隔(每天、每周等)设置定时抓取,并直接导出到 Google Sheets、Notion、Airtable、Excel 或 CSV——无需手动操作。
准备好自动化你的数据采集了吗?免费试用 Thunderbit ,看看网页爬取对每个人来说能有多简单。
了解更多




