

我还记得自己第一次尝试抓取网站、整理销售线索名单时的情景。当时我心里还想:“嘿,我会 JavaScript,这能有多难?”结果几个小时后,我已经陷在一团乱麻般的选择器里,被不断消失的动态内容折腾得焦头烂额,还对反爬机制心生敬畏。事实证明,我并不孤单——如今90% 的企业都表示,数据对业务的重要性正在不断提升,而网页数据抓取正是这一趋势的核心。不过,随着网站越来越“花”,用 JavaScript 去抓取它们既像超能力,也像解谜题。
使用 AI 从任何网站抓取数据 Get Started Free
在这篇指南里,我会把自己在 JavaScript 网页抓取方面的经验全都分享给你——从基础入门到那些让人头大的复杂情况,再到像 Thunderbit 这样的现代 AI 工具,如何帮你摆脱选择器带来的头痛。不管你是在为电商团队整理商品列表,还是在为销售团队搭建线索管道,我们都来聊聊如何用 JavaScript 抓网页,再顺手借助一点 AI 的力量。
使用 JavaScript 进行网页抓取:基础知识与局限性
先从最基础的说起:使用 JavaScript 进行网页抓取,就是通过脚本程序从网站中提取数据,可以是在浏览器里运行脚本,也可以在后端用 Node.js 来完成。JavaScript 本身就是网页的语言,所以拿它来做抓取非常顺手——尤其是配合 Cheerio(适合解析静态 HTML)以及 Puppeteer 或 Playwright(用于无头浏览器自动化)这些成熟的库。
为什么 JavaScript 在抓取领域这么受欢迎?
- 可直接操作 DOM: 在浏览器里,你可以像真人一样直接“摸”DOM。
- 生态丰富: Node.js 让你能使用大量强大的库来发请求、解析页面、做自动化。
- 灵活性高: 登录、点击、滚动这些动作都能自动化;只要你在 Chrome 里能做,脚本通常也能做。
但问题来了:现代网站变化太快了。它们会用 JavaScript 动态加载内容、重排 DOM 节点,还会部署各种反爬手段。这意味着你的抓取脚本今天能跑,明天就可能报废。你会不断更新选择器、处理弹窗、追着异步加载的数据满世界跑。有点像打地鼠,只不过多了很多花括号。
为什么复杂网页会让 JavaScript 抓取变得更难
以前,网页抓取很简单:拿到 HTML,再解析出你想要的数据就行。但今天的网页已经不是当年的网页了。像 Facebook Marketplace、Amazon,甚至你本地的房产信息网站,往往都依赖 JavaScript 框架实时渲染内容,把数据藏在无限滚动里,或者塞进极其复杂的 DOM 结构中。
传统的 HTML 解析已经不够用了。比如,提取商品评论或嵌套评论,不只是找到正确的 <div> 那么简单;你还得理解元素之间的关系、每个字段的上下文,甚至数据背后的含义。
这时候,更智能的预处理就变得很重要了。你不能只是粗暴地抓一堆原始 HTML 然后祈祷一切顺利,而是需要一种方式去理解页面的语义:哪个是商品名,哪个是价格,哪个是用户评论?光靠传统 JavaScript 做这件事并不轻松,但这正是 AI 工具最能发挥作用的地方。
传统的 JavaScript 网页抓取方案
来聊聊工具。经典的 JavaScript 抓取技术栈通常会包含以下一种或多种工具:
- Cheerio: 非常适合解析静态 HTML。你可以把它理解为服务器端的 jQuery。
- Puppeteer/Playwright: 无头浏览器自动化工具。它们会启动一个真实浏览器,执行 JavaScript,并让你像真人一样与页面交互(或者像一个摄入过量咖啡因的机器人)。
典型流程如下:
- 请求页面(可以用无头浏览器,也可以不用)。
- 等待内容加载(有时会用
waitForSelector之类的方法)。 - 解析 DOM,找出你要的数据。
- 提取并整理 结果。
听起来很简单,对吧?但麻烦就在这:只要网站一改版,你的选择器就可能失效;网站一加弹窗,脚本就卡住;字段顺序一调整,数据就乱套。维护工作会变成永无止境的苦差事。
常见 JavaScript 抓取库对比
| 特性 | Cheerio | Puppeteer | Playwright |
|---|---|---|---|
| 最适合 | 静态 HTML | 动态页面 | 动态页面 |
| 浏览器自动化 | 否 | 是 | 是 |
| 支持 JS 内容 | 否 | 是 | 是 |
| 速度 | 快 | 较慢 | 较慢 |
| API 简洁度 | 简单 | 中等 | 中等 |
| 反爬规避能力 | 有限 | 中等 | 中等 |
| 跨浏览器支持 | 否 | 仅 Chrome | Chrome、Firefox、WebKit |
| 适用场景 | 简单网站、API | 交互式网站 | 交互式网站 |
Cheerio(目前版本线在 1.1.x)对静态页面或返回 HTML 的 API 来说速度飞快,但它无法执行 JavaScript。Puppeteer(24.x)和 Playwright(1.60.x)更适合处理动态内容,不过它们更重,配置也更复杂。两者都能实现登录、点击和滚动,但你仍然需要为网站抛出的每一个变化编写处理逻辑。如果你还需要 Firefox 或 WebKit,Playwright 依然更有优势;如果你想走更聚焦 Chrome 的路线,Puppeteer 会更直接。
认识 Thunderbit:面向 JavaScript 工作流的 AI 网页抓取工具
真正有意思的部分来了。在 Thunderbit,我们意识到网页抓取不只是抓 HTML,而是要像人一样理解页面。所以我们打造了 Thunderbit,一款 AI 网页爬虫 Chrome 扩展,把语义理解带入网页抓取流程。
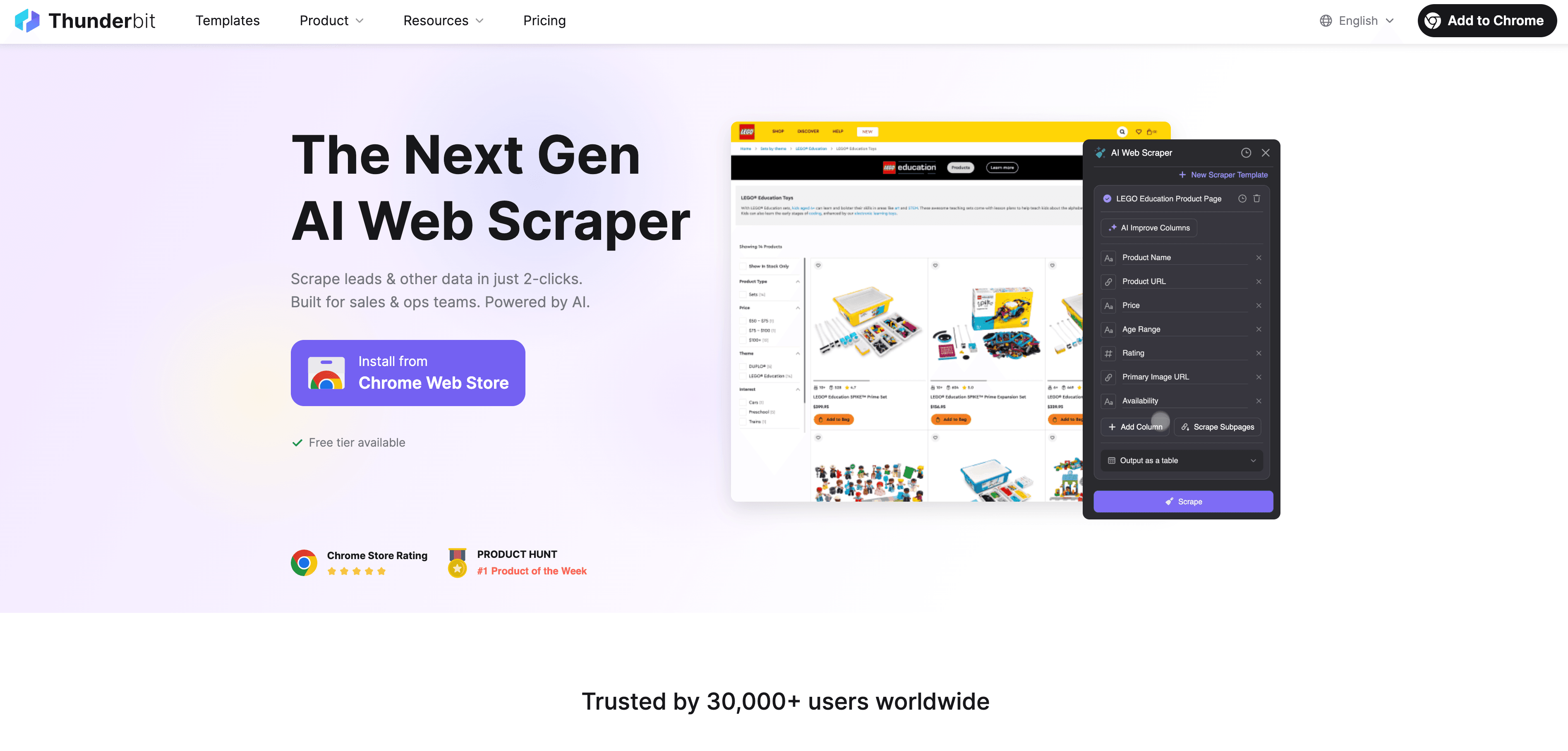
它是怎么工作的?
- Thunderbit 会先把网页转换成 Markdown 表示——你可以把它理解成更干净、更结构化的页面版本。
- 然后,AI 会分析这些 Markdown 内容,识别字段、关系和上下文,从而判断哪个是价格、哪个是评论、哪个只是装饰性的表情符号。
- 最终,你拿到的是结构清晰、带标签的数据,而且对页面布局变化、动态内容,甚至 DOM 层级变动都更有韧性。
对于业务用户来说,这意味着更少的手工清洗、更少的脚本报错、更多时间用于真正的分析洞察。对于开发者来说,则意味着你可以专注于自动化浏览部分(登录、点击、滚动),把繁琐的数据提取交给 Thunderbit。
分步教程:使用 JavaScript 进行网页抓取(传统方式与 Thunderbit 方案)
接下来我们实战一下。我会带你抓取一个电商示例网站上的商品列表。先用传统的 Puppeteer 方法来做,然后再展示如何把繁重的提取工作交给 Thunderbit,让整个流程更高效。
第一步:搭建 JavaScript 抓取环境
首先,你需要安装 Node.js——当前 Node 24 是 Active LTS 版本,Node 22 处于维护阶段,如果你想追新,Node 26 则是最新的 Current 版本。配置好之后,我们来安装 Puppeteer:
npm install puppeteer
如果你更喜欢 Playwright(它支持更多浏览器),可以这样安装:
npm install playwright
如果你不是技术背景,也不用担心:你不需要成为 JavaScript 高手。直接复制代码片段就行,我会解释每一部分的作用。
第二步:导航并与动态页面交互
现代网站很喜欢把数据藏在登录页、弹窗和无限滚动里。下面是用 Puppeteer 自动完成这些操作的方法:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// 进入登录页
await page.goto('https://example.com/login');
await page.type('#username', 'your_username');
await page.type('#password', 'your_password');
await page.click('#login-button');
await page.waitForNavigation();
// 打开商品列表页
await page.goto('https://example.com/products');
// 滚动加载更多内容
await page.evaluate(async () => {
for (let i = 0; i < 5; i++) {
window.scrollBy(0, window.innerHeight);
await new Promise(resolve => setTimeout(resolve, 1000));
}
});
// 等待商品加载完成
await page.waitForSelector('.product-card');
// ...(下一步我们会提取数据)
})();
这段脚本会完成登录、进入商品页,并通过滚动加载更多条目。关键点在于:一定要等元素出现,否则你抓到的可能只是一片空白。
第三步:用 JavaScript 提取数据
现在我们来抓数据。假设每个商品都放在一个 .product-card 的 div 里:
const products = await page.$$eval('.product-card', cards =>
cards.map(card => ({
name: card.querySelector('.product-title').innerText,
price: card.querySelector('.product-price').innerText,
link: card.querySelector('a').href,
}))
);
console.log(products);
常见坑点包括:
- 选择器很容易失效。 如果网站把
.product-title改成了.title,脚本就会崩。 - 隐藏数据。 有些价格或评论会在页面加载后通过 AJAX 再请求出来。
- 反爬机制。 请求太多,可能直接被封。
第四步:用 Thunderbit AI 强化提取能力
这时候 Thunderbit 就派上用场了。与其跟选择器和脆弱的逻辑死磕,不如把渲染后的 HTML(甚至截图)交给 Thunderbit,由 AI 来提取数据。
实际操作是怎样的?
- 先用 Puppeteer 或 Playwright 自动完成浏览、登录和跳转。
- 到达目标页面后,抓取页面 HTML:
const pageContent = await page.content();
- 通过 Thunderbit Chrome 扩展 把 HTML 交给 Thunderbit,让它进行 AI 提取。
Thunderbit 会:
- 将页面转换为 Markdown,便于语义解析。
- 用 AI 识别字段、关系和上下文。
- 输出结构化数据,并可导出到 Excel、Google Sheets、Airtable 或 Notion。
从此你不用再追着变动的选择器跑,也不用为脏乱的数据后处理头疼。
处理动态内容与异步加载
动态内容几乎是所有爬虫的噩梦。网站往往会在首屏渲染之后再加载数据,比如无限滚动、“加载更多”按钮,或者 AJAX 异步评论。
传统做法通常是:
- 使用
waitForSelector等待元素出现。 - 等到网络空闲(没有更多请求)后再抓取。
- 手动触发滚动或点击来加载更多数据。
但这些方法都很脆弱。只要网站的加载逻辑一变,脚本就容易挂掉。
Thunderbit 的做法不同: 通过把页面转换成 Markdown 并让 AI 分析结构,Thunderbit 对特定 DOM 层级或 ID 的依赖更少。即使网站改了布局,只要内容还在,Thunderbit 的 AI 通常还是能找到并提取出来。这就意味着更少维护,更多稳定可靠的数据。
构建可持续的数据管道:从脚本到业务洞察
抓取并不只是一次性任务,它往往是整个数据管道的起点。我通常会这样理解:
- 用 JavaScript(Puppeteer/Playwright)自动完成浏览和提取。
- 再交给 Thunderbit 做 AI 驱动的结构化与标签整理。
- 将结果导出到你常用的工具:Excel、Google Sheets、Airtable、Notion。
- 用 Thunderbit 的 Scheduled Scraper 设置定时任务——只要描述好执行频率(比如“每周一上午 9 点”),输入 URL,其余交给 Thunderbit。
- 把结构化数据接入业务流程中,比如销售外联、价格监控或市场调研。
这种组合——JavaScript 负责自动化,Thunderbit 负责 AI 提取——可以帮你建立可重复、低维护的数据管道,让业务始终基于最新、最准确的数据运转。
结论:如何根据需求选择合适的网页抓取方式
那么,用 JavaScript 抓网页,最佳方案到底是什么?我的看法是这样的:
- 传统 JavaScript 抓取(Cheerio、Puppeteer、Playwright)适合简单、静态的网站,或者当你需要完全掌控浏览器自动化时使用。但它的维护成本不低——选择器会失效,页面会改版,反爬也会越来越严。
- Thunderbit 的 AI 提取 增加了语义理解这一层能力。它对页面变化更稳健,减少手工清洗数据的工作量,让你把精力放在洞察上,而不是调试脚本。
什么时候用哪种?
- 对于简单页面、一次性快速抓取,Cheerio 或 Puppeteer 就够了。
- 对于复杂、动态的网站——或者你想让工作流更有未来适应性——可以把 JavaScript 脚本和 Thunderbit 的 AI 提取结合起来。
- 对于完全不想写代码的业务用户来说,Thunderbit 的 Chrome 扩展是最省事的方案,几乎两步就能把网页变成表格。
想看更多例子?可以去看看 Thunderbit 的博客,里面有关于抓取 Amazon 商品、将数据提取到 Excel 等更深入的内容。
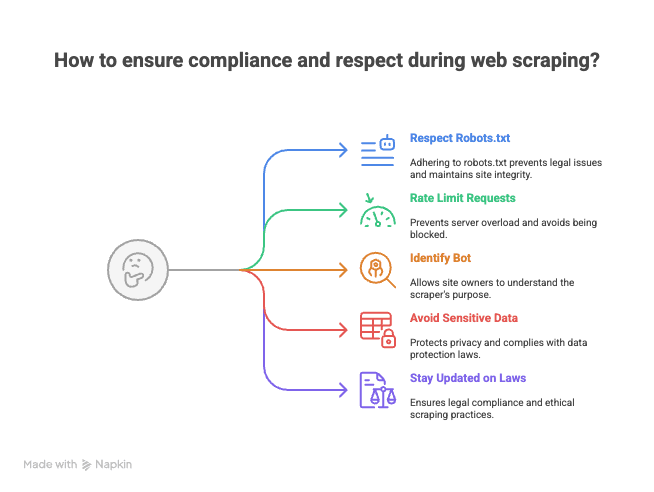
补充:网页抓取时如何保持合规与尊重
在你把抓取脚本放出去“跑”之前,我想提醒一句(这来自一个收到过几封网站管理员“友好”邮件的人):
- 尊重 robots.txt 和服务条款。 不是所有网站都欢迎被抓取。
- 控制请求频率。 别猛刷服务器,要适当间隔,避免被封(或者更糟,被拉黑)。
- 标明你的机器人身份。 设置自定义 User-Agent,让网站管理员知道请求来自谁。
- 避免抓取敏感或个人数据。 只处理公开信息,并尊重隐私。
- 关注法律与最佳实践的更新。 在某些司法辖区,网页抓取仍处于法律灰色地带,而近年来的一些案例(hiQ v. LinkedIn、Bright Data v. Meta)也在持续影响哪些行为被允许——在基于抓取内容构建公开数据产品之前,务必先查看最新判例。
记住:能力越大,责任越大(有时还会收到措辞严厉的停止侵权函)。
使用 JavaScript 进行网页抓取,既是一门艺术,也是一门科学。只要工具选对,再加上一点 AI 的帮助,你就能把整个互联网变成自己的结构化数据乐园。如果你哪天卡住了,嗯,你知道该去哪找我——大概率我正端着咖啡,一边调试选择器,一边打开着 Thunderbit 标签页。
祝你抓取顺利!
常见问题(FAQs)
1. 什么是使用 JavaScript 进行网页抓取?为什么它这么受欢迎?
使用 JavaScript 进行网页抓取,是指通过在浏览器中运行脚本或在后端使用 Node.js,程序化地从网站提取数据。它之所以受欢迎,是因为 JavaScript 能直接访问 DOM,拥有丰富的 HTTP 请求和自动化库生态,并且能灵活地自动完成登录、点击和滚动等交互。
2. 抓取现代动态网站时,主要难点是什么?
现代网站通常会用 JavaScript 框架动态加载内容,把数据藏在无限滚动或弹窗后面,并且频繁改版。这让传统抓取方式非常脆弱,因为选择器一变、数据一异步加载,脚本就很容易失效。
3. Cheerio、Puppeteer 和 Playwright 这些传统 JavaScript 抓取工具有什么区别?
- Cheerio 最适合静态 HTML,速度很快,但不能处理 JavaScript 渲染的内容,也不能做浏览器自动化。
- Puppeteer 和 Playwright 面向动态页面,支持浏览器自动化,也能处理 JavaScript 内容,但速度更慢,配置也更复杂。Playwright 还支持多个浏览器,而 Puppeteer 主要面向 Chrome。
4. Thunderbit 相比传统抓取方式有什么优势?
Thunderbit 通过把网页转换成结构化 Markdown,再用 AI 提取带标签的数据字段,从而实现对网页的语义理解。相比传统基于选择器的抓取,这种方式对页面布局变化更稳健,减少了手工清洗数据的需要,也大幅降低了维护成本。
5. 网页抓取时有哪些合规且尊重网站的最佳实践?
- 始终检查并遵守网站的 robots.txt 和服务条款。
- 控制请求频率,避免压垮服务器。
- 使用自定义 User-Agent 标识你的机器人。
- 避免抓取敏感或个人数据,只处理公开信息。
- 关注你所在地区的法律规定和最佳实践。
了解更多:
- 借助 AI 进行实时网页爬取:快速指南
- 如何使用 AI 抓取任意网站
- 使用 JavaScript 和 Node.js 进行网页抓取——新手教程
- 使用 JavaScript 和 Node.js 进行网页抓取
立即试用 Thunderbit AI 网页爬虫 Get Started Free




