
我第一次为产品发布会追踪新闻的经历,真是记忆犹新。那会儿我桌上摆着三台显示器,开着十几个 Google 新闻的标签页,生怕漏掉什么大新闻——比如竞争对手突然搞了个大动作,或者一场公关危机突然爆发。后来我才发现,这种焦虑其实大家都有:现在每天涌上网络。别说一辈子,光一杯咖啡的工夫都刷不完这些头条。
如果你做销售、市场、运营或者公关,这种“信息焦虑”你肯定懂。手动追新闻就像用水管喝水,根本忙不过来。这也是为什么用 Python 抓取 Google 新闻会成为你的“外挂”:自动收集新闻、灵活分析数据,不管是品牌监控、竞品追踪,还是抢先发现行业风向,都能让你不再错过任何风吹草动。接下来我会带你从零开始,手把手用 Python 搭建 Google 新闻爬虫,从入门到进阶,代码、实战经验、数据分析技巧全都有(还会穿插点趣事和小彩蛋)。
为什么企业用户要抓取 Google 新闻
说实话,商业世界的节奏就是“头条速度”。无论你是公关、销售还是战略岗,第一时间掌握舆论动态都是刚需。全球媒体监测工具市场已经有的规模,预计到 2030 年还要翻倍。为什么?因为企业不能错过任何可能影响声誉、销售或合规的新闻。
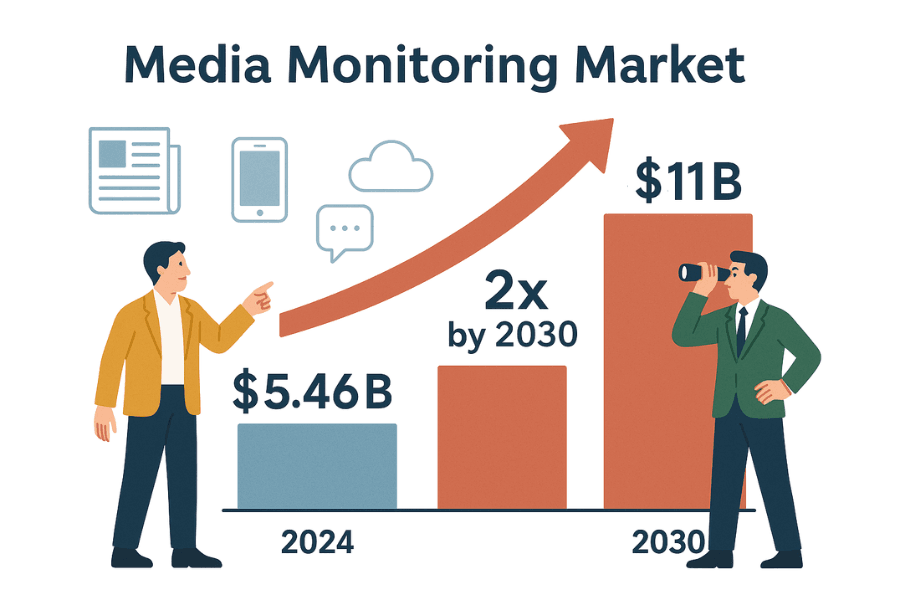
通过抓取 Google 新闻,你可以成为团队里的“情报达人”——或者至少是那个总能掌握最新动态的人:
手动追新闻?不仅慢,还容易出错,关键机会和风险很可能被漏掉()。自动化抓取则能持续、结构化地推送新闻情报,让你不再错失良机。
入门:用 Python 实现网页抓取基础(新手友好示例)
在正式进入 google 新闻抓取之前,先用一个专门练习爬虫的网站 热热身。这个网站就是为爬虫练手准备的,不用担心被封号。
我们的流程如下:
- 发送请求获取首页内容。
- 用 BeautifulSoup 解析 HTML。
- 提取书名和价格。
- 用 pandas 保存为 DataFrame 并导出为 CSV。
- 循环翻页,优雅处理异常。
步骤 1:发送请求并解析 HTML
首先,用 Python 的 requests 库获取首页:
1import requests
2url = "http://books.toscrape.com/index.html"
3response = requests.get(url)
4print(response.status_code) # 成功会输出 200状态码 200 说明请求成功()。
接下来解析 HTML:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, 'html.parser')这样就得到了 soup 对象,可以像操作 Python 对象一样遍历页面结构()。
步骤 2:提取数据并保存为 CSV
获取所有书籍条目:
1books = soup.find_all("li", {"class": "col-xs-6 col-sm-4 col-md-3 col-lg-3"})
2print(f"本页共找到 {len(books)} 本书")提取书名和价格:
1book_list = []
2for item in books:
3 title = item.h3.a["title"]
4 price = item.find("p", class_="price_color").get_text()
5 book_list.append({"Title": title, "Price": price})用 pandas 保存为 CSV:
1import pandas as pd
2df = pd.DataFrame(book_list)
3df.to_csv("books.csv", index=False)或者用原生 csv 模块:
1import csv
2keys = book_list[0].keys()
3with open("books.csv", "w", newline="", encoding="utf-8") as f:
4 writer = csv.DictWriter(f, fieldnames=keys)
5 writer.writeheader()
6 writer.writerows(book_list)打开 books.csv,你就拥有了属于自己的数据表。
步骤 3:处理翻页和异常
如果想抓取所有书籍,需要循环翻页:
1all_books = []
2for page in range(1, 51): # 共 50 页
3 url = f"http://books.toscrape.com/catalogue/page-{page}.html"
4 try:
5 res = requests.get(url, timeout=10)
6 if res.status_code != 200:
7 break
8 soup = BeautifulSoup(res.text, 'html.parser')
9 books = soup.find_all("li", {"class": "col-xs-6 col-sm-4 col-md-3 col-lg-3"})
10 for item in books:
11 title = item.h3.a["title"]
12 price = item.find("p", class_="price_color").get_text()
13 all_books.append({"Title": title, "Price": price})
14 except requests.exceptions.RequestException as e:
15 print(f"请求失败: {e}")
16 continue这个循环能自动翻页,遇到不存在的页面会自动停下,还能捕获网络异常。(小建议:每次请求间加个 time.sleep(1),更友好。)
恭喜!你已经掌握了网页抓取的基础:请求、解析、提取、翻页和异常处理。这些技能同样适用于 google 新闻抓取。
用 Python 抓取 Google 新闻:分步实战
准备好升级了吗?我们来搭建一个 google 新闻爬虫,自动获取新闻标题、链接、来源和时间戳,把全球新闻变成结构化数据。
环境准备
确保你已经装好 Python 3 和下面这些库:
1pip install requests beautifulsoup4 pandas()
还需要设置 User-Agent,模拟真实浏览器访问,不然 Google 可能会限制你的请求()。
构建 Google 新闻爬虫
分解步骤如下:
1. 定义搜索 URL 和参数
Google 新闻搜索 URL 格式如下:
1https://news.google.com/search?q=YOUR_QUERY&hl=en-US&gl=US&ceid=US:enq:搜索关键词hl:语言(如en-US)gl:国家(如US)ceid:国家:语言(如US:en)
Python 代码示例:
1base_url = "https://news.google.com/search"
2params = {
3 'q': 'technology',
4 'hl': 'en-US',
5 'gl': 'US',
6 'ceid': 'US:en'
7}
8headers = {
9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)...'
10}()
2. 获取结果页面
1response = requests.get(base_url, params=params, headers=headers)
2html = response.text
3print(response.status_code)()
3. 解析并提取数据
解析 HTML 并提取新闻条目:
1soup = BeautifulSoup(html, 'html.parser')
2articles = soup.find_all('article')
3news_data = []
4for art in articles:
5 headline_tag = art.find('h3')
6 title = headline_tag.get_text() if headline_tag else None
7 link_tag = art.find('a')
8 link = link_tag['href'] if link_tag else ''
9 if link.startswith('./'):
10 link = 'https://news.google.com' + link[1:]
11 source_tag = art.find(attrs={"class": "wEwyrc"})
12 source = source_tag.get_text() if source_tag else None
13 time_tag = art.find('time')
14 time_text = time_tag.get_text() if time_tag else None
15 snippet_tag = art.find('span', attrs={"class": "xBbh9"})
16 snippet = snippet_tag.get_text() if snippet_tag else None
17 news_data.append({
18 "title": title,
19 "source": source,
20 "time": time_text,
21 "link": link,
22 "snippet": snippet
23 })()
保存为 CSV:
1df = pd.DataFrame(news_data)
2df.to_csv("google_news_results.csv", index=False)处理缺失数据
提取前务必判断标签是否存在。Google 的 HTML 结构并不总是统一,有些字段可能缺失,建议用 None 或空字符串填充。
多页抓取与限速处理
Google 新闻采用无限滚动,requests 通常只能获取第一页。如果需要更多结果,可以:
- 使用 RSS 订阅(能获取更多内容,)
- 用 Selenium、Playwright 等无头浏览器模拟滚动(进阶用法)
- 或者定时抓取(比如每小时一次),持续获取新内容
注意: 抓取过快会被 Google 限制。用户反馈,连续 10 次快速请求就会被 429 拒绝()。建议:
- 每次请求间加
time.sleep(random.uniform(2,6)) - 批量抓取时轮换 User-Agent 和 IP
- 检测到验证码或拦截页面时及时暂停
如何让 Google 新闻抓取可复用、可分析
核心秘诀:高质量抓取不仅仅是“拿到数据”,更要让数据可复用、可分析。 如果你想让 BI 看板、公关监控或竞品追踪长期稳定运行,必须控制语言、地区、时间和去重。
按语言、地区、时间切片
Google 新闻内容高度个性化。想要结果一致:
- 用
hl、gl、ceid参数控制语言和地区() - 例如,
hl=ko&gl=KR&ceid=KR:ko获取韩文新闻,hl=en-IN&gl=IN&ceid=IN:en获取印度英文新闻
时间切片:
- Google 新闻没有直接的“过去 24 小时”参数,但结果通常按时间排序
- 可以抓取后筛选:如
time字段包含“hour ago”、“minutes ago”或“Today”则保留 - 更精细可用 RSS 或高级搜索指令(但支持有限)
过滤与去重
重复新闻会影响分析。建议:
- 来源/主题白名单: 只保留特定来源或主题的数据。也可在查询中用
source:指定(如q=特斯拉 source:Reuters)。 - 按 URL 去重: 去掉 URL 中的追踪参数(如
utm_*)。示例:
1import urllib.parse
2clean_link = urllib.parse.urljoin(link, urllib.parse.urlparse(link).path)()
- 按标题去重: 多条新闻标题相似时只保留一条。可统一小写、去标点后比对。
- 记录已抓取文章: 每次抓取时存储已抓取文章的哈希,下次抓取前先查重。
这样你的数据就能保持干净、可用,避免重复统计或情感分析失真()。
方案对比:Python 爬虫 vs. Google 新闻 API
自己写 Python 爬虫,还是用第三方 Google 新闻 API?对比如下:
| 对比维度 | 自建 Python 爬虫 | 第三方 Google 新闻 API 服务 |
|---|---|---|
| 实现难度 | 需编写和调试代码,适应页面变化 | 直接调用 API,无需解析 HTML |
| 灵活性 | 可自定义字段、跟进子页面 | 受限于 API 提供的字段和选项 |
| 数据掌控 | 完全掌控原始数据 | 数据已被预处理,需信任对方解析 |
| 扩展性与速度 | 受限于本地 IP/资源,易被封 | 支持大规模抓取,自动代理防封 |
| 稳定性 | Google 改版或封 IP 时易失效 | 高可用,API 会适配页面变化 |
| 维护成本 | 需持续维护选择器和反爬措施 | 基本无需维护,服务方负责 |
| 成本 | 免费(但耗时,可能需代理) | 付费,按请求量或套餐计费(价格示例) |
| 被封风险 | 高,Google 可封禁 IP | 低,API 自动处理封禁和重试 |
| 数据时效性 | 可自控抓取频率,但过频易被封 | 实时,套餐高可支持高频抓取 |
| 法律/合规 | 需自行遵守 Google 条款,风险自担 | 仍需注意,但 API 通常声明合理使用(非法律建议) |
小型项目或学习建议自建,生产或大规模建议用 API。如果想要“无代码、零维护”,可以试试下方的 Thunderbit。
Google 新闻抓取常见问题与排查
抓取 google 新闻并不是一帆风顺,常见问题和解决方法如下:
- 验证码或“异常流量”页面: 降低请求频率,轮换 User-Agent,必要时用代理。遇到验证码建议暂停抓取()。
- HTTP 429/503 错误: 被限速或封禁。建议指数退避、检查 robots.txt、避免并发抓取。
- HTML 结构变化: Google 经常改版,需及时更新选择器。用 try/except 包裹提取逻辑防止崩溃。
- 字段缺失: 并非每条新闻都有摘要或来源,代码需兼容缺失字段。
- 重复数据: 按上述方法去重。
- 编码问题: 保存文件时统一用 UTF-8。
- JS 渲染内容: 大部分 Google 新闻为服务端渲染,极少数需用 Selenium、Playwright 等工具(进阶)。
更多排查技巧可参考和。
Google 新闻抓取的合规与最佳实践
说说合规和最佳实践——能力越大,责任越大:
- 遵守 robots.txt: Google 新闻 robots.txt 禁止抓取部分路径()。即使技术上能抓,也建议遵守。
- 避免高频请求: 加延时,选择低峰时段,不要频繁访问。
- 合理使用数据: 仅用于分析头条、摘要和链接,勿全文转载()。
- 注明来源: 分享分析时请注明 Google 新闻及原始媒体。
- 持续维护爬虫: 网页常变,代码也要及时更新。
- 数据安全与合规: 妥善存储数据,遵守隐私法规。
- 合理使用与限速: 不要过度抓取,若被要求停止请及时配合()。
总之:做一个负责任的网络公民,你和你的 IT 团队都会感谢自己。
核心要点与下一步建议
回顾一下:
- 你学会了网页抓取基础,用 Python 的 requests 和 BeautifulSoup,从静态网站到 google 新闻。
- 你搭建了可复用的 google 新闻抓取流程: 控制语言、地区、时间,去重,数据结构化,便于分析。
- 你对比了自建爬虫和 API 方案: 理解了控制力、稳定性和成本的权衡。
- 你掌握了排查技巧和合规实践,确保抓取安全、合规。
下一步?把这些方法用到你的业务场景——无论是品牌监控、竞品追踪,还是自建新闻看板。想更进一步?可以尝试抓取其他新闻网站、自动化数据流,甚至对头条做情感分析。
如果你厌倦了维护 Python 脚本,或者想节省时间,不妨试试 。Thunderbit 是一款 AI 网页爬虫 Chrome 插件,无需写代码,几步即可抓取 Google 新闻及其他网站。支持“AI 智能字段推荐”、定时抓取、子页面导航、一键导出 Excel/Google 表格,是团队自动化收集新闻的高效利器。()
更多抓取技巧,欢迎访问 ,或阅读我们的、、。
祝你抓取顺利,愿你的新闻数据永远新鲜、结构化,领先一步!
作者:Shuai Guan,Thunderbit 联合创始人兼 CEO。多年深耕 SaaS、自动化与 AI,最喜欢把混乱变成有用的数据。如果你有问题或想交流抓取经验,欢迎联系我。
常见问题解答
1. 为什么企业要用 Python 抓取 Google 新闻?
通过抓取 Google 新闻,企业可以自动收集与品牌、竞品或行业相关的新闻,实现实时监控公关危机、追踪竞争动态、获取销售线索、分析市场趋势和管理风险。手动追踪不仅慢,还容易遗漏关键信息,而自动化抓取能持续提供结构化、最新的新闻数据。
2. 用 Python 抓取 Google 新闻的基本步骤有哪些?
主要流程包括:
- 配置 Python 环境,安装
requests、BeautifulSoup、pandas等库; - 定义 Google 新闻搜索 URL 和参数(如关键词、语言、地区);
- 发送请求并设置合适的 headers(如 User-Agent);
- 解析 HTML,提取标题、链接、来源、时间、摘要等信息;
- 将数据保存为 CSV 文件,便于后续分析;
- 处理缺失字段和去重,确保数据干净可用。
3. 抓取 Google 新闻时会遇到哪些挑战,如何应对?
常见挑战包括:
- 验证码或“异常流量”警告:降低请求频率,轮换 User-Agent,必要时用代理;
- 限速(HTTP 429/503):加延时,避免并发抓取;
- HTML 结构变化:定期更新选择器,用 try/except 防止崩溃;
- 字段缺失或不一致:提取前先判断标签是否存在;
- 重复数据:按 URL 或标题去重;
- 编码问题:保存文件时用 UTF-8;
- JS 渲染内容:进阶可用 Selenium、Playwright 等工具。
4. 如何让 Google 新闻抓取流程可复用、可分析?
建议:
- 用
hl、gl、ceid参数控制语言和地区; - 按时间筛选结果,可用 RSS 或抓取后过滤;
- 按 URL 规范化和标题去重;
- 记录已抓取文章,避免重复统计;
- 数据安全存储,流程有文档便于后续维护。
5. 是自建 Google 新闻爬虫好,还是用第三方 API?
自建爬虫灵活、免费(除时间和代理成本),但需持续维护,易因页面变化失效,被封风险高。第三方 API 稳定、易扩展,自动处理反爬,但需付费,且对数据掌控有限。小型项目或学习建议自建,生产或大规模建议用 API。