网络数据就像新时代的石油,但它分布在无数网站里,藏在各种混乱的 HTML 代码中,还被验证码和反爬虫机制层层包裹。如果你曾经手动复制粘贴商品价格、竞品信息或者客户线索,肯定体会过那种手指发麻、错失商机的无力感。这也是为什么网页爬虫已经成了现代企业的标配技能。实际上,另类数据市场(包括网页爬虫)在,而且还在持续高速增长。

有意思的是,虽然 Python 是很多新手的首选,Go(Golang)却悄悄成为全球最快、最稳定的爬虫利器。Go 的秘诀是什么?超强的并发能力、强大的标准库,还有让后端开发者都心动的高性能。我见过不少团队,仅仅切换到 Go,爬取速度就直接翻倍。而且有了合适的工具,就算不是 Google 工程师,也能轻松搞定。
想让 Go 成为你的网页爬虫神器?接下来我会用 5 个关键步骤,从环境搭建到进阶实战,配合实用代码和技巧,还会介绍像 这样的 AI 工具,帮你效率翻倍。
为什么选择 Go 语言做网页爬虫?商业价值全解析
说句实话:当你需要抓取成千上万甚至上百万网页时,每一秒都很宝贵。Go 天生就是为这种高强度任务而生。越来越多企业选择 Go 做网页爬虫,原因很简单:
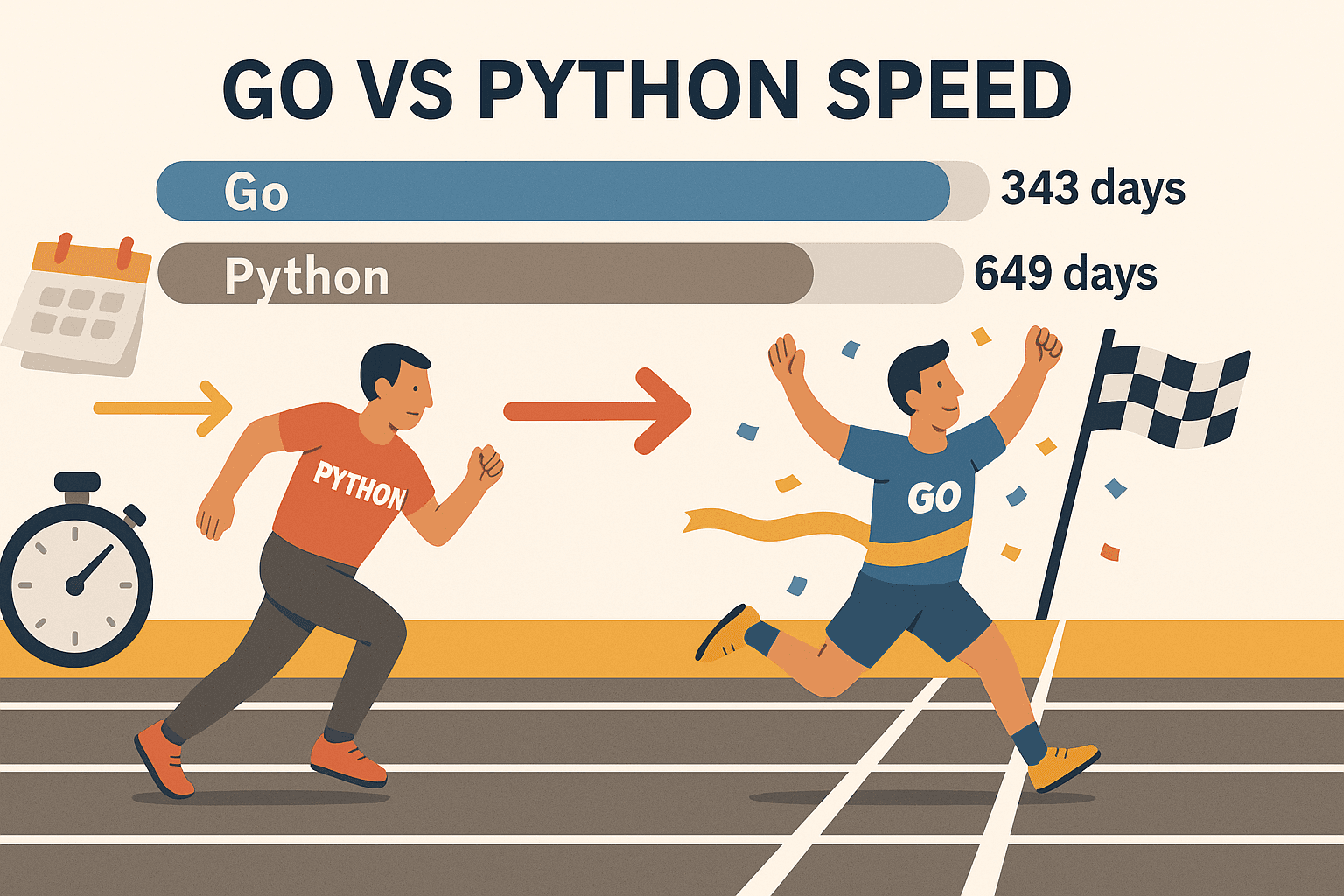
- 超强并发: Go 的 goroutine(轻量级线程)让你可以同时抓取上百个页面,电脑也不会卡死。有个基准测试显示,Go 用 343 天爬完,而 Python 需要 649 天。这不仅仅是快,而是完全不同的量级。
- 稳定可靠: Go 的强类型和高效内存管理,非常适合长时间、大规模的数据抓取。再也不用担心半夜脚本崩溃。
- 网络支持一流: Go 的标准库自带 HTTP 请求、HTML 解析、JSON 处理等功能,无需到处找第三方包。
- 部署超简单: Go 编译后就是一个可执行文件,随时随地运行,无需虚拟环境,也没有依赖地狱。
- 行业认可度高: Go 现在已经成为(甚至超过 Node.js),Google、Uber、Netflix 等大厂都在用。
当然,Python 依然适合快速原型或需要机器学习库的场景。但如果你追求速度、规模和稳定性,Go 绝对是更优选择,尤其配合 Colly、Goquery 等库。
步骤一:搭建 Go 网页爬虫开发环境
在正式开爬之前,先把 Go 环境搭好。好消息是,这个过程非常简单。
1. 安装 Go
- 访问 ,选择适合你系统的安装包(Windows、macOS 或 Linux)。
- 按提示安装。Linux 用户也可以用包管理器安装。
- 打开终端,输入:
如果看到类似1go versiongo version go1.21.0 darwin/amd64的输出,说明安装成功。
常见问题排查: 如果提示找不到 go,请检查 PATH 是否配置正确。Linux/macOS 用户可能需要在 ~/.bash_profile 或 ~/.zshrc 里加上 export PATH=$PATH:/usr/local/go/bin。
2. 初始化新项目
- 新建一个文件夹:
1mkdir my-scraper && cd my-scraper - 初始化 Go 模块:
这样会生成一个1go mod init github.com/yourname/my-scrapergo.mod文件,方便管理依赖。
3. 选择编辑器
- 推荐用 并安装 Go 插件(支持自动补全、代码检查、调试)。
- JetBrains GoLand 也是 Go 开发者的热门选择。
- 喜欢命令行的可以用 Vim/Neovim 配合 Go 插件。
4. 测试环境是否可用
新建 main.go 文件:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go is installed and working!")
5}运行:
1go run main.go如果看到输出,说明一切就绪。
步骤二:用 Go 发起第一个 HTTP 请求
现在来抓取第一个网页!Go 的 net/http 包让这一切变得很简单。
基础 HTTP GET 示例:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Error fetching the URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Error reading the response body:", err)
17 return
18 }
19 fmt.Println(string(body))
20}要点:
- 每次
http.Get后都要检查错误。 - 用
defer resp.Body.Close()及时释放资源。 - 用
io.ReadAll读取完整响应内容。
进阶技巧:
- 想自定义请求头(比如 User-Agent),用
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - 记得检查
resp.StatusCode,200 表示成功,403/404 说明被拦截或页面不存在。
步骤三:用 Go 解析 HTML 并提取数据
拿到 HTML 只是第一步,接下来要提取有价值的信息,比如商品名、价格、链接等。
Goquery 登场: 这是一个 Go 语言的 HTML 解析库,支持类似 jQuery 的选择器。
安装 Goquery:
1go get github.com/PuerkitoBio/goquery示例:提取商品名称和价格
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Product %d: %s - %s\n", i+1, name, price)
21 })
22}原理说明:
doc.Find("div.product")选中所有商品容器。s.Find("h2").Text()获取商品名,s.Find(".price").Text()获取价格。
正则表达式: 如果只需简单匹配(比如邮箱),Go 的 regexp 包很方便。复杂结构建议用 Goquery。
步骤四:用 Go 网页爬虫库(Colly & Gocolly)提升效率
想进一步提升效率? 是 Go 领域最受欢迎的网页爬虫框架。它支持自动爬取、并发、Cookie 管理等,让你专注于数据本身。
Colly 的优势:
- API 简单易用: 注册回调函数,指定要抓取的元素。
- 并发抓取: 通过
colly.Async(true),轻松并发爬取上百页面。 - 自动爬取链接和分页: 轻松跟踪“下一页”等链接。
- 反爬虫功能: 支持自定义请求头、User-Agent 轮换、Cookie 管理。
- 错误处理: 内置请求失败钩子。
安装 Colly:
1go get github.com/gocolly/colly/v2Colly 基础爬虫示例:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Product: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Request failed:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Goquery 与 Colly 功能对比
| 功能 | Goquery | Colly |
|---|---|---|
| HTML 解析 | 支持 | 支持(内部用 Goquery) |
| HTTP 请求 | 需手动实现 | 内置 |
| 并发能力 | 需手动(goroutine) | 简单(Async(true)) |
| 爬取/跟踪链接 | 需手动 | 自动 |
| 反爬虫功能 | 需手动 | 内置 |
| 错误处理 | 需手动 | 内置 |
Colly 能极大提升复杂爬虫项目的开发效率。
步骤五:应对 Go 网页爬虫中的实际挑战
真实环境下的网页爬虫并非一帆风顺,常见难题及应对方法如下:
1. IP 被封
- 用 Go 的
http.Transport或 Colly 的代理功能轮换 IP。 - 随机延迟请求,降低被封风险。
2. User-Agent 与请求头
- 设置真实浏览器的 User-Agent(比如 Chrome、Firefox)。
- 模拟真实浏览器的请求头(如 Accept-Language)。
3. 验证码(CAPTCHA)
- 遇到验证码,说明抓取频率太高或行为太明显。
- 对于需要 JS 或交互的网站,可用 等无头浏览器。
- 针对复杂反爬,可集成验证码识别服务。
4. 分页处理
- 用 Colly 自动跟踪“下一页”链接:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. 动态内容(JavaScript 渲染)
- Go 的 HTTP 库无法执行 JS。可用无头浏览器(Rod、chromedp),或直接抓取接口数据。
6. 实在搞不定?用 Thunderbit 省心省力
有时候,遇到极其复杂或动态性强的网站,或者你急需数据但不想写代码,这时 就能帮你轻松搞定。Thunderbit 是一款 AI 网页爬虫 Chrome 插件,具备:
- AI 智能识别并提取字段,一键“AI 建议列”。
- 自动处理子页面、分页,无需手动配置。
- 支持真实浏览器(本地或云端),能应对 JS 动态渲染和大部分反爬机制。
- 一键导出到 Excel、Google Sheets、Airtable、Notion,无需写代码。
- 支持定时任务,团队自动化采集数据。
Thunderbit 特别适合业务人员、销售团队或任何需要结构化数据但不想写代码的人。说实话,我和团队就是为了解决这些痛点才开发了它。
Go + Thunderbit:效率最大化的组合
秘诀就是:你完全可以同时用 Go 和 Thunderbit,强强联合。
示例工作流:
- 用 Go(配合 Colly)大规模爬取 URL 或基础数据。
- 把这些 URL 输入 Thunderbit,提取详细结构化信息,尤其适合处理子页面、动态内容或复杂反爬。
- 从 Thunderbit 导出数据到 Google Sheets 或 CSV。
- 再用 Go 处理、合并或分析数据。
这种混合方案,既有 Go 的速度和灵活性,又有 Thunderbit 的 AI 智能和易用性。就像工具箱里同时有瑞士军刀和电钻。
Go 网页爬虫方案对比:原生 Go vs. Colly vs. Thunderbit
下面这张表帮你快速选对工具:
| 维度 | 原生 Go(net/http + html) | Go + Colly(库) | Thunderbit(AI 无代码) |
|---|---|---|---|
| 上手难度 | 高(需写代码) | 中(API 简单) | 最低(无需代码,AI 驱动) |
| 并发能力 | 手动(goroutine) | 内置(Async(true)) | 云端/浏览器并发 |
| 动态内容(JS) | 需无头浏览器 | 部分支持 JS,或用 Rod | 完整浏览器,原生支持 JS |
| 反爬虫处理 | 手动(代理、请求头) | 内置多种功能 | 基本自动,云端 IP |
| 数据结构化 | 自定义代码 | 回调+自定义结构体 | AI 智能建议,自动格式化 |
| 导出选项 | 自定义(CSV、数据库等) | 自定义 | Excel、Sheets、Notion、Airtable |
| 维护成本 | 高(需频繁改代码) | 中 | 低(AI 自动适应网站变化) |
| 适用人群 | 开发者、定制化流程 | 开发者、快速原型 | 非技术用户、业务人员 |
小贴士: 大规模、定制化或后端集成项目建议用 Go/Colly。需要快速、简单或应对复杂前端网站时,Thunderbit 更高效。
总结:Go 语言网页爬虫入门要点
- Go 是网页爬虫的强力引擎,尤其适合追求速度、并发和稳定性的场景。
- 从基础做起: 配置 Go 环境,学会发 HTTP 请求,用 Goquery 解析 HTML。
- 用 Colly 提升效率: 爬取、并发、反爬等功能一应俱全。
- 应对实际挑战: 轮换代理、设置请求头,遇到难题用无头浏览器或 Thunderbit。
- 工具组合更高效: Go + Thunderbit,兼顾灵活性和智能化。
网页爬虫能极大提升销售、运营和研究团队的效率。有了 Go 及相关库(再加点 AI),你可以自动化繁琐工作,把精力投入到真正有价值的洞察上。
Go 网页爬虫进阶资源推荐
想深入学习?以下是我的常用资料:
祝你爬虫顺利,数据结构清晰,效率飞快,咖啡常备!
常见问题解答
1. 为什么用 Go 做网页爬虫,而不是 Python 或 JavaScript?
Go 在并发、速度和稳定性方面表现突出,尤其适合大规模、长时间运行的爬虫项目。如果你需要快速抓取大量页面,并希望生成可移植的可执行文件,Go 是理想选择。
2. Go 解析 HTML 最简单的方法是什么?
推荐使用 库,支持类似 jQuery 的选择器,DOM 遍历和数据提取都很方便。
3. Go 如何处理 JavaScript 渲染的网页?
需要用无头浏览器库,比如 或 。或者直接用 ,无需代码,浏览器自动处理 JS。
4. 如何避免爬虫被封?
轮换 User-Agent,使用代理,增加请求间隔,模拟真实浏览器行为。Colly 可以轻松实现这些技巧,Thunderbit 也能自动应对大部分反爬措施。
5. 可以把 Go 和 Thunderbit 结合使用吗?
当然可以!用 Go 做大规模爬取或后端集成,用 Thunderbit 做 AI 智能提取、子页面抓取和导出到业务工具。开发者和业务用户都能受益。
想提升你的网页爬虫技能?赶快试试 ,或访问 获取更多实用技巧、教程和深度解析。