告诉你一个小秘密:互联网其实就是全球最大的图书馆,只不过大多数“书”都上了锁。每天我都会碰到企业老板、市场营销和销售团队,他们都知道网页里藏着无数宝藏——比如产品参数、竞品价格、客户评价、联系方式等等——但想把这些信息提取出来?这才是真正的难题。我在 SaaS 和自动化行业摸爬滚打了很多年,见过太多“复制粘贴马拉松”和“自己写 Python 脚本”的故事。好在现在有了 AI 网页爬虫工具和更智能的浏览器插件,从网页提取文本比以前简单太多了。
这篇指南会带你一步步了解各种实用方法——从最基础的复制粘贴,到像 这样先进的 AI 解决方案(没错,这是我们团队的产品,但我会客观分析优缺点)。不管你是表格达人、开发高手,还是只是厌倦了盯着网页发呆的人,都能在这里找到适合自己的操作方式。让我们一起“解锁”这些数字图书,轻松拿到你想要的文本信息。
什么是从网站提取文本?
所谓“从网站提取文本”,其实就是把网页上你能看到(有时候甚至看不到)的内容,变成你能用的数据格式——比如表格、数据库,或者干净的 Word 文档。但网页上的文本类型可不止一种:
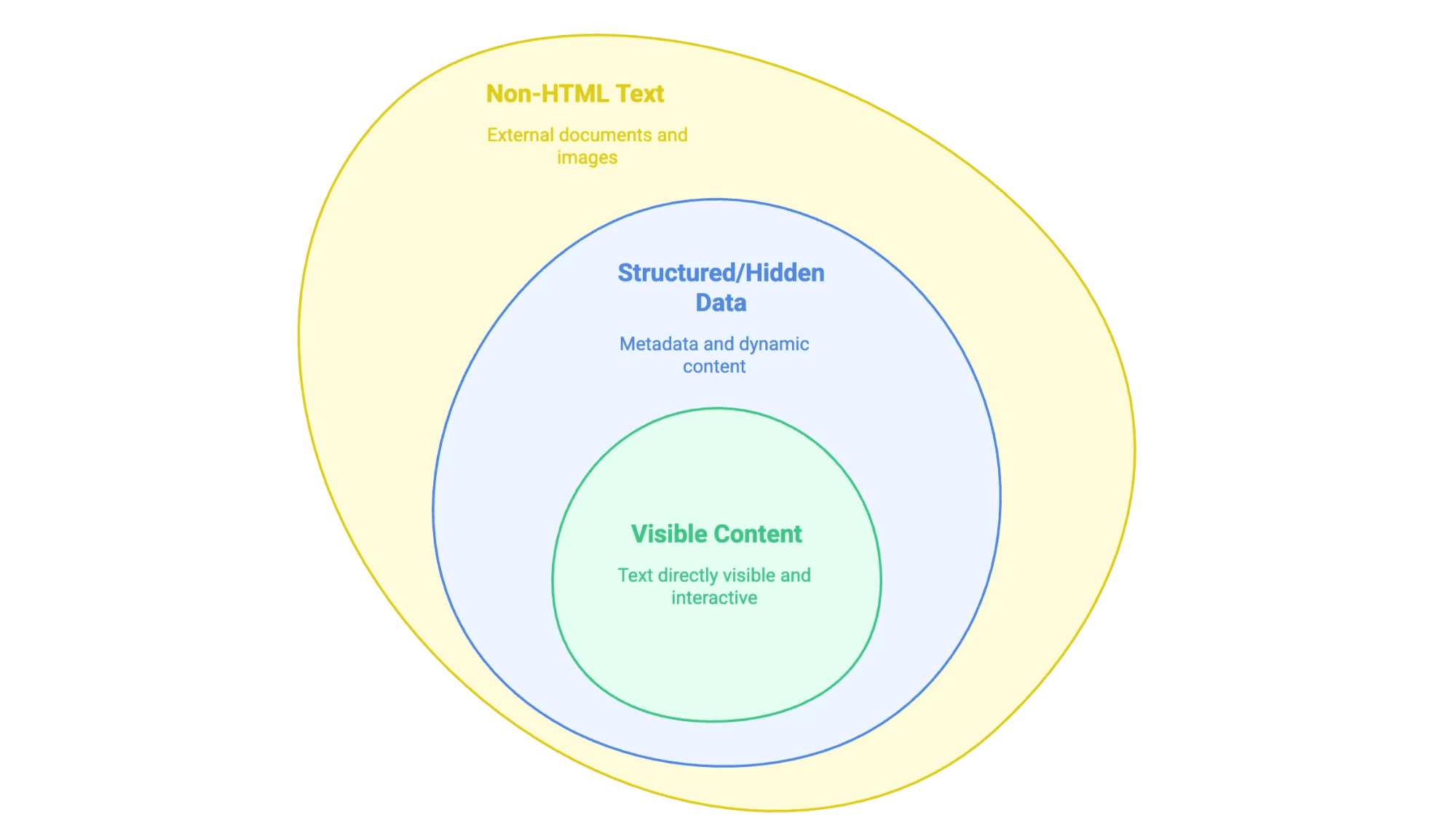
- 可见内容: 你能用鼠标选中的内容,比如正文、标题、列表、表格、产品描述、博客文章等。
- 结构化或隐藏数据: 比如
<meta>标签里的元数据、JSON-LD 脚本,或者通过 JavaScript 动态加载、需要点击或滚动才能显示的信息。 - 非 HTML 文本: 网站上链接或嵌入的 PDF、Word 文档,甚至图片(比如扫描合同、信息图)里的文字。
关键在于你想提取哪一类内容,因为不同类型要用不同的方法。
为什么要从网站提取文本?业务价值与应用场景
说实话,没人会无聊到纯粹为了好玩去提取网页文本(除非你有特别的爱好)。企业之所以这么做,是因为回报实打实。网页爬虫软件市场在 ,而且还在持续增长。原因很简单:
| 团队 | 应用场景示例 | 业务价值 |
|---|---|---|
| 销售 | 抓取名录获取潜在客户和联系方式 | 更快、更丰富的客户开发 |
| 市场 | 提取竞品博客和 SEO 数据 | 内容差距分析、趋势洞察 |
| 运营 | 监控电商网站产品价格 | 动态定价、库存跟踪 |
| 房地产 | 汇总房源和物业信息 | 市场分析、线索获取 |
| 客服 | 收集客户评价和论坛问答 | 情感分析、问题预警 |
一些真实案例:

- 客户开发: 某餐饮供应企业通过自动化 ,而不是几天。
- 竞品监控: 零售商 John Lewis 利用抓取的价格数据 。
- SEO 分析: 团队通过提取 meta 标签和关键词来 。
而且借助 AI 工具,企业的数据采集效率比传统方式提升了 。
手动方法:基础的网页文本复制粘贴
先说最基础的。有时候,你只需要快速拿到一小段内容,这时候其实不需要任何工具。
如何手动提取文本
- 复制粘贴: 打开网页,选中需要的内容,按 Ctrl+C(或右键复制),然后粘贴到文档或表格里。
- 另存为网页: 浏览器菜单选择“文件 > 另存为”,保存为“仅 HTML 网页”可以拿到原始 HTML,有时也能保存为 .txt 纯文本。
- 打印为 PDF: 用浏览器的打印功能选择“另存为 PDF”,再用 PDF 阅读器复制文本,或者直接“另存为文本”。
- 开发者工具: 右键选择“检查”或按 F12 打开开发者工具,可以查看 HTML 源码、meta 标签或隐藏的 JSON,复制你需要的内容。
局限性
手动提取适合偶尔用用,但如果量大就很痛苦了。它 。我见过实习生一行行复制表格,几天都干不完——没人愿意做这种苦力活。
用浏览器插件和在线工具提取网页文本
想提升效率?浏览器插件和在线工具是大多数企业用户的首选:不用写代码,操作简单,点点鼠标就能搞定。
为什么选择这些工具?

- 比手动复制快太多
- 不需要编程基础
- 能处理表格、列表,甚至部分文件
- 可导出为 Excel、Google Sheets、CSV 等格式
下面来看看主流的几种选择。
Thunderbit:AI 网页爬虫,快速精准提取文本
虽然我有点偏心,但 的确让网页文本提取变得像点外卖一样简单。操作流程如下:
步骤详解:用 Thunderbit 提取网页文本
- 安装 Chrome 插件: 从 Chrome 应用商店 。
- 打开目标网页: 进入你想提取文本的页面。
- 点击“AI 智能识别字段”: Thunderbit 的 AI 会自动扫描页面,推荐可提取的字段(如产品名、价格、描述等)。
- 检查与调整: 可以根据需要修改或添加字段。
- 点击“抓取”: Thunderbit 会自动采集数据,支持子页面和分页列表。
- 导出数据: 可一键导出到 Excel、Google Sheets、Airtable、Notion,或保存为 CSV/JSON。导出不收取额外费用。
Thunderbit 有哪些独特优势?
- AI 智能字段推荐: 无需手动设置选择器或写代码,AI 自动识别页面重点内容。
- 支持子页面与分页采集: 需要批量抓取分类下所有产品详情?Thunderbit 可自动点击翻页。
- 支持 PDF、图片、文档提取: 有 PDF 手册或产品图片?Thunderbit 内置 OCR,能直接识别并提取文本。
- 多语言支持: 覆盖 34 种语言(克林贡语还在开发中,敬请期待)。
- 免费数据导出: 获取数据不设门槛。
- 应用场景广泛: 产品描述、联系方式、博客内容、客户名单等都能搞定。
想看实际效果?欢迎访问我们的 ,有详细的实操教程,比如 。
其他浏览器插件和在线工具
再来简单介绍几款常见工具:
- Web Scraper (): 免费、可视化操作,但上手有一定门槛。适合技术型分析师,需要自己设置“站点地图”和选择器。支持分页,但不支持 PDF 或图片。 。
- CopyTables: 极简工具——直接把网页表格复制到剪贴板或 Excel。适合偶尔抓取单个表格,但只能一页一页操作,仅限表格。 。
- ScraperAPI (): 面向开发者。你只需提供网址,它返回 HTML(自动处理代理和反爬),但需要自己解析文本。 。
何时用哪种工具?
- Thunderbit: 追求速度、AI 辅助、多格式支持(包括 PDF/图片)时首选。
- Web Scraper: 喜欢自定义、需要更高控制力时。
- CopyTables: 只需快速抓取表格时。
- ScraperAPI: 需要用代码自建爬虫时。
自动化网页爬取:用编程方式提取网站文本
如果你是开发者(或有开发资源),自写爬虫能获得最大灵活性。基本流程如下:
- 发送 HTTP 请求: 用 Python 的
requests等库获取网页内容。 - 解析 HTML: 用
BeautifulSoup、lxml或Scrapy等库定位所需文本。 - 提取与导出: 把文本提取出来,清洗后保存为 CSV、JSON 或数据库。
示例:Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)优缺点
- 优点: 灵活性极高,几乎能处理任何网站和数据类型,可与自有系统集成。
- 缺点: 需要编程能力,后期维护成本高,还要应对反爬机制。
适用场景
- 需要批量抓取成千上万页面。
- 网站结构复杂(如需登录、多步表单)。
- 需要将爬虫集成到自有应用或自动化流程中。
提取非 HTML 格式文本:PDF、Word 文档和图片
网站内容不仅限于 HTML,很多有价值的信息藏在 PDF、Word、图片等文件里。怎么提取?
PDF 文件
- 文本型 PDF: 可用 Adobe Acrobat 或
PDFMiner、PyPDF2等库提取文本。 - 扫描型 PDF: 需用 OCR(光学字符识别)工具,比如 Tesseract、 或 。
Word/Excel 文档
- Word: 用
python-docx读取 .docx 文件。 - Excel: 用
openpyxl或pandas处理 .xlsx 文件。
图片
- OCR 工具: 开源可用 Tesseract,云服务识别率更高。图片清晰度(150–300 DPI)越高效果越好。
Thunderbit 的做法
“图片/文档解析器”支持上传或链接 PDF、图片、文档,AI 会自动提取文本(比如识别到表格还能智能推荐字段)。不用切换各种工具,文件处理就像网页一样简单。
方法对比:哪种文本提取方案适合你?
下面这张表帮你快速选型:
| 方法 | 易用性 | 可扩展性 | 技术门槛 | 支持数据类型 | 适用场景 |
|---|---|---|---|---|---|
| 手动(复制粘贴) | 非常简单 | 低 | 无 | 仅可见文本 | 临时、小量任务 |
| 浏览器插件/工具 | 简单–中等 | 中等 | 低–中 | HTML、部分表格 | 非技术用户、中小规模 |
| AI 工具(Thunderbit) | 非常简单 | 高 | 无 | HTML、PDF、图片等 | 商业用户、混合内容 |
| 编程(代码) | 困难 | 非常高 | 高 | 任意(配合库) | 开发者、大规模项目 |
| 非 HTML 提取(OCR) | 中等 | 低–中 | 中等 | PDF、图片、文档 | 文件/图片为主时 |
如果你想要最快、最灵活、最省心的方式——尤其是企业场景——AI 工具如 Thunderbit 是不二之选。但如果你需要极致定制或大规模批量抓取,自建代码爬虫也值得考虑。
核心总结:马上开始你的网页文本提取之旅
- 互联网上充满了有价值的文本数据,但获取并不总是容易。
- 手动方法适合小量任务,但无法应对大规模需求。
- 浏览器插件和 AI 网页爬虫(如 )让文本提取变得快速、精准、人人可用——无需编程。
- 针对非 HTML 内容(如 PDF、图片),选择带 OCR 和文档解析功能的工具。
- 选择最适合你团队技能、项目规模和数据类型的方法。
祝你抓取顺利——再也不用没完没了地 Ctrl+C。用对工具,网页数据提取可以变得自动高效,让你把时间花在更有价值的事情上。告别繁琐的手工操作,迎接更高效的未来!
常见问题解答
Q1:我可以抓取任何网站的数据吗? A1:不一定。有些网站会屏蔽爬虫,或者在服务条款中禁止抓取。一定要先看清楚目标网站的政策。
Q2:AI 网页爬虫的准确率高吗? A2:像 Thunderbit 这样的 AI 网页爬虫准确率很高,但遇到复杂或高度动态的页面时,可能需要手动微调。
Q3:使用网页爬虫工具需要编程基础吗? A3:不需要。Thunderbit 以及其他浏览器插件都是为非技术用户设计的,无需写代码。
Q4:可以从 PDF 或图片中提取哪些数据? A4:OCR 工具不仅能提取文本,还能识别表格,甚至扫描 PDF 和图片中的隐藏信息,让数据采集更灵活。
延伸阅读