
执行摘要
这项研究从四个维度对 1,238 个 DTC 域名 的 AI 搜索就绪度进行了评估:AI 文件质量、通用结构化数据、产品页结构化信号和元数据。平均得分是 100 分中的 36.4 分,中位数为 37.0 分。按这套评分模型看,只有 11 个域名 达到了 ai_ready 档位。
最关键的发现,是“表层可发现性”和“产品层理解能力”之间的落差。规模最大的 llms.txt 质量分组是 platform_default,共有 629 个域名。这说明很多品牌之所以拥有一个基本能被 AI 读取的文件,并不是自己特意搭建的,而是平台自动生成的。相比之下,首页 Product schema 只出现在 0.9% 的被评分域名上;而在尝试抓取产品页的域名中,产品页 Product schema 也只出现在 39.2% 的样本里。产品页价格信号出现在 48.1%,评论或评分信号出现在 43.5%。
档位分布也说明,这个市场还处在早期阶段:
| AI 就绪档位 | 域名数 |
|---|---|
| 未就绪 | 435 |
| 部分就绪 | 425 |
| 基础可发现 | 367 |
| AI 就绪 | 11 |
这个划分之所以有价值,是因为它把常常被混在一起的三个概念区分开了:品牌可能可被发现,品牌可能有元数据,品牌也可能有 llms.txt。但“可被发现”并不等于“能在产品层面被理解”。
llms.txt 的质量分布把这一点讲得更直观:
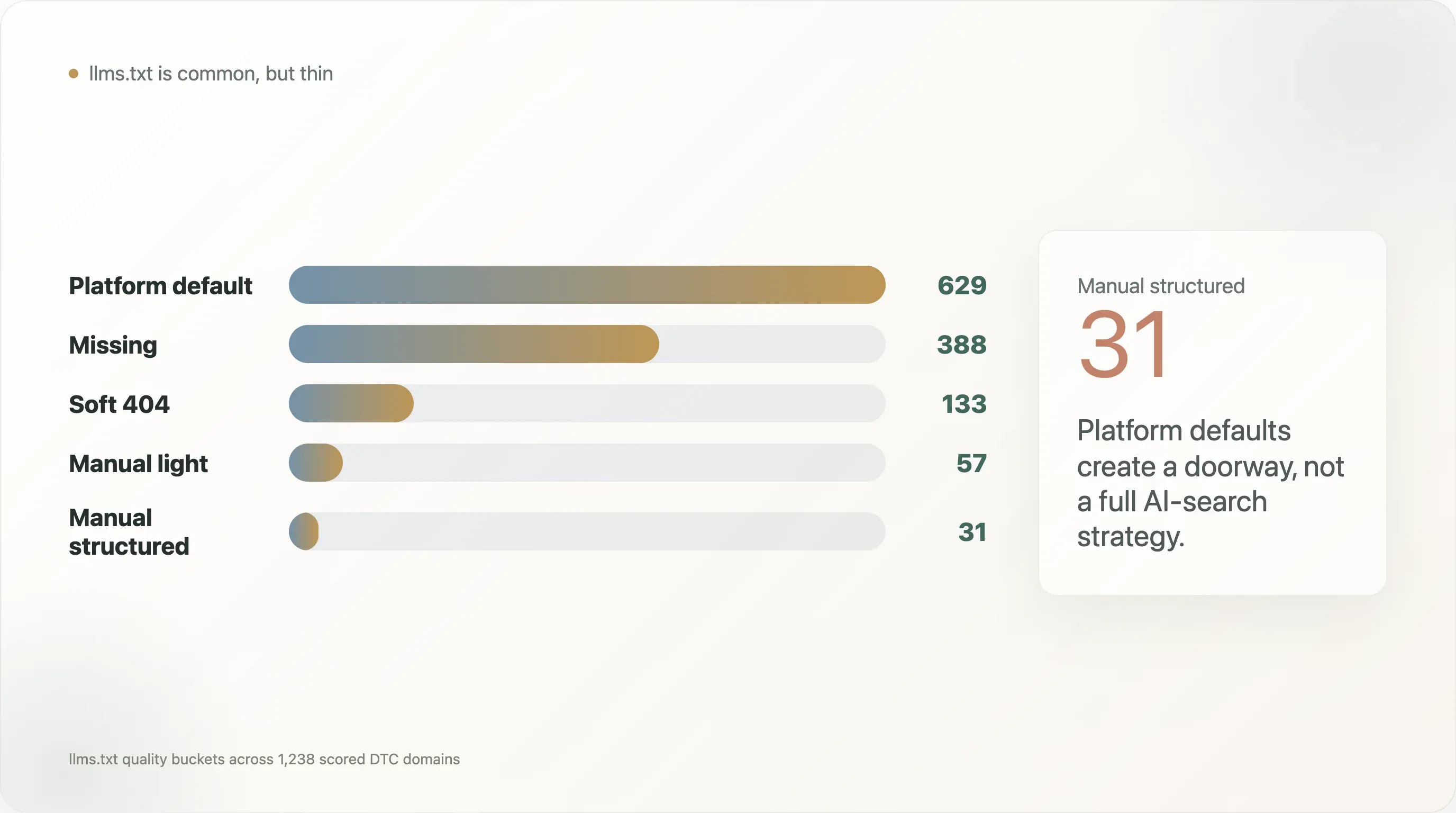
| llms.txt 质量分组 | 域名数 |
|---|---|
| 平台默认 | 629 |
| 缺失 | 388 |
| 软 404 | 133 |
| 人工轻量 | 57 |
| 人工结构化 | 31 |
所以,这份报告最有力的表述并不是“DTC 品牌都有 llms.txt”。这个说法太浅了。更准确的结论是:平台默认文件已经给 AI 可发现性搭了一个很薄的外壳,但大多数 DTC 品牌还没有建立 AI 购物和问答引擎真正需要的产品级结构化数据层。
积极案例则展示了更高就绪度应该是什么样。ai_ready 档位中的品牌包括 Mokobara、Magic Mind、Le Petit Ballon、Maine Lobster Now、Yo Mama's Foods、La Maison Convertible、Unbloat、NuRange Coffee、Three Ships Beauty 和 Manukora。这些例子很重要,因为它们说明,AI 就绪并不只属于某一个品类,也不只属于某一种品牌。食品、美妆、健康、家具、服饰和特色电商品牌,都可以把自己的机器可读产品层做得更好。
最值得传播的发现
-
DTC 的平均 AI 就绪得分只有 36.4/100。
-
1,238 个被评分域名中,只有 11 个达到了
ai_ready档位。 -
llms.txt 很常见,但大多是平台生成的。 最大的质量分组是平台默认,共 629 个域名。
-
人工结构化的 llms.txt 非常少见。 只有 31 个域名进入人工结构化分组。
-
首页 Product schema 几乎缺席。 它只出现在 0.9% 的被评分域名上。
-
产品页 Product schema 更好一些,但仍不完整。 在尝试抓取产品页的域名中,它只出现在 39.2% 的样本里。
-
AI 购物就绪需要的是产品事实,而不只是爬虫访问权限。 价格、优惠、评论、库存和 Product schema 信号,远比一份单薄的文件更重要。
1. 为什么 AI 搜索就绪和基础 SEO 不一样
传统 SEO 关注的是页面能否被抓取、收录、排名和点击。AI 搜索则多了一层:系统是否能理解品牌、产品、优惠、价格、评论、库存、政策和实体关系,并据此回答问题或推荐产品?
这个差异对 DTC 尤其重要,因为电商页面本身就充满了对人类来说很清楚、对机器来说却可能很混乱的细节。消费者看产品页时,可以轻松理解产品名、价格、尺寸、订阅选项、折扣、评论、库存状态和退货政策;而爬虫或 AI 代理需要把这些事实以一致的方式表达出来。
元数据有帮助。Open Graph 有帮助。规范标签有帮助。llms.txt 也可能有助于爬虫找到重要内容。但真正的考验是产品级结构。如果一个 AI 购物助手要比较五款蛋白粉、护肤品、蜡烛、连衣裙或咖啡订阅,它需要的是结构化事实。没有这些事实,品牌也许可见,却不一定能被可靠理解。
这份报告把就绪度分成四个层级:
- AI 文件层: 是否存在 llms.txt,以及它是缺失、软 404、平台默认、人工轻量还是人工结构化。
- 通用结构化数据层: JSON-LD、Organization、WebSite、BreadcrumbList 和 Product schema。
- 产品页层: Product schema、优惠或价格信号、评分或评论信号,以及库存信号。
- 元数据层: 规范链接、元描述、Open Graph 图片、Twitter 卡片、hreflang 以及类似的机器可读上下文。
这种分层模型很重要,因为它能避免得出过于表面的结论。一个有 llms.txt 但没有产品事实的品牌,并没有看起来那么就绪;而一个没有 llms.txt、但产品页结构化程度很高的品牌,可能比文件层面显示得更容易被理解。
2. llms.txt 的故事:一层很薄的外壳,主要由平台创建
llms.txt 审计得出了五个质量分组:
| 质量分组 | 域名数 | 解释 |
|---|---|---|
| 平台默认 | 629 | 标准的平台生成文件,通常较薄,但有效 |
| 缺失 | 388 | 没有找到可用文件 |
| 软 404 | 133 | 返回了内容,但并不是有用的 llms.txt 文件 |
| 人工轻量 | 57 | 人工创建或自定义文件,但结构有限 |
| 人工结构化 | 31 | 更完整的人工文件,包含标题、链接、产品或政策术语 |
这正是本报告里最重要的细微差别。表面上看,llms.txt 的采用率似乎很高,因为平台默认文件非常常见。但平台默认并不等于经过深思熟虑的 AI 搜索策略,它通常只是一个基础入口层。
这并不意味着平台默认文件没有价值。它们也许能帮爬虫找到关键路径,也说明平台层面的决策可以多快地改变市场。甚至在大多数品牌团队还没开始讨论 AI 搜索运营之前,平台就已经能先给成百上千家商店提供一个新的机器可读文件。
但人工结构化分组要小得多:只有 31 个域名。审计中出现的例子包括 Dermalogica、Ad Hoc Atelier、DKNY,以及一些 ai_ready 例子,比如 Magic Mind、Le Petit Ballon、Maine Lobster Now、Yo Mama's Foods 和 Three Ships Beauty。这些都是很好的正面案例,因为它们展示了超越默认文件意味着什么:更多链接、更多标题、更多产品术语、更多政策术语,以及更有意识的结构设计。
软 404 分组也很重要。软 404 的意思是请求返回了内容,但并不是有用的 llms.txt 文件。这会让简单的审计结果产生误导。对 AI 搜索就绪度来说,不能只看“有没有”,还要看“质量好不好”。
3. 产品层结构才是真正的差距
数据里最明显的差距,是 Product schema。
首页 Product schema 只出现在 0.9% 的被评分域名上。产品页 Product schema 出现在 39.2% 的被评分域名上,而这些样本都是已经尝试抓取产品页的。产品页价格信号出现在 48.1%,评论或评分信号出现在 43.5%。
这些数字讲得很清楚:即使品牌已经有电商店面,基础产品事实也并没有稳定地变成机器可读信息。
这很重要,因为 AI 搜索和 AI 购物更容易奖励“清晰度”。如果产品页暴露了 Product schema、优惠信息、价格、库存、评论信号和政策链接,机器就能拿到更可靠的事实;如果这些事实被埋在 JavaScript 里,或者散落在不一致的模板、图片或动态组件中,机器就可能误解,甚至直接忽略。
就绪度差距不只是关乎排名,更关乎“如何被表述”。当 AI 系统总结某个品类、比较选项、回答“最适合什么”这类问题,或者生成购物推荐时,产品事实更清晰的品牌,往往更容易被准确纳入其中。
ai_ready 组里的正面案例说明了这一点:
- Mokobara 以 83 分 位居最高分。
- Magic Mind、Le Petit Ballon 和 Maine Lobster Now 都拿到了 81 分。
- Yo Mama's Foods 得到 80 分。
- La Maison Convertible、Unbloat、Vinocheepo 和 NuRange Coffee 得到 79 分。
- Three Ships Beauty 得到 77 分。
- Manukora 得到 75 分。
这些案例横跨多个品类。AI 就绪并不是美妆行业才需要,也不是科技行业才需要;食品、健康、家具、服饰、特色产品,以及任何可能被用户拿去问 AI 做推荐、比较或解释的品类,都需要它。
4. AI 就绪档位:大多数品牌仍在及格线以下
档位分布如下:
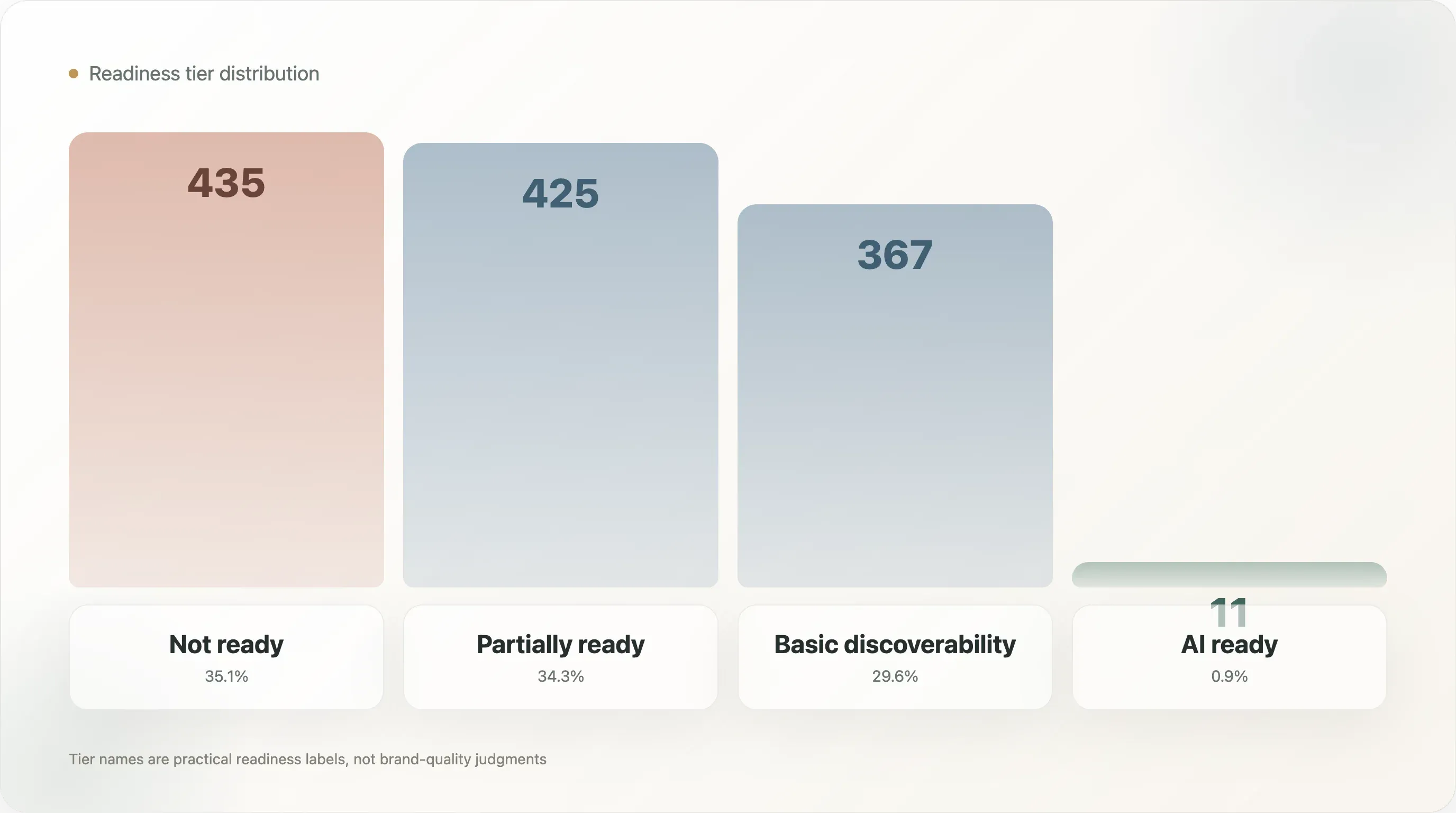
| 档位 | 域名数 | 样本占比 |
|---|---|---|
| 未就绪 | 435 | 35.1% |
| 部分就绪 | 425 | 34.3% |
| 基础可发现 | 367 | 29.6% |
| AI 就绪 | 11 | 0.9% |
这些名字是刻意设计的,而且很务实。Not ready 并不代表品牌本身不好,它只是说明这个模型所用的公开信号,没有显示出足够的 AI 搜索就绪度。Partially ready 的意思是有一部分已经到位,但关键层仍然缺失。Basic discoverability 的意思是品牌对机器更可见了,但可能仍然缺少产品层完整性。AI ready 则意味着这个域名在文件质量、结构化数据、产品事实和元数据之间,形成了更强的组合。
只有 11 个域名 达到了最高档位。这当然是头条,但更有价值的洞察,是中间地带的形状:样本几乎平均分布在未就绪、部分就绪和基础可发现三类之间。市场并不是空白,而是在过渡期。很多品牌已经有了一些信号,但真正完整的系统很少。
这也带来了一个近在眼前的机会。AI 搜索就绪度仍处于早期阶段,所以品牌只要做一些相对务实的工作,就有可能从“平均”提升到“强”:改进 llms.txt、验证 schema、暴露产品事实、整理元数据,并让产品页更容易被机器解析。
5. 品类模式:美妆和服饰领先,但没有哪个品类已经做完
品类分类是方向性的,不是绝对精确的。不过,这张品类表仍然能看出一些有用的模式:
| 品类 | 样本数 | 平均 AI 就绪度 | 人工或结构化 llms | 产品页 schema | 产品页 schema 率 |
|---|---|---|---|---|---|
| 美妆与护肤 | 98 | 46.2 | 3 | 56 | 57.1% |
| 服饰与鞋类 | 149 | 45.7 | 6 | 79 | 53.0% |
| 珠宝与配饰 | 34 | 44.5 | 0 | 20 | 58.8% |
| 宠物 | 15 | 43.5 | 0 | 8 | 53.3% |
| 婴童 | 27 | 42.6 | 1 | 15 | 55.6% |
| 食品与饮料 | 118 | 42.5 | 5 | 58 | 49.2% |
| 家居与家具 | 48 | 42.3 | 0 | 23 | 47.9% |
| 健康与保健 | 58 | 40.7 | 6 | 27 | 46.6% |
| 户外与运动 | 49 | 39.8 | 1 | 23 | 46.9% |
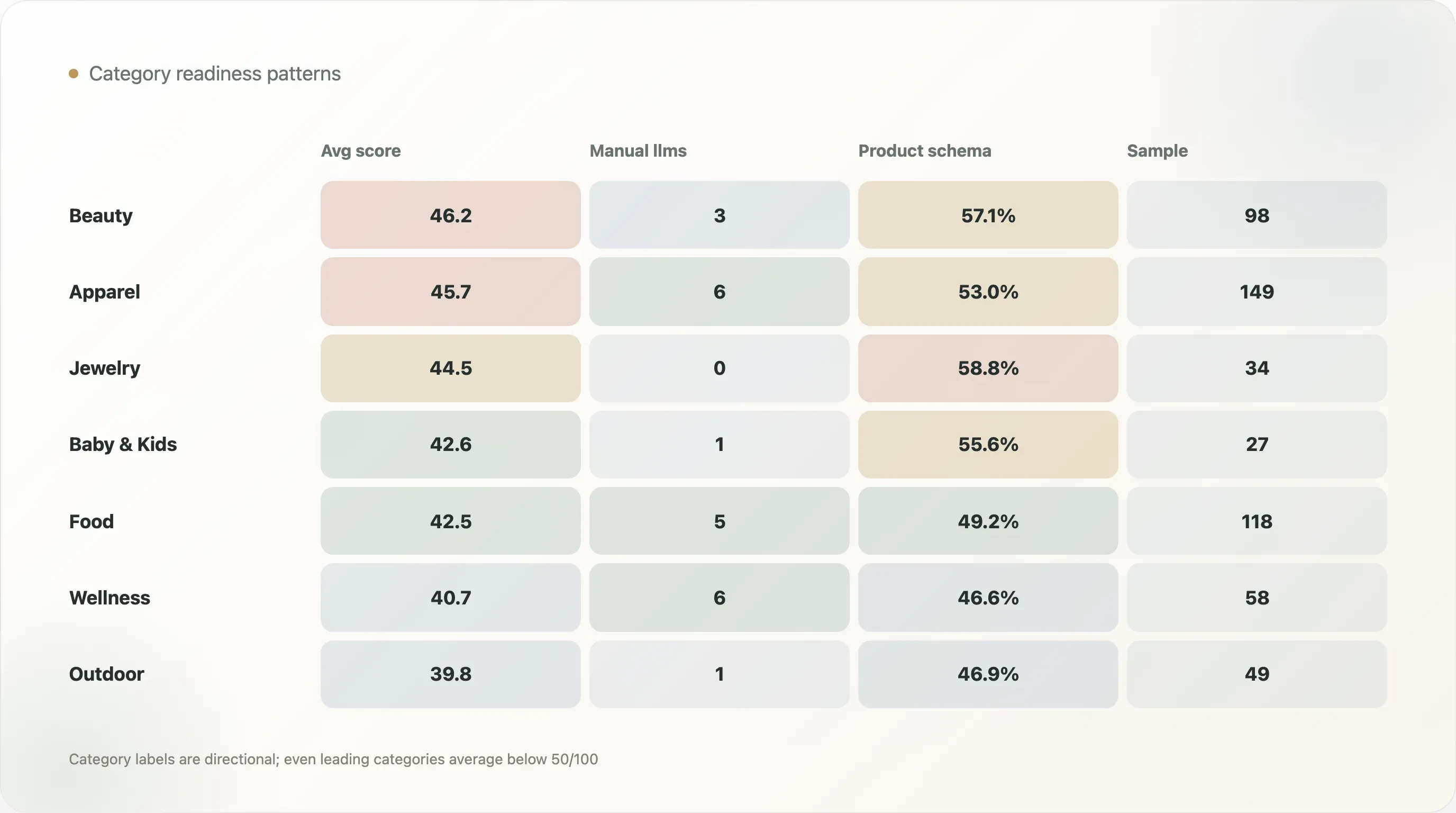
美妆与护肤的平均 AI 就绪得分最高,达到 46.2。服饰与鞋类紧随其后,为 45.7。这些品类通常拥有更成熟的电商模板、更丰富的产品目录、更多评论和变体、更多视觉素材,也有更强的内容需求,因此更容易从结构化产品工作中获益。
珠宝与配饰的产品页 schema 率很高,达到 58.8%,但在品类表中没有检测到人工或结构化的 llms.txt。这正好说明了为什么就绪度必须分层看:一个品类可以在产品 schema 上很强,但在 AI 文件质量上却很弱。
食品与饮料里包含了多个很强的正面案例,包括 Maine Lobster Now、Yo Mama's Foods、NuRange Coffee 和 Manukora。这很重要,因为食品饮料产品通常需要非常清楚的事实:成分、营养、份量、订阅、产地、配送、储存、评论和库存。只有当网站把这些内容清清楚楚地暴露出来,AI 系统才能准确呈现。
健康与保健的人工或结构化 llms 占比为 10.3%,在表中的主要品类里是最高的,但平均得分只有 40.7。这说明这个品类里的一些品牌已经开始认真尝试 AI 可读文件,但产品页结构仍然有很大的提升空间。考虑到健康与保健领域对信任和教育的要求,这个品类本来就应该更积极地推进结构化事实。
没有哪个品类已经把这件事做完。即使领先品类的平均分,也都低于 50/100。这也让“按品类切入的 AI 就绪内容”成了 SEO 写手和顾问的一个很强的机会点。
6. 什么是好样子:来自 AI 就绪品牌的正面模式
ai_ready 组虽然很小,但很有价值,因为它展示了值得复制的模式。
Mokobara 拿到 83 分,是输出中的最高分。它更像是综合就绪度很强的例子,而不是靠单一信号取胜的例子。
Magic Mind、Le Petit Ballon 和 Maine Lobster Now 都拿到 81 分,而且都属于人工结构化 llms 分组。这一点很重要,因为它们展示的是有意识地做文件层工作,而不只是依赖平台默认文件。
Yo Mama's Foods 拿到 80 分,同样属于人工结构化 llms。食品品牌尤其能从 AI 可读结构中受益,因为 AI 系统可能会被问到成分、口味、使用场景、食谱、饮食适配性和对比问题。
Three Ships Beauty 拿到 77 分,而且也有人工结构化 llms。美妆是做结构化 AI 就绪的理想品类,因为消费者会问肤质、成分、护理步骤、质地、评论和替代方案。
Manukora 拿到 75 分。蜂蜜和健康相关食品往往需要围绕产地、品质、益处、认证和使用方式做教育,因此结构化的产品和政策信号非常有价值。
这里的教训不是“每个品牌都要长得一样”。真正的结论是:AI 就绪是一个系统:
- 有用的 llms.txt 文件
- 干净的元数据
- 结构化的组织和网站数据
- 产品页 schema
- 价格和优惠信号
- 评论或评分信号
- 库存信号
- 清晰的政策和支持信息
任何一个层面都能帮上忙,而真正形成就绪度的是这些层面的组合。
7. 为什么只靠 llms.txt 还不够
llms.txt 现在已经成了 AI 就绪度的一个方便代称。这可以理解,因为它可见、易检查,而且又新到足以显得很有策略性。但这项研究也说明了,为什么它不能被当成全部故事。
一个平台默认的 llms.txt 文件可以建立基础入口,它也许能把爬虫指向重要页面,也许能告诉机器这个站点有一个 AI 可读入口。但如果产品页没有清楚地暴露产品事实,这个入口最后只会通向一个乱糟糟的房间。
AI 搜索的问题不只是“爬虫能不能找到这个站点?”,而是:
- 爬虫能识别这个产品吗?
- 能识别这个品牌吗?
- 能解析价格吗?
- 能解析库存吗?
- 能识别评论或评分吗?
- 能区分产品内容和营销内容吗?
- 能理解政策吗?
- 能比较不同变体吗?
- 能引用正确的规范页面吗?
llms.txt 解决的是导航和优先级问题。结构化产品数据解决的是理解问题。AI 就绪需要两者同时具备。
8. 运营手册:如何提升 AI 搜索就绪度
对 DTC 和电商团队来说,实际操作路径很直接。
步骤 1:检查 AI 文件层。 域名是否有 llms.txt?它是真文件,还是软 404?它是平台默认、人工轻量,还是结构化文件?它有没有指向有用页面?
步骤 2:审计元数据。 确认规范标签、元描述、Open Graph 图片、Twitter 卡片、相关的 hreflang 以及移动端 viewport。这些不花哨,但能帮机器建立上下文。
步骤 3:验证 JSON-LD。 检查 Organization、WebSite、BreadcrumbList 和 Product schema。Product schema 是电商最重要的缺口。
步骤 4:审计产品页,而不只是首页。 AI 购物更关注产品页。确认产品名、描述、图片、价格、优惠、库存、SKU、评论、评分、变体和退货政策。
步骤 5:让产品事实稳定可见。 不要把关键产品事实只放在图片里、不会被干净渲染的标签页里,或者爬虫可能解析不了的 JavaScript 组件里。
步骤 6:提升政策清晰度。 配送、退货、订阅条款、保障、认证和安全声明都应该容易找到,也容易被解析。
步骤 7:模板变更后重新测试。 schema 常常会在重新设计、主题切换、应用更新和无头架构迁移时失效。要把结构化数据当作 QA 的一部分。
步骤 8:由整个系统共同负责。 AI 就绪不应该只归 SEO 管。它会影响电商、产品、内容、工程、法务和客服。
9. SEO 与内容团队可以怎么引用
这项研究提供了几个很强的引用角度:
“1,238 个被评分的 DTC 域名中,只有 11 个达到了 AI 就绪档位。” 这是最直接的整体切入点。
“llms.txt 很常见,但大多是平台生成的。” 平台默认分组包含 629 个域名,而人工结构化文件只有 31 个。
“首页 Product schema 只出现在 0.9% 的被评分域名上。” 这是最尖锐的结构化数据缺口。
“在尝试抓取产品页的样本中,产品页 Product schema 只出现在 39.2%。” 这补充了细节:产品页比首页更好,但还是不完整。
“美妆和服饰在品类表中领先,但平均分仍然低于 50/100。” 这是一个很适合按品类切入的角度。
“AI 就绪是分层的。” 对那些可能会把 llms.txt 直接等同于就绪度的读者来说,这是最重要的教育点。
需要说明的是,这些数据反映的是本样本中的公开网站信号,而不是整个行业的总采用率,也不是内部搜索表现。
10. AI 购物会如何改变 DTC 团队的工作
传统电商发现路径是围绕页面、排名、广告和点击构建的。消费者搜索、比较结果、打开页面、读评论,然后做决定。AI 购物和问答引擎把这段旅程压缩了。消费者可能会直接问“最适合工作日晚餐的低糖酱料”“200 美元以内、评价好的登机箱背包”或“适合敏感肌、无香精的温和洁面”。在消费者真正看到品牌页面之前,AI 系统可能就已经把选项总结好了。
这改变了产品页的职责。它仍然要打动人类,但也必须把产品说明得足够清楚,让机器能够比较。品牌语气还不够。漂亮的图片还不够。聪明的产品名也不够。机器需要的是事实:它是什么、适合谁、多少钱、是否有货、有哪些变体、评论怎么说、哪些声明有依据、哪些成分或材质重要,以及适用哪些政策。
这就是为什么产品层结构比通用 AI 文件更重要。llms.txt 可以帮爬虫知道该去哪里找;Product schema 和干净的产品页事实,则能帮它理解自己找到了什么。
对 DTC 品牌来说,风险不只是被排除在外,还包括被错误呈现。如果产品页不清楚,AI 答案可能会总结错特征、漏掉关键差异点、忽略重要政策,或者把它和结构更好的竞争对手进行不公平比较。从这个意义上说,AI 就绪也部分是品牌保护问题。
对于考虑路径更复杂的品类,风险更高。美妆消费者会问肤质、成分、护理步骤、敏感性和效果;食品消费者会问营养、过敏原、产地、口味、食谱和饮食适配;服饰消费者会问版型、尺码、面料、退货和搭配;健康与保健消费者会问证据、使用方式、安全性和可信度;家居消费者会问尺寸、材质、配送、组装和耐用性。这些既是营销问题,也是机器可读内容问题。
机会在于,大多数品牌还处在很早期。平均就绪分数只有 36.4/100,而且只有 11 个域名 达到了 ai_ready 档位。品牌不必等到把整个站点重建完才开始;它可以先从模板、schema、政策清晰度和产品事实入手。
11. 按部门拆分的 AI 就绪计划
AI 就绪不应该只由 SEO 负责,它会影响多个团队。
SEO 负责可发现性和 schema 验证。 SEO 团队应该审计规范标签、元数据、结构化数据、产品 schema、面包屑、hreflang 和可抓取性。他们还应监测产品 schema 是否在主题变更和应用更新后依然存在。
电商团队负责产品页事实。 产品名称、价格、变体、库存、套装、订阅、评论、配送条款和退货细节都必须清晰且一致。如果这些事实分散在组件、标签页、图片和脚本里,机器就很难处理。
内容团队负责解释深度。 AI 系统会奖励那些能清楚回答问题的页面。购买指南、对比表、成分说明、使用场景页面、尺码指南和 FAQ 都能帮助人和机器。
工程团队负责实现质量。 schema 必须有效、稳定,并由模板驱动。产品事实不应该完全依赖脆弱的客户端渲染。产品页模板在发布后也要测试。
法务和合规团队负责声明。 如果产品涉及健康、可持续性、安全、成分或性能声明,这些说法必须准确、可支撑、也容易理解。AI 系统可能会放大不清楚的表述。
客服团队负责高频问题。 支持工单会揭示消费者和 AI 系统可能会问什么:配送时间、版型、成分、兼容性、退货、订阅取消、护理说明和产品比较。这些问题都应该反哺产品页内容。
管理层负责优先级。 AI 就绪会和很多其他项目争资源。领导层最简单的理由是:结构化产品事实会同时支持 SEO、AI 搜索、产品 feed、付费购物、站内搜索、客服和转化。这不只是一个 AI 项目。
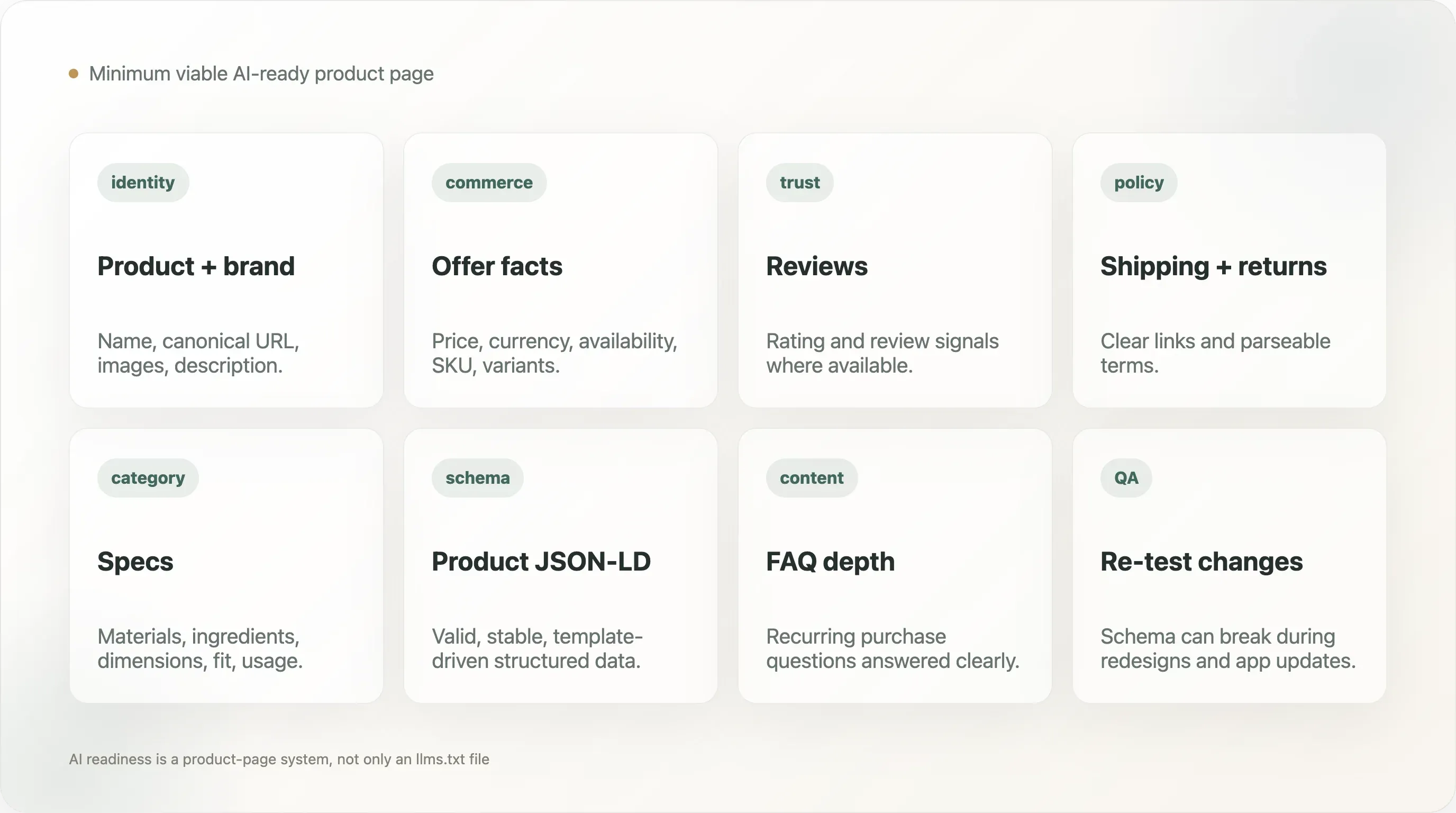
12. 最小可行的 AI 就绪产品页
一个实用的 DTC 产品页应该暴露以下内容:
- 产品名称
- 品牌名称
- 规范 URL
- 产品描述
- 产品图片
- 价格
- 货币
- 库存状态
- 变体信息
- SKU 或产品标识符(如适用)
- 评论或评分信号(如有)
- 优惠详情
- 配送和退货政策链接
- 与品类相关的材质、成分或规格信息
- 用于回答常见购买问题的 FAQ 或支持内容
页面还应该包含有效的 Product schema,并避免把关键事实只藏在图片里,或者藏在爬虫可能无法解析的脚本中。这并不意味着产品页要变得无聊;它要求把“有说服力的设计”和“可靠的结构化事实”分开。
对很多品牌来说,最快的胜利不是写一份很长的 AI 战略文档,而是先验证十个关键产品页,修好 schema,并确保最重要的产品事实能在 HTML 和结构化数据中清楚呈现。
方法论
这项研究使用的是 2026 年 5 月 11 日 收集的 DTC 双报告数据集。它基于 master.csv、detection.csv、seo_signals.csv、原始 llms.txt 文件,以及可用的原始产品页 HTML,对 1,238 个域名 进行了评分。
评分模型分为四层:
- AI 文件层: llms.txt 的存在与质量。
- 通用结构化数据层: JSON-LD、Organization、WebSite、BreadcrumbList、Product 及相关结构化信号。
- 产品页层: Product schema、优惠或价格信号、评论或评分信号,以及库存信号。
- 元数据层: 规范链接、元描述、Open Graph 图片、Twitter 卡片、hreflang 以及相关页面上下文。
该模型会生成 0 到 100 的 AI 就绪分数,并把域名分为四个档位之一:未就绪、部分就绪、基础可发现和 ai_ready。
注意事项
-
AI 就绪不等于 AI 流量。 这个分数不衡量来自 AI 搜索系统或购物代理的实际引荐流量。
-
公开信号只是下限。 有些结构化数据可能是动态加载的,或者以爬取未能捕捉到的方式出现。
-
llms.txt 质量采用启发式判断。 人工结构化文件是通过可观察到的文件特征识别的,例如标题、链接、产品术语和政策术语。
-
产品页检测依赖于是否成功尝试抓取产品页。 产品页 schema 的百分比仅适用于已经尝试且可用的产品页。
-
样本并不是完整的 DTC 普查。 它会偏向那些在电商工具生态和公开 DTC 名录中更容易被看到的品牌。
-
品类标签是方向性的。 它们适合做大致比较,但不是精确分类法。
-
AI 搜索标准仍在演变。 评分模型被设计为一个实用的 2026 年基准,而不是永久定义。
可复现性说明
交付文件夹包含:
analyze_ai_search_readiness.py— 用于评估 DTC 域名在llms.txt、结构化数据、产品页信号和元数据上得分的脚本。ai_search_readiness_scores.csv— 域名级 AI 就绪分数、档位和组件信号。llms_quality_audit.csv— 域名级llms.txt质量审计,包括平台默认、软 404、缺失、人工轻量和人工结构化分类。category_ai_readiness.csv— 品类级 AI 就绪对比。top_ai_ready_brands.csv— 最高分域名,用于编辑审阅和示例筛选。lowest_ai_ready_brands.csv— 最低分域名,用于差距分析和编辑审阅。summary.json— 本报告中引用的头条汇总指标,包括样本量、档位数量、平均分、中位数和产品页信号率。
如需方法论修正、数据集问题或后续分析,欢迎联系 support@thunderbit.com。本报告的发布独立于 Thunderbit 所持有的任何商业立场;我们打造的是一款 AI 驱动的网页爬虫,而我们在结构上也有动机,希望公开电商网站能更容易被人类、搜索引擎和 AI 代理准确理解。本基准基于 2026 年 5 月 11 日收集的 1,238 个已评分 DTC 域名的公开网站信号。本文数据自成体系。—— Thunderbit 研究团队,2026 年 5 月。