互联网里藏着无数有价值的数据,但大多数网页内容都没法直接下载。到了 2025 年,网页爬虫已经从小众技能变成了各类团队(比如价格监控、招聘、房产、竞品分析等)不可或缺的利器。问题是,GitHub 上的网页爬虫项目五花八门,有的成熟易用,有的上手门槛高,还有不少项目早就没人维护了。特别是对非开发者来说,怎么挑到合适的项目?
这篇指南会带你详细了解 2025 年 GitHub 上最值得一试的 15 个网页爬虫项目。不只是简单罗列,我会从安装难度、适用场景、动态网页支持、维护活跃度、数据导出方式和适合人群等多个角度帮你对比。如果你已经不想再和代码死磕,也能看到像 这样无需编程、AI 驱动的新一代工具,普通用户和非技术团队也能轻松搞定数据采集。
我们怎么筛选出这 15 个 GitHub 网页爬虫项目?
说实话,GitHub 上的项目质量参差不齐。有些项目被成千上万用户验证过,有些只是开发者的周末练手。我们的筛选标准包括:
- GitHub Star 数 & 社区活跃度: 既有几千 Star 的热门项目,也有 9 万+ Star 的超级明星,社区活跃、贡献者多。
- 近期更新: 2025 年还在维护的项目,避免用到“数字化化石”。
- 文档与易用性: 文档清晰、示例代码齐全、上手门槛合理。
- 真实应用场景: 被实际用于商业或科研数据采集,而不是“Hello World”演示。
考虑到大家需求不同,我们还会从以下几个方面对每个项目进行对比:
- 安装与配置难度: 是几分钟就能跑起来,还是要折腾各种依赖和驱动?
- 适用场景: 更适合电商、新闻、科研,还是其他领域?
- 动态网页支持: 能不能搞定现在流行的 JavaScript 网站?
- 项目活跃度: 还在持续维护,还是早就没人管了?
- 数据导出方式: 能不能直接导出结构化数据,还是只给你一堆 HTML?
- 适用人群: 适合 Python 新手、数据工程师,还是非技术团队?
每个项目都会有一目了然的标签,方便你根据自己的需求快速定位,无论你是代码高手,还是只想把数据导入 Google 表格的小白。

安装与配置难度:最快多久能开始爬?
对大多数人来说,最大障碍就是怎么让爬虫顺利跑起来。我们把难度分成三档:
- 即装即用(零配置): 安装就能用,几乎不用设置,适合新手。
- 中等难度(命令行/少量代码): 需要写点代码或用命令行,有脚本经验的人能轻松搞定。
- 进阶难度(驱动/反爬/深度开发): 需要环境配置、浏览器驱动或较强的 Python/JS 能力。
主流项目难度分布如下:
- 即装即用: MechanicalSoup(Python)、Nokogiri(Ruby)、Maxun(部署后适合终端用户)
- 中等难度: Scrapy、Crawlee、Node Crawler、Selenium、Playwright、Colly、Puppeteer、Katana、Scrapling、WebMagic
- 进阶难度: Heritrix、Apache Nutch(需要 Java、配置文件或大数据环境)
如果你不是开发者,建议优先选“即装即用”或无代码工具。其他项目虽然要写代码,但难度也不算太高。
按应用场景分组:找到最适合你的爬虫
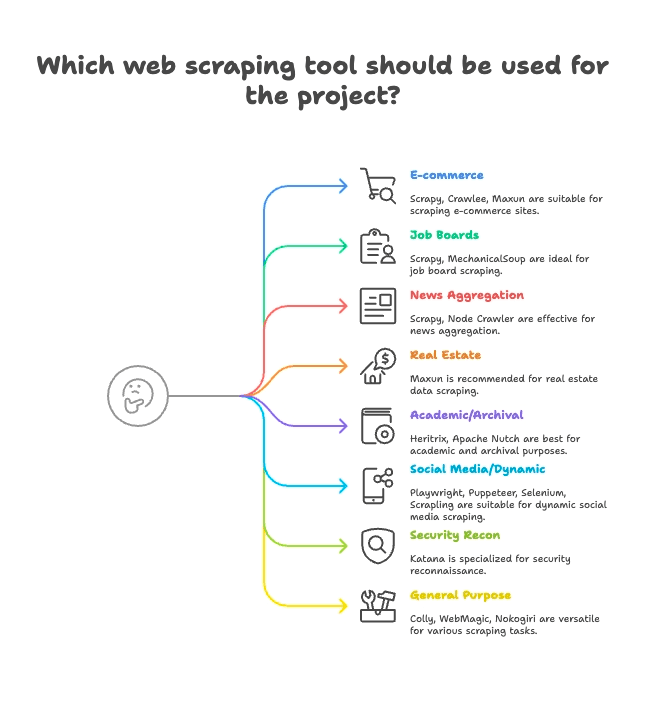
不同爬虫项目各有专长,下面是 15 个主流项目的最佳应用场景分组:
电商 & 价格监控
- Scrapy: 适合大规模、多页面商品采集
- Crawlee: 静态/动态电商网站都能搞定,灵活强大
- Maxun: 无代码,快速提取商品列表
招聘 & 职位信息
- Scrapy: 支持分页、结构化职位列表
- MechanicalSoup: 适合需要登录的招聘网站
新闻 & 内容聚合
- Scrapy: 大规模新闻站点爬取
- Node Crawler: 静态新闻聚合高效
房产数据
- Thunderbit: AI 智能采集列表+详情页
- Maxun: 可视化选择房源信息
学术研究 & 网页归档
- Heritrix: 全站归档(WARC 文件)
- Apache Nutch: 分布式爬取科研数据集
社交媒体 & 动态内容
- Playwright、Puppeteer、Selenium: 动态内容采集、模拟登录
- Scrapling: 针对反爬机制的隐身爬取
安全测试 & 资产探测
- Katana: 快速发现 URL、进行安全爬取
通用/多用途爬虫
- Colly: Go 语言高性能通用爬虫
- WebMagic: Java 平台,适用多领域
- Nokogiri: Ruby 解析自定义脚本
动态网页支持:这些 GitHub 项目能爬现代网站吗?
现在的网站大量用 JavaScript(比如 React、Vue、无限滚动、AJAX)。如果你爬过页面却啥都没抓到,肯定体会过那种“空手而归”的无力感。
各项目对动态内容的支持情况如下:
- 原生支持 JS(无头浏览器):
- Selenium: 控制真实浏览器,完整执行 JS
- Playwright: 多浏览器、多语言,JS 支持很强
- Puppeteer: 支持 Chrome/Firefox,无头模式渲染 JS
- Crawlee: 可切换 HTTP/浏览器(集成 Puppeteer/Playwright)
- Katana: 可选无头模式解析 JS
- Scrapling: 集成 Playwright,隐身爬取 JS 内容
- Maxun: 底层用浏览器处理动态内容
- 不支持 JS(只抓静态 HTML):
- Scrapy: 需要配合 Selenium/Playwright 插件
- MechanicalSoup、Node Crawler、Colly、WebMagic、Nokogiri、Heritrix、Apache Nutch: 只能抓 HTML,没法直接处理 JS
Thunderbit 的 AI 在这方面特别强:自动识别并采集动态内容,无需手动配置、插件或选择器。只要点一下“AI 智能识别字段”,哪怕是 React 重度网站也能轻松搞定。想了解更多原理,可以看看 。
项目活跃度与可靠性:明年还能用吗?
最糟糕的情况就是,辛苦搭建的流程突然因为项目没人维护而“崩盘”。主流项目活跃度如下:
- 持续活跃(频繁更新):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- 稳定但更新较慢:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- 维护模式(专用型,更新慢):
- Heritrix:
- Apache Nutch:
Thunderbit 作为托管服务,无需担心项目弃坑。AI、模板和集成持续更新,遇到问题还有新手引导、教程和客服支持。
数据处理与导出:从原始 HTML 到业务可用数据
拿到数据只是第一步,关键是能不能直接导出成团队能用的格式(比如 CSV、Excel、Google Sheets、Airtable、Notion,甚至 API)。
- 内置结构化导出:
- Scrapy: 支持 CSV、JSON、XML 导出
- Crawlee: 灵活的数据集与存储
- Maxun: 支持 CSV、Excel、Google Sheets、JSON API
- Thunderbit:
- 手动处理(需自定义代码):
- MechanicalSoup、Node Crawler、Selenium、Playwright、Puppeteer、Colly、WebMagic、Nokogiri、Scrapling: 需要自己写导出逻辑
- 专用导出:
- Heritrix: WARC(网页归档文件)
- Apache Nutch: 原始内容存储/索引
Thunderbit 的结构化导出和多平台集成极大节省了业务用户的时间,无需再手动处理 CSV 或写代码,数据一键可用。
适用人群:每个 GitHub 网页爬虫项目适合谁?
不是每个工具都适合所有人。推荐如下:
- Python 新手: MechanicalSoup、Scrapling(进阶可尝试)
- 数据工程师: Scrapy、Crawlee、Colly、WebMagic、Node Crawler
- 测试/自动化专家: Selenium、Playwright、Puppeteer
- 安全研究员: Katana
- Ruby 开发者: Nokogiri
- Java 开发者: WebMagic、Heritrix、Apache Nutch
- 非技术/业务团队: Maxun、Thunderbit
- 增长黑客、分析师: Maxun、Thunderbit
如果你不想写代码,或者追求高效,Thunderbit 和 Maxun 是首选。其他用户可以根据自己的语言和场景选择合适工具。
2025 年 GitHub 最佳网页爬虫项目详细对比
下面会按应用场景分组,逐一介绍每个项目的亮点和标签。
电商、价格监控与通用爬取
— 57.1k stars,2025 年 6 月更新

- 简介: 高级异步 Python 框架,适合大规模爬取
- 安装: 中等难度(需要 Python 编码,异步框架)
- 场景: 电商、新闻、科研、多页面爬虫
- JS 支持: 不支持(需配合 Selenium/Playwright 插件)
- 维护: 持续活跃
- 导出: 内置 CSV、JSON、XML
- 适用人群: 开发者、数据工程师
- 亮点: 可扩展性强,插件丰富,新手学习曲线较陡
— 17.9k stars,2025 年

- 简介: Node.js 全功能爬虫库,支持静态与动态网页
- 安装: 中等难度(Node/TS 编码)
- 场景: 电商、社交媒体、自动化
- JS 支持: 支持(集成 Puppeteer/Playwright)
- 维护: 非常活跃
- 导出: 灵活(数据集、存储)
- 适用人群: JS/TS 开发团队
- 亮点: 反封锁工具包,HTTP/浏览器模式切换便捷
— 13k stars,2025 年 6 月

- 简介: 开源无代码网页数据提取平台,界面可视化
- 安装: 中等难度(需服务器部署),终端用户易用
- 场景: 通用、电商、业务数据采集
- JS 支持: 支持(底层浏览器)
- 维护: 活跃且增长快
- 导出: CSV、Excel、Google Sheets、JSON API
- 适用人群: 非技术用户、分析师、团队
- 亮点: 所见即所得采集,多层级导航,支持自部署
招聘、职位信息与简单交互
— 4.8k stars,2024 年

- 简介: Python 库,自动化表单提交与简单导航
- 安装: 即装即用(Python,极少代码)
- 场景: 需登录的招聘网站、静态页面
- JS 支持: 不支持
- 维护: 成熟,偶有更新
- 导出: 无内置(需手动)
- 适用人群: Python 新手、快速脚本
- 亮点: 几行代码模拟浏览器会话,不适合动态网站
新闻聚合与静态内容
— 6.8k stars,2024 年

- 简介: 高并发服务器端爬虫,集成 Cheerio 解析
- 安装: 中等难度(Node 回调/异步)
- 场景: 新闻、静态内容高效采集
- JS 支持: 不支持(仅 HTML)
- 维护: 活跃度中等(v2 测试版)
- 导出: 无内置(需自定义)
- 适用人群: Node.js 开发者、高并发需求
- 亮点: 异步爬取、速率限制、类 jQuery API
房产、列表与详情页采集

- 简介: 面向业务用户的 AI 网页爬虫,无需代码
- 安装: 即装即用(Chrome 插件,2 步完成)
- 场景: 房产、电商、销售、营销、任意网站
- JS 支持: 支持(AI 自动识别动态内容)
- 维护: 持续更新,托管服务
- 导出: 一键导出 Sheets、Airtable、Notion、CSV、JSON
- 适用人群: 非技术用户、业务团队、销售、市场
- 亮点: AI 智能识别字段、子页面采集、即刻导出、模板丰富,
学术研究与网页归档
— 3k stars,2023 年

- 简介: Internet Archive 官方网页归档爬虫
- 安装: 进阶难度(Java 应用,需配置文件)
- 场景: 全站归档、域名级爬取
- JS 支持: 不支持(仅抓取)
- 维护: 稳定维护(更新较慢)
- 导出: WARC(网页归档文件)
- 适用人群: 档案馆、图书馆、机构
- 亮点: 可扩展、稳定、标准合规,不适合定向采集
— 3k stars,2024 年

- 简介: 面向大数据和搜索引擎的开源爬虫
- 安装: 进阶难度(需 Java+Hadoop)
- 场景: 搜索引擎爬取、大数据采集
- JS 支持: 不支持(仅 HTTP)
- 维护: 活跃(Apache)
- 导出: 原始内容存储/索引
- 适用人群: 企业、大数据、学术研究
- 亮点: 插件架构、分布式爬取
社交媒体、动态内容与自动化
— ~30k stars,2025 年

- 简介: 浏览器自动化,支持主流浏览器
- 安装: 中等难度(需驱动,多语言)
- 场景: JS 重度网站、测试流程、社交媒体
- JS 支持: 支持(完整浏览器自动化)
- 维护: 活跃、成熟
- 导出: 无内置(需自定义)
- 适用人群: QA 工程师、开发者
- 亮点: 多语言支持,模拟真实用户操作
— 73.5k stars,2025 年

- 简介: 现代浏览器自动化,适合爬虫与端到端测试
- 安装: 中等难度(多语言脚本)
- 场景: 现代 Web 应用、社交媒体、自动化
- JS 支持: 支持(无头或真实浏览器)
- 维护: 非常活跃
- 导出: 无内置(需自定义)
- 适用人群: 需强大浏览器控制的开发者
- 亮点: 跨浏览器、自动等待、网络拦截
— 90.9k stars,2025 年

- 简介: Chrome/Firefox 自动化高级 API
- 安装: 中等难度(Node 脚本)
- 场景: 无头 Chrome 爬取、动态内容
- JS 支持: 支持(Chrome/Firefox)
- 维护: 活跃(Chrome 团队)
- 导出: 无内置(需自定义)
- 适用人群: Node.js、前端开发者
- 亮点: 丰富浏览器控制、截图、PDF、网络拦截
— 5.4k stars,2025 年 6 月

- 简介: 隐身高性能爬虫,集成反爬机制
- 安装: 中等难度(Python 编码)
- 场景: 隐身采集、反爬、动态网站
- JS 支持: 支持(集成 Playwright)
- 维护: 活跃,前沿
- 导出: 无内置(需自定义)
- 适用人群: Python 开发者、黑客、数据工程师
- 亮点: 隐身、代理、反封锁、异步
安全测试与资产探测
— 13.8k stars,2025 年

- 简介: 面向安全、自动化和链接发现的高速爬虫
- 安装: 中等难度(CLI 工具或 Go 库)
- 场景: 安全爬取、端点发现
- JS 支持: 支持(可选无头模式)
- 维护: 活跃(ProjectDiscovery)
- 导出: 文本输出(URL 列表)
- 适用人群: 安全研究员、Go 开发者
- 亮点: 高速、并发、JS 解析
通用/多用途爬虫
— 24.3k stars,2025 年

- 简介: Go 语言高效优雅的爬虫框架
- 安装: 中等难度(Go 编码)
- 场景: 高性能通用爬取
- JS 支持: 不支持(仅 HTML)
- 维护: 活跃,近期有提交
- 导出: 无内置(需自定义)
- 适用人群: Go 开发者、追求性能
- 亮点: 异步、速率限制、分布式爬取
— 11.6k stars,2023 年

- 简介: 类 Scrapy 的灵活 Java 爬虫框架
- 安装: 中等难度(Java,API 简单)
- 场景: Java 领域通用爬取
- JS 支持: 不支持(可扩展 Selenium)
- 维护: 社区活跃
- 导出: 可插拔管道
- 适用人群: Java 开发者
- 亮点: 线程池、调度器、反封锁
— 6.2k stars,2025 年

- 简介: Ruby 原生高效 HTML/XML 解析器
- 安装: 即装即用(Ruby gem)
- 场景: Ruby 应用中的 HTML/XML 解析
- JS 支持: 不支持(仅解析)
- 维护: 活跃,紧跟 Ruby 生态
- 导出: 无内置(用 Ruby 格式化)
- 适用人群: Ruby 开发者、Rails 工程师
- 亮点: 高速、合规、默认安全
一览表:功能对比速查
下表为主流项目及 Thunderbit 的对比:
| 项目 | 安装难度 | 应用场景 | JS 支持 | 维护情况 | 数据导出 | 适用人群 | Github Star |
|---|---|---|---|---|---|---|---|
| Scrapy | 中等 | 电商、新闻 | 否 | 活跃 | CSV、JSON、XML | 开发者、数据工程师 | 57.1k |
| Crawlee | 中等 | 多场景、自动化 | 是 | 非常活跃 | 灵活数据集 | JS/TS 团队 | 17.9k |
| MechanicalSoup | 即装即用 | 静态、表单 | 否 | 稳定 | 无(手动) | Python 新手 | 4.8k |
| Node Crawler | 中等 | 新闻、静态 | 否 | 中等 | 无(手动) | Node.js 开发者 | 6.8k |
| Selenium | 中等 | JS 重度、测试 | 是 | 活跃 | 无(手动) | QA、开发者 | ~30k |
| Heritrix | 进阶 | 归档、科研 | 否 | 维护 | WARC | 档案、机构 | 3k |
| Apache Nutch | 进阶 | 大数据、搜索 | 否 | 活跃 | 原始内容 | 企业、科研 | 3k |
| WebMagic | 中等 | Java、通用 | 否 | 社区活跃 | 可插拔管道 | Java 开发者 | 11.6k |
| Nokogiri | 即装即用 | Ruby 解析 | 否 | 活跃 | 无(手动) | Ruby 开发者 | 6.2k |
| Playwright | 中等 | 动态、自动化 | 是 | 非常活跃 | 无(手动) | 开发者、QA | 73.5k |
| Katana | 中等 | 安全、发现 | 是 | 活跃 | 文本输出 | 安全、Go 开发者 | 13.8k |
| Colly | 中等 | 高性能、通用 | 否 | 活跃 | 无(手动) | Go 开发者 | 24.3k |
| Puppeteer | 中等 | 动态、自动化 | 是 | 活跃 | 无(手动) | Node.js 开发者 | 90.9k |
| Maxun | 易用(终端用户) | 无代码、业务 | 是 | 活跃 | CSV、Excel、Sheets、API | 非技术、分析师 | 13k |
| Scrapling | 中等 | 隐身、反爬 | 是 | 活跃 | 无(手动) | Python 开发者、黑客 | 5.4k |
| Thunderbit | 即装即用 | 无代码、业务 | 是 | 托管、持续更新 | Sheets、Airtable、Notion | 非技术、业务用户 | N/A |
为什么 Thunderbit 是非技术和业务用户的首选?
说实话,大多数开源 GitHub 项目都是为开发者设计的,意味着你得自己搞定安装、维护和各种疑难杂症。如果你是业务人员、市场、销售,或者只想要结果不想折腾正则表达式,Thunderbit 就是为你量身定制的。
Thunderbit 的优势:
- 无代码,AI 智能极简体验: 安装 ,点击“AI 智能识别字段”,就能采集数据,无需 Python、选择器或“pip install”烦恼。
- 动态网页支持: Thunderbit 的 AI 能自动识别并提取现代 JS 重度网站(比如 React、Vue、AJAX)数据,无需手动配置。
- 子页面采集: 需要采集每个商品或房源详情?Thunderbit 的 AI 能自动点击子页面并合并数据,无需写一行代码。
- 业务级导出: 一键导出到 Google Sheets、Airtable、Notion、CSV 或 JSON,适合销售线索、价格监控、内容聚合等场景。
- 持续更新与支持: Thunderbit 是托管服务,无“弃坑”风险,配有新手引导、教程和丰富模板库。
- 适用人群: 非技术用户、业务团队,以及追求高效与稳定的所有人。
Thunderbit 已经获得全球 3 万+ 用户信赖,包括 Accenture、Grammarly、Puma 等知名团队。我们还曾荣获 Product Hunt 周榜第一。
想体验数据采集的极致简单?。
总结:2025 年如何选择合适的网页爬虫方案?
一句话总结:GitHub 上有很多强大的网页爬虫工具,但大多是为开发者设计的。如果你喜欢编程,Scrapy、Crawlee、Playwright、Colly 等框架能让你自由发挥。如果你专注学术或安全,Heritrix、Nutch、Katana 也是不错的选择。
但如果你是业务用户、分析师,或者只想快速拿到结构化、可用的数据,Thunderbit 无疑是最佳选择。无需安装、无需维护、无需写代码,直接拿到结果。
下一步怎么选?可以试试一个适合你技能和需求的 GitHub 项目,或者直接安装 Thunderbit,几分钟内见到成效。
想深入了解网页爬虫?欢迎访问 ,阅读更多实用指南,比如 或 。
祝你采集顺利,数据始终结构清晰、干净可用。如果遇到难题,记住:GitHub 上总有现成项目,或者直接让 Thunderbit 的 AI 替你搞定一切。