
Trustpilot 目前在 127 万家企业中积累了 ——但专门用来抓这些数据的大多数爬虫,几个月前就已经失效了。如果你最近试着提取评论,大概率已经撞上了臭名昭著的第 10 页登录墙,只能眼睁睁看着工具不断报错。
过去几周,我一直在测试、研究并对比那些到了 2026 年仍能稳定提取 Trustpilot 评论数据的工具。这个领域变化很大:Trustpilot 的反爬措施更激进了,Next.js 前端每次部署都会生成变化的类名,而最关键的是——未登录访问现在只能看到前 10 页评论。2025 年底的一条 把大家的挫败感说得很到位:"商店里没有一个可用的 actor。"
那么,到底哪些工具真的能用?我从它们如何应对登录墙、反爬机制、维护成本,以及营销人员和开发者的实际需求这几个维度,评估了 5 款工具。
为什么 2026 年抓取 Trustpilot 评论比想象中更难
Trustpilot 不是那种能直接用简单 HTTP 请求抓下来、再靠 BeautifulSoup 解析的静态网站。它是一个基于 Next.js 构建的现代动态平台,而且过去一年的防护明显更严格了。
你真正要面对的是:

第 10 页登录墙。 这是最大痛点。 也确认了这一点:Trustpilot 只允许查看前 10 页评论,之后就会弹出登录提示。对于一家有 2000 条评论的企业来说(按每页 20 条算,大约 100 页),如果没有已认证会话,你就会错过 90% 的数据。
反爬保护。 Trustpilot 使用 reCAPTCHA、基于会话的拦截、CDN 层请求过滤以及浏览器指纹识别。它的 明确写着网站“受 reCAPTCHA 保护”,并会收集设备和交互信号。
动态 CSS 类名。 由于 Trustpilot 使用 Next.js 和 CSS modules,像 styles_reviewCardInner__EwDq2 这样的类名会在构建时生成,并且每次 Trustpilot 部署更新都会变化。 正是依赖这些精确选择器——也就是说,只要 Trustpilot 下次改前端,按照这篇教程写的代码就会失效。
DOM 结构变化。 除了类名,实际的 HTML 层级也可能改变。元素会换嵌套方式,新的包裹层会出现,分页组件也会被重构。
基于 CSS 选择器的爬虫——不管是 Apify Actors、Octoparse 工作流,还是自定义 Python 脚本——在 Trustpilot 上都非常脆弱。它们能跑,直到不能跑。至于“直到不能跑”这件事,往往不是按月算,而是按周算。
我们在挑选最佳 Trustpilot 评论爬虫时看什么
我并没有用泛泛的“能不能抓网页”标准来评估这些工具。这里每个工具都能从一个简单 HTML 页面里提取数据。
真正的问题是:它能不能在 2026 年面对 Trustpilot 的各种特殊情况时仍然扛得住?
以下这些因素最重要:
| 标准 | 它对 Trustpilot 的重要性 |
|---|---|
| 登录墙处理(第 10 页及以后) | 大多数企业的评论数都远超 200 条。10 页上限意味着你会错过绝大部分历史数据。 |
| 反爬绕过方式 | reCAPTCHA、会话拦截和 CDN 过滤会直接卡死天真的爬虫。 |
| 选择器抗变更能力 / 维护成本 | 生成式 CSS 类名会频繁让依赖选择器的工具失效。工具会自愈吗? |
| 分页支持 | 评论可能跨越数百页。手动一页页提取根本不现实。 |
| 无代码 vs 代码要求 | 营销人员需要点点点,开发者则希望完全可控。 |
| 价格 / 免费层 | 预算敏感的团队需要在承诺前先看清成本。 |
| 导出选项 | 商业用户需要的是 Google Sheets、Airtable、Notion,而不仅是原始 JSON。 |

登录墙就是分水岭。
如果一款工具连第 10 页都过不去——或者至少不能为已认证访问提供明确方案——那它在 2026 年就不能算是可用的 Trustpilot 爬虫。
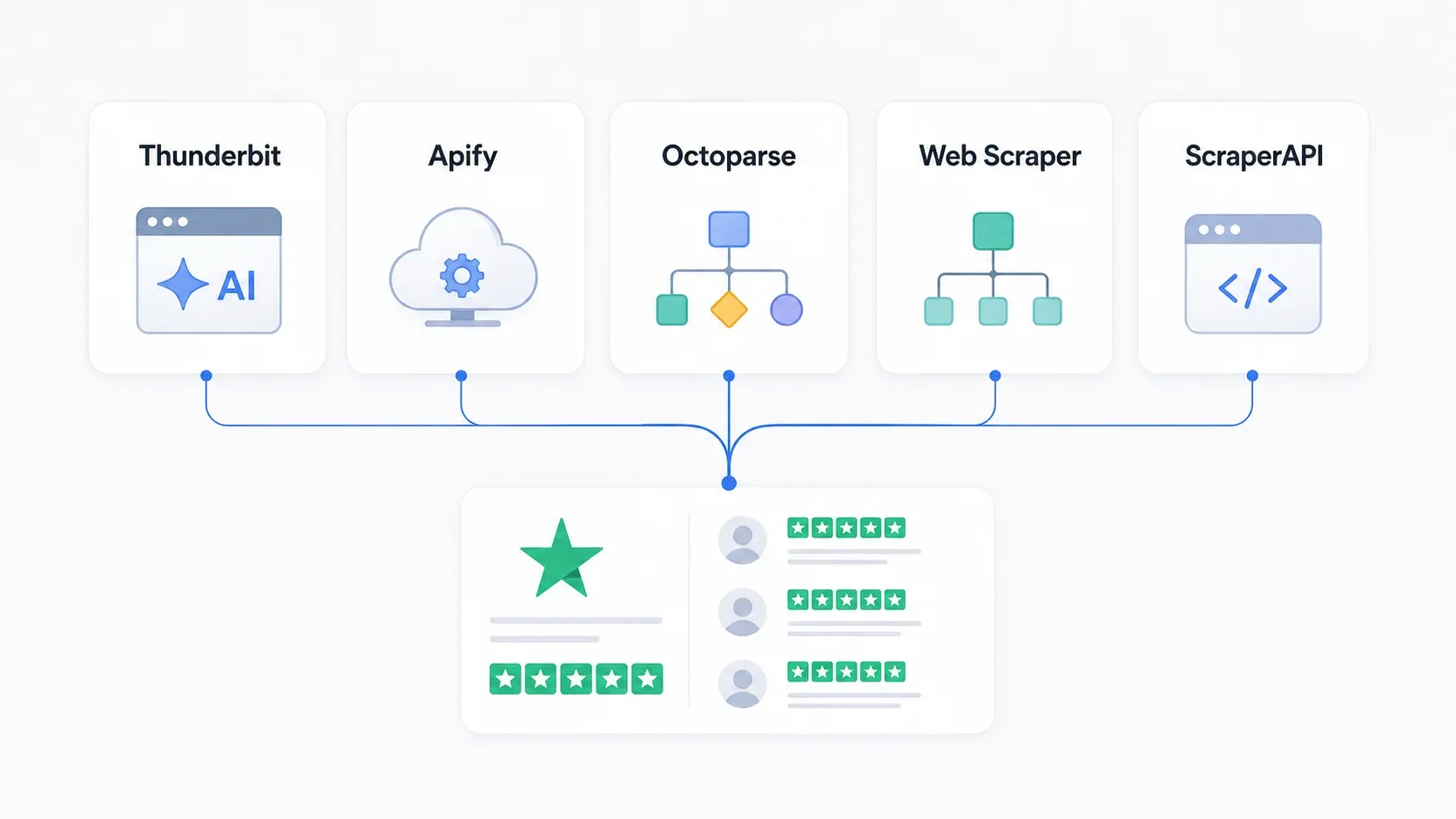
最佳 Trustpilot 评论爬虫一览
完整对比如下:
| 工具 | 技能要求 | 登录墙处理 | 反爬方式 | 分页 | 免费层 | 导出选项 |
|---|---|---|---|---|---|---|
| Thunderbit | 无代码 | 浏览器模式(使用你已登录的 Chrome 会话) | AI 语义提取可适应布局变化 | 自动识别,多页 | 每月免费 6 页 | Excel、Sheets、Airtable、Notion、CSV、JSON |
| Apify | 低代码 | 取决于 Actor;部分需要为第 10 页以上配置 cookie | 内置代理轮换,按 Actor 配置 | 可按 Actor 配置 | 每月 $5 平台免费额度 | JSON、CSV、Excel、XML、RSS |
| Octoparse | 无代码(可视化) | 需要手动配置 cookie / 会话 | IP 轮换、住宅代理、CAPTCHA 处理(付费) | 点击 / 滚动工作流 | 免费计划 + 14 天高级试用 | CSV、Excel、JSON、HTML、XML、数据库 |
| Web Scraper | 无代码(站点地图) | 有限——其自己的指南写明只支持前 10 页评论 | 付费方案提供云端 + 代理 | 可配置;建议用 JS 点击 | 免费 Chrome 扩展 | CSV、XLSX |
| ScraperAPI | 开发者(Python) | 代码级会话 / cookie 管理 | 4000 万+ 住宅代理、JS 渲染、CAPTCHA 处理 | 基于代码 | 7 天试用,5000 API credits | 由开发者自定义(CSV、JSON 等) |
1. Thunderbit
是一款 AI 驱动的 Chrome 扩展,面向需要从网站获取结构化数据、但又不想写代码的商业团队。针对 Trustpilot,它提供了一个 ,只需两次点击,就能提取评论者姓名、评分、评论标题、评论正文、日期以及企业回复。
我有点偏心——因为我就在这里工作——但我们之所以把 Thunderbit 做成这样,和 Trustpilot 抓取为什么这么难直接相关。我们的 AI 不是依赖 CSS 选择器,而是按语义理解页面。即使 Trustpilot 改了类名或重构了 DOM,Thunderbit 也能适应,因为它关注的是页面元素的含义,而不是具体的 HTML 地址。
Thunderbit 如何应对第 10 页登录墙
这就是浏览器模式发挥作用的地方。Thunderbit 运行在你的 Chrome 浏览器里——也就是你已经登录 Trustpilot 的那个浏览器。当你切换到浏览器抓取模式时,扩展会读取你已认证会话中可见的页面。无需代理操作。无需注入 cookie。也无需 Playwright 会话池。
实际流程很简单:先在 Chrome 里登录 Trustpilot,打开你想抓取的评论页,点击“AI 建议字段”,再点“抓取”。之后分页会自动进行——Thunderbit 会按你的浏览器会话能访问到的页面继续工作。
为什么 Trustpilot 一改版 Thunderbit 也不会轻易失效
我们的 对此做了很直接的对比:传统爬虫在布局变化、CSS 选择器需要更新时就会失效。Thunderbit 使用的是能理解内容的语义 AI,不依赖特定 CSS,能处理动态内容,也会自动分页。
对比一下 ScraperAPI 教程里的代码,它是通过像 styles_reviewCardInner__EwDq2 这样的类名来解析内容的。Trustpilot 下一次部署,这个选择器就会失效。Thunderbit 的 AI 不是在问“这个页面上评论正文在哪个 div class 里”,而是在问“这个页面上的评论正文在哪里”。
Trustpilot 抓取的核心功能
- AI 建议字段:自动识别评论字段(姓名、评分、日期、标题、正文、企业回复),无需手动配置
- 两步流程:AI 建议字段 → 抓取,就这么简单
- 登录页浏览器模式:可在你已认证的 Chrome 会话中工作,访问第 10 页及以后内容
- 自动分页:无需手动干预即可处理多页评论
- 子页面抓取:可访问单个评论者资料页,补充丰富数据
- 定时抓取:可按周或按月设置评论监控,用于口碑跟踪
- 导出:Google Sheets、Airtable、Notion、CSV、JSON,全部免费包含
价格
- 免费计划:每月 6 页,无需信用卡
- 按积分计费:1 积分 = 1 行输出
- 付费计划:从 上约每月 $9 起
适合谁:营销团队、运营团队,以及需要 Trustpilot 评论、又不想碰代码的商业用户——也适合不想维护一个每隔几周就会坏掉的爬虫的人。
2. Apify
是一个基于云的抓取平台,带有一个预构建“Actors”市场——也就是其他用户和 Apify 团队创建的抓取模板。针对 Trustpilot,商店里有多个社区维护的 Actors,但可靠性各不相同。
Apify 的取舍很明显:它很强大,但也很碎片化。有些 Actor 能用,有些已经弃用,有些需要为第 10 页以上配置 cookie。Reddit 上关于“商店里没有一个 actor 可用”的吐槽也是真实存在的——这反映出 Trustpilot 的变化有多快,会把某个 Actor 的专用逻辑迅速打坏。
Trustpilot Actors 及其已知限制
里有多个 Trustpilot Actor。其中至少有一个(开发者为“burbn”)明确说明,10 页之后需要输入 cookie。其他一些则显示 0.0 评分、用户量很低,或者最近才改过,说明维护仍在进行,但可靠性差异很大。
那些已经弃用的 Actor 也值得一提。一个旧版 Actor 直接读取 Trustpilot 内嵌的 __NEXT_DATA__ JSON——这是一种很巧妙的方式,比 DOM 解析更快,但当 Trustpilot 改变数据结构后,它同样会失效。
登录墙与反爬处理
- 登录墙:完全取决于你选的 Actor。有些支持为第 10 页以上注入 cookie;有些不支持。
- 反爬:Apify 平台包含代理轮换和按计算单元计费的基础设施。住宅代理在 。
- 维护:当 Actor 失效时,你只能等维护者修复,或者换另一个 Actor,或者定制一个私有 Actor。
价格
- 免费计划:每月预付 $5 用量,无需信用卡
- Starter:每月 $9 + 按量付费
- Scale:每月 $99 + 按量付费
- 导出:JSON、CSV、Excel、XML、RSS(取决于 Actor)
适合谁:技术能力较强、能评估多个 Actor、会配置 cookie、也能在出问题时排查的人。不太适合想要“设置好就不用管”的团队。
3. Octoparse
是一款桌面端无代码爬虫,使用可视化点选式工作流构建器。它介于 Thunderbit 的“两步即可”与 ScraperAPI 的完整开发者控制之间——你可以不用代码进行可视化配置,但仍然需要自己搭建并维护工作流。
在 Octoparse 中设置 Trustpilot 抓取
工作流程很直接,但要手动配置:
- 粘贴 Trustpilot 企业评论页 URL
- 以可视化方式选择评论元素(标题、正文、评分、日期、评论者姓名)
- 用下一页按钮定义分页循环
- 配置等待时间(建议 2-5 秒,以避免 reCAPTCHA)
- 小规模样本可本地运行,大任务可在云端运行
如果你熟悉这款工具,整个设置大约需要 10-15 分钟。问题在于:由于 Octoparse 使用的是绑定到 DOM 元素的可视化选择器,当 Trustpilot 改变页面结构时,你就需要更新工作流。
登录墙与反爬处理
- 登录墙:需要手动登录 / cookie / 会话配置,不会自动处理。
- 反爬: 包含 IP 轮换、住宅代理($3/GB)以及自动 CAPTCHA 解决(每千次 $1-1.5)。
- 维护:中等。Trustpilot 前端更新后,通常都得重建或调整工作流。
价格
- 免费计划:永久免费,10 个任务,1 台设备,本地提取,每月最多 50,000 行
- Standard:每月 $69(按年计费)
- Professional:每月 $149
- 14 天高级试用:包含云端提取、定时、API 和模板
- 导出:Excel、CSV、JSON、HTML、XML;更高等级支持数据库和 Google Sheets
适合谁:想要可视化流程控制、不介意前期设置时间,并且能接受页面变化时维护工作流的用户。适合需要比两步工具更多定制、但又不想写 Python 的团队。
4. Web Scraper
是一款 Chrome 扩展和云平台,采用基于站点地图的抓取方式。它在 Trustpilot 上最强的方案是一个 ,可提取公司级数据:公司名、类别、地址、评分、评论数、TrustScore 和网站 URL。
如果是评论抓取,Web Scraper 有一个值得注意的已知限制。
预置模板 vs 自定义设置
这个市场模板很适合企业发现——也就是抓取 Trustpilot 各类别中的公司资料。若要自定义评论提取,Sitemap Wizard 可以让你在 Chrome 扩展里通过可视化方式搭建爬虫。
建议使用 JavaScript 点击分页,而不是基于 URL 的分页,因为 Trustpilot 会在不同页面之间动态重排内容,导致结果错位。
登录墙与反爬处理
这里必须说实话:Web Scraper 官方指南明确指出,Trustpilot 只允许查看前 10 页评论,随后就会显示登录提示。该指南把这视为一个已知限制,而不是给出绕过方案。
- 登录墙:处理能力有限。10 页评论上限已在其官方指南中说明。
- 反爬:云端方案支持代理;指南建议使用 2-5 秒延迟并降低并发。
- 分页:可以配置,但对未认证访问而言,实际上只能到前 10 页评论。
价格
- 免费 Chrome 扩展:本地抓取,功能有限
- Project:每月 $50(5000 URL credits)
- Professional:每月 $100(20,000 URL credits)
- Scale:每月起价 $200(在特定条件下提供无限 URL credits)
- 付费云端方案有 7 天免费试用
- 导出:CSV、XLSX
适合谁:想要一个现成模板来抓取 Trustpilot 公司资料,或者只需要前 10 页评论的人。如果你需要高评论量企业的完整评论历史,这不是合适选择。
5. ScraperAPI
是面向开发者的抓取基础设施——它不是点点点工具,而是一个代理 / 渲染层,负责处理反爬措施,而你编写解析逻辑。它的 宣传了 JS 渲染、CAPTCHA 处理以及 4000 万+ 代理。
如果你是想完全掌控提取逻辑的 Python 开发者,ScraperAPI 会给你需要的底层能力。
但维护也归你。
用 ScraperAPI 自定义 Trustpilot 爬虫
展示了一个 Python + BeautifulSoup 流程:
1import requests
2from bs4 import BeautifulSoup
3payload = {
4 "api_key": "YOUR_API_KEY",
5 "url": "https://www.trustpilot.com/review/example.com",
6 "render": "true",
7 "keep_headers": "true",
8}
9html = requests.get("https://api.scraperapi.com", params=payload).text
10soup = BeautifulSoup(html, "html.parser")该教程的完整代码把 pages_to_scrape 设成了 10——这实际上默认承认了公开页面限制。到了第 10 页以上,开发者就得自己处理已认证会话、cookie 和 token。
登录墙与反爬处理
- 登录墙:需要代码级的会话 / cookie 管理。ScraperAPI 负责代理和渲染,你负责认证逻辑。
- 反爬:使用住宅代理池和自动 IP 轮换,通过
render=true进行 JS 渲染,并借助智能代理轮换处理 CAPTCHA。所有 都可使用。 - 维护:Trustpilot 一旦改类名(而且它确实会定期改),你就必须更新解析代码。教程里的
styles_reviewCardInner__EwDq2选择器本身就是个定时炸弹。
价格
- 7 天试用:,无需信用卡
- Hobby:每月 $49(100,000 API credits)
- Startup:每月 $149(1,000,000 credits)
- Business:每月 $299(3,000,000 credits)
- 导出:取决于你的代码输出什么(通常是 CSV、JSON、数据库写入)
适合谁:想要完全自定义、能维护自己的解析脚本,并且需要对会话管理、分页逻辑和数据结构进行可编程控制的开发者。不适合非技术用户。
为什么 Trustpilot 爬虫总是失效,以及如何选到一个不容易坏的
这是选择 Trustpilot 爬虫时最容易被忽视的因素。问题不是“这个工具今天能不能用”,而是“它三周后还会不会能用”。
Trustpilot 上的爬虫通常会因为 4 个反复出现的原因失效:
-
生成式 CSS 类名变化。 Next.js 的 CSS modules 会生成像
styles_reviewCardInner__EwDq2这样的类名。每次前端部署,这些类名都会变。任何针对这些类名的爬虫都会失效。 -
DOM 结构变化。 Trustpilot 可以重构 HTML 层级——评论卡片的嵌套方式会变,包裹元素会变,元数据的位置也会变。
-
反爬触发条件变化。 reCAPTCHA 阈值会调整,Session token 轮换会更严格,CDN 过滤规则也会更新。
-
认证 / 会话变化。 第 10 页登录墙是在 2025 年底引入的(或者说被更严格地执行了)。未来随时可能出现新的访问限制。
从架构上看,根本区别在于 基于选择器的提取 和 语义提取:
-
基于选择器的工具(Apify Actors、Octoparse 工作流、ScraperAPI 脚本、Web Scraper 站点地图)会问:“找到这个精确 CSS 路径上的元素。” 一旦路径变了,它们就会静默失败,或者返回空数据。
-
语义 / AI 工具(Thunderbit)会问:“找出这个页面上的评论正文、评分和日期。” AI 是按含义理解页面内容,而不是按地址查找。布局变化不会把它搞坏,因为含义并没有变。
我的建议是:
- 完全不能接受维护? → 基于 AI 的(Thunderbit)
- 可以接受少量维护,想要云端自动化? → Apify(配合 Actor 选择和监控)
- 想要可视化控制,能接受中等维护? → Octoparse
- 基于模板、范围有限? → Web Scraper
- 想要完全掌控,所有东西都自己管? → ScraperAPI
抓到 Trustpilot 评论后能做什么
提取评论只是第一步。我经常在论坛里看到一个问题:“我已经有数据了——接下来呢?”

情感分析
最简单的流程是:把评论导出到 Google Sheets,然后用 AI 工具(ChatGPT、Claude,或 Sheets 里的 AI 函数)把每条评论标记为正面、中性或负面。再加上投诉类别、紧急程度和建议处理优先级等列。
如果数据量更大,可以把 CSV 上传到 ChatGPT,然后让它总结:“请按情感分类这些评论,并找出前 5 个主要投诉主题,同时给出代表性原话。”
竞品监控
使用 Thunderbit 的定时抓取,每周或每月拉取竞品评论。跟踪:
- 平均评分随时间的变化趋势
- 1 星和 2 星评论占比
- 评论量变化(是在变多还是变少)
- 最常见的投诉主题
- 企业回复率和回复速度
一个简单的 Google Sheets 仪表板,按评分和日期做透视表,就能给你一个自动更新的竞争情报源。
主题提取
把评论按常见类别分组:发货 / 配送、客服、退款、产品质量、账单、应用可用性、价格 / 性价比,以及欺诈相关问题。输出结果应是一张表,包含:主题、数量、平均评分、代表性原话和建议的业务动作。
这比词云更有用。它能告诉你,到底是什么在推动满意或不满意。
批量多企业分析
如果你做的是类别级研究,可以抓取同一 Trustpilot 类别下多个企业的评论。比较整个市场细分的评论量、评分、星级分布和主题占比。Web Scraper 的企业列表模板适合用来发现公司;而 Thunderbit 或 ScraperAPI 可以负责每家公司评论层面的采样。
抓取 Trustpilot 的法律与伦理考量
我不是律师,这也不是法律意见。但合规现实在这里很重要。
Trustpilot 的使用条款写得很明确。它们 用户以 Trustpilot 未提供或未明确批准的任何方式访问或收集内容,并且明确点名禁止在未获明确许可的情况下进行文本挖掘、数据挖掘和网页抓取。
风险区间大致如下:
- 较低风险:导出自己公司的评论用于内部分析,尤其是使用 Trustpilot 官方的商业工具或 API。
- 中等风险:以低频率抓取公开的竞品页面用于市场研究。仍然受使用条款和隐私义务约束。
- 较高风险:抓取需要认证的第 10 页以上内容、绕过技术控制、重新分发评论者数据,或把抓取到的评论用于 AI 模型训练。
GDPR 考量:评论者姓名、个人资料链接、评论文本和地理位置数据,在欧盟隐私法下都可能构成个人数据。实际可行的保护措施包括:只收集必要字段、对评论者姓名做哈希用于内部分析、设置数据保留期限,以及不要大规模重新发布原始评论文本。
公开数据 vs 已认证数据:抓取任何人都能看到的页面(前 10 页评论)与抓取认证墙后面的数据,在法律和伦理上是有实质区别的。通过公开数据运行的工具,合规风险通常低于那些需要登录凭证的工具。
这也应该成为你选工具时的重要因素。Thunderbit 的浏览器模式只会处理你自己会话里可见的页面——它不会独立绕过认证。ScraperAPI 给开发者的是完整控制力,但也意味着你必须对会话管理的合法性承担全部责任。
如何选择合适的 Trustpilot 评论爬虫
按角色给出一个决策框架:
- 不懂技术、又想要评论数据、不要写代码的营销人员? → Thunderbit。两次点击,剩下的交给 AI,导出到 Sheets / Notion / Airtable。
- 能接受配置和调试的低代码用户? → Apify。选一个 Actor,给第 10 页以上配好 cookie,并持续监控是否失效。
- 想要工作流控制的可视化构建者? → Octoparse。点选式搭建,但要接受 Trustpilot 变化后需要维护。
- 只需要公司级数据或前 10 页评论? → Web Scraper。企业资料模板很强。
- 想要完全自定义的开发者? → ScraperAPI。自己负责解析逻辑、会话管理和数据管道。
如果你最在意的是维护成本,这条谱系从 Thunderbit(几乎零维护)一直到 ScraperAPI(所有东西都得你维护)。从预算来看,这份清单里的每个工具都有免费入口——先从那里开始,再决定是否付费。
结论
Trustpilot 评论数据对竞争情报、口碑监控和客户洞察都非常有价值。
但到了 2026 年,想稳定提取这些数据,你需要一款既能处理第 10 页登录墙、又能适应 DOM 变化、还无需你不断手动介入去应对反爬防护的工具。
对于大多数商业用户来说, 是阻力最小的路径——两次点击、AI 驱动字段识别、支持已认证页面的浏览器模式,并且在 Trustpilot 改前端时几乎不用维护。你可以用每月 6 页、无需信用卡的方式 。
如果你是想完全掌控的开发者,ScraperAPI 提供了所需基础设施。而对于介于两者之间的人,Apify、Octoparse 和 Web Scraper 都有各自适合的场景。关键是把工具和你的技术水平、维护承受度,以及合规要求匹配起来。
如果你想看看 Thunderbit 具体是怎么处理 Trustpilot 的,我们在 上有一个演示。至于更广泛的 或 ,这些指南也会讲清楚基础内容。
常见问题
1. 能抓取第 10 页之后的 Trustpilot 评论吗?
可以,但前提是走已认证路径。Trustpilot 会在前 10 页评论后阻止未登录访问。Thunderbit 的浏览器模式可在你已登录的 Chrome 会话中工作,因此能访问你可见的页面。ScraperAPI 需要代码级的会话 / cookie 管理。Apify Actors 需要配置 cookie。Octoparse 需要手动登录 / cookie 设置。Web Scraper 的官方文档也承认 10 页限制,但没有提供内置绕过方案。
2. 抓取 Trustpilot 评论合法吗?
Trustpilot 的使用条款禁止在未经明确许可的情况下进行自动化数据收集。法律风险会因方法和用途而异:抓取自己公开的评论,风险低于绕过认证墙去抓竞品。面向欧盟评论者数据时,GDPR 适用。这不是法律建议——如果是大规模或商业化抓取项目,请咨询律师。
3. 你可以从 Trustpilot 提取哪些数据?
常见字段包括:评论者姓名、星级评分、评论标题、评论正文、发布日期、体验日期、已验证购买状态、评论者所在地、企业回复文本、公司名称、TrustScore、总评论数、星级分布,以及评论 URL。
4. Trustpilot 爬虫多久会失效一次?
基于选择器的工具(Apify Actors、Octoparse 工作流、自定义 Python 脚本)只要 Trustpilot 改了 CSS 类名或 DOM 结构,就可能失效——这种情况一个月内可能发生多次。像 Thunderbit 这样的 AI 语义工具会自动适应,因为它们理解的是页面含义,而不是死盯特定选择器。不过,没有任何工具能免疫像第 10 页登录墙这样的重大访问控制变化。
5. 我可以免费抓取 Trustpilot 评论吗?
这份列表里的每个工具都有免费入口:Thunderbit 每月提供 6 页免费额度,ScraperAPI 提供 7 天 5000 个试用 credits,Web Scraper 有免费的 Chrome 扩展供本地使用,Octoparse 有永久免费方案(10 个任务、每月 50,000 行),Apify 则提供每月 $5 的平台免费额度。对于小规模采样或测试,这些工具都可以不花钱使用。
了解更多