

Temu 目前已覆盖 50 多个市场,月活跃用户超过 4.16 亿。它的商品目录从厨房小工具到宠物配件,再到 LED 灯带,几乎什么都有。如果你在做电商、无货源代发,或者竞争情报分析,大概率想过把 Temu 数据拉到表格里——然后才发现,Temu 真的、真的不想让你这么做。
我花了很多时间研究和测试面向受保护电商网站的爬虫工具。Temu 是最难搞的目标之一。网上大多数教程,要么直接甩给你一份 Python 教程,结果一周内就失效;要么把你引向价格比你月广告预算还高的企业级 API。
现实是,大多数业务用户——无货源卖家、独立运营者、营销团队——只想要一份干净的表格,里面有商品名称、价格、图片、评分和卖家信息。他们不想在凌晨 2 点调试 Playwright 脚本。
这篇指南就是为了解决这个差距:按技能水平拆解 2026 年真正能用的最佳 Temu 爬虫,以及如何把一次原始抓取,变成持续运转的竞争情报。无论你是完全新手,还是在搭建数据管道的开发者,这里都有适合你的部分。
为什么要抓取 Temu?业务团队的核心使用场景
Temu 数据不只是有意思——它还很有战略价值。
这个平台已经成了低客单价和中客单价品类里的价格风向标。即使你不在 Temu 上卖货,客户也会拿你的价格和它对比。下面看看不同团队会怎么用 Temu 数据:
| 使用场景 | 所需数据 | 重要原因 |
|---|---|---|
| 无货源代发选品研究 | 标题、价格、图片、评分、评论数、销量、变体 | 找到有需求信号的低成本商品,并与 Amazon、Shopify、AliExpress、TikTok Shop 做对比 |
| 竞争性定价 | 当前价格、原价、折扣%、币种、运费、时间戳 | 为定价策略和促销规划建立基准 |
| 选品与供货来源分析 | 规格、图片、变体、卖家/店铺、商品 ID、分类 | 识别值得进一步核验的商品类型和供应商式列表 |
| 市场趋势分析 | 搜索关键词、分类、销量、评论数、评分 | 看出哪些商品正在各个品类中加速增长 |
| 营销与创意研究 | 标题、图片、评论数、评分、描述、分类标签 | 挖掘高销量商品使用的文案、视觉钩子、组合销售和卖点 |
| 库存与可用性监控 | 商品 URL、可用性、预计运送时间、价格、时间戳 | 追踪缺货、本地仓变化和价格波动 |
搜索“最佳 Temu 爬虫”的人通常分成三类。非技术用户想要一个能导出表格的 Chrome 扩展。半技术用户想要带模板和定时功能的可视化工具。开发者则想要 API、Playwright 脚本和代理策略。
这篇文章会覆盖这三类——但我们先从最大的一类开始:需要数据,而不是代码的人。
2026 年最好的 Temu 爬虫,凭什么脱颖而出
能抓 Amazon 或 Shopify 的爬虫,不一定能在 Temu 上活下来。本文的评估标准是:
- Temu 上的稳定性 —— 它真的能返回干净数据,还是会被拦截、返回空行,或者在页面结构一改之后就坏掉?
- 易用性 —— 非技术业务用户能不能不写代码就上手?
- 数据完整性 —— 它支不支持子页面补全(逐个访问商品详情页抓取规格、变体、卖家信息)?
- 维护成本 —— Temu 改页面结构时,它能不能跟着适应?
- 定时与监控 —— 能不能按周期运行,并导出到持续更新的数据目的地?
- 导出目标 —— CSV、Excel、Google Sheets、Airtable、Notion、JSON 是否都支持?
- 成本透明度 —— 一个现实可行的 Temu 抓取流程,每个月到底要花多少钱?
Reddit 的 r/webscraping 社区报告一直把 Temu 描述为最难抓取的电商网站之一。有用户写道,自己“连作为买家都拿不到价格”;也有人指出,Temu 和 Shopee 都在持续加强反爬机制。虽然还没有公开的 Temu 专项失败率基准,但 2025 年 Imperva 恶意机器人报告 显示,自动化流量已经超过人工流量,机器人占据了互联网流量的 51%。Temu 防御的就是这种环境。
Temu 的反爬防线:为什么大多数爬虫都会失败
很多讲 Temu 抓取的文章,只用一句话带过反爬措施:“Temu 有反爬。”这毫无帮助。
如果你在选工具,你需要知道 Temu 用了哪些防御,以及哪些工具能力能逐一破解。下面是实用版地图:
| Temu 防御机制 | 它的作用 | 需要的工具能力 | 示例工具 |
|---|---|---|---|
| Cloudflare WAF / 浏览器校验 | 拦截自动化 user-agent,识别机器人指纹,返回验证页 | 带旋转住宅 IP 和真实浏览器指纹的云基础设施 | Thunderbit(云端抓取)、Bright Data、Oxylabs、ScraperAPI |
| 重度 JavaScript 渲染 | 商品数据通过 JS 加载;原始 HTML 为空 | 无头浏览器或完整浏览器渲染 | Thunderbit(浏览器抓取模式)、Playwright、Selenium、ParseHub、Apify 浏览器 actor |
| 动态 CSS 选择器 | 类名在不同部署间变化,导致基于 CSS 的爬虫失效 | 基于 AI 的字段识别(不依赖固定选择器) | Thunderbit(AI 每次重新读取页面)、Bright Data AI 爬虫构建器 |
| 速率限制 | 限制高频顺序请求 | 带智能限流的并发云请求 | Thunderbit(云端一次最多 50 页)、ScraperAPI、Bright Data |
| CAPTCHA 验证 | 在可疑行为后打断会话 | 内置验证码处理或更低触发策略 | Bright Data、Oxylabs、ScraperAPI 高级/超高级方案 |
| 无限滚动 / 懒加载 | 不交互就只显示前几个商品 | 智能滚动、分页识别、交互自动化 | Thunderbit 分页、Apify 智能滚动、Octoparse 工作流构建器 |
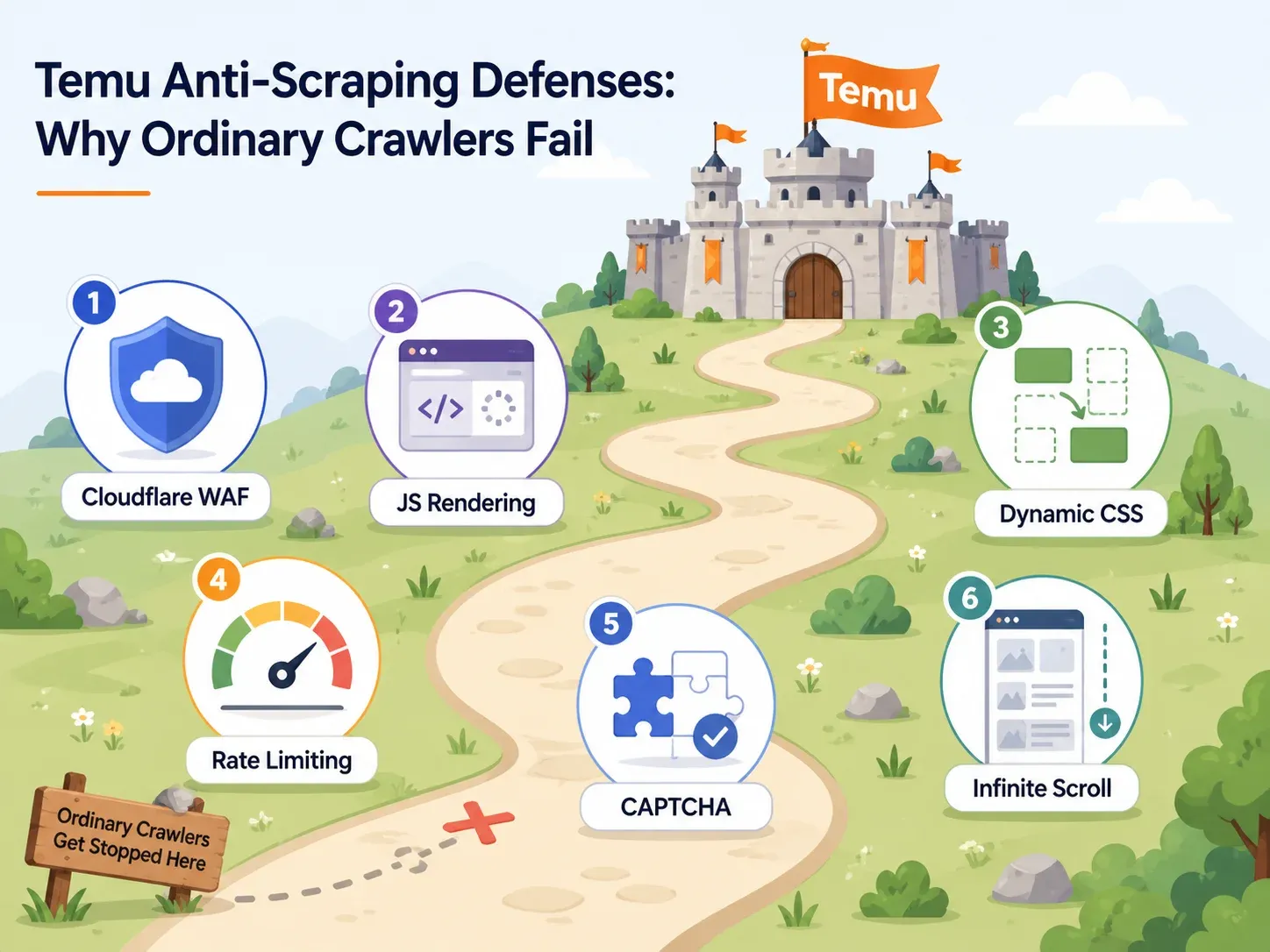
Cloudflare WAF 和 IP 屏蔽
Temu 的入口受 Cloudflare 风格的浏览器完整性检查保护。最基础的 HTTP 请求——也就是简单 Python requests.get() 会发出的那种——通常会被挑战、返回 403,或者只给你不完整的数据。
在这里能工作的工具,需要旋转住宅 IP 或移动 IP,以及真实的浏览器指纹。Cloudflare 2025 年 Radar 回顾显示,2025 年初,非 AI 机器人就已经占据了大约一半的 HTML 页面请求。这就是 Temu 需要防御的自动化规模。
JavaScript 渲染和动态选择器
这里正是大多数新手爬虫悄悄失败的地方。
如果你查看 Temu 的页面源码,往往会发现只是一个空壳——真正的商品卡片、价格和图片,是页面加载后由 JavaScript 注入的。只读取原始 HTML 的爬虫,基本拿不到有用内容。更麻烦的是,Temu 的 CSS 类名和 DOM 结构会在不同部署间变化。依赖固定 CSS 选择器(比如 .product-card__price)的爬虫,今天能跑,明天就可能全空。
基于 AI 的爬虫(比如 Thunderbit)会在每次运行时按语义重新读取页面,因此不依赖某个类名永远不变。
速率限制与 CAPTCHA 验证
如果从同一个 IP 过快或过频繁地访问 Temu,就会触发限流或验证码。有些工具会用智能限流和内置验证码处理来应对。另一些则把问题丢给你——对于非技术用户来说,这基本就是死路一条。
对于云端抓取,关键是让并发请求分散到干净 IP 上,并配好自动重试逻辑。
按技能水平划分的最佳 Temu 爬虫:完整拆解
先找到你的位置,再直接跳到对应部分:
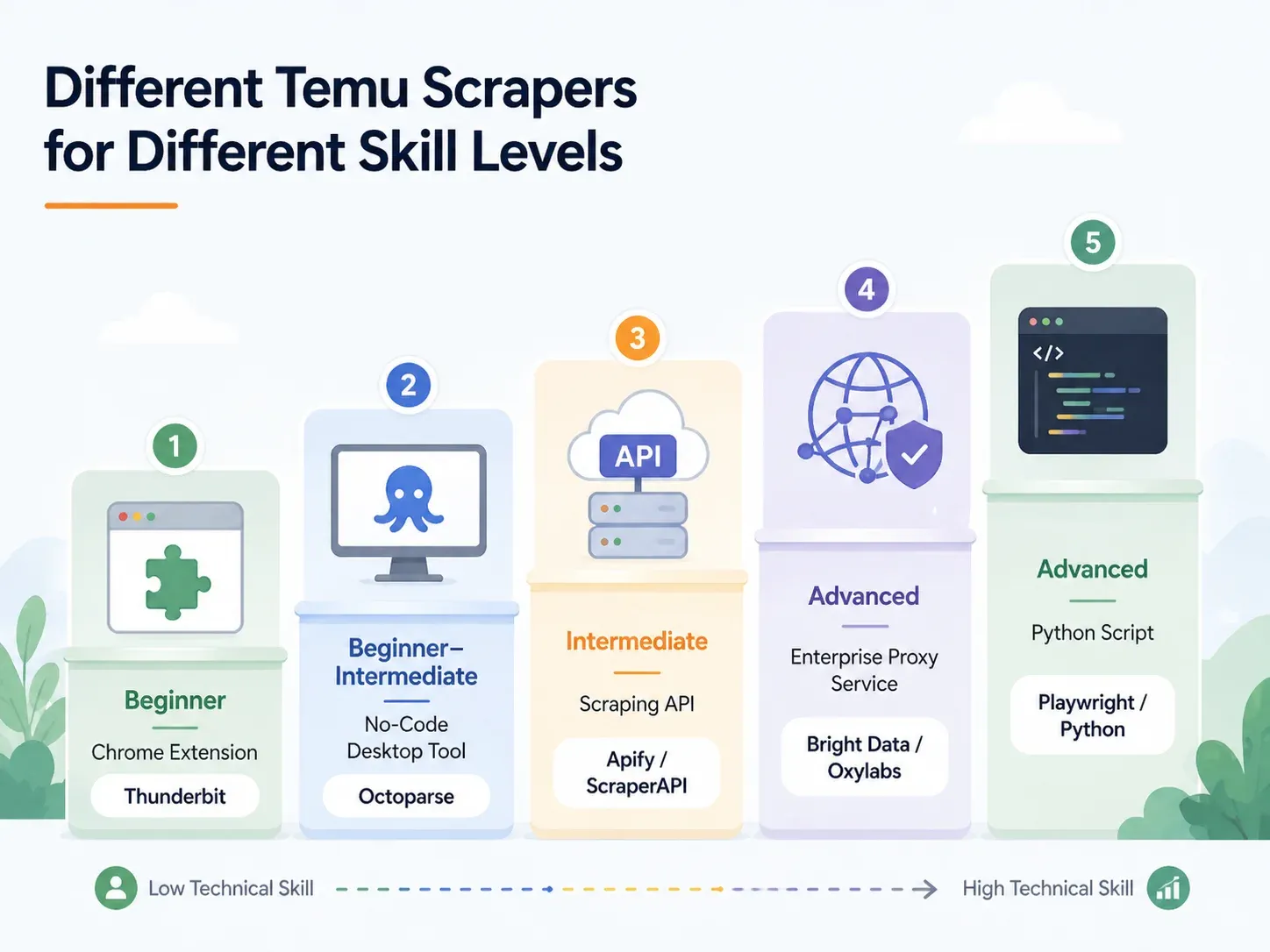
| 方案 | 技能水平 | 搭建时间 | 反爬处理 | 最适合 |
|---|---|---|---|---|
| AI Chrome 扩展(如 Thunderbit) | 新手 | 少于 2 分钟 | 已处理(云端或浏览器) | 无货源卖家、营销人员、电商运营 |
| 无代码桌面工具(如 Octoparse、ParseHub) | 新手–中级 | 10–60 分钟 | 部分支持(需要代理配置) | 使用模板进行周期性抓取 |
| 抓取 API/服务(如 ScraperAPI、Apify) | 中级 | 15–45 分钟 | 内置 | 集成进数据管道的开发者 |
| 托管代理/企业级方案(如 Bright Data、Oxylabs) | 高级/企业级 | 数小时–数天 | 完整基础设施 | 大批量抓取、仓库级交付 |
| 自定义 Python 脚本(Playwright/Selenium) | 高级 | 1–4 小时以上 | 手动配置(代理 + 验证码) | 完全控制、边缘场景定制 |
Thunderbit:非技术用户的最佳 Temu 爬虫
Thunderbit 是一款 AI 驱动的 Chrome 扩展,面向需要从网站获取结构化数据、但不想写代码的业务用户——销售团队、电商运营、无货源卖家、营销人员。我在 Thunderbit 团队工作,所以很了解这个产品。下面我会直接说明它能做什么,以及适合放在哪些场景。
核心流程只要两步:打开 Temu 页面,点击 AI 建议字段,检查系统建议的列(商品名、价格、图片、评分等),然后点击 抓取。
Thunderbit 的 AI 会读取页面结构,并自动提出列名和数据类型。它不依赖固定 CSS 选择器,所以即使 Temu 改了类名或卡片布局,爬虫也能跟着适应。
Temu 场景下的关键功能:
- 云端抓取模式: 适合公开页面,速度更快,一次最多可处理 50 个页面。最适合分类页、搜索结果页和无需登录的商品列表页。
- 浏览器抓取模式: 使用你当前的 Chrome 会话,包括 cookies、地区和登录状态。适合页面展示会受地区、弹窗或登录内容影响的场景。
- 抓取子页面: 抓完列表页后,点击“抓取子页面”,即可逐个访问商品详情页,追加完整描述、变体、卖家信息、预计运送时间和规格等列——无需额外配置。
- 字段 AI 提示词: 在抓取过程中对数据进行分类、翻译或重排。比如:“把这个商品归类为厨房用具、小家电、收纳,或其他。”
- 定时抓取: 用自然语言设置周期(“每周一上午 9 点”),输入 URL,Thunderbit 就会在云端自动运行抓取,并导出到 Google Sheets、Airtable 或其他目的地。
- 免费导出: Excel、CSV、Google Sheets、Airtable、Notion、JSON——导出不设付费墙。图片在 Airtable 和 Notion 中会作为真实附件导出。
价格:免费版最多 6 页(试用加成后可到 10 页);付费方案约从 $15/月(按月)或 $9/月(按年) 起,包含 500 积分,1 积分 = 1 行输出。
用 AI 抓取 Temu 数据 Get Started Free
对比:Thunderbit 与 Python 脚本抓同一 Temu 页面
这个差距非常明显:
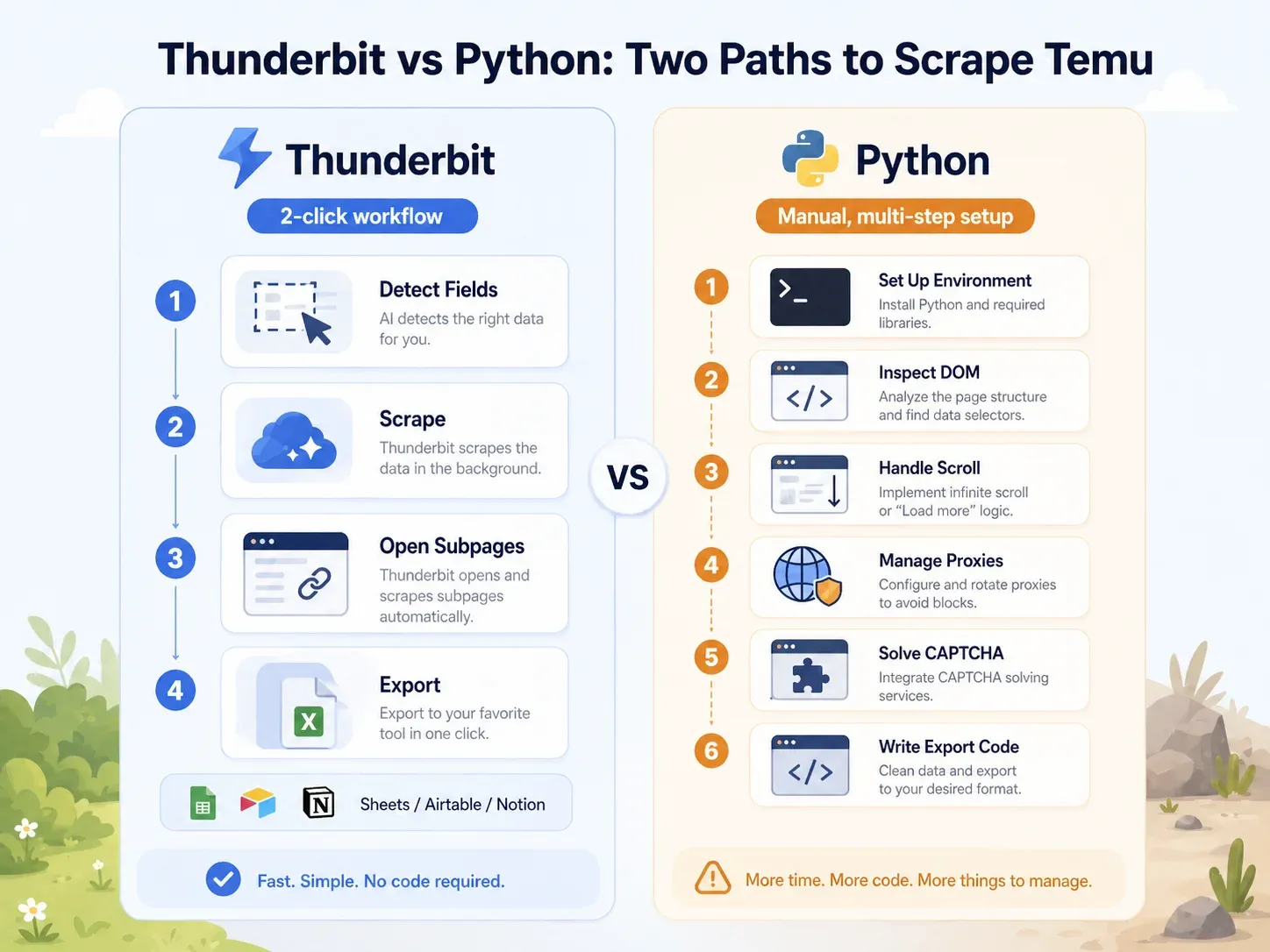
| 任务 | Thunderbit | Python(Playwright) |
|---|---|---|
| 打开 Temu 分类页 | 在 Chrome 中打开页面 | 搭建 Python 环境,安装 Playwright,安装浏览器 |
| 识别字段 | 点击“AI 建议字段” | 检查 DOM、网络请求、JSON 负载 |
| 处理动态加载 | 浏览器/云端模式 + 分页 | 编写滚动/等待逻辑,拦截请求 |
| 处理封锁 | 试云端模式或浏览器模式 | 添加代理、请求头、指纹、重试、验证码 |
| 抓取列表字段 | 点击“抓取” | 编写选择器或 API 解析逻辑 |
| 补全商品页信息 | 点击“抓取子页面” | 单独搭建 PDP 爬虫 |
| 导出 | 点击 Sheets/Airtable/Notion/Excel | 编写 CSV/JSON/Sheets 集成代码 |
| 业务用户的典型搭建时间 | 2 分钟以内 | 至少 1–4 小时;后续还要维护 |
一个最小化的 Playwright Temu 原型大概会长这样(伪代码,不是生产可用版本):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# 生产代码仍然需要选择器、代理、重试、
# 验证码处理、PDP 爬取和导出逻辑。
print(cards.count())
在拿到一个字段之前,这已经有 10 多行代码了,而且你还没碰代理、验证码、PDP 补全或导出。对非技术用户来说,Thunderbit 把这整套流程压缩成了几次点击。对开发者来说,Python 路线能提供更多控制,但维护成本高得多。
Octoparse 和 ParseHub:无代码桌面 Temu 爬虫
如果你想比 Chrome 扩展拥有更多控制,但又不想写代码,Octoparse 和 ParseHub 是主要选择。
Octoparse 有一个公开的 Temu 详情爬虫模板。它的示例输出包含商品 ID、标题、价格、卖家/店铺数据、图片 URL、折扣、店铺 URL 和详细规格。这是个很大的优势——你可以直接从模板开始,而不是从零搭工作流。Octoparse 也支持云端提取、定时任务和可视化工作流构建。
在 Temu 上需要注意的地方:
- 反爬附加项(住宅代理 $3/GB,验证码处理每千次 $1–$1.50)加起来会很贵。
- 当 Temu 改版时,模板可能会失效。你可能需要更新选择器,或者等 Octoparse 维护模板。
- 根据页面复杂度,搭建时间通常在 10–60 分钟。
Octoparse 定价:免费方案包含 10 个任务和每月 5 万条数据导出;Standard 年付约 $75/月;Professional 年付约 $108/月。代理、验证码和托管服务等附加项需要另付费。
ParseHub 是一款可视化桌面/网页爬虫,对动态页面支持不错(它会运行完整的 Chromium 浏览器)。不过付费方案从 $189/月起,对独立运营者来说门槛偏高。我在研究中没有找到强力的公开 Temu 专用模板。ParseHub 更适合已经习惯搭建可视化抓取项目的团队。
| 工具 | Temu 上的优势 | Temu 上的劣势 | 定价 |
|---|---|---|---|
| Octoparse | 公开 Temu 模板、可视化工作流、云端提取、定时任务 | 模板维护成本、反爬附加项增加费用 | 免费;年付 Standard 约 $75/月;年付 Pro 约 $108/月;附加项另算 |
| ParseHub | 动态页面处理、项目工作流构建器、付费方案支持 IP 轮换 | 进入成本更高,未找到公开 Temu 模板 | 付费方案从 $189/月起 |
抓取 API:Temu 场景下的 ScraperAPI、Apify 和 Bright Data
基于 API 的抓取服务会帮开发者处理代理、渲染和反爬逻辑,让你把精力放在解析和存储数据上。它们适合你在搭建数据管道,而不是做一次性的表格导出时使用。
ScraperAPI 是一个面向开发者的 API,提供代理轮换和页面渲染。它的定价页显示有 7 天试用、5,000 积分,Hobby 套餐 $49/月可得 100,000 积分,更高档位依次递增。Temu 上的难点在于:JavaScript 渲染和高级代理池会根据套餐,每次请求消耗 10–75 积分不等。这意味着你真正的每行成本,可能比页面上标价高得多。
Apify 是一个带有预制“actor”(爬虫)的平台。平台市场里已经有多个 Temu actor。一个社区维护的 Temu Scraper 标注的是按事件付费,免费层大约每 1,000 个商品 $5。另一个 Temu Products Scraper 则标价每 1,000 条结果 $4。风险在于:actor 质量不一,维护依赖社区,有些 actor 可能已经弃用,或者在 Temu 更新后失效。付费前一定要查看“最后修改时间”和用户评分。
Bright Data 是企业级方案。它的 Temu 爬虫页面说明,任务会运行在 Bright Data 基础设施上,配备代理轮换、地理定位、验证码/解封逻辑和自动扩缩容。输出格式包括 JSON、CSV、Parquet,并可直接投递到 S3、GCS、Azure Blob、BigQuery 和 Snowflake。行业评测显示,其 Web Scraper API 按量计费约为每 1,000 条记录 $2.5,承诺方案从约 $499/月起。功能很强,但价格是按有预算的团队来定的。
Oxylabs 也有专门的 Temu Scraper API 页面。套餐从 $49/月起,并提供最多 2,000 条结果的免费试用。对于想通过 API 获取结构化 Temu 数据的开发团队来说,它是 Bright Data 的一个强替代方案。
| API/平台 | Temu 相关证据 | 优势 | 劣势 | 最适合 |
|---|---|---|---|---|
| ScraperAPI | 未找到 Temu 专页,但有电商反爬功能文档 | 接口简单,支持 JS 渲染,高级代理 | 高级功能会增加积分消耗;开发者仍需自己解析数据 | 开发者管道 |
| Apify | 市场中有多个 Temu actor | 如果 actor 匹配且维护良好,是最快的开发路径 | actor 质量不一;部分已弃用 | 想用 actor 市场 + 定时任务的开发者 |
| Bright Data | 有专门的 Temu 爬虫页面 | 企业级基础设施、解封、仓库级交付 | 昂贵;仍需要理解网页爬虫概念 | 企业级数据团队 |
| Oxylabs | 有专门的 Temu Scraper API 页面 | 按结果计费清晰,支持 JS 处理,宣称支持 IP/CAPTCHA | 开发者 API 工作流 | 需要 Temu API 访问的开发团队 |
自定义 Python 脚本(Playwright/Selenium):完全控制,工作量也最大
自定义 Python 爬虫的优点是灵活性最大——这就是它的上限。对 Temu 来说,Playwright 通常比 Selenium 更适合作为起点,因为它有自动等待机制,并且对 JavaScript 重度页面处理更好。
但代价也很残酷。
一个原型要花 1–4 小时。生产级爬虫则需要代理轮换、真实浏览器指纹、验证码策略、重试、数据结构校验、结果存储、监控、告警和法律审查。
而且它会坏。Reddit 抓取社区反复提到,现代电商网站一旦用了 Cloudflare、JavaScript 渲染和反爬指纹,抓取就会变得非常不稳定。
| 失败模式 | 典型原因 | 缓解方式 | |---|---|---|---| | HTML 为空 / 商品缺失 | JS 在初始 HTML 之后加载商品卡片 | 使用 Playwright,等待网络和 DOM | | 只有前几个商品 | 无限滚动 / 懒加载 | 滚动循环、等待网络空闲、设置卡片数量阈值 | | 价格缺失或不一致 | 地区/会话/币种状态,或反爬响应 | 设置地区、cookies、地理定位代理 | | 403 / 验证 / CAPTCHA | IP 信誉、无头指纹、请求频率 | 住宅代理、隐身浏览器、降低频率 | | 选择器失效 | DOM/类名变化、A/B 测试 | 若可行,改用语义提取或 API 解析 |
自定义脚本并不是“免费”方案。它只是把成本从订阅费,转移到了开发者时间、代理账单、验证码成本和维护风险上。如果你有专职爬虫工程师,而且需求里有特殊逻辑,这条路是对的。对其他人来说,它在实践中往往是最贵的方案。
最佳实践:用子页面抓取补全 Temu 商品数据
这是本文中影响最大的一条最佳实践——几乎没有其他指南会讲到它。
Temu 的分类页或搜索页只能给你基础信息:标题、缩略图、价格、粗略评分。但真正让一行数据变得可操作的字段——详细描述、变体列表、完整评论数、运送时间、卖家名称、规格表——都在商品详情页(PDP)里。
如果你只抓列表页,拿到的只是半截数据。
两步工作流如下:
- 步骤 1 —— 抓取列表页(PLP): 从 Temu 搜索页或分类页提取商品名、价格、缩略图、评分。
- 步骤 2 —— 通过子页面抓取补全: 逐个访问每个商品的 PDP,追加完整描述、评论数、变体选项、运送时间、卖家信息等列。
抓取前后,数据长这样:
| 字段 | 来自 PLP(步骤 1) | 从 PDP 新增(步骤 2) |
|---|---|---|
| 商品标题 | ✅ | — |
| 价格 | ✅ | ✅(已验证 / 折扣%) |
| 缩略图 | ✅ | — |
| 星级评分 | ✅ | ✅(含评论数) |
| 完整描述 | ❌ | ✅ |
| 变体(尺寸、颜色) | ❌ | ✅ |
| 卖家名称 | ❌ | ✅ |
| 运送时间 | ❌ | ✅ |
| 详细规格 | ❌ | ✅ |
在 Thunderbit 里,这一步只要一次点击:初次抓取后,点“抓取子页面”。AI 会逐个访问每个商品 URL 并追加额外列——无需额外配置、无需单独蜘蛛、无需维护选择器。Octoparse 的 Temu 详情模板和 Apify 的 Temu actor 也支持 PDP 级字段,但需要更多设置和维护。在 Python 里,你得单独构建一个 PDP 爬虫、维护选择器,并处理详情页内的分页——投入会大很多。
最佳实践:定时抓取 Temu,持续监控价格和库存
一次性抓取适合做选品发现。竞争情报需要持续观察。
价格会变,商品会缺货,新品每天都在上架,促销也会改变折扣力度。每周或每天抓一次,就能形成一张你团队真正能用的历史表。
值得自动化的三个场景:
- 价格监控: 每周追踪竞争对手最热的 50 个 Temu SKU。更新后的价格自动导出到 Google Sheets,方便和自己的定价做对比。
- 库存与可用性监控: 发现某个热门商品缺货、新变体出现,或者运送时间变化。
- 新品/趋势发现: 每天定时抓取 Temu 的“新品上架”或优先分类页。按销量或评论数排序,尽早发现正在起势的商品。
在 Thunderbit 里,你只需要用自然语言描述时间间隔(“每周一上午 9 点”),输入目标 URL,然后点击“定时”。抓取会在云端运行,并导出到你选择的目的地。因为 AI 每次都会重新读取页面,定时抓取能自动适应 Temu 的布局变化——Temu 重设计商品卡片时,你不需要手动更新选择器。
替代方案则是:设置 cron 任务、维护 Python 脚本、配置代理轮换、搭建输出管道,并且每次 Temu 改版时都要修选择器。对非技术团队来说,这根本不可行。对开发者来说,这也是持续开销。Apify 和 Bright Data 也支持定时运行,但技术门槛更高,成本底线也更高。
最佳实践:端到端 Temu 数据流程(抓取 → 清洗 → 导出 → 行动)
大多数爬虫指南会在“下载 CSV”这里结束。
但业务用户需要把数据放进自己真正工作的工具里——Google Sheets 用于协作,Airtable 用于商品数据库,Notion 用于团队仪表盘。真正的最佳实践,是一个端到端工作流:
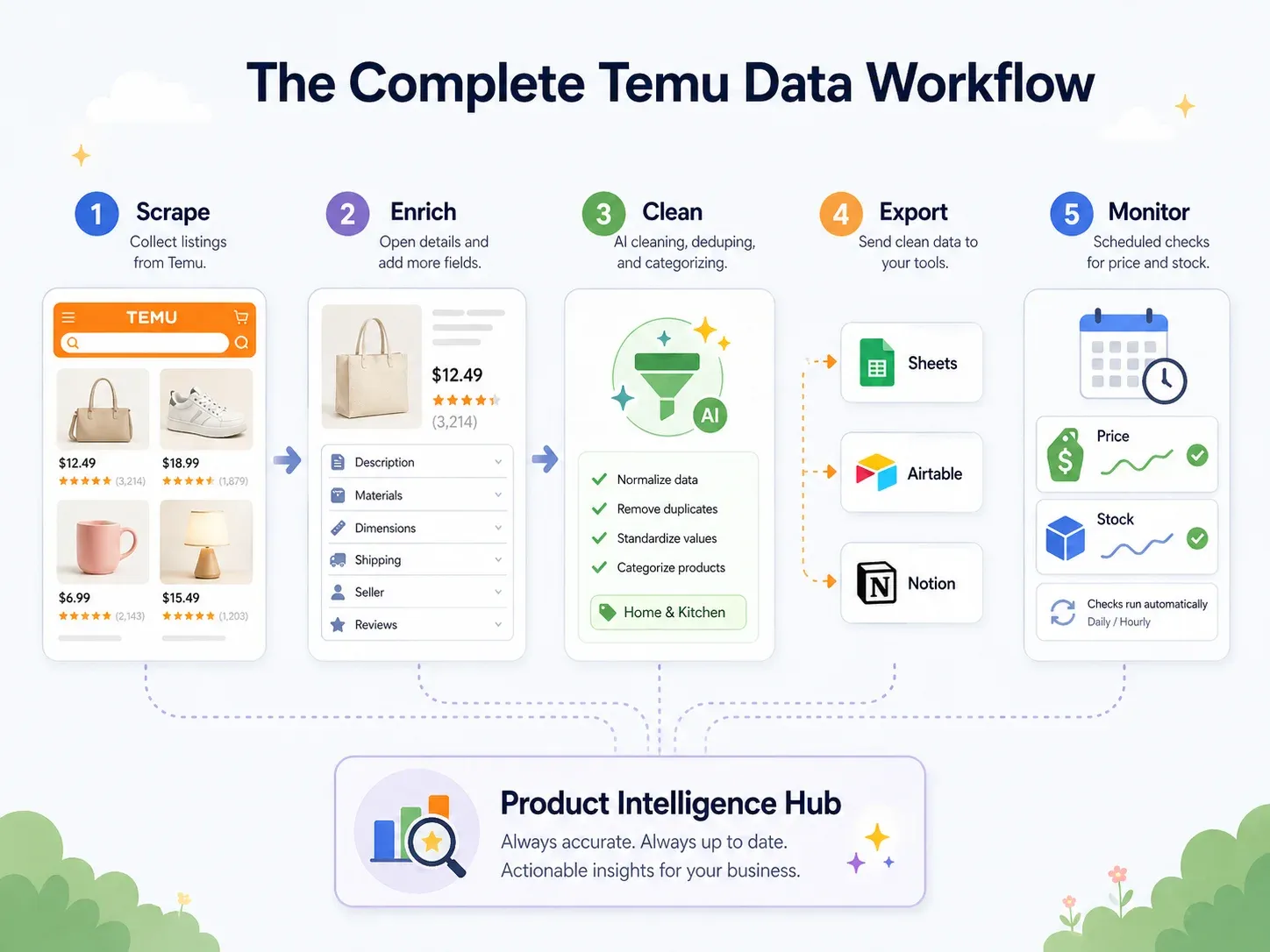
| 流程步骤 | 发生了什么 | Thunderbit 能力 |
|---|---|---|
| 抓取 | 从 Temu 页面提取数据 | AI 建议字段 → 抓取(2 次点击) |
| 补全 | 访问每个商品详情页 | 抓取子页面(1 次点击) |
| 清洗与标注 | 商品分类、价格标准化、标题翻译 | 字段 AI 提示词——在抓取时标注、格式化、翻译 |
| 导出 | 将数据推送到业务工具 | 免费导出到 Excel、Google Sheets、Airtable、Notion;下载 CSV/JSON |
| 监控 | 跟踪时间变化 | 支持自然语言间隔的定时爬虫 |
举个具体例子:你抓取 200 个 Temu 厨房类商品。抓取过程中,字段 AI 提示词会自动把每个商品归类为“厨具 / 小家电 / 收纳 / 清洁 / 装饰”。价格被标准化为数字形式的 USD。中文商品标题被翻译成英文。数据会直接导出到一个 Airtable base,并保留商品图片(不是只有 URL——而是真正的图片附件,正如 Thunderbit 的图片抓取指南 所描述的那样)。定时抓取会每周刷新一次数据。
下面是一些适合 Temu 数据的字段 AI 提示词示例:
- “把这个商品归类为以下之一:厨房用具、小家电、收纳、清洁、装饰、其他。只返回类别。”
- “在保留品牌名、数量、尺寸和型号的前提下,把商品标题翻译成简洁英文。”
- “把价格标准化为不带货币符号的数字。”
- “根据评分、评论数和销量把需求标记为高、中、低。如果缺少数据,返回 Unknown。”
这个工作流能把一次原始抓取,变成一个持续更新的商品情报数据库——而不需要开发者再搭一条独立的 ETL 管道。
最佳 Temu 爬虫对比:并排表格
| 工具 | 技能水平 | 搭建时间 | 反爬处理 | 子页面抓取 | 定时 | 导出选项 | 价格层级 | 最适合 |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | 新手 | 几分钟 | 浏览器模式、云端模式、AI 字段识别 | 支持(抓取子页面) | 支持(自然语言定时) | Excel、CSV、Google Sheets、Airtable、Notion、JSON | 免费 6 页;付费约从 ~$9–15/月起,500 积分 | 非技术电商团队、无货源卖家 |
| Octoparse | 新手–中级 | 10–60 分钟 | 云端提取、代理/CAPTCHA 附加项 | 支持(模板工作流) | 支持(付费/云端方案) | Excel、CSV、JSON、HTML、XML、数据库、Google Sheets | 免费;年付 Standard 约 ~$75/月;附加项另算 | 想要可视化工作流 + Temu 模板的运营者 |
| ParseHub | 新手–中级 | 30–60 分钟 | 动态渲染、付费 IP 轮换 | 支持(项目流程) | 付费方案支持 | CSV/JSON,付费版支持 Dropbox/S3 | 付费从 $189/月起 | 为动态网站搭建可视化项目的团队 |
| ScraperAPI | 开发者 | 数小时 | 代理轮换、JS 渲染、高级代理池 | 需自定义代码 | DataPipeline/定时器 | HTML/JSON/CSV | 试用 5K 积分;Hobby $49/月;更高层级可用 | 构建自定义 Temu 管道的开发者 |
| Apify | 中级 | 如果 actor 匹配,10–30 分钟 | actor 专属浏览器/代理逻辑 | 取决于 actor | 支持 | JSON、CSV、Excel、API/dataset | 平台免费;Temu actor 约 $4–5/1K 商品 | 能评估 actor 质量的开发者/运营者 |
| Bright Data | 高级/企业级 | 数小时–数天 | 完整代理、CAPTCHA、解封、自动扩缩容 | 通过 scraper/API 自定义 | 支持 | JSON、CSV、Parquet、S3、GCS、Azure、BigQuery、Snowflake | 按量约 ~$2.5/1K 记录;承诺方案从 ~$499/月起 | 企业数据团队、大规模抓取 |
| Oxylabs | 高级 | 数小时 | JS 处理、IP/CAPTCHA 声称支持 | 通过 API 自定义 | 支持 | JSON/API 输出 | 从 $49/月起;试用最多 2K 结果 | 需要 Temu API 访问的开发团队 |
| 自定义 Python(Playwright) | 高级 | 1–4 小时以上;持续维护 | 手动代理、验证码、指纹 | 完全自定义 | Cron/队列/手动 | 自定义 | 开发时间 + 代理/CAPTCHA/主机成本 | 边缘场景、拥有爬虫工程师的团队 |
你该选哪种 Temu 爬虫?快速建议
- 无货源卖家,想快速做选品研究? 先用 Thunderbit 免费版 试试。这是从“我想要 Temu 数据”到“我已经有表格了”最快的路径。如果它在你的目标页面上可用(对大多数公开分类页和商品页都应该可以),那就够了。
- 想要可视化控制和可复用模板的运营者? Octoparse 有公开的 Temu 详情模板和可视化工作流构建器。预计需要 10–30 分钟搭建,并进行一些代理/CAPTCHA 配置。
- 在搭建数据管道或内部工具的开发者? ScraperAPI 或 Apify 提供能和代码及定时任务集成的 API/actor 工作流。Apify 的 actor 一定要仔细审查——看维护状态和用户评分。
- 需要大批量 Temu 数据和仓库级交付的企业团队? Bright Data 是基础设施路线。价格不便宜,但能处理规模、解封和到 S3/BigQuery/Snowflake 的交付。
- 需要特殊逻辑的爬虫工程师? 自定义 Playwright/Selenium 给你完全控制。只是要为持续维护、代理成本和验证码处理留足预算。
对大多数非技术业务用户来说,我建议先测试 Thunderbit 的免费版。最直接的问题永远是“我能不能从这一个 Temu 页面拿到我需要的行?”——你完全可以在不到两分钟内、且不花一分钱回答它。对开发者来说,在正式投入预算前,先对 Apify、ScraperAPI 和一个小型 Playwright 原型做每条成功数据的成本基准测试。
关于抓取 Temu 的常见问题
抓取 Temu 合法吗?
这取决于司法管辖区、你收集的数据、访问方式,以及你如何使用这些数据。Temu 的 使用条款 明确限制自动化访问,包括抓取、爬取或蜘蛛式抓取页面或数据。美国法院对访问公开可得数据曾给出过一些有利先例(第九巡回法院的 hiQ v. LinkedIn 判决),但 后续裁决 也支持了违约和侵入主张。简单说:在某些场景下,抓取公开可得的商品数据用于研究可能有辩护空间,但服务条款、隐私法、版权,以及你如何使用数据,都很重要。这不是法律意见——用于商业用途前请咨询律师。
Temu 多久会改一次网站布局?
目前没有公开的固定节奏。社区报告和工具生态都把 Temu 当成一个动态、频繁更新的目标。你应该默认 CSS 选择器随时可能失效,并优先选择 AI/语义提取,或者持续维护的模板,而不是硬编码选择器。
我能不被封地抓取 Temu 吗?
对于少量公开页面,只要节奏合理,是可以的——尤其是使用带真实浏览器渲染、会话支持和限流控制的工具时。没有任何工具能保证百分百不封。使用轮换 IP 的云端抓取适合公开目录页;如果地区、登录或弹窗会影响数据,那么使用当前会话的浏览器抓取效果更好。
我能从 Temu 商品页提取哪些数据?
常见公开字段包括商品标题、URL、当前价格、原价、折扣百分比、图片 URL、星级评分、评论数、销量、卖家/店铺名称、运送信息、分类、商品规格、变体(颜色、尺寸)和抓取时间戳。具体可用字段取决于页面类型(列表页还是详情页)以及地区。
抓取 Temu 需要代理吗?
对于少量、像手动浏览一样的浏览器模式抓取(一次几页),不一定需要。对于云端、定时或大批量采集,通常就需要代理或托管反封锁基础设施。Thunderbit、Bright Data 和 ScraperAPI 等工具会把代理管理打包到平台里,所以你不必单独配置。
如果你想进一步了解相关主题,可以查看我们关于 价格对比网页抓取、最佳电商网页爬虫、把网站数据抓取到 Excel 以及 如何抓取到 Google Sheets 的指南。你也可以在 Thunderbit YouTube 频道 看实操演示。
用 Thunderbit 抓取 Temu Get Started Free
了解更多




