

2026 年的网页爬虫圈子,就像早上 7 点最热闹的农贸市场——大家都在抢最新鲜的数据,而最好的工具能让你在人群里进退自如,抢在拥挤人潮前把东西拿到手。如今,企业把抓来的数据用在销售线索、竞品情报等各种场景里,选对 Python 网页爬虫库早就不只是技术决定,更是一项战略选择。说实话,市面上的选择多得夸张,各种“终极指南”也多得离谱,想挑个工具包,有时候真会让人怀疑自己是不是得先去拿个博士学位。
我在 SaaS 和自动化领域干了很多年,也亲眼见过合适的 Python 网页爬虫工具,怎么把原本要花一整周的活儿压缩成一个上午就能搞定。不管你是要搭建稳定管道的开发者,还是只想把干净数据放进表格里的业务人员,这份清单都会拆解 2026 年 12 款最佳 Python 网页爬虫库——外加一个正在改变无代码用户和专业人士玩法的 AI 方案。
为什么选对 Python 网页爬虫库很重要
网页爬虫不只是拿数据,而是要拿到对的数据,在合适的速度下拿到数据,同时还不能把自己逼疯。到了 2026 年,美国已有超过 65% 的企业 在销售、市场研究和运营中使用自动化网页爬虫,而每天抓取的页面数量已经达到数百亿级。代价也不小:工具选错了,可能意味着错失机会、脚本报错,或者把大量时间浪费在调试上。
用 AI 从任何网站抓取数据 Get Started Free
在挑选 Python 网页爬虫工具时,关键会落在这些方面:
- 性能: 能不能扛住大规模任务而不崩?
- 易用性: 你是在写代码,还是在尽快拿结果?
- 浏览器与 JavaScript 支持: 能不能处理现代动态网站?
- 可扩展性: 能不能随着需求一起成长?
- 集成能力: 和你的数据管道或业务流程配合得有多顺手?
常见业务场景?比如线索生成、价格跟踪、竞品监控,以及自动化那些“拜托别再来一次”的数据录入任务。选对库,可能就是销售团队总能快人一步,和团队被困在表格地狱里之间的差别。
我们如何评估最佳 Python 网页爬虫库
为了做出这份清单,我重点看了每个库的:
- 性能与可扩展性: 它能不能很好地处理大任务和复杂网站?
- 易用性: 对新手友好吗,还是得有 Python 黑带水平?
- 浏览器与 JavaScript 处理能力: 能否应对动态内容和现代 Web 应用?
- 安全性与维护: 是否持续维护,使用起来是否安全?
- 社区与支持: 文档、教程和社区是否足够,遇到问题时能不能找到帮助?
- 集成潜力: 能不能和其他工具(或者像 Thunderbit 这样的 AI 方案)组合,发挥更大威力?
我也考虑了真实业务需求——因为归根结底,你的代码好不好,得看它交付的数据好不好。
1. Thunderbit
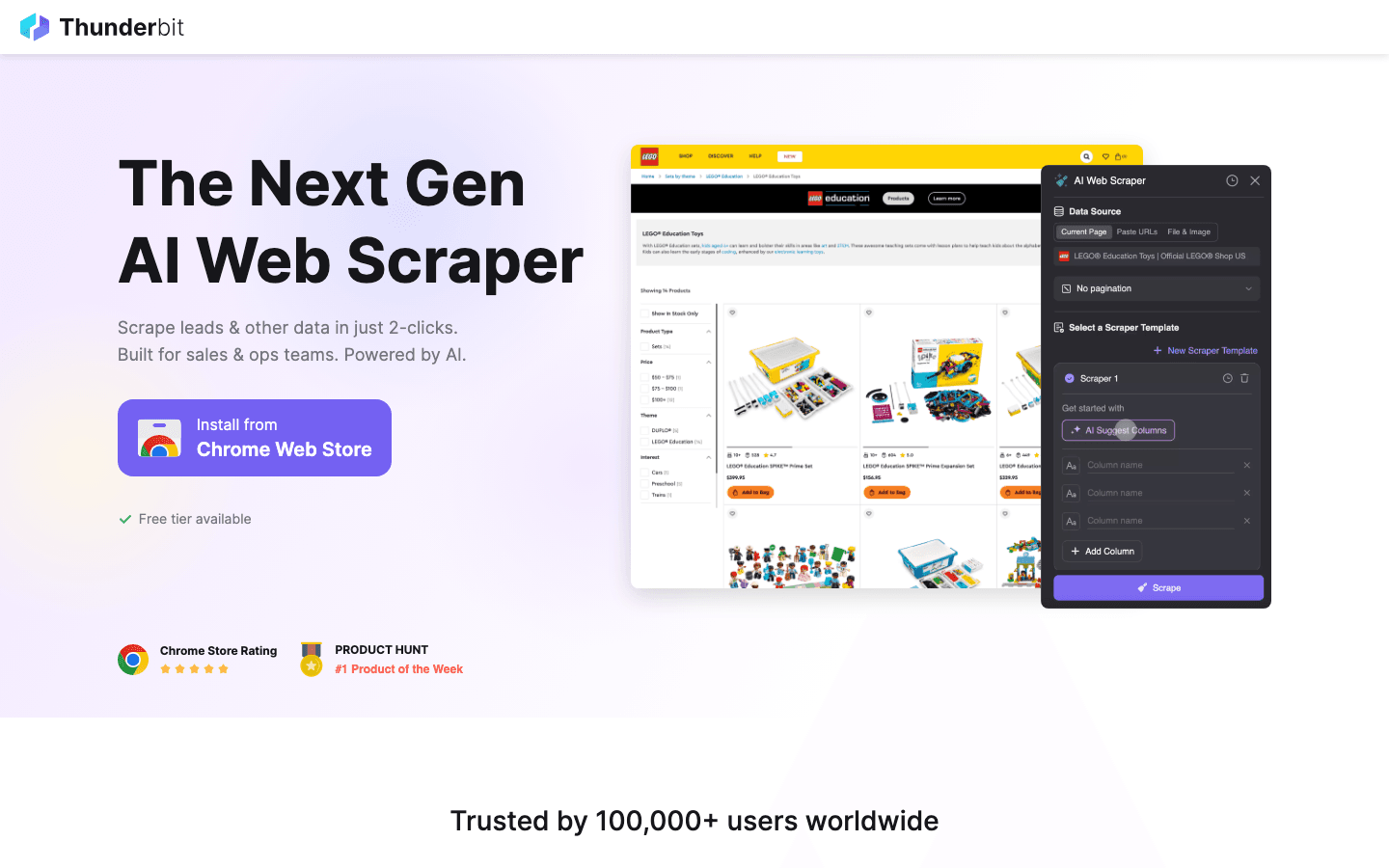 Thunderbit 不是传统的 Python 库,而是一个正在改变 2026 年业务用户和开发者做网页抓取方式的 AI 浏览器扩展。它值得出现在这份清单里,原因如下。
Thunderbit 不是传统的 Python 库,而是一个正在改变 2026 年业务用户和开发者做网页抓取方式的 AI 浏览器扩展。它值得出现在这份清单里,原因如下。
主要功能:
- AI 自动建议字段: 只要描述你想要什么,Thunderbit 的 AI 就会自动判断列和数据类型。
- 子页面抓取: 自动访问并提取子页面数据(比如商品详情页或领英资料页)。
- 即用模板: 一键抓取热门网站(Amazon、Zillow、Shopify 等)。
- 免费导出数据: 可导出到 Excel、Google 表格、Airtable、Notion、CSV 或 JSON,不收额外费用。
- 无代码流程: 既适合非技术用户,也能与 Python 工具集成,支持更高级的工作流。
最佳使用场景: 销售线索生成、电商价格监控、房源列表、运营,以及任何需要快速获取结构化数据的场景。
优点:
- 无需编写代码——点点、选选、描述一下就行
- AI 能适应网站布局变化
- 轻松处理杂乱、长尾的网页数据
- 可与 Python 库(如 Scrapy 或 Beautiful Soup)组合成混合工作流
缺点:
- 不是纯 Python 库(但可以很好地配合 Python 管道)
- 更适合业务用户,或作为代码爬取的补充
专业提示: 如果你想快速做爬虫原型,或者处理杂乱、一次性的任务,Thunderbit 很合适。若要做大规模自动化,可以先用 Thunderbit 导出结构化数据,再交给 Python 脚本继续处理。
2. Beautiful Soup
 Beautiful Soup 是解析和浏览 HTML 或 XML 的首选 Python 库。如果你曾经清理过一个乱七八糟、格式不规范的网页,就会明白为什么它这么受新手和专业人士欢迎。
Beautiful Soup 是解析和浏览 HTML 或 XML 的首选 Python 库。如果你曾经清理过一个乱七八糟、格式不规范的网页,就会明白为什么它这么受新手和专业人士欢迎。
主要功能:
- 用直观语法搜索、浏览和修改 HTML/XML
- 能够优雅处理格式不佳或损坏的标记
- 与 Requests 无缝集成,用于抓取页面
最佳使用场景: 快速抓取、数据清洗、解析中小型页面。
优点:
- 极易上手
- 很适合清理丑陋的 HTML
- 灵活且宽容
缺点:
- 处理大型文档时比 LXML 慢
- 没有内置 JavaScript 支持
专业提示: 想要更快,可以把 Beautiful Soup 和 lxml 解析器一起用。面对更复杂、动态的网站,可以考虑搭配 Selenium 或 Pyppeteer。
3. Selenium
 Selenium 是浏览器自动化领域的重量级选手。它能控制 Chrome、Firefox、Edge 等浏览器,非常适合抓取动态、JavaScript 很重的网站。
Selenium 是浏览器自动化领域的重量级选手。它能控制 Chrome、Firefox、Edge 等浏览器,非常适合抓取动态、JavaScript 很重的网站。
主要功能:
- 自动化真实浏览器(Chrome、Firefox 等)
- 支持无头模式,速度更快,也无需图形界面
- 可与表单、按钮交互,并模拟用户操作
最佳使用场景: 需要登录、点击或大量 JavaScript 渲染的网站抓取。
优点:
- 几乎能处理任何网站,不管它有多动态
- 支持多个浏览器和平台
- 既适合测试,也适合抓取
缺点:
- 比纯无头方案慢
- 资源消耗更高
- 如果网站布局变化,脚本可能比较脆弱
专业提示: 当别的方法都不行时,就用 Selenium;但如果追求速度和规模,可以看看 Scrapy 或 Pyppeteer。
4. Requests
 Requests 是 Python 里必备的 HTTP 库。它是许多爬虫流程的基础,让发送 GET/POST 请求和处理响应变得非常简单。
Requests 是 Python 里必备的 HTTP 库。它是许多爬虫流程的基础,让发送 GET/POST 请求和处理响应变得非常简单。
主要功能:
- 简洁、符合 Python 风格的 HTTP 请求 API
- 处理 cookie、会话和身份验证
- 能和 Beautiful Soup、LXML 等解析器很好配合
最佳使用场景: 抓取静态页面、API,或作为自定义爬虫的基础组件。
优点:
- 使用极其简单
- 可靠且维护良好
- 非常适合快速脚本和原型验证
缺点:
- 没有内置 HTML 解析
- 无法处理 JavaScript 渲染内容
专业提示: 把 Requests 和 Beautiful Soup 或 LXML 结合起来,就是经典又轻量的爬虫技术栈。
5. LXML
 LXML 是 Python HTML/XML 解析里的速度怪兽。如果你需要处理超大文档或执行复杂的 XPath 查询,LXML 就是你的好帮手。
LXML 是 Python HTML/XML 解析里的速度怪兽。如果你需要处理超大文档或执行复杂的 XPath 查询,LXML 就是你的好帮手。
主要功能:
- 基于 C 后端,解析速度极快
- 完整支持 XPath 和 CSS 选择器
- 同时处理 HTML 和 XML
最佳使用场景: 大规模解析、复杂文档结构、对速度要求很高的项目。
优点:
- 处理大任务时比 Beautiful Soup 快得多
- 选择器支持强大
- 错误处理稳健
缺点:
- 对损坏 HTML 的容错性没那么高
- 学习曲线略陡
专业提示: 可以把 LXML 作为 Beautiful Soup 的解析器,这样就能兼顾易用性和性能。
6. Pyppeteer
 Pyppeteer 是 Puppeteer 的 Python 版本,让你能控制无头 Chrome,完成高级爬取任务。它专为现代 Web 应用和大量 JavaScript 场景而生。
Pyppeteer 是 Puppeteer 的 Python 版本,让你能控制无头 Chrome,完成高级爬取任务。它专为现代 Web 应用和大量 JavaScript 场景而生。
主要功能:
- 完整控制无头 Chrome(或 Chromium)
- 出色的 JavaScript 渲染和用户模拟能力
- 可处理复杂导航、截图和 PDF 生成
最佳使用场景: 抓取现代、JavaScript 很重的网站,自动化用户流程,绕过反机器人措施。
优点:
- 顶级 JavaScript 支持
- 能模拟人类行为,应对棘手网站
- 很适合抓取单页应用(SPA)
缺点:
- 比 Requests 或 Scrapy 更重、更慢
- 上游仓库已经明确说明不再维护,并建议使用 Playwright for Python 作为仍在积极开发的替代方案——如果你在 2026 年开启新项目,除非你需要维护已有的 Pyppeteer 代码库,否则更建议直接选 Playwright
- 需要更多配置
专业提示: 2026 年大多数“我需要一个能驱动 Chromium 的 Python 库”的新项目,默认都应该考虑 Playwright for Python(连 Pyppeteer 维护者本身也会把你引过去)。如果你已经有现成代码库,Pyppeteer 仍然能用,而“先用 Thunderbit 做原型,再交给 Python”这种模式在 Playwright 上同样适用。
7. Splash
 Splash 是一个轻量级浏览器引擎,专门用于大规模渲染 JavaScript。它通常与 Scrapy 搭配,用于抓取动态网站。
Splash 是一个轻量级浏览器引擎,专门用于大规模渲染 JavaScript。它通常与 Scrapy 搭配,用于抓取动态网站。
主要功能:
- 带 HTTP API 的无头浏览器
- 渲染 JavaScript,并返回 HTML、截图或 HAR 文件
- 可通过中间件与 Scrapy 集成
最佳使用场景: 批量处理 JavaScript 很重的页面、可扩展的爬虫管道、服务器端渲染。
优点:
- 大规模渲染时速度快、效率高
- 基于 API,易于集成
- 比完整浏览器自动化更省资源
缺点:
- 与 Selenium 或 Playwright 相比交互能力有限
- 公共仓库自 2022 年 5 月以来就没有合并到 master 的提交,最新的 PyPI 版本(3.5)也还是 2020 年 6 月发布的——它今天仍然能作为 JavaScript 渲染服务使用,但你要预期自己维护 Docker 镜像,不能指望上游继续修复
- 配置和脚本编写有一定学习成本
专业提示: 如果要大规模抓取动态网站,Scrapy + Splash 是非常强的组合。
8. MechanicalSoup
 MechanicalSoup 是一个轻量级 Python 库,用于自动化网页表单和简单导航。它建立在 Requests 和 Beautiful Soup 之上。
MechanicalSoup 是一个轻量级 Python 库,用于自动化网页表单和简单导航。它建立在 Requests 和 Beautiful Soup 之上。
主要功能:
- 自动提交表单并进行页面导航
- 维护会话状态和 cookie
- API 简单,新手友好
最佳使用场景: 网站登录、填写表单、抓取静态或轻度动态页面。
优点:
- 配置极少——很适合快速自动化
- 开箱即用地处理 cookie 和会话
- 非常适合带简单登录或搜索表单的网站
缺点:
- 不支持 JavaScript
- 不适合大规模或高度动态的抓取任务
专业提示: 登录流程可以先用 MechanicalSoup,后续内容再交给 Requests + Beautiful Soup 处理。
9. Twisted
 Twisted 是 Python 的事件驱动网络引擎。严格说它并不是网页爬虫,但它是构建自定义、高吞吐爬虫管道的基础。
Twisted 是 Python 的事件驱动网络引擎。严格说它并不是网页爬虫,但它是构建自定义、高吞吐爬虫管道的基础。
主要功能:
- 用于 HTTP、TCP 等的异步网络能力
- 可扩展到数千个并发连接
- 用于自定义、分布式爬虫系统
最佳使用场景: 构建自定义的大规模爬虫;与其他异步框架集成。
优点:
- 可扩展性和能力都非常强
- 支持多种协议
- 很适合高级用户
缺点:
- 学习曲线陡峭
- 对大多数标准爬取任务来说有点大材小用
专业提示: 如果你要做真正的大规模抓取(比如数百万页面),Twisted 值得学习。
10. Scrapy
 Scrapy 是 Python 网页爬虫框架里的瑞士军刀。它面向大规模、可投入生产的项目,基于异步架构构建,能让你轻松抓取成千上万的页面。
Scrapy 是 Python 网页爬虫框架里的瑞士军刀。它面向大规模、可投入生产的项目,基于异步架构构建,能让你轻松抓取成千上万的页面。
主要功能:
- 异步、事件驱动引擎,吞吐量高
- 内置管道、中间件和数据导出(JSON、CSV、XML)支持
- 把爬取、解析和数据清洗放在同一个地方完成
- 可通过代理、用户代理等插件扩展更多能力
最佳使用场景: 企业级爬取、结构化数据提取、需要速度和稳定性的项目。
优点:
- 大任务时速度飞快
- 高度可定制、可扩展
- 社区和文档都很强
缺点:
- 新手学习曲线陡峭
- 默认并不适合直接抓取 JavaScript 很重的动态网站
专业提示: Scrapy 很适合和 Splash 搭配做 JavaScript 渲染,或者和 Thunderbit 搭配,实现 AI 自动字段识别和数据结构化。
11. PyQuery
 PyQuery 把 jQuery 风格的选择器带到了 Python 里。如果你喜欢 jQuery 的语法,会觉得它非常顺手。
PyQuery 把 jQuery 风格的选择器带到了 Python 里。如果你喜欢 jQuery 的语法,会觉得它非常顺手。
主要功能:
- 类 jQuery API,用于选择和操作 HTML
- 基于 lxml 构建,速度很快
- 支持 CSS 选择器和 DOM 操作
最佳使用场景: 熟悉 jQuery 的开发者、快速原型验证、需要快速且灵活选择器的项目。
优点:
- 速度快、效率高
- 对有 jQuery 经验的人来说很直观
- 既适合解析,也适合修改 HTML
缺点:
- 社区规模比 Beautiful Soup 或 LXML 小
- 对损坏 HTML 的支持有限
专业提示: 如果你想要 lxml 的性能,但更偏好 CSS 选择器而不是 XPath,就用 PyQuery。
12. Parsel
 Parsel 是一个强大的库,专门用于用 XPath 和 CSS 选择器从 HTML 和 XML 中提取数据。它也是 Scrapy 解析引擎背后的“秘密武器”。
Parsel 是一个强大的库,专门用于用 XPath 和 CSS 选择器从 HTML 和 XML 中提取数据。它也是 Scrapy 解析引擎背后的“秘密武器”。
主要功能:
- 对 XPath 和 CSS 选择器提供高级支持
- 用于提取和清洗数据的简洁 API
- 可单独使用,也可在 Scrapy 中使用
最佳使用场景: 复杂数据提取、需要稳健选择器逻辑的项目、与 Scrapy 集成。
优点:
- 非常灵活、能力强大
- 很适合处理棘手的页面布局
- 文档完善,并且持续维护中
缺点:
- 需要一定的选择器知识
- 不是完整的爬虫框架——更适合作为解析组件
专业提示: 如果你要写自定义 Scrapy 爬虫或独立解析脚本,Parsel 很适合承担核心解析工作。
一览对比:Python 网页爬虫工具速查表
| 库 | 主要功能 | 性能 | 易用性 | JavaScript 支持 | 最适合 | 集成选项 |
|---|---|---|---|---|---|---|
| Thunderbit | AI 驱动、无代码、子页面 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 是(基于浏览器) | 业务用户、混合工作流 | Excel、Sheets、Notion、Python |
| Beautiful Soup | HTML/XML 解析、容错性强 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 否 | 数据清洗、小任务 | Requests、LXML、Thunderbit |
| Selenium | 浏览器自动化、动态内容 | ⭐⭐ | ⭐⭐ | 是 | 动态网站、用户交互 | Beautiful Soup、PyQuery |
| Requests | HTTP 请求、会话 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 否 | 抓取静态页面、API | Beautiful Soup、LXML |
| LXML | 解析快、XPath、CSS 选择器 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 否 | 大文档、复杂解析 | Beautiful Soup、PyQuery |
| Pyppeteer | 无头 Chrome、JS 渲染 | ⭐⭐ | ⭐⭐ | 是 | 现代 JS 网站、SPA | Thunderbit、Pandas |
| Splash | JS 渲染、基于 API | ⭐⭐⭐ | ⭐⭐ | 是 | 批量 JS 抓取、管道 | Scrapy、Thunderbit |
| MechanicalSoup | 表单处理、页面导航 | ⭐⭐ | ⭐⭐⭐⭐ | 否 | 简单表单、登录 | Requests、Beautiful Soup |
| Twisted | 异步网络、自定义管道 | ⭐⭐⭐⭐⭐ | ⭐ | 否 | 高吞吐、自定义爬虫 | Scrapy、自定义框架 |
| Scrapy | 高性能、异步、管道 | ⭐⭐⭐⭐⭐ | ⭐⭐ | 受限(通过 Splash) | 企业级、结构化数据 | Splash、Parsel、Thunderbit |
| PyQuery | jQuery 风格选择器、速度快 | ⭐⭐⭐ | ⭐⭐⭐⭐ | 否 | jQuery 用户、快速原型 | LXML、Requests |
| Parsel | XPath/CSS 选择器、灵活解析 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 否 | 复杂提取、Scrapy 用户 | Scrapy、独立使用 |
如何根据需求选择最佳 Python 网页爬虫库
这是我的快速决策流程:
-
处理静态页面或 API?
用 Requests + Beautiful Soup 或 LXML。 -
需要快速抓取海量数据?
Scrapy 是你的好朋友。若需要异步网络能力,可以考虑 Twisted。 -
抓取动态、JavaScript 很重的网站?
试试 Selenium、Pyppeteer,或者 Splash(配合 Scrapy)。 -
想要 jQuery 风格的选择器?
PyQuery 很适合。 -
需要自动化表单或登录?
MechanicalSoup 简单又有效。 -
不是程序员,或者想省掉配置时间?
Thunderbit 让你用自然语言定义需求,然后把结构化数据导出到你常用的工具里。 -
混合方案?
用 Thunderbit 快速做原型并结构化数据,再把结果交给 Python 脚本继续处理。
选工具清单:
- 网站复杂度如何(静态还是动态)?
- 你需要抓多少数据?
- 需不需要处理表单或登录?
- 你对 Python 和选择器的熟悉程度如何?
- 需不需要导出到业务工具(Excel、Sheets、Notion)?
- 后续维护会不会是个问题?
结语:在 2026 年释放 Python 网页爬虫的力量
Python 网页爬虫从未像今天这样强大,也从未像今天这样容易上手。无论你是用 Scrapy 扩大规模、用 Beautiful Soup 清洗数据、用 Selenium 或 Pyppeteer 处理 JavaScript,还是只是想不写一行代码就把数据放进表格里,总有一款工具适合你。
什么是数据抓取,以及如何在 2025 年完成它 Get Started Free
真正的秘诀是什么?别害怕混搭。最好的 Python 网页爬虫库各有长处,把它们组合起来(或者加入像 Thunderbit 这样的 AI 方案)能帮你节省大量时间、减少错误,并解锁新的商业洞察。顺带说一句,到了 2026 年要诚实地提醒你:这份清单里的两个库——Pyppeteer 和 Splash——虽然在现有代码库里仍然能安装、也能正常使用,但它们的上游仓库基本已经停止更新。所以如果你要从零开始做真实浏览器或 JavaScript 渲染相关的新项目,Playwright for Python 才是大多数团队应该优先考虑的活跃维护方案。
在 2026 年,赢家不只是最快的程序员,而是那些能把工具用对、把枯燥工作自动化、并专注于真正重要事情的人:把网页数据转化为真实的商业价值。
常见问题
1. 如果我是新手,哪款 Python 网页爬虫库最好?
Beautiful Soup 因为语法简单、容错性强,通常最推荐给新手。对于非程序员,Thunderbit 提供了 AI 驱动、无需代码的替代方案。
2. 哪个 Python 网页爬虫工具最适合动态或 JavaScript 很重的网站? 对于 2026 年的新项目,Selenium 和 Playwright for Python 是两个值得默认考虑的、仍在积极维护的选项(Microsoft 大约每月发布一次 Playwright;Selenium 4.44 于 2026 年 5 月发布)。Pyppeteer 和 Splash 目前仍可安装并使用,但上游开发基本已经停止,所以只有在你已经在生产环境中使用它们时,才建议继续选用。
3. 我能把 Thunderbit 和 Scrapy 或 Beautiful Soup 这类 Python 库一起用吗?
当然可以!Thunderbit 可以快速把数据结构化并导出,然后你再用自己喜欢的 Python 库做进一步处理。
4. 解析大型 HTML 文档时,哪款 Python 库最快?
对于大规模解析,LXML 通常是最快的,尤其是在使用 XPath 或 CSS 选择器时。
5. 我该如何在 Scrapy 和 Selenium 之间做选择?
如果你要处理的是大规模、结构化、且大多是静态的网站,就用 Scrapy。若需要与动态元素、登录流程或 JavaScript 很重的页面交互,就选 Selenium。
想看看 Thunderbit 如何让你的网页爬虫流程更高效吗?下载 Chrome 扩展,并在 Thunderbit 博客 阅读更多指南。祝你抓取顺利!
免费试用 Thunderbit AI 网页爬虫 Get Started Free
了解更多




