互联网已经变成一片狂野、不断变化的地带——与其说是“数字图书馆”,不如说是“数据丛林”。到了 2025 年,如果你想从现代网站抓取数据,面对的早已不只是满屏 JavaScript,而是一座堡垒。我亲眼见过传统爬虫工具如何在动态内容、无限滚动和反爬机制面前一步步失守。这也是为什么 python 无头浏览器 的崛起,不只是一种趋势——它已经成了任何需要稳定、可扩展网页数据提取的人绕不开的一场变革。
而且,关心这件事的可不只是技术人员。到 2025 年,,同时现在已有超过 。无论你做销售、电商还是运营,合适的 python 无头浏览器,决定了你面对的是“数据触手可及”,还是“数据遥不可及”。所以,让我们拨开噪音——我已经测试、对比并长期使用过这些工具,现在就来拆解 10 款最适合现代抓取的 python 无头浏览器(其中还会特别看看 AI 如何为不会写代码的人改写游戏规则)。
为什么 Python 无头浏览器对现代抓取如此重要?
先把术语说清楚:所谓 python 无头浏览器,其实就是你可以用 Python 代码控制的网页浏览器,只不过它不会在屏幕上弹出那个笨重的窗口。它会加载页面、运行 JavaScript、点击按钮、填写表单——所有动作都悄无声息地在后台完成。你可以把它想成一台“幽灵浏览器”,在你喝咖啡的时候默默干活。
这为什么重要?因为现代网站是给用户设计的,不是给机器人设计的。它们会把数据藏在 JavaScript 后面,需要登录,并且希望你像真人一样交互。那些只能抓取 HTML 的传统爬虫,只能面对一层空壳。相比之下,无头浏览器会 模拟真实用户行为——等待 AJAX 请求完成、滚动无限信息流,并抓取你在 Chrome 或 Firefox 里看到的完整内容()。
但这还不止:
- 速度与效率: 无头浏览器跳过了可视化渲染,所以更快、占用内存更少——非常适合大规模抓取()。
- 动态内容支持: 它们可以执行 JavaScript,因此你拿到的是渲染后的真实数据,而不只是原始 HTML。
- 自动化能力: 需要登录、翻页或处理弹窗?Python 无头浏览器都能自动完成。
- 可扩展性: 可以在云端运行数百个实例,并行抓取成千上万页面,毫不费力。
对于企业用户来说,这意味着你终于可以获取线索、监控竞品或追踪价格——哪怕网站的防护像金库一样严密。再加上最新的 AI 工具,即使不会写代码,你也能参与进来。
我们如何挑选最佳 Python 无头浏览器
我可不是随便列了一堆浏览器名字。我的筛选标准如下:
- 性能与速度: 能否快速、稳定地处理现代、重 JavaScript 的网站?
- 浏览器支持: 是否支持 Chrome、Firefox、WebKit,甚至像 IE 这样的老旧引擎?
- 易用性: 对不会写代码的人友好吗,还是要你先拿到 Python 博士学位?
- AI 与无代码功能: 企业用户能否借助 AI 自动抓取,而不用写脚本?
- 社区与支持: 是否有活跃社区、完善文档和持续开发?
- 独特功能: 是否提供即时模板、云端抓取或子页面导航等特别能力?
我见过很多团队花了几周时间折腾环境,结果网站一改版又立刻卡住。真正好的工具,不只是“能用”,而是能适应、能扩展,还能让你的工作轻松很多。
现代抓取的 10 款最佳 Python 无头浏览器
下面是我的权威名单,我会深入讲讲每个工具的亮点和短板。
1. Thunderbit
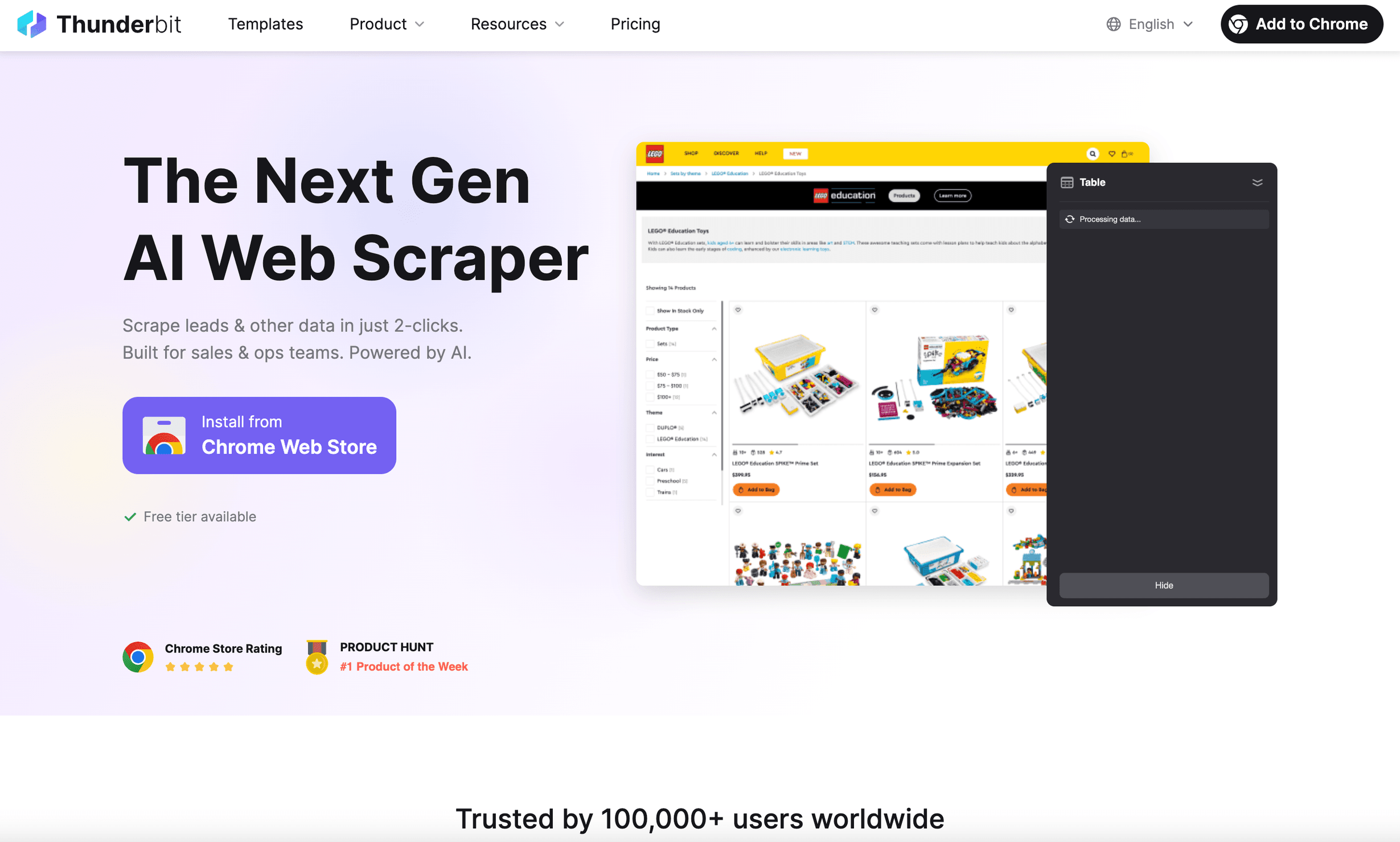 是我几年前就希望能拥有的 python 无头浏览器。它不只是浏览器自动化工具,更是一款面向企业用户、以结果为导向的 AI 网页爬虫 Chrome 扩展。
是我几年前就希望能拥有的 python 无头浏览器。它不只是浏览器自动化工具,更是一款面向企业用户、以结果为导向的 AI 网页爬虫 Chrome 扩展。
Thunderbit 的突出之处:
- AI 推荐字段: 只要点击“AI 推荐字段”,Thunderbit 的 AI 就会读取页面、建议要提取哪些数据,并帮你完成爬虫设置()。
- 即时数据模板: 对于 Amazon、Zillow、领英等热门网站,你可以直接一键使用模板,无需配置。
- 子页面与分页抓取: Thunderbit 可以点击进入子页面、处理无限滚动,并把所有数据合并成一张表。
- 自然语言提示词: 你只要用普通英语描述需求,剩下的交给 Thunderbit 的 AI。
- 云端或浏览器抓取: 可以在本地或云端运行抓取任务(为了速度,云端最多可同时处理 50 个页面)。
- 无需编程: 说真的——只要你会用浏览器,就会用 Thunderbit。
- 免费导出数据: 一键导出到 Excel、Google Sheets、Notion 或 Airtable。
我见过 Thunderbit 为销售和运营团队省下大量时间——抓取线索、监控价格、汇总产品数据,全程不用碰代码。它在全球拥有 的信任,而且大家的反馈几乎都一样:“真不敢相信这么简单。”
适合: 非技术用户、企业团队,以及任何希望 AI 替你完成重活的人。
2. Selenium
 是浏览器自动化领域的老牌王者。如果你搜过“python 无头浏览器”,大概率见过 Selenium WebDriver。
是浏览器自动化领域的老牌王者。如果你搜过“python 无头浏览器”,大概率见过 Selenium WebDriver。
优点:
- 支持所有主流浏览器: Chrome、Firefox、Safari、Edge,甚至 Internet Explorer(勇士专用)。
- 社区庞大: 教程、插件、Stack Overflow 解答都非常多。
- 高度灵活: 用户能做的事,基本都能自动化——点击、表单、导航都不在话下。
缺点:
- 安装配置有点折腾: 你需要管理浏览器驱动,并保持版本同步。
- 比现代工具慢: WebDriver 协议会带来额外开销,扩展到几百个浏览器实例也比较笨重。
- API 冗长: 写起来通常比 Playwright 或 Puppeteer 更啰嗦。
适合: 已经有 Selenium 经验的团队、跨浏览器测试,或者遗留自动化流程。
3. Puppeteer
 是 Google 为 Chrome/Chromium 提供的高层自动化库。虽然它原生面向 Node.js,但 Python 用户也可以通过 Pyppeteer 参与进来。
是 Google 为 Chrome/Chromium 提供的高层自动化库。虽然它原生面向 Node.js,但 Python 用户也可以通过 Pyppeteer 参与进来。
优点:
- 为 Chrome 优化: 快、轻、与 Chrome DevTools 深度集成。
- 异步 API: 很适合现代、重 JavaScript 的网站。
- 功能丰富: 支持截图、导出 PDF、拦截网络请求。
缺点:
- 仅支持 Chromium: 不支持 Firefox 或 Safari。
- 原生是 Node.js: Python 用户必须使用 Pyppeteer(而且它现在已经停止维护——见下文)。
适合: 想要快速、稳定控制 Chrome 的开发者,并且不需要跨浏览器支持。
4. Playwright
 是微软推出的新秀,如今已迅速成为我做高级抓取的首选。
是微软推出的新秀,如今已迅速成为我做高级抓取的首选。
优点:
- 多浏览器支持: 通过一个 API 就能自动化 Chromium、Firefox 和 WebKit。
- 自动等待: 不用再猜页面什么时候准备好了——Playwright 会替你等。
- 并发能力: 可以并行运行多个浏览器上下文,速度非常快。
- Python 优先: 原生 Python 绑定,同时支持异步和同步。
缺点:
- 安装包更大: 会打包多个浏览器,所以安装稍重一些。
- 仍然需要编程: 对非技术用户来说,不如 Thunderbit 友好。
适合: 需要强大、现代自动化能力的开发者,尤其适合复杂、动态的 Web 应用。
5. Headless Chrome
 是上面许多工具背后的引擎。你可以直接通过 Chrome DevTools Protocol(CDP)控制它,从而获得最大的灵活性。
是上面许多工具背后的引擎。你可以直接通过 Chrome DevTools Protocol(CDP)控制它,从而获得最大的灵活性。
优点:
- 前沿 Web 支持: 只要在 Chrome 里能运行,在无头 Chrome 里也能运行。
- 精细控制: 可以深入浏览器的每个角落。
缺点:
- 学习曲线陡峭: 你得会 CDP,或者使用封装库。
- 仅支持 Chrome: 不支持跨浏览器。
适合: 构建自定义自动化流水线,或在底层集成 Chrome 的专家。
6. Pyppeteer
 是 Puppeteer 的非官方 Python 移植版。它把异步 Chrome 自动化带进了 Python,但……有个问题。
是 Puppeteer 的非官方 Python 移植版。它把异步 Chrome 自动化带进了 Python,但……有个问题。
优点:
- Puppeteer 风格 API: 如果你会用 Puppeteer,上手会很顺。
- 快速 Chrome 自动化: 很适合动态网站。
缺点:
- 停止维护: 原项目已经不再更新(开发者建议迁移到 Playwright)。
- 仅支持 Chromium: 不支持 Firefox 或 Safari。
适合: 已经在用 Pyppeteer 的遗留项目。新项目建议直接用 Playwright。
7. Splash
 是一款轻量、可脚本化的无头浏览器,带有 HTTP API,由 Scrapinghub(现在是 Zyte)团队打造。
是一款轻量、可脚本化的无头浏览器,带有 HTTP API,由 Scrapinghub(现在是 Zyte)团队打造。
优点:
- 轻量: 使用 QtWebKit,比 Chrome 更省资源。
- HTTP API: 不只限于 Python,任何语言都能控制。
- 对 Scrapy 友好: 和 Scrapy 爬虫无缝集成,用于 JS 渲染。
缺点:
- WebKit 内核较旧: 在最新 JavaScript 特性面前可能吃力。
- 需要 Lua 脚本: 如果要做更复杂的交互,你得学一点 Lua。
适合: 需要偶尔做 JS 渲染的 Scrapy 用户,或轻量级服务器端渲染任务。
8. PhantomJS
 是最早一批可脚本化的无头浏览器,基于 WebKit 构建。它曾经是先驱,但如今大多已经过时。
是最早一批可脚本化的无头浏览器,基于 WebKit 构建。它曾经是先驱,但如今大多已经过时。
优点:
- 脚本简单: 用 JavaScript 自动化很容易。
- 兼容旧系统: 对旧的静态网站仍然可用。
缺点:
- 停止维护: 自 2016 年以来就没有更新。
- 内核过时: 无法应对现代、重 JS 的网站。
- 安全风险: 没有近期补丁。
适合: 维护遗留脚本。新项目建议迁移到 Playwright 或 Puppeteer。
9. HtmlUnit
 是一款基于 Java 的无头浏览器,用来模拟浏览器行为。它速度快、很轻量,但不是真正的浏览器引擎。
是一款基于 Java 的无头浏览器,用来模拟浏览器行为。它速度快、很轻量,但不是真正的浏览器引擎。
优点:
- 纯 Java: 很适合 Java 技术栈很重的环境。
- 静态页面快: 不需要启动完整浏览器。
缺点:
- JS 支持有限: 在现代、动态网站上表现一般。
- 不是 Python 原生: 需要通过集成层使用,例如 Selenium 的 HtmlUnitDriver。
适合: 基于 Java 的工作流、测试遗留应用,或抓取简单、服务器渲染的页面。
10. TrifleJS
 是一款面向 Internet Explorer(IE)的无头浏览器,目标是在 Windows 上自动化遗留 Web 应用。
是一款面向 Internet Explorer(IE)的无头浏览器,目标是在 Windows 上自动化遗留 Web 应用。
优点:
- IE 自动化: 适合处理老旧内网应用,或只能在 IE 中运行的系统。
- 类似 PhantomJS 的 API: 迁移 PhantomJS 脚本时改动很少。
缺点:
- 仅限 Windows: 不支持跨平台。
- 已经过时: IE 已经退役,TrifleJS 也很小众,维护很少。
适合: 仍然必须做 IE 自动化的特殊遗留流程。
功能对比表:一眼看懂 Python 无头浏览器
| 工具 | 浏览器支持 | 性能与规模 | 易用性 | AI/无代码功能 | 社区与支持 | 最适合 |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome(扩展/云端) | 高(云端并行) | 最简单——无需代码 | 有(AI、模板) | 持续增长、活跃 | 不会写代码的人、销售/运营、快速数据提取 |
| Selenium | 所有主流浏览器 | 中等 | 中等(需配置) | 无 | 非常大、很成熟 | 跨浏览器、遗留、测试自动化 |
| Puppeteer | Chromium/Chrome | 非常高 | 高(开发者友好) | 无 | 很大(Node.js) | 仅 Chrome、开发者、快速自动化 |
| Playwright | Chromium、Firefox、WebKit | 非常高(多上下文) | 高(开发者友好) | 无 | 增长迅速 | 高级、多浏览器、现代抓取 |
| Headless Chrome | Chrome/Edge | 非常高 | 低(手动 CDP) | 无 | 不适用(基础引擎) | 自定义、专家级、底层控制 |
| Pyppeteer | Chromium/Chrome | 高 | 中等(异步) | 无 | 较小、已停止维护 | 遗留的 Pyppeteer 脚本 |
| Splash | QtWebKit | 中等 | 中等(API/Lua) | 无 | 小众(Scrapy/Zyte) | Scrapy 用户、轻量级 JS 渲染 |
| PhantomJS | WebKit(旧版) | 低(现已过时) | 中等(JS) | 无 | 已终止 | 仅限遗留 |
| HtmlUnit | 模拟(Java) | 中等/高(静态) | 低(Java) | 无 | 较小、以 Java 为中心 | Java 工作流、简单/静态页面 |
| TrifleJS | Internet Explorer(Trident) | 低/中等 | 中等(JS,Windows) | 无 | 很小众、偏遗留 | 仅 IE 的遗留自动化 |
如何为你的业务选择合适的 Python 无头浏览器
下面是我帮你整理的选型速查表:
- 需要快速、无代码、还带 AI 辅助的抓取? 选 。它是非技术人员获取可靠数据最简单的方式——尤其适合销售、电商或研究团队。
- 想要最大的控制力和跨浏览器支持? 是最佳选择。它强大、现代,而且为规模化而生。
- 你已经在 Selenium 上投入很多? 那就继续用 ——它依然是遗留流程和多浏览器工作流的王者。
- 开发者要做仅限 Chrome 的自动化? (或者 Playwright)都很快、很强。
- 在 Java 环境里抓取简单静态页面? 轻量又容易集成。
- 还在维护遗留脚本或 IE 专用应用? 和 可以作为你的(最后手段)朋友。
别忘了:最好的工具,是最适合你的工作流、团队技能和业务需求的工具。有时候,这意味着混着用——用 Thunderbit 处理快速任务,用 Playwright 扛重活,再用 Selenium 兼顾遗留系统。
常见问题
1. 什么是 python 无头浏览器,为什么抓取时需要它?
python 无头浏览器就是你可以用 Python 代码控制的网页浏览器,但它会在看不见的情况下运行(没有图形界面)。它对抓取现代、重 JavaScript 的网站非常重要,因为它能执行脚本、处理用户交互,并提取完整渲染后的内容——这是传统 HTML 爬虫做不到的。
2. 哪款 python 无头浏览器最适合非技术用户?
是不会写代码的人首选。它用 AI 自动完成设置,提供即时模板,并且只需点几下就能抓取数据——完全不需要编程。
3. 对 Python 用户来说,Playwright 和 Puppeteer 有什么区别?
Playwright 支持多种浏览器(Chromium、Firefox、WebKit),并提供强大的 Python 绑定,非常适合高级自动化。Puppeteer 只支持 Chrome,且原生面向 Node.js,但 Python 用户可以用 Pyppeteer(不过它现在已经停止维护)。对新的 Python 项目来说,Playwright 更好。
4. Selenium 对现代网页抓取还有用吗?
有用——Selenium 仍然被广泛使用,尤其适合跨浏览器测试和遗留自动化。不过,相比 Playwright 或 Thunderbit 这类新工具,它更慢、配置更复杂,而且大规模抓取时效率更低。
5. 什么时候该用 PhantomJS、HtmlUnit 或 TrifleJS 这类遗留工具?
只在维护或迁移旧流程时使用。PhantomJS 和 TrifleJS 已经过时,而 HtmlUnit 更适合 Java 环境中的简单页面。新项目请使用现代、仍在积极维护的工具。
如果你已经准备好看看现代、AI 驱动的抓取是什么样子,。想了解更多网页自动化深度内容,也可以看看 。祝你抓取顺利——愿你的数据始终新鲜,愿你的浏览器永远无头。
了解更多