信息时代,网络数据铺天盖地,但怎么把这些杂乱的信息变成真正有用的商业情报?这其实既是难题,也是机会。作为一个长期深耕 SaaS 和自动化工具的开发者,我亲眼见证了企业决策从“拍脑袋”到“全靠数据”的转变。现在不只是大公司,连小团队都在拼命用网页数据来做销售、市场、定价和产品策略。但网页内容越来越复杂、动态,想高效又合规地拿到干净、可用的数据,难度也直线上升。
接下来我们就来点实操:我会带你了解网站数据提取为什么对现代企业这么关键,实际操作中会遇到哪些坑,以及怎么用最佳实践(包括 Thunderbit 团队的实战经验)做到合法、高效、可扩展。不管你是面对非结构化内容、担心合规,还是想摆脱手动复制粘贴的苦恼,这份指南都能帮你少走弯路。
为什么网站数据提取对现代企业如此重要
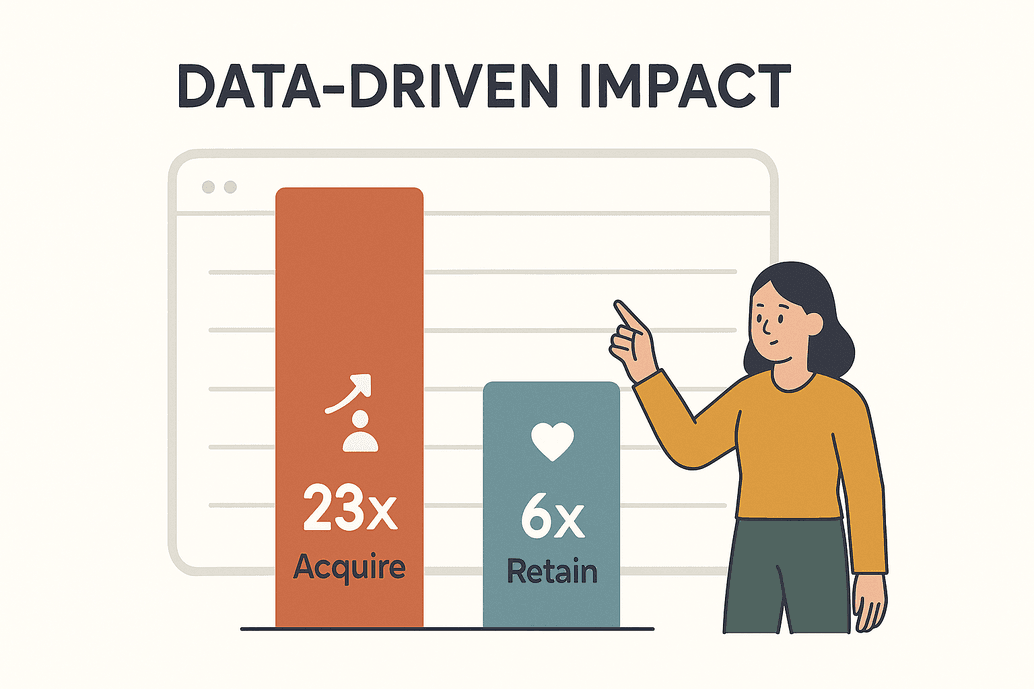 数据早就不是个新鲜词,而是企业竞争的核心动力。根据,以数据驱动的企业获客能力提升 23 倍,客户留存率提升 6 倍。这可不是随便说说,直接关系到企业能不能活下去。到 2025 年,企业每天要抓取数十亿网页,为分析、AI 模型和实时决策提供数据支撑()。
数据早就不是个新鲜词,而是企业竞争的核心动力。根据,以数据驱动的企业获客能力提升 23 倍,客户留存率提升 6 倍。这可不是随便说说,直接关系到企业能不能活下去。到 2025 年,企业每天要抓取数十亿网页,为分析、AI 模型和实时决策提供数据支撑()。
那实际都用在哪?下面这些场景,我几乎每周都能遇到:
| 业务场景 | 描述与优势 | 示例/数据 |
|---|---|---|
| 价格监控 | 实时追踪竞争对手价格、库存和促销,灵活调整自身策略,保持领先。 | 超过 80% 的头部电商每天抓取竞争对手价格(kanhasoft.com)。 |
| 线索挖掘 | 从目录、社交媒体或点评网站抓取新客户线索和联系方式。 | 自动化数据提取让 CRM 填充速度远超人工。 |
| 市场趋势分析 | 汇总评论、论坛和新闻,提前洞察趋势和舆情变化。 | 26% 的数据抓取聚焦社交媒体趋势(blog.apify.com)。 |
| 内容聚合 | 汇集多站点新闻、产品或活动信息,便于统一访问。 | 媒体团队为受众定制内容流。 |
| 产品与研究数据 | 收集产品详情、评论或研究数据,助力分析与开发。 | 67% 的投资顾问使用网页替代数据(scrap.io)。 |
| AI 训练数据 | 批量抓取文本、图片或记录,为 AI 模型提供训练素材。 | 约 70% 的大型 AI 模型依赖网页抓取数据(kanhasoft.com)。 |
如果你还没用上网站数据提取,那基本就是在市场里“隐身”。我见过电商团队光靠自动化价格监控,半年 ROI 就翻了三倍()。结论很直接:网页数据已经是战略资产,谁能高效提取,谁就有竞争资格。
网站数据提取面临的主要挑战
当然,数据提取没那么简单。互联网环境变化快,抓数据时经常遇到这些问题:
- 非结构化数据: 约80% 的在线数据都是非结构化,藏在乱七八糟的 HTML、分散在不同页面,或者埋在交互元素后面。想把这些内容整理成干净表格,真不是件容易事()。
- 网站频繁变动: 网站布局说变就变。我见过爬虫一个月内因为目标站点小改动就崩了 15 次()。
- 数据量与规模: 企业经常要定期抓几百上千个页面,手动复制粘贴根本跟不上。
- 反爬机制: 各种验证码、限流、登录墙……网站的反爬技术越来越聪明。现在三分之一以上的网络流量都是机器人(),反爬手段也在不断升级。
- 人工失误: 手动复制粘贴不仅慢,还容易出错。一个选择器写错,数据全错,甚至啥都抓不到。
传统方法已经很难应对这些挑战,所以越来越多团队都在用智能自动化工具(这也是我看好 AI 网页爬虫的原因)。
网站数据提取的合规与安全最佳实践
先说清楚:能抓数据,不代表你可以随便抓——至少要考虑法律和道德底线。每个企业都要注意:
- 公开数据 vs. 私有数据: 抓取公开信息在很多地区是合法的,但只要是登录后才能看的内容都属于禁区,绕过认证就是违规()。
- 服务条款: 一定要看清楚目标网站的 ToS(服务条款)。如果明确禁止抓取,强行操作可能被封号甚至被起诉。有疑问就申请授权或者用官方 API。
- 隐私法规(GDPR、CCPA): 涉及个人数据时,必须有合法理由(比如合法利益),能不采集就不采集,采集了也要能随时删除。违规可能会被罚得很惨()。
- 遵守 robots.txt: 虽然不是法律强制,但遵守 robots.txt 是基本礼仪。要尊重爬取频率,别给服务器添堵。
- 数据安全: 抓到的数据要当敏感信息处理,妥善存储、限制访问,用前要清洗。
合规检查清单:
| 注意事项 | 最佳实践 |
|---|---|
| 合法访问 | 仅抓取公开数据,绝不绕过登录(xbyte.io)。 |
| 服务条款 | 仔细阅读并遵守网站 ToS,若禁止抓取请用 API。 |
| 个人数据 | 能不采集就不采集,必要时要最小化并严格遵守 GDPR/CCPA。 |
| robots.txt & 爬取频率 | 遵守网站规则,合理控制请求频率。 |
| 数据安全 | 加密存储、限制访问、用完即删。 |
AI 如何提升网站数据提取效率
AI 的出现,直接把网页数据提取的玩法彻底颠覆了。再也不用手动写选择器、维护脆弱脚本,AI 网页爬虫能“看懂”页面结构,自动识别要提取的内容,基本就是点点鼠标的事。
实际体验怎么样?
- 极简设置: 像 这样的 AI 网页爬虫能自动识别字段。只要点下“AI 智能识别”,系统就会推荐合适的列,无需写代码、也不用反复试错。
- 自适应能力: AI 能识别页面模式,不死板依赖布局。网站改版也能自动适应,维护成本大大降低。
- 高准确率: AI 能自动去除无关内容、去重、清洗杂乱数据。有团队反馈,AI 网页爬虫准确率高达 99.5%()。
- 动态内容支持: AI 网页爬虫能处理 JavaScript 动态加载、无限滚动,甚至能从图片或 PDF 里提取文本。
- 实时处理: 需要边抓边翻译、分类或摘要?AI 一步到位。
 我见过团队用 AI 网页爬虫,数据提取时间直接省了 30–40%()。这不仅是效率提升,更是竞争力提升。
我见过团队用 AI 网页爬虫,数据提取时间直接省了 30–40%()。这不仅是效率提升,更是竞争力提升。
Thunderbit 的目标就是让数据提取变得简单、精准、人人都能用——哪怕你不会写代码。(我妈都能用,虽然她还在研究 Netflix 怎么看。)
Thunderbit AI 网页爬虫:为企业用户量身打造的核心功能
必须自豪地介绍下 Thunderbit 的亮点(毕竟是我们团队的心血)。Thunderbit 专为企业用户设计——无论你是做销售、运营、市场还是房产,都能轻松上手,专注结果,不用折腾。核心优势包括:
- AI 智能识别字段: 一键扫描页面,AI 自动推荐字段并配置爬虫,无需手动设置选择器。
- 两步抓取: 字段设置好后,只需点击“抓取”,就能拿到干净表格,无需写代码。
- 子页面抓取: 需要更详细信息?Thunderbit 能自动访问每个子页面(比如产品页、个人资料页),补充更多数据。
- 内置模板: 针对热门网站(如亚马逊、Zillow、Instagram、Shopify 等)直接选模板,无需配置。
- 多平台导出: 免费导出到 Excel、Google Sheets、Airtable、Notion 或 CSV,无隐藏费用。
- 定时爬取: 支持自动定时抓取,只需描述时间间隔(比如“每周一早上 8 点”),剩下的交给 Thunderbit。
- 云端/本地双模式: 可用云服务器高速抓取,也可用本地浏览器处理需登录的网站。
- 多语言支持: 支持 34 种语言抓取,包括英语、西班牙语、中文等。
自动化与扩展:用定时与集成工具提升数据提取效率
手动抓数据早就过时了。真正的价值在于把数据提取自动化,并无缝集成到你的业务流程里:
- 定时爬取: 设置 Thunderbit 按天、周或自定义频率自动抓取,适合价格监控、线索挖掘或新闻聚合。
- 直接集成: 抓取结果可直接导出到 Google Sheets、Excel、Airtable 或 Notion,无需手动下载上传。
- CRM & 分析集成: 数据可自动流入 CRM 或 BI 工具,实现实时看板、预警或自动化跟进。
举个例子:自动化价格监控流程
- 在竞争对手产品页配置 Thunderbit。
- 用“AI 智能识别”提取产品名、价格和链接。
- 设定每天早上 7 点自动抓取。
- 结果导出到 Google Sheets,并连接到数据看板。
- 定价经理第一时间查看变化,及时调整策略。
自动化让你不仅更快,还能保证数据始终是最新的。
处理非结构化数据的最佳实践
现实中,大多数网页数据都不规整,格式混乱甚至五花八门。怎么让它变得有用?
- 提前规划结构: 利用 AI 字段建议或模板,先确定好需要哪些列和数据类型。
- 字段 AI 提示词: Thunderbit 支持为每个字段添加自定义指令。比如产品分类、电话格式化、描述翻译等,只要告诉 AI 你的需求就行。
- NLP 技术加持: 针对评论、文章等文本内容,可用内置 NLP 功能自动摘要、情感分析或提取关键词。
- 数据规范化: 抓取时就统一格式(比如日期、价格、电话),而不是事后再整理。
- 去重与校验: 自动去除重复,抽查结果准确性。如果有异常,及时调整提示词或设置。
字段 AI 提示词:让数据提取更智能
这是我最喜欢的功能之一。通过字段级 AI 提示词,你可以:
- 自动分类: “根据描述将产品归类为电子、家具或服饰。”
- 格式规范: “日期输出为 YYYY-MM-DD 格式。” “只提取数字价格。”
- 实时翻译: “将产品描述翻译为英文。”
- 去除杂项: “只提取用户简介,忽略‘查看更多’或广告。”
- 字段合并: “将地址多行合并为一个字段。”
就像给你的爬虫配了个永远不喊累的小助手。
如何保证网站数据提取的质量与一致性
高质量的数据提取绝不是点下“导出”就完事。想让数据靠谱,建议:
- 校验机制: 设置数值范围、必填项、唯一键等,及时发现错误。
- 抽样审核: 定期人工抽查抓取结果,尤其是初次配置或网站变动后。
- 错误处理: 记录失败抓取,设置异常预警(比如行数突然变少)。
- 持续清洗: 用表格工具或脚本去除多余空格、修正编码、统一文本格式。
- 结构一致性: 字段名称和格式要长期保持一致,变更要有文档记录,方便团队协作。
数据的可信度很关键,前期多花点心思,后面省无数麻烦。
工具对比:选择网页数据提取方案时要关注什么
市面上的网页爬虫工具五花八门,选的时候要看哪些点?
| 工具 | 优势 | 注意事项 |
|---|---|---|
| Thunderbit | 非技术用户最友好;AI 字段识别;支持子页面抓取;内置模板;免费导出;价格实惠(Thunderbit Blog)。 | 不适合超大规模、开发者主导项目;采用积分制。 |
| Browse AI | 无需编程,适合监控变动;可集成 Google Sheets;支持批量抓取。 | 起步价较高,配置流程较繁琐。 |
| Octoparse | 功能强大,支持动态网站;适合技术用户。 | 学习曲线陡峭,价格较高。 |
| Web Scraper (webscraper.io) | 小型项目免费,图形化配置,社区活跃。 | 手动配置易混淆,AI 辅助有限。 |
| Diffbot | AI 驱动,API 解析非结构化页面,开发者友好。 | 价格昂贵,API 为主,不适合非技术用户。 |
我的建议: 如果你追求高效、准确, 很适合企业用户。开发者或高级用户可以试试 Octoparse 或 Diffbot。不管选哪个,建议先用免费版或试用期体验下。
总结:将网站数据提取最佳实践落地
网站数据提取早已不是“可有可无”,而是每个想保持竞争力企业的必备能力。记住这些要点:
- 价值驱动: 网页数据让决策更快更准,别让它白白浪费。
- 突破难题: 用 AI 工具搞定非结构化、海量和网站变动等难题。
- 合规为先: 尊重隐私法规、网站规则和数据安全。
- 自动化集成: 把数据提取融入日常流程,定时自动化。
- 质量优先: 持续校验、清洗和监控,确保数据靠谱。
想体验高效、便捷的数据提取?,开启你的下一个数据项目。想深入学习,欢迎访问 ,获取更多实用指南和案例。
祝你抓取顺利,数据合规、结构清晰、随时可用!
常见问题解答
1. 从任何网站提取数据合法吗?
一般来说,抓取公开数据在很多地区是合法的,但绝不能绕过登录或安全措施。一定要查目标网站的服务条款,并遵守 GDPR、CCPA 等隐私法规()。
2. AI 如何提升网站数据提取效率?
像 这样的 AI 工具能自动识别字段,适应页面变动,自动清洗和格式化数据,还能支持动态内容和翻译,设置简单,准确率高()。
3. 处理非结构化数据有哪些最佳实践?
提前规划数据结构,利用字段级 AI 提示词引导提取,抓取时规范格式,并及时校验结果。Thunderbit 等工具让分类、格式化、标签化数据变得轻松。
4. 如何实现网站数据提取的自动化与扩展?
用定时功能定期自动抓取,并把结果直接集成到 Google Sheets、Airtable 或 CRM 等工具。自动化让数据始终保持新鲜,减少人工操作。
5. 如何保证提取数据的质量与一致性?
设置校验机制,定期抽查样本,妥善处理错误,保持字段结构一致。持续优化和监控是数据可信的关键。
想亲自体验这些最佳实践?,感受高效、合规、可扩展的数据提取。
延伸阅读