

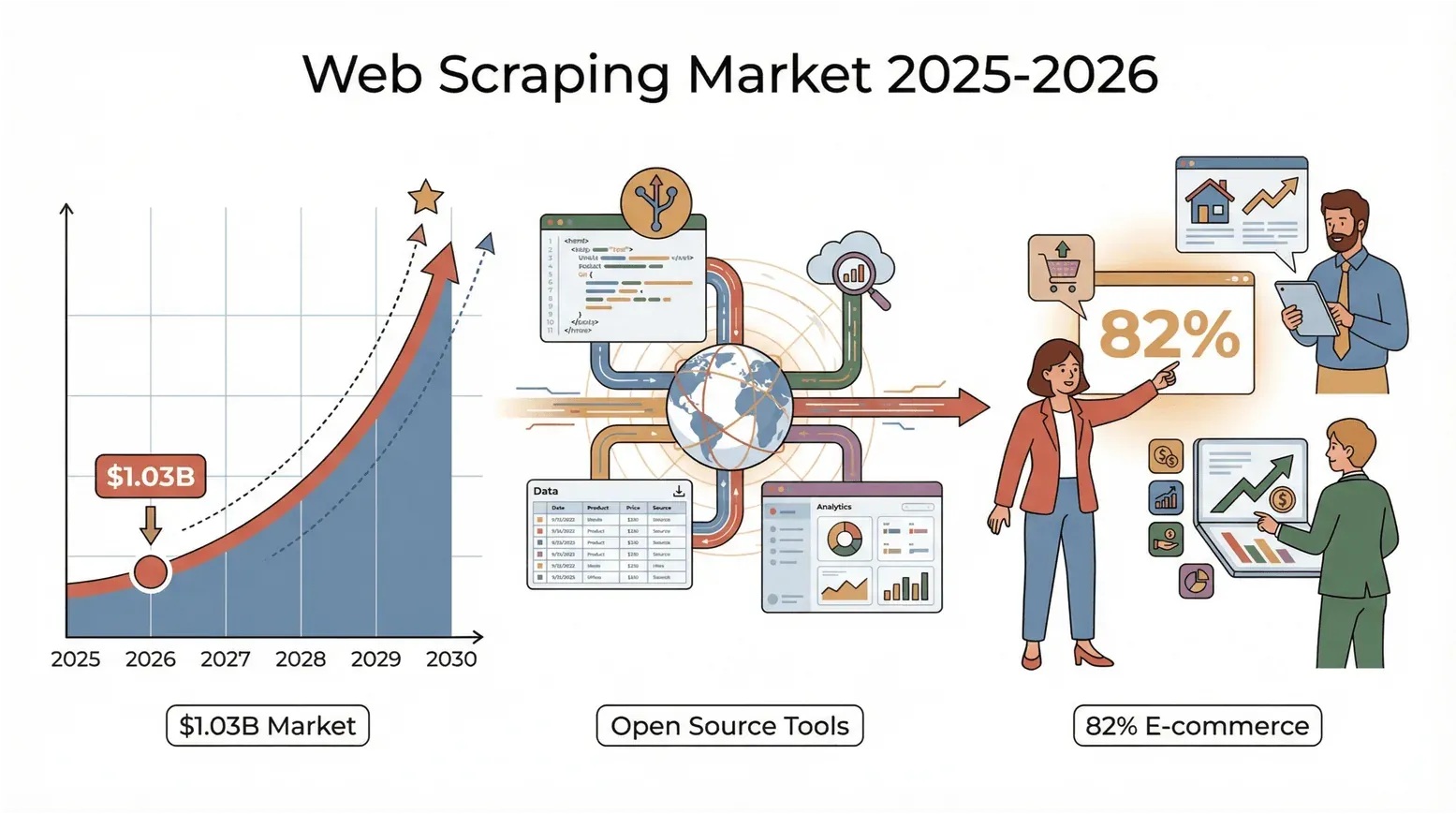
网络里到处都是数据,而到了 2026 年,把这些零散信息变成洞察的竞争,比以前更激烈。无论你做销售、电商、房地产,还是像我一样只是个数据控,你大概率都已经发现,过去那套“复制粘贴”的老办法早就不够用了。先看一个夸张但真实的数字:根据 Mordor Intelligence(并被 PromptCloud 的《2026 年网页爬虫现状报告》 引用),全球网页爬虫市场在 2025 年达到 10.3 亿美元,并预计到 2030 年左右翻一番。
而且,这不只是科技巨头在做——82% 的电商公司和超过三分之一的投资机构都在抓取网页,用来找线索、看价格和做市场研究(Browsercat)。说白了:如果你还没用网页爬虫工具,可能就是在把钱和洞察白白留在桌面上。
好消息是:开源网页爬虫工具比以前更强大、更容易上手,也更有社区活力。不管你是 Python 高手、JavaScript 发烧友,还是只想轻松拿到数据的业务用户,总有一款工具适合你。我在 SaaS 和自动化领域工作了很多年,也一直看着这个生态不断演进。所以,接下来我们就来看看 2026 年你值得关注的 5 款最佳开源网页爬虫工具,以及如何根据自己的需求做选择。
为什么选择开源网页爬虫工具?
2026 年什么是数据爬取,以及如何操作 Get Started Free
开源网页爬虫工具就像数据世界里的瑞士军刀。它们成本更低(没有授权费)、灵活性更强(几乎都能自定义)、透明度更高(你能清楚看到它是怎么工作的)。但真正厉害的地方在于社区。开源工具背后有成千上万的开发者和用户,会分享插件、教程和修复方案,所以你不会孤军奋战(Oreate AI)。
和商业工具相比,开源方案让你真正掌握主动权。你不会被供应商的路线图或定价绑住,而且当网站结构变化时,你也能随时调整自己的爬虫。更何况,很多商业爬取服务本身其实也是建立在这些开源引擎之上的——那为什么不直接用源头方案呢?
我们是如何筛选最佳开源网页爬虫工具的
市面上的选择太多了,所以我主要看了几个关键标准:
- 易用性: 非程序员能不能快速上手?有没有可视化或 AI 驱动的方案?
- 可扩展性: 这个工具能处理大型项目,还是只能做一次性任务?
- 语言和平台支持: Python、JavaScript、浏览器端、桌面端——是否覆盖不同技术栈。
- 社区和维护: 这个工具是否持续更新?有没有论坛、文档和插件?
- 独特功能: AI 字段识别、子页面抓取、定时任务、云端支持等等。
我也参考了真实用户反馈和业务使用场景——因为最好的工具,永远是那个真正能解决你问题的工具。
值得探索的 5 款最佳开源网页爬虫工具
下面进入重点。从 AI 驱动的简单方案,到面向开发者的强力工具,这份清单都是我精心挑选出来的。
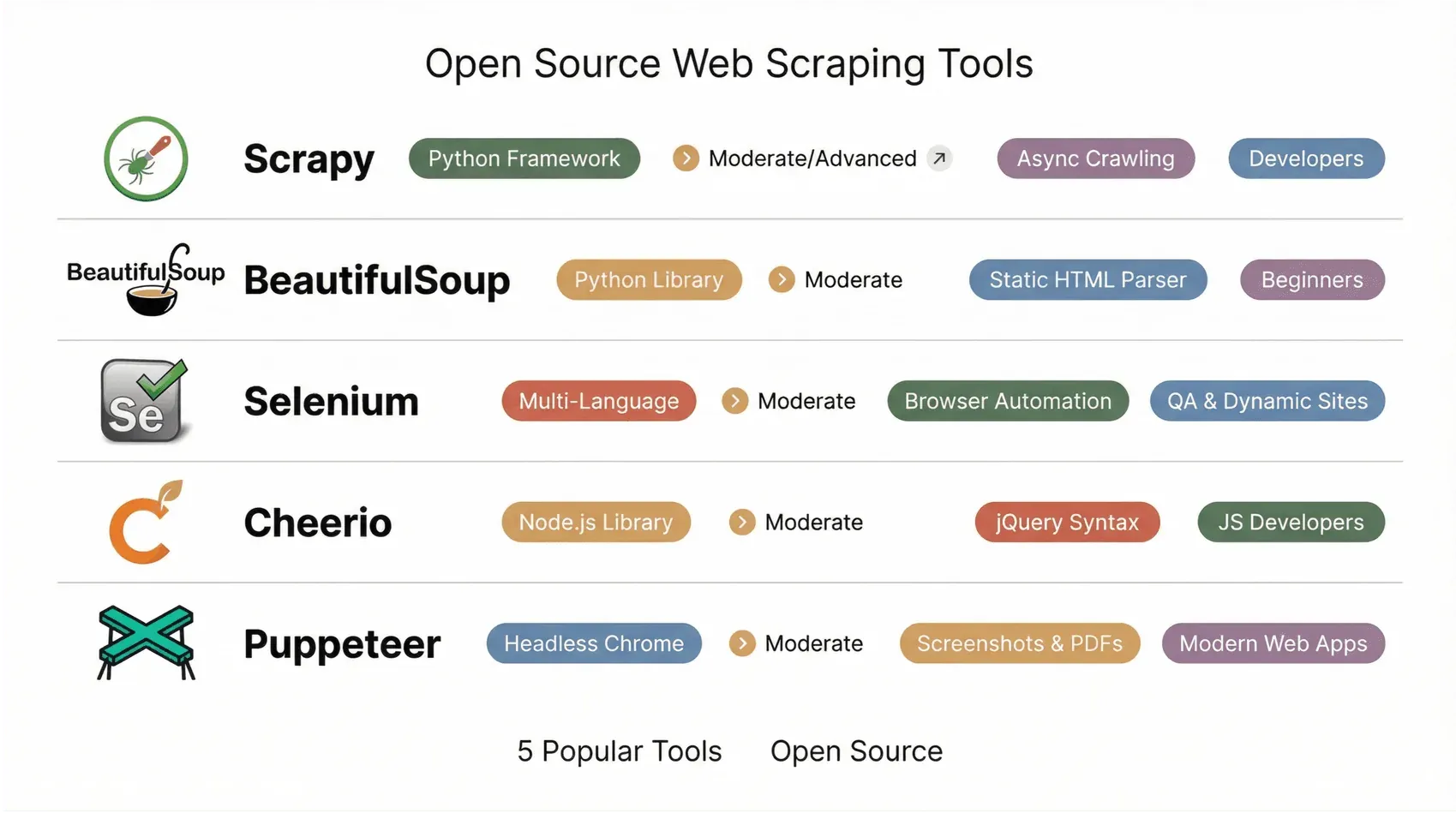
1. Scrapy
Scrapy 是 Python 开发者的梦想工具。它是经过实战验证的框架,适合构建可扩展、可定制的爬虫和数据管道。你可以用 Python 定义“spiders”,然后由 Scrapy 负责排队、限速,并导出为 JSON、CSV 或 XML。截至 2.14 版本(2025 年 10 月)和 2.14.1 补丁(2026 年 1 月),Scrapy 很大一部分基于 Twisted-Deferred 的内部实现已经重写为原生 asyncio 协程,并新增了 AsyncCrawlerProcess 入口,与现代 Python 异步生态更好地协同;而且新创建项目现在默认使用 asyncio reactor。提醒一下:Scrapy 2.14 及以上版本需要 Python 3.10 或更高。
它的插件生态非常庞大,支持代理、Cookie,甚至还能通过无头浏览器集成处理动态网站。对于抓取整套电商目录或大规模聚合新闻,Scrapy 往往是很多团队的首选。它对非程序员来说学习曲线较陡,但如果你追求强大和灵活,Scrapy 绝对不虚(Octoparse)。
2. Beautiful Soup
Beautiful Soup 是经典的 Python 库,适合快速、直接地解析 HTML。它因学习曲线平缓、解析器宽容而深受初学者和专业人士喜爱(即使是很乱的 HTML,它也能处理)。你先抓取页面内容(通常配合 requests),再交给 Beautiful Soup,然后用简单的方法查找并提取元素。
它非常适合小项目、原型开发和教学用途。缺点也很明确:Beautiful Soup 不能执行 JavaScript,所以只能处理静态 HTML。对于动态网站,你需要把它和 Selenium 或 requests_html 之类的工具配合使用(ProsperaSoft)。
3. Selenium
Selenium 是浏览器自动化的老牌工具。它最初用于测试,如今已经成为抓取动态、JavaScript 密集型网站的热门选择。Selenium 会启动真实浏览器(Chrome、Firefox 等),并模拟用户操作——点击、滚动、登录,等等。只要人能看见的内容,Selenium 基本都能抓。
它支持多种语言(Python、Java、JS、C#),非常适合抓取登录后的内容或交互式流程。Selenium 4 也在持续集成 WebDriver BiDi,这是一种双向协议,能让你的脚本订阅浏览器事件(网络请求、控制台日志、DOM 变化)并拦截网络调用——这类能力过去往往让 Puppeteer 或 Playwright 成为更轻松的抓取选择。4.40 版本(2026 年 1 月)和 4.41 版本(2026 年 2 月)进一步扩展了 Python、Java、.NET 和 Ruby 绑定中的 BiDi 支持。缺点依然存在:Selenium 比纯 HTTP 爬虫更慢、更重,而且管理浏览器驱动仍然很麻烦。但对于棘手网站——以及已经把 Selenium 作为测试自动化标准的团队——它在 2026 年仍然是一个靠谱的抓取选项(ScrapeHero)。
4. Cheerio
Cheerio 可以说是 Node.js 世界里的 jQuery。它让你能用熟悉的、类似 jQuery 的语法在服务器端解析 HTML。它速度飞快,非常适合静态页面——你只要先获取 HTML(用 Axios 或 Fetch),再加载进 Cheerio,然后用选择器提取你需要的内容。
Cheerio 不执行 JavaScript,所以它最适合静态内容。不过它和其他 Node.js 工具配合得非常好,而且很受想全程使用 JavaScript 的开发者欢迎(Cheerio Docs)。
5. Puppeteer
Puppeteer 是一个用于以无头模式控制 Chrome 或 Chromium 的 Node.js 库。它很受欢迎,适合抓取现代网页应用和单页应用,因为它们需要真实浏览器渲染:截图、生成 PDF、拦截网络请求,这些都可以通过干净的 async/await API 完成。Google 的 Chrome 团队至今仍在维护 Puppeteer,并让它与每个新的 Chrome 版本和 DevTools Protocol 更新保持同步。
到了 2026 年,有一点背景值得了解:Puppeteer 的发布节奏已经收窄,更多是在做 Chrome 兼容性和依赖更新,而不是加入新能力;而最早打造 Puppeteer 最雄心勃勃功能的那支团队,后来在 Microsoft 创建了 Playwright。如果你已经深度使用 Puppeteer,而且只需要 Chrome 自动化,它依然是一个稳定的选择。如果你从零开始,并且想要跨浏览器支持、内置测试运行器、自动等待定位器和 trace 查看器,那么到了 2026 年,大多数团队会先推荐 Playwright(Firecrawl — Playwright vs Puppeteer,Autonoma — Playwright vs Puppeteer 2026)。
开源网页爬虫工具快速对比表
| 工具 | 易用性 | 平台/语言 | 动态内容 | 适合场景 | 独特优势 |
|---|---|---|---|---|---|
| Scrapy | 中等/高级(代码) | Python 框架 | 部分支持 | 开发者、数据科学家 | 异步爬取、插件丰富、社区庞大 |
| BeautifulSoup | 中等(简单代码) | Python 库 | 不支持 | 初学者、快速解析 | 解析器宽容,特别适合静态 HTML |
| Selenium | 中等(脚本) | 多语言 | 支持 | 测试、动态网站抓取 | 真实浏览器自动化,可处理登录和用户事件 |
| Cheerio | 中等(JS 代码) | Node.js 库 | 不支持 | JS 开发者、静态页面 | 类 jQuery 语法,HTML 解析速度快 |
| Puppeteer | 中等(JS 代码) | Node.js(无头 Chrome) | 支持 | 开发者、现代网页应用 | 截图、PDF、单页应用抓取、async/await API |
如何根据需求选择合适的开源网页爬虫工具
如何使用 AI 抓取任何网站 Get Started Free
下面这份速查表可以帮助你选对工具:
- 技术能力: 不会写代码?从 Thunderbit、Octoparse、ParseHub 或 WebHarvy 开始。是开发者?Scrapy、Cheerio、Puppeteer 或 Apify 更适合你。
- 项目规模: 一次性或小任务?Beautiful Soup、Cheerio、WebHarvy。大规模或持续任务?Scrapy、Apify、Thunderbit(支持定时)。
- 数据类型: 静态 HTML?用 Cheerio、Beautiful Soup 或 WebHarvy。动态 / JS 密集型?Puppeteer、Selenium、Thunderbit、Octoparse。
- 集成需求: 需要导出到 Sheets、Notion 或数据库?Thunderbit 和 Octoparse 很方便。需要 API 或自定义数据管道?Scrapy 和 Apify 会是好帮手。
- 社区与支持: 看看是否有活跃论坛、近期更新和大量教程。Scrapy、Cheerio 和 Selenium 的社区都非常大;Thunderbit 和 Octoparse 的用户群也在快速增长,而且资料不少。
不妨先拿一个小项目试试两三款工具,看看哪个更符合你的工作流和使用习惯。也别害怕混搭使用:有时候最快的方案,是先用可视化工具快速抓一遍,再用代码框架做更深入的爬取。
开源爬取中的社区价值与持续支持
开源最重要的优势之一就是社区。活跃论坛、GitHub 仓库和 Stack Overflow 标签意味着你永远不会是一个人在战斗。遇到问题时,通常不是已经有人解决过,就是有人愿意帮你。社区驱动的工具会更频繁地更新,也会不断加入新功能;你还能找到大量教程、插件和最佳实践(Oreate AI)。
因此,对于 Thunderbit 和 Octoparse 这类可视化工具来说,用户论坛和模板分享就是一座金矿。对于开发者工具来说,GitHub issue 和 Discord / Slack 群组才是真正发生“魔法”的地方。当你选择一个开源工具时,其实就是加入了一个全球化的问题解决者网络——这非常宝贵。
Thunderbit:人人都能用的更轻松、无需编码的网页爬取方案
没错,开源很好——但有时候你并不想为了拿到可用数据,还要自己搭建、调优和长期维护一个爬虫。也不是每个抓取问题都能靠开源代码解决,而这正是 Thunderbit 非常适合的地方。如果你读到这里,心里想的是“这些工具都很强,但我只是想要数据,不想自己建爬虫或维护它”,那 Thunderbit 就是很自然的下一步。
Thunderbit 是一款基于 AI 的 Chrome 扩展,专为更关注结果而不是基础设施的业务用户设计。你不需要写选择器或脚本,而是先点击 AI Suggest Fields。AI 会理解页面结构,自动建议列,然后你只需要第二次点击就能完成抓取。分页、子页面和列表-详情页流程都会帮你处理好。
Thunderbit 最大的优势之一,是它把人的意图和结构化数据连接了起来。你可以直接用自然语言描述想要什么,比如“收集产品名称、价格和评分”,Thunderbit 就会把它转换成干净的表格。子页面抓取还能自动访问详情页,提取更丰富的数据。它内置导出到 Excel、Google Sheets、Notion 和 Airtable 的功能,所以数据可以立刻投入使用。
Thunderbit 尤其受销售、市场、电商和房地产团队欢迎,因为这些团队需要稳定的数据,但并不想维护开源数据管道。它支持几十种语言,在动态网站上表现也很好,而且提供了相当不错的免费额度供你上手。虽然它不是开源的,但它和开源工具可以很好地互补——你可以把它看作是在没有工程负担的情况下,最快验证想法或处理重复业务爬取的方式。
结论:用最佳开源工具释放网页数据价值
网页爬取早就不只是程序员或大公司的专利了。有了今天的开源工具,任何人都能把网页变成结构化、可执行的数据——无论你是在构建潜在客户列表、监控价格,还是为下一个 AI 项目提供燃料。关键在于把工具和需求匹配起来:追求速度和简洁时,用 AI 驱动和可视化工具;追求能力和规模时,用代码框架。
那么下一步是什么?从这份清单里挑一款工具,拿一个真实任务试试,看看你能省下多少时间和精力。如果你想快速见效,直接 下载 Thunderbit 试试,就会发现网页爬取其实可以这么简单。网络就是你的牡蛎,去把那些数据珍珠捞起来吧。
想看更深入的内容和教程,可以访问 Thunderbit 博客。祝你抓取顺利!
免费试用 Thunderbit AI 网页爬虫 Get Started Free
常见问题
1. 与商业工具相比,开源网页爬虫工具的主要优势是什么?
开源工具成本更低、更灵活,而且有活跃社区支持。你可以自由定制,避免被供应商锁定,还能享受到共享知识和频繁更新的好处。
2. 哪款开源工具最适合非技术型业务用户?
Thunderbit、Octoparse、ParseHub 和 WebHarvy 都非常适合非程序员。Thunderbit 的 AI 驱动、两步式工作流和直接导出功能尤其突出。
3. 开源工具能处理动态、JavaScript 很重的网站吗?
可以!Thunderbit、Selenium、Puppeteer、Octoparse 和 ParseHub 都能通过真实浏览器或无头浏览器渲染页面来抓取动态内容。
4. 我怎么判断一个工具是否仍在积极维护和支持?
去 GitHub 看最近的提交、未解决问题和贡献者活跃度。还可以看看是否有活跃论坛、近期博客文章,以及大量用户贡献的插件或模板。
5. 如果我是新手,开始网页爬取的最佳方式是什么?
先从 Thunderbit 或 Octoparse 这类可视化或 AI 工具开始。先尝试抓取一小份数据,导出到 Excel 或 Sheets 里练手。等你更熟悉后,再去探索基于代码的工具,处理更高级的项目。
想亲眼看看 Thunderbit 怎么用?下载 Chrome 扩展 ,加入 3 万多名把网页变成数据的用户——无需写代码。
了解更多




