

该用哪种编程语言做网页爬取?这得看你的项目类型——我见过不少开发者,因为选错语言,最后直接崩溃收工。
网页爬取软件市场在 2024 年达到 10.1 亿美元,预计到 2032 年将增长一倍多。选对语言,意味着更快出结果、维护更省心;选错了,就只会得到一堆坏掉的爬虫和被浪费的周末。
我做自动化工具已经很多年了。下面是我用过的七种爬取语言——包含代码示例、真实优缺点,以及哪些情况下你应该干脆别写代码,直接用 Thunderbit。
我们如何选出最适合网页爬取的语言
说到网页爬取,不是所有编程语言都生而平等。我见过一些项目因为几个关键因素一路起飞,也见过因为同样的原因直接翻车:
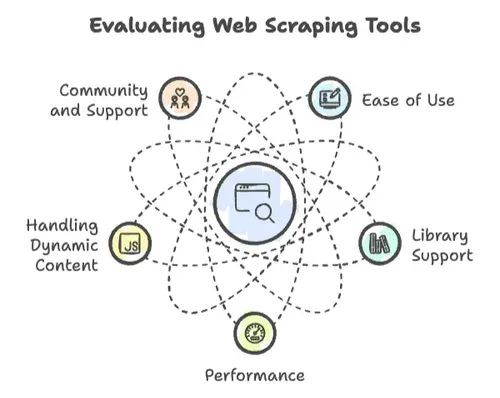
- 易用性: 上手速度有多快?语法够不够友好,还是你得先拿个计算机博士学位,才能打印一句“Hello, World”?
- 库支持: 有没有成熟的 HTTP 请求、HTML 解析、动态内容处理库?还是只能自己从头造轮子?
- 性能: 能不能处理几百万个页面,还是几百个就开始吃力?
- 动态内容处理: 现代网站都爱 JavaScript。你的语言跟得上吗?
- 社区和支持: 遇到卡点时——而且你一定会遇到——有没有人能帮你?
基于这些标准,再加上无数个熬夜测试,我会讲到下面这七种语言:
- Python:新手和老手都最常用的选择。
- JavaScript & Node.js:动态内容之王。
- Ruby:语法简洁,脚本上手快。
- PHP:服务器端简单直接。
- C++:追求极致速度时的选择。
- Java:适合企业级,扩展性强。
- Go(Golang):快,而且并发能力强。
如果你心里正在想:“帅,我其实根本不想写代码”,那就先别走,最后我会讲到 Thunderbit。
Python 网页爬取:最适合新手的强力选择
先从大家最喜欢的开始:Python。如果你在一屋子数据人面前问:“哪种编程语言最适合网页爬取?”——你会听到 Python 像泰勒·斯威夫特演唱会的万人合唱一样回响。
为什么选 Python?
- 语法对新手友好: 你大声读 Python 代码,几乎就像在读英文。
- 无可匹敌的库支持: 从用来解析 HTML 的 BeautifulSoup,到用于大规模抓取的 Scrapy,再到 HTTP 请求的 Requests,以及浏览器自动化的 Selenium——Python 一应俱全。
- 庞大的社区: 仅网页爬取相关的 Stack Overflow 问题就有 33,000+ 条。
Python 示例代码:抓取页面标题
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Page title: {title}")
优点:
- 开发和原型验证速度快。
- 教程和问答资源极多。
- 很适合做数据分析——用 Python 抓取,再用 pandas 分析,用 matplotlib 可视化。
- 库也在持续进化:Scrapy 的 2.14 版本(2026 年 1 月)为整个框架带来了原生
async/await,所以异步不再只是 Selenium/Playwright 的专利。
局限:
- 和编译型语言相比,大规模任务会慢一些。
- 处理超动态网站时可能有点笨重(不过 Selenium 和 Playwright 能帮上忙)。
- 不太适合以闪电般速度抓取数百万页面。
结论:
如果你刚接触爬取,或者只是想快速把事情做完,Python 就是网页爬取的最佳语言——没有之一。更多关于为什么 Python 主导网页爬取的原因。
JavaScript & Node.js:轻松爬取动态网站
如果说 Python 是瑞士军刀,JavaScript(和 Node.js) 就是电钻——尤其适合爬取现代、JavaScript 密集型网站。
为什么选 JavaScript/Node.js?
- 对动态内容原生友好: 它在浏览器里运行,所以能看到用户看到的内容——即使页面是用 React、Angular 或 Vue 构建的。
- 默认支持异步: Node.js 可以同时处理成百上千个请求。
- 网页开发者上手快: 如果你做过网站,你其实已经会一些 JavaScript 了。
核心库:
- Playwright:支持多浏览器(Chromium、Firefox、WebKit),带自动等待和按上下文配置代理。2026 年如果你要新建一个 Node 爬虫,这基本就是默认首选。
- Puppeteer:通过 Chrome DevTools Protocol 控制无头 Chrome。对于只做 Chrome 的任务,以及想减少依赖的场景,它依然很稳。
- Cheerio:如果你不需要真实浏览器,Node 里可以用它进行类似 jQuery 的 HTML 解析。
Node.js 示例代码:用 Puppeteer 抓取页面标题
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Page title: ${title}`);
await browser.close();
})();
优点:
- 原生处理 JavaScript 渲染内容。
- 非常适合无限滚动、弹窗和交互式网站。
- 适合大规模并发爬取,效率高。
局限:
- 异步编程对新手来说可能有点绕。
- 如果同时跑太多无头浏览器,内存吃得很快。
- 和 Python 相比,数据分析工具少一些。
什么时候 JavaScript/Node.js 是网页爬取的最佳编程语言?
当你的目标网站是动态的,或者你想自动化浏览器操作时。更多关于 Node.js 处理动态内容爬取的说明。
Ruby:适合快速网页爬取脚本的简洁语法
Ruby 不只是给 Rails 应用和优雅代码诗歌用的。它也是网页爬取的不错选择——尤其是当你喜欢代码读起来像俳句一样顺的时候。
为什么选 Ruby?
- 可读性强,表达力好: 你可以写出几乎和购物清单一样容易读懂的 Ruby 爬虫。
- 很适合快速原型: 写得快,也容易调整。
- 核心库: 用于解析的 Nokogiri,以及用于自动导航的 Mechanize。
Ruby 示例代码:抓取页面标题
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Page title: #{title}"
优点:
- 极其简洁、易读。
- 很适合小项目、一次性脚本,或者你本来就常用 Ruby 的情况。
局限:
- 做大任务时,比 Python 或 Node.js 慢。
- 爬取相关库更少,社区支持也弱一些。
- 不太适合爬取 JavaScript 很重的网站(不过可以用 Watir 或 Selenium)。
最适合的场景:
如果你本来就是 Ruby 开发者,或者只想快速写个脚本,Ruby 很舒服。要是追求大规模、动态爬取,就换别的语言吧。
PHP:服务器端网页数据提取的简单方案
PHP 可能看起来像早期互联网时代的“老古董”,但它依然活跃——尤其是当你想直接在服务器上抓数据时。
为什么选 PHP?
- 到处都能跑: 大多数 Web 服务器都已经装了 PHP。
- 很容易和 Web 应用集成: 一次性完成抓取和展示。
- 核心库: HTTP 用 cURL,请求用 Guzzle,无头浏览器自动化用 Symfony Panther。
PHP 示例代码:抓取页面标题
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Page title: $title\n";
?>
优点:
- 很容易部署到 Web 服务器上。
- 适合作为 Web 工作流的一部分来抓数据。
- 处理简单的服务器端爬取任务时速度不错。
局限:
- 高级爬取的库支持有限。
- 不适合高并发或大规模抓取。
- 处理 JavaScript 很重的网站比较麻烦(不过 Panther 能帮一点忙)。
最适合的场景:
如果你的技术栈本来就是 PHP,或者你想在自己的网站上直接抓取并展示数据,PHP 是个实用选择。更多关于 PHP 和 Python 爬取对比的内容。
C++:面向大规模项目的高性能网页爬取
C++ 就像编程语言里的肌肉车。如果你需要原始速度和控制力,而且不怕多动点手工活,C++ 可以带你跑得很远。
为什么选 C++?
C++ 示例代码:抓取页面标题
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Page title: " << title << std::endl;
} else {
std::cout << "Title tag not found" << std::endl;
}
return 0;
}
优点:
- 在超大规模爬取任务中,速度无可匹敌。
- 很适合把爬取能力集成到高性能系统里。
局限:
- 学习曲线陡峭(咖啡请备好)。
- 需要手动管理内存。
- 高层次库较少;不太适合动态内容。
最适合的场景:
当你需要抓取数百万页面,或者性能是绝对关键因素时。否则,你可能会把更多时间花在调试上,而不是爬取上。
Java:面向企业级的网页爬取方案
Java 是企业世界里的主力工具。如果你要构建一个需要长期运行、处理海量数据、还能在僵尸末日里幸存下来的系统,Java 就是你的朋友。
为什么选 Java?
- 稳健且可扩展: 适合大型、长周期的爬取项目。
- 强类型和错误处理: 生产环境里的意外更少。
- 核心库: 解析用 Jsoup,浏览器自动化用 Selenium WebDriver,HTTP 用 Apache HttpClient。
Java 示例代码:抓取页面标题
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Page title: " + title);
}
}
优点:
- 性能高,并发能力强。
- 非常适合大型、可维护的代码库。
- 对动态内容支持不错(通过 Selenium 或 HtmlUnit)。
局限:
- 语法比较啰嗦;比脚本语言需要更多准备工作。
- 对于小型一次性脚本来说,有点大材小用。
最适合的场景:
企业级爬取,或者你需要极高的稳定性和扩展性时。
Go(Golang):快速且并发友好的网页爬取
Go 是编程界的新秀,但已经开始大放异彩——尤其适合高速、并发爬取。
为什么选 Go?
Go 示例代码:抓取页面标题
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page title:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Error:", err)
}
}
优点:
- 对大规模爬取来说,速度极快、效率很高。
- 部署很简单(一个二进制文件就够)。
- 很适合并发抓取。
局限:
- 社区规模比 Python 或 Node.js 小。
- 高层次爬取库较少。
- 处理 JavaScript 很重的网站需要额外配置(Chromedp 或 Selenium)。
最适合的场景:
当你需要大规模抓取,或者 Python 的速度已经不够时。Go 和 Python 爬取性能对比。
对比最适合网页爬取的编程语言
把前面的内容放在一起看。下面这张对比表可以帮你在 2026 年选出最适合网页爬取的语言:
| 语言/工具 | 易用性 | 性能 | 库支持 | 动态内容处理 | 最佳使用场景 |
|---|---|---|---|---|---|
| Python | 很高 | 中等 | 极佳 | 良好(Selenium/Playwright) | 通用、新手、数据分析 |
| JavaScript/Node.js | 中等 | 高 | 很强 | 极佳(原生) | 动态网站、异步爬取、网页开发者 |
| Ruby | 高 | 中等 | 不错 | 有限(Watir) | 快速脚本、原型开发 |
| PHP | 中等 | 中等 | 一般 | 有限(Panther) | 服务器端、Web 应用集成 |
| C++ | 低 | 很高 | 有限 | 非常有限 | 追求极致性能、超大规模 |
| Java | 中等 | 高 | 良好 | 良好(Selenium/HtmlUnit) | 企业级、长时间运行的服务 |
| Go(Golang) | 中等 | 很高 | 持续增长 | 中等(Chromedp) | 高速、并发爬取 |
什么时候该跳过写代码:用 Thunderbit 作为无代码网页爬取方案
试试 Thunderbit AI 网页爬虫 面向商业用户、营销人员和销售团队的无代码 AI 网页爬取。 Get Started Free
好吧,说实话:有时候你只是想要数据,不想折腾写代码、调试,或者反复琢磨“为什么这个选择器就是不生效”。这就是 Thunderbit 的用武之地。
作为 Thunderbit 的联合创始人,我想打造一款让网页爬取像点外卖一样简单的工具。下面这些就是 Thunderbit 的不同之处:
- 2 步设置: 只要点击“AI 推荐字段”和“爬取”就行。不用再折腾 HTTP 请求、代理或反爬技巧。
- 智能模板: 一个爬虫模板就能适配多种页面布局。网站一变,也不用重写爬虫。
- 浏览器和云端爬取: 你可以选择在浏览器里爬取(适合登录后的网站),也可以选择云端爬取(公共数据速度超快)。
- 可处理动态内容: Thunderbit 的 AI 会控制真实浏览器,所以无限滚动、弹窗、登录等都能搞定。
- 导出到任意地方: 可下载到 Excel、Google Sheets、Airtable、Notion,或者直接复制到剪贴板。
- 无需维护: 网站一变,重新运行 AI 推荐即可。再也不用半夜修 bug。
- 定时与自动化: 可以设置爬虫按计划运行——不用 cron 作业,也不用服务器配置。
- 专业提取器: 需要邮箱、电话号码或图片?Thunderbit 也有一键提取器。
最棒的是?你一行代码都不用会。Thunderbit 是专门为商业用户、营销人员、销售团队、房产专业人士——以及任何需要快速拿到数据的人打造的。
想看看 Thunderbit 实际怎么用?可以下载 Chrome 扩展 或查看我们的 YouTube 频道 了解演示。
结论:2026 年如何选择最适合网页爬取的语言
什么是数据抓取,以及如何操作 Get Started Free
到了 2026 年,网页爬取比以往更容易上手,也更强大。做了这么多年自动化,我学到的是:
- Python 依然是网页爬取的最佳语言,如果你想快速入门、又希望有海量资源可用,它仍然是首选。
- JavaScript/Node.js 在爬取动态、JavaScript 密集型网站时几乎无可匹敌。
- Ruby 和 PHP 很适合快速脚本和 Web 集成,尤其是你本来就在用它们的时候。
- C++ 和 Go 则适合你需要速度和规模的时候。
- Java 是企业级、长期项目的首选。
- 如果你想彻底跳过写代码?Thunderbit 就是你的秘密武器。
在动手之前,先问问自己:
- 我的项目规模有多大?
- 我需要处理动态内容吗?
- 我对技术的熟悉程度如何?
- 我是想自己搭建,还是只想拿到数据?
你可以试试上面的代码片段,也可以在下一个项目里直接体验一下 Thunderbit。如果你想继续深入了解,欢迎去看我们的 Thunderbit 博客,里面有更多指南、技巧和真实爬取案例。
祝你爬取顺利——愿你的数据永远干净、结构化,而且只需轻轻一点就能拿到。
P.S. 如果你有一天凌晨 2 点还卡在网页爬取的死胡同里,记住:总有 Thunderbit。或者咖啡。或者两者都有。
立即试用 Thunderbit AI 网页爬虫 Get Started Free
常见问题
1. 2026 年网页爬取最好的编程语言是什么?
Python 仍然是首选,因为它语法易读、库功能强大(如 BeautifulSoup、Scrapy 和 Selenium),而且社区庞大。无论是新手还是专业人士都很适合,尤其适合把爬取和数据分析结合起来。
2. 哪种语言最适合爬取 JavaScript 很重的网站?
JavaScript(Node.js)是动态网站的最佳选择。Puppeteer 和 Playwright 这类工具可以让你完整控制浏览器,方便与 React、Vue 或 Angular 加载的内容交互。
3. 网页爬取有没有无代码方案?
有——Thunderbit 是一款无代码 AI 网页爬虫,可以处理从动态内容到定时任务的各种需求。只要点击“AI 推荐字段”就能开始抓取。它非常适合需要快速获取结构化数据的销售、市场或运营团队。
4. 如果 AI 编程助手已经能帮我写爬虫,我还需要选语言吗?
这是 2026 年一个很合理的问题。像 Claude Code、Cursor 和 OpenAI Codex 这类工具,完全可以根据一段简短提示词生成 Scrapy 爬虫、Playwright 脚本,或者 Go + Colly 爬虫——所以“先学哪种语言”的门槛,确实比两年前低了很多。但代理最终还是会产出某种语言的代码,而你(或者接手这个项目的人)最后还是要去读、去调试、去部署。所以,语言选择依然重要;只是它对维护的影响,比对最初那 30 行代码的影响更大。如果你根本不想碰任何代码,那就是 Thunderbit 发挥作用的地方——它会直接跳过语言选择这一步。
了解更多:




