
互联网数据的增长速度简直让人咋舌——到2025年,全球数字内容预计会飙升到,这个体量不仅让人头晕目眩,甚至能直接把你的表格“干趴下”。更有意思的是,现在越来越多的数据都是靠 AI 网页爬虫自动采集出来的,人工操作早就跟不上节奏。事实上,光是2024年末,自动化爬虫和爬虫工具的。
不管你是做销售、市场还是运营,或者已经被网页间的复制粘贴折磨到怀疑人生,你一定懂得:手动收集数据不仅慢,还容易出错,过程还超级无聊。正因为如此,免费的 AI 网页爬虫工具成了团队高效整理网络数据的秘密武器——不用写一行代码,就能把杂乱无章的网页内容变成结构化数据。
我在 SaaS 和自动化领域摸爬滚打了好几年,亲眼见证了合适的 AI 网页爬虫能帮团队省下成千上万小时的重复劳动,还能挖掘出人工根本发现不了的洞察。接下来,我会为你盘点2026年12款最值得一试的免费 AI 网页爬虫工具,详细介绍每款工具的独特亮点、适用场景,以及如何根据你的需求选到最合适的那一款。
为什么免费 AI 网页爬虫对企业用户这么重要
说句实在话,“雇个实习生来复制粘贴客户名单”这种操作早就过时了。现在的企业团队讲究反应快、流程自动化,把精力都用在真正能带来业绩的地方。这就是免费 AI 网页爬虫的价值——让任何人(不只是程序员)都能:
- 快速获取潜在客户,不管是行业名录、领英还是垂直网站,几分钟就能搞定。
- 实时监控竞争对手,价格、产品上新、评论动态一网打尽,无需反复点页面。
- 自动化业务流程,比如自动更新 CRM、库存跟踪、市场调研等。
这些工具带来的效率提升非常明显。根据最新行业报告,AI 驱动的爬虫,大大降低了成本和部署时间。很多团队用过之后都说,省下了大量人力,还显著减少了人为失误()。
我们如何评选最佳免费 AI 网页爬虫工具
并不是所有爬虫工具都一个样。我们在挑选前12名时,主要看了这些维度:
- 易用性:必须是零代码或低代码界面。如果需要精通 Python 才能用,直接淘汰。
- AI 智能辅助:能自动识别字段、推荐列、适应网页变化的工具优先。
- 免费额度:免费版到底能用多少?我们对比了页面/记录限制、导出方式,以及核心功能是否免费开放。
- 功能丰富度:比如是否支持分页、子页面抓取、图片/邮箱/电话提取、模板库等。
- 扩展性与集成:能不能导出到 Excel、Google Sheets、Notion,或者通过 API 连接?能不能搞大批量任务?
- 适用场景:有的工具适合新手,有的更适合开发者或大规模项目。
文末还有一张对比表,帮你快速锁定最适合自己的工具。
1. Thunderbit
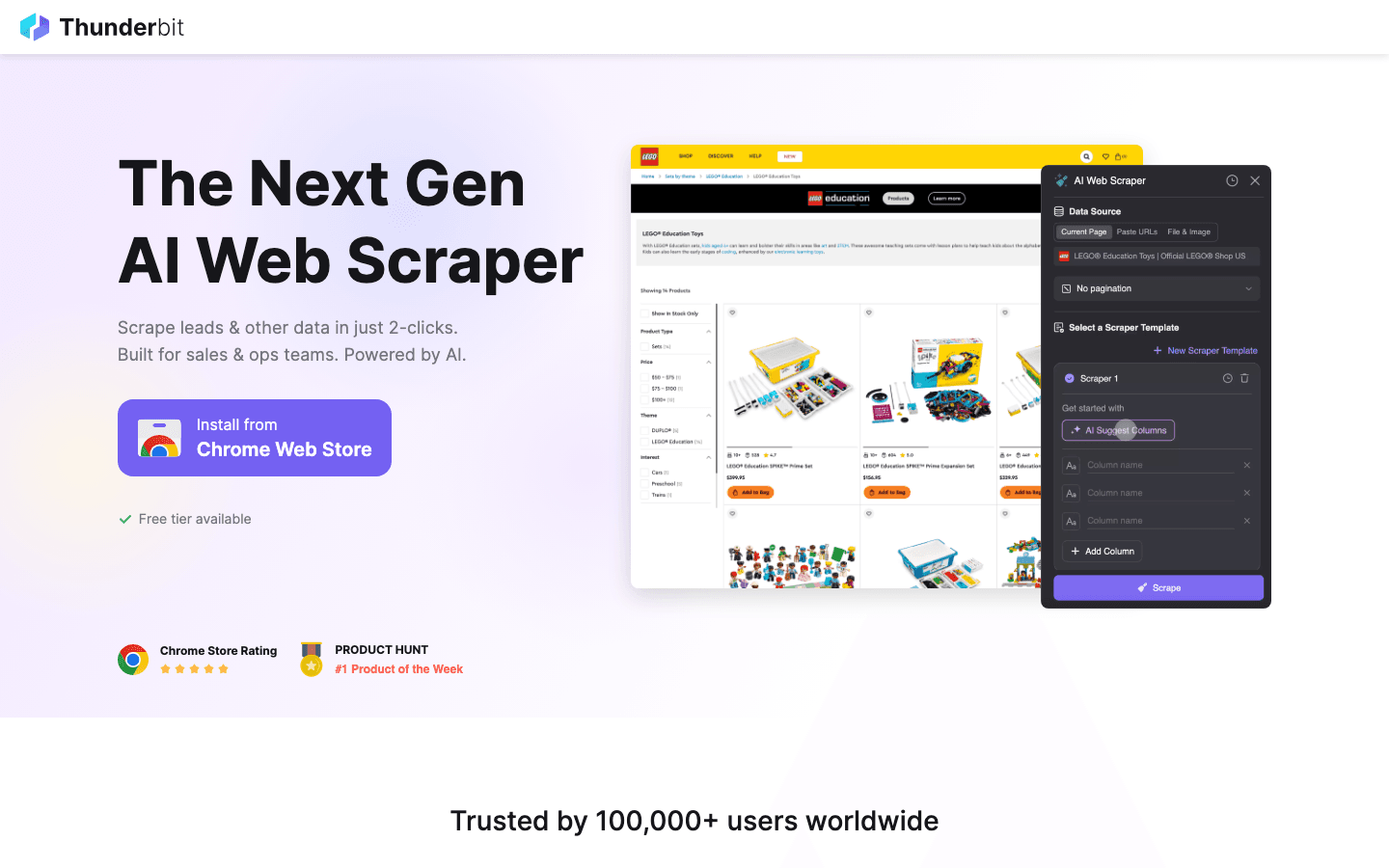 是我最推荐给企业用户的免费 AI 网页爬虫,真正做到了极致简单。作为 Chrome 扩展,Thunderbit 专为非技术团队设计——无论你是销售、运营、电商还是房产行业,只需两步就能从任意网站采集数据。
是我最推荐给企业用户的免费 AI 网页爬虫,真正做到了极致简单。作为 Chrome 扩展,Thunderbit 专为非技术团队设计——无论你是销售、运营、电商还是房产行业,只需两步就能从任意网站采集数据。
Thunderbit 有哪些独家亮点?
- AI 字段推荐:点一下“AI 推荐字段”,Thunderbit 的 AI 会自动分析页面,推荐最合适的列(比如姓名、邮箱、价格等),还能为每个字段生成专属提取提示词。
- 子页面与分页抓取:需要深入详情页或处理无限滚动?Thunderbit 的 AI 能自动跟踪链接、处理分页,把所有数据合并到一张表里。
- 一键模板:针对热门网站(如亚马逊、Zillow、Instagram、Shopify 等),直接用内置模板一键采集,无需配置。
- 免费数据导出:数据可免费导出到 Excel、Google Sheets、Airtable 或 Notion,也支持下载为 CSV 或 JSON。
- 图片/邮箱/电话提取:一键提取任意网站的图片、邮箱和电话号码。
- 零代码、零维护:不用写代码、不用模板、不用维护。Thunderbit 的 AI 会自动适应网页变化。
免费额度:每月可采集6个页面(注册试用可提升到10个),所有功能全开。需要更多?付费版每月只要15美元起,含500积分。
用户反馈:团队普遍称赞 Thunderbit 简单高效,尤其在处理结构混乱的小众网站时表现特别好。它已经成了快速获取客户名单、产品监控和市场调研的首选工具()。
想亲自体验?,一分钟内就能完成首次采集。
2. ParseHub
 是一款可视化、零代码的网页爬虫,非常适合新手和小团队。它用机器学习自动分组元素,能搞定 AJAX、表单和图片等复杂网页。
是一款可视化、零代码的网页爬虫,非常适合新手和小团队。它用机器学习自动分组元素,能搞定 AJAX、表单和图片等复杂网页。
- 可视化点击操作:只要点一下想要的数据元素,ParseHub 就能自动识别并采集。
- 图片识别与 API 支持:能抓取图片、动态内容,还能通过 API 获取数据。
- 云端或本地运行:支持云端和本地两种方式。
- 免费额度:每次最多采集200页,最多5个项目。支持导出为 CSV 或 JSON。
适用场景:适合小型、可视化项目,比如商品列表或新闻文章采集。上手简单,但大规模用要付费()。
3. Octoparse
 是一款零代码、支持本地和云端的爬虫,拥有丰富的模板库和强大的 AI 功能。
是一款零代码、支持本地和云端的爬虫,拥有丰富的模板库和强大的 AI 功能。
- AI 自动识别:Octoparse 的 AI 能自动生成采集流程,支持 JavaScript 动态页面和验证码保护网站。
- 批量处理:一次性采集成千上万条数据,支持定时任务、登录和无限滚动。
- 免费额度:每月可采集1万条数据,核心功能基本开放。
- 多种导出方式:支持 CSV、Excel、Google Sheets 及 API 集成。
适用场景:适合需要采集动态网站或定期大批量采集的团队。上手有点门槛,但官方文档很详细()。
4. Scrapy
 是全球最受欢迎的开源 Python 网页爬虫框架。需要有编程基础,但在自定义和大规模采集方面非常强大。
是全球最受欢迎的开源 Python 网页爬虫框架。需要有编程基础,但在自定义和大规模采集方面非常强大。
- 高度灵活:可以自定义爬虫,适应各种网站结构,还能集成 AI 模块。
- 无限制使用:开源免费,采集量只受硬件限制。
- 可扩展性强:有丰富插件和社区支持。
适用场景:适合开发者和技术团队,追求极致定制和扩展性。不建议零基础用户使用()。
5. Data Miner
 是一款 Chrome/Edge 扩展,内置5万+预设“配方”,能从1.5万+热门网站采集表格、列表和联系方式。
是一款 Chrome/Edge 扩展,内置5万+预设“配方”,能从1.5万+热门网站采集表格、列表和联系方式。
- 一键采集:选好配方,点一下就能拿到数据。
- 分页与自动填表:支持多页列表采集和表单自动填写。
- 免费额度:每月可采集500页。支持导出为 CSV、Excel 或 Google Sheets。
适用场景:适合快速提取表格、名单、产品目录等,无需配置()。
6. WebHarvy
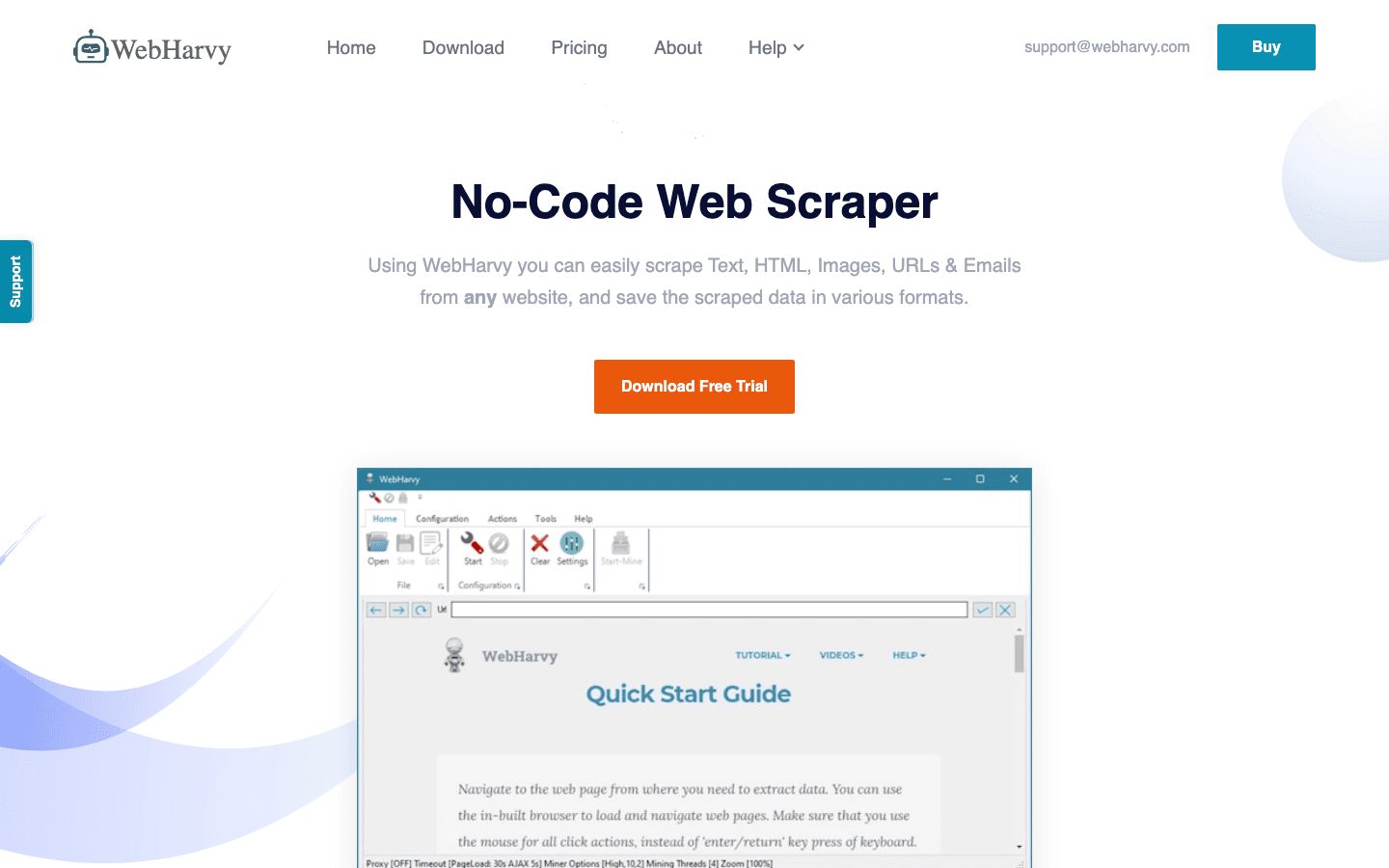 是一款 Windows 桌面爬虫,拥有可视化点击界面和智能模式识别。
是一款 Windows 桌面爬虫,拥有可视化点击界面和智能模式识别。
- 模式识别:点一个商品,WebHarvy 会自动选中所有类似项目。
- 图片采集:轻松下载图片、邮箱和网址。
- 免费试用:没有永久免费版,但可以试用。需购买一次性授权。
适用场景:适合电商团队或需要批量采集图片、商品数据的用户()。
7. Dexi.io
 是一款云端平台,专为高级、可扩展的网页采集和自动化流程设计。
是一款云端平台,专为高级、可扩展的网页采集和自动化流程设计。
- 可视化流程设计器:通过拖拽工具设计复杂采集流程。
- API 集成:能连接数据仓库、CRM 或分析系统。
- 免费试用:提供有限免费试用,付费版起价119美元/月。
适用场景:适合企业级团队或需要自动化复杂数据任务的运营人员()。
8. Apify
 是一款面向开发者的云平台,拥有6000+现成“Actor”(爬虫脚本)和完整 API。
是一款面向开发者的云平台,拥有6000+现成“Actor”(爬虫脚本)和完整 API。
- 市场与自定义:可以用现成 Actor,也能用 JavaScript/Python 自定义开发。
- 云端运行与定时:支持云端任务、定时采集和 AI 流程集成。
- 免费额度:每月30个计算单元。
适用场景:适合技术团队自动化自定义流程或扩展采集管道()。
9. Import.io
 是一款企业级、AI 加持的数据采集平台,专注于结构化数据和合规性。
是一款企业级、AI 加持的数据采集平台,专注于结构化数据和合规性。
- AI 智能选择器:自动适应网页结构变化。
- 数据清洗与转换:导出前可对数据进行清洗、丰富和转换。
- 免费试用:14天免费试用,付费版起价249美元/月。
适用场景:适合需要大规模、合规数据源的企业用于 BI 或分析()。
10. Diffbot
 是一款 AI 平台,利用 NLP 和计算机视觉自动从网页提取结构化数据,无需配置。
是一款 AI 平台,利用 NLP 和计算机视觉自动从网页提取结构化数据,无需配置。
- 知识图谱:自动识别人物、产品、文章等实体。
- API 接口:通过 API 获取结构化数据,适用于新闻、分析或研究。
- 免费额度:每月1万积分,支持 Extract、NLP 和 Knowledge Graph API。
适用场景:适合需要高质量结构化数据的团队,比如新闻、产品或论坛数据()。
11. VisualScraper
 是一款简单易用的网页爬虫服务,适合新手。
是一款简单易用的网页爬虫服务,适合新手。
- 无需编程:只要选字段就能采集。
- 多页支持:能实时采集多页数据。
- 免费额度:基础功能不限量,支持导出为 CSV、JSON、XML 或 SQL。
适用场景:适合快速采集公开数据,比如新闻、论坛或小型名录()。
12. Portia by Scrapinghub
 是一款开源可视化网页爬虫,可以在浏览器里标注页面训练爬虫,无需编程。
是一款开源可视化网页爬虫,可以在浏览器里标注页面训练爬虫,无需编程。
- 拖拽式界面:点选元素,Portia 自动推断采集规则。
- 开源免费:永久免费,但自2018年起无官方维护。
- Scrapy 集成:能通过 Scrapy 管道导出数据。
适用场景:适合有一定技术基础、希望用可视化方式替代代码爬虫的团队()。
快速对比表:最佳免费 AI 网页爬虫工具一览
| 工具 | 易用性 | AI/智能功能 | 免费额度 | 导出方式 | 最佳适用场景 |
|---|---|---|---|---|---|
| Thunderbit | ★★★★★(2步操作) | AI 字段推荐、子页/分页抓取 | 6页/月(试用10页) | Excel、Sheets、Airtable、Notion、CSV | 非技术团队、快速网页数据 |
| ParseHub | ★★★★☆(可视化界面) | 机器学习分组、API | 200页/次,5项目 | CSV、JSON、API | 小型项目、AJAX/JS 网站 |
| Octoparse | ★★★★☆(可视化界面) | AI 自动识别、JS/CAPTCHA 支持 | 1万条/月 | CSV、Excel、Sheets、API | 动态网站、定时任务、云端采集 |
| Scrapy | ★★☆☆☆(需编程) | 可扩展、开源 | 无限制(开源) | 任意(编程实现) | 开发者、自定义/大规模采集 |
| Data Miner | ★★★★☆(浏览器扩展) | 5万+配方、选择器查找 | 500页/月 | CSV、Excel、Sheets | 快速表格/名单/联系方式采集 |
| WebHarvy | ★★★★☆(可视化界面) | 模式识别、图片抓取 | 免费试用(需授权) | CSV、SQL、Excel | 电商、商品图片采集 |
| Dexi.io | ★★★☆☆(云端应用) | 流程自动化、API | 免费试用 | JSON、CSV、集成 | 企业级、复杂自动化流程 |
| Apify | ★★★☆☆(开发者向) | Actor 市场、API | 30计算单元/月 | JSON、API、webhook | 自定义自动化、开发团队 |
| Import.io | ★★★☆☆(企业级) | AI 选择器、合规功能 | 14天试用 | CSV、Excel、数据库 | 大规模、合规数据采集 |
| Diffbot | ★★★☆☆(API/界面) | NLP、视觉、知识图谱 | 1万积分/月 | JSON、API | 高质量实体/新闻/产品数据 |
| VisualScraper | ★★★☆☆(网页界面) | 可视化选择 | 基础功能不限量 | CSV、JSON、XML、SQL | 简单、定时、多页采集 |
| Portia | ★★★☆☆(浏览器界面) | 可视化 Scrapy 封装 | 无限制(开源) | JSON、XML(通过 Scrapy) | 技术型团队免费可视化采集 |
如何选择适合你的免费 AI 网页爬虫工具
选工具时可以参考这些建议:
- 新手/零代码:Thunderbit、ParseHub、Data Miner、VisualScraper 上手最快。
- 复杂/动态网站:Octoparse、Dexi.io、ParseHub 能搞定 JS 动态或复杂布局。
- 大规模/自定义:Scrapy、Apify、Import.io 适合开发者或企业级团队。
- 图片/商品数据:WebHarvy 和 Thunderbit 擅长图片及结构化商品信息采集。
- 结构化知识/实体:Diffbot 是高质量 AI 数据的首选。
- 开源/社区:Scrapy 和 Portia 永久免费,适合有技术基础的用户。
小贴士:在启动大项目前,务必确认免费额度和导出方式。免费不等于最适合你的业务,还是要结合实际需求(比如获客、竞品监控、调研等)选最合适的工具。
总结:用最佳免费 AI 网页爬虫释放业务价值
AI 网页爬虫早就不是开发者或数据科学家的专属。选对免费工具,任何人都能自动化数据采集,打造更智能的业务流程,挖掘真正有价值的洞察。不管你是做客户名单、价格监控,还是已经厌倦了手动复制粘贴,这份榜单总有一款工具能帮你省时省力。
如果你想最快上手,尤其是面对结构混乱的小众网站, 凭借 AI 字段推荐、子页面采集和一键导出,表现特别亮眼。当然,也可以多试几款工具,找到最适合自己的那一款。
准备好彻底告别手动录入了吗?赶紧下载一款免费的 AI 网页爬虫,亲自体验高效采集带来的生产力飞跃吧!
想了解更多网页爬虫技巧、深度解析和实用教程,欢迎访问 。
常见问题
1. 什么是 AI 网页爬虫,它和传统爬虫有啥区别?
AI 网页爬虫用人工智能自动识别、提取和结构化网页数据,通常不需要编程。和传统爬虫依赖固定模板或手动配置不同,AI 爬虫能适应网页结构变化,处理杂乱无序的数据。
2. 有哪些真正免费的 AI 网页爬虫适合企业用?
当然有!像 、ParseHub、Octoparse 和 Data Miner 都有功能丰富的免费版。建议提前看下每款工具的免费额度(比如每月可采集页面数、导出方式等),确保能满足你的需求。
3. 哪款免费 AI 网页爬虫最适合非技术用户?
Thunderbit、ParseHub、Data Miner 和 VisualScraper 都是为零编程用户设计的。Thunderbit 以2步操作和 AI 字段推荐,尤其适合销售、运营和市场团队。
4. 这些工具能采集图片、邮箱或电话号码吗?
可以!Thunderbit、WebHarvy 和 Data Miner 都支持图片、邮箱和电话采集。记得合法合规使用采集到的联系方式哦。
5. 如何选择零代码和代码型爬虫?
追求速度和简便,建议用 Thunderbit 或 ParseHub 这类零代码工具;如果需要高度定制、大规模自动化或系统集成,可以考虑 Scrapy 或 Apify 这类代码型工具。
祝你采集顺利,数据永远干净、结构化、好用!
延伸阅读