还记得我刚开始接触 python 网页爬虫那会儿的情景吗?2015 年,我窝在新泽西一间小公寓里,连灌三杯咖啡,死磕一段 Python 脚本——只要目标网站一改版,代码立马崩溃。那时候我用的就是 beautiful soup 和 selenium。转眼到了 2025 年,“beautiful soup 与 selenium 谁更强”依然是热门话题,但 AI 的加入已经彻底颠覆了整个玩法。现在的工具不仅能解析 HTML,还能理解网页内容,像人一样点链接、用自然语言指令提取结构化数据,甚至还能自动清洗、总结、翻译数据。

现在,python 网页爬虫早就不是程序员的专利了。销售、市场、电商、运营等团队都离不开新鲜、结构化的数据。随着网页爬虫软件市场规模突破 ,像 这样的 AI 工具层出不穷,大家关心的早就不是“我该用哪个 Python 网页爬虫”,而是“怎么最快、最省心、最低门槛拿到我想要的数据?”下面我们就来聊聊 beautiful soup 与 selenium 的较量,以及 AI 如何彻底改变这一切。
beautiful soup 与 selenium:核心区别是什么?
如果你查过“python 网页爬虫”,一定见过 和 。但它们到底有啥不同?
你可以把 beautiful soup 想象成一个高效的图书管理员。它是专门用来解析和提取静态 HTML 或 XML 文件数据的 python 库。如果你要的信息已经在网页源码里,beautiful soup 能帮你快速定位、整理、提取出来。它速度快、体积小,不需要像人一样“看”网页,只要直接读 HTML 源码就行。
selenium 更像一个能操作浏览器的机器人实习生。它可以自动化真实浏览器的各种操作:点按钮、填表单、登录、滚动页面、等 JS 加载完。当你要的数据只有在页面交互或动态加载后才出现时,selenium 就能大显身手。
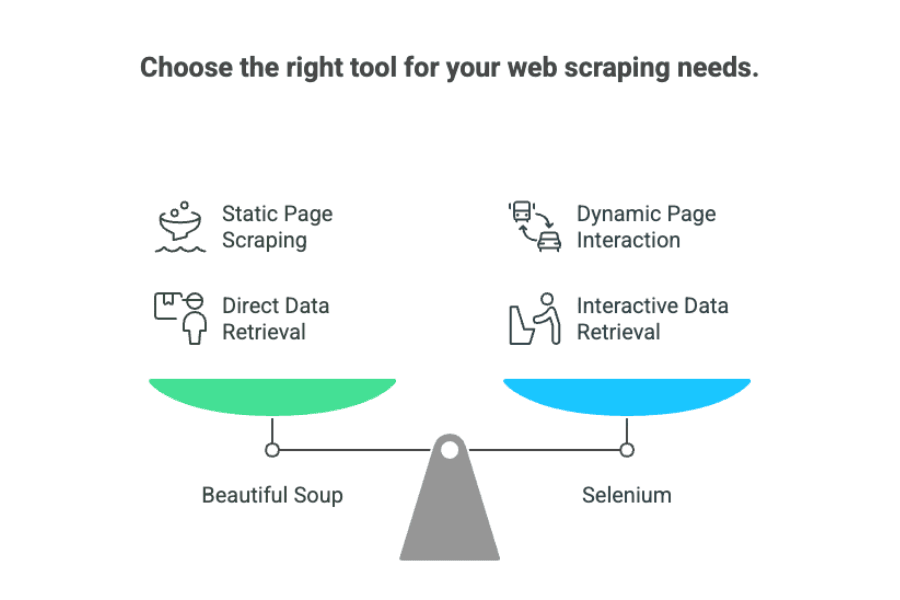
所以,“beautiful soup 与 selenium 谁更好”其实要看你遇到什么场景:
- beautiful soup: 适合数据直接在 HTML 里的静态页面。
- selenium: 适合需要交互或动态加载内容的网站。
如果你是业务用户,可以这样理解:
- beautiful soup 就像直接从纸质目录抄信息。
- selenium 则像派人去商店翻目录、按按钮、查最新价格。
常见难题:beautiful soup 和 selenium 的局限
说句实话,作为一个曾经无数次调试爬虫脚本的人,这两款工具的痛点主要有:
1. 对网站结构变动极其敏感
只要网站结构稍微一变,比如类名换了、div 位置动了,爬虫就可能直接失效。正如 :“维护成本可能比开发成本高 10 倍。”
2. 速度问题
- beautiful soup 解析速度快,但如果要顺序爬成千上万页面,依然很耗时。
- selenium 更慢——每个页面都要开浏览器、等脚本加载、模拟操作。大规模用 selenium 意味着要开一堆浏览器,资源消耗爆炸。
3. 代码难以复用
每个网站结构都不一样,意味着每次都得写新的解析逻辑。网站一变,又得重写,根本没有“万能脚本”这回事。
4. 技术门槛高
这两款工具都需要 python 编程、HTML/CSS 选择器知识,selenium 还得懂浏览器驱动。对非技术人员来说,学习曲线很陡。
5. 维护压力大
爬虫维护是个无底洞。网站变动、反爬机制升级,你得不断监控和修复脚本。对企业来说,这就意味着要依赖开发者或外包爬虫任务。
传统 python 网页爬虫之外:AI 网页爬虫的崛起
精彩的来了。近几年,AI 网页爬虫迅速崛起——这些工具用大语言模型(比如 GPT),不用写代码就能“读懂”网页并提取数据。
Thunderbit 登场:为企业用户打造的 AI 网页爬虫
是一款 Chrome 插件,只需两步点击就能抓取任意网页。无需 python、无需写代码、无需配置浏览器驱动。只要打开网页,点几下,剩下的交给 AI。
为什么像 Thunderbit 这样的 AI 网页爬虫如此颠覆?
- 真正零代码、零门槛: Thunderbit 不只是“零代码”,更是“零操作”。无需任何配置,装好 ,打开目标网页,AI 自动推荐可提取字段。
- 动态内容轻松搞定: Thunderbit 在浏览器里运行,能看到你看到的所有内容,包括 JS 动态加载、点击后出现的数据,甚至登录后的页面。
- 速度快且准确: Thunderbit 的 AI 能批量抓取多个页面,特别适合线索收集、电商、房产等业务场景,既快又准。
- 无需维护: 把 Thunderbit 想象成永不疲倦的 AI 实习生。网站变了,AI 自动适应,无需你反复改代码。
- 数据清洗与增强: Thunderbit 不只是抓原始数据,还能自动打标签、格式化、翻译、总结。就像让 ChatGPT 帮你把一万页网页整理成干净的表格。
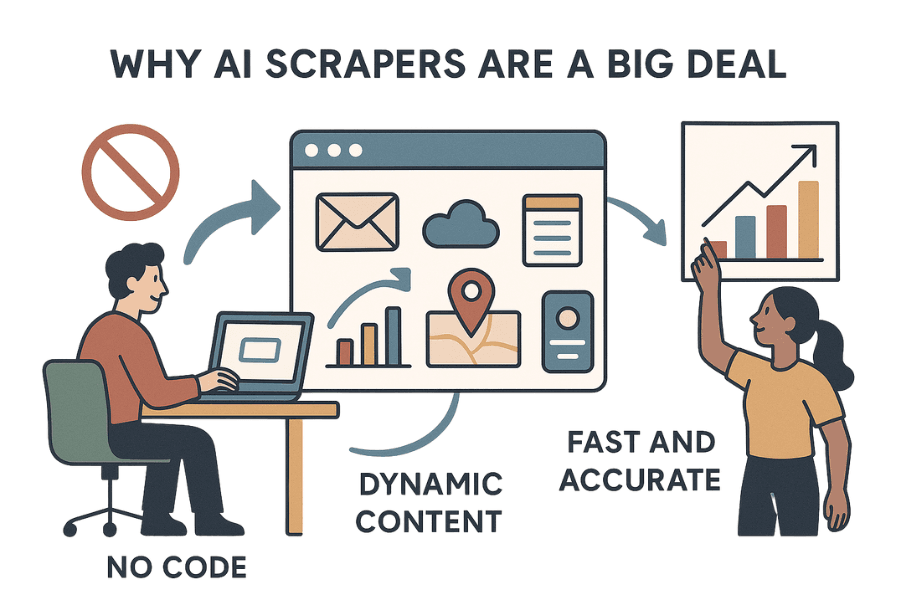
结果就是:业务用户不用等开发、也不用学 python,照样能轻松拿到想要的数据。
Thunderbit vs beautiful soup vs selenium:一图对比
下面是三款工具在企业场景下的对比:
| 对比维度 | Beautiful Soup | Selenium | Thunderbit (AI 网页爬虫) |
|---|---|---|---|
| 安装配置 | Python 安装简单 | 配置复杂(需浏览器驱动) | Chrome 插件,零配置 |
| 易用性 | 程序员友好 | 更难,需要编程 | 零代码,业务友好 |
| 速度 | 静态页面快 | 慢(浏览器开销大) | 小中型任务快,不适合超大规模 |
| 动态内容 | 无法处理 JS | 动态内容全支持 | 动态内容全支持 |
| 维护成本 | 高(易失效) | 高(易失效、驱动需更新) | 低(AI 自动适应) |
| 可扩展性 | 静态页面好,需搭建基础设施 | 难扩展,资源消耗大 | 适合小中型任务,不适合批量爬取 |
| 数据清洗 | 需手动后处理 | 需手动后处理 | 内置:打标签、格式化、翻译、总结 |
| 集成能力 | 需自定义代码 | 需自定义代码 | 一键导出到 Excel、Sheets、Airtable、Notion |
| 技术门槛 | 需 Python | 需 Python+浏览器知识 | 无需技术基础 |
高阶亮点:Thunderbit 如何革新企业网页爬虫
Thunderbit 给企业用户带来了哪些突破?
1. AI 智能字段识别
Thunderbit 利用 AI 自动“读懂”网页,推荐最优提取字段。你只要点“AI 推荐字段”,确认列名,点“抓取”就行,完全不用写选择器或解析 HTML。
2. 子页面自动爬取
比如你要先抓产品列表,再进每个产品详情页补充信息?Thunderbit 能自动访问每个子页面,丰富你的数据表,无需额外配置。
3. 数据清洗、打标签、翻译
Thunderbit 的 AI 能:
- 打标签: 抓取时自动分类或加标签。
- 格式化: 统一电话、日期、价格等格式。
- 翻译: 实时把内容翻译成你需要的语言。
- 总结: 长文本自动生成摘要或要点。
相当于自带数据分析师。
4. 一键集成
数据可一键导出到 Excel、Google Sheets、Airtable 或 Notion,无需再手动处理 CSV。
5. 零代码、零维护
Thunderbit 专为业务用户设计,无需懂 python,也不用担心维护。AI 自动适应网页变化,流程持续稳定。
想了解更多 Thunderbit 功能?可以参考。
如何选工具:企业用户实用建议
那 beautiful soup、selenium、Thunderbit 到底怎么选?结合多年实战经验,给你几点建议:
1. 你需要抓取多少数据?
- 小中型任务(几百到几千页): Thunderbit 最合适,快速上手、零代码、内置数据清洗。
- 大规模爬取(数万到百万页): 推荐 beautiful soup(配合 Scrapy 等框架)或企业级方案。Thunderbit 暂不适合超大批量。
2. 你有开发资源吗?
- 有开发团队: beautiful soup 和 selenium 灵活可控。
- 没有开发,或想快速上线: Thunderbit 或其他 AI 工具。
3. 目标网站变动频繁吗?
- 经常变动: Thunderbit 的 AI 能自动适应,省心省力。
- 很少变动: beautiful soup 或 selenium 也能胜任,但要做好随时维护脚本的准备。
4. 需要数据清洗或增强吗?
- 需要: Thunderbit 可自动打标签、格式化、翻译、总结。
- 只要原始数据: beautiful soup 或 selenium。
决策速查表
| 问题 | 最佳工具 |
|---|---|
| 没有开发,急需数据 | Thunderbit |
| 需要边抓边清洗/翻译 | Thunderbit |
| 超大规模、需自定义流程 | Beautiful Soup/Scrapy |
| 网站经常变动,想省维护 | Thunderbit |
总结:python 网页爬虫的未来
网页爬虫技术早已不是我当年苦战 python 脚本的样子。2025 年,“beautiful soup vs selenium”依然有讨论价值,但 AI 工具如 Thunderbit 的崛起,正让企业用户彻底告别技术门槛。
beautiful soup 依然是静态 HTML 解析的利器,速度快、轻量、适合简单任务。selenium 还是自动化浏览器、抓取动态网站的首选,但配置和维护成本不低。
但如果你想彻底摆脱写代码、维护脚本的烦恼,想要高效、结构化的数据,AI 网页爬虫如 Thunderbit 正在引领新潮流。它们不仅“零代码”,更是“零操作”。对于需要快速获取数据的销售、电商、运营团队来说,这绝对是巨大福音。
我的建议?重新审视你的爬虫流程。如果你厌倦了脚本崩溃、维护无休止、总是等开发,不妨试试 Thunderbit。网页爬虫的未来一定会更智能、更高效、更易用——我也很期待接下来会发生什么。
想亲自体验 Thunderbit?,或者浏览 获取更多实用指南。如果你关心特定网站(比如亚马逊、推特、PDF 等)的爬取方法,也可以参考:
祝你抓数顺利,数据永远新鲜、结构清晰、无烦恼!