

想象一下:你正盯着一个有成千上万商品信息的网站,不管是老板催你,还是你自己想搞点数据分析,都希望能把所有价格、名称和评论一股脑地整理进表格里——还得马上搞定。你可以花好几个小时手动复制粘贴,或者……直接让 Python 帮你一键解决。这就是网页爬取的魅力。别以为只有黑客或者硅谷程序员才会用,其实网页爬取早就成了销售、房产、市场调研等各行各业的标配技能。全球网页爬虫软件市场规模已经超过 $10 亿美元,预计到 2032 年还会翻一倍。数据的价值和机会只会越来越大。
作为 Thunderbit 的联合创始人,这些年我一直在帮企业自动化数据采集的各种繁琐流程。在 AI 网页爬虫(比如 Thunderbit)让网页数据一键提取之前,我也是靠 Python 的经典三件套——BeautifulSoup、requests 和无数次踩坑积累经验的。今天这篇文章就带你了解什么是 BeautifulSoup、怎么安装和用它,以及为什么它依然是很多开发者的首选。最后我还会聊聊像 Thunderbit 这样的 AI 工具,怎么让网页爬取变得更简单高效。不管你是 Python 新手、企业用户,还是对爬虫感兴趣的朋友,都可以跟着一起玩一玩。
什么是 BeautifulSoup?Python 网页爬取的利器简介
先来点基础知识。BeautifulSoup(大家常叫它 BS4)是一个专门用来解析 HTML 和 XML 文件的 Python 库。你可以把它想象成你的专属 HTML 侦探:只要把一堆乱七八糟的网页代码交给它,它就能帮你整理成结构清晰、好操作的树状结构。这样,想要获取商品名称、价格或者评论,只需要按标签或类名查找就行。
要注意的是,BeautifulSoup 本身不负责抓取网页(这通常得靠 requests 之类的库),但只要你拿到 HTML 内容,后续的查找、筛选和提取数据就变得特别简单。难怪最近有调查显示,超过 43% 的开发者 都选 BeautifulSoup 做网页爬虫,远超其他同类库。
BeautifulSoup 脚本被广泛用在学术研究、电商分析、线索收集等场景。我见过市场团队用它批量整理网红名单,招聘人员抓职位信息,甚至有记者用它自动化调查。它灵活、容错率高,只要你会点 Python,入门其实不难。
为什么选择 BeautifulSoup?业务价值与实际应用场景
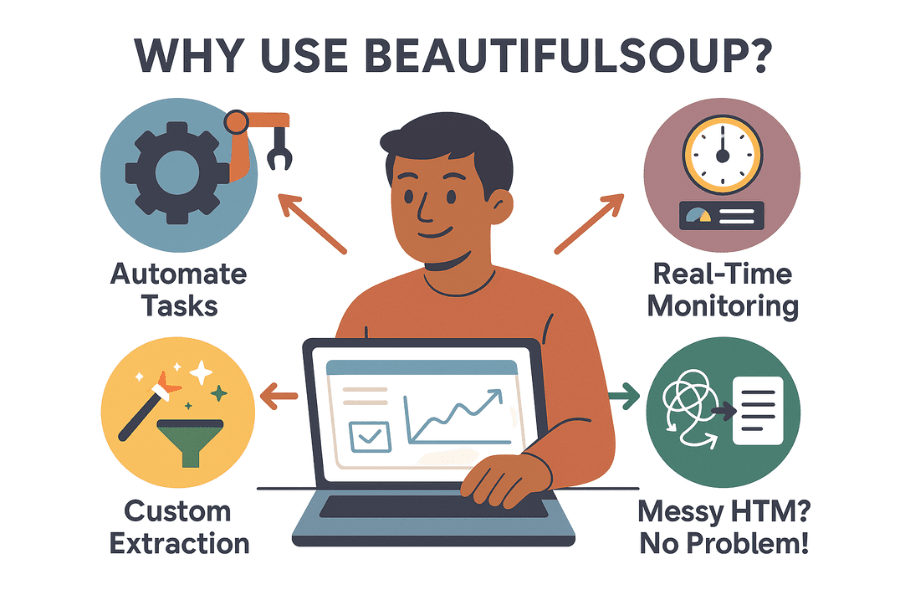
那为什么这么多企业和数据爱好者都在用 BeautifulSoup?它在网页爬取领域的地位,主要靠这些优势:
- 自动化繁琐流程: 与其手动复制粘贴,不如让脚本帮你批量采集。BeautifulSoup 能在几分钟内抓取成千上万条数据,让团队把时间花在更重要的事上。
- 实时监控: 可以定时检测竞争对手价格、库存或新闻头条。再也不用担心错过关键信息——比如对手突然降价,你第一时间就能知道。
- 自定义数据提取: 想要热门商品、评分和评论?BeautifulSoup 让你精准控制采集内容和处理方式。
- 应对杂乱 HTML: 就算网页代码写得一团糟,BeautifulSoup 也能帮你解析出来。
来看几个实际应用案例:
| 应用场景 | 说明 | 预期结果 |
|---|---|---|
| 线索收集 | 抓取企业名录或 LinkedIn 上的邮箱和电话 | 构建精准的销售名单 |
| 价格监控 | 跟踪电商网站上的竞争对手价格 | 实时调整自家定价策略 |
| 市场调研 | 收集网店的评论、评分或商品详情 | 洞察市场趋势,优化产品开发 |
| 房产数据 | 汇总 Zillow 或 Realtor.com 等网站的房源信息 | 分析价格走势或投资机会 |
| 内容聚合 | 整理新闻、博客或社交媒体提及 | 支持资讯推送或情感分析 |
实际收益也很可观:英国某零售商通过网页爬取监控竞争对手,销售额提升了 4%。ASOS 通过分析本地价格数据,调整营销策略,实现了国际销售翻倍。简单来说:数据爬取正在推动真实的商业决策。
入门指南:在 Python 中安装 BeautifulSoup
准备好动手了吗?下面教你怎么快速配置 BeautifulSoup:
步骤 1:正确安装 BeautifulSoup
首先,确保装的是最新版——BeautifulSoup 4(也就是 bs4),别被老包名坑了!
pip install beautifulsoup4
如果你用的是 macOS 或 Linux,可能需要用 pip3 或加上 sudo:
sudo pip3 install beautifulsoup4
小提醒: 如果不小心运行了 pip install beautifulsoup(少了“4”),会装上老版本,可能不兼容。别问我怎么知道的。
步骤 2:安装解析器(推荐)
BeautifulSoup 可以用 Python 自带的 HTML 解析器,但为了速度和兼容性,建议额外装上 lxml 和 html5lib:
pip install lxml html5lib
步骤 3:安装 Requests(用于抓取网页)
BeautifulSoup 负责解析 HTML,但你还得先拿到网页内容。推荐用 requests 库:
pip install requests
步骤 4:检查 Python 环境
确保你用的是 Python 3。如果在 IDE(比如 PyCharm、VS Code)里操作,记得检查解释器。如果遇到导入错误,可能是装错了环境。Windows 用户可以用 py -m pip install beautifulsoup4 指定 Python 版本。
步骤 5:测试环境是否配置成功
试试下面这个小例子:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
如果能看到 <title> 标签内容,说明环境没问题。
BeautifulSoup 基础:核心概念与语法解析
来看看 BeautifulSoup 的几个核心对象和概念:
- BeautifulSoup 对象: 解析后 HTML 的根节点。通过
BeautifulSoup(html, parser)创建。 - Tag: 代表 HTML 或 XML 标签(比如
<div>、<p>、<span>),可以访问属性、子节点和文本。 - NavigableString: 标签里的文本内容。
理解解析树结构
可以把 HTML 想象成家谱树:<html> 是祖先,<head> 和 <body> 是子节点,依次往下。BeautifulSoup 让你用 Python 语法轻松遍历这棵树。
示例:
html = """
<html>
<head><title>My Test Page</title></head>
<body>
<p class="story">Once upon a time <b>there were three little sisters</b>...</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# 访问 title 标签
print(soup.title) # <title>My Test Page</title>
print(soup.title.string) # My Test Page
# 访问第一个 <p> 标签及其 class 属性
p_tag = soup.find('p', class_='story')
print(p_tag['class']) # ['story']
# 获取 <p> 标签内所有文本
print(p_tag.get_text()) # Once upon a time there were three little sisters...
遍历与查找元素
- 元素访问器:
soup.head、soup.body、tag.parent、tag.children - find() / find_all(): 按标签名或属性查找元素。
- select(): 支持 CSS 选择器,适合复杂查询。
示例:
# 查找所有链接
for link in soup.find_all('a'):
print(link.get('href'))
# CSS 选择器示例
for item in soup.select('div.product > span.price'):
print(item.get_text())
实战演练:用 BeautifulSoup 构建你的第一个网页爬虫
来点实操。假设你想抓取电商搜索页上的商品标题和价格(以 Etsy 为例),可以这样做:
步骤 1:抓取网页内容
import requests
from bs4 import BeautifulSoup
url = "https://www.etsy.com/search?q=clothes"
headers = {"User-Agent": "Mozilla/5.0"} # 有些网站需要设置 user-agent
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
步骤 2:解析并提取数据
假设每个商品都在 <li class="wt-list-unstyled"> 块中,标题在 <h3 class="v2-listing-card__title">,价格在 <span class="currency-value">。
items = []
for item in soup.find_all('li', class_='wt-list-unstyled'):
title_tag = item.find('h3', class_='v2-listing-card__title')
price_tag = item.find('span', class_='currency-value')
if title_tag and price_tag:
title = title_tag.get_text(strip=True)
price = price_tag.get_text(strip=True)
items.append((title, price))
步骤 3:保存为 CSV 或 Excel
用 Python 自带的 csv 模块:
import csv
with open("etsy_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Product Title", "Price"])
writer.writerows(items)
或者用 pandas:
import pandas as pd
df = pd.DataFrame(items, columns=["Product Title", "Price"])
df.to_csv("etsy_products.csv", index=False)
这样你就能得到一份可用于分析和报告的表格数据。
BeautifulSoup 的挑战:维护、反爬与局限性
说点实话:虽然我很喜欢 BeautifulSoup,但它也有一些“坑”,尤其是在大规模或长期爬取时。
1. 易受网页结构变化影响
网站经常调整布局、类名或元素顺序。你的 BeautifulSoup 脚本依赖这些选择器,一旦网页结构变了,脚本就可能失效——有时候还不会报错。如果你要维护几十甚至上百个脚本,更新起来可不是小事。
2. 反爬机制
现在的网站会用各种手段防爬:验证码、IP 封禁、限速、JavaScript 动态加载等。BeautifulSoup 本身没法应对这些,需要你额外加代理、无头浏览器,甚至外部验证码识别。和网站管理员斗智斗勇,简直像打地鼠。
3. 扩展性与性能
BeautifulSoup 适合一次性脚本或中小规模数据采集。如果你要抓取百万级页面或并发运行任务,就得自己写并发、错误处理和基础设施。这些都能搞,但工作量不小。
4. 技术门槛
说实话,如果你对 Python、HTML 和调试不熟,BeautifulSoup 上手会有点难度。就算是有经验的开发者,爬虫开发也常常是“查看元素-写代码-运行-调试-再改”的循环。
5. 法律与合规风险
网页爬取有时候会踩到法律红线,尤其是无视 robots.txt 或网站服务条款时。用代码爬数据时,记得自觉遵守规则,合理限速,尊重数据使用伦理。
超越 BeautifulSoup:AI 工具 Thunderbit 让网页爬取更简单
使用 AI 从任何网站抓取数据 Get Started Free
现在,AI 让网页爬取变得前所未有的简单。像 Thunderbit 这样的工具,让不会写代码的小白也能轻松采集网页数据。
Thunderbit 是一款基于 AI 的 Chrome 扩展,只需两步就能抓取任意网页。无需写 Python、无需选 CSS 选择器、无需维护。只要打开网页,点一下“AI 智能识别字段”,Thunderbit 的 AI 就会自动判断你可能需要的数据(比如商品名、价格、评论、邮箱、电话等)。再点“抓取”,数据就到手了。
Thunderbit 与 BeautifulSoup 对比一览
| 功能 | BeautifulSoup(需编程) | Thunderbit(AI 无代码) |
|---|---|---|
| 上手难度 | 需要 Python 编程、HTML 基础和调试能力 | 无需编程,AI 自动识别字段,界面操作 |
| 获取数据速度 | 需编写和测试代码,耗时数小时 | 2-3 次点击,几分钟搞定 |
| 适应网页变化 | 网页结构变动需手动维护脚本 | AI 能适应大部分变化,热门网站有模板 |
| 分页/子页面 | 需手动写循环和请求 | 内置分页和子页面采集,开关即可 |
| 反爬处理 | 需自行加代理、验证码、模拟浏览器 | 多数反爬问题自动处理,浏览器环境更易绕过封锁 |
| 数据处理 | 代码可自定义,但需自己实现 | 内置 AI 支持摘要、分类、翻译、清洗等 |
| 导出选项 | 需自写导出 CSV、Excel、数据库等 | 一键导出到 CSV、Excel、Google Sheets、Airtable、Notion |
| 扩展性 | 理论无限,但需自建基础设施和容错 | 高并发、定时任务、批量采集由云端/扩展处理(受套餐限制) |
| 成本 | 开源免费,但耗时且需维护 | 免费小量使用,付费可扩展,极大节省时间和维护成本 |
| 灵活性 | 代码可实现一切,只要你愿意写 | 覆盖大多数常见场景,极少数特殊需求需代码 |
想了解更多,可以参考 Thunderbit 博客 和 功能文档。
实操对比:Thunderbit 与 BeautifulSoup 的网页爬取流程
以抓取电商网站商品数据为例,看看两种方式的流程差异:
使用 BeautifulSoup
- 用浏览器开发者工具分析网页结构。
- 编写 Python 代码,使用
requests抓取页面,BeautifulSoup解析并提取字段。 - 调试选择器(类名、标签路径)直到拿到正确数据。
- 处理分页需写循环跟进“下一页”链接。
- 额外写代码导出为 CSV 或 Excel。
- 网页结构变动时,重复上述步骤。
耗时: 新网站通常需 1-2 小时(遇到反爬机制还会更久)。
使用 Thunderbit
- 在 Chrome 打开目标网站。
- 点击 Thunderbit 扩展。
- 点“AI 智能识别字段”,AI 自动推荐如商品名、价格等字段。
- 如有需要可调整字段,然后点击“抓取”。
- 如需分页或子页面采集,直接开关即可。
- 在表格中预览数据,一键导出所需格式。
耗时: 2-5 分钟。无需写代码、无需调试、无需维护。
额外亮点: Thunderbit 还能自动提取邮箱、电话、图片,甚至自动填写表单。就像请了个高效又不抱怨的实习生。
总结与核心要点
2025 年数据爬取是什么,怎么做? Get Started Free
网页爬取早就不是小众黑科技,而是主流商业工具,广泛应用于线索收集、市场调研等领域。BeautifulSoup 依然是入门 Python 网页爬虫的绝佳选择,灵活且可高度自定义。但随着网页结构越来越复杂、企业用户对效率和易用性的要求越来越高,像 Thunderbit 这样的 AI 工具正逐步改变行业格局。

如果你喜欢写代码、追求极致定制,BeautifulSoup 依然值得深入研究。但如果你想省去编程、维护的烦恼,快速拿到结果,Thunderbit 无疑是更高效的选择。与其花数小时造轮子,不如用 AI 轻松搞定。
想亲自体验吗? 赶快下载 Thunderbit Chrome 扩展,或者访问 Thunderbit 博客 获取更多教程。如果你还想继续玩转 Python,欢迎多多尝试 BeautifulSoup——不过记得敲代码时注意手腕休息哦。
祝你爬虫愉快!
试用 Thunderbit AI 网页爬虫 Get Started Free
延伸阅读:
如果你有疑问、经验或者想分享爬虫故事,欢迎留言或联系我。说不定我踩过的坑比你写过的爬虫还多呢。




