执行摘要
我们抓取了全球高流量网站榜单 Tranco 前 10,000 中每个域名的 robots.txt 文件。随后,我们用一个符合 RFC 9309 的解析器逐个解析,并按站点采用了哪种 AI 机器人政策(如果有)进行分类,统计到 2026 年为止,全球最常访问的网站里到底有多少在试图阻止 ChatGPT、Claude、Perplexity、Gemini、Common Crawl、Bytespider、Apple Intelligence,以及其他为大语言模型训练和服务提供数据的爬虫。
在我们能够清晰读取 robots.txt 的 7,248 个站点样本中,核心数字如下:
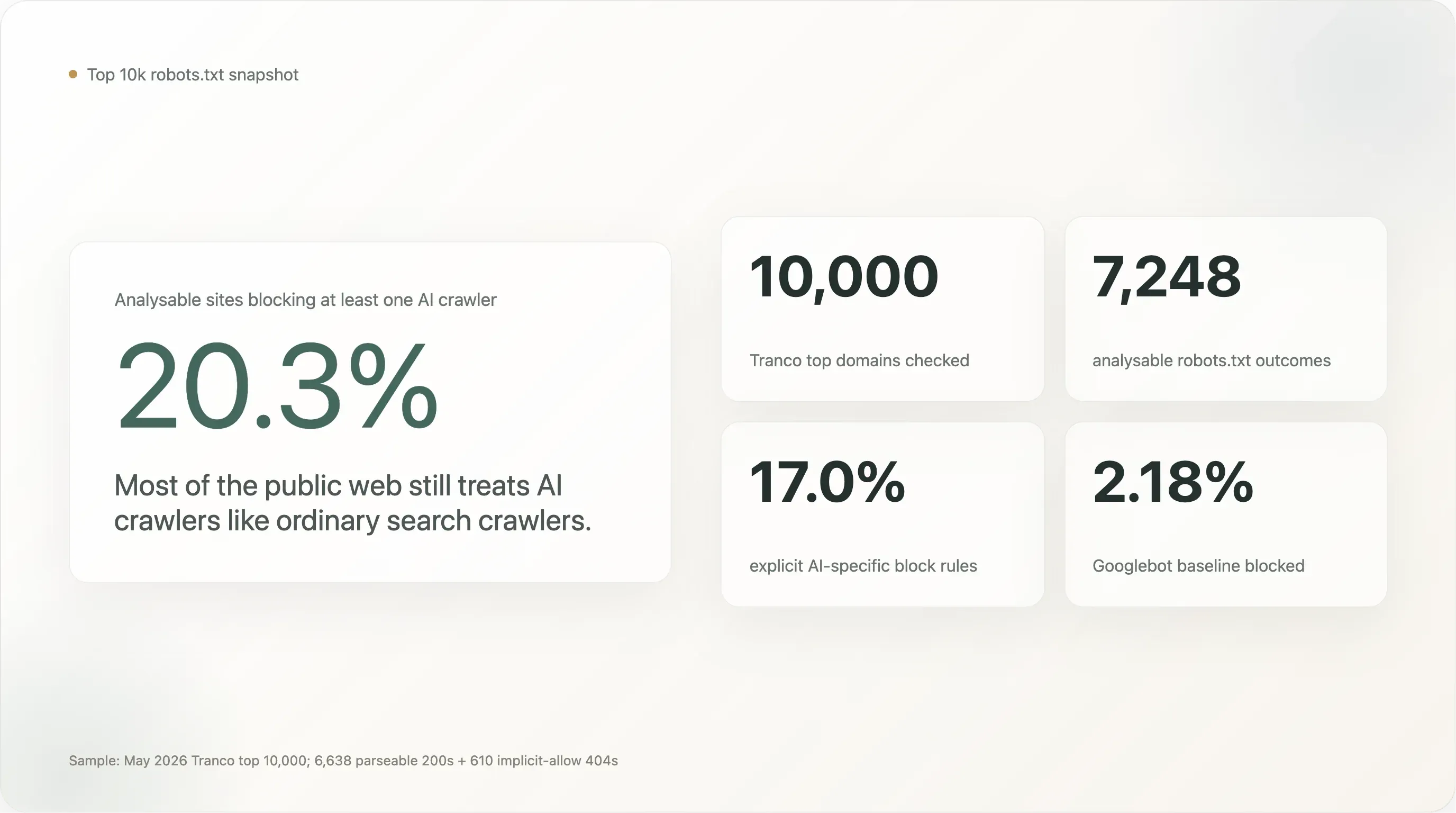
全球前 10,000 个网站中,20.3% 至少阻止了一种 AI 爬虫。17.0% 明确写了针对 AI 的专门规则。剩下 80% 对 AI 爬虫的态度,和对 Googlebot 一样开放。
六个改变叙事结构的发现:
- 新闻机构的阻挡率达到 47%,是所有行业中最高的。德国新闻站点高达 88%,法国 80%,俄罗斯 0%。真正起决定作用的是法律环境,而不是技术或行业经济。
CCBot(Common Crawl)是被阻挡最多的机器人,达到 16.3%,高于GPTBot(15.8%)和Bytespider(14.9%)。出版商针对的是训练语料,而不是模型品牌。最常见的选择性规则是“阻止CCBot,允许Googlebot”,占 14.1%。- 法国在
.fr站点上的 AI 阻挡率达到 50.6%,领跑所有国家;欧盟群组比全球基线高出 16 个百分点。 有 275 份robots.txt明确引用了欧盟指令 2019/790。第 4 条是唯一真正显著推动数字变化的法律机制。 - 17.8% 的站点自己手写 AI 规则;4.5% 使用了 Cloudflare 的模板;75.7% 什么都没写。 大站更倾向于自写规则;长尾站点则多用开关模板。The Atlantic 和
cloudflare.com自己都在 Cloudflare 托管列表里。 - 108 个站点明确 允许
GPTBot——包括 WordPress.org、Kaspersky、Norton、Avast、Sophos、The Verge、The Atlantic、NBA.com、The Sun、Branch.io。安全和开发工具类网站占比偏高。 - AI 政策并不会随着流量排名越高而变得更激进。 前 100、101–1000、1001–5000、5001–10000 这四个区间都落在 19% 到 23% 之间。这个总体现象是 2026 年公共网络的属性,而不是某个大站规模有多大的信号。
如今的核心问题,已经不再是“网页是否在反击”。真正的问题是:哪些行业、哪些国家、哪些法律体系、哪些 AI 厂商,正在成为主动政策的目标——又有哪些没有。
I. 背景:robots.txt 如何变成 AI 政策载体
自从 OpenAI 在 2023 年 8 月推出 GPTBot 之后,三股力量重新定义了 robots.txt 的含义。
AI 厂商数量暴增。 Google 的 Google-Extended、Anthropic 的 ClaudeBot、字节跳动的 Bytespider、Apple 的 Applebot-Extended、Amazon 的 Amazonbot、Meta 的 Meta-ExternalAgent 先后出现。Common Crawl 既有的 CCBot 变成了最有杠杆效应的封锁目标,因为它的档案库会喂给大多数开源权重模型。非厂商机器人也不断冒出来:AI2Bot、cohere-ai、PerplexityBot、YouBot、DuckAssistBot、Diffbot、Omgili。到 2026 年,一份完整的封锁清单大约会有 25 个名字。
欧盟版权指令 2019/790 的第 4 条建立了一个文本与数据挖掘例外,但前提是权利人必须以“机器可读”的方式“明确保留”权利。整个 2024–2025 年间,欧盟出版商及其律师最终把 robots.txt 视为表达这种保留的标准方式。我们的数据集显示,275 个站点明确引用了指令 2019/790,另有 87 个提到 “TDM”——这些内容高度集中在欧洲新闻站点里,通常作为 4–8 行的法律前言出现。
Cloudflare 把这个开关产品化了。 在 2024–2025 年,Cloudflare 推出了 “AI Audit” 面板、“Block AI Bots” 开关,以及一个托管 robots.txt 模板,模板中带有 Content-Signal: search=yes,ai-train=no 这套词汇和欧盟 2019/790 的标准法律条款。到 2026 年 5 月,这个模板已经运行在可解析前 10k 的 4.5% 上。Cloudflare 的路线图公开讨论了把新账户默认开启这个开关——这意味着,即使单个出版商没有做任何决定,全球封锁率也会直接上升 5–8 个百分点。
到了 2026 年,robots.txt 已经不再是 2022 年那种不起眼的配置文件。它在欧盟是带有条约支撑的版权保留机制,在长尾市场里是厂商塑形的政策产物,同时也是网站运营者与模型训练者之间缓慢博弈的前线。
II. 方法论
我们尽量让整个流程既无聊又可复现。完整流水线(Python 脚本、解析后的 CSV、原始 robots.txt 档案、图表)都随本报告一并发布。
样本
我们从 2026 年 5 月的 Tranco 列表开始,下载 top-1m.csv.zip,然后截取前 10,000 行。Tranco 聚合了四个上游排名源(Cisco Umbrella、Majestic、Farsight 和 Cloudflare Radar),并过滤了 30 天窗口内不稳定的域名,同时移除明显的爬虫/CDN 噪声。它生成的列表,是目前公开世界里最接近“全球网页流量前 10k”的标准样本,也是学术网页研究的常用样本(自 2018 年 KU Leuven 发布以来,已被 600 多篇同行评审论文使用)。
这个列表里混合了:(a) 用户真正访问的主网站;(b) 不提供 / 页面内容的基础设施 / API / DNS / CDN 根域;(c) 大平台内部使用的域名(例如 gvt1.com、apple-dns.net、googleusercontent.com)。我们没有预先过滤这些域名,而是在分析层将它们标记为 infrastructure 类别。只有在我们把范围限制为“返回了可解析 robots.txt 的站点”时,它们才会自然剔除。
抓取
对于这 10,000 个域名中的每一个,我们都通过 HTTPS 发送异步 GET /robots.txt 请求;如果 HTTPS 不通,则回退到 HTTP;最多跟随 4 次重定向;总超时 12 秒;正文上限 500 KB;并使用带 Accept-Language: en-US 的真实浏览器 User-Agent。并发数固定为 80 个请求。任务从旧金山的单一住宅 IP 发起。
抓取结果:
| 状态 | 数量 | 解释 |
|---|---|---|
200 OK | 6,638 | 返回了可解析的 robots.txt 正文。 |
404 Not Found | 610 | 不存在 robots.txt。RFC 9309 将其定义为隐式“允许全部”。 |
403 Forbidden | 563 | 源站主动拒绝 robots.txt 请求。已排除出分析。 |
429 Too Many Requests | 7 | 在这个排名层级,几乎没有 CDN 级限流。 |
fetch_failed(TLS / DNS / TCP 错误) | 2,065 | 主要是 CDN 根域(akamai.net、cloudfront.net、fastly.net、gtld-servers.net、apple-dns.net)——它们并没有在 / 上运行网站服务。并不是“被阻挡”,而是根本没有 robots.txt 可供提供。 |
| 其他 4xx/5xx | 117 | 混合情况——服务器错误、地理封锁、响应格式异常。 |
这给我们带来了 7,248 个可分析样本(6,638 个 200 + 610 个 404)。那 2,065 个 fetch_failed 当然是真实域名,但它们是 CDN/DNS 根节点,不是用户会访问的网站,把它们算作“有 AI 政策”并不合理。它们在数据集中只作为一项单独的可访问性统计存在。
解析
所有 200 正文都用 protego 解析——这是一个 RFC 9309 的 Python 实现,Scrapy 生产环境也在用。对于每一对(站点,机器人),我们计算了三项内容:
can_fetch_root——该机器人是否被允许抓取/,依据标准里的组记录语义、最长匹配优先规则,以及当两者同时存在时,特定机器人阻止规则对User-agent: *的覆盖。has_specific_rule——文件里是否包含一行明确命名该机器人(不区分大小写)的User-agent:。disallow_count——匹配块里有多少条Disallow:指令,用来区分全站禁用和路径级限制。
这个组合很重要,因为单看总封锁率,会把两种完全不同的情况混在一起:一类是品牌有意写了 User-agent: GPTBot \n Disallow: /,明确表态要反制;另一类则是品牌多年以前为了测试或维护而写下的通用 User-agent: * \n Disallow: /,后来恰好把所有当时还不存在的 AI 机器人也一起挡住了。整份报告中,“任意 AI 封锁” 数字包含这两类;“明确 AI 封锁” 则是更纯粹的刻意子集。
机器人范围
我们跟踪了 25 个机器人,分为三类:
- AI 训练爬虫(16 个):
GPTBot、ClaudeBot、anthropic-ai、CCBot、Google-Extended、Meta-ExternalAgent、Bytespider、Applebot-Extended、Diffbot、Amazonbot、ImagesiftBot、FacebookBot、cohere-ai、AI2Bot、Omgili、Omgilibot。 - AI 推理 / 实时检索机器人(7 个):
PerplexityBot、Perplexity-User、ChatGPT-User、OAI-SearchBot、ClaudeBot(同时用于训练和推理)、YouBot、DuckAssistBot。 - 搜索基线(6 个):
Googlebot、Bingbot、DuckDuckBot、Slurp(Yahoo)、Baiduspider、YandexBot。
有些机器人同时跨越训练和推理边界。ClaudeBot 是最典型的例子——Anthropic 在 2024 年弃用了旧的 anthropic-ai UA,现在同时用 ClaudeBot 做训练和实时检索,所以一条 Disallow: ClaudeBot 规则,已经不能干净地对应“阻止训练但保留可见性”了。我们保留了原始归类,并在后文说明其影响。
行业分类
我们用分层方法把每个域名归入 16 个行业桶之一(news、social、streaming、ecommerce、search、finance、infrastructure、saas、academia、dev、gov、adult、gambling、travel、telecom、unknown):
- 已知域名词典——人工整理的约 500 个高流量域名到行业的映射。
- TLD / 后缀模式——
.gov→gov,.edu和.ac.*→academia,已识别的 CDN 后缀 →infrastructure。 - 域名关键词——news、post、shop、bank、porn、casino 等作为兜底信号。
- 主页抓取——对于前三层无法分类且返回了
robots.txt200的站点,我们再抓取主页 HTML,提取<title>、<meta name="description">、<meta property="og:type">,并使用类似大语言模型场景的类别线索做关键词打分。
最终得到 3,407 个有把握的行业标签站点(34%),其余 6,593 个保留为 unknown。unknown 桶主要由非英语地区门户、无法轻易归入单一类别的 .com 品牌站点,以及我们没有词典条目的小语种传统媒体组成。凡是报告中提到行业百分比的地方,分母都是该行业的已分类样本,而不是完整的 10,000。
III. 发现
发现 1——每五个高流量网站里,就有一个至少阻止一种 AI 机器人
在 7,248 个可分析站点中,1,472 个(20.31%) 至少阻止了一种 AI 机器人。1,230 个(16.97%) 写了明确的 AI 专门规则。Googlebot 的基线是 2.18%(158 个站点——其中大多数要么是出于维护默认把一切都挡了,要么是少数几家搜索引擎在阻止竞争对手)。
这个 20% 的头条数字是 Googlebot 基线的 9 倍。这确实是个强信号——高流量站点阻止 AI 爬虫的概率,确实比阻止搜索爬虫高出一个数量级——但它也远小于自 2024 年以来媒体里一直在流传的“AI 阻挡正在全面普及”叙事。即使放到全网最常访问的前 10,000 个站点里,仍然有 5/6 的多数对 AI 保持沉默。
“任意 AI 阻挡”(20.3%)与“明确 AI 阻挡”(17.0%)之间的差距在绝对值上不大,但概念上非常重要。那 3.3 个百分点,代表的是这些站点之所以会挡住 AI 机器人,只是因为它们原先的 User-agent: * \n Disallow: / 规则会把路过的一切都拦下,包括规则写下时根本不存在的机器人。17.0% 的刻意数字,更准确地反映了“全球最大的网站里,有多少已经做出了 AI 专门决策”。
与既有研究对照:
| 来源 | 日期 | 样本 | 阻挡率 |
|---|---|---|---|
| Originality.ai | 2025 年 3 月 | 1,000 个最受欢迎新闻站(英文) | 35.7% 阻止 GPTBot |
| Palewire | 2024 年 8 月 | 1,500 家新闻机构 | 36.0% 阻止任意 AI 爬虫 |
| Reuters Institute | 2025 年春 | 50 个头部新闻品牌,10 个国家 | 78% 阻止任意 AI 爬虫 |
| WIRED / NYT | 2023 年底 | 美国前 50 大新闻站 | 26% 阻止 GPTBot |
| 本报告(Thunderbit) | 2026 年 5 月 | Tranco 前 10,000(全行业) | 20.3% / 17.0% 明确 |
我们的 17.0% 明确值低于任何仅新闻样本研究,因为我们的样本里三分之二并不是新闻。若只看 650 个新闻站点,就会得到 47%——在考虑样本构成后,这个数字与前述研究处于同一量级。结构性图景是一致的:新闻群组阻止 AI 的比例,是其余网络的 3–4 倍。
发现 2——行业深挖:从新闻到电信,差距高达 12 倍
过去两年里,围绕“AI 抓取”的报道中,最常被引用的结论是 Originality.ai 和 Palewire 提出的“80% 的新闻机构阻止 GPTBot”。我们的切片得出了一个更小但依然鲜明的结果:前 10,000 网站中的新闻站点,有 47.2% 至少阻止一种 AI 机器人,45.2% 写了明确的 AI 规则。
但“新闻 vs 其他所有行业”太粗糙了。完整拆分(样本中 n ≥ 10 的行业)展示了更丰富的图景:
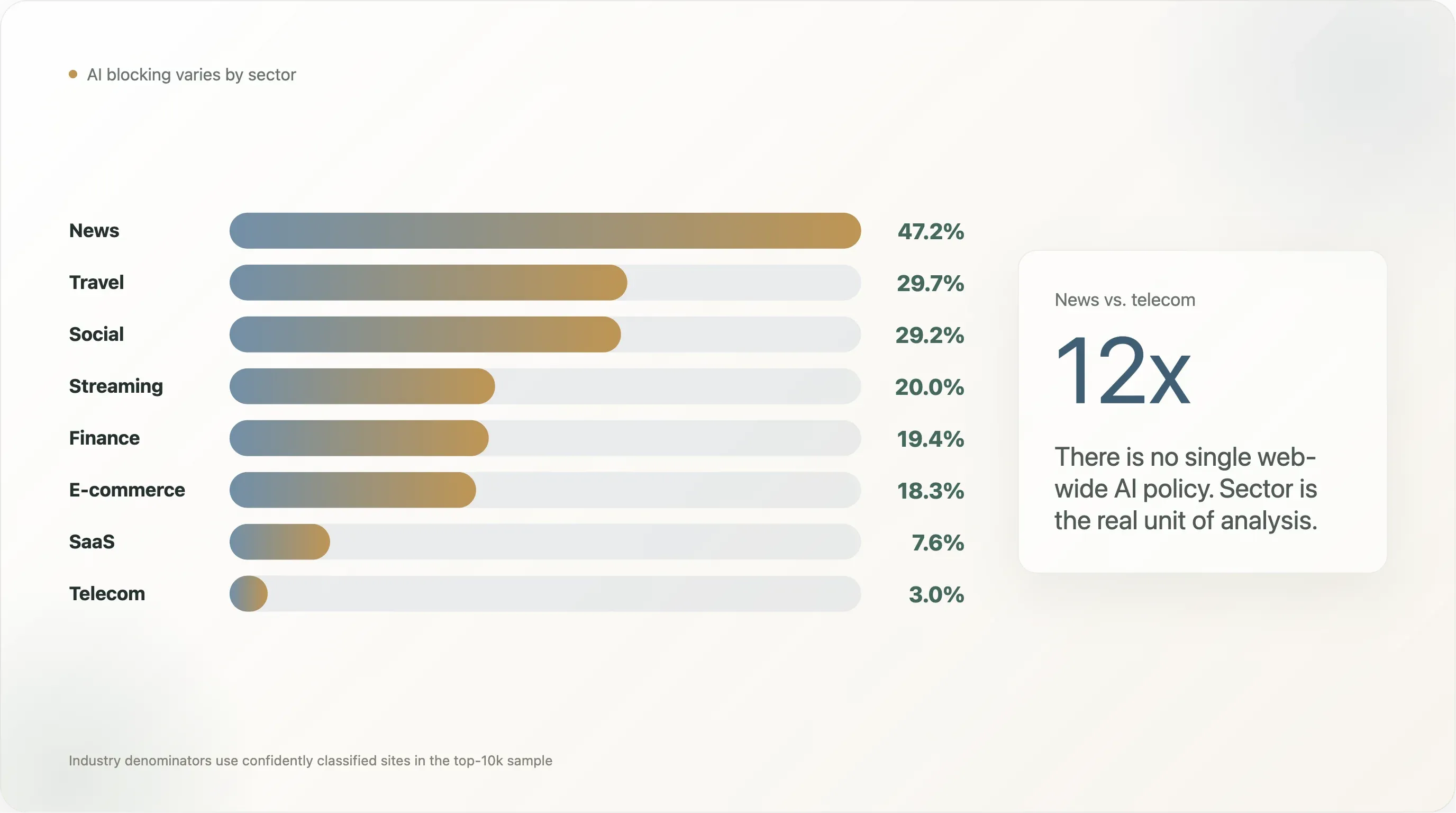
| 行业 | n | 任意 AI 阻挡 | 明确阻挡 | Googlebot 被挡 | 自写规则 | Cloudflare 托管 | 沉默 |
|---|---|---|---|---|---|---|---|
| 新闻 | 650 | 47.2% | 45.2% | 1.5% | 46.9% | 1.5% | 48.5% |
| 旅游 | 64 | 29.7% | 29.7% | 0.0% | 35.9% | 3.1% | 54.7% |
| 社交 | 65 | 29.2% | 23.1% | 4.6% | 23.1% | 6.2% | 66.2% |
| 流媒体 | 440 | 20.0% | 17.7% | 0.7% | 16.8% | 3.6% | 75.5% |
| 金融 | 129 | 19.4% | 12.4% | 0.8% | 14.7% | 2.3% | 75.2% |
| 电商 | 224 | 18.3% | 17.4% | 0.4% | 24.1% | 1.3% | 66.1% |
| 成人 | 254 | 17.3% | 14.6% | 0.4% | 10.2% | 7.9% | 79.5% |
| 搜索 | 12 | 16.7% | 0.0% | 0.0% | 0.0% | 0.0% | 100.0% |
| 学术 | 268 | 14.6% | 13.8% | 0.4% | 13.4% | 3.4% | 77.2% |
| 博彩 | 100 | 14.0% | 13.0% | 0.0% | 18.0% | 4.0% | 77.0% |
| 开发工具 | 129 | 10.1% | 7.8% | 0.0% | 8.5% | 5.4% | 77.5% |
| SaaS | 369 | 7.6% | 6.2% | 0.3% | 9.5% | 0.8% | 87.5% |
| 政府 | 172 | 5.2% | 3.5% | 0.0% | 4.1% | 0.6% | 83.1% |
| 基础设施 | 47 | 4.3% | 0.0% | 0.0% | 4.3% | 2.1% | 72.3% |
| 电信 | 33 | 3.0% | 3.0% | 0.0% | 12.1% | 0.0% | 78.8% |
新闻和电信之间 12 倍的差距,正说明“整个网络的 AI 政策”这个单位本身就不对。没有一个数字能概括全部;真正有效的是按行业拆开看,因为不同板块之间的差异可达一个数量级。下面我们会展开最有代表性的四个发现。
新闻:47% 阻挡,47% 自写。 新闻是写出这份规则的人群。Cloudflare 托管模板在新闻行业里的占比只有 1.5%——这些出版商不把规则外包出去。文本也异常丰富:NYT 用 14 行法律前言开头,引用“欧盟指令第 4 条”;BBC 写的是 “请像人一样使用我们的网站,不要像机器人……一句话总结:浏览、阅读、观看、享受——像人一样。”;The Sun 则写着 “The Sun 不允许未经授权将我们的内容用于大语言模型。” 这已经不是配置文件,而是 robots.txt 形式的政策声明。
旅游行业 30%——出人意料。 Booking、Expedia、TripAdvisor、Kayak 以及主要航空公司,阻挡率只有新闻行业的约三分之二。其选择性模式很一致:平均每个旅游行业的阻挡者会禁掉 5–7 个训练 UA,但会保留推理 UA(PerplexityBot、ChatGPT-User、OAI-SearchBot)不受影响。聚合后的价格和点评数据是护城河,而引用回站点本身就是收益。这是任何单一行业里最清晰的“阻训练、放推理”模式。
成人行业 17%——同样让人意外。 早先更小规模的样本显示这里是 0%。完整样本则显示,大约每 6 个成人站点里就有 1 个至少禁掉一种 AI 机器人,而且 Cloudflare 托管比例是所有行业里最高的(7.9%)。成人站点的 AI 阻挡中,超过一半来自 Cloudflare 开关,而不是出版商自己做的决定。图像生成训练是隐含威胁——Stable Diffusion 一类模型学视觉风格的速度,比文本模型学习写作风格更快。
SaaS 只有 7.6%,反直觉。 软件厂商是 AI 政策讨论里最高调的群体,但他们的 robots.txt 反而很开放。更合理的理解是:SaaS 营销团队已经正确把 AI 搜索识别成一个分发渠道。真正认真思考过这件事的厂商,选择的是“加入”而不是“退出”——明确 Allow GPTBot 的名单(见发现 12)主要由安全和开发工具类 SaaS 构成。
政府 5.2%、电信 3.0%、基础设施 4.3%、开发工具 10.1%。 公共记录义务让 .gov 的 Disallow: / 在法律上更麻烦。电信营销站点则希望被发现。CDN 根域没什么可保护的。开发工具则会明确加入,因为当大语言模型引用它们的内容时,内容价值反而提升。
结论是:不存在一个不按行业切分、又能真正说明问题的“网页到底在不在阻止 AI”的统一数字。只有按行业分层,才是诚实的表达方式。
发现 3——按 AI 厂商看:谁被挡得最多?
另一个自然的切法,不是按机器人,而是按 AI 公司。几家厂商同时运行多个机器人(OpenAI 运行三个:GPTBot、ChatGPT-User、OAI-SearchBot;Anthropic 运行两个:ClaudeBot、anthropic-ai;Meta 运行两个:Meta-ExternalAgent、FacebookBot)。聚合到厂商层面,已经是我们能最接近“公众网页如何看待各家 AI 公司”的方式。
| AI 厂商 | 聚合机器人 | 阻挡 ≥ 1 个机器人的网站数 | 占可分析样本比 |
|---|---|---|---|
| Common Crawl | CCBot | 1,178 | 16.25% |
| OpenAI | GPTBot、ChatGPT-User、OAI-SearchBot | 1,172 | 16.17% |
| Anthropic | ClaudeBot、anthropic-ai | 1,111 | 15.33% |
| ByteDance | Bytespider | 1,082 | 14.93% |
| Meta | Meta-ExternalAgent、FacebookBot | 989 | 13.65% |
Google-Extended | 970 | 13.38% | |
| Amazon | Amazonbot | 877 | 12.10% |
| Apple | Applebot-Extended | 859 | 11.85% |
| Webz.io(Omgili) | Omgili、Omgilibot | 731 | 10.09% |
| Cohere | cohere-ai | 717 | 9.89% |
| Perplexity | PerplexityBot、Perplexity-User | 715 | 9.86% |
| Diffbot | Diffbot | 684 | 9.44% |
| You.com | YouBot | 563 | 7.77% |
| AI2(Allen AI) | AI2Bot | 487 | 6.72% |
| DuckDuckGo | DuckAssistBot | 482 | 6.65% |
Common Crawl 是被针对得最厉害的单一实体,尽管它是非营利网页档案馆,而不是 LLM 运营商。原因在于它的杠杆效应:CCBot 为几乎所有开源权重模型以及相当一部分闭源模型提供数据。若出版商只想写一条覆盖面最高的规则,先阻止 CCBot 永远是优先级最高的做法。
OpenAI、Anthropic、ByteDance 聚在 14–16% 区间。 OpenAI 略高,部分原因是统计口径上它有三个机器人,而 ByteDance 只有一个。Bytespider 的 14.9% 可以看作“Bytespider 行为效应”——自 2024 年以来,它忽视 robots.txt 的情况已被反复记录,出版商阻止它更像是发出公开信号,而不是因为担心 TikTok。
Meta、Google、Amazon、Apple 处在 12–14% 的第二梯队——这些规则更多是防御性写法,而不是公开立场声明。小厂商(Webz.io、Cohere、Perplexity、Diffbot、You.com、AI2、DuckDuckGo)在 6–10% 区间,其中大多是被那 3.8% 的“兜底地板”带起来的;对它们的明确规则基本在 1–4% 之间。
xAI(Grok)、Mistral,以及多数欧洲/中国模型实验室都没出现在表里——因为它们还没有发布可文档化的训练爬虫 UA。当前的 robots.txt 生态,本质上是“发布了 UA 的美中厂商”与“写了规则的美欧出版商”之间的对话;没有发布 UA 的厂商,在这个谈判里是隐形的。
发现 4——CCBot 已经成了新靶子,而不是 GPTBot
前 10k 中各机器人被阻止的排序如下:
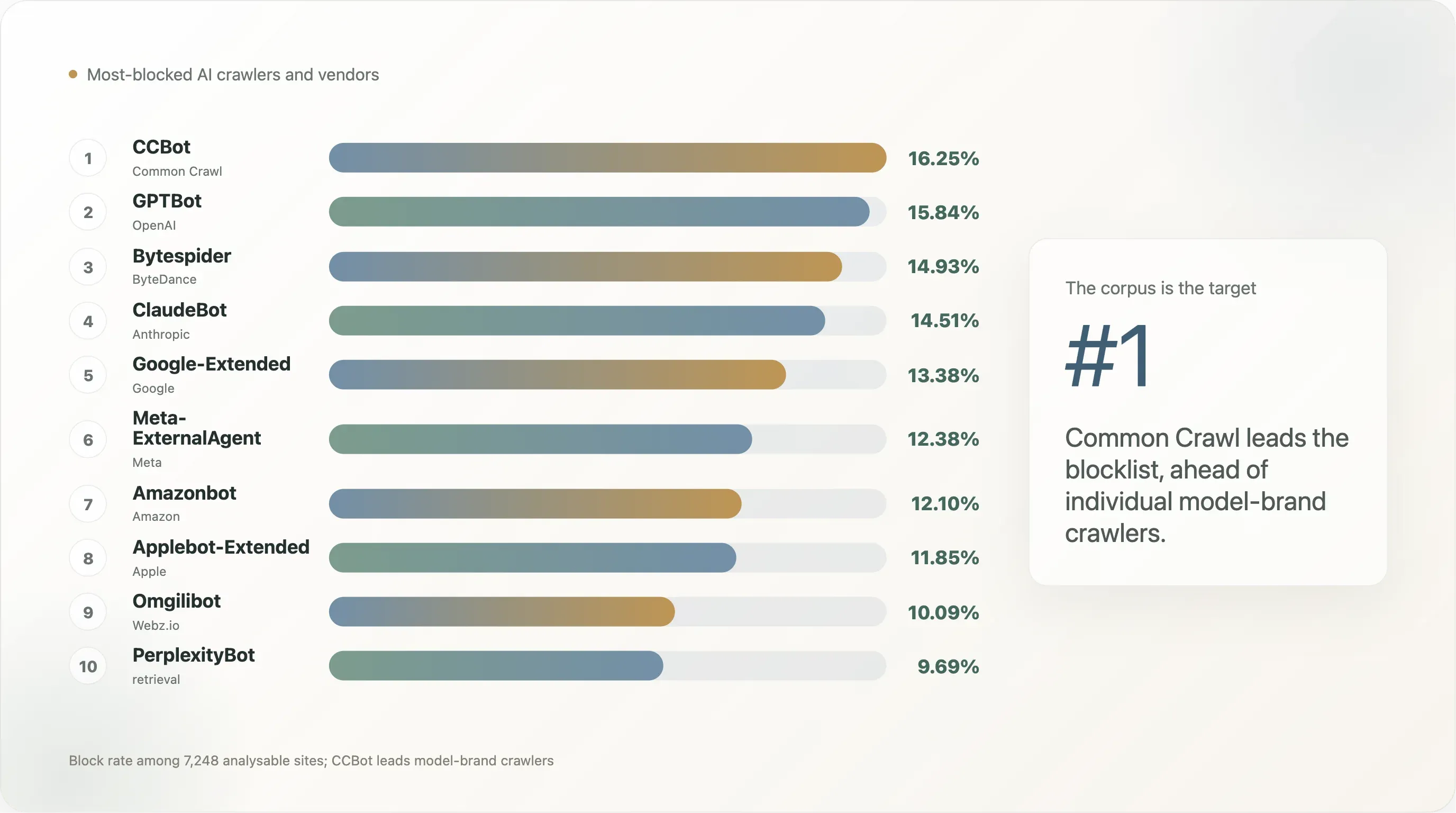
| 排名 | 机器人 | 阻挡率 | 明确规则率 |
|---|---|---|---|
| 1 | CCBot(Common Crawl) | 16.25% | 12.90% |
| 2 | GPTBot(OpenAI) | 15.84% | 12.72% |
| 3 | Bytespider(ByteDance) | 14.93% | 11.35% |
| 4 | ClaudeBot(Anthropic) | 14.51% | 11.13% |
| 5 | Google-Extended | 13.38% | 10.18% |
| 6 | Meta-ExternalAgent | 12.38% | 8.95% |
| 7 | Amazonbot | 12.10% | 8.66% |
| 8 | Applebot-Extended | 11.85% | 8.72% |
| 9 | Omgilibot | 10.09% | 5.31% |
| 10 | anthropic-ai(已弃用) | 9.99% | 6.55% |
| 11 | cohere-ai | 9.89% | 6.42% |
| 12 | PerplexityBot | 9.69% | 6.40% |
| 13 | Diffbot | 9.44% | 5.95% |
| 14 | ChatGPT-User(推理) | 8.90% | 5.73% |
| 15 | YouBot(推理) | 7.77% | 4.29% |
| 16 | OAI-SearchBot(推理) | 6.83% | 3.66% |
| 基线 | Googlebot | 2.18% | — |
| 基线 | Bingbot | 2.27% | — |
这张表传达的核心意思是:公众网页最先封锁的机器人,并不是某个模型品牌,而是语料本身。 Common Crawl 的 2,500 亿网页档案,是 GPT-3、GPT-4、Llama 1 / 2 / 3、Falcon、Mistral、BLOOM,以及 2020 年以来大多数开源权重模型最主要的训练输入。一个想要“退出下一代前沿模型训练”的站点,最优策略是先禁掉 CCBot——一旦你不在 Common Crawl 里,实际上就等于被免费排除在开源训练流水线之外。GPTBot 和 ClaudeBot 排在第二和第三,因为它们是两个商业产品的可见前端;而语料层 UA 才是结构性目标。
表里排名更靠后的 AI 机器人同样有信息量。Omgilibot 的阻挡率达到 10%,对于一个大多数读者可能从没听过的机器人来说,这个数字异常高。 它由 Webz.io 运营,是一个向 LLM 运营方出售网页档案的内容数据中介,而且有相当多的新闻机构已经开始在文件里点名它。AI2Bot 的 6.7%(以及 Squarespace 站点上的相应 Ai2Bot-Dolma 规则)说明学术界的 LLM 采集也开始被出版商标记——而这些出版商并不一定会把“非营利研究爬虫”和“商业爬虫”区分得很清楚。
推理机器人组——ChatGPT-User、OAI-SearchBot、YouBot、Perplexity-User——比训练机器人组低了 4–8 个百分点。这个差距,正是一个长期存在的政策问题的答案:是的,高流量网站确实会区分“为未来模型训练收集数据的机器人”和“现在就为回答用户问题而做实时检索的机器人”。它们不总是区分(兜底规则当然不会),但有相当一部分站点会写出专门针对训练侧的规则。
发现 5——14% 的站点阻止 CCBot,同时保留 Googlebot 访问——“封语料、保搜索”模式
在前 10k 中,采用最广泛的选择性规则是:
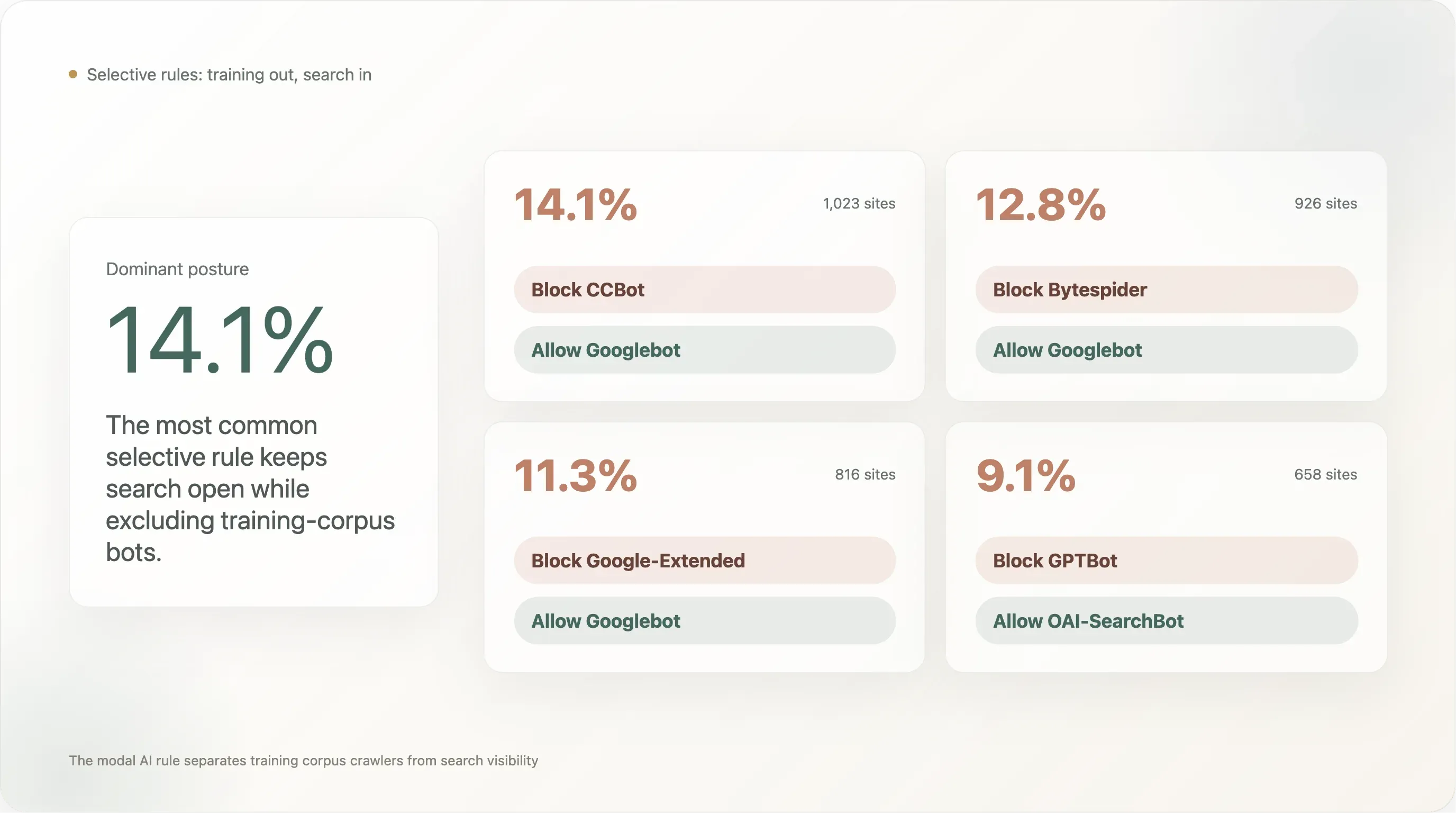
| 规则模式 | 站点数 | 占可分析样本比 |
|---|---|---|
阻止 CCBot,允许 Googlebot | 1,023 | 14.11% |
阻止 Bytespider,允许 Googlebot | 926 | 12.78% |
阻止 Google-Extended,允许 Googlebot | 816 | 11.26% |
阻止 GPTBot,允许 OAI-SearchBot | 658 | 9.08% |
阻止 GPTBot,允许 ChatGPT-User | 525 | 7.24% |
阻止 CCBot,允许 PerplexityBot | 519 | 7.16% |
阻止 anthropic-ai,允许 ClaudeBot | 59 | 0.81% |
最常见的模式(14.1%)是“阻止 Common Crawl,但保留 Google 搜索可见性”。第二位(12.8%)是“阻止 Bytespider,但保留 Google 搜索可见性”——也就是封掉字节跳动这个有风险标记的爬虫,同时保留合法搜索基线。第三位(11.3%)是“阻止 Google 自己的 AI 训练 UA,但保留 Google 的搜索 UA”,这正是 Google 为 Google-Extended 设计的用途:出版商可以退出 Bard / Gemini 训练,但不会失去搜索排名。
这三个数字合在一起,描述了前 10k 网络上的主流政策姿态:阻止训练语料机器人,保留搜索和推理机器人。“阻止训练,但允许这家 LLM 自己的实时检索 UA”这种少数模式——比如 GPTBot ✗ / ChatGPT-User ✓,占 7.2%——确实存在,但它比语料层的切分要少。
anthropic-ai / ClaudeBot 这一行只有 0.81%,反映的是 Anthropic 在 2024 年弃用 UA 后的结果:ClaudeBot 现在同时承担训练和推理,导致 Claude 过去那个由 anthropic-ai 允许的“阻止训练、允许引用”的清晰表达方式不再存在。这大概是 2024–2025 年最少被讨论的 UA 设计决策——它直接从 robots.txt 中移除了一整类政策表达。
发现 6——新闻细分:按国家和语言看
如果按国家代码顶级域名(ccTLD)来切新闻类别——注意这表示的是 .de 代表德国新闻、.fr 代表法国新闻,而不是所服务的语言——那么新闻内部的差异,比新闻与其他行业之间的差异还要大:
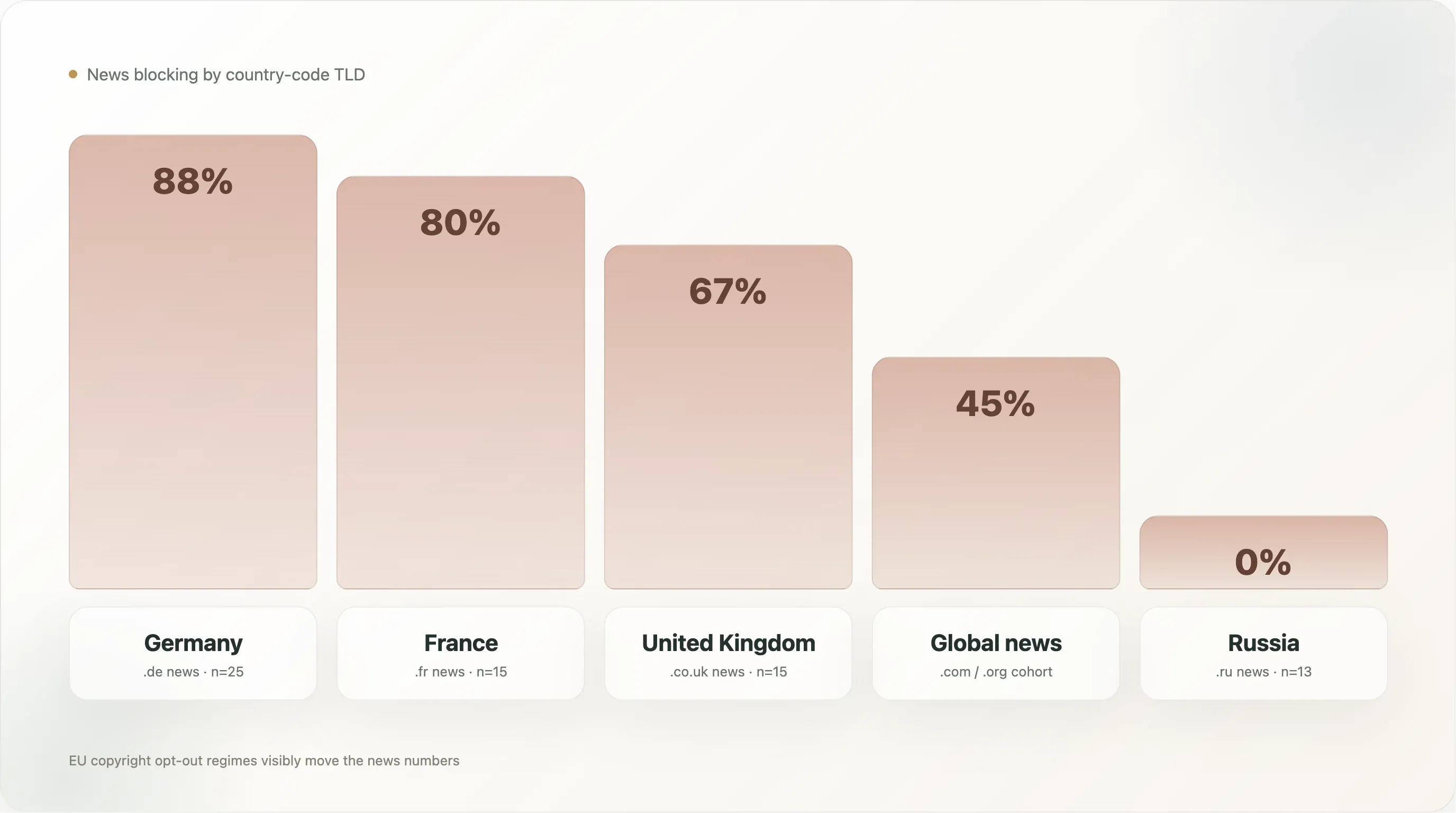
| 国家(仅新闻) | n | 任意 AI 阻挡 | 明确阻挡 |
|---|---|---|---|
🇩🇪 德国(.de) | 25 | 88.0% | 88.0% |
🇫🇷 法国(.fr) | 15 | 80.0% | 80.0% |
🇬🇧 英国(.co.uk) | 15 | 66.7% | 53.3% |
🇪🇸 西班牙(.es) | 5 | 60.0% | 60.0% |
🇮🇹 意大利(.it) | 13 | 53.8% | 53.8% |
全球新闻(.com/.org/等) | 500 | 45.0% | 42.8% |
🇵🇱 波兰(.pl) | 7 | 42.9% | 42.9% |
🇯🇵 日本(.jp) | 12 | 25.0% | 25.0% |
🇷🇺 俄罗斯(.ru) | 13 | 0.0% | 0.0% |
🇬🇷 希腊(.gr) | 6 | 0.0% | 0.0% |
德国新闻在整个数据集中阻挡率最高,达到 88%,而且 88% 都是明确阻挡——前 10k 里几乎没有德国新闻站点会让 AI 训练爬虫进入其档案。这个群组由 Spiegel、Bild、Welt、Zeit、FAZ、Süddeutsche、Heise、Golem、Stern、Focus 领衔——整套德国主流出版体系,再加上一些独立写规则的科技媒体。其背后的政治基础十分厚实:德国出版商集体维权组织 VG Media 一直是欧盟 AI 版权诉讼中最积极的原告群体,而欧盟指令第 4 条在德国法中被落实为 §44b UrhG,并明确包含机器可读退出语言。等 AI 厂商真正到场时,德国出版商已经是各国群体里最适合把这种法律姿态翻译成 robots.txt 规则的。
法国新闻 80% 紧随其后。 法国的法律环境相似(指令 2019/790 已转化为法国法),群体行为也类似——lemonde.fr、lefigaro.fr、liberation.fr、lequipe.fr、20minutes.fr、ouest-france.fr 都在阻挡,其中 Le Monde 的文件还额外引用了法国《知识产权法典》第 L 342-1 条的数据库生成者权利,作为并行的国内法律依据。法国还有一个额外变量:巴黎商业法院在 2024 年的一项裁定中认定,基于 robots.txt 的退出足以构成第 4 条所需通知;这给出了其他司法辖区尚未拥有的直接判例支持。
英国 67% 略低,原因是几家主要英国出版商(thesun.co.uk、dailymail.co.uk、mirror.co.uk)使用的是 User-agent: * 的全拒绝块,而不是 AI 专门规则,这把“明确”数字拉低到了 53%。总体效果并没有变——这些站点就是不允许 AI 爬取——只是它们的表达方式是“除了这份搜索引擎白名单,其他机器人都不行”,而不是按名字点名 AI 机器人。法律支架也更弱:脱欧后,英国继承了第 4 条的逻辑,但对应的国内判例要薄得多。
俄罗斯新闻 0% 是最出人意料的一行。样本中的 13 个俄罗斯新闻站点(dzen.ru、rbc.ru、ria.ru、kommersant.ru、tass.ru、lenta.ru、gazeta.ru、interfax.ru、kp.ru、tass.com 等)——没有一个阻止任何 AI 爬虫。最可能的解释是:俄语 LLM 训练主要由 Yandex 自家的 GPT 类模型主导(它们使用的是 Yandex 内部爬虫,而不是 Common Crawl),俄罗斯版权环境也没有形成类似第 4 条的等价物;更重要的是,俄罗斯头部出版商并不把西方 LLM 视为主要问题(美国出口管制本来就限制了 OpenAI/Anthropic 在俄罗斯的服务),而把 Yandex 视为国内利益相关方,而非对手。政策姿态本身就完全不同。
日本新闻 25% 则是第三种模式。日本国内版权法中有明确的文本与数据挖掘例外(日本版权法第 30-4 条,2018 年修订),其宽松程度甚至高于欧盟指令第 4 条——它允许出于“非享受”目的进行 TDM,包括 AI 训练,而且不要求权利人同意。日本出版商对退出的法律抓手更少,因此相应的 robots.txt 比例也更低。那 25% 仍在阻挡的,大多是最大、最国际化的出版商(asahi.com、nikkei.com),它们的定位更偏国际市场,而非纯国内。
这组跨国新闻数据,是报告中最清晰的证据,说明 真正推动 AI 阻挡变化的是法律环境,而不是技术或行业经济。 欧盟新闻群组聚集在 54% 到 88% 之间;非欧盟新闻群组(俄罗斯、日本、全球 .com 群组)则从 0% 到 45% 不等。88% 的峰值出现在第 4 条落实最成熟的国家;0% 的底部则出现在几乎没有 AI 政策法律的国家。
发现 7——欧盟 vs 其他地区:相差 16 个百分点
把国家视角再往上提一层,欧盟与非欧盟的整体差距非常明显:
| 地区 | n | 任意 AI 阻挡 | 明确阻挡 |
|---|---|---|---|
欧盟 ccTLD(.fr、.de、.es、.it、.nl、.pl、.se、.dk、.fi、.be、.at、.cz、.hu、.ro、.gr、.pt、.ie、.sk、.bg) | 617 | 35.2% | 33.9% |
非欧盟国家 ccTLD(.uk、.jp、.kr、.cn、.ru、.br、.in、.au、.mx、.ca、.tr、.ar、.cl、.co、.pe) | 897 | 17.2% | 13.6% |
全球(.com、.net、.org 等) | 5,734 | 19.2% | 15.7% |
欧盟 ccTLD 站点阻挡 AI 的比例,是非欧盟国家群组的 两倍,几乎也是全球 .com 基线的 两倍。这个差异在欧盟成员国之间相当一致(并不是某一个国家拉高平均值),在各行业之间也同样一致(.de 新闻 88%、.de SaaS 约 12%、.de 电商约 25%——全都高于全球对应行业)。
我们在前 10k 中找到了 275 份 robots.txt,其注释里 明确引用了指令 2019/790——约占可解析样本的 3.8%。这个群体以欧盟出版商为主,但范围并不止于此:一些美国新闻品牌(尤其是 NYT,它直接引用了“EU Directive 第 4 条”)、部分英国站点,以及少数规模较大的欧洲电商站点,也都复用了这套法律语言。另有 87 份文件明确写了 “TDM” 或 “text and data mining”。460 份文件里,即使没有引用具体法条,也包含某种版权保留语言(例如“明确退出”“保留所有权利”“禁止商业用途”“禁止机器学习”)。
这张切片里还有两个更细的观察:
欧盟效应并不只发生在新闻行业。 在固定新闻变量后,欧盟的非新闻站点仍然以更高比例阻止 AI(大约 28% 对 14%)。有一小部分但真实存在的欧盟 SaaS、电商、学术站点,已经把第 4 条框架内化到了自己的行业场景里。
欧盟风格的语言正在成为事实上的全球模板。 Cloudflare 托管的 robots.txt 模板——全世界都在用——在其标准条款里直接引用了 “ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790”。一个美国站点只要打开 Cloudflare 的“Block AI Bots”开关,即使它自己未必意识到,也是在主张一种欧盟法定的权利保留。这是我们发现的更有意思的政策扩散现象之一:一个欧洲法律概念,正通过一家美国基础设施提供商的产品界面被全球化。
发现 8——模板与模板来源
在 6,638 个返回可解析 robots.txt 的站点里,模板来源分布如下:
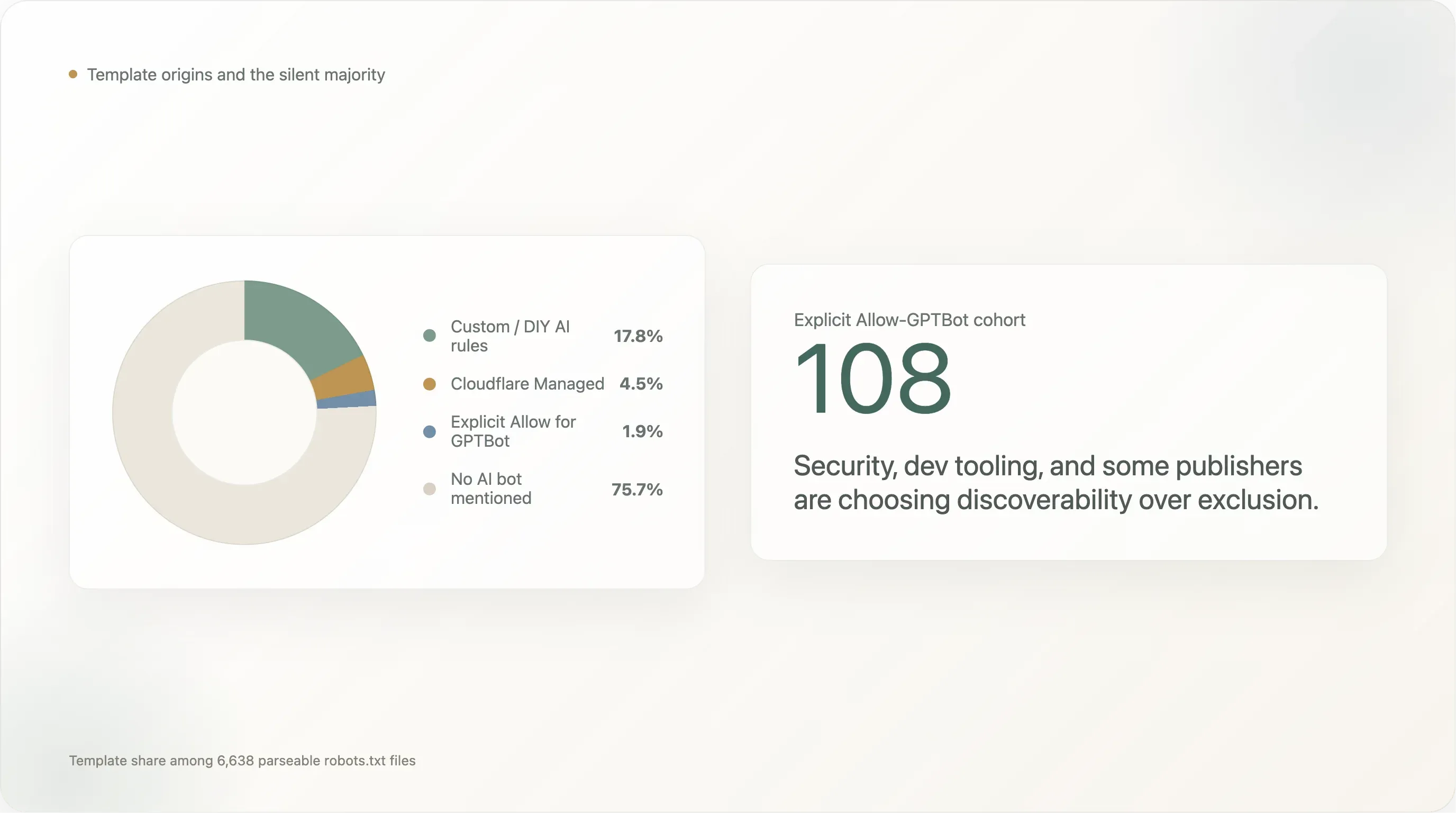
| 模板 | 站点数 | 占比 |
|---|---|---|
| 未提及任何 AI 机器人(默认 Shopify 风格、Yoast、或完全手写但未考虑 AI) | 5,024 | 75.7% |
| 自定义 / DIY AI 规则 | 1,183 | 17.8% |
Cloudflare 托管(Content-Signal: search=yes,ai-train=no) | 302 | 4.5% |
显式对 GPTBot 使用 Allow: / | 124 | 1.9% |
| Squarespace 默认模板(路径限制块里列出 28 个 AI UA) | 5 | 0.1% |
DIY 规则以 17.8% 领先。 这批自写阻挡者主要来自所有社交媒体平台(facebook.com、twitter.com、linkedin.com、whatsapp.com、tiktok.com、snapchat.com、pinterest.com、x.com、chatgpt.com 本身)、最大的电商站点(amazon.com、amazonvideo.com)、主要新闻品牌(nytimes.com、cnn.com、bbc.com、theguardian.com、forbes.com、reuters.com、bbc.co.uk、t-online.de、weather.com)、关键流媒体 / 媒体站(netflix.com、vimeo.com、soundcloud.com、imdb.com),以及一长串专业服务类站点(canva.com、medium.com)。
Cloudflare 托管占 4.5%——在曲线最前端,这个比例比我们采样窗口外的长尾情况更低,但又高于前 1000 名顶端的采用率。模板在排名 1001–10000 的区间里最常见(4–5%),而在曲线最前端几乎看不到(前 100 名:只有 1 个站点使用;101–1000 名:5 个站点)。大体量全球站点更倾向于自己写规则;长尾站点则使用开关模板。
几个值得注意的 Cloudflare 托管站点:cloudflare.com 自己就在用这个模板,逻辑上完全一致(Cloudflare 正在自己的域名上“狗粮”自己的产品)。theatlantic.com 也在用这个模板——它是我们找到的唯一一个没有自写规则的美国头部新闻品牌。spankbang.com 也在用这个模板——这是采用 Cloudflare 注入式 AI 封锁的最高排名成人站点。linktr.ee 也在用这个模板,通过单一厂商决策就把 Linktree 托管的创作者经济整体从 AI 训练里排除掉。launchpad.net、nexusmods.com、vinted.fr、cookielaw.org、rustdesk.com,以及一长串较小的媒体属性站点,共同构成了可见的 Cloudflare 托管群体。
Cloudflare 的采用模式,是我们见过最具体的证据,说明“网页的 AI 政策”有相当一部分其实是基础设施提供商在决定。绝对占比不大(4.5%),但结构意义很强:这个模板就是 Cloudflare 默认提供的模板,而且未来 12 个月默认开启的趋势是向上的。如果 Cloudflare 把新账户默认切换成开启状态,那么全球封锁率会明显上升,而单个出版商甚至不需要做任何决策。
Squarespace 的默认模板(前 10k 里只有 5 个站点,但在我们的样本之外还有更大群体)则是另一种模式:Squarespace 会发布一份 robots.txt,一次性列出 28 个 AI 机器人,但这些机器人继承的是 User-agent: * 的路径限制,而不是整站封禁。AI 爬虫仍然可以抓 /、首页、产品页、博客页,只是不能访问 /config 或 /account。我们之前已经指出,这正是第三方扫描 Squarespace 站点时出现“AI 被阻挡”误判的来源;在这里也同样适用。
发现 9——AI 政策在排名分布上非常均匀
这类研究的传统直觉是:访问量最高的网站应该会采取最激进的 AI 政策——它们最担心训练造成的流量替代,法律能力最强,也承受最多公开关注。但数据并不支持这个直觉。
| 排名区间 | n | 任意 AI 阻挡 | 明确阻挡 | Cloudflare 托管 |
|---|---|---|---|---|
| 前 100 | 67 | 22.4% | 17.9% | 1 个站点 |
| 101–1,000 | 598 | 22.9% | 19.2% | 5 个站点 |
| 1,001–5,000 | 2,810 | 19.0% | 15.3% | 99 个站点 |
| 5,001–10,000 | 3,773 | 20.8% | 17.8% | 197 个站点 |
四个区间都落在 19% 到 23% 之间。前 100 名的激进程度,并不比 5001–10000 名的长尾更高。这个头条率,似乎是 2026 年公共网络的属性,而不是任何单个网站有多大或多显眼的信号。
有两个因素在起作用。第一,曲线头部主要由基础设施 / SaaS / 搜索 / 门户类域名(微软、Apple、Google 等)构成,而它们本身的 AI 阻挡率就较低。第二,长尾里有更高比例的地区性新闻出版商和欧盟法域站点——正如发现 6 和 7 所示,它们的 AI 阻挡比全球平均更激进。两者大致相互抵消,最后就形成了一个很均匀的头条数字。
Cloudflare 托管这一列会随排名变化。前 1000 名只有 6 个 Cloudflare 托管站点(1.0%);而 1001–10000 名则有 296 个(5.7%)。大站自己写规则;长尾用厂商开关。这是数据里唯一真正和排名相关的信号,也说明 当你沿着流量曲线从网站顶端往长尾走时,厂商设定而不是出版商设定的 AI 政策占比会稳步上升。 我们预计这种梯度会继续延伸到前 10 万、甚至更远。
发现 10——五种解剖:当 robots.txt 真正成为政策时,它长什么样
数字能描述数据集的结构;但“公共网络上的 AI 政策”真正的性格,最好通过阅读具体文件来理解。下面有五个值得细看,它们覆盖了整个政策光谱。
解剖 1——《纽约时报》(nytimes.com)
nytimes.com/robots.txt 的前 14 行:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.这是把 robots.txt 当成法律证据来写。这个文件的结构,已经足以作为 NYT v. OpenAI 相关诉讼中的证据。它提到“欧盟指令第 4 条”——而且是由一家美国出版商写出的——这很好地说明了发现 7 中的现象:欧盟的法定框架正在渗入全球公共话语。它明确禁止“创建或提供归档或缓存数据集”,这显然是在直接指向 Common Crawl。该文件长达 60 多行,针对 GPTBot、OAI-SearchBot、ChatGPT-User、anthropic-ai、ClaudeBot、CCBot、Google-Extended、Applebot-Extended、Bytespider、Diffbot、Meta-ExternalAgent、Amazonbot、Omgili、Omgilibot 以及其他半打机器人都单独写了 Disallow: /——每个命名机器人都有自己的禁令。
解剖 2——《明镜周刊》(spiegel.de)——分区级 AI 许可
Der Spiegel 是我们在整个数据集中找到的、操作上最成熟的 robots.txt。相关区块如下:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /注释的意思是“对 OpenAI 搜索爬虫进行试运行式的指定栏目放行”。Spiegel 为 OpenAI 的推理 UA 白名单放行了七个具体内容类别——国际新闻、合作、健康、家庭、旅行、心理学、生活方式——同时屏蔽其他一切。政治版块、德国国内新闻和调查报道都被明确排除。Common Crawl、Bytespider、Cohere、Webzio-Extended,以及其他训练 UA 在文件更下方都被完整 Disallow: /。
这就是把 robots.txt 当成栏目级编辑政策来写。其背后的隐含理论是:生活方式内容的训练替代风险更低,而被推理引用的收益更高,所以 Spiegel 允许 AI 呈现这些栏目;政治与调查内容才是护城河,因此 AI 被排除。我们在其他地方没有见过这种模式。它意味着编辑、法务和基础设施团队之间存在相当程度的内部协同,而多数新闻编辑室还没达到这个程度。我们预计这种更细粒度的栏目级政策表达,会在 2026–2027 年间扩散开来——Spiegel 的文件基本上就是一个领先指标。
解剖 3——BBC(bbc.com)——政策声明体
BBC 的 robots.txt 以以下内容开头:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.BBC 给自己的 robots.txt 加了版本号(# version: ec59bd... 是一个 git 提交哈希),明确禁止 BBC 法务正在追踪的八种 AI 用法,并且以品牌一贯的口吻,用一行总结收尾。“在任何司法辖区内,明确退出任何法定例外”这句话,是一种有意的全球保留——意思是:我们不相信任何单一法律体系就能给我们想要的保护,所以我们要同时在所有地方主张退出。 这是整个数据集中最像“精修过”的 robots.txt,读起来更像新闻稿,而不是配置文件。
解剖 4——WordPress.org——明确欢迎
把上面的都拿来和 wordpress.org 对比:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org 明确对 9 个 AI 训练爬虫开放,其中包括三种(Bytespider、CCBot、anthropic-ai)在其他地方最常被阻止的机器人。其隐含逻辑是:WordPress 的文档和插件生态是一种公共利益,而当 AI 助手能够回答相关问题时,它的价值会进一步提升。每当有人问 Claude “我该怎么在 WordPress 里配置固定链接?”而 Claude 又是基于 wordpress.org/documentation/ 训练出来的,WordPress 的使命就被服务到了。WordPress 基金会显然认为,进入每个模型的训练语料库是一种战略上的正收益,于是就用文件的表达语法把这件事说了出来。
解剖 5——The Verge(theverge.com)——赞助内容的混合策略
还有一种值得展示的模式。The Verge 将 AI 规则写成了 Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp//sp/ 路径是 The Verge 的赞助 / 合作内容区。编辑内容被禁止用于 AI 训练;赞助内容则被允许。这里的经济逻辑很清楚:赞助商付费让自己的内容可被发现,包括通过 AI;而编辑旗舰内容才是真正的护城河。GPTBot 完全开放(大概是因为与 OpenAI 有直接合作关系),Applebot 作为搜索基线也完全开放,其余机器人则使用这种混合处理。这是我们找到的唯一一种“分层 AI 访问”结构。
这五个文件,定义了当前 robots.txt AI 政策的范围。前 10k 中的大多数文件都不像它们中的任何一个——它们要么沉默,要么用了厂商模板。那些长得像这些文件的,都是由认真决定“这个文件值得仔细阅读”的人写出来的。
关于文件规模还有一个补充:我们样本中 robots.txt 正文的中位数只有 858 字节——太小了,根本装不下一套有意义的 AI 政策。真正承载规则的是右侧长尾:1,005 个站点(15.3%)的文件大于 5 KB,273 个大于 20 KB,最大值达到 248 KB。460 份文件含有版权保留语言;275 份按名称引用了欧盟 2019/790。 在 2026 年,robots.txt 越来越像一个有版本记录、经过律师审阅的文件,而不是一行配置。
发现 11——108 个站点明确 欢迎 GPTBot
有一小群但非常可见的站点,会写 User-agent: GPTBot \n Allow: /——这是更常见的“Disallow GPTBot”的反向写法。我们样本中,共有 108 个站点在根路径上明确允许 GPTBot。按 Tranco 排名前 25 个如下:
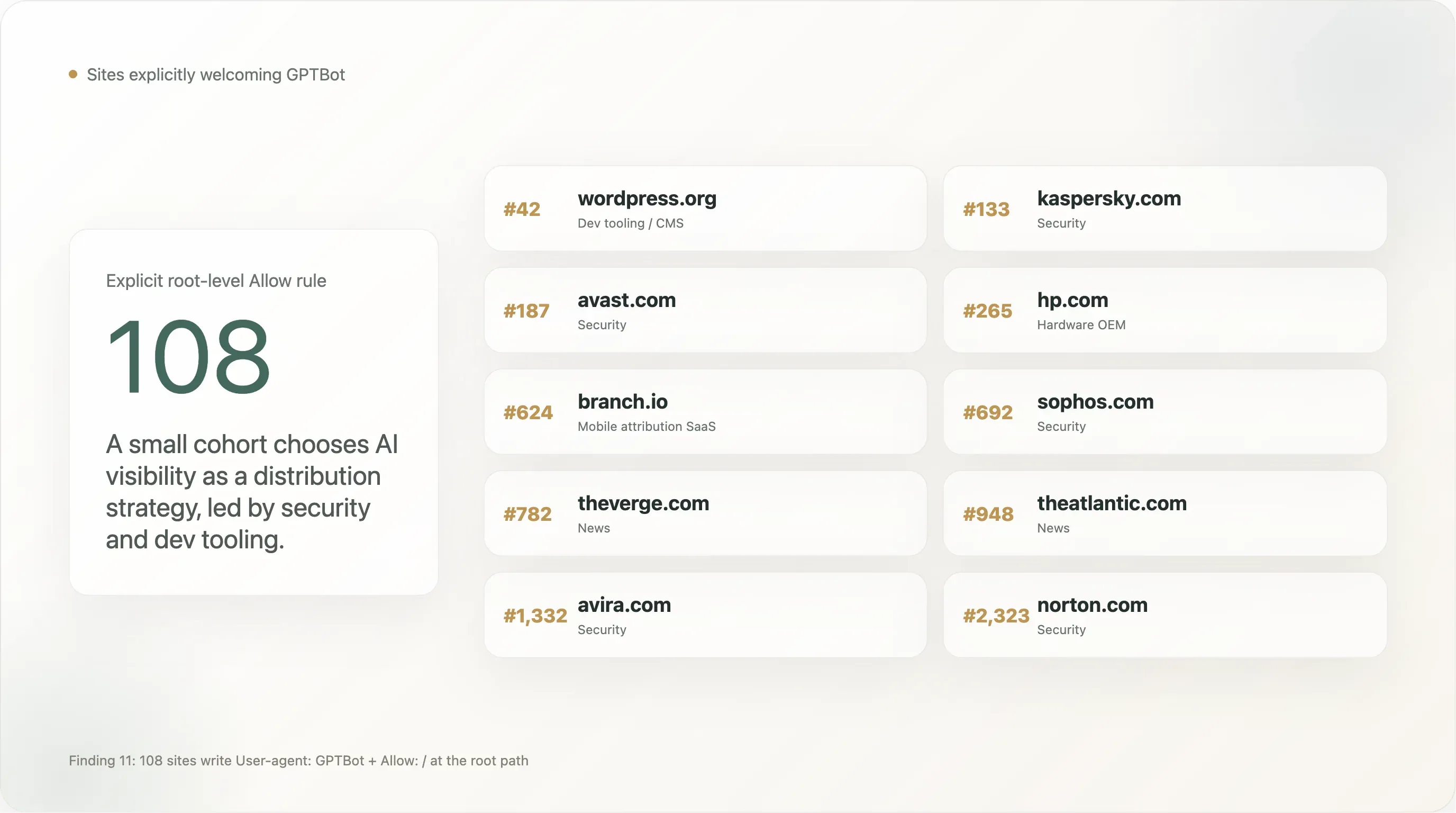
| 排名 | 域名 | 行业 |
|---|---|---|
| 42 | wordpress.org | 开发工具 / CMS |
| 133 | kaspersky.com | 安全 |
| 187 | avast.com | 安全 |
| 265 | hp.com | 硬件 OEM |
| 624 | branch.io | 移动归因 SaaS |
| 692 | sophos.com | 安全 |
| 782 | theverge.com | 新闻 |
| 905 | rambler.ru | 俄罗斯门户 |
| 945 | kleinanzeigen.de | 德国分类信息 |
| 948 | theatlantic.com | 新闻 |
| 1,092 | lge.com | LG 电子 |
| 1,300 | justdial.com | 印度本地搜索 |
| 1,332 | avira.com | 安全 |
| 1,412 | youm7.com | 埃及新闻 |
| 1,530 | goodreturns.in | 印度金融 |
| 1,621 | publi24.ro | 罗马尼亚分类信息 |
| 1,807 | geocomply.com | 合规 SaaS |
| 1,908 | nba.com | 体育 |
| 1,956 | oneindia.com | 印度新闻 |
| 1,974 | mindbox.ru | 俄罗斯 SaaS |
| 2,009 | thesun.co.uk | 新闻 |
| 2,126 | vox.com | 新闻 |
| 2,140 | mgid.com | 原生广告 |
| 2,314 | ninjarmm.com | IT 管理 SaaS |
| 2,323 | norton.com | 安全 |
几个模式很明显:
安全公司明显过度代表。 Kaspersky、Avast、Sophos、Avira、Norton、NinjaRMM 都明确允许 GPTBot。这是一个有意的分发策略:当用户在 ChatGPT 里问“Windows 机器上最好的杀毒软件是什么?”时,品牌是否进入模型训练语料,直接影响推荐结果。安全是少数几个 B2C 产品类目之一,AI 搜索已经在很大程度上替代 SEO 成为主要获客渠道,这些品牌也最先转向了这条路。我们预计其余安全行业会在 12 个月内跟进。
一些头部新闻品牌出现在“允许名单”里,而不是阻挡名单。 The Verge、The Atlantic、Vox、The Sun、NBA.com 都在其中。这并不矛盾——这些出版商似乎认为,能被 ChatGPT 搜索引用,比防止训练更有价值,于是写了显式 Allow 规则,用来防止未来由 CDN 或 CMS 造成的误封。与 NYT / Reuters / BBC / Forbes / Guardian 那种明确 Disallow 的姿态相比,两者都说得通;新闻行业并不是铁板一块。
The Sun 的出现尤其值得注意。 因为同一个站点在文件别处还使用了 User-agent: * 的全拒绝规则。The Sun 的政策,最合理的理解是:“AI 训练是禁止的,AI 搜索是允许的,我们已经特地把 GPTBot 从全拒绝规则里白名单放行,确保 ChatGPT 能回答引用 The Sun 的问题。” 这大概是 GPTBot-Allow 规则里最具法律工整性的写法——既有退出,也有对单一厂商的加入。
WordPress.org 是这份名单里最重要的一条。 全球开源 CMS 生态中,有相当一部分站点会指向 WordPress.org 获取文档,或者直接托管它的插件。WordPress Foundation 通过在 wordpress.org/robots.txt 中明确允许 GPTBot,实际上等于在说 WordPress 文档生态可供训练——这会连带影响 Claude、Gemini 和 ChatGPT 在回答 WordPress “怎么做”类问题时的表现。
完整 Allow-GPTBot 名单中的其余 83 个站点,是地区性新闻、小型安全厂商、非英语市场的分类信息平台,以及 B2B SaaS 的长尾。就我们所能判断的范围内,并不存在行业级的“Allow-GPTBot”协调——这个规则是一家一家站点自己决定采用的,决定理由都是“进入语料库就是战略位置”。
发现 12——llms.txt 在这个尺度上几乎只是个传闻
llms.txt 是一种面向 LLM 友好内容发现的提议替代文件格式(自 2024 年底以来由 Mintlify、Anthropic、Vercel 以及少数开发工具厂商推动),但在我们的样本里几乎看不到可见采用。
在 6,638 个返回可解析 robots.txt 的站点中,只有 83 个(1.15%)提到了 llms.txt——通常只是写成 Sitemap: https://example.com/llms.txt 一行。这比开发工具密集型的商业样本低了两个数量级;在那些样本里,Vercel 和 Mintlify 的默认配置会把采用率抬高很多。
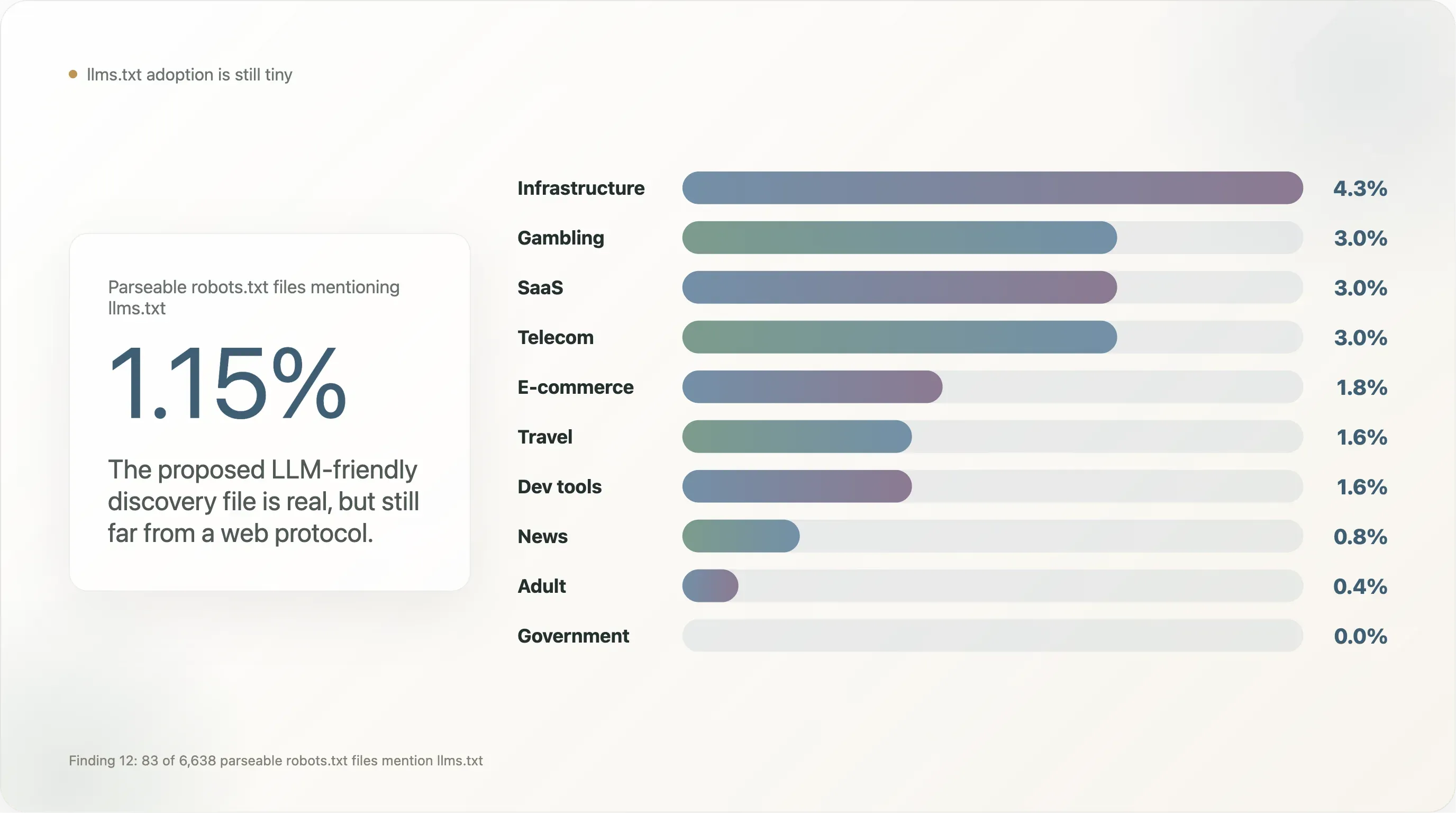
类别拆分如下:
| 行业 | n | 提到 llms.txt 的比例 |
|---|---|---|
| 基础设施 | 47 | 4.3% |
| 博彩 | 100 | 3.0% |
| SaaS | 369 | 3.0% |
| 电信 | 33 | 3.0% |
| 电商 | 224 | 1.8% |
| 旅游 | 64 | 1.6% |
| 开发工具 | 129 | 1.6% |
| 新闻 | 650 | 0.8% |
| 成人 | 254 | 0.4% |
| 政府 | 172 | 0.0% |
| 学术 | 268 | 0.0% |
| 搜索 | 12 | 0.0% |
llms.txt 主要集中在开发工具相关 SaaS、博彩(这类受监管行业对元数据层叠更熟悉,因此更快接受 robots.txt 的新词汇特性)、以及 B2B 电商。它在新闻和政府里几乎缺席——而这两个板块恰恰最活跃于 AI 政策讨论,也是标准要从“厂商实验”升级为“网络协议”所必须获得采用的地方。至少在目前阶段,llms.txt 是真实存在的,但规模仍然很小;到 2026 年底再做一次复查会很有价值。
llms.txt 面临的结构性问题在于,它没有经过任何 IETF 标准流程,也没有主要 AI 厂商承诺支持。robots.txt 有 30 年爬虫基础设施围绕它构建;llms.txt 没有。除非至少有一家大厂(OpenAI、Anthropic、Google、Cloudflare)正式宣布支持,否则这份文件基本上仍只是 Mintlify / Vercel 生态的一种营销产物。我们不认为 2026 年会发生本质变化。
发现 13——可访问性:robots.txt 对前两/三分之一的互联网仍然可读
还有一条本来不打算算作发现的旁观观察:前 10,000 个站点中,有 66% 对单一研究 IP 返回了可解析的 robots.txt,而且只有 7/10,000(0.07%)返回了 429 Too Many Requests。 这对 robots.txt 作为公共协议来说,是个好消息。
对比一下,两个月前我们在一个 1,008 域名的中端商业样本上跑了同样的流水线,结果有 52% 的解析域返回了 429——Shopify 和 Cloudflare CDN 对任何非主要搜索引擎 UA 都在激进限流。高流量网络友好多了:头部站点更可能具备 (a) 没那么激进的机器人管理层级,或者 (b) 针对已知研究爬虫的显式白名单,甚至两者兼有。
前 10k 中 21% 的 fetch_failed,主要来自 CDN 根节点(akamai.net、cloudfront.net、fastly.net、apple-dns.net、gtld-servers.net)——它们在 / 上根本没有网站服务。它们不是在封我们,而是没有东西可供提供。把这些排除后,真正“尝试读取但失败”的比例只剩下个位数。
这意味着,今后这份报告的后续版本——季度快照、同比比较——都可以在单机上低成本且可复现地运行。审计窗口在曲线顶端仍然是打开的。相反的情况出现在长尾和商业板块:那里 CDN 级限流已经事实上把 robots.txt 私有化了。我们预计这种分化会继续扩大:头部站点因为要被搜索引擎索引,所以会保持可读;长尾商业站点则会随着 Cloudflare 的反爬层级更激进地投放,变得更不可读。robots.txt 的公共可审计性,正在沿着“可见网络”和“运营保护网络”的分界线分裂。
IV. 这意味着什么
四个判断,按数据支持强度排序。
1. 互联网存在的是分行业 AI 政策,而不是统一的全网政策。 新闻与电信之间 12 倍的差距,压过了所有汇总数字。只说“X% 的网页在阻止 AI”而不按行业拆开,会高估 SaaS/政府/开发工具,低估新闻/旅游/社交。按行业拆分,才是唯一诚实的表达。
2. 欧盟版权指令第 4 条,是目前唯一明显在推动数字变化的法律体系。 欧盟 ccTLD 站点的 AI 阻挡率为 35%,而全球基线只有 19%。美国的诉讼(NYT 对 OpenAI、版权局 2025 年 1 月报告)已经改变了美国新闻群体,但没有改变更广泛的美国网络。欧盟框架还通过 Cloudflare 的模板向全球外溢,因为这个模板不管客户所在司法辖区,都在标准文案里引用指令 2019/790。
3. 两套并行的“AI 政策”正在被表达出来,而且彼此并不一致。 刻意手写的政策(17.8%,主要来自新闻 / 社交 / 旅游 / 电商)和继承而来的 Cloudflare 托管政策(4.5%)在实质上有重叠,但在合法性上不同。在 AI 运营方试图寻找法律理由无视 robots.txt 的世界里,“我们自己写过、审核过” 的抗辩,结构上会比 “我只是打开了开关” 更强。诉讼的激励机制,就是把政策从第二类推到第一类。
4. 出版商封的是语料,不是模型。 CCBot 以 16.3% 排在最高,甚至高于任何模型品牌机器人,这是最清楚的表述。阻止 OpenAI 并不会让出版商从训练中脱身;阻止 CCBot 才会。前 10k 中有 14.1% 的网页在封 CCBot 的同时保留 Googlebot。2026 年最典型的 AI 规则,就是“阻止训练,保留搜索”。
对考虑自己政策的站点来说: 主流姿态其实是沉默——前 10k 中 80% 对 AI 什么都没写。那 17% 写规则的站点大多偏向 Disallow,但有一小部分、而且在增长中的群体(以安全厂商为主的 1.5% 显式 Allow GPTBot 名单)正在反向选择公开加入。行业里没有共识,而且未来 12 个月也不会有。
对 AI 运营方来说: 当全球最大的一批站点里已经有 17% 明确手写机器人名字、而且 3.8% 的文件还按条款编号引用欧盟法规时,再继续坚持说 robots.txt 是一个语义含糊的遗留协议,已经越来越难站得住脚。是否尊重这些规则是商业决策;它们是否存在,如今已经是可验证的经验事实。
V. 展望:我们对 2026 年底的预期
数据里有三条已经可见的趋势:
Cloudflare 托管的份额会翻倍以上,很可能达到可解析前 10k 的 10%+。 Cloudflare 的路线图公开讨论过新账户默认开启 Block AI Bots。如果这个开关真的默认开启,全球阻挡率会在没人单独做决定的情况下上升 5–8 个百分点。我们会在排名 5001–10000 区间里,Cloudflare 托管占比超过当前 5.7% 时,确认这件事正在发生。
分区级 AI 政策(Spiegel 式)会在主要新闻旗舰中扩散。 经济逻辑——让 AI 引用低风险内容,保护真正的护城河内容——已经足够有说服力,所以我们预计到 2026 年底,至少会有另外 10 家旗舰新闻室推出分区级规则。优先关注德国和法国的中型媒体;那里的法律框架最鼓励试验。
显式 Allow GPTBot 群体会增长,主要由 B2B SaaS 和开发工具推动。 当 AI 搜索像现在在安全领域那样,成为软件厂商可量化的获客渠道时,越来越多的 CMO 会写 User-agent: GPTBot \n Allow: /,以避免意外的过度封锁。我们预计这 108 个站点的名单,到年底大致会翻倍。
我们不预期的变化是:沉默多数会有实质性下降。那 80% 对 AI 什么都不说的网站,里头包含了政府、电信、基础设施、B2B SaaS 等行业——这些行业既没有经济理由写规则,也没有法律压力必须写。全网统一 AI 政策不会到来。
VI. 局限性
- 单快照偏差。 抓取发生在 2026 年 5 月初的 36 小时窗口里。前 100 名网站的文件每天都可能变化;头条数字每个季度预计会有 1–2 个百分点的漂移。
- 行业分类缺口。 在四层分类器之后,10,000 个站点里仍有 6,593 个留在
unknown。行业百分比在样本量大时很稳(新闻:650,流媒体:440,SaaS:369,学术:268,成人:254,电商:224,政府:172,金融:129,开发工具:129),但在 n<30 时噪声更大。国家新闻切片也同样有限——DE/FR/UK 的 n 都 ≥15,而韩国/瑞典/捷克则基本靠 n=20–25 支撑。 robots.txt是自愿协议。Disallow是请求,不是屏障。Bytespider、PerplexityBot等机器人都已有无视规则的文档记录。我们测的是政策声明,而不是政策执行。- 单一美国 IP 审计。 我们无法读取 21% 的解析域。其中大部分是没有网页服务的 CDN 根节点;也有小部分是 CDN 在到达源站前就把我们标记了。这会让样本略微偏向旧基础设施,并对按国家来源地做地理封锁的站点不利。
- Tranco 列表语义。 Tranco 会做稳定性过滤;它不是严格的用户行为排名。总体数字对列表选择很稳,但具体排名位置并不稳。
- 没有流量数据。 我们测的是
robots.txt政策,不是真实 AI 机器人吞吐量。政策和流量并不总是一致。
VII. 复现方法
用于生成这份报告的所有材料,都在交付文件夹里。
- tranco_top10k.csv —— 输入列表
- out/sites.csv —— 域名 × 排名 × 行业 × 语言 × robots.txt 状态(10,000 行)
- out/fetch_meta.csv —— 每个域名的抓取结果(状态、协议、字节数、错误)
- out/bot_status.csv —— 域名 × 机器人网格(250,000 行:是否阻挡、是否有规则、抓取状态)
- out/site_meta.csv —— 每个站点一条分析记录(模板、摘要布尔值)
- out/analysis.json —— 报告中引用到的所有指标
- 01_fetch_robots.py、02_classify.py、03_parse_and_analyze.py —— 完整 Python 流水线
欢迎就方法论修正、数据集问题和后续分析与我们联系: support@thunderbit.com。本报告独立于 Thunderbit 的任何商业立场发布;我们打造的是一款 AI 驱动的网页爬虫,因此我们在结构上希望 robots.txt 继续成为公共网络上一个有意义、机器可读的契约。本报告中的数据自成体系。——Thunderbit 研究团队,2026 年 5 月。