

机器学习对高质量标注数据的需求,从来没有像今天这么高。每次我和做新 AI 模型的团队交流——不管是销售预测、产品推荐,还是客户情感分析——都会听到同样的痛点:手工给数据打标签太慢、太贵,而且说实话,也挺让人心力交瘁。我见过不少项目因为一直等不到足够多的标注样本,拖了好几周,甚至几个月,才勉强能训练出一个像样的模型。要是标签还不一致?那我只能说,你模型的预测结果,可能跟我倒车入库的水平差不多,不太靠谱。
好消息是:借助机器学习进行自动数据标注,正在改变这一切。让 AI 承担最繁重的工作,不仅能加快标注流程,还能提升准确性和一致性——这两点,往往决定了你的 ML 项目是成功还是失败。在这篇指南里,我会带你了解自动数据标注的工作原理、它为什么对构建稳健模型如此关键,以及你如何借助 Thunderbit 这类工具搭建自己的自动标注流程——而且完全不需要写代码。
什么是借助机器学习的自动数据标注?
先拆开来看。借助机器学习的自动数据标注,指的是使用算法和 AI 工具,为原始数据自动分配标签(比如“垃圾邮件”或“非垃圾邮件”、“猫”或“狗”、“正面”或“负面”),而不需要人手逐条点击标注。你可以把它理解成:成千上万张旅行照片,如果手动一张张打标签,和用人脸识别自动按人物、地点,甚至情绪来分类,差别有多大。
传统的人工标注,顾名思义,就是人工逐条查看数据并赋予正确标签。它确实准确(至少有时候是这样),但速度慢、成本高,而且很难扩展。相比之下,自动标注会使用机器学习模型——这些模型先用少量人工标注数据训练好——然后为其余数据集预测标签。结果就是:标注更快、更一致,也更易扩展(GeeksforGeeks)。
对于企业用户来说,这意味着你可以用更少的人工重复劳动,更快地构建更好的模型。而在今天这个数据驱动的时代,这就是实打实的竞争优势。
用 Thunderbit 自动化数据标注 使用 Thunderbit 的 AI 网页爬虫,自动化你的数据标注流程——无需编写代码。 Get Started Free
为什么自动数据标注是高质量机器学习模型的关键
关键在于:你的标注数据质量,会直接影响机器学习模型的表现。俗话说得好,“垃圾进,垃圾出”。如果标签不一致或者有错误,模型学到的就是错误模式,预测结果自然也会受影响(DataCamp)。
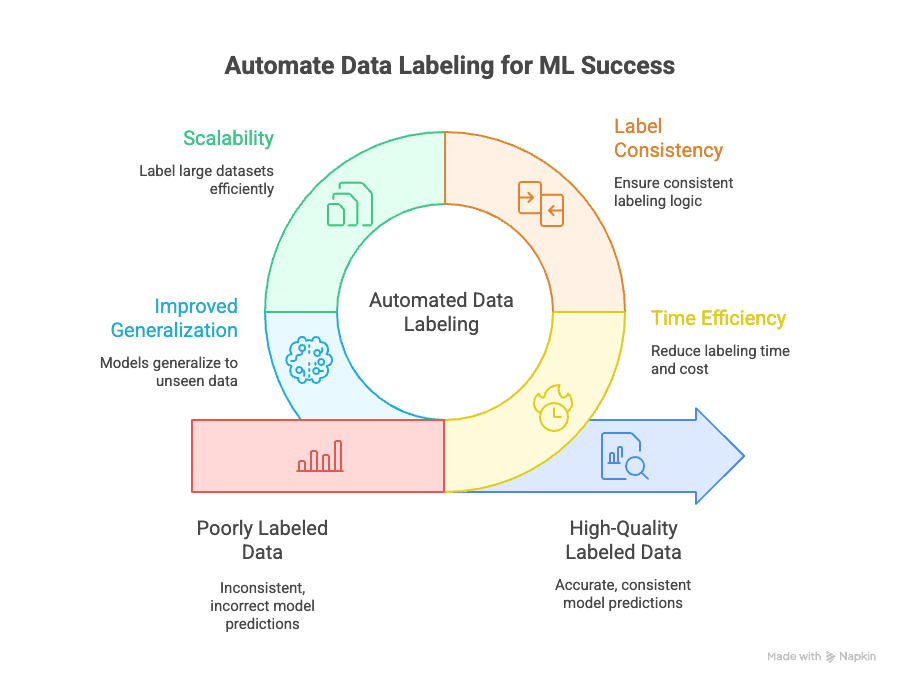
自动数据标注能解决几个核心问题:
- 时间效率: 人工标注可能会吞掉 ML 项目70% 的总时间和成本。自动化能把这部分压缩到很小,让你更快迭代和上线模型。
- 标签一致性: 机器不会疲倦,也不会分心。自动标注能确保每个数据点都按照同一套逻辑打标签,从而减少人为错误和偏差(GeeksforGeeks)。
- 可扩展性: 需要标注 10,000、100,000 甚至 100 万条数据点?自动化都能做到,而且不用雇一大批标注人员(Keylabs)。
- 更好的泛化能力: 一致且高质量的标签,能帮助模型更好地泛化到新的、未见过的数据,这也是机器学习的最终目标(Kili Technology)。
而且商业价值是实打实的:Keylabs 指出,与纯人工流程相比,结合 AI 辅助标注和人工复核的混合工作流,能将标注准确率提升高达 80%,这会直接带来更快的模型迭代,以及更可靠的下游预测。
手工标注与自动数据标注对比
我们直接放在一起看看:
| 因素 | 人工标注 | 借助机器学习的自动标注 |
|---|---|---|
| 速度 | 慢(大数据集往往要几周/几个月) | 快(大数据集只需几分钟/几小时) |
| 准确性 | 较高,但容易出现人为错误/不一致 | 较高,逻辑一致,错误更少 |
| 可扩展性 | 受限于人力资源 | 轻松扩展到数百万个数据点 |
| 成本 | 昂贵(劳动密集型) | 长期成本更低(Keylabs) |
| 最适合 | 小型、复杂或模糊的数据集 | 大型、重复性高或定义明确的数据集 |
人工标注依然有它的用武之地——尤其是处理边缘情况或模糊数据时——但对大多数业务场景来说,自动化才是更合适的选择。
借助机器学习进行自动数据标注的基本步骤
那自动数据标注到底是怎么运作的?下面是我推荐、自己也一直在用的一套端到端流程:
- 数据收集与预处理
- 特征提取与准备
- 使用机器学习进行自动标注
- 质量保证与人工复核
我们逐步来看。
第 1 步:数据收集与预处理
在你开始标注之前,先要收集并清洗数据。这可能包括从网站抓取商品列表、导出客户评论,或者从内部数据库收集图片。这里最重要的是质量:垃圾数据会带来垃圾标签,进而产生垃圾模型(Snorkel AI)。
最佳实践:
- 删除重复和无关条目
- 统一格式(日期、货币等)
- 处理缺失或不完整数据
第 2 步:特征提取与准备
接下来,你需要找出对标注任务真正有价值的特征。比如,如果你要给商品列表打标签,可能会提取价格、品牌、类别和描述等属性。在销售或营销场景中,这可能意味着从邮件里提取公司名称、联系方式或情感倾向。
业务示例: 使用 Thunderbit,你可以从网页中抓取结构化数据——比如商品规格、评论或联系方式——完全不用写一行代码。
第 3 步:使用机器学习进行自动标注
真正“魔法”发生在这里。你使用机器学习模型(先用一小批人工标注数据训练好),为剩余数据预测标签。常见方法包括:
- 监督学习模型: 先用已标注样本训练分类器,再用它给新数据打标签。
- 基于规则的标注: 针对简单场景使用预定义规则(例如“如果价格 > 1000 美元,就标记为‘高端’”)。
- 主动学习: 模型会把不确定的案例交给人类确认,并在过程中不断改进(GeeksforGeeks)。
- 迁移学习: 使用预训练模型,帮助在新领域中更快启动标注(GeeksforGeeks)。
结果就是:大规模、稳定、高质量的标签。
第 4 步:质量保证与人工复核
再好的模型也需要做“体检”。定期人工复核可以帮助发现边缘情况、模糊数据或模型漂移。实用的 QA 步骤包括:
- 随机抽取一部分已标注数据进行人工复查
- 将自动标签与“金标准”数据集进行对比
- 使用标注者一致性指标衡量一致性(Kili Technology)
如何使用 Thunderbit 实现借助机器学习的自动数据标注
现在我们来上手实操。Thunderbit 是一款面向业务用户的 AI 网页爬虫和数据标注工具——无需编写代码。你可以这样用它来自动化数据标注流程:
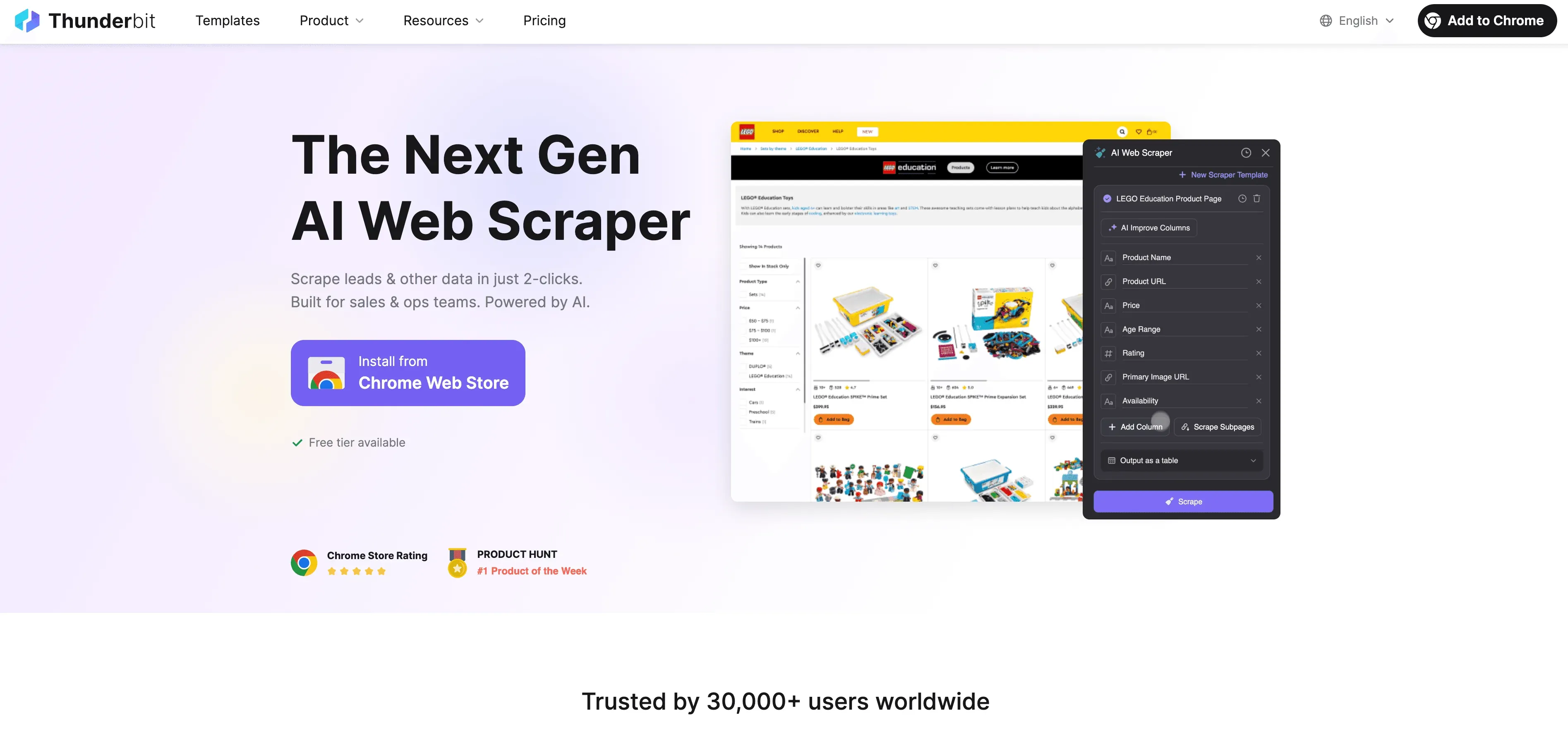
分步指南
- 抓取网站数据: 使用 Thunderbit Chrome 扩展 从任意网站收集结构化数据。只要打开扩展,选择数据来源,Thunderbit 的 AI 就会帮你建议最适合提取的字段。
- 定义标签指令: 用 Thunderbit 的自然语言提示词告诉 AI 该如何给数据打标签。例如:“将所有价格高于 500 美元的商品标记为‘高端’”或者“给带有正面情绪的评论打标”。
- 应用自动标注: Thunderbit 的字段 AI 提示词功能,可以让你自定义并细化标签分配方式——非常适合多字段或复杂标注任务。
- 导出已标注数据: 数据标注完成后,你可以直接导出到 Excel、Google 表格、Airtable 或 Notion,立刻用于模型训练或分析。
最棒的是?Thunderbit 专为销售、营销、运营等非技术用户打造。你完全不需要写代码,也不用去和复杂模板死磕。
Thunderbit 的自然语言提示词与字段 AI 功能
我最喜欢的功能之一,就是你可以直接用自然语言定义标签逻辑。想按地区给线索分类、按类别给产品打标,或者给包含紧急措辞的邮件加标记?只要把你的需求说出来,Thunderbit 的 AI 就会替你完成。
示例提示词:
- “将所有使用 .edu 邮箱的联系人标记为‘教育’类别。”
- “如果评论里提到‘快速发货’,就标记为‘正向配送体验’。”
- “按品牌和价格区间对产品分组。”
Thunderbit 的字段 AI 提示词还能让你更精细地控制:你可以为每一列定制标签逻辑、组合多条规则,甚至把标签翻译成多种语言。
子页面抓取与多字段标注
数据结构复杂?没问题。Thunderbit 的子页面抓取功能,可以让你从嵌套页面(比如商品详情页或作者简介页)中提取并标注数据,再把所有内容合并成一个结构化表格。你还可以一次性标注多个字段,进一步节省时间。
真实应用场景: 先从电商网站抓取商品列表,再逐个打开商品链接,提取并标注规格、评论和卖家信息——全部在一个工作流里完成。
结合多个数据标注工具,以提升准确性和效率
虽然 Thunderbit 已经能覆盖很多场景,但有时候你还是需要一些针对特定数据类型的专业工具——比如图像标注或视频标注。这时就轮到 Label Studio 或 Supervisely 这类平台上场了。
小技巧: 你可以先用 Thunderbit 处理网页数据提取和初步标注,然后把数据导出到 Label Studio 或 Supervisely,进行更高级的标注(比如图像边界框或逐帧视频标签)。这种多工具协同的方法,能让每个平台各尽其长,进一步提升准确性和效率(GeeksforGeeks)。
什么时候在 Thunderbit 之外使用专业工具
- 图像标注: 对于目标检测或分割这类任务,使用 Supervisely 或 Label Studio。
- 视频标注: 专业视频工具更适合逐帧标注和目标跟踪。
- 复杂的多标签任务: 将 Thunderbit 的结构化数据提取,与高级标注工具结合,效果最好。
最佳实践: 先用 Thunderbit 快速、可扩展地标注结构化和半结构化数据,然后按需要引入专业工具进行深度标注。
如何使用 AI 抓取 PDF 数据 了解如何使用 Thunderbit 的 AI 工具从 PDF 中提取并标注数据。 Get Started Free
借助机器学习进行自动数据标注的最佳实践
想把自动标注流程的价值发挥到最大?下面是我的几个核心建议:
- 先定义清晰的标签规范: 模糊的标签会导致数据不一致——一定要明确每个标签的含义。
- 从高质量种子集开始: 先手动标注一小批有代表性的样本,用来训练初始模型。
- 持续迭代优化: 用主动学习不断改进模型,把人工复核重点放在最难的案例上。
- 定期验证: 周期性抽查一部分标注数据,及时发现错误或漂移。
- 集成并自动化: 用 Thunderbit 这类工具,把数据收集、标注和导出串成一个完整工作流。
常见挑战及应对方法
自动数据标注也不是没有挑战。下面是最常见的问题和应对方式:
- 数据模糊: 使用清晰、详细的标签定义,并为边缘情况提供示例。
- 模型漂移: 用新的、经过人工复核的数据定期重新训练标注模型。
- 边缘案例: 建立人工复核流程,专门处理不确定或新出现的数据点。
- 集成问题: 选择像 Thunderbit 这样支持轻松导出到你常用平台的工具。
结论与核心要点
借助机器学习的自动数据标注,是当今最有效 AI 模型背后的秘密武器。它能节省时间、降低成本,更重要的是,能为你的模型提供稳定且高质量的标签,让模型发挥最佳表现。把 Thunderbit 这样的工具,与专业标注平台结合起来,你就能搭建出一个快速、准确、可扩展的标注工作流——不管你的技术背景如何。
准备亲自看看效果了吗?下载 Thunderbit,在下一个项目中试试自动标注,看看你的机器学习模型如何变得更聪明、更快。如果你还想了解更多技巧和最佳实践,欢迎去看 Thunderbit 博客 里的深度文章和教程。
常见问题解答
1. 什么是借助机器学习的自动数据标注?
就是使用 AI 和 ML 模型自动为数据分配标签,而不是让人工手动完成。这样可以加快标注速度、提升一致性,并且能扩展到大规模数据集。
2. 为什么标注质量对机器学习这么重要?
模型只能学习标签所编码的模式,所以不一致或错误的标签,会教给模型错误的信息。来自 Keylabs 等标注供应商的行业文章发现,AI + 人工的混合工作流,能比纯人工流程把标注准确率提升高达 80%——而这种提升会直接传导到模型表现上。
3. Thunderbit 如何帮助实现自动数据标注?
Thunderbit 让你可以用 AI 抓取并标注网页数据,支持自然语言提示词和可定制的字段逻辑——无需编写代码。它非常适合销售、营销和运营等业务用户。
4. 我可以把 Thunderbit 和其他标注工具一起用吗?
当然可以。你可以先用 Thunderbit 做结构化数据提取和初步标注,然后导出到 Label Studio 或 Supervisely 这类工具中,进行更高级的图像或视频标注。
5. 自动数据标注的最佳实践是什么?
定义清晰的标签规范,从高质量种子集开始,借助主动学习持续迭代,定期验证,并使用集成工具来简化工作流。
准备好自动化你的数据标注、给机器学习项目加速了吗?试试 Thunderbit,看看你能省下多少时间,以及多少烦恼。
了解更多:
试用 AI 网页爬虫,自动化数据标注 Get Started Free




