Wikipedia Search Result Scraper
Toplu veri çekmek mi istiyorsun? Thunderbit’i ücretsiz dene.








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
Collect Topic Data from Wikipedia Search Pages

Analyze and Organize Large Sets of Wikipedia Results
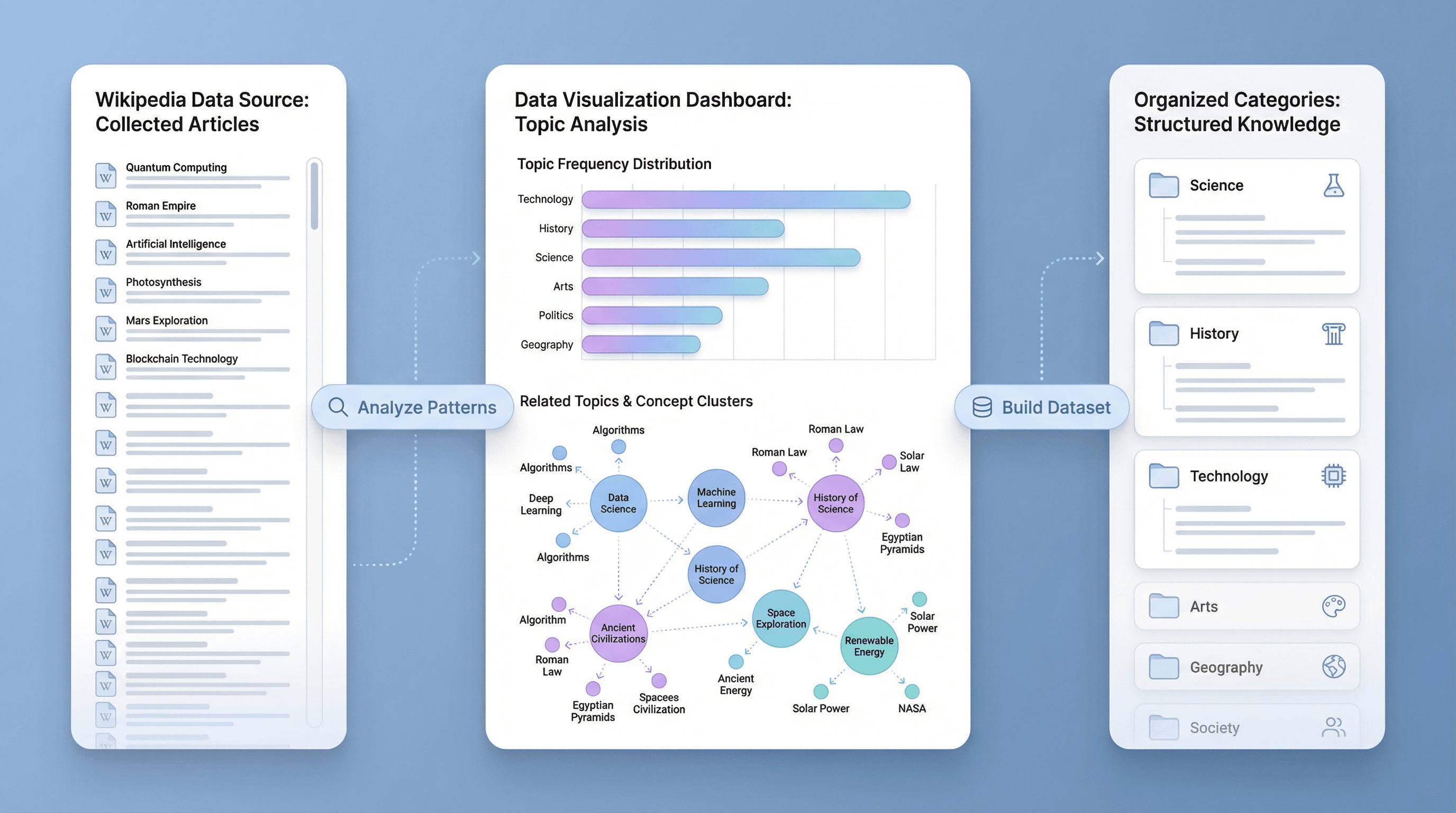
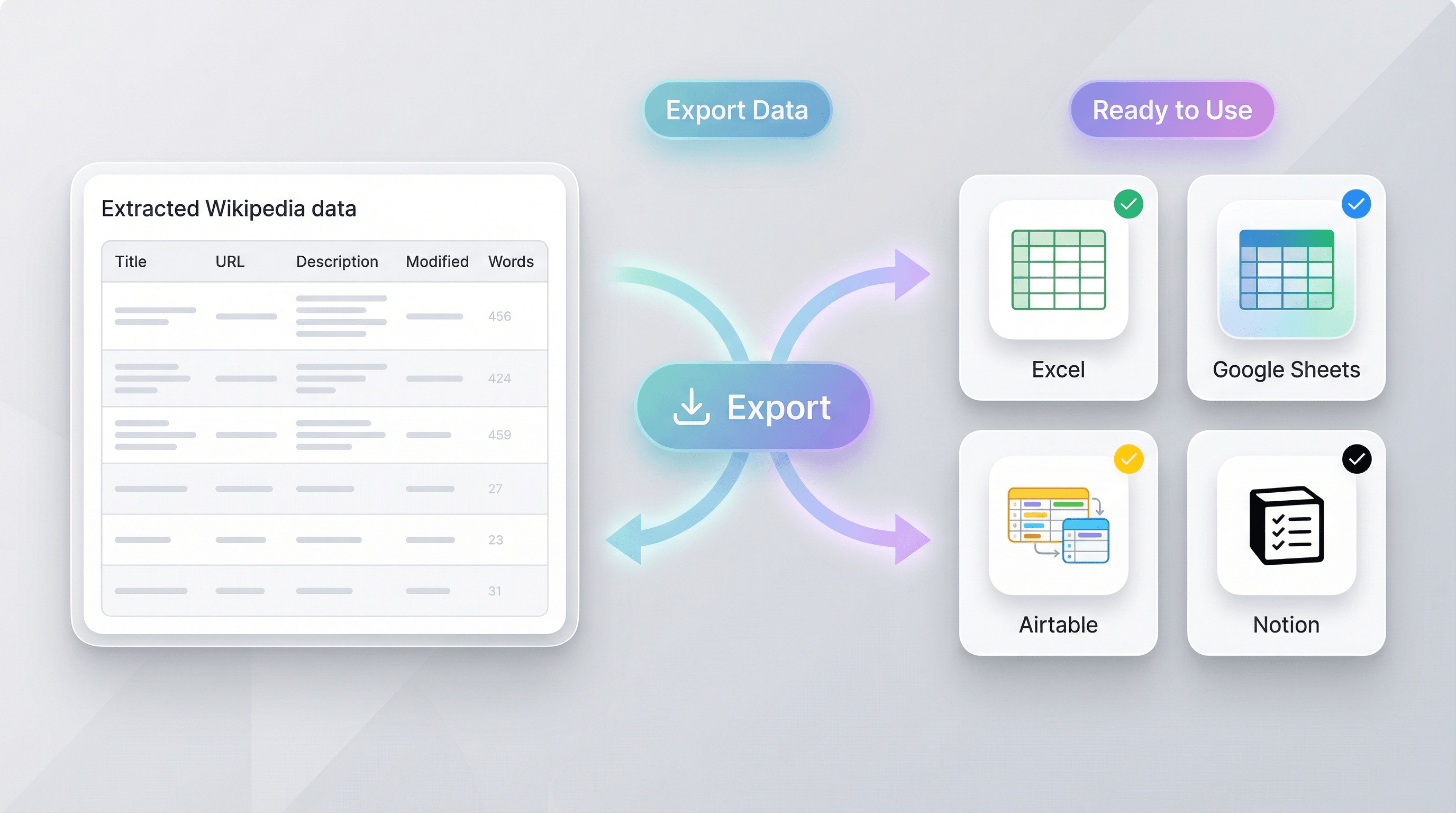
Export Wikipedia Data to Spreadsheets and Databases
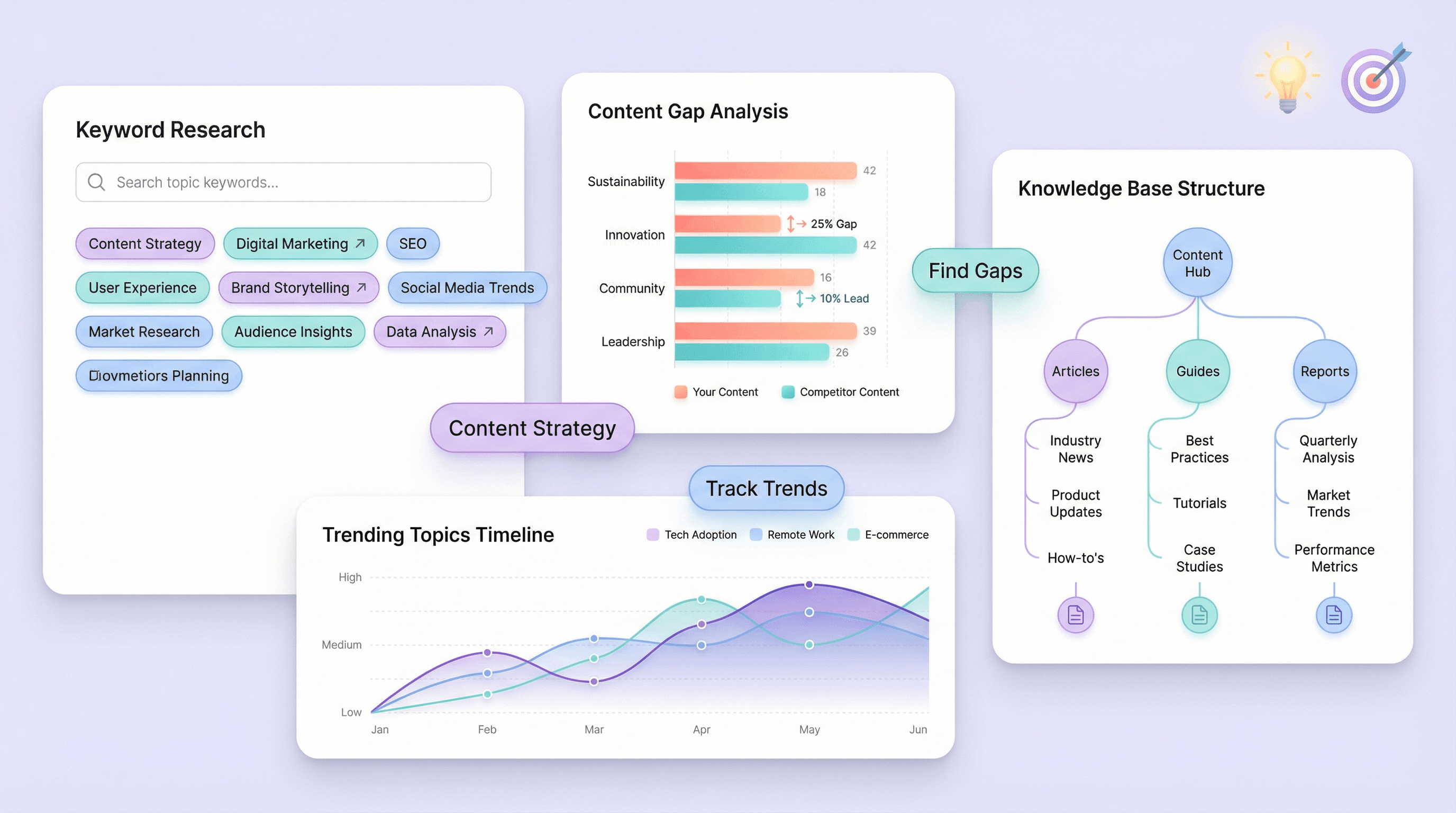
Support Content Strategy and SEO Research
Daha Fazla Ücretsiz Araç Keşfet
Sitemap çıkarıcı
Bir XML sitemap URL’sini ayrıştırın ve her sayfa bağlantısını temiz bir tabloda listeleyin. Site yapısını hızla denetleyin, SEO ve QA için eksik ya da beklenmeyen URL’leri bulun.
Bir Web Sitesinden Görsel Çıkarıcı
Herhangi bir web sayfasındaki tüm görselleri anında çıkarın ve kısa sürede indirin. Tamamen ücretsiz, hızlı ve dışa aktarması son derece kolay.
Liste tarayıcı
Herhangi bir web sayfası URL'sinden sıralı ve sırasız liste öğelerini çıkarın. Temel noktaları hızlıca yakalamak için gruplandırılmış listeleri düz metin olarak inceleyin.
Google Scholar Kazıyıcı
Bir Google Scholar sayfasından akademik sonuçları çıkarın ve daha hızlı araştırma için makale başlıklarını, atıfları, yazarları ve yayın ayrıntılarını CSV olarak dışa aktarın.
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
URL Çıkarıcı ve Toplu İndirici
Herhangi bir sayfadaki tüm site bağlantılarını çıkarın ve CSV olarak indirin. Araştırma, analiz veya veri toplama görevleri için URL’leri hızlıca toplayın.
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
Amazon Ürünleri Çıkarıcı
Ürün URL’lerini yapıştırarak Amazon’dan ürün bilgilerini çıkarın. Başlık, fiyat, puan ve daha fazlasını düzenli bir tabloda toplayarak hızlıca dışa aktarın ve inceleyin.
Görüntüden Excel’e Dönüştürücü
Tablo, fiş veya liste görsellerini kolayca Excel'e aktarılabilir yapılandırılmış JSON dizilerine dönüştürün. Manuel veri girişinde zaman kazanın ve doğruluğu artırın.
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
AI E-posta Konu Satırı Oluşturucu
Kısa bir açıklamadan etkileyici e-posta konu satırları oluşturun. Yapay zekâ destekli önerilerle açılma oranlarınızı artırın. Hızlı, kolay ve kayıt gerektirmez.
Telefon Numarası Çıkarıcı
Telefon numaralarını bulmak için web sayfalarını, dosyaları veya metni hızla tarayın. Temiz ve dışa aktarılabilir bir listeyi saniyeler içinde alın; iletişim listeleri oluşturmak veya verileri doğrulamak için idealdir.
E-posta çıkarıcı ve doğrulayıcı
Web sayfalarından, PDF’lerden veya metinden Email Extractor ile e-posta adreslerini bulun ve çıkarın. Hızlı, doğru ve istediğiniz an dışa aktarmaya hazır.
E-posta konu satırı test aracı
Bir konu satırını uzunluk, netlik, aciliyet, kişiselleştirme ve spam riski açısından puanlayın. Açılma oranını artırmak için uygulanabilir ipuçları alın.